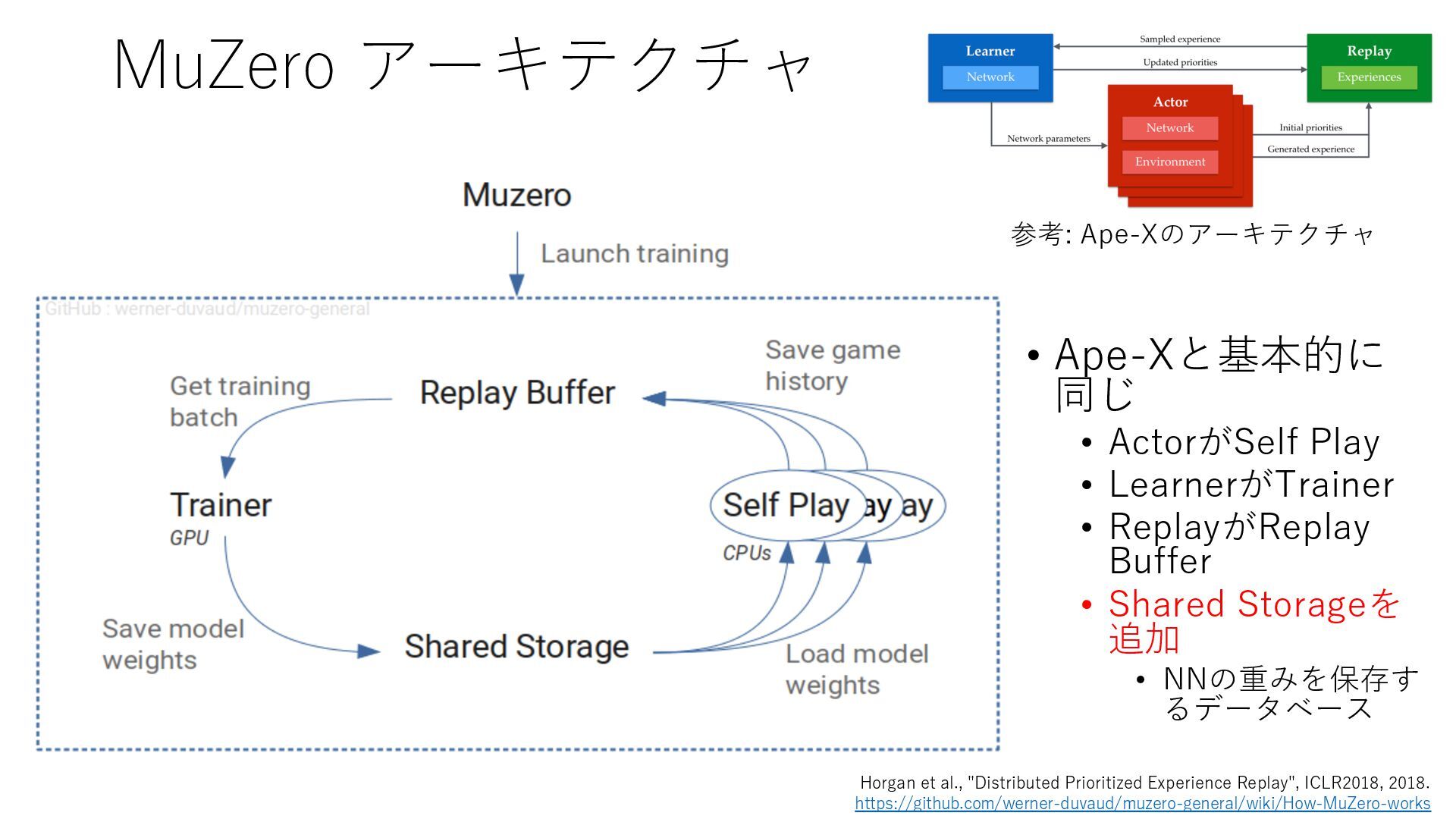
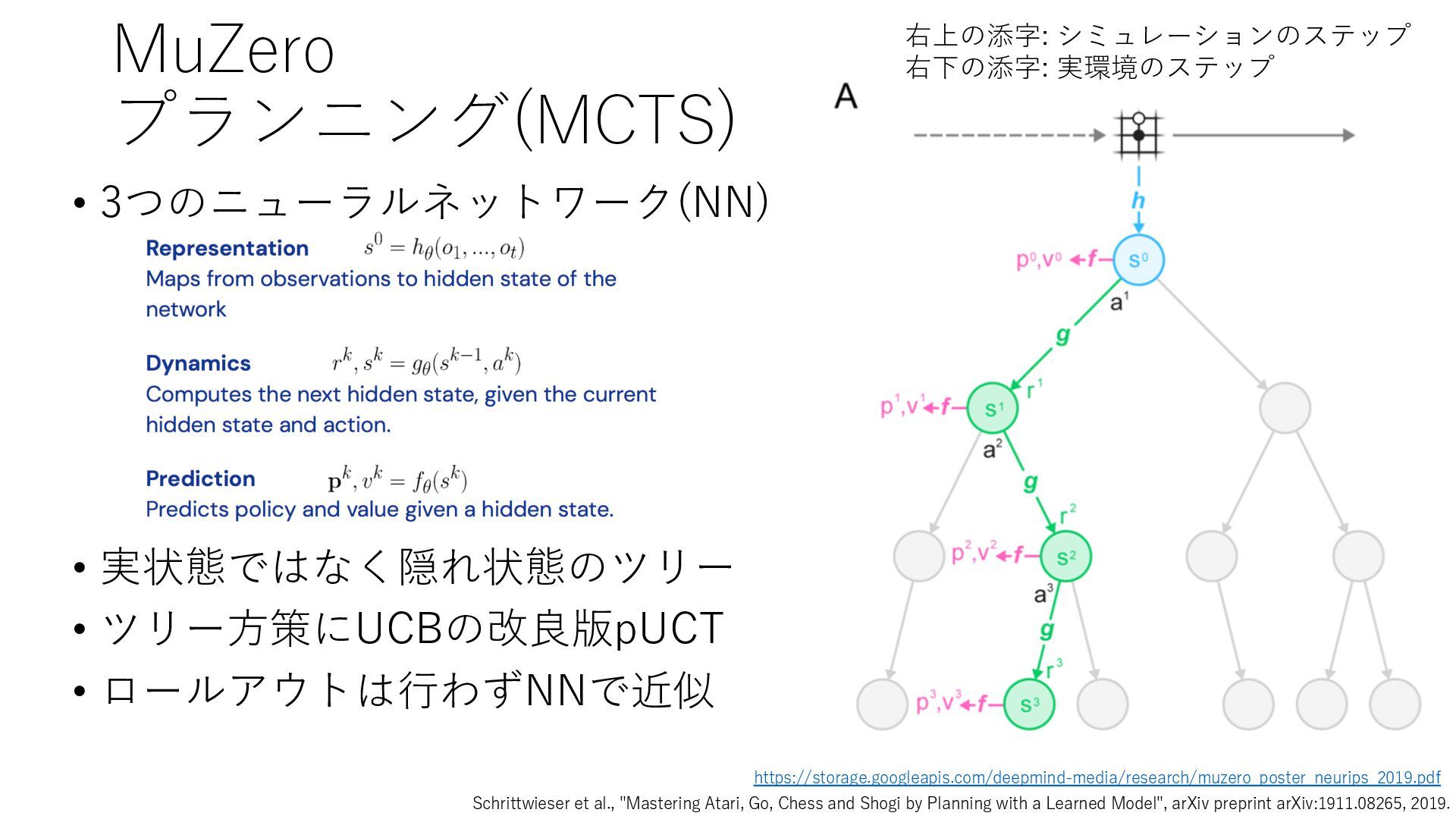
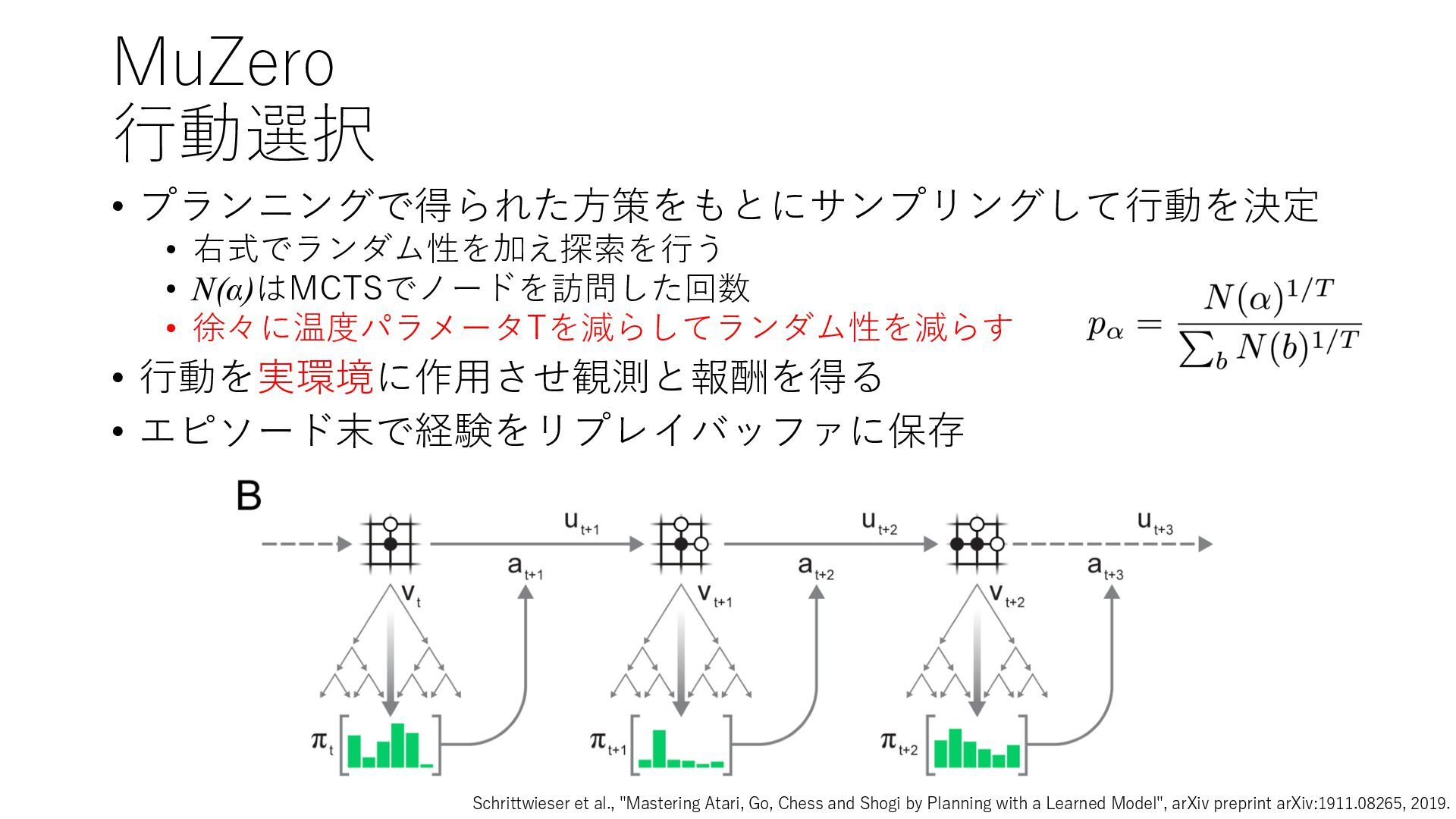
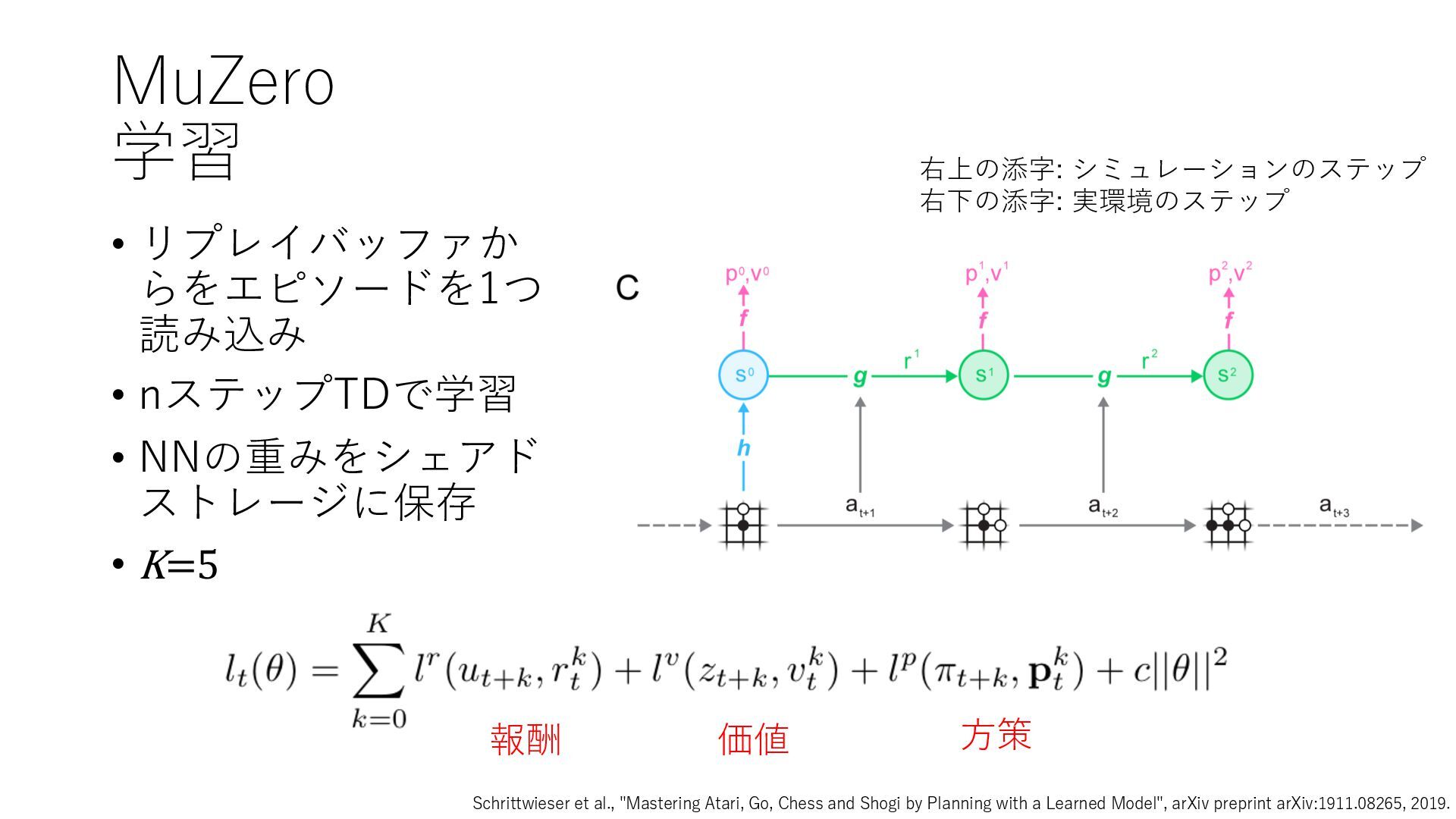
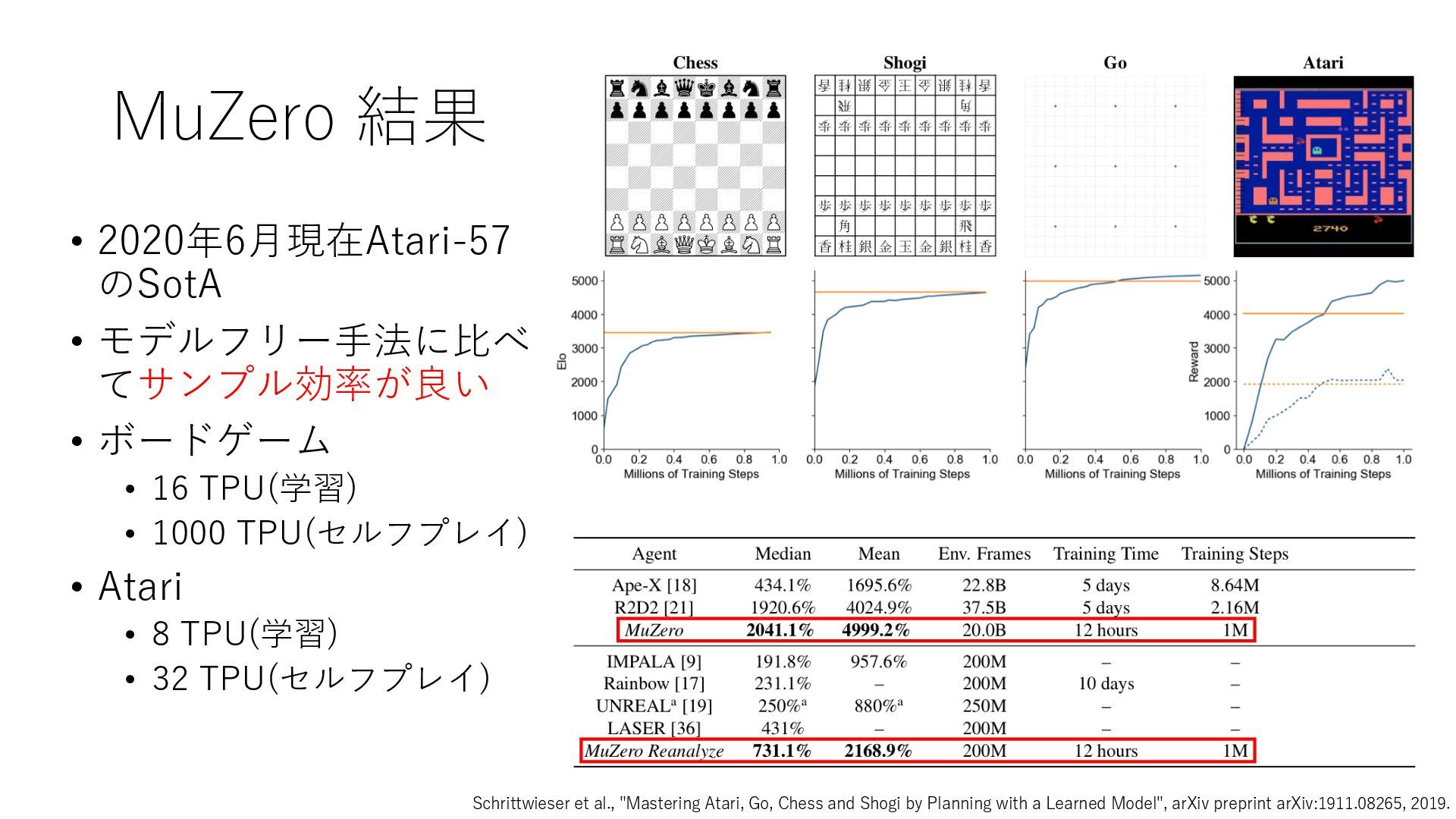
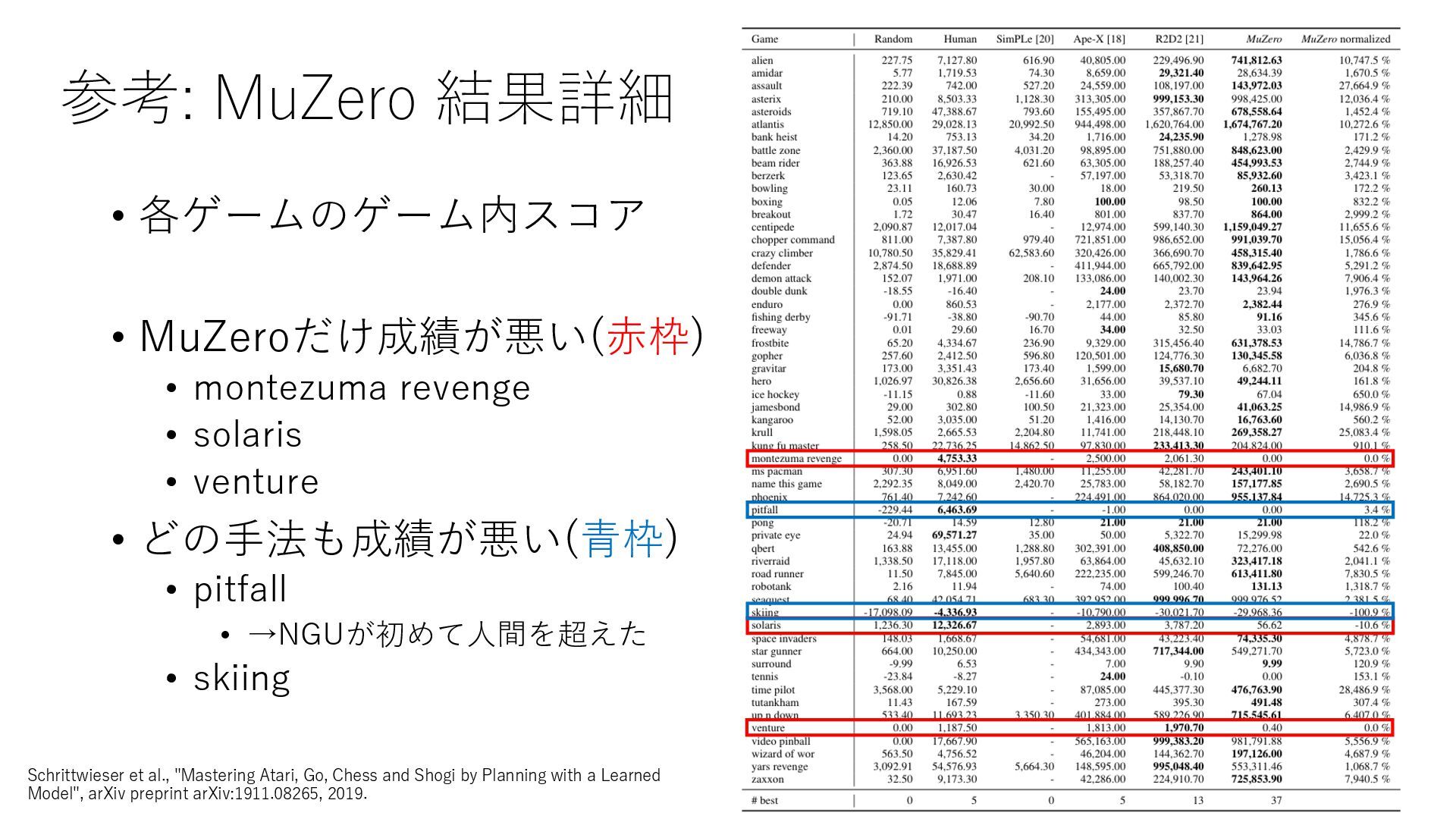
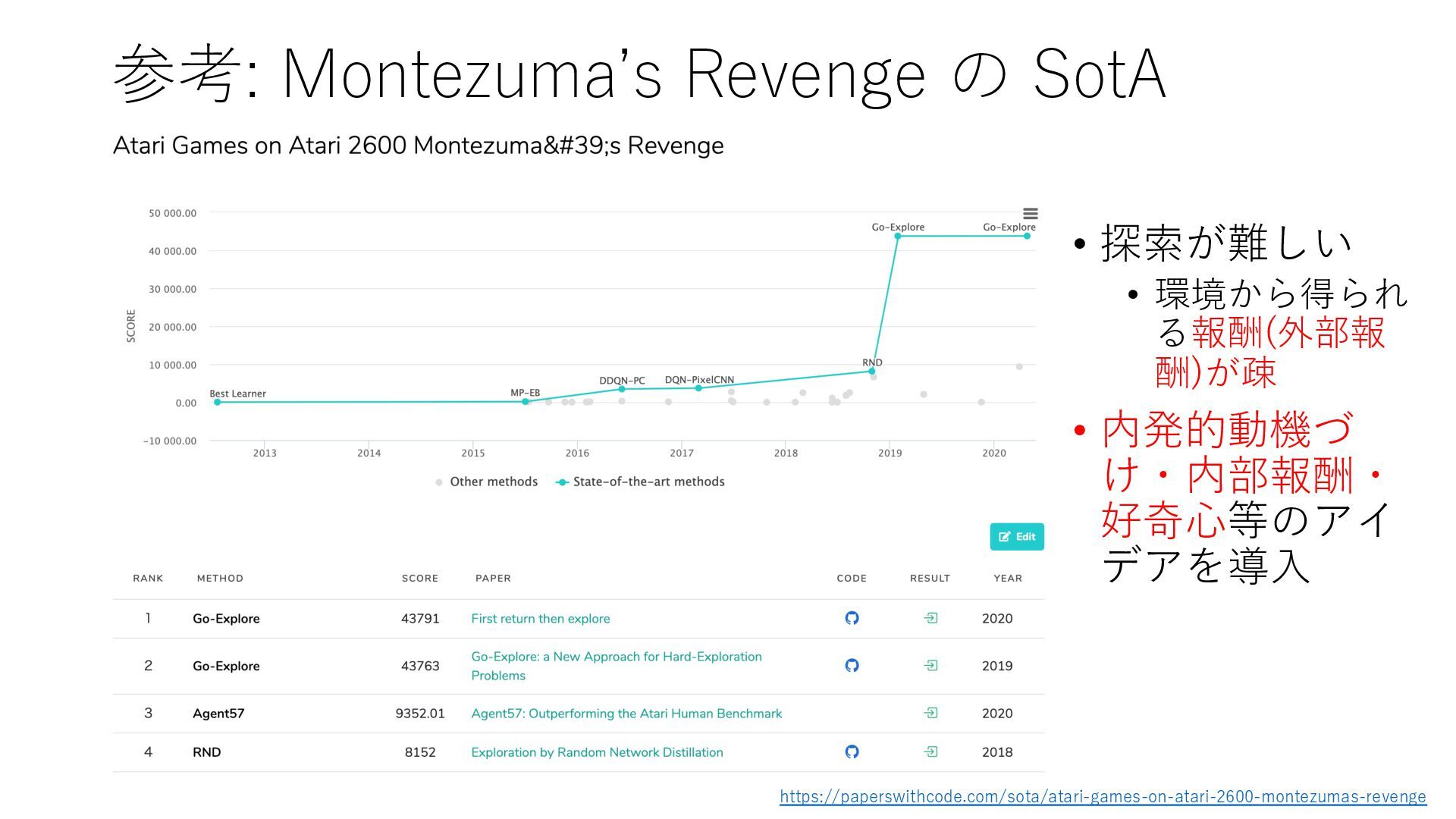
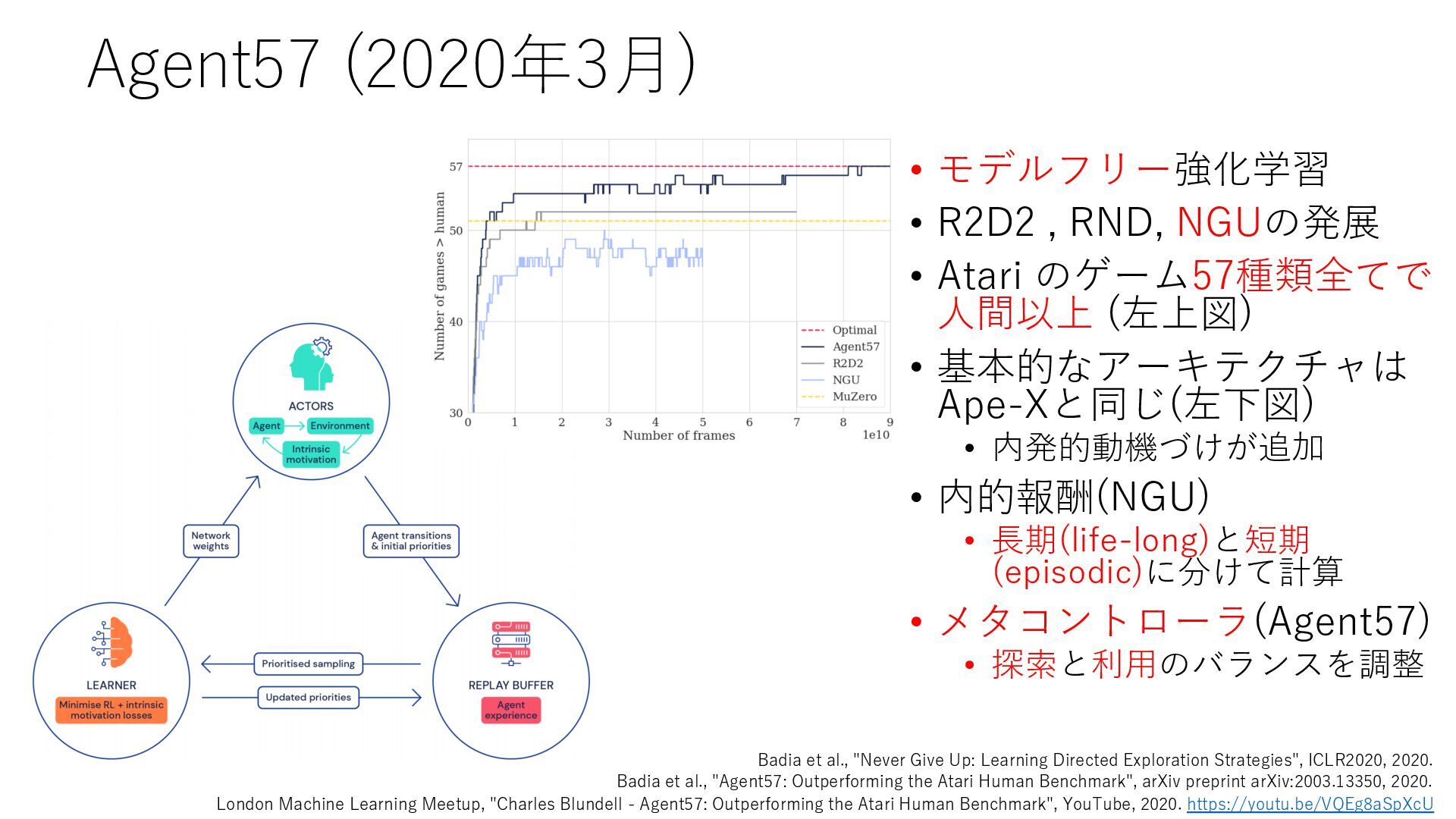
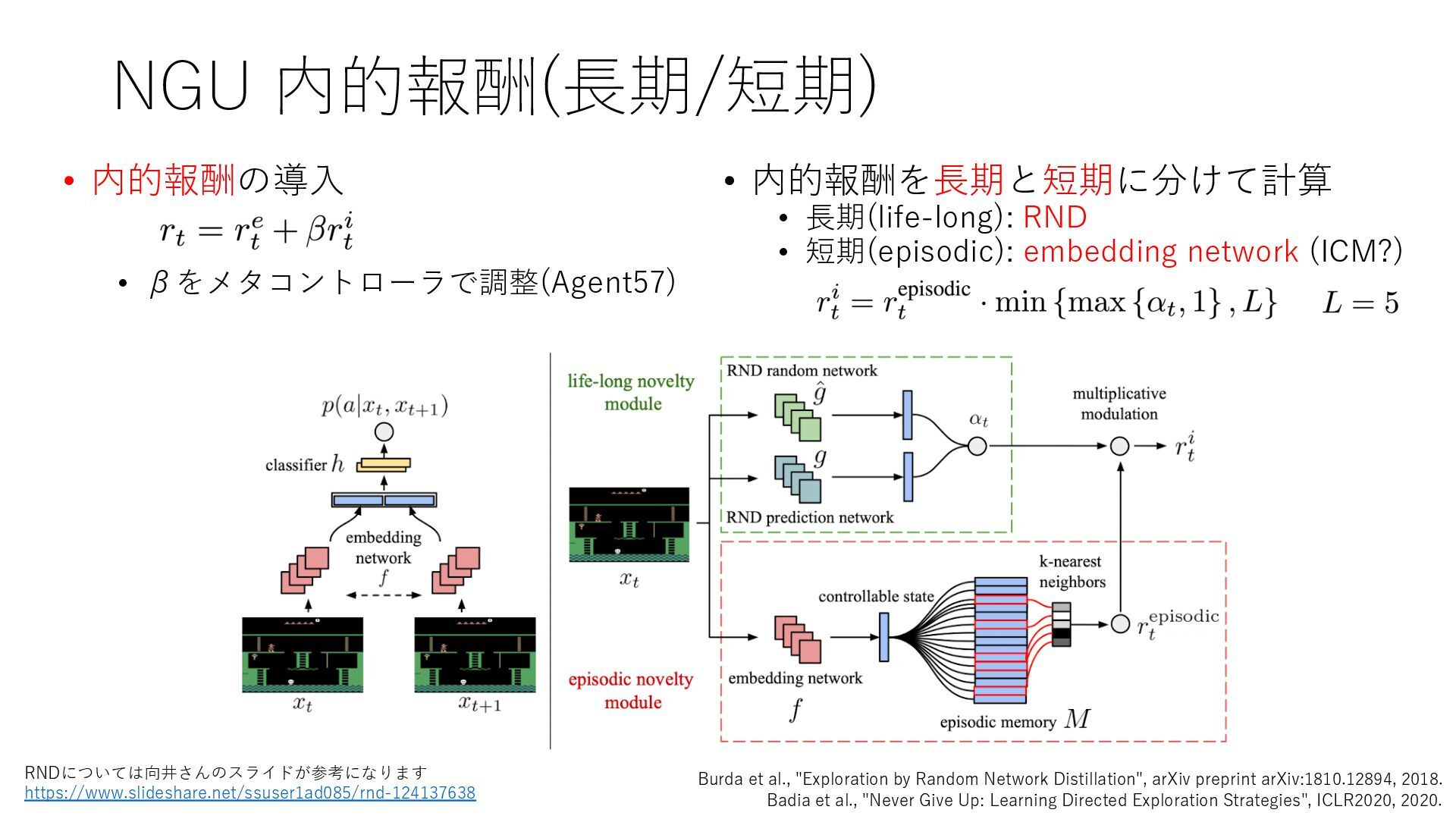
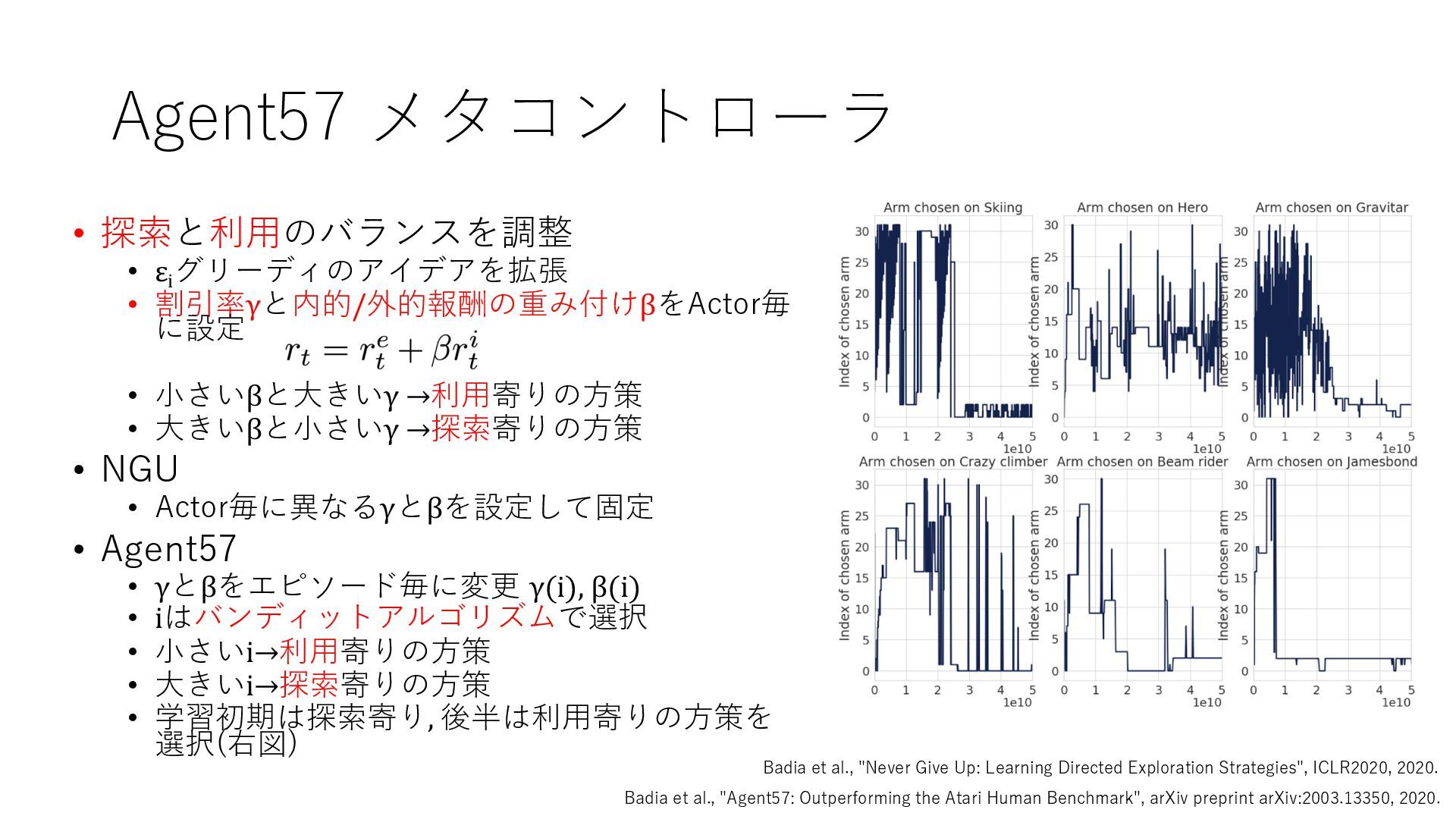
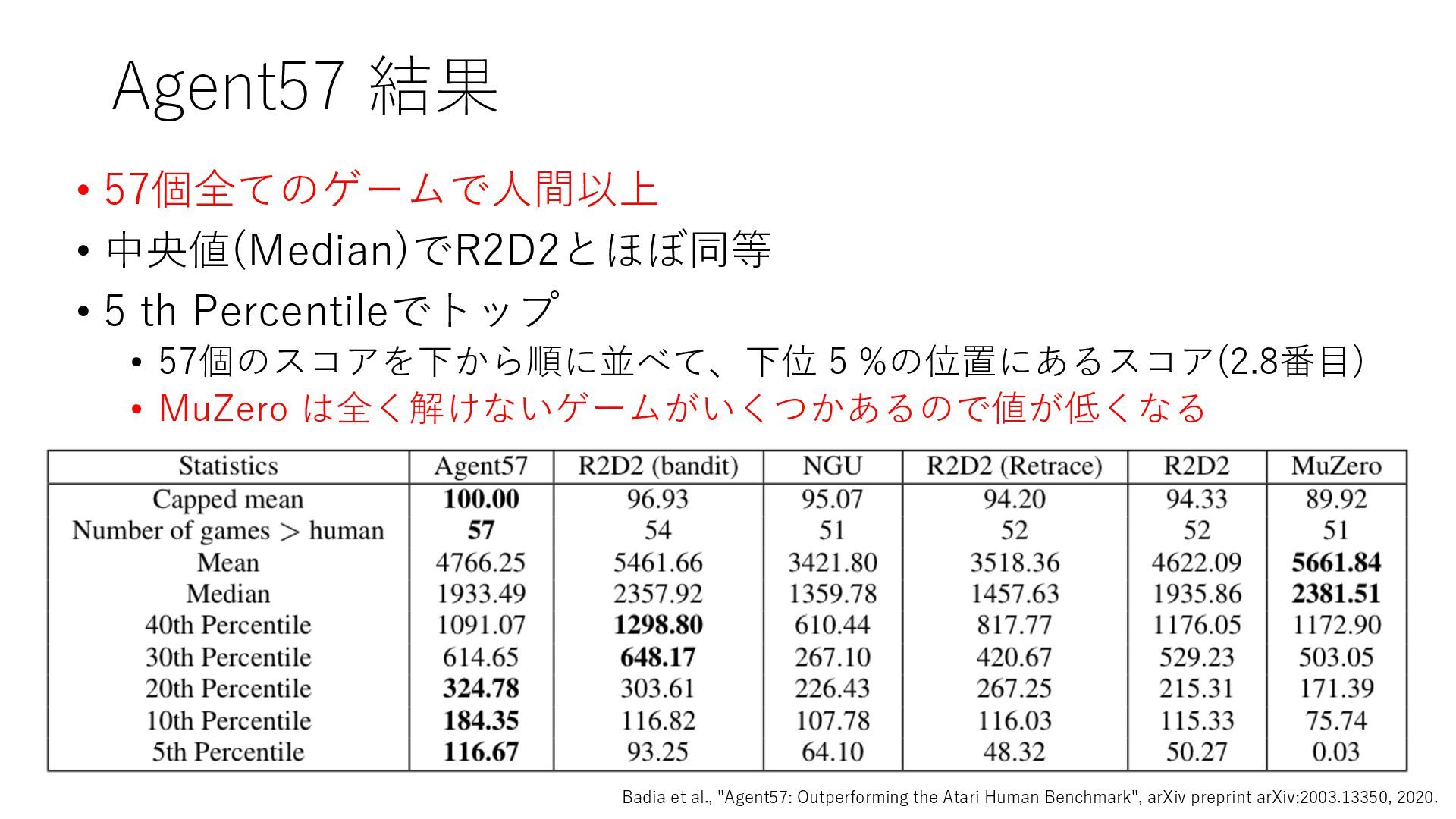
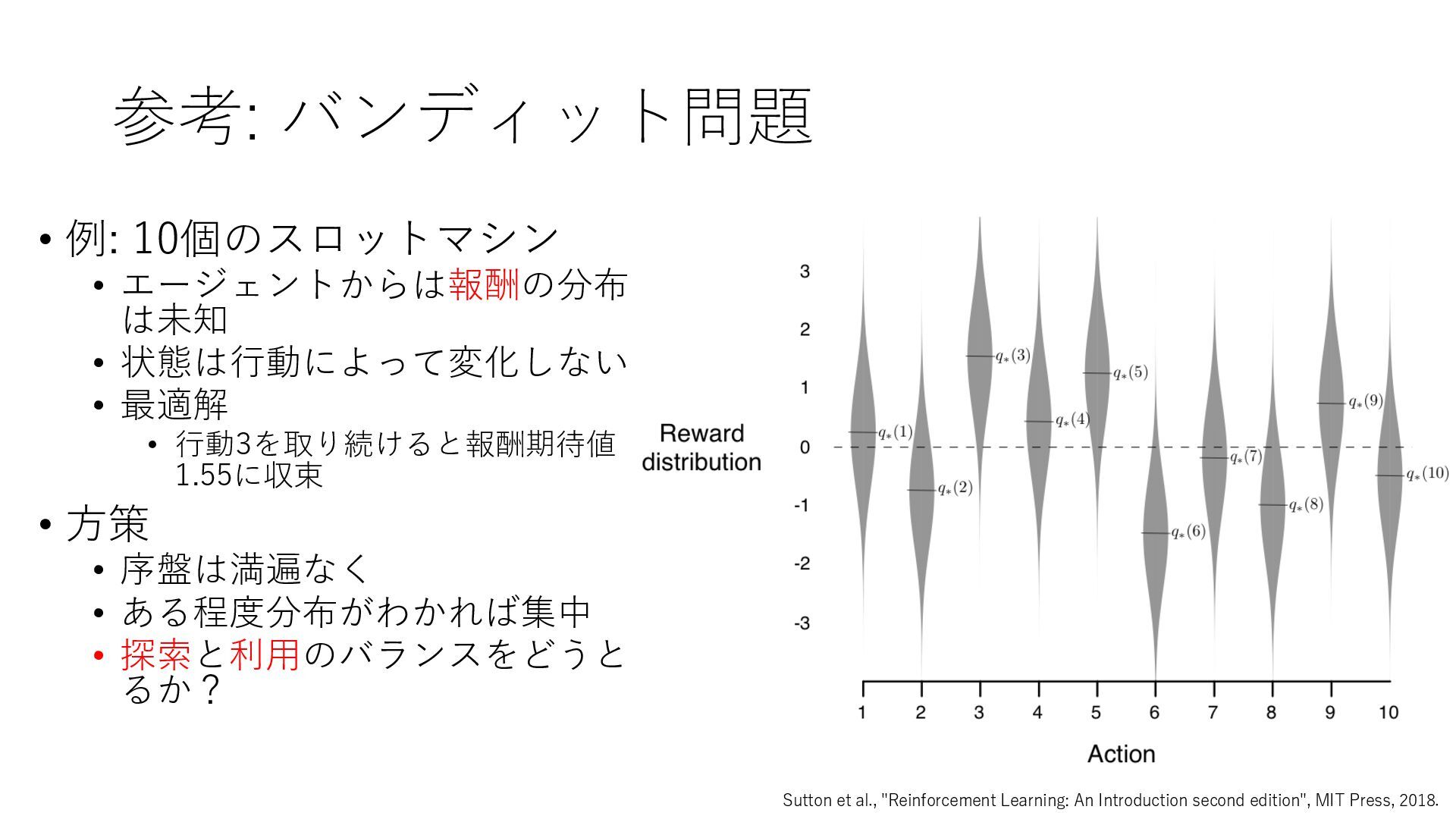
Deep Reinforcement Learning", arXiv preprint arXiv:1312.5602, 2013. https://arxiv.org/abs/1312.5602 • Mnih et al., "Human-level control through deep reinforcement learning", Nature, 2015. https://www.nature.com/articles/nature14236 • Prioritized Experience Replay • Schaul et al., "Prioritized Experience Replay", ICLR2016, 2016. https://arxiv.org/abs/1511.05952 • Rainbow • Hessel et al., "Rainbow: Combining Improvements in Deep Reinforcement Learning", AAAI- 18, 2018. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/download/17204/16680 • Ape-X • Horgan et al., "Distributed Prioritized Experience Replay", ICLR2018, 2018. https://openreview.net/forum?id=H1Dy---0Z • R2D2 • Kapturowski et al., "Recurrent Experience Replay in Distributed Reinforcement Learning", ICLR2019, 2019. https://openreview.net/forum?id=r1lyTjAqYX • MuZero • Schrittwieser et al., "Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model", arXiv preprint arXiv:1911.08265, 2019. https://arxiv.org/abs/1911.08265 • W. Duvaud, "MuZero General: Open Reimplementation of MuZero", GitHub repository, 2019. https://github.com/werner-duvaud/muzero-general • David Foster, "How To Build Your Own MuZero AI Using Python (Part 1/3)", Medium, 2019. https://medium.com/applied-data-science/how-to-build-your-own-muzero-in-python- f77d5718061a • 布留川 英⼀, "AlphaZero 深層学習・強化学習・探索 ⼈⼯知能プログラミング実践⼊⾨", ボー ンデジタル, 2019. https://www.borndigital.co.jp/book/14383.html • Agent57 • Badia et al., "Agent57: Outperforming the Atari Human Benchmark", arXiv preprint arXiv:2003.13350, 2020. https://arxiv.org/abs/2003.13350 • Badia et al., "Never Give Up: Learning Directed Exploration Strategies", ICLR2020, 2020. https://openreview.net/forum?id=Sye57xStvB • Burda et al., "Exploration by Random Network Distillation", arXiv preprint arXiv:1810.12894, 2018. https://arxiv.org/abs/1810.12894 • London Machine Learning Meetup, "Charles Blundell - Agent57: Outperforming the Atari Human Benchmark", YouTube, 2020. https://youtu.be/VQEg8aSpXcU • Sutton and Barto の強化学習の教科書 • Sutton et al., "Reinforcement Learning: An Introduction second edition", MIT Press, 2018. http://incompleteideas.net/book/the-book-2nd.html • 奥村さんの強化学習アーキテクチャ勉強会での発表スライド • “DQNからRainbowまで 〜深層強化学習の最新動向〜” https://www.slideshare.net/juneokumura/dqnrainbow • “深層強化学習の分散化・RNN利⽤の動向〜R2D2の紹介をもとに〜” https://www.slideshare.net/juneokumura/rnnr2d2 • 関⾕さんの強化学習アーキテクチャ勉強会での発表スライド • “強化学習の分散アーキテクチャ変遷” https://www.slideshare.net/eratostennis/ss- 90506270 • 向井さんの強化学習アーキテクチャ勉強会での発表スライド • ” RNDは如何にしてモンテスマズリベンジを攻略したか” https://www.slideshare.net/ssuser1ad085/rnd-124137638
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}