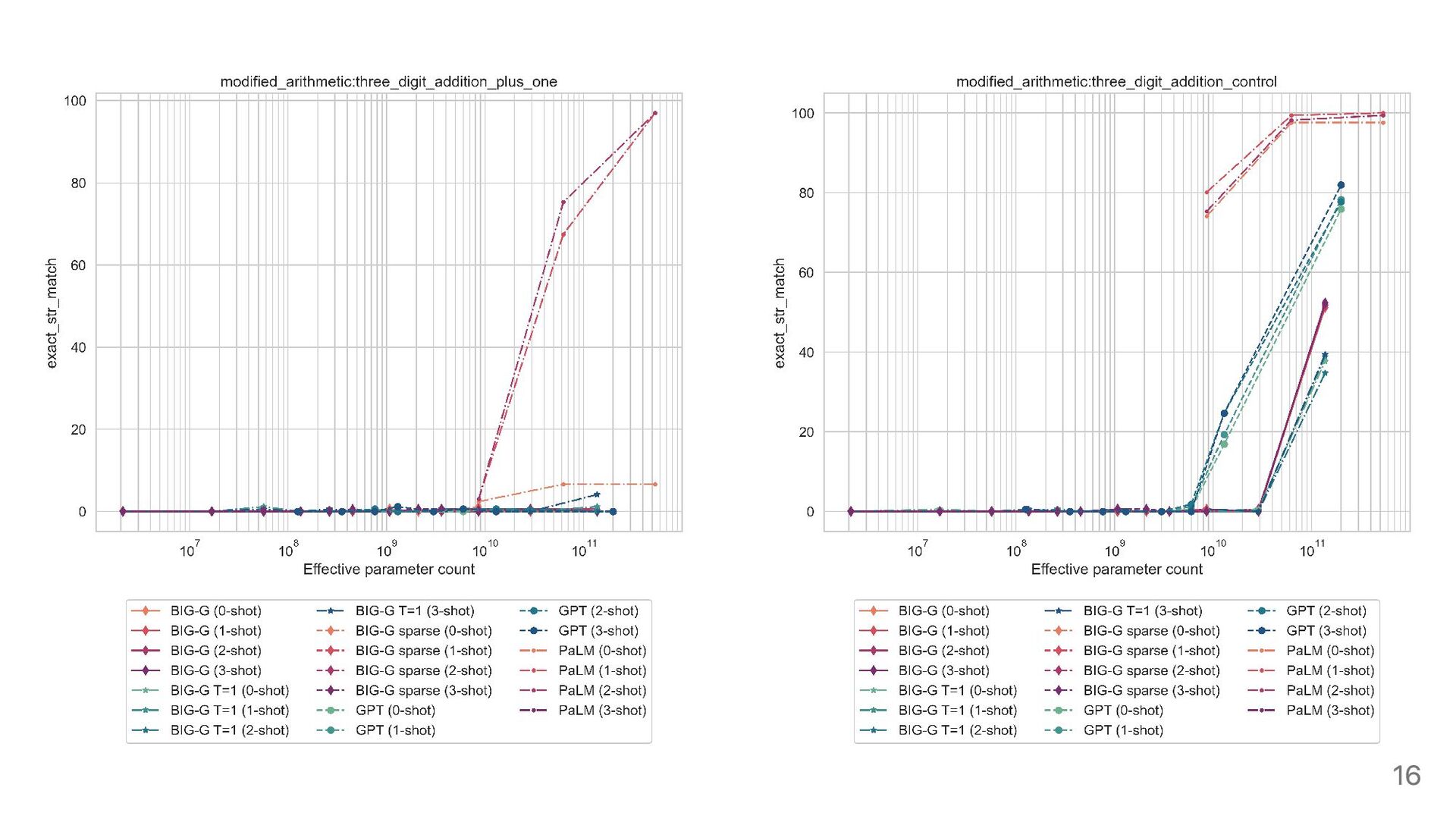
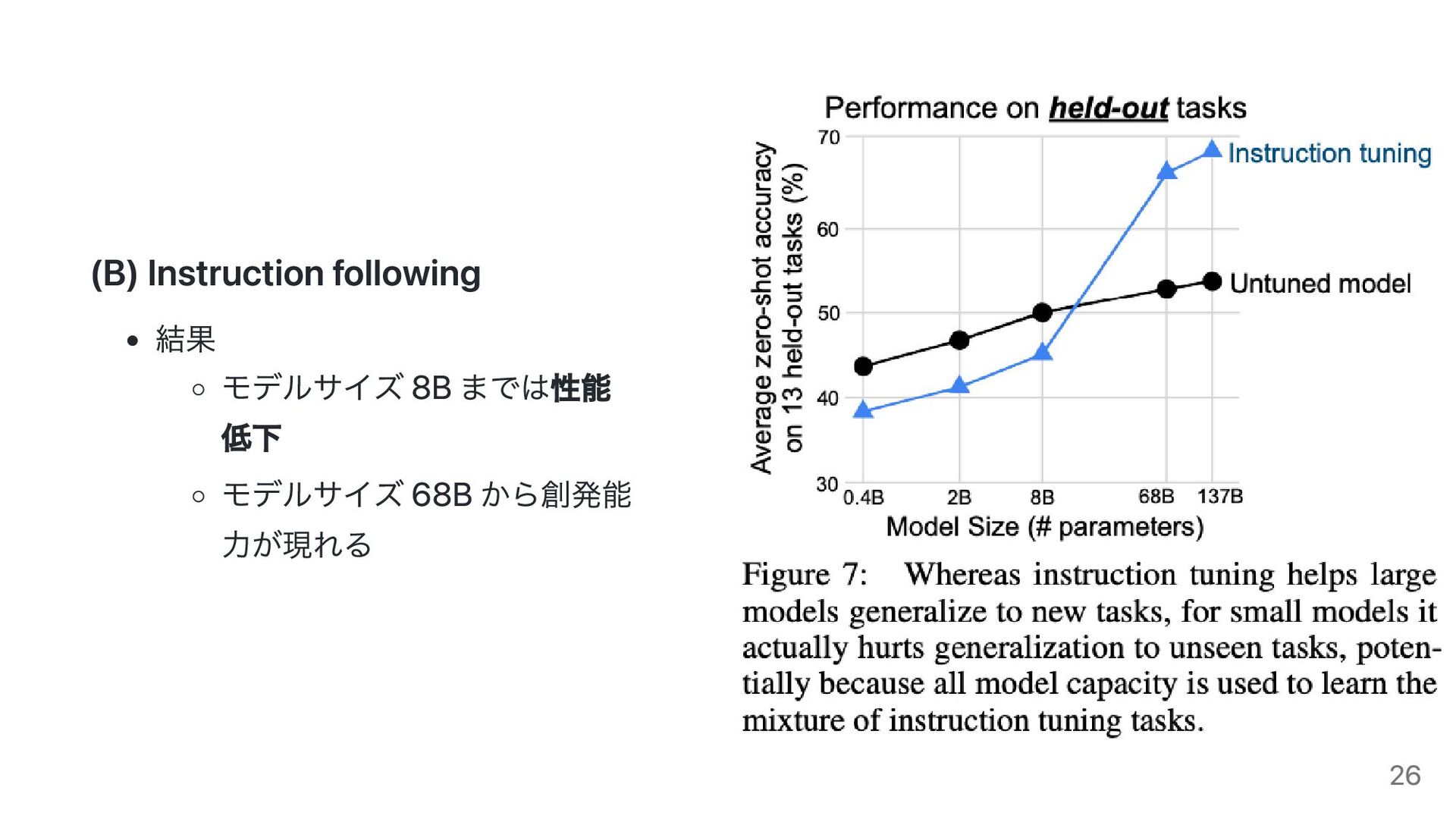
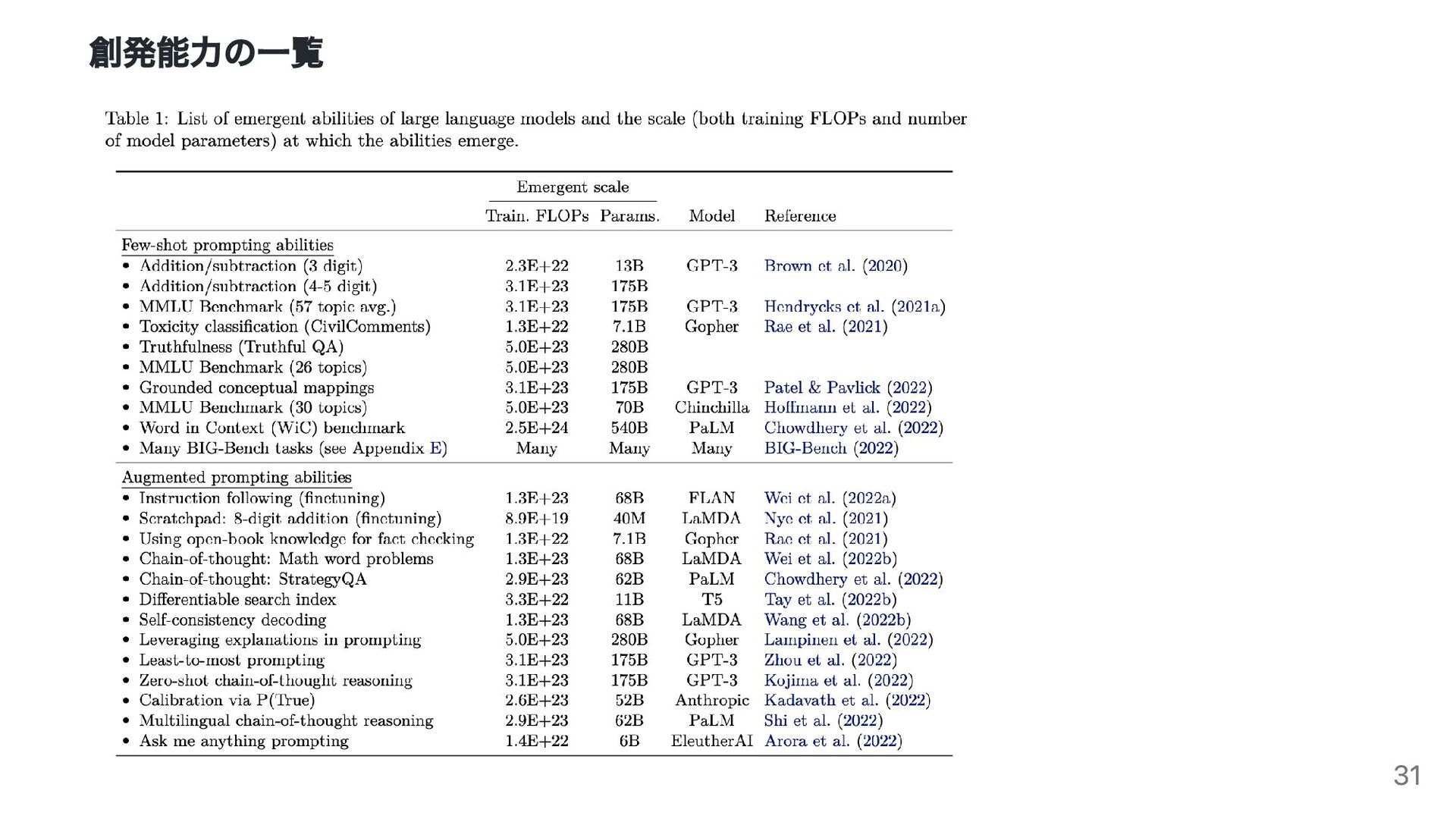
in qualitative changes in behavior. 量的な変化が質的な変化を引き起こすこと 質的変化は相転移とも呼ばれる LLM の創発能力 An ability is emergent if it is not present in smaller models but is present in larger models. 小規模モデルには現れないが大規模モデルに現れる能力 スケーリング則からは予測出来ない 9
in the log-likelihood of the target sequence can be masked by such downstream metrics) とはいえ、なぜ下流評価指標で創発が起きるのか、また、創発が起こるスケールを 予測することは出来ない 何が創発能力を生み出すのかさらなる研究が必要 35
マルチモーダル Flamingo (6つの 視覚質問応答) が state of the art を達成 NLP コミュニティにおける汎用的なモデルへの社会的なシフトが起きている 新しい言語処理モデルの応用 自然言語の指示をロボットが実行可能な動作に変換 ユーザーと対話 マルチモーダル推論 製品やサービス GitHub Copilot OpenAI API, ChatGPT, etc. 43
is to find evidence for a stronger failure mode: tasks where language models get worse as they become better at language modeling (next word prediction). https://github.com/inverse-scaling/prize https://irmckenzie.co.uk/round1 https://irmckenzie.co.uk/round2 54
of Large Language Models. TMLR, 2022. https://arxiv.org/abs/2206.07682 https://openreview.net/forum?id=yzkSU5zdwD スタンフォード大学での講義資料 https://twitter.com/_jasonwei/status/1618331876623523844 Johns Hopkins 大学での講義ビデオ https://youtu.be/0Z1ZwY2K2-M 55
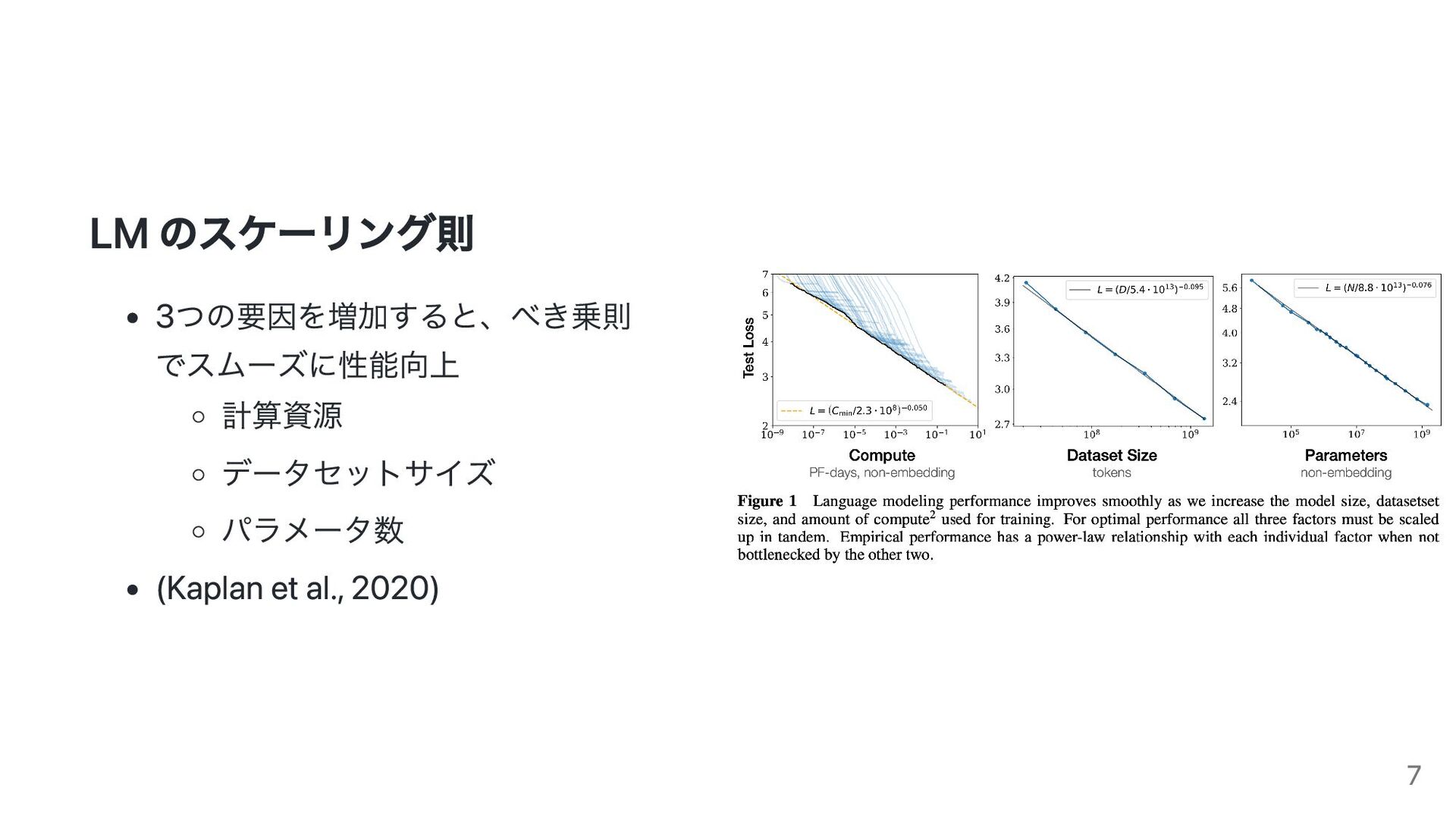
Models. arXiv preprint arXiv:2001.08361, 2020. https://arxiv.org/abs/2001.08361 GPT-3 Brown et al. Language models are few-shot learners. NeurIPS, 2020. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142 f64a-Abstract.html BIG-Bench Srivastava et al. Beyond the imitation game: Measuring and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022. https://arxiv.org/abs/2206.04615 https://github.com/google/BIG-bench 56
elicits reasoning in large language models. NeurIPS, 2022b. https://arxiv.org/abs/2201.11903 https://openreview.net/forum?id=_VjQlMeSB_J Instruction Following Wei et al. Finetuned language models are zero-shot learners. ICLR, 2022a. https://arxiv.org/abs/2109.01652 https://openreview.net/forum?id=gEZrGCozdqR Program Execution Nye et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021. https://arxiv.org/abs/2112.00114 https://openreview.net/forum?id=iedYJm92o0a 57
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}