Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SLOとあるサービスのお話
Search
yuta sakai
September 08, 2023
990
0
Share
SLOとあるサービスのお話
yuta sakai
September 08, 2023
More Decks by yuta sakai
See All by yuta sakai
楽になりたくてECS Fargate〜Cloud NativeとECS利用の現場〜
sakai99
1
1.3k
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
Between Models and Reality
mayunak
4
320
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
130
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
54k
Building AI with AI
inesmontani
PRO
1
1.1k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
Six Lessons from altMBA
skipperchong
29
4.3k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Accessibility Awareness
sabderemane
1
130
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
200
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Transcript
SLOとあるサービスのお話 2023.08.29 Uzabase, Inc. Product Div. SRE Team Yuta Sakai
2 語り部(自己紹介 ) 酒井 優太 株式会社ユーザベース Product Division SRE Team所属 2018年より株式会社ユーザベースに入社、サービスインフラ
の改善・運用・情報セキュリティ等を担当。
3 今日のお話 自社サービスの一つにSLOを策定した際の具体的な流れにつ いて発表します。 ちょうどSLOに興味があったり、一旦調べてナルホドとなっ て他社はどういう風に進めているのかな?と気になってい る人の参考の一つになればと思います。 *今回はSLOに関わる用語自体の説明はあまりしません
4 今回のお話の舞台(SLOを策定したサービス) サービス概要 • 顧客分析や企業データの名寄せを提 供するサービス • B to B
• 人のアクセスは主にビジネスタイム • SFA/MAから定常的にAPIアクセス あり • 5年以上継続しているサービスなの で色々な提供機能がある
5 技術的なところの補足説明 • Datadogを導入していてAPMでアプリケーション のエラー検知やレイテンシー測定ができる
6 サービスに関わる人たち(今回の説明に関して) 開発チームメンバー SREチーム 担当メンバー PdM(プロダクトマネージャー)
7 SLOを取り決める前の課題感 • アラートが飛びすぎて大変 ◦ Datadogで500エラーはSlack通知していたので、影 響の低い箇所や既知の問題でも確認する必要があり 対応負荷が高い • 改善アクションをやるやらないの判断の難しさを感
じている ◦ エラー改善に対する優先度を上げる判断軸がない • 利用頻度の高いユーザからレスポンスが遅く感じる 時があるという声 ◦ 個別事象なのか広い影響なのか確認しずらい
8 SLOを取り決めた後に実現したい状態 • 影響の低いエラーの通知は減らしたい • エラーに対する改修の判断軸を持てるようにした い • レスポンス速度に対する判断軸を持てるようにし たい
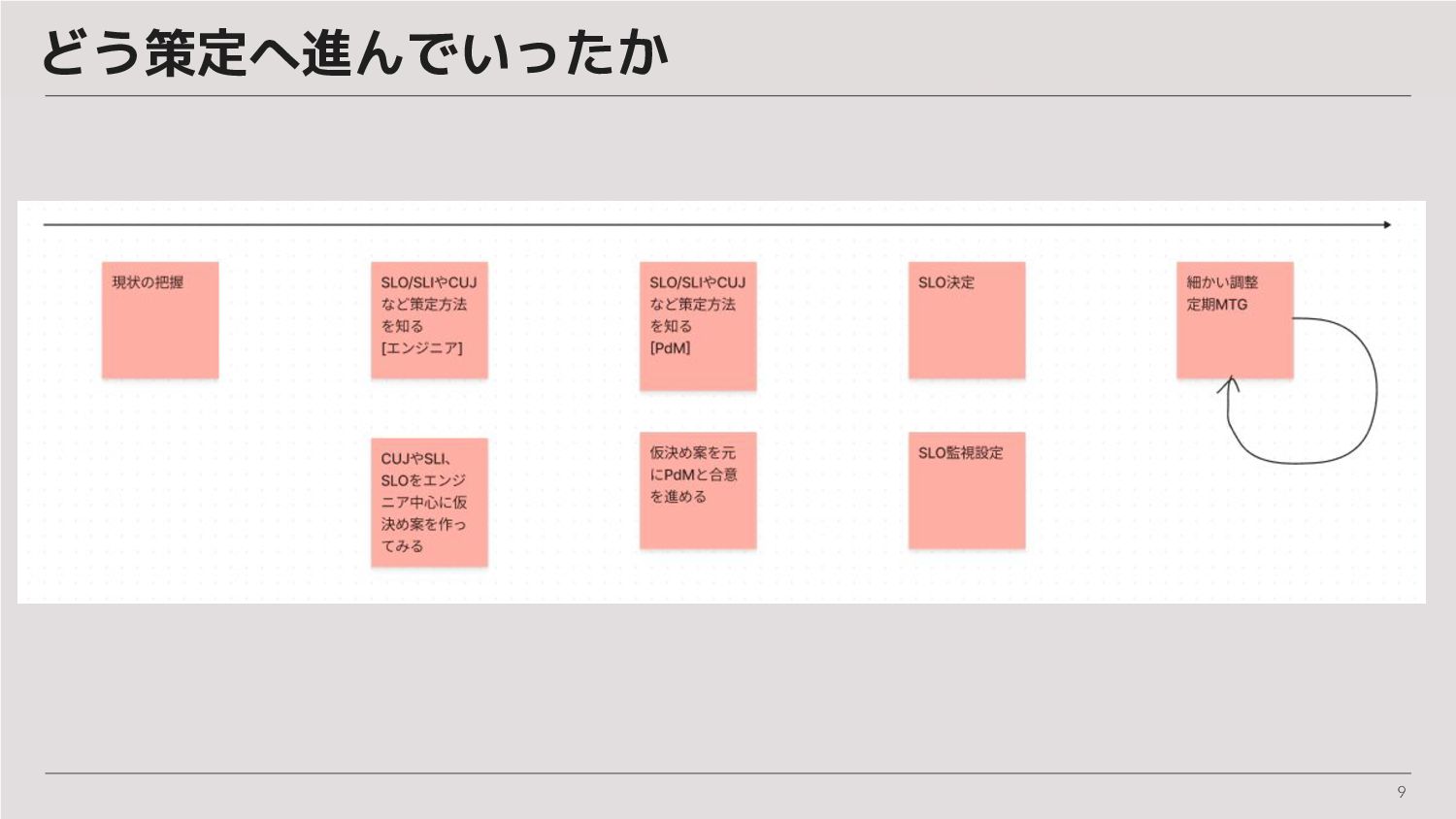
9 どう策定へ進んでいったか
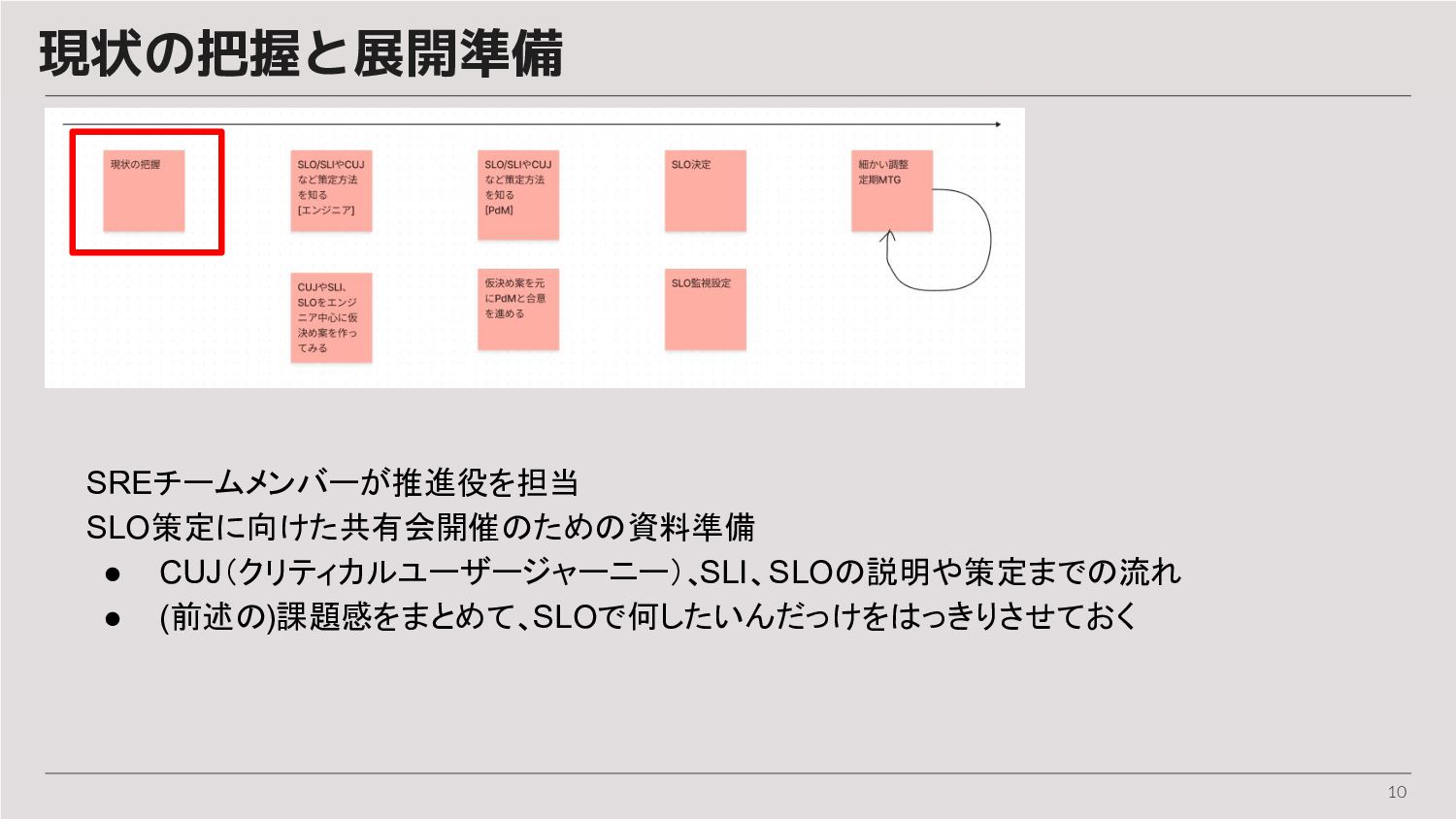
10 現状の把握と展開準備 SREチームメンバーが推進役を担当 SLO策定に向けた共有会開催のための資料準備 • CUJ(クリティカルユーザージャーニー)、 SLI、SLOの説明や策定までの流れ • (前述の)課題感をまとめて、SLOで何したいんだっけをはっきりさせておく
11 開発チームと共有会 SREメンバー、開発メンバーで共有会開催 • 準備していた資料を展開して説明 • 説明後、開発メンバーにCUJの洗い出しとSLI、SLOを仮で取り決めて貰う ◦ 許容エラー率とレイテンシー秒数を取り決め (既存のDatadog情報を参照しつつ)
◦ PdMとの共有会での判断の叩き台として利用 ◦ (目安)2時間x3回くらいの打ち合わせで決定していた印象
12 PdMと共有会 SREメンバー、開発メンバー、PdMで共有会開催 • 準備していた資料を展開して説明 • 説明後、開発メンバーとPdMを中心に仮決めしていたCUJとSLOに過不足ないか議 論してブラッシュアップ ◦ (目安)1時間x3回くらいの打ち合わせで決定していた印象
13 共有会時期の感想 CUJを選定する際にtier1 - 3といった優先度を作って振り分けると議論しや すかった 今回のFORCASはサービスとして規模があり優先度高いと判断したもの が多かったため、20個のCUJを設けるスタートとなった 既存Datadogのエラー頻度から大丈夫そうという判断で進んだが、もっと少 ない数(5個くらい)からスタートする方が一般的かも
14 合意されたSLOの決定と監視設定 共有会を通して合意されたSLOが決定 「合意されたSLO」を元にSREメンバーが監視設定を作成 • エラー率、レイテンシー共にDatadogのデータを利用 • DatadogのSLO監視サービス機能を利用してSLIとSLOを定義 ◦ 過剰にアラートが上がらないかなど様子見しつつスタート
15 調整時期 SREメンバーと開発メンバーでSLO定例MTGを開催(隔週) • SLO違反が出ていないかを確認 • 違反があった場合、発生理由を参加メンバーで確認してネクストアクションを決める ◦ 監視設定自体に誤りがあって調整することもあれば、アプリの改修が必要だねという認 識になってPdMと対応時期の会話をスタートさせることもあった
◦ SLO監視の閾値見直しは数値遊びになっていないかの意識を持って臨む
16 策定〜調整時期の感想 「アクセス頻度は低めで、利用者の使い方によってレイテンシーの幅が大き い」ものはバーンレートアラートが出やすいので、エラーバジェットが消費し 切ったらアラート出す方法で調整した 「アクセス頻度は低め」系のSLOはアラートノイズになりやすく、なかなか調 整難しいなと感じている
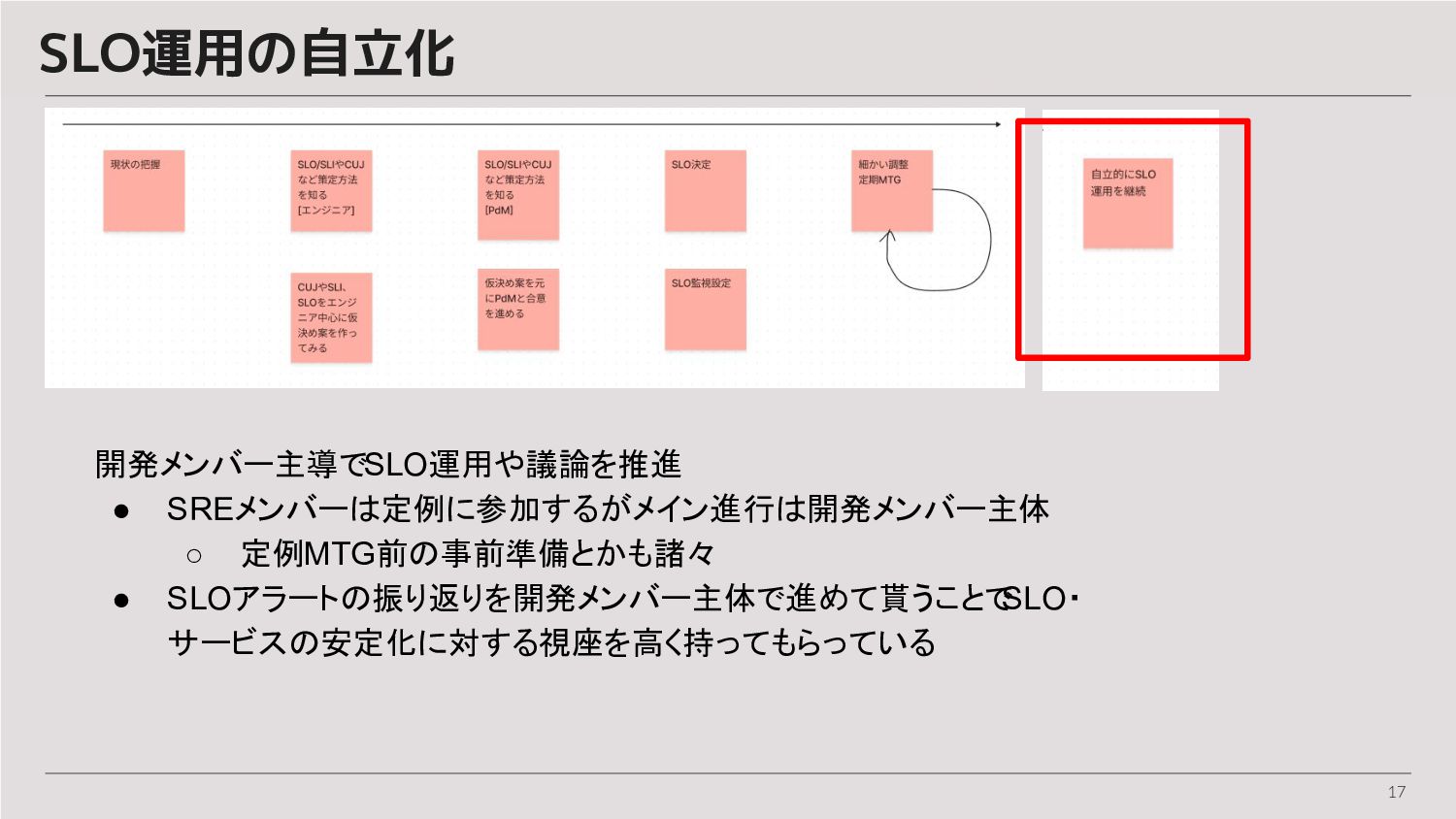
17 SLO運用の自立化 開発メンバー主導でSLO運用や議論を推進 • SREメンバーは定例に参加するがメイン進行は開発メンバー主体 ◦ 定例MTG前の事前準備とかも諸々 • SLOアラートの振り返りを開発メンバー主体で進めて貰うことで SLO・
サービスの安定化に対する視座を高く持ってもらっている
18 実現したい状態は達成したの? • 影響の低いエラーの通知は減らしたい => 減った。けど、バーンレート通知で一時的で影響低いケースを拾 うことはボチボチある(アラートが出やすいSLO項目の傾向は掴めて いる) • エラーに対する改修の判断軸を持てるようにしたい
=> SLOを定めたのでアラートが出たものは開発チームとPdMで対応 判断をする時の基準ができた。けど、機能開発とのスケジュールバラ ンスは難しい • レスポンス速度に対する判断軸を持てるようにしたい => CUJを定めてことでどの部分のレスポンスを注視すべきかが定 まった。けど、利用者によってレイテンシーの幅が大きい場合の最適 なSLOが難しい
19 俺たちの戦いはこれからだ! オレはようやくのぼりはじめたばかりだからな このはてしなく遠いSLO坂をよ… 未完
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}