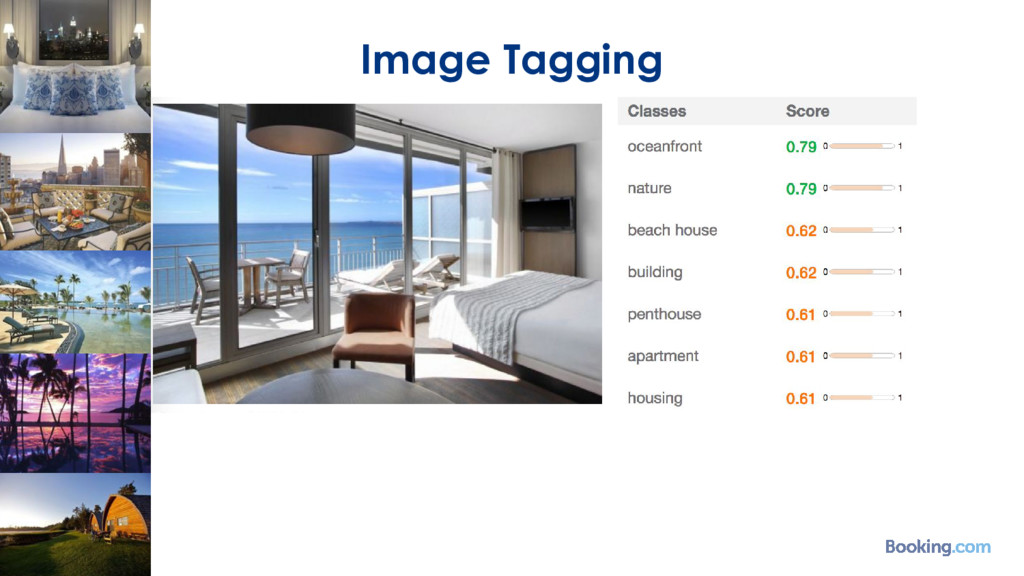
Each day, over 1.5 million room nights are reserved on Booking.com. That gives us access to huge amount of data which we can utilize in order to provide a better experience to our customers.
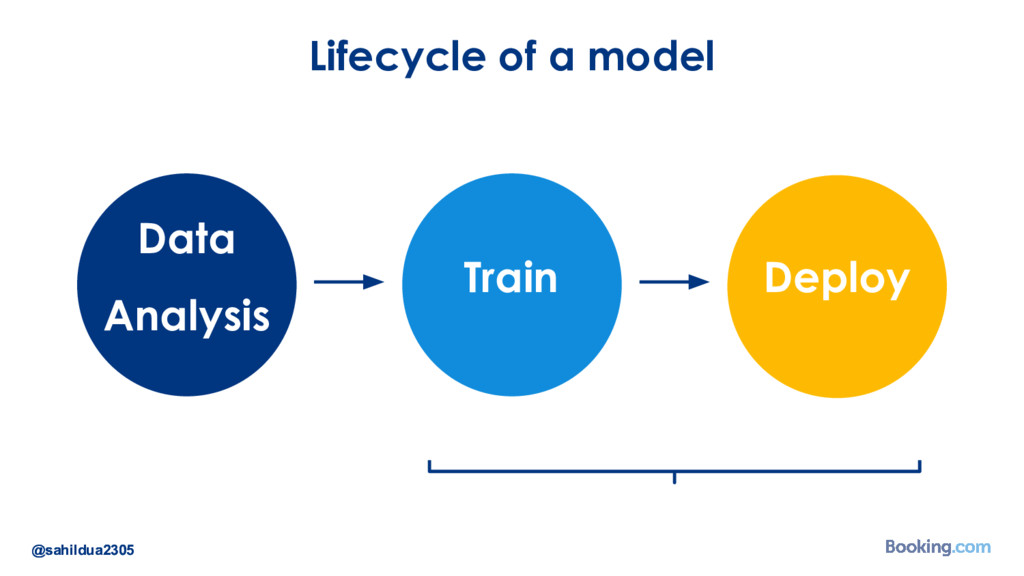
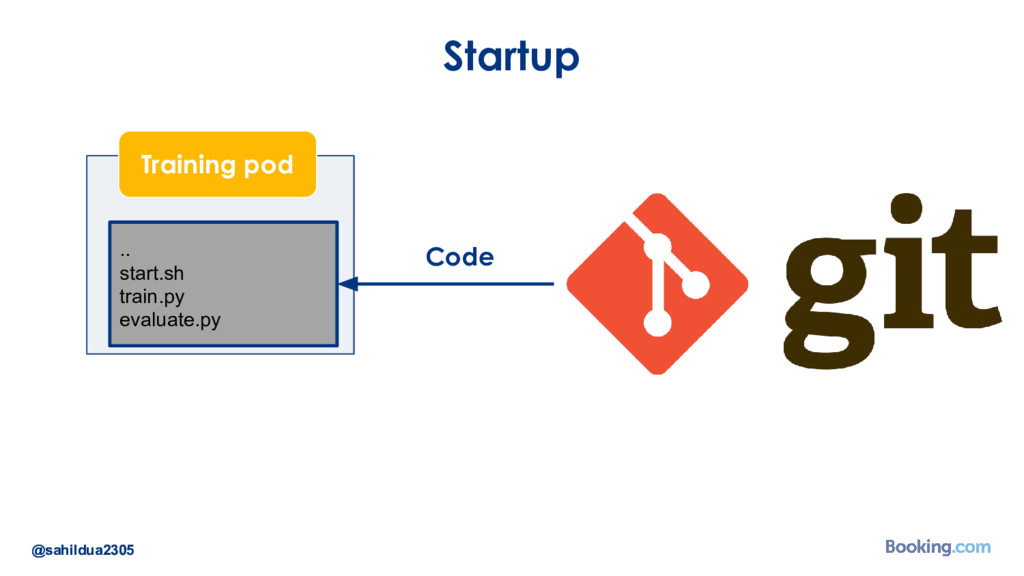
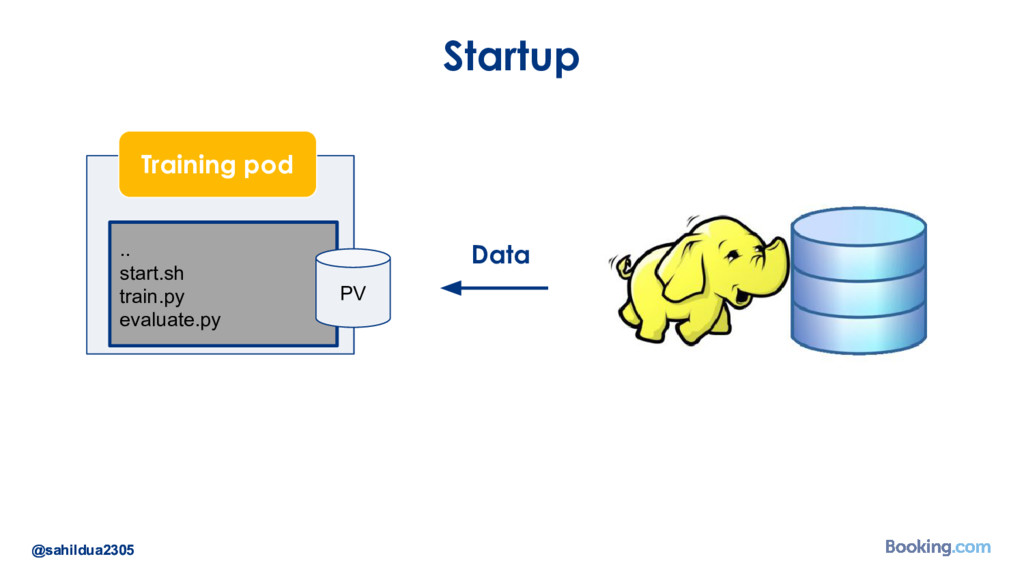
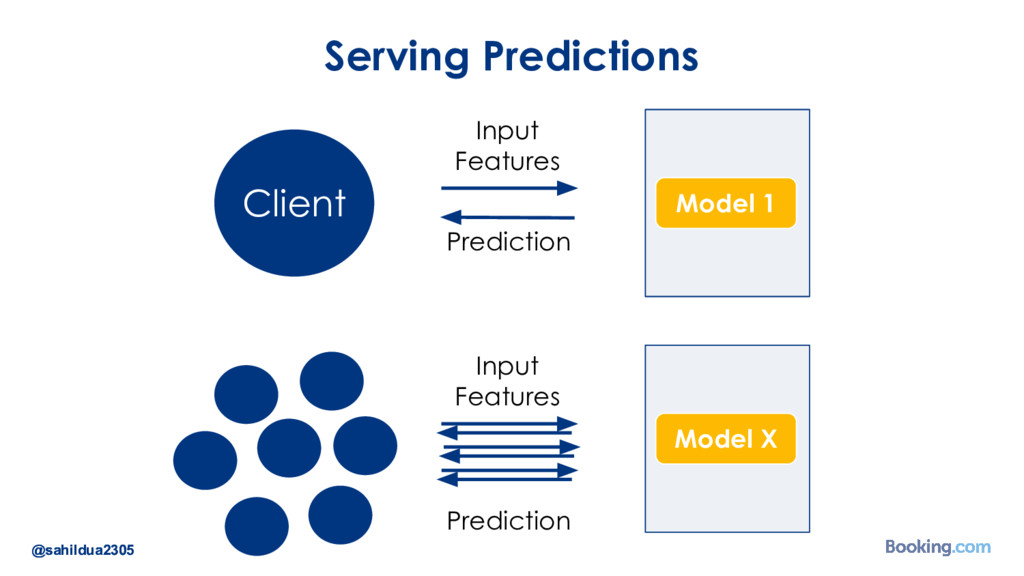
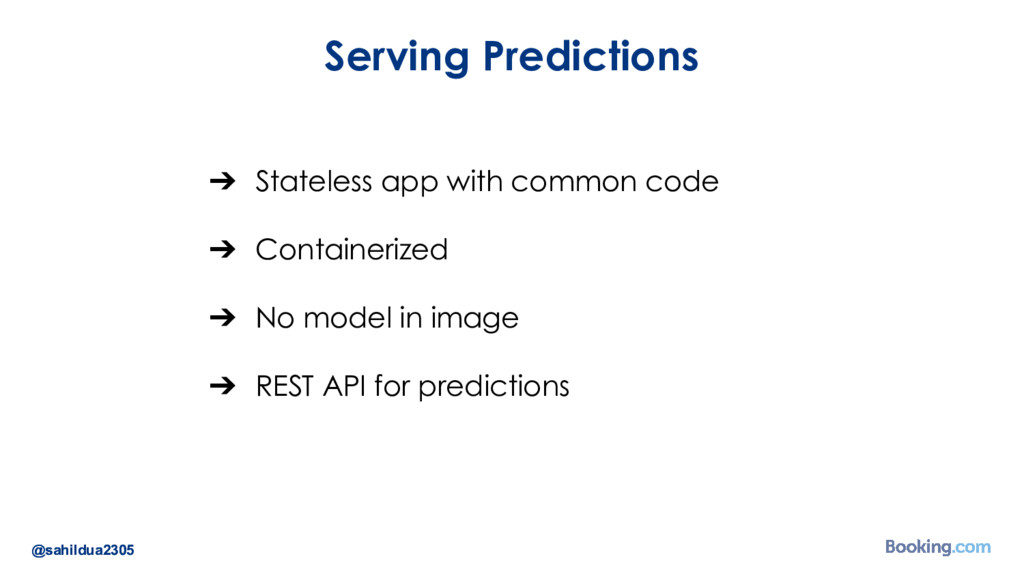
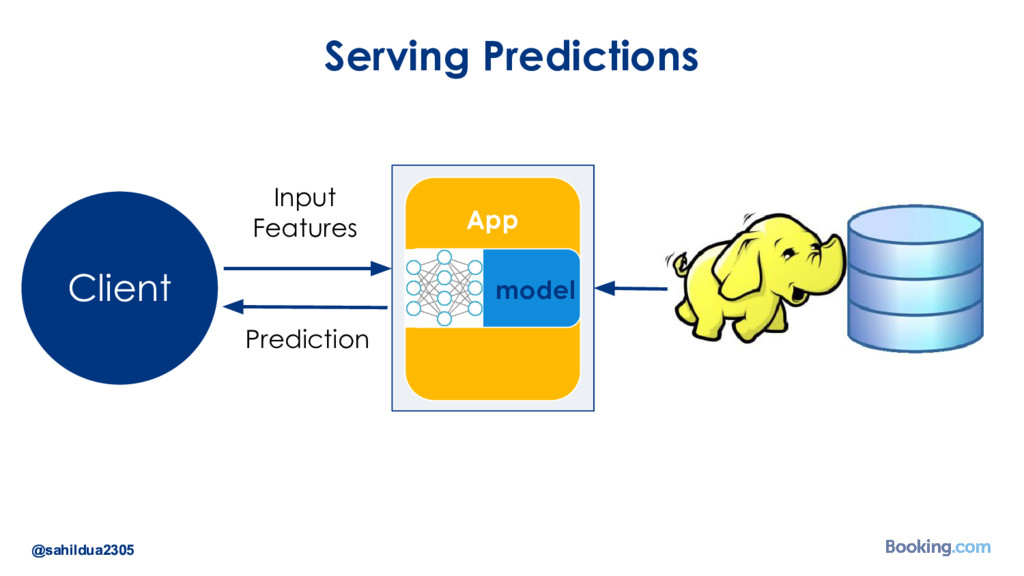
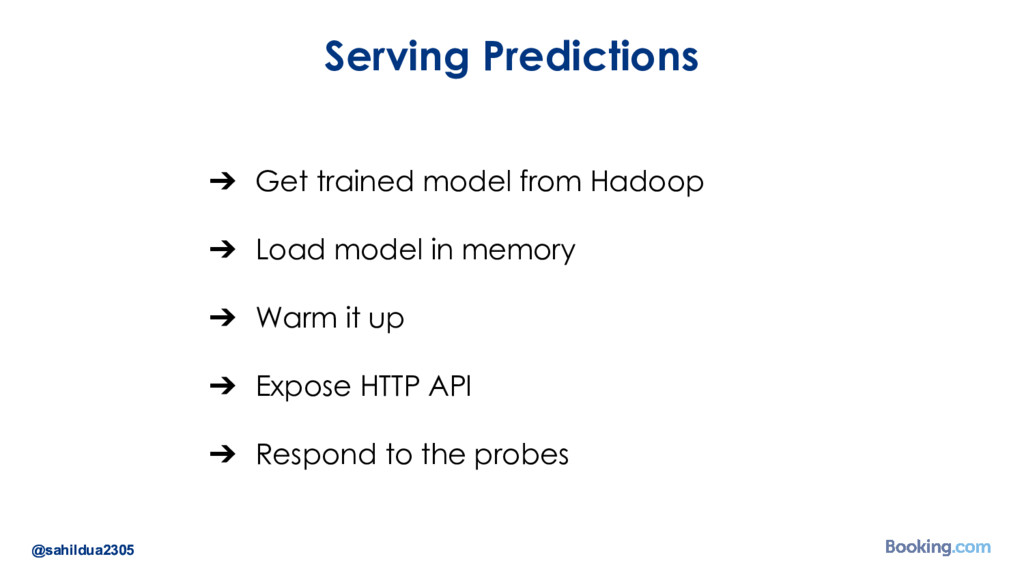
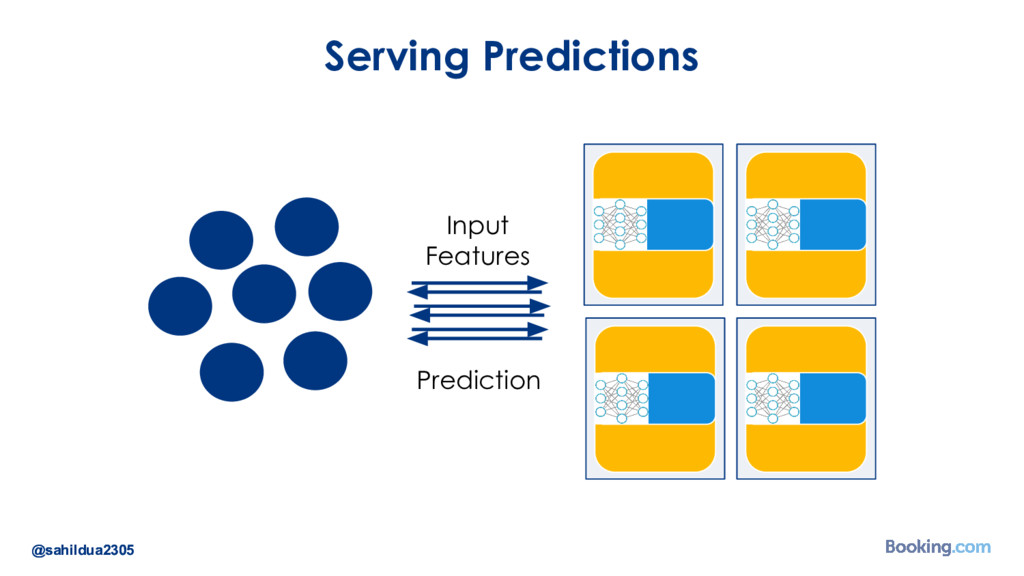
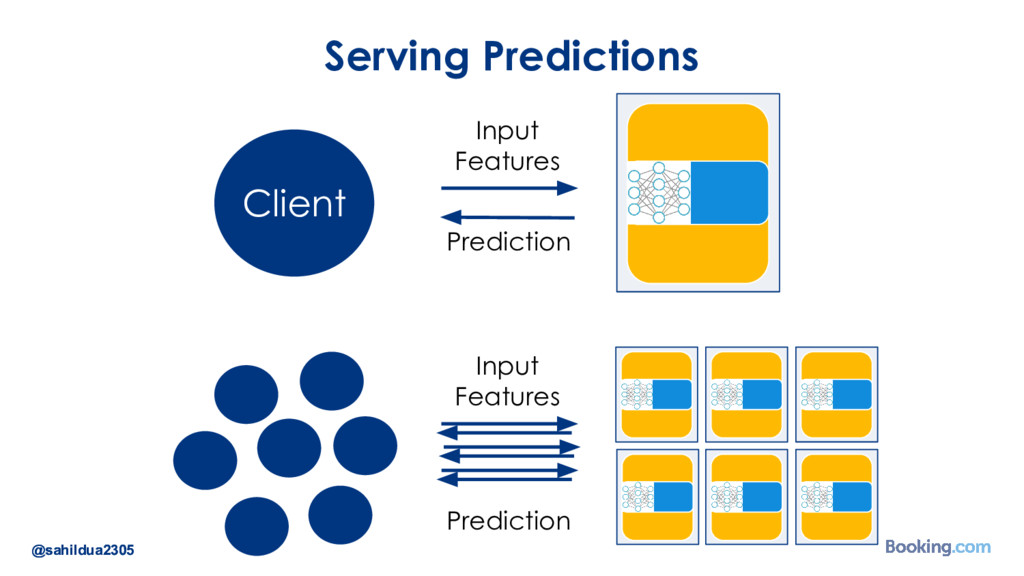
We understand that while there are a lot of machine learning frameworks and libraries available, putting the models in production at large scale is still a challenge. I’d like to talk about how we took on the challenge of deploying deep learning models in production: how we chose our tools and developed our internal deep learning infrastructure. I’ll cover how we do model training in Docker containers, distributed TensorFlow training in a cluster of containers, automated re-training of models and finally - deployment of models using Kubernetes. I’ll also talk about how we optimize our model prediction infrastructure for latency or throughput depending on the use case.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
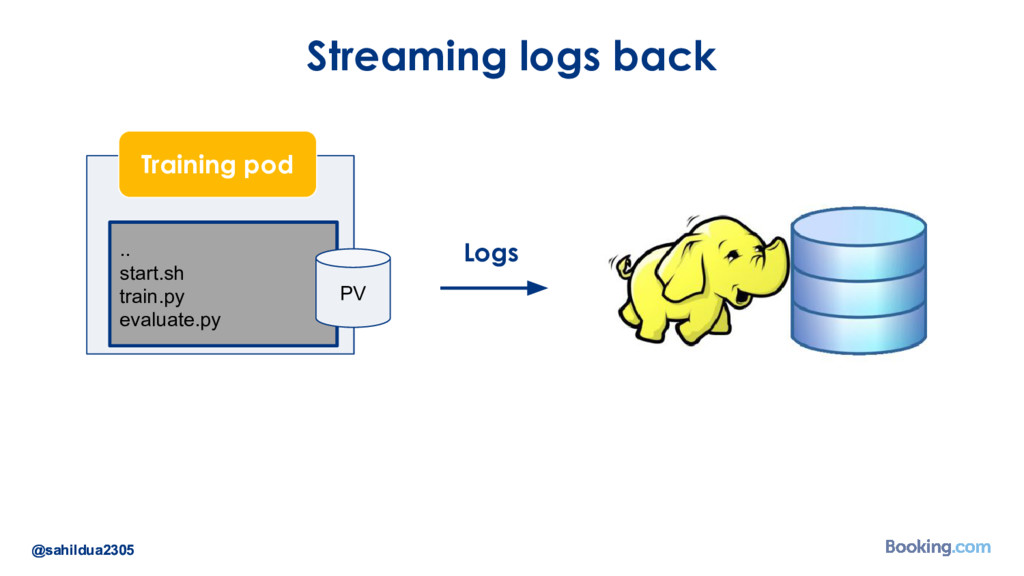{kind=link}
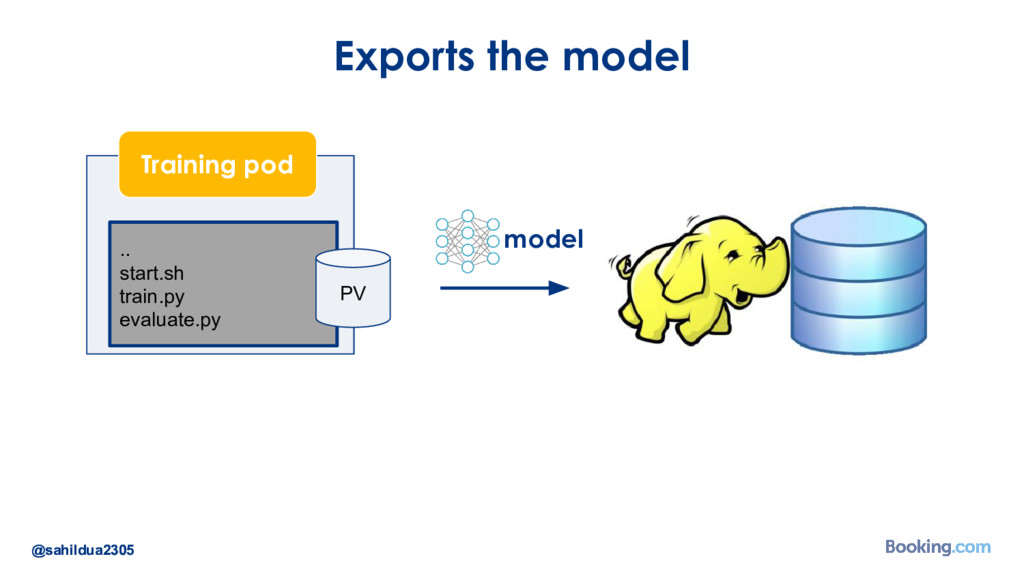{kind=link}
{kind=link}
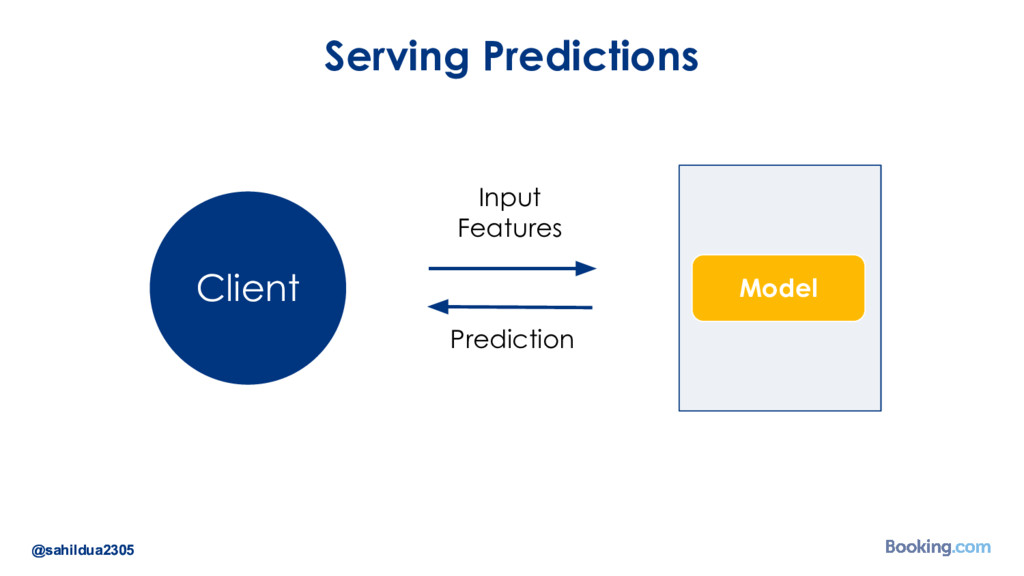{kind=link}
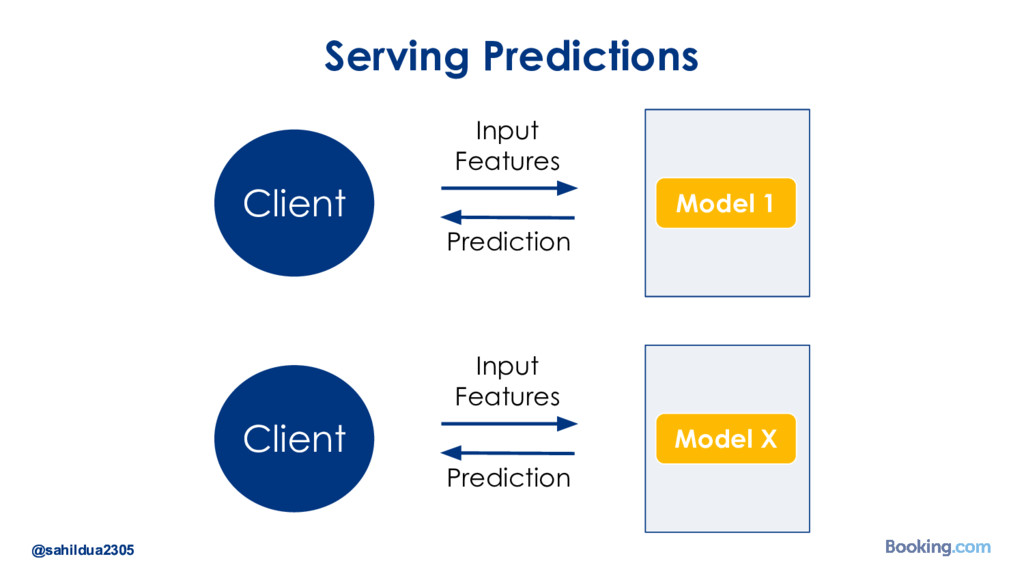{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}