World Models", ICML 2020, 2020. https://arxiv.org/abs/2005.05960 • Pathak et al., "Self-Supervised Exploration via Disagreement". ICML 2019, 2019. https://arxiv.org/abs/1906.04161 • Burda et al., "Large-Scale Study of Curiosity-Driven Learning", ICLR 2019, 2019. https://openreview.net/forum?id=rJNwDjAqYX • Burda et al., "Exploration by Random Network Distillation", ICLR 2019, 2019. https://openreview.net/forum?id=H1lJJnR5Ym • Pathak et al., "Curiosity-driven Exploration by Self-supervised Prediction", ICML 2017, 2017. https://arxiv.org/abs/1705.05363 • Bellemare et al., "Unifying Count-Based Exploration and Intrinsic Motivation", NIPS 2016, 2016. https://arxiv.org/abs/1606.01868 • Hafner et al., "Dream to Control: Learning Behaviors by Latent Imagination", ICLR 2020, 2020. https://openreview.net/forum?id=S1lOTC4tDS • Badia et al., "Agent57: Outperforming the Atari Human Benchmark", arXiv preprint arXiv:2003.13350, 2020. https://arxiv.org/abs/2003.13350 • Badia et al., "Never Give Up: Learning Directed Exploration Strategies", ICLR2020, 2020. https://openreview.net/forum?id=Sye57xStvB • Finn et al., "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks", ICML 2017. 2017. https://arxiv.org/abs/1703.03400 • Baker et al., "Emergent Tool Use From Multi-Agent Autocurricula", ICLR2020, 2020. https://openreview.net/forum?id=SkxpxJBKwS • Chua, K. et al., “Deep reinforcement learning in a handful of trials using probabilistic dynamics models.”, NIPS 2018, 2018. https://arxiv.org/abs/1805.12114 • Leibo et al., "Autocurricula and the Emergence of Innovation from Social Interaction: A Manifesto for Multi-Agent Intelligence Research", arXiv preprint arXiv:1903.00742, 2019. https://arxiv.org/abs/1903.00742 • Sutton et al., "Reinforcement Learning: An Introduction second edition", MIT Press, 2018. http://incompleteideas.net/book/the-book- 2nd.html • Tassa et al., "dm_control: Software and Tasks for Continuous Control", arXiv preprint arXiv:2006.12983, 2020. https://arxiv.org/abs/2006.12983 2020/08/26 第69回 汎用人工知能輪読会 担当:太田 晋 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
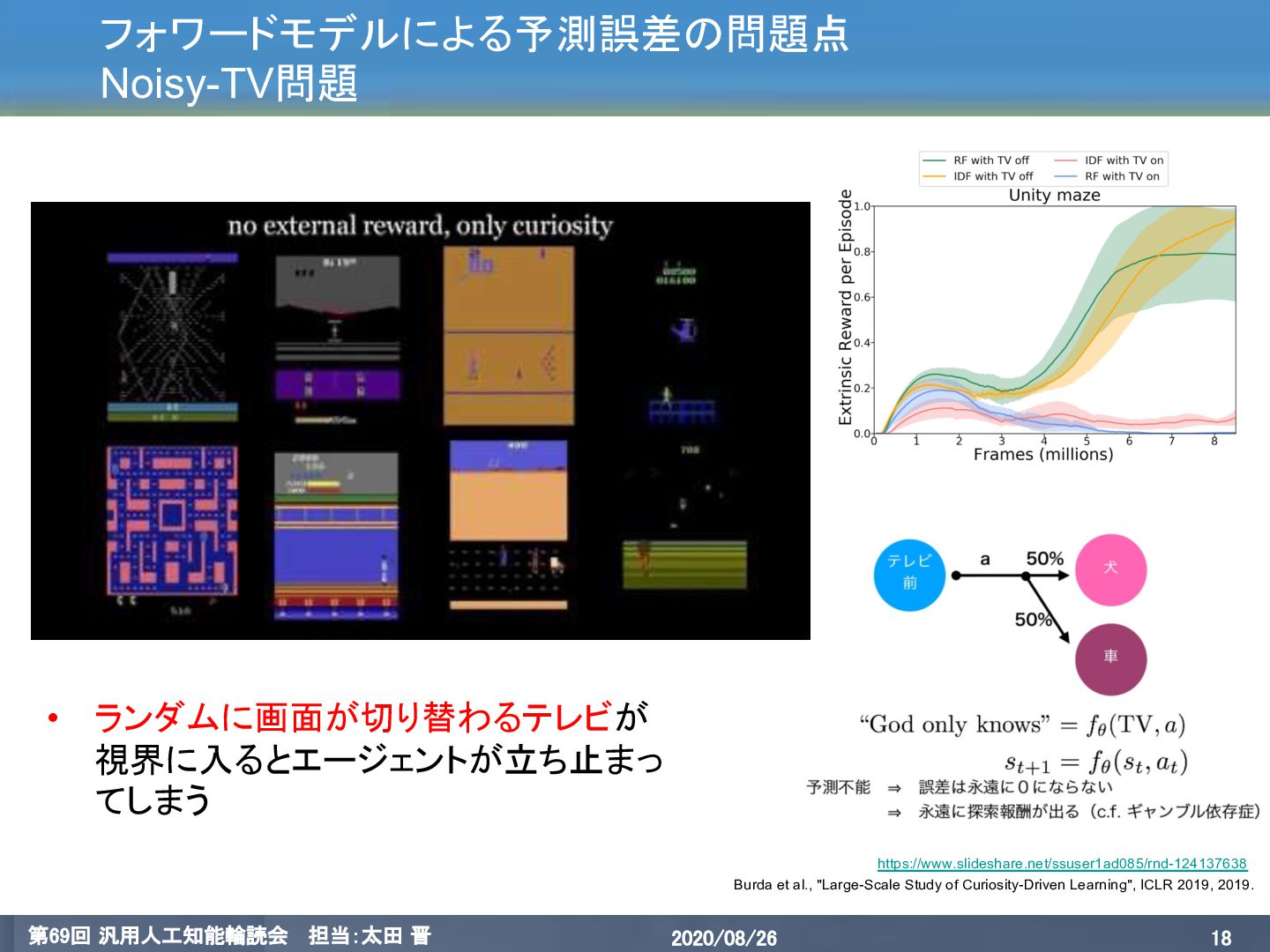{kind=link}
{kind=link}
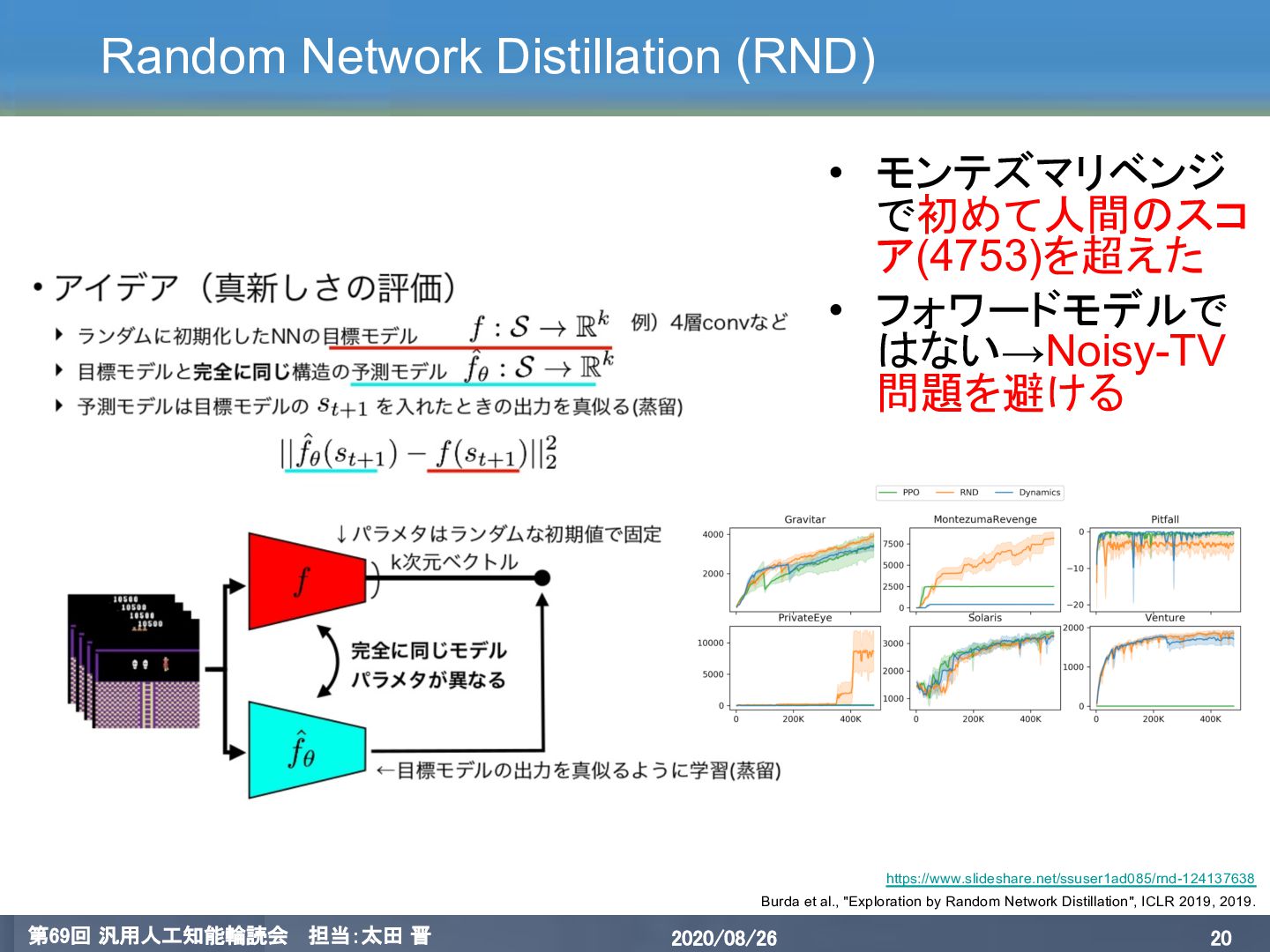{kind=link}
{kind=link}
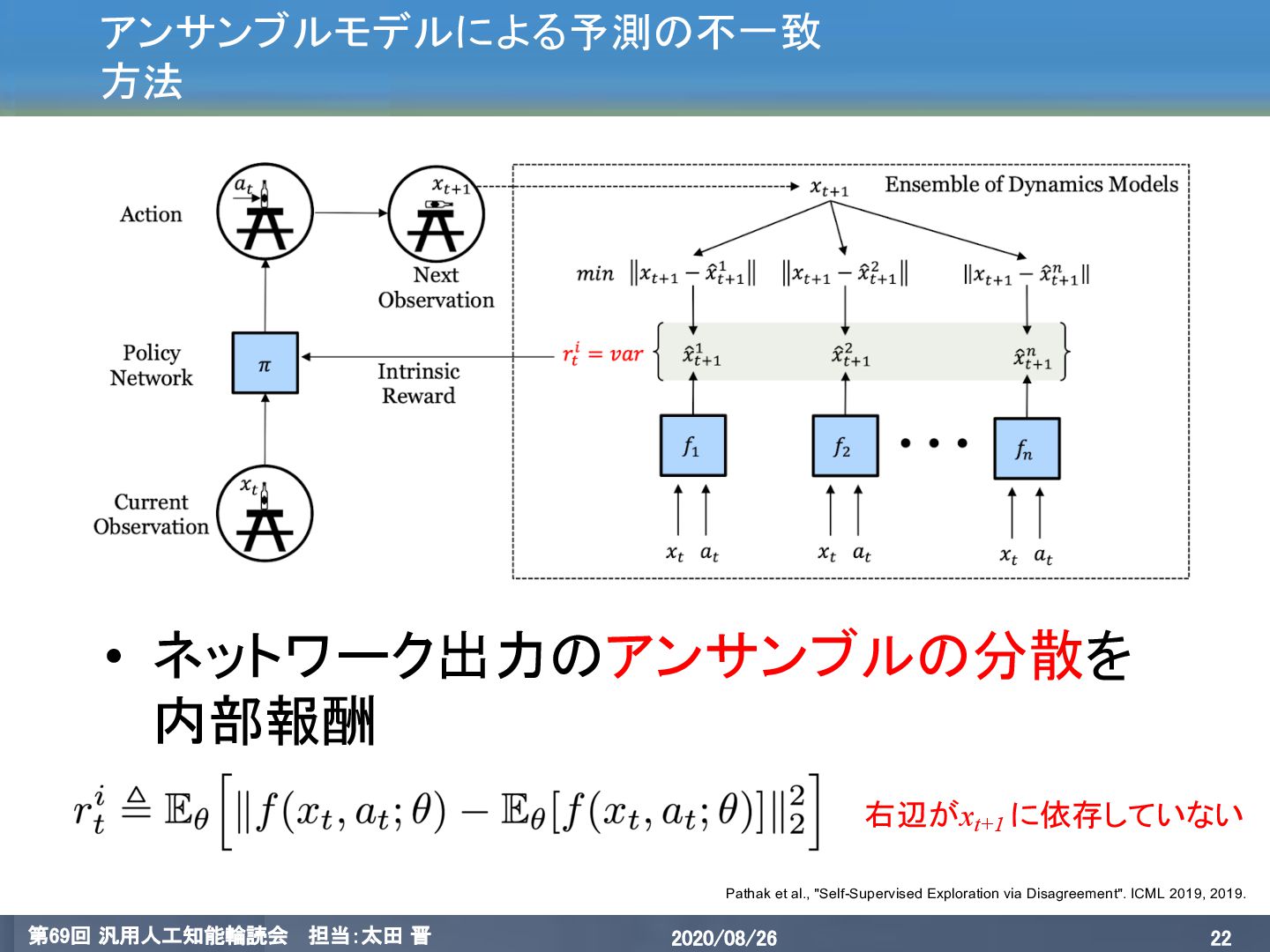{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}