Лекция курса "Большие данные и машинное обучение" (v2.0-МОТ)
Лекция-6: разведочный анализ, корреляция
Регрессия, регрессионная модель — модель предсказания целевой переменной на непрерывной шкале
Часть 1: разведочный анализ, распределение значений, отношения переменных, корреляция
- Переменная на непрерывной шкале
- Разведочный анализ
- Пример: разведочный анализ в датасете ILO (МОТ - Международная организация труда) ilostat.ilo.org
- Что с чем может коррелировать?
- Объединение множества специализированных таблиц в одну таблицу объектов с целевыми признаками
- Чистка данных
- Библиотека визуализации данных Seaborn
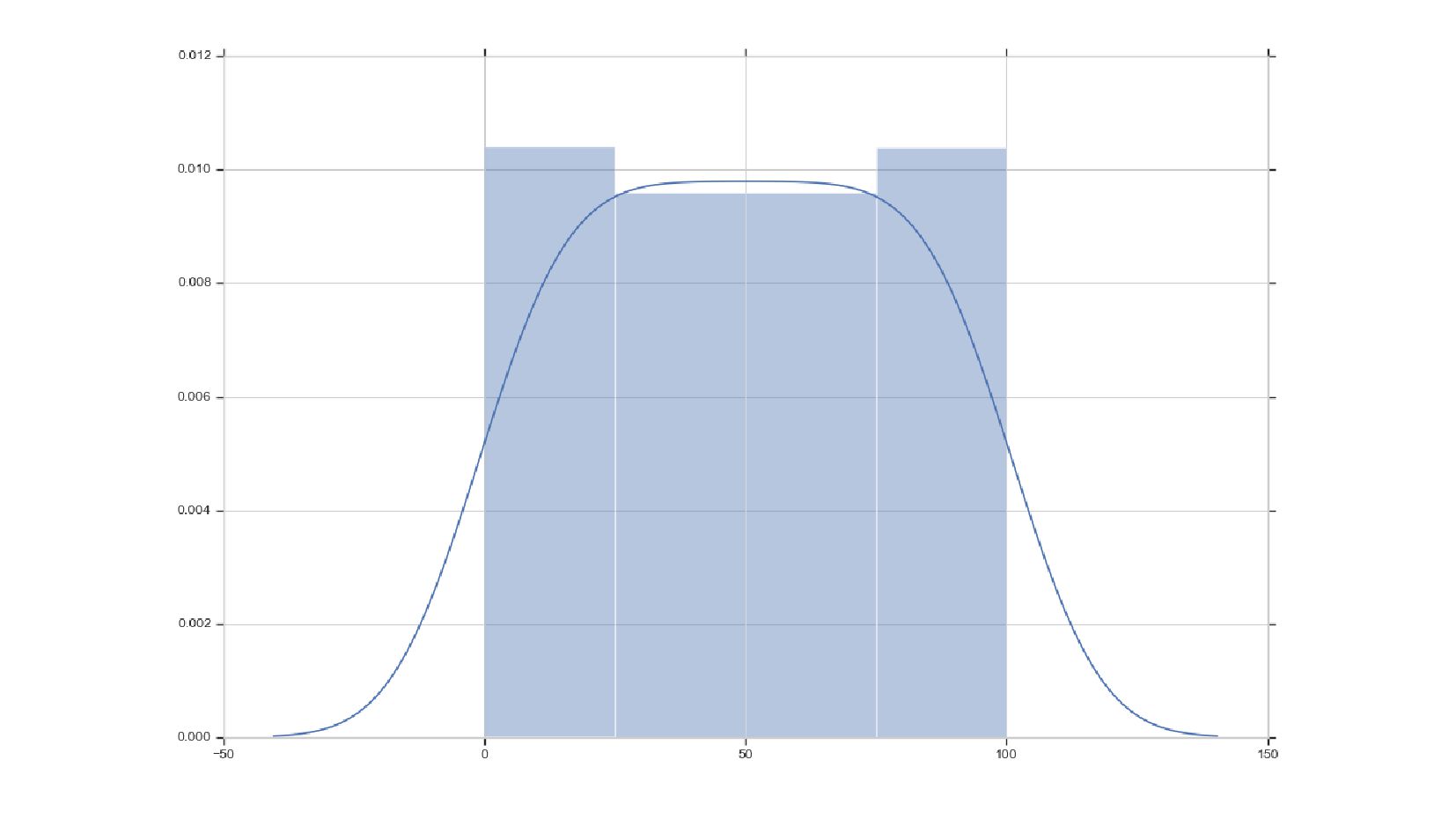
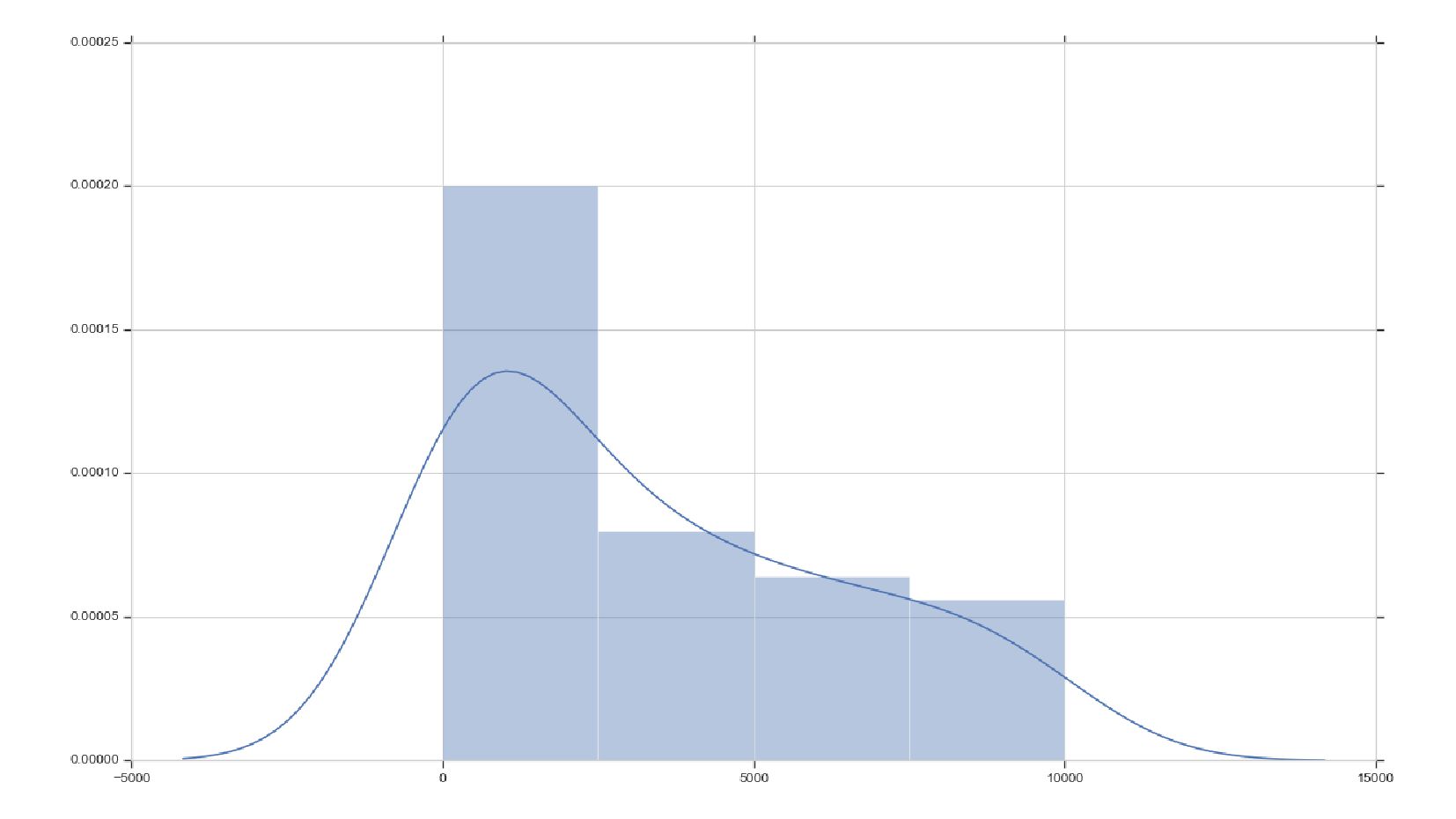
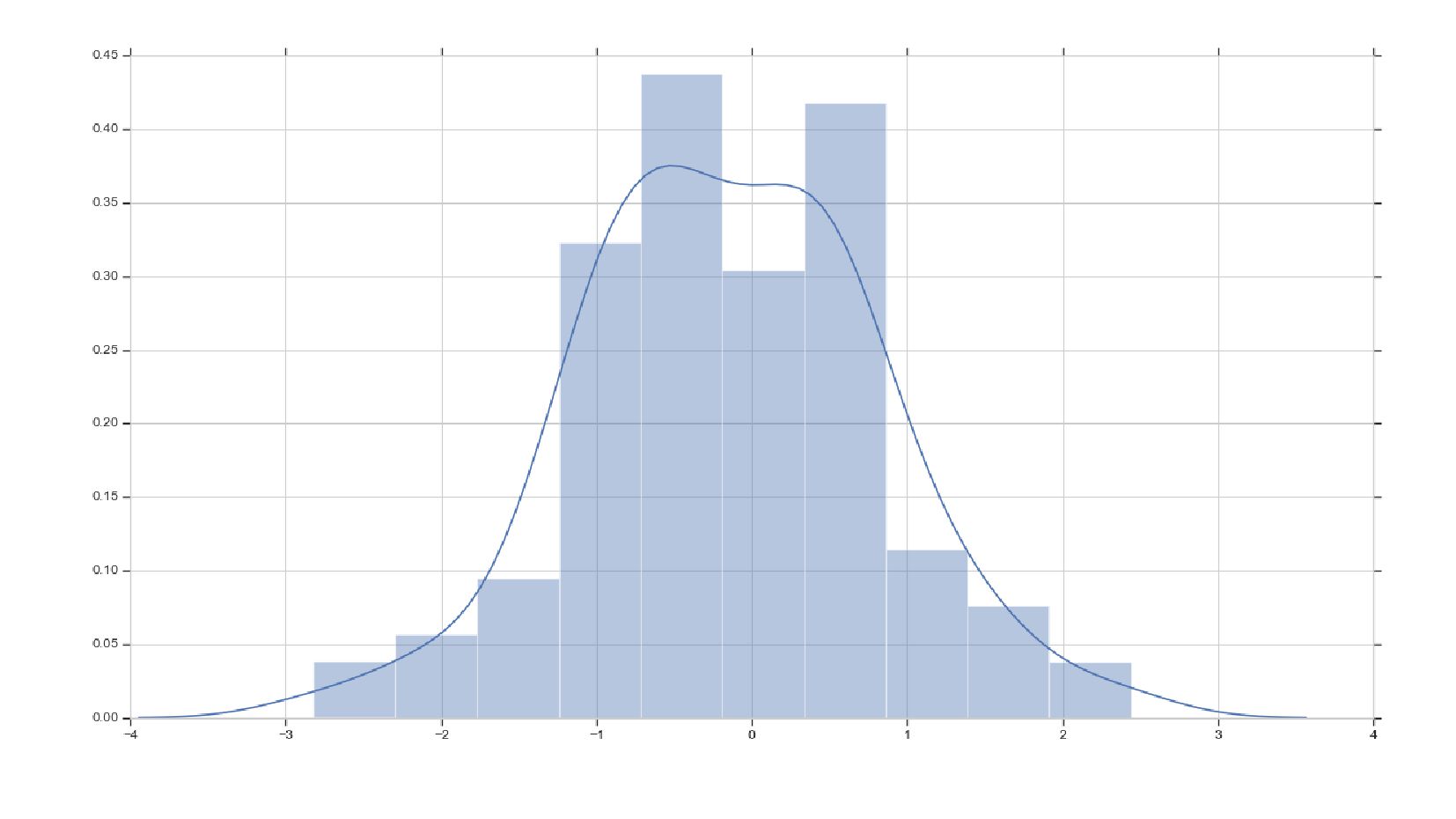
- График распределения значений признака: Distplot
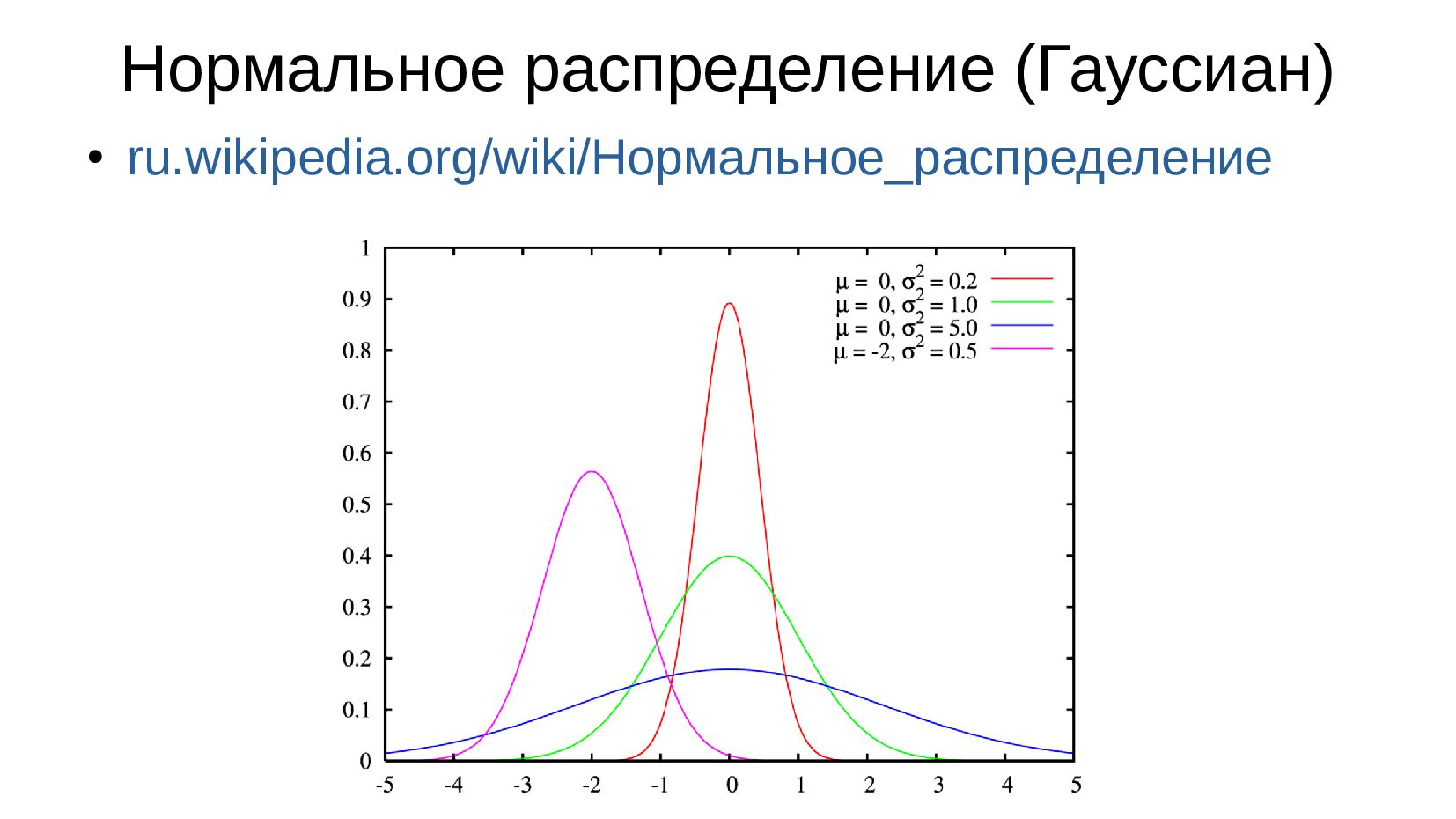
- Нормальное распределение
- Точечный график — отношения между двумя величинами: Relplot
- Групповой график распределений и попарных отношений: Pairplot
- Проблема пропуска данных в датасете ILO
- Корреляция
- Коэффициент корреляци; и Пирсона
- Вычисление корреляции последовательностей значений: Pandas:Series.corr
- Матрица корреляций: numpy.corrcoef
- Матрица корреляций: Pandas:DataFrame.corr
- Тепловая карта корреляций: Heatmap
- Палитра для heatmap:cmap
- Высокая корреляция != причинно-следственная связь
- Задания для самостоятельной работы
лекция с данными ILO: 22.04.2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
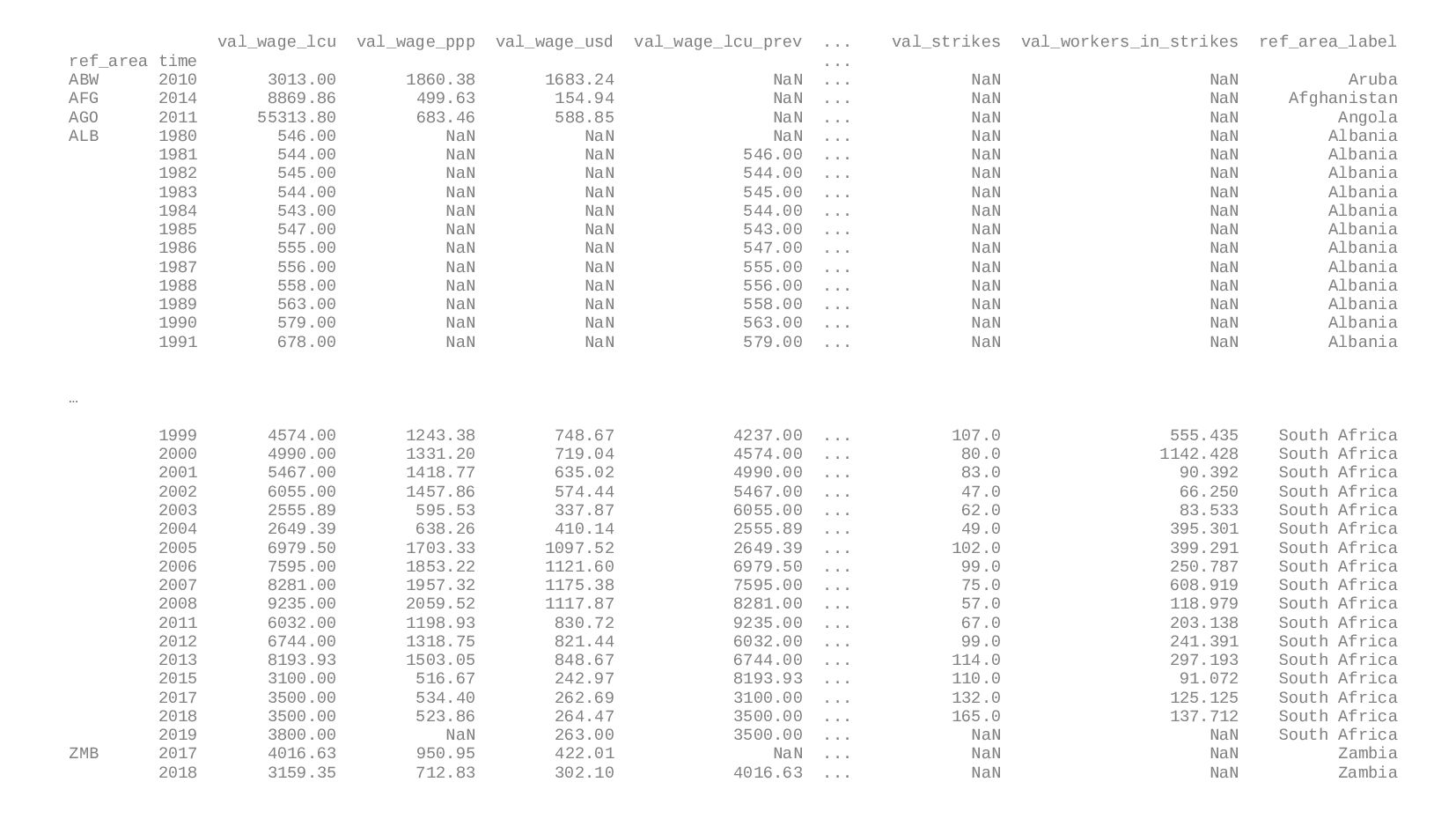
![data_wage['val_wage_lcu_prev'] = data_wage.sort_index(ascending=True).groupby( by=['ref_area']) ['val_wage_lcu'].shift() data_wage['val_wage_change_lcu'] = data_wage['val_wage_lcu'] / data_wage['val_wage_lcu_prev']](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_16.jpg){kind=link}
![data_cpi = pandas.read_csv('CPI_NCYR_COI_RT_A.csv') data_cpi = data_cpi[ data_cpi.classif1 == 'COI_COICOP_CP01T12' ]](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Избавиться от NaN'ов data = data[ ~np.isnan(data.val_wage_usd) ] data =](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
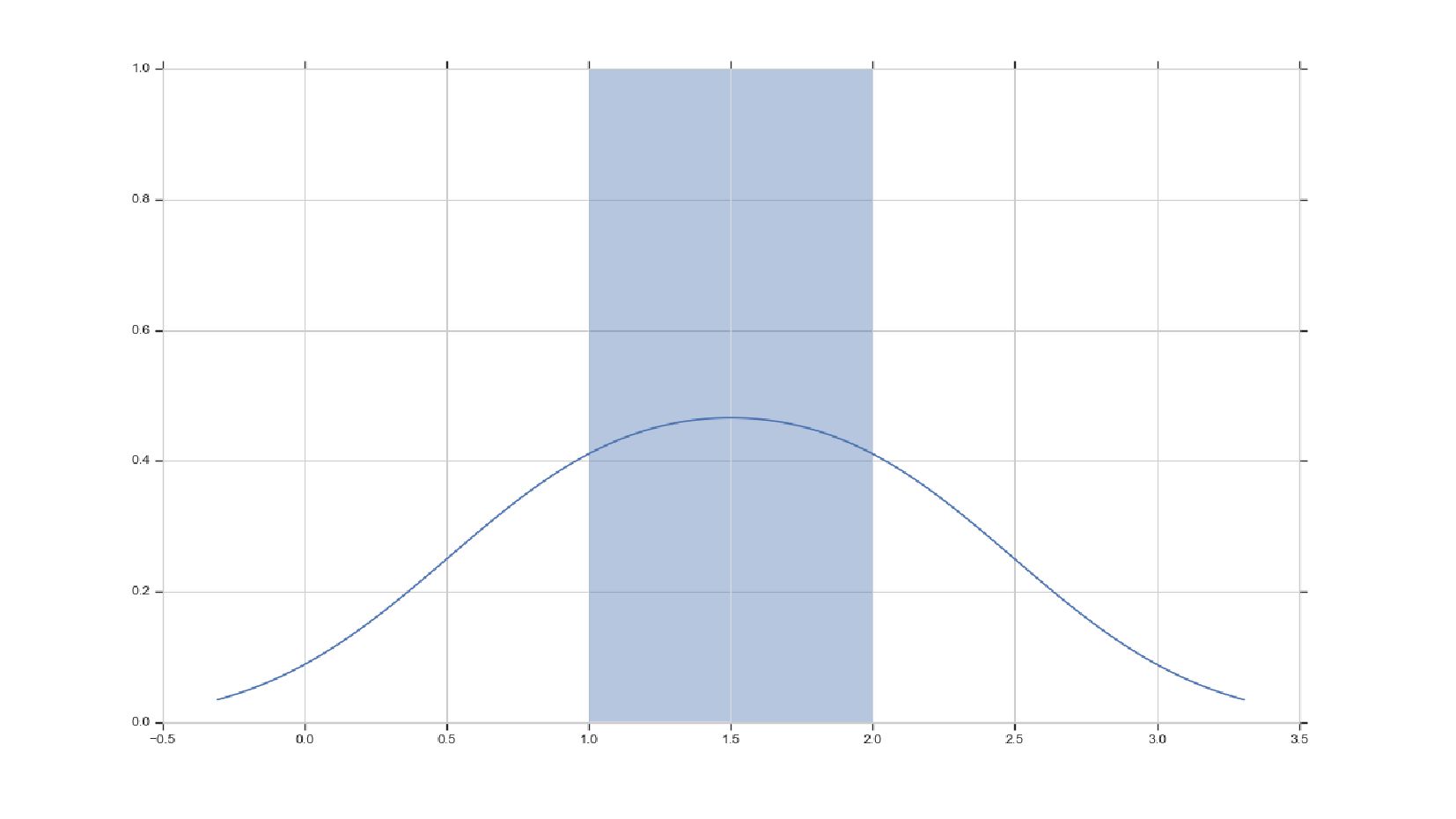
![distplot-demo.py # здесь обе строки покажут один результат sns.distplot(np.array([1,2])) sns.distplot(np.array([1,1,2,2]))](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_29.jpg){kind=link}
{kind=link}
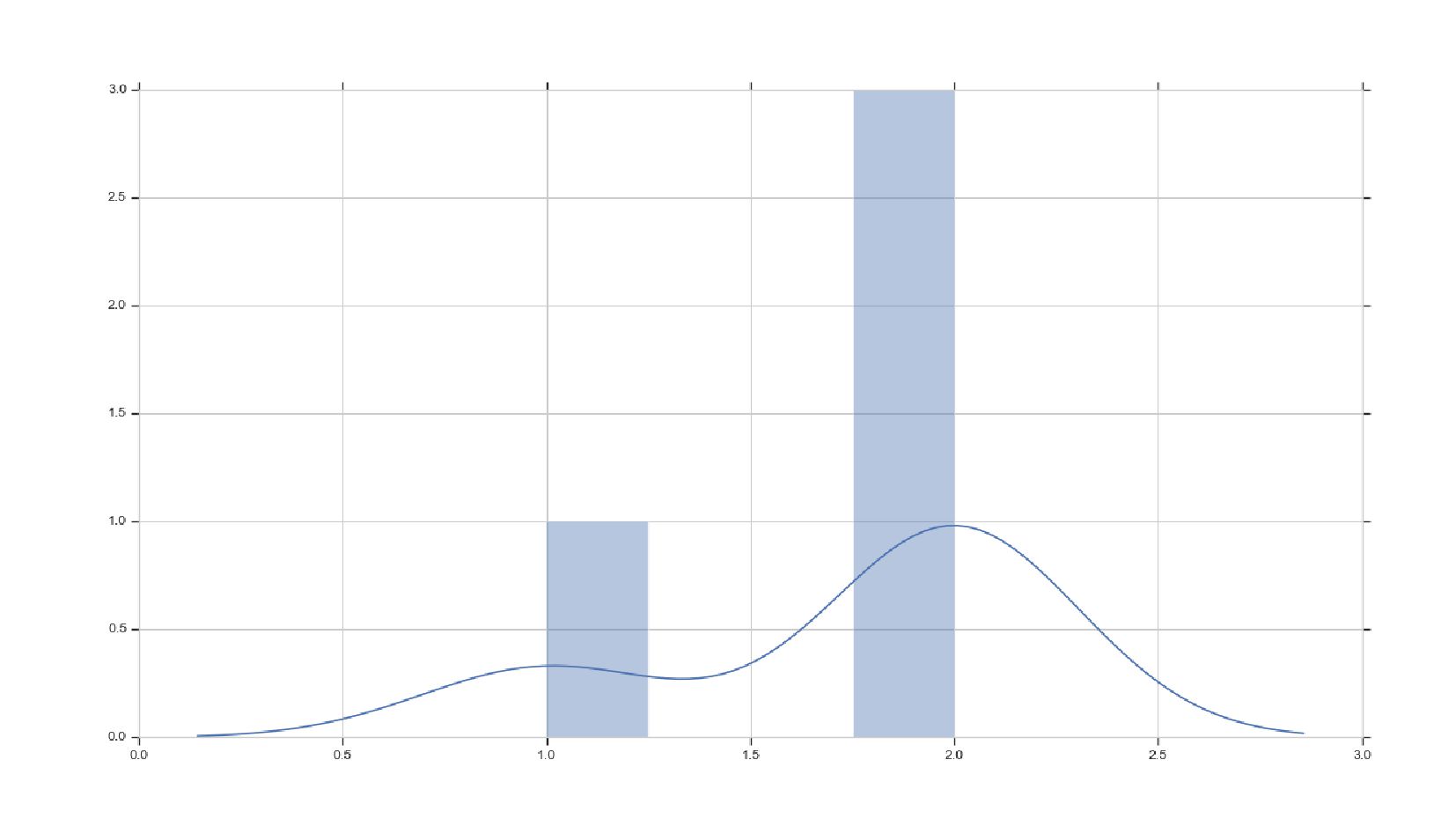
![distplot-demo.py sns.distplot(np.array([1,1,2,2,2,2,2,2]))](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
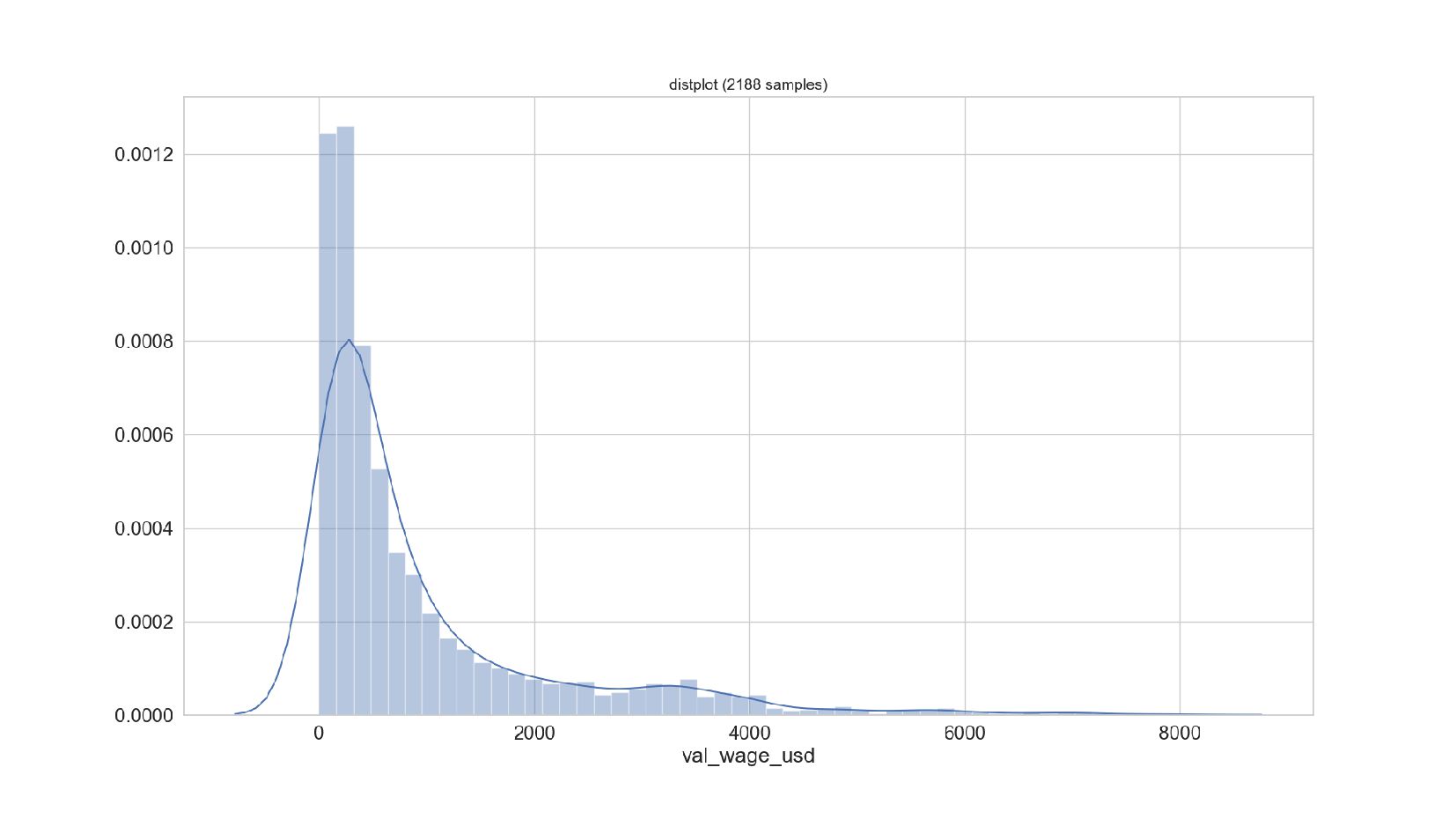{kind=link}
{kind=link}
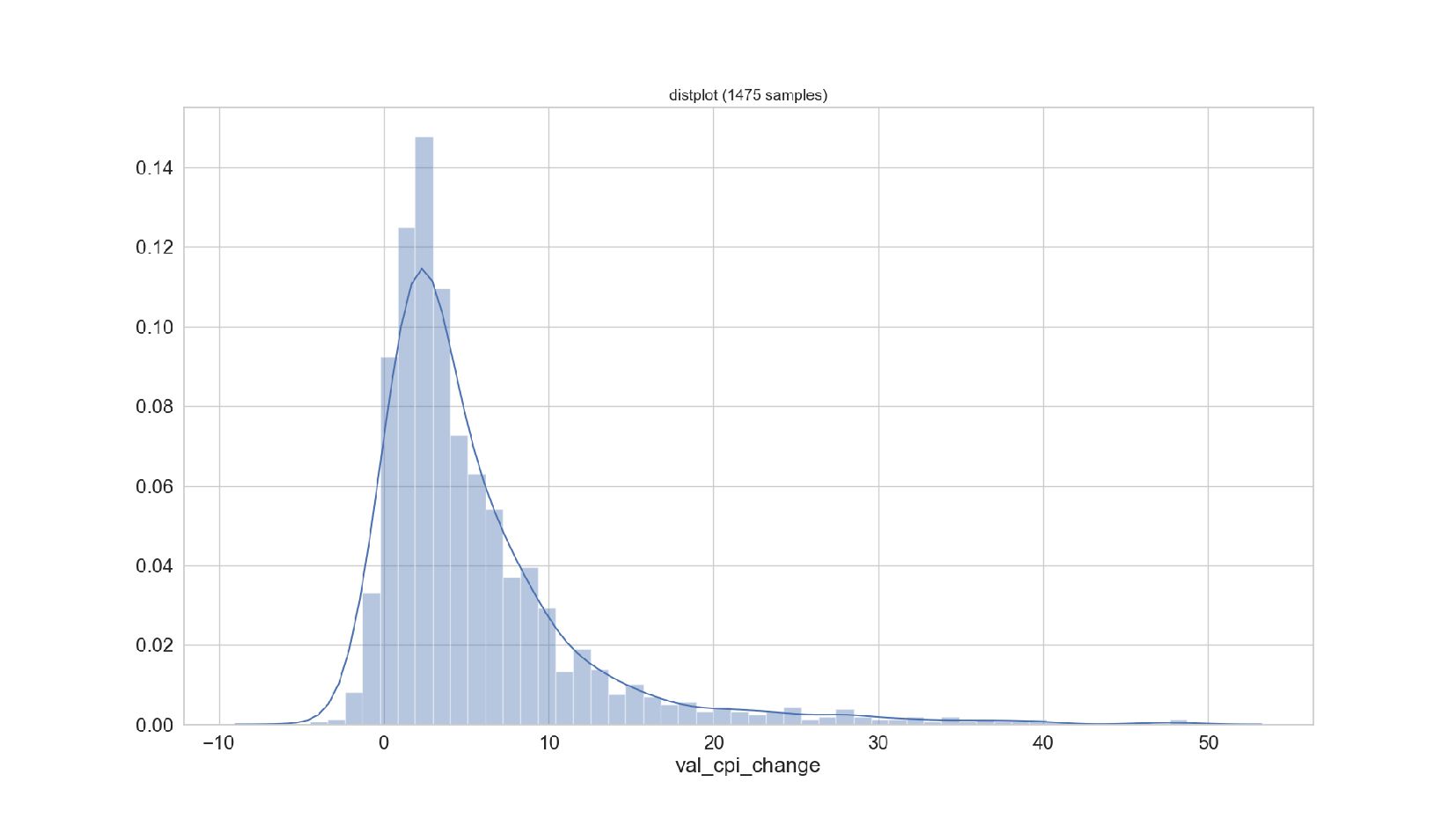{kind=link}
{kind=link}
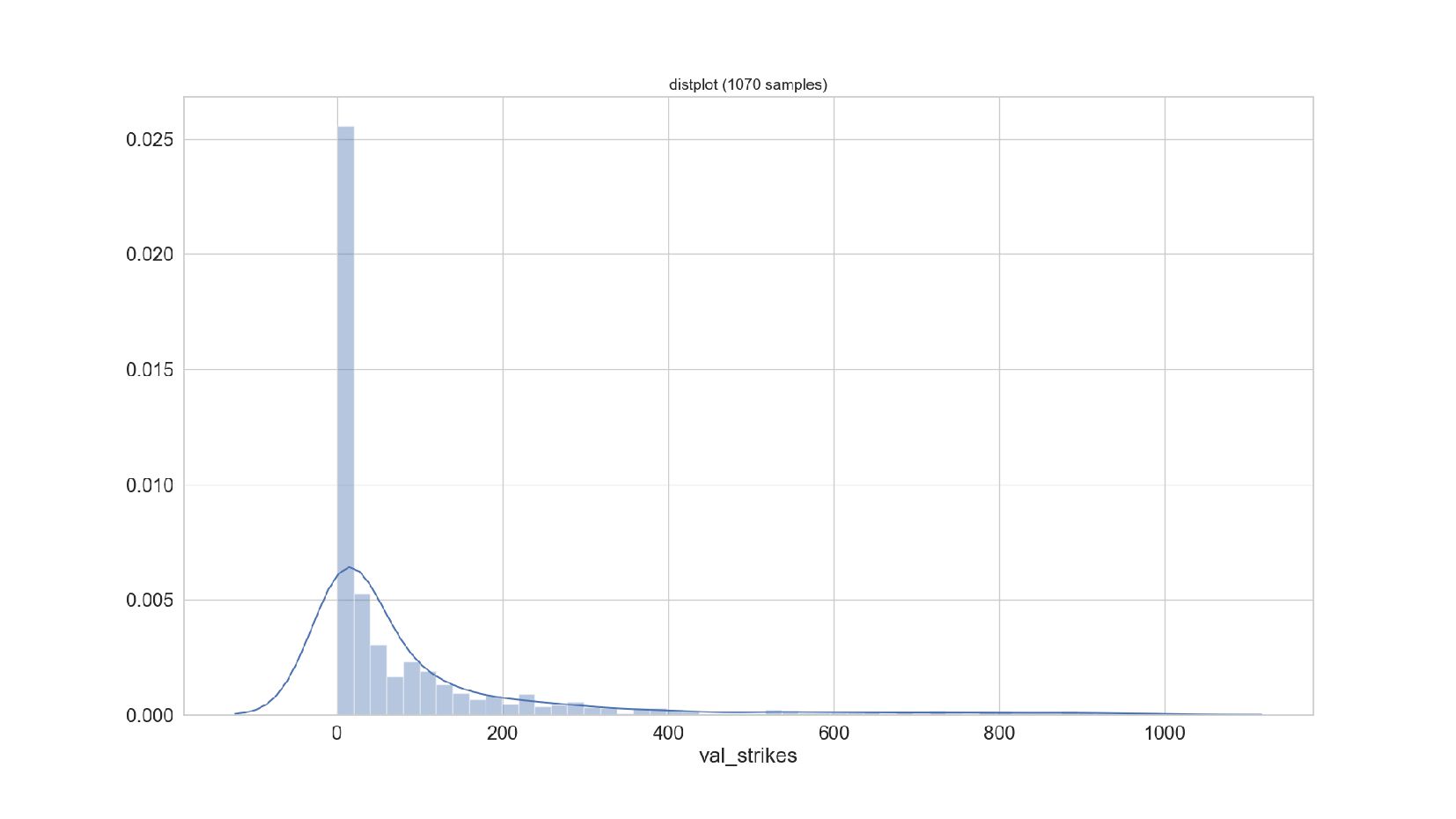{kind=link}
{kind=link}
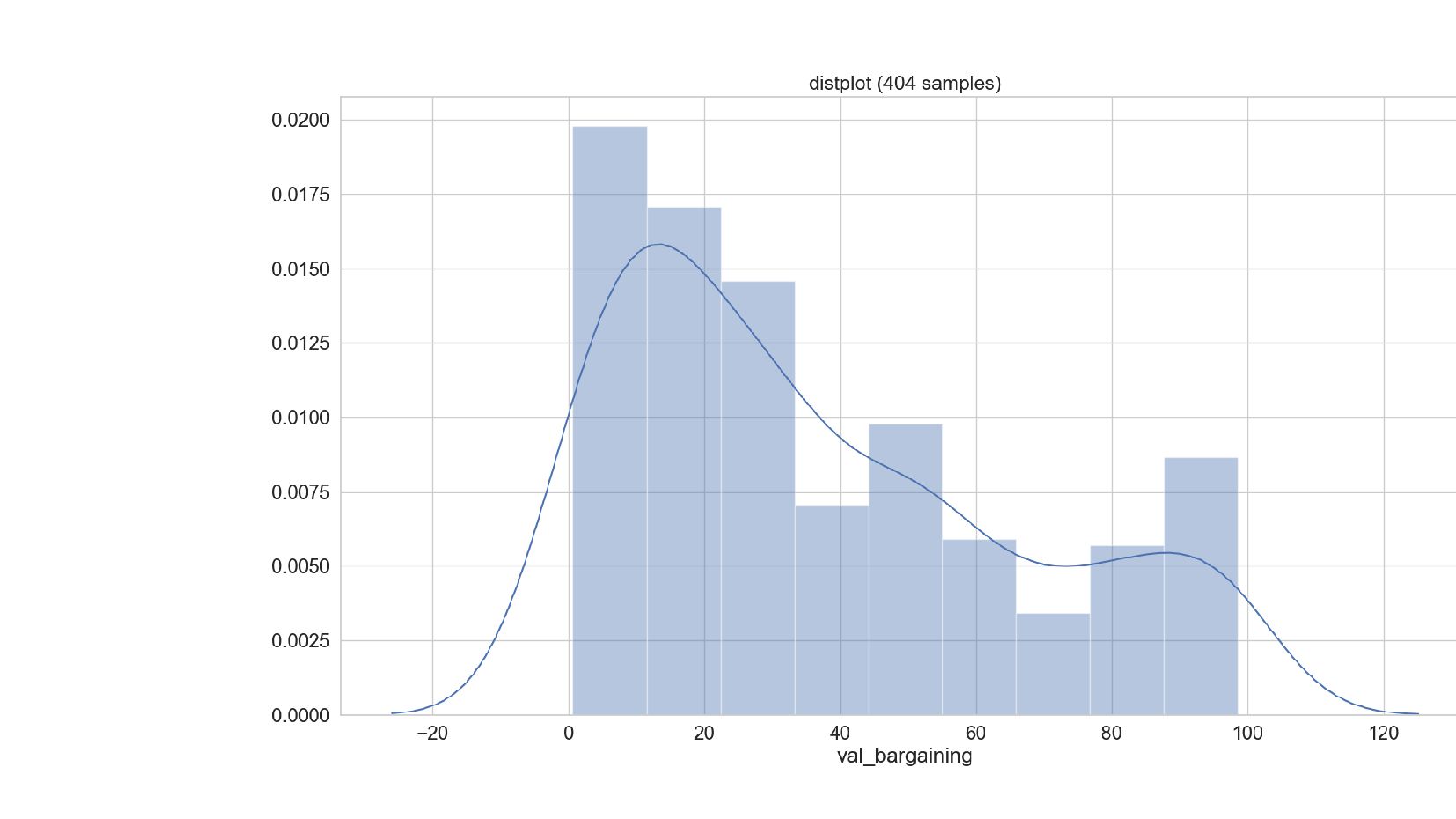{kind=link}
{kind=link}
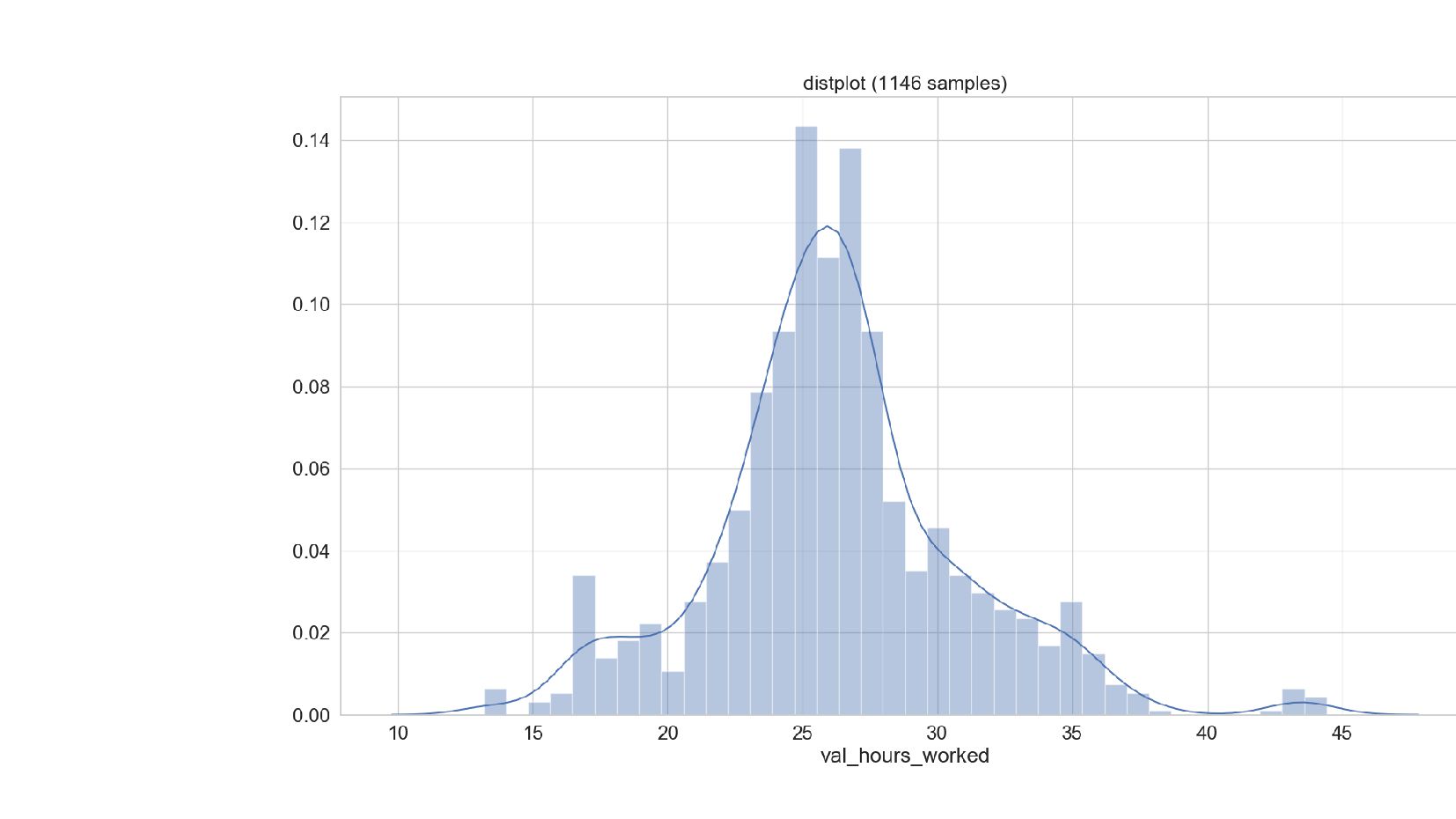{kind=link}
{kind=link}
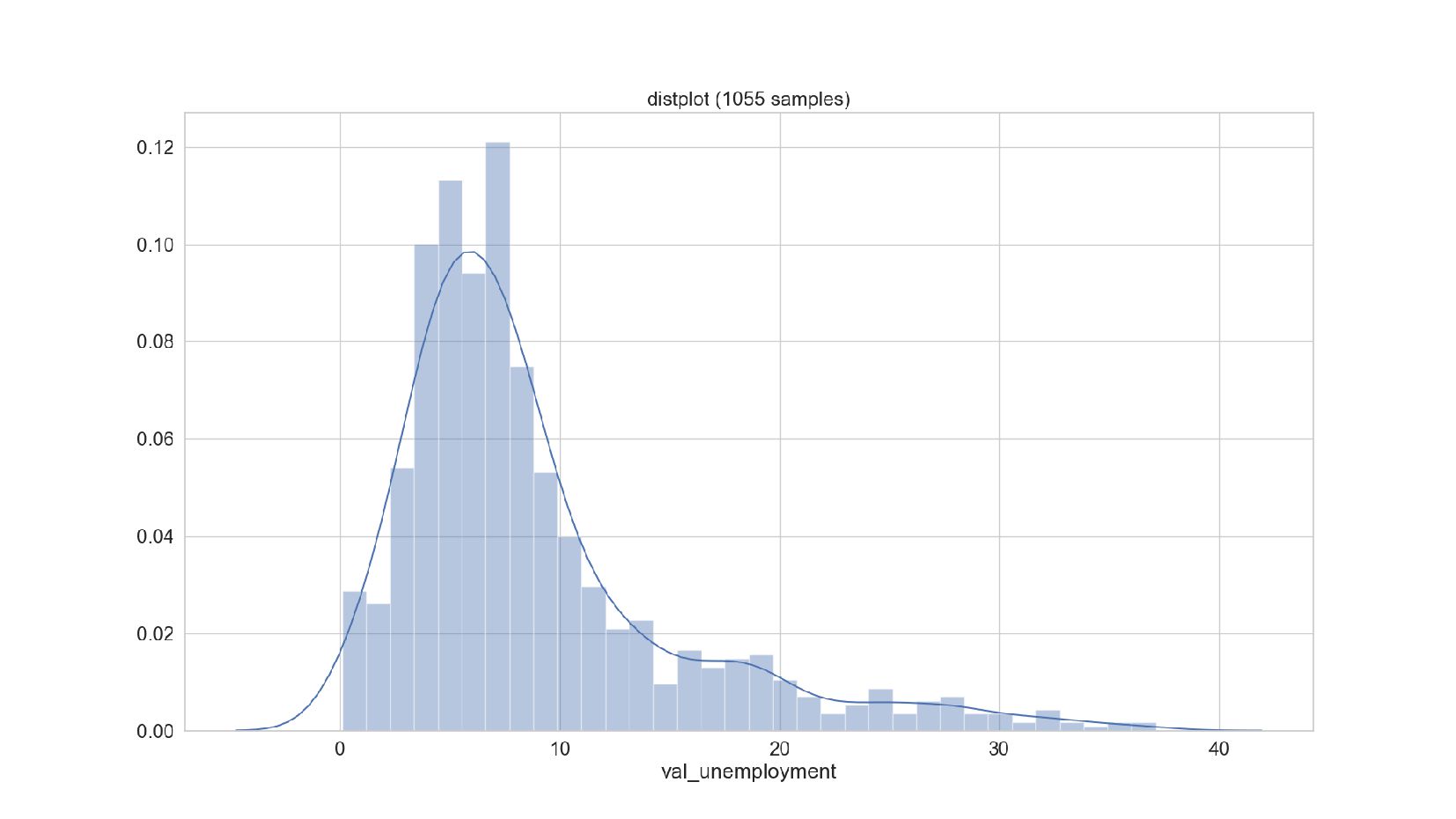{kind=link}
{kind=link}
{kind=link}
![relplot-demo.py df = pd.DataFrame(data={ 'X': [1,2,3], 'Y': np.array([1,2,3])**2 }) sns.relplot(x='X',](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_57.jpg){kind=link}
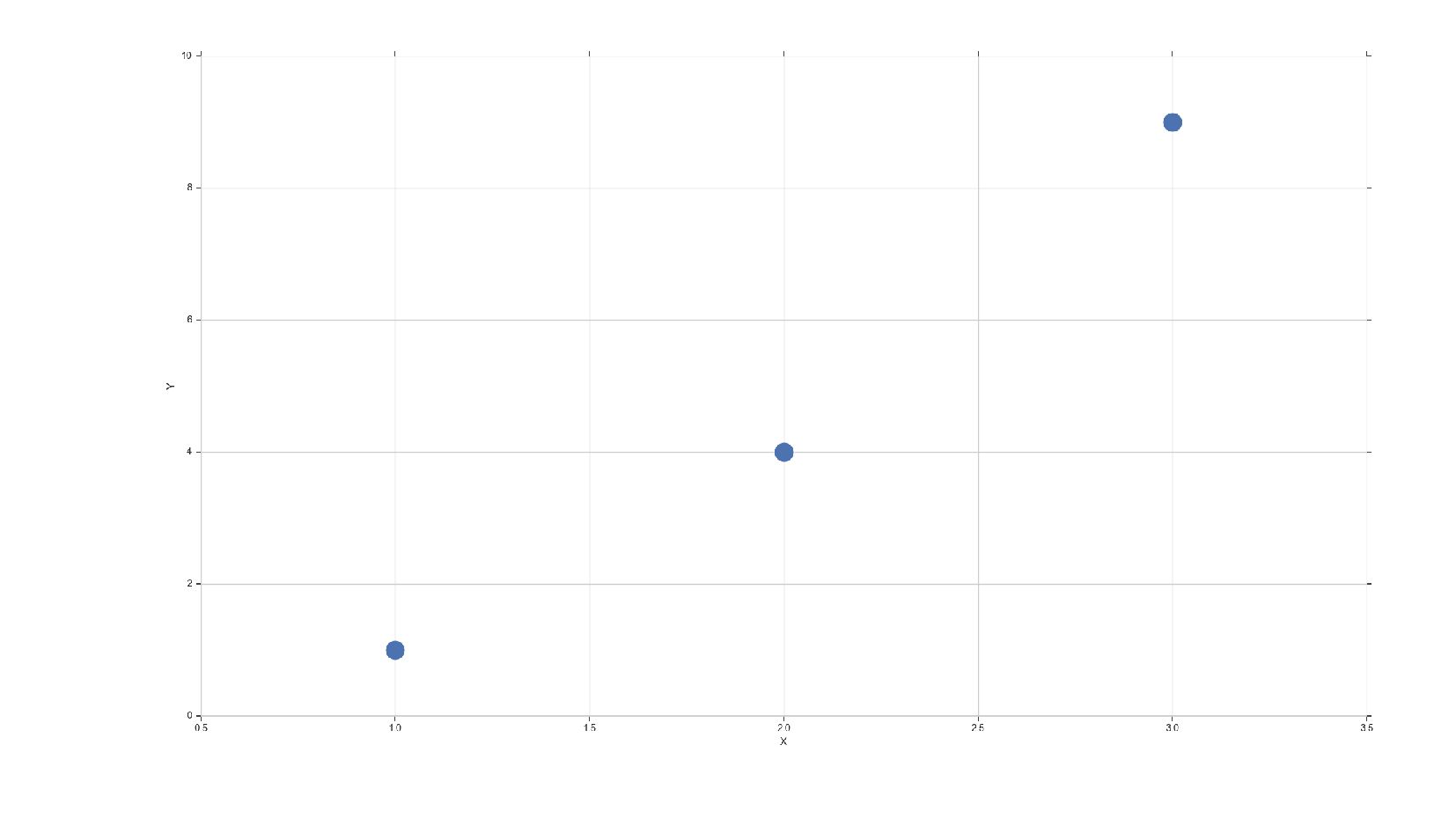{kind=link}
{kind=link}
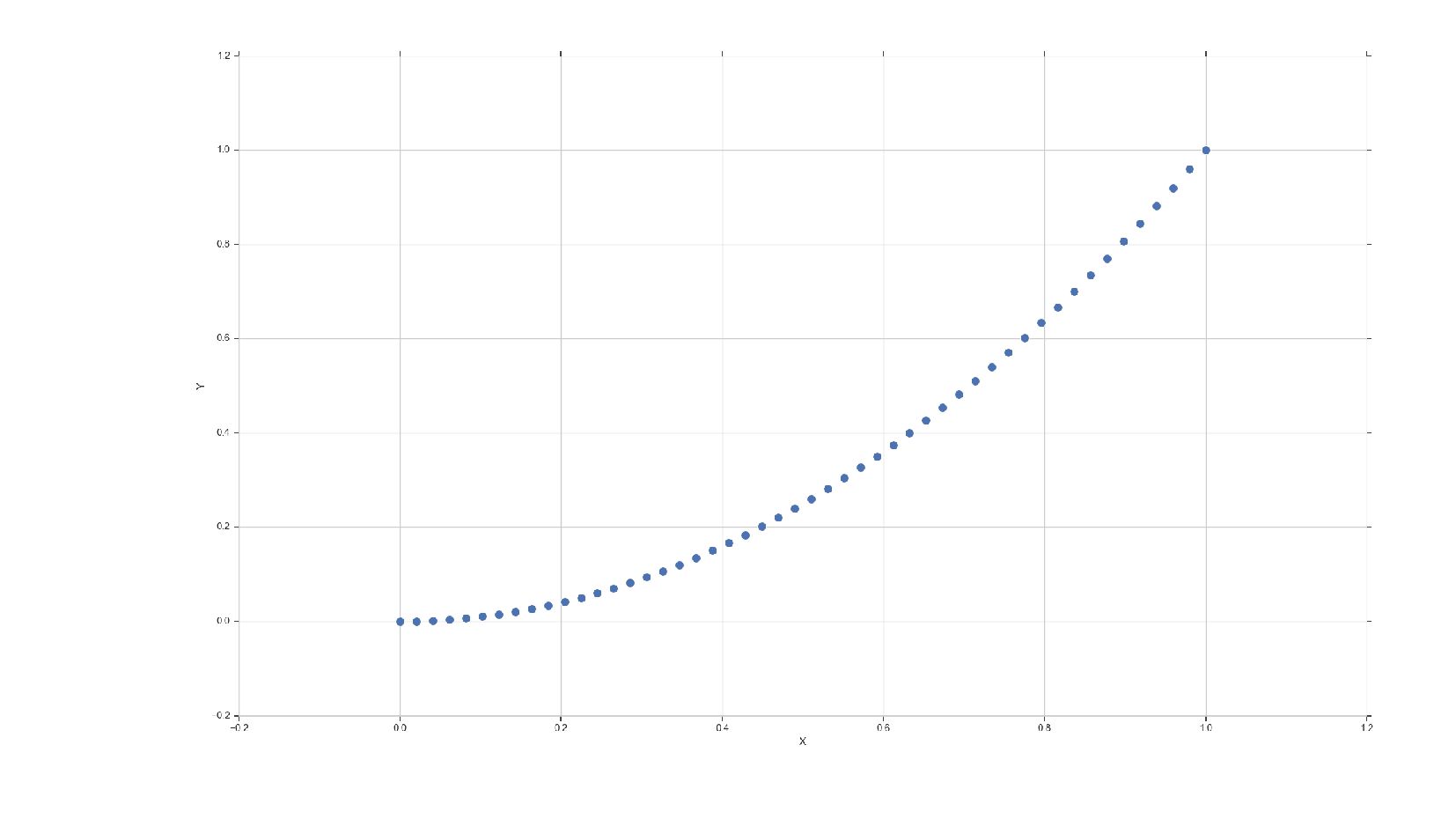{kind=link}
{kind=link}
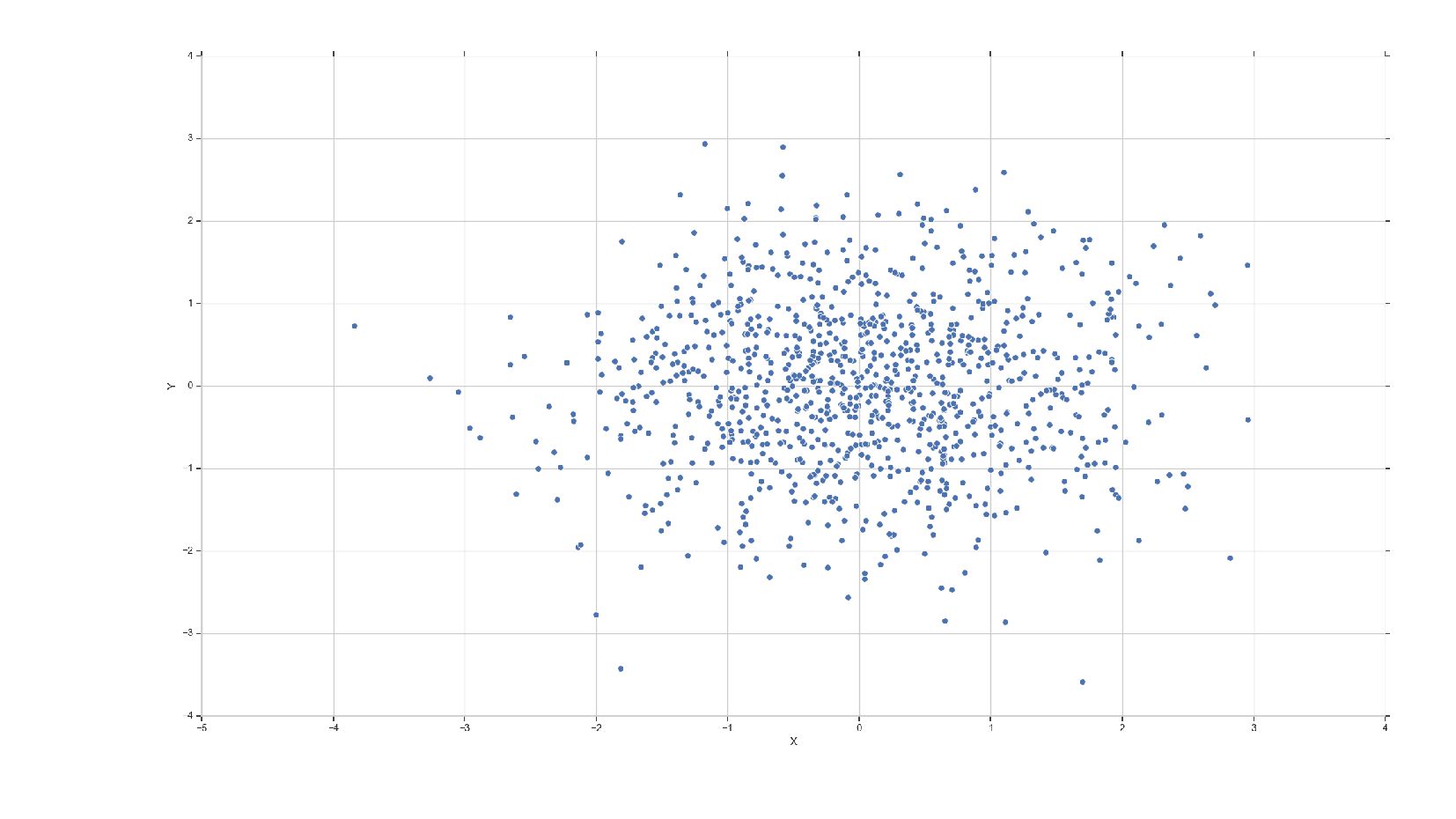{kind=link}
{kind=link}
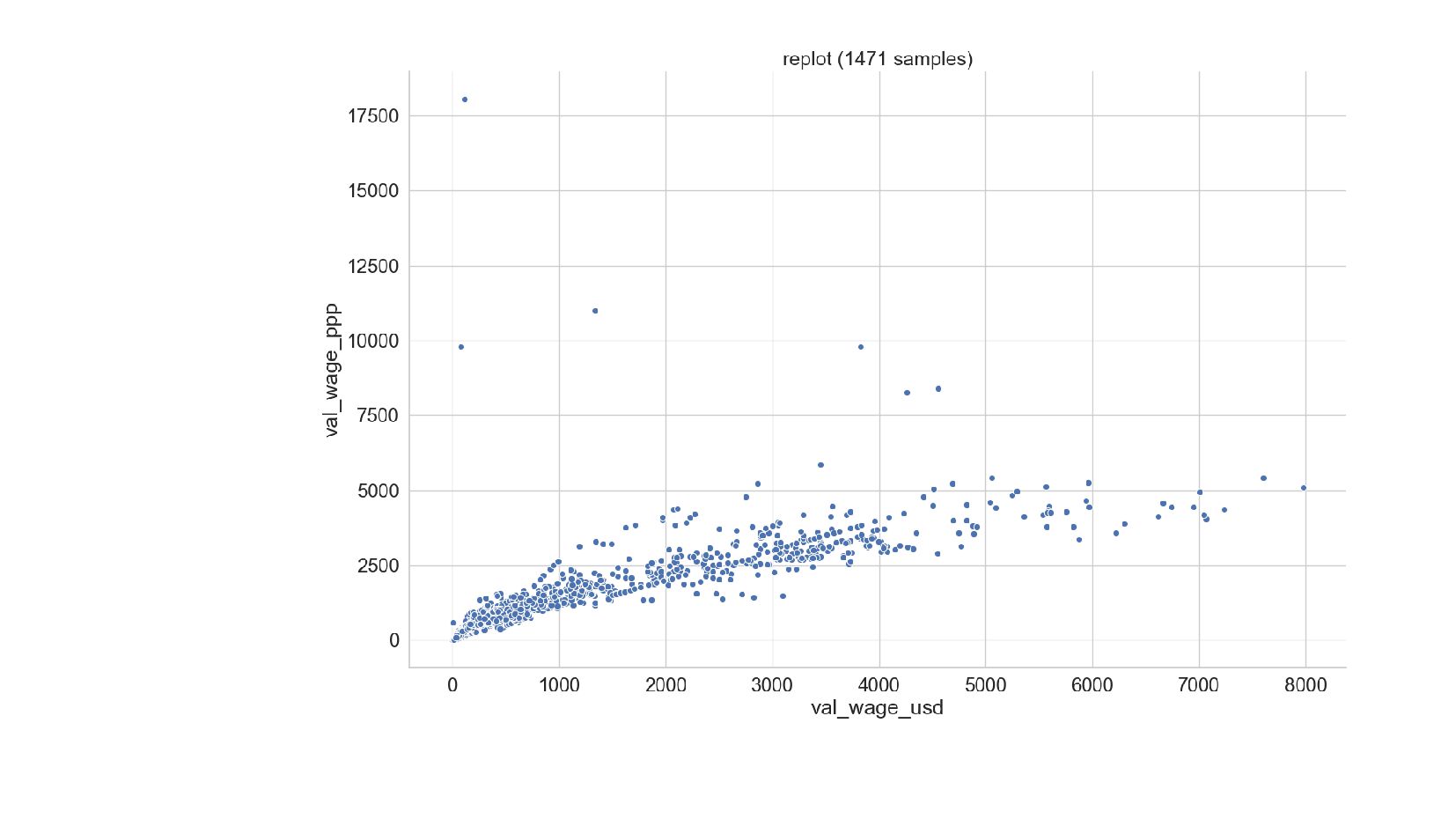{kind=link}
{kind=link}
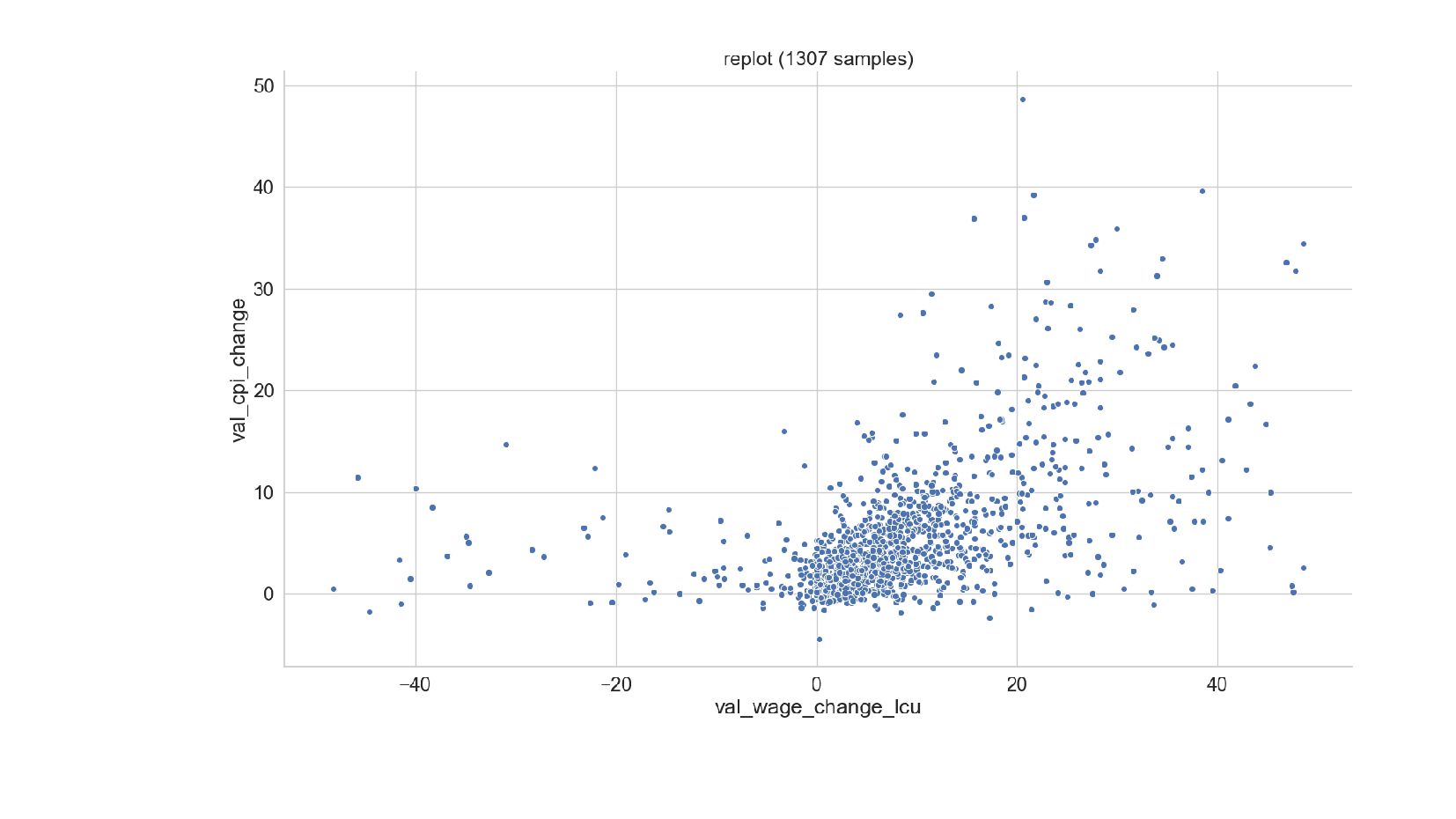{kind=link}
{kind=link}
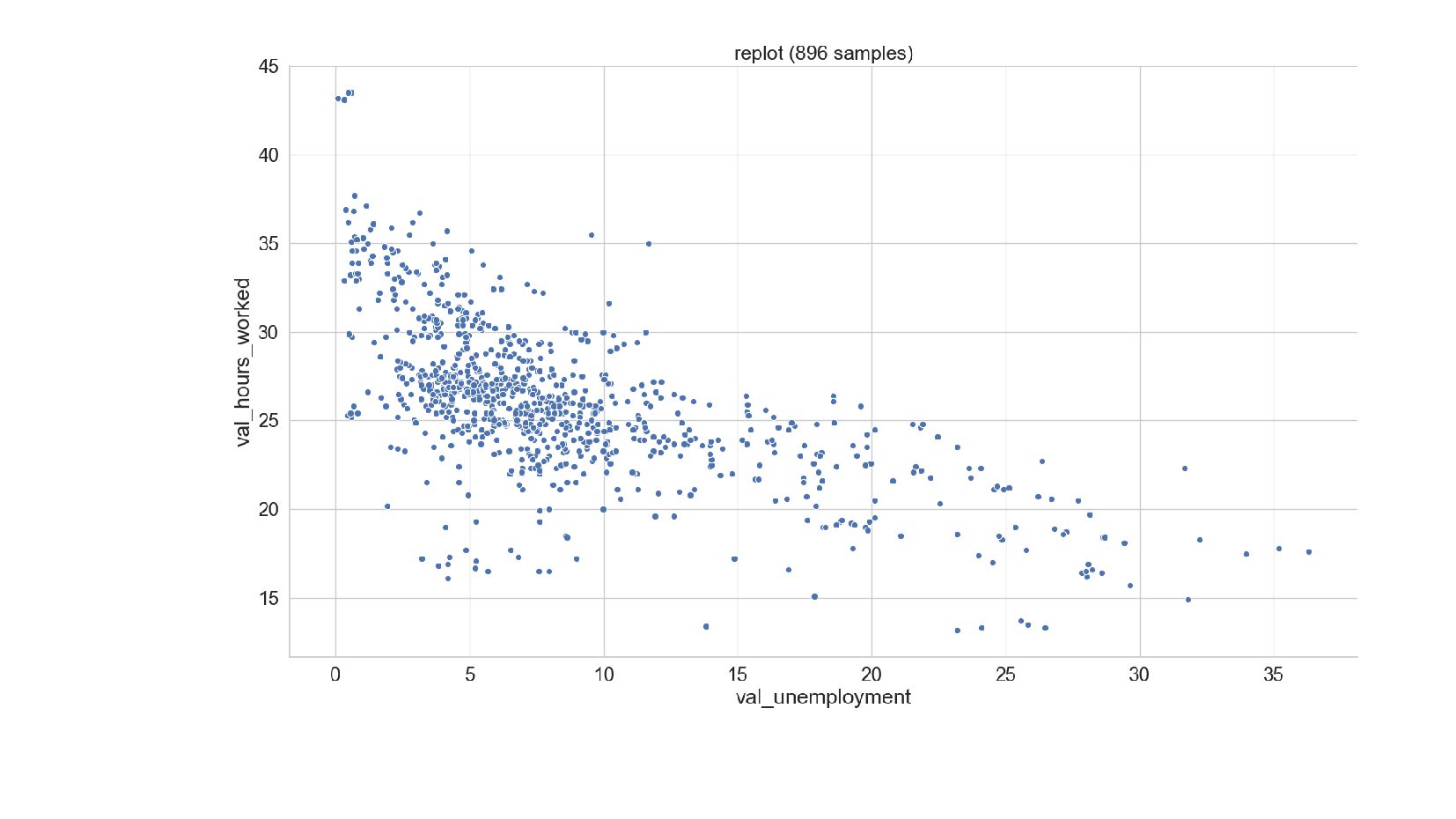{kind=link}
{kind=link}
![explore-ilo.py sns.pairplot(data[[ 'val_wage_usd', 'val_wage_ppp', 'val_cpi_change', 'val_wage_change_lcu' ]]).fig.suptitle( "ILO pairplot (%d](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_70.jpg){kind=link}
{kind=link}
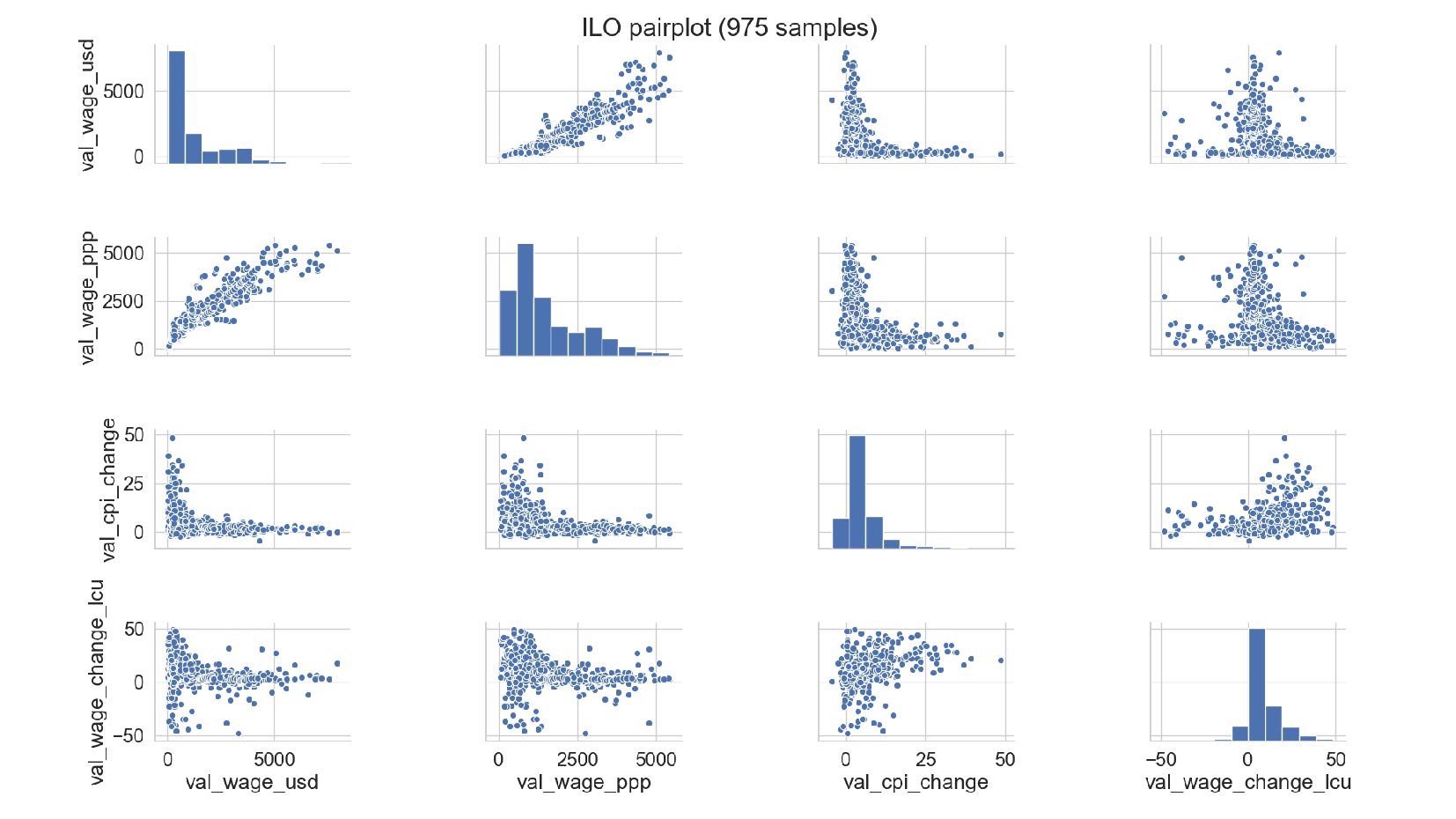{kind=link}
{kind=link}
![explore-ilo.py sns.pairplot(data[[ 'val_bargaining', 'val_union_density', 'val_unemployment', 'val_wage_usd', 'val_cpi_change', 'val_hours_worked' ]]).fig.suptitle( "ILO](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_74.jpg){kind=link}
{kind=link}
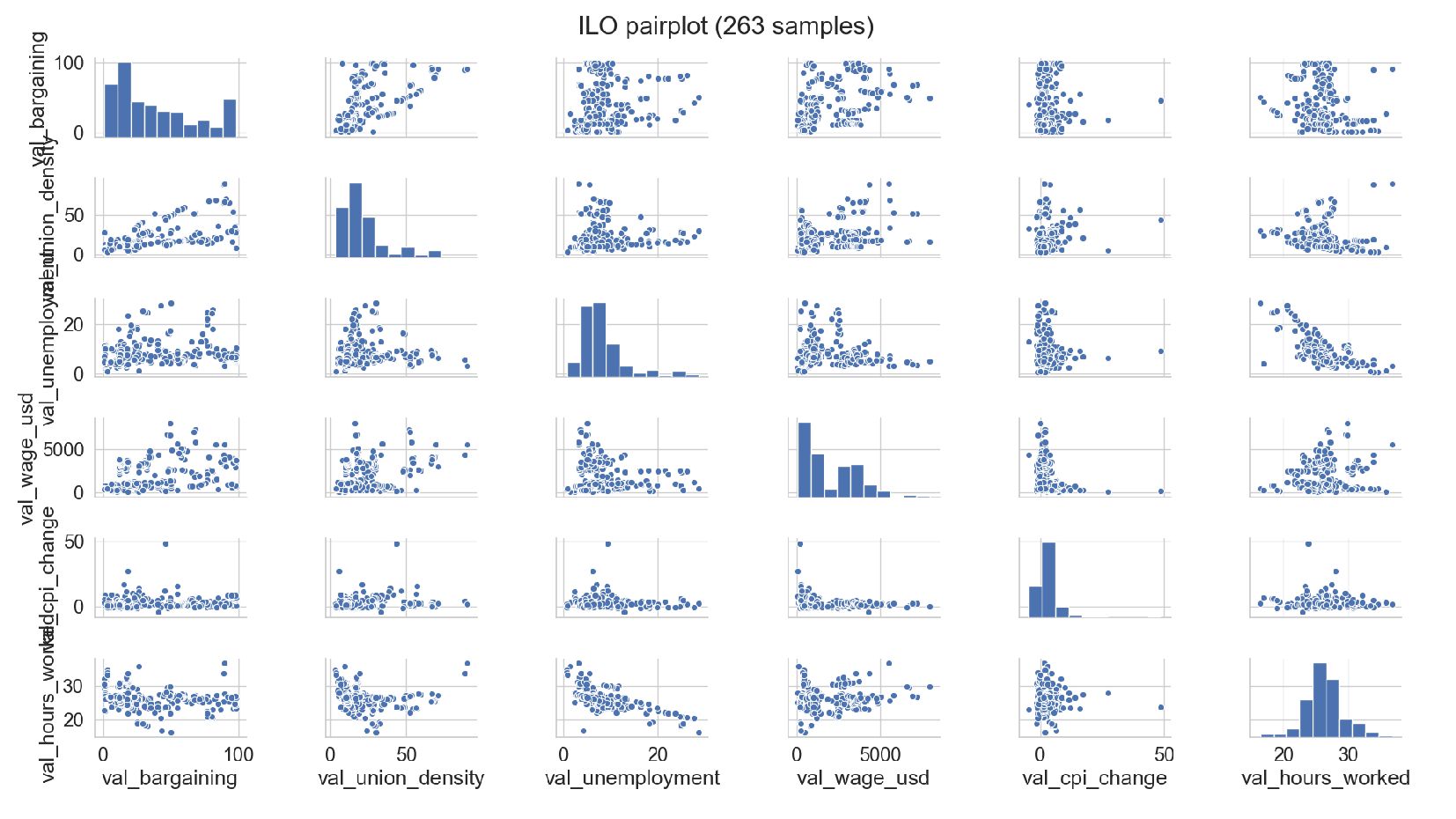{kind=link}
{kind=link}
{kind=link}
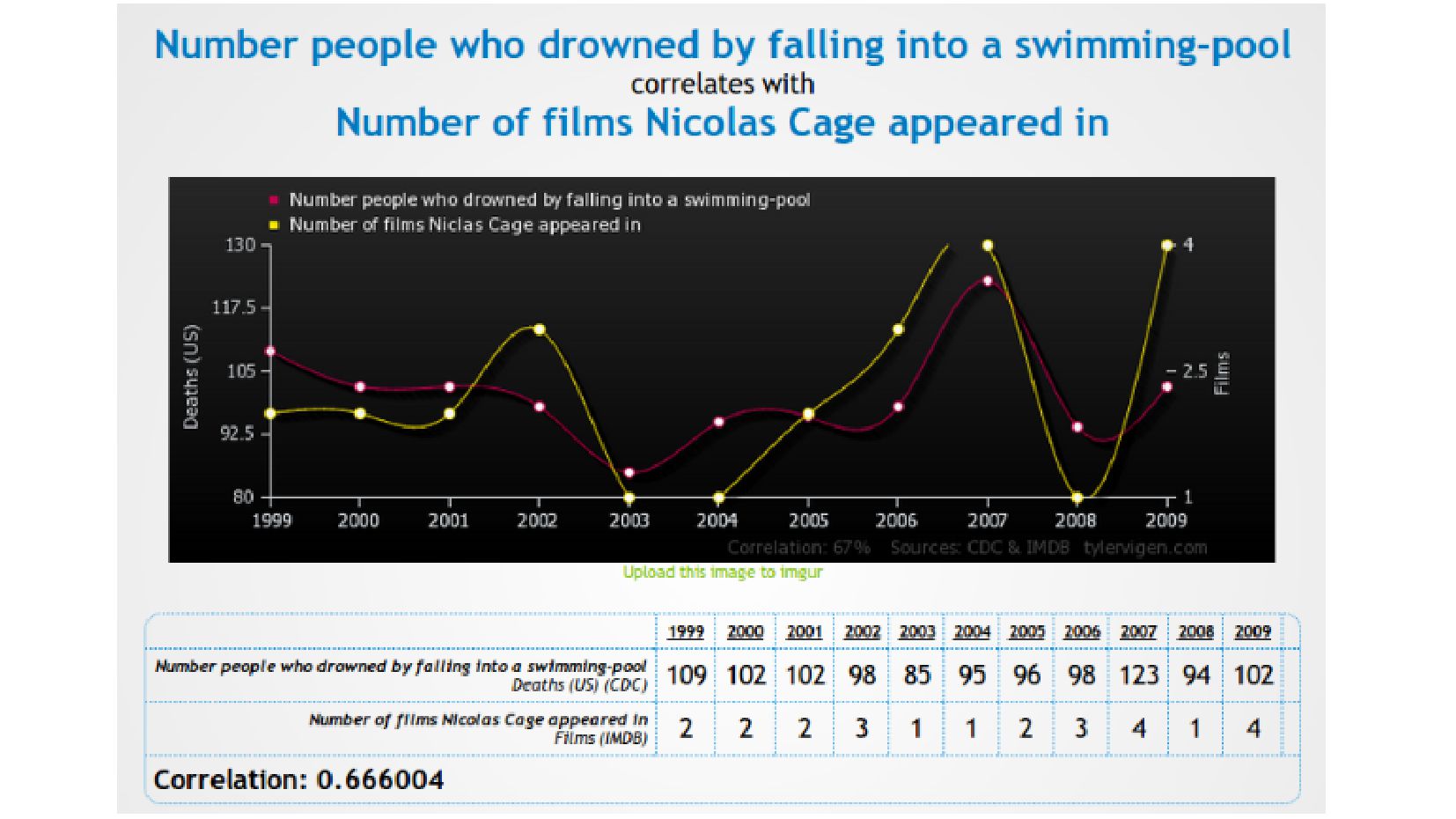{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Пример 1 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_87.jpg){kind=link}
{kind=link}
![Пример 2 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_89.jpg){kind=link}
![Пример 3 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_90.jpg){kind=link}
![Пример 4 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_91.jpg){kind=link}
![Пример 5 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_92.jpg){kind=link}
{kind=link}
![Pandas: Series.corr print( pandas.Series([1]).corr( pandas.Series([2]), 'pearson') ) print( pandas.Series([1, 1]).corr(](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_94.jpg){kind=link}
{kind=link}
{kind=link}
![Матрица корреляций: numpy.corrcoef # возьмем правое верхнее значение: print(np.corrcoef([[1,2,3], [1,2,3]])[0][1])](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_97.jpg){kind=link}
![Матрица корреляций: numpy.corrcoef # матрица 3x3 print(np.corrcoef([[1,2,3], [1,8,27], [11,19,0]])) [[](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_98.jpg){kind=link}
![Pandas: DataFrame.corr df = pd.DataFrame( data={'X': [1,2,3], 'Y': [1,8,27], 'Z':](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_99.jpg){kind=link}
{kind=link}
![explore_ilo.py cols=[ 'val_wage_usd', 'val_wage_ppp', 'val_cpi_change', 'val_wage_change_lcu' ] # .T —](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_101.jpg){kind=link}
{kind=link}
![В консольке [[ 1. 0.93715961 -0.36321207 -0.27213668] [ 0.93715961 1.](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_103.jpg){kind=link}
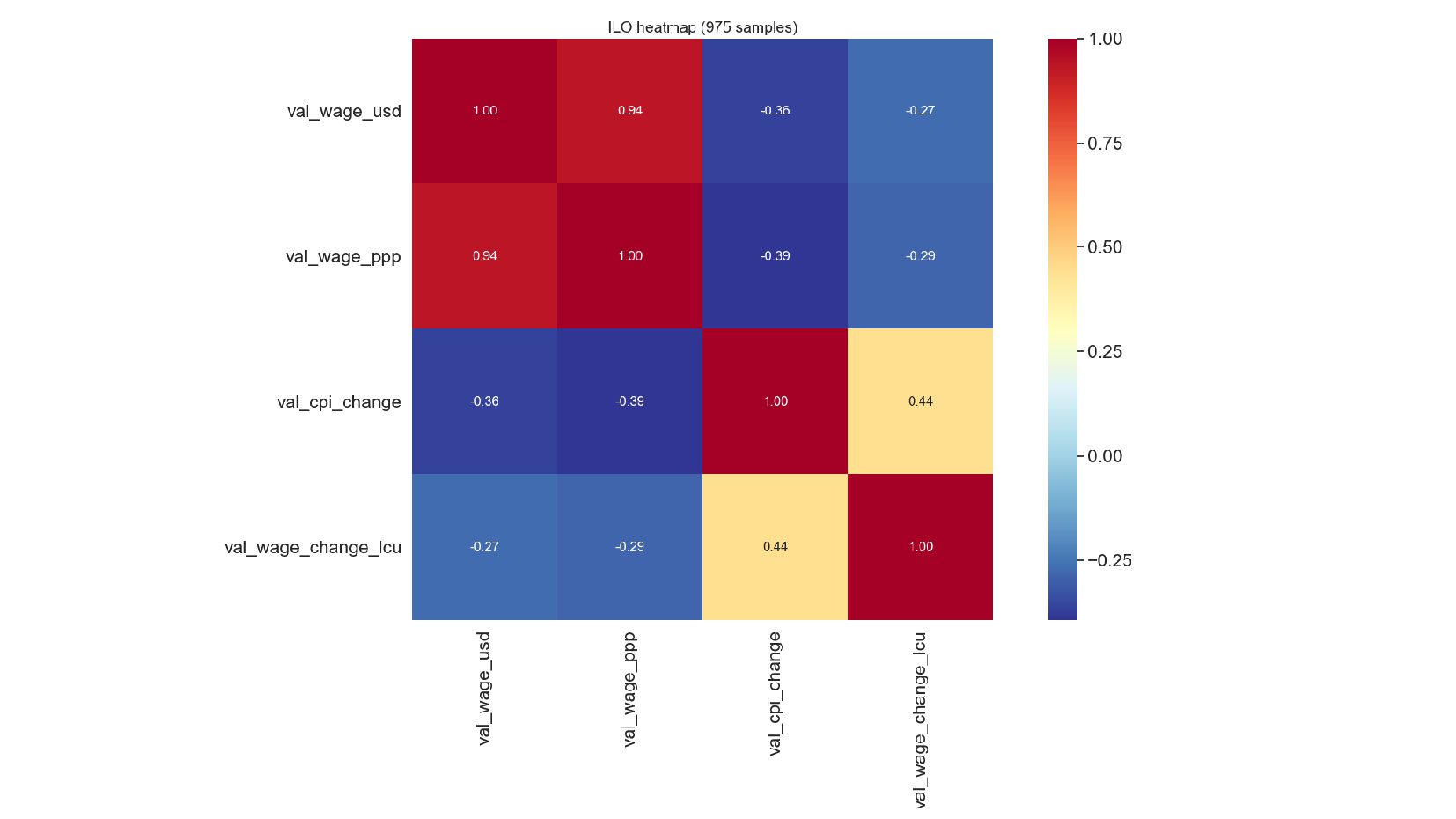{kind=link}
{kind=link}
![explore_ilo.py cols=[ 'val_bargaining', 'val_union_density', 'val_unemployment', 'val_wage_usd', 'val_cpi_change', 'val_hours_worked'] # .T](https://files.speakerdeck.com/presentations/f8eb8d39c4f54de7a8727e45fd9fbd20/slide_106.jpg){kind=link}
{kind=link}
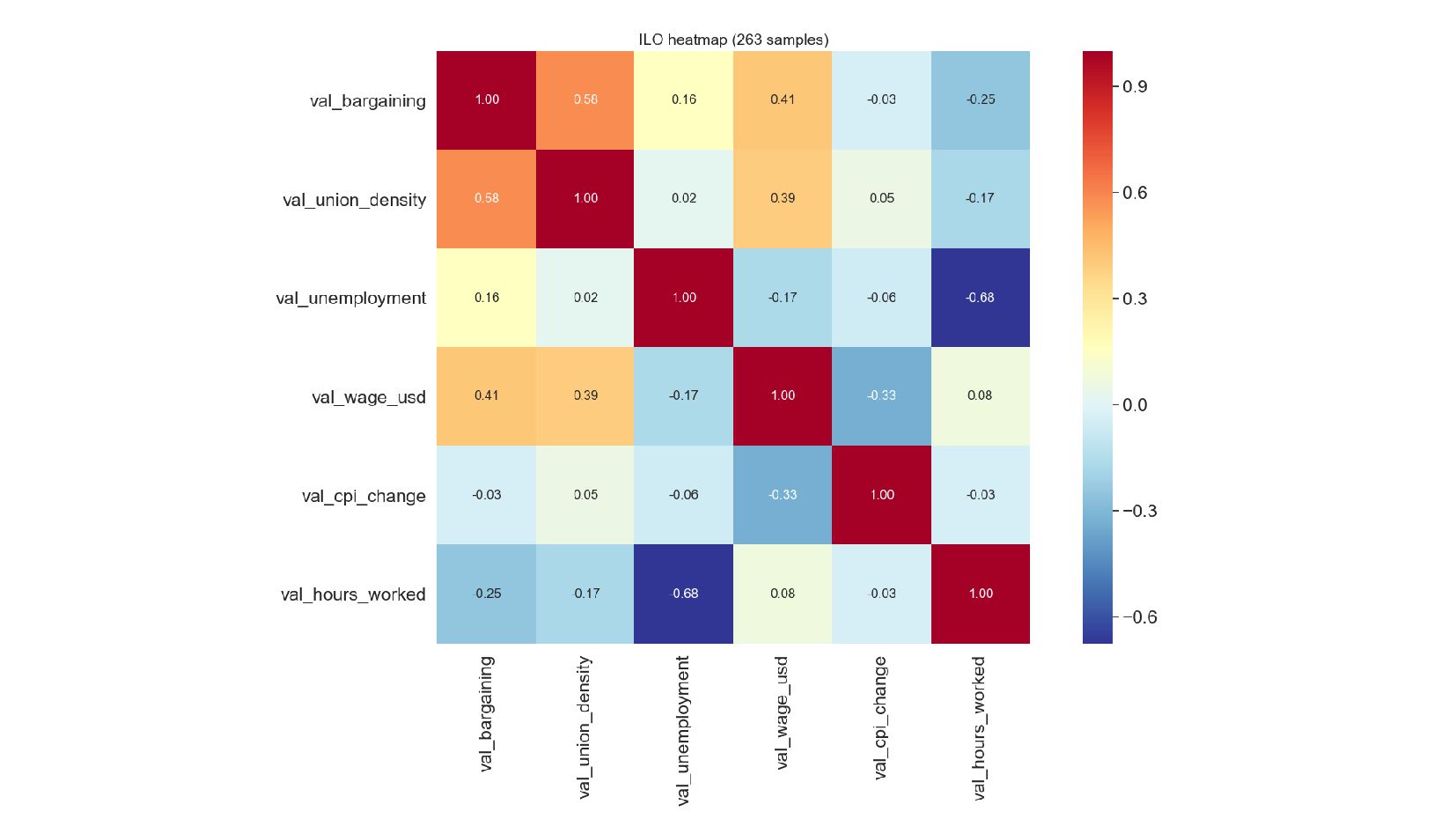{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
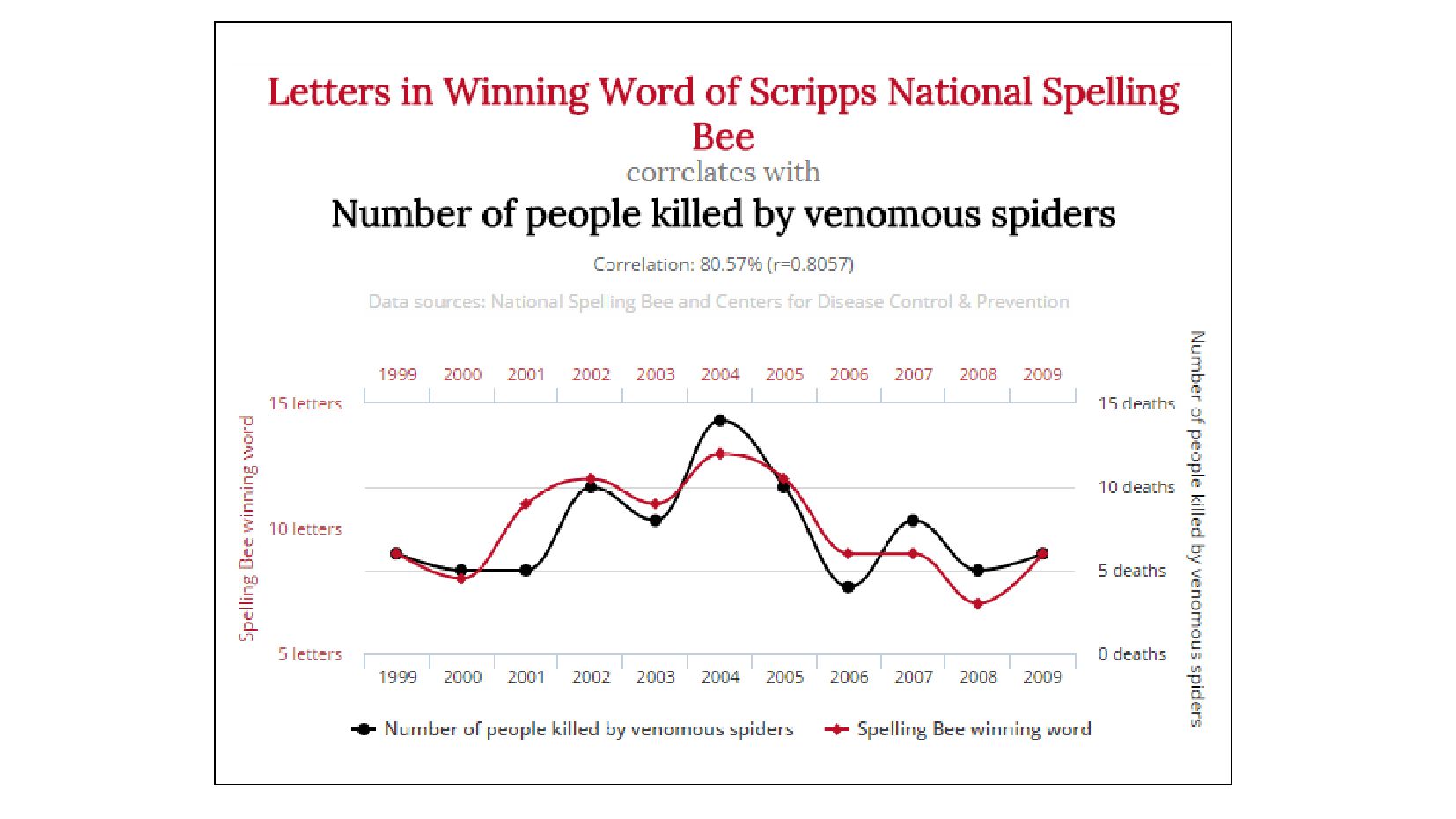{kind=link}
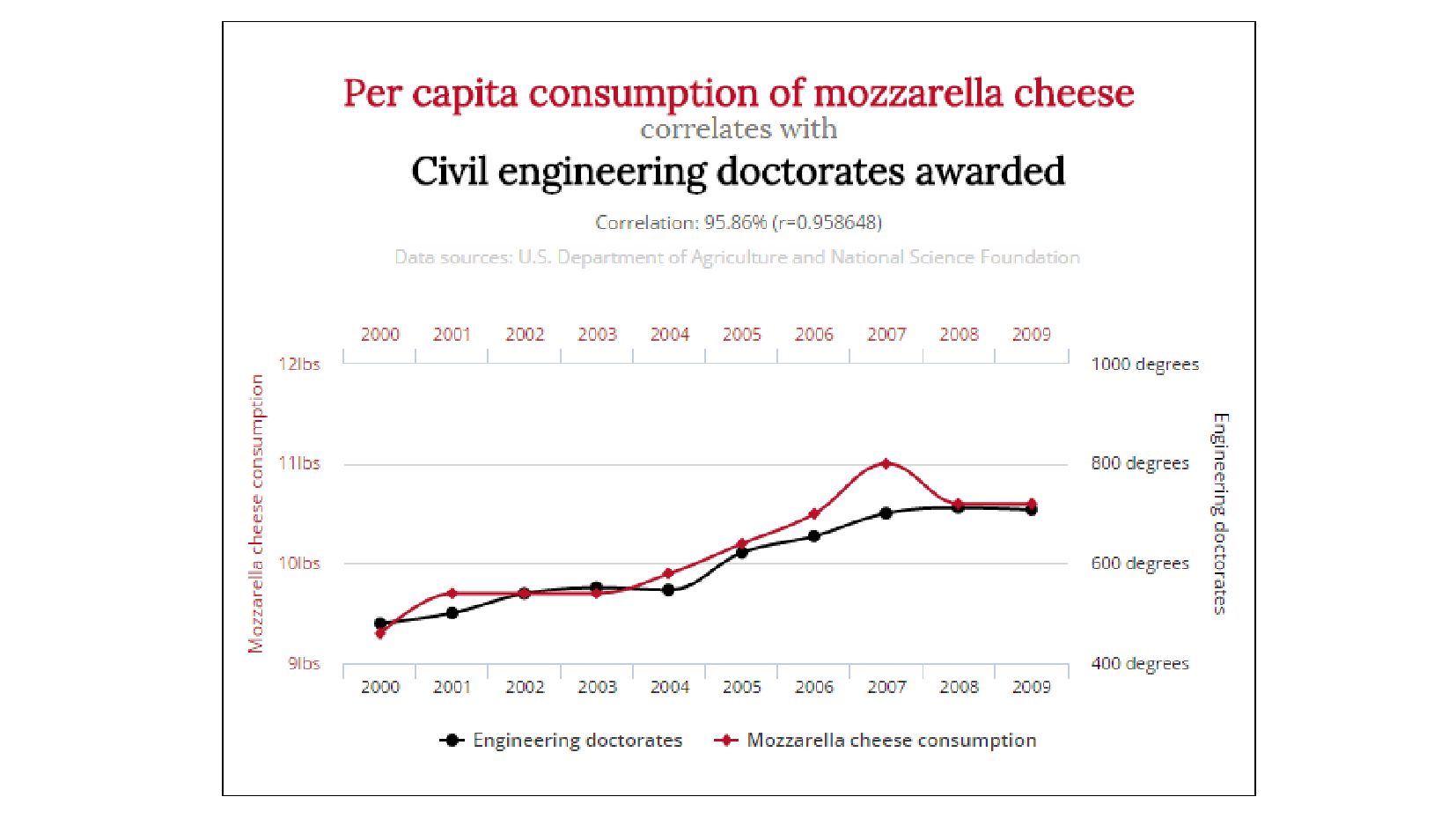{kind=link}
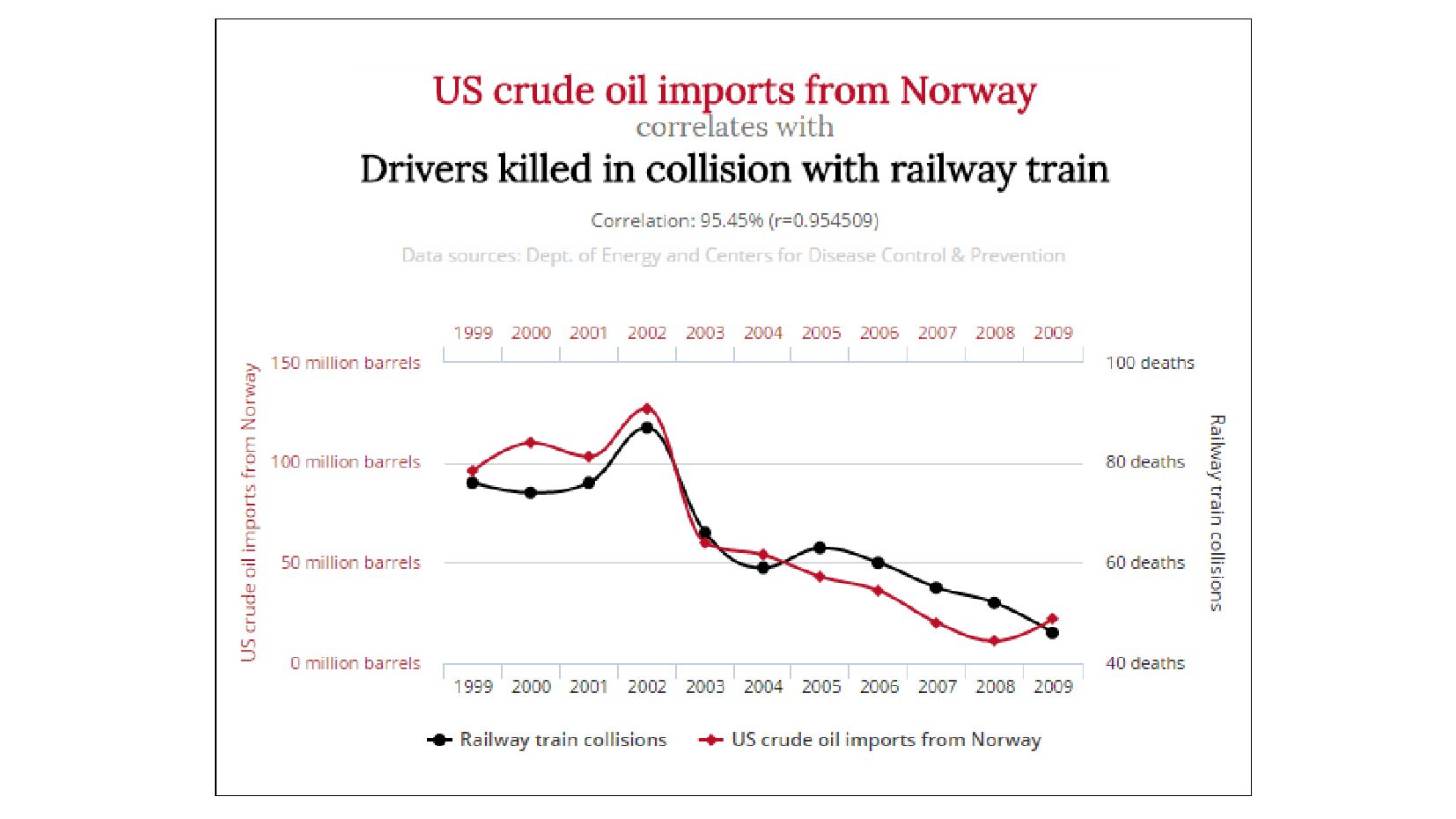{kind=link}
{kind=link}
{kind=link}
{kind=link}