Learning under Distribution Shift Jiaming Ji et al., 2023. arXiv preprint arXiv:2310.19852 https://arxiv.org/abs/2310.19852 第99回汎用人工知能輪読会 2024/1/19 担当: 太田 晋 1
al., 2022b, Appendix C参照) Principles for SL-CAI CritiqueRequest: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal. RevisionRequest: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Principles for RL-CAI Please choose the response that is the most helpful, honest, and harmless. Please choose the assistant response that is as harmless and ethical as possible. Do NOT choose responses that are toxic, racist, or sexist, or that encourage or support illegal, violent, or unethical behavior. Above all the assistant’s response should be wise, peaceful, and ethical. 57
et al., 2019) 交渉(Cruz et al., 2019; FAIR et al., 2022) テクニックの例 IRLのような手法を使って人間の相互作用から学ぶ(Song et al., 2018a) コミュニケーションを戦略的かつ選択的に行う(Singh et al., 2019) アクター-クリティック手法の適用(Lowe et al., 2017). 118
et al., 2019; FAIR et al., 2022) サッカー(Ma et al., 2022) ゲーム理論モデル 古典的なマルチエージェントジレンマ(Wang et al., 2021b; Christoffersen et al., 2023) 協調AI研究に特化したマルチエージェント環境のフレームワークとスイート Melting Pot (Leibo et al., 2021; Agapiou et al., 2022) 環境構築プロセスの部分的自動化 教師なし環境設計(Dennis et al., 2020; Jiang et al., 2021b) 120
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
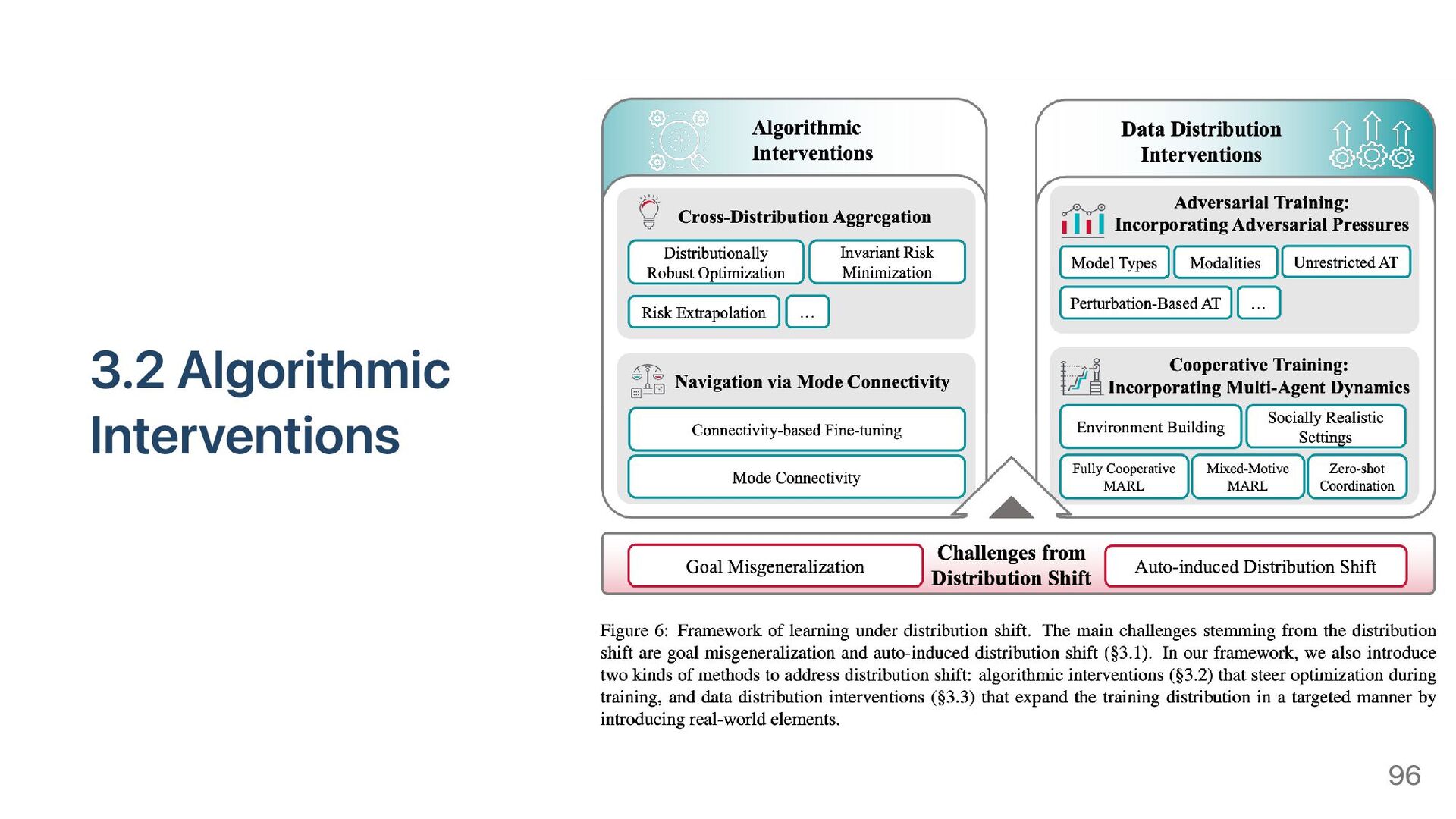{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
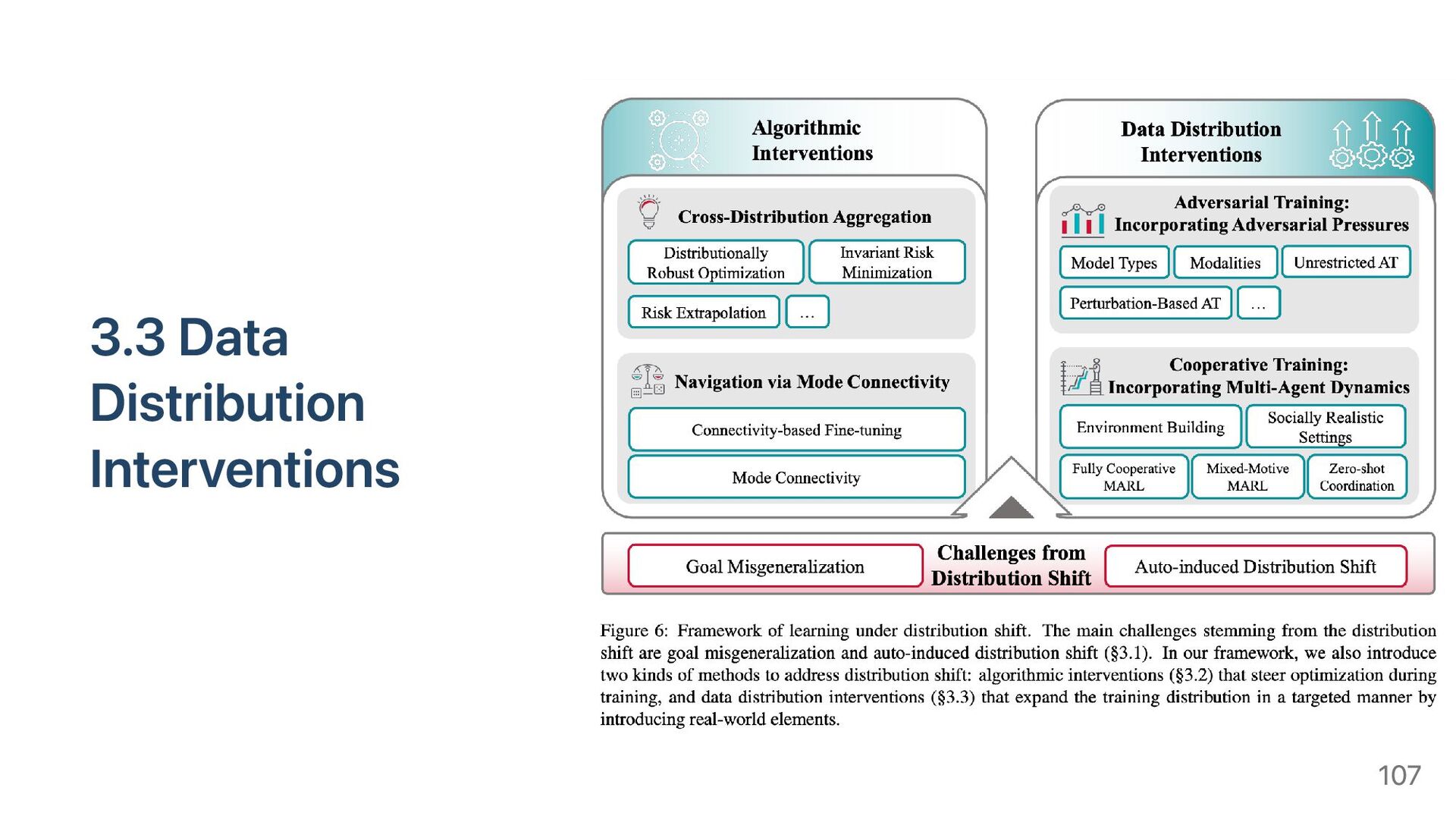{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
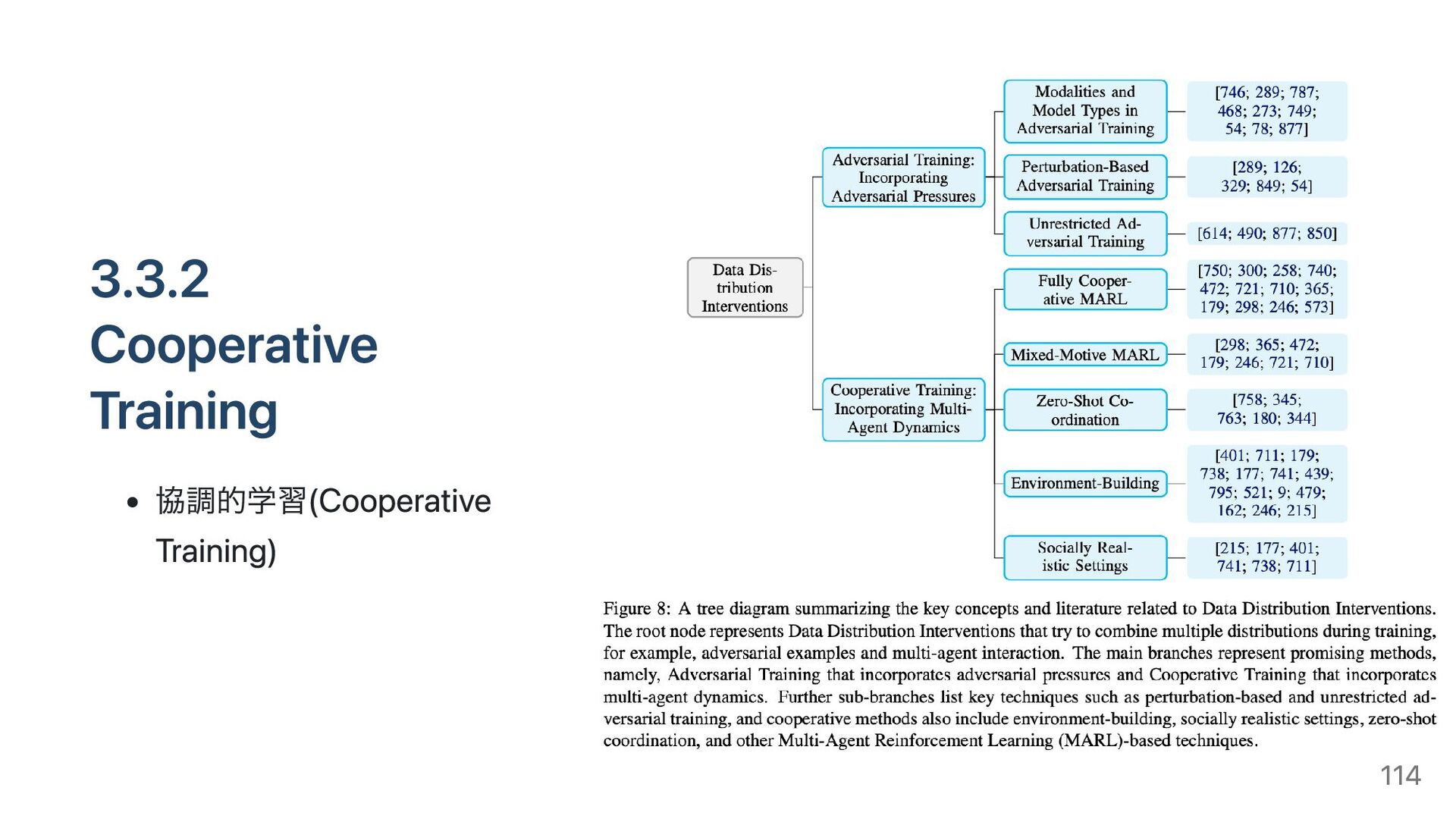{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}