Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
楽になりたくてECS Fargate〜Cloud NativeとECS利用の現場〜
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
yuta sakai
June 30, 2021
Technology
1.3k
1
Share
楽になりたくてECS Fargate〜Cloud NativeとECS利用の現場〜
Cloud Native Lounge #1「サービスを支えるクラウドネイティブな基盤」
https://forkwell.connpass.com/event/215187/
yuta sakai
June 30, 2021
More Decks by yuta sakai
See All by yuta sakai
SLOとあるサービスのお話
sakai99
0
990
Other Decks in Technology
See All in Technology
AI フレンドリーなエラー監視を TypeScript で実現する
shinyaigeek
2
250
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
50k
「コーディング」しない人のための Claude Code 入門 ChatGPT の次の一歩 — 業務に組み込む 育成・共有・自動化
rfdnxbro
2
1.2k
正解のないAIプロダクトをどう導くか?dodaが挑む、ユーザーの『本音』を構造化する評価設計と検証のリアル
techtekt
PRO
0
180
地元にいないローカルオーガナイザーの立ち回り
uvb_76
1
470
AIを「創る」と「使う」の循環 — HRテックが実践するリアルなAI組織実装
taketo957
0
1.5k
Agentic ERPをどう設計するか ー 受発注エージェントを動かす、現場の知見と設計思想ー
recerqainc
1
1.5k
Agentic Web
dynamis
1
110
データ基盤をDataformで整えた話 〜 開発環境を添えて 〜
takapy
0
110
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
2
140
Claude Code×Terraform IaC テンプレート駆動開発
itouhi
0
210
MIERUNE JCT 発表資料「宇宙から伊能忠敬ごっこ」
syuchimu
0
180
Featured
See All Featured
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
220
Git: the NoSQL Database
bkeepers
PRO
432
67k
Leo the Paperboy
mayatellez
7
1.8k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
240
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
600
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
300
How to train your dragon (web standard)
notwaldorf
97
6.7k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The SEO identity crisis: Don't let AI make you average
varn
0
480
Transcript
楽になりたくてECS Fargate 〜Cloud NativeとECS利用の現場〜 2021.06.17 Uzabase, Inc. SaaS Product Div.
SRE Team Yuta Sakai
2 自己紹介 酒井 優太 株式会社ユーザベース SaaS Product Division SRE Team所属 2018年より株式会社FORCAS(株式会社ユーザベース完全子会社、2021
年より株式会社ユーザベースに統合)に入社、サービスインフラの改善・ 運用・情報セキュリティ等を担当。
3 今日のお話1 AWSを利用 + 取り敢えずEC2内でコンテナ起動する形でサービス稼働開始 + JenkinsでAWS CLIを使ってB/Gデプロイ処理などを自作 + 役割コンテナが20くらいに育ってきた
= 色々と積み上がって大変な環境 これをなんとかしないと。。。
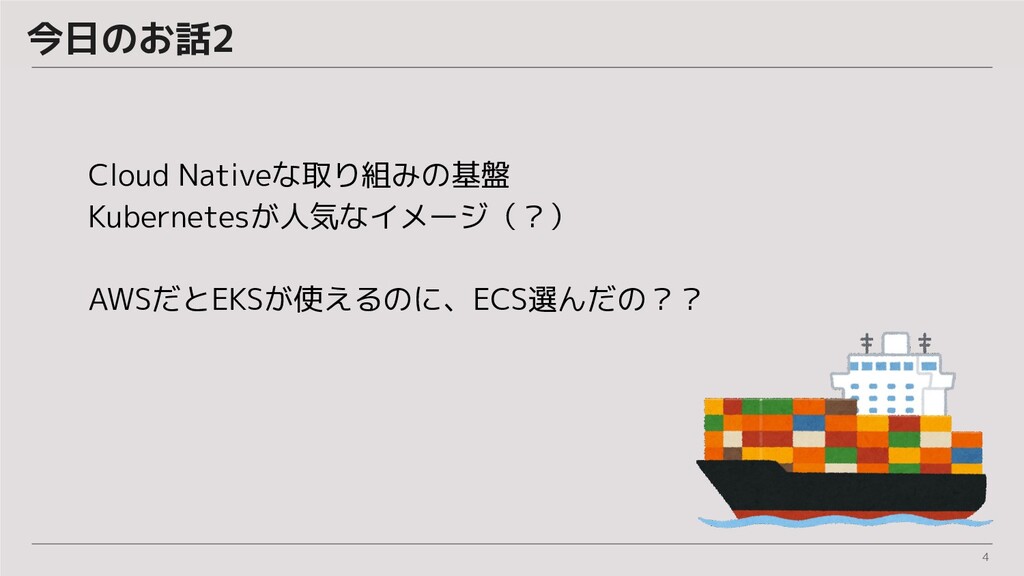
4 今日のお話2 Cloud Nativeな取り組みの基盤 Kubernetesが人気なイメージ(?) AWSだとEKSが使えるのに、ECS選んだの??
5 今回のお話の舞台 • B to B サービス • 人のアクセスは主にビジネスタイム •
Salesforceから定期にAPIアクセス あり
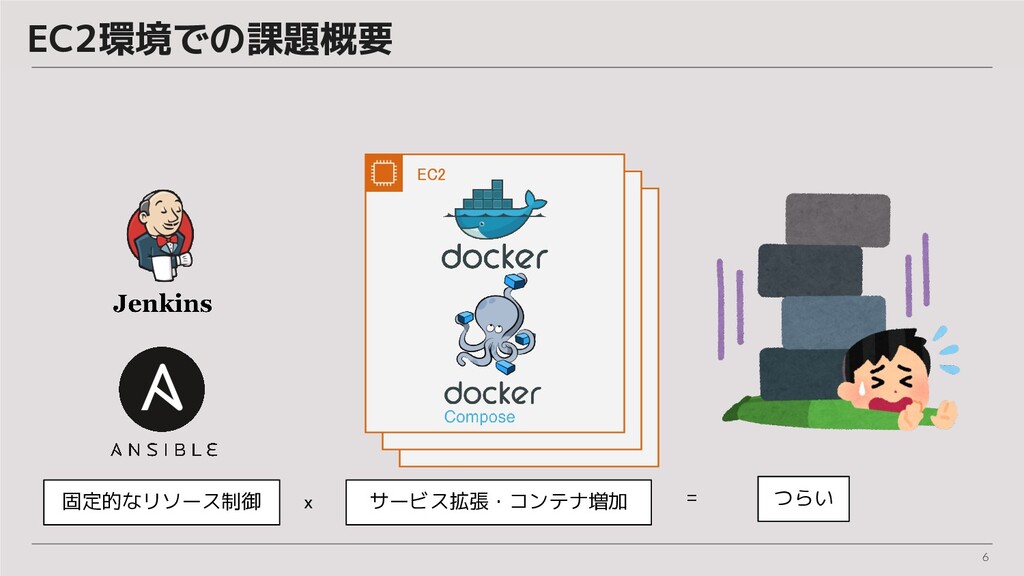
6 EC2環境での課題概要 EC2 固定的なリソース制御 サービス拡張・コンテナ増加 つらい x =
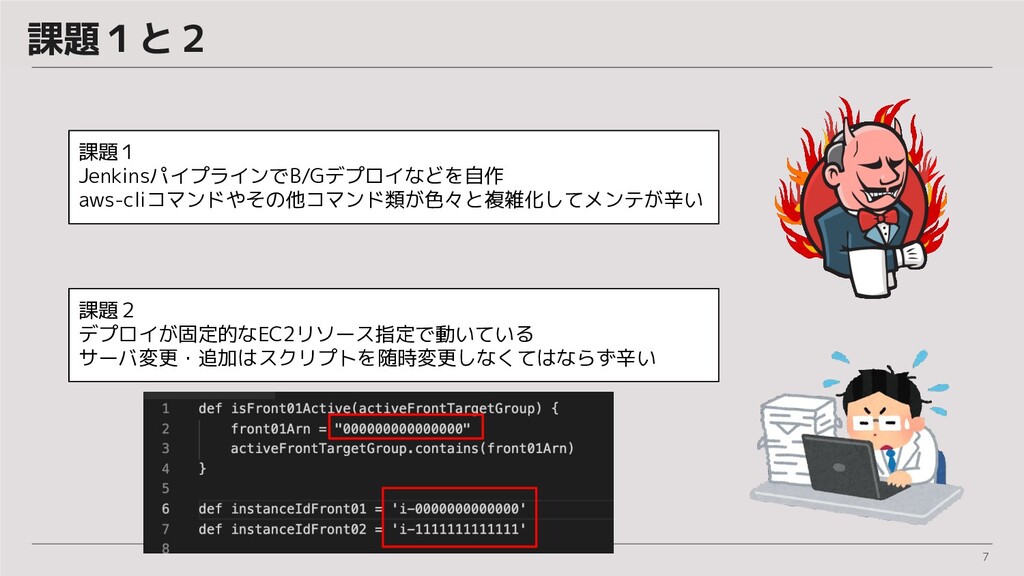
7 課題1と2 課題1 JenkinsパイプラインでB/Gデプロイなどを自作 aws-cliコマンドやその他コマンド類が色々と複雑化してメンテが辛い 課題2 デプロイが固定的なEC2リソース指定で動いている サーバ変更・追加はスクリプトを随時変更しなくてはならず辛い
8 課題3と4 課題3 密結合でmutableなリソースの使い方をしているので、連携待ち が発生してデプロイが遅い 課題4 サービスが成長してきて複数アプリケーション間の問題が特定 しづらい
9 解決したいことはシンプル 1. デプロイ設定をシンプルにしたい 2. 変化に対応しやすいリソース制御を可能にしたい 3. 疎な関係で早くデプロイできるようにしたい 4. コンテナ間の通信状態のモニタができるようにしたい
10 EKS、ECSと選択肢があった話1 CodeDeploy CodePipeline デファクトスタンダード エコシステムが豊富・色々できる シンプルな機能 マネージドシステムで管理が楽
11 EKS、ECSと選択肢があった話2 サービス構成はシンプル、解決したい事もシンプルな要件 結果、ECSの方が今回のシンプルな利用にマッチしていた CodeDeploy CodePipeline 採用 チーム課題を最短で解決して、 サービスの価値をユーザに届けたい! +
12 これもまたCloud Native 1. 回復性 -> ECS Fargateは自動で複数AZへ分散起動・障害時に自動復帰する 2. 管理力
-> ECSは簡単に必要実行数を設定可能・immutableなコンテナ実行環境 3. 可観測性 -> Datadogでアプリケーションモニタリング・ログ分析を実施 4. 疎結合システム -> ALBでコンテナ間を疎結合に通信・1task1アプリ実行 5. 堅牢な自動化 -> CodePipeline/Deployを組み合わせたシンプルなデプロイ Cloud Nativeの技術で実現すること 回復性、管理力、および可観測性のある疎結合システム 堅牢な自動化 *「CNCF Cloud Native Definition v1.0」から抜粋 https://github.com/cncf/toc/blob/main/DEFINITION.md#日本語版
13 課題はどうなったの? 色々と解決しました!!
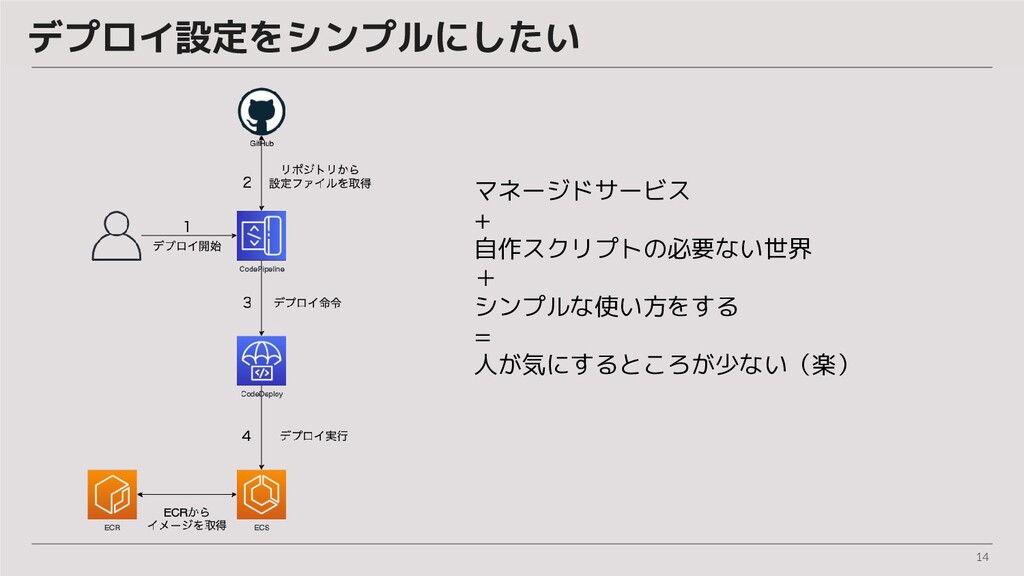
14 デプロイ設定をシンプルにしたい マネージドサービス + 自作スクリプトの必要ない世界 + シンプルな使い方をする = 人が気にするところが少ない(楽)
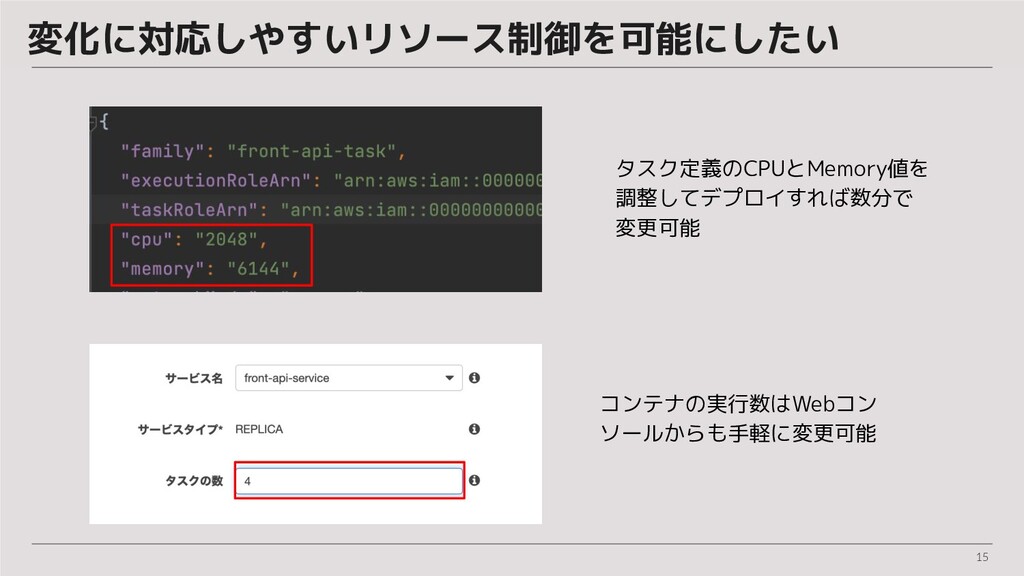
15 変化に対応しやすいリソース制御を可能にしたい タスク定義のCPUとMemory値を 調整してデプロイすれば数分で 変更可能 コンテナの実行数はWebコン ソールからも手軽に変更可能
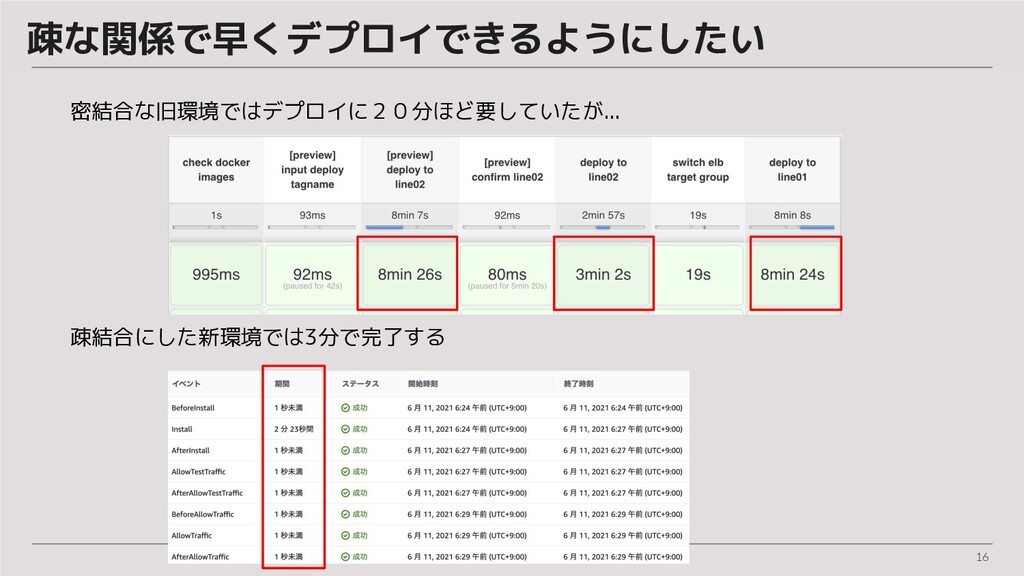
16 疎な関係で早くデプロイできるようにしたい 密結合な旧環境ではデプロイに20分ほど要していたが... 疎結合にした新環境では3分で完了する
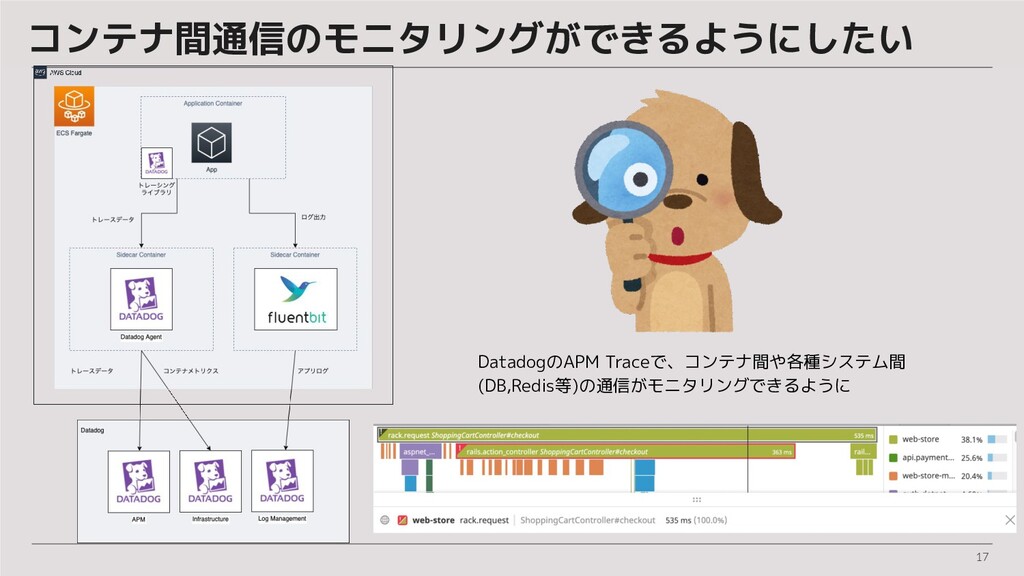
17 コンテナ間通信のモニタリングができるようにしたい DatadogのAPM Traceで、コンテナ間や各種システム間 (DB,Redis等)の通信がモニタリングできるように
18 (補足)費用はどうなの? *EC2 m5.xlarge相当オンデマンド / Tokyo Region / 4 vCPU
/ 16GB Mem / 20GB Storage ざっくり比較 単純なEC2とFargateの費用比較 EC2 < Fargate($180.48 < $209.32) Datadog(Infrastructure + APM)を含めた、EC2とFargateの費用比較 EC2 > Fargate($226.48 > $212.32) *DatadogをFargateで動かす時のイニシャル費用が安い (Fargate 1taskあたり Infrastructure $1/mo、APM $2/moとか。EC2だとそれぞれ $15/mo 、$31/mo) トータルとして大きく膨らむ事はない費用感で使えている
19 ECSで全て順調?? 色々と問題あったよ!!
20 トラブル事例1 CPUパラメーターが未設定で起動エラー タスク定義のcontainerDefinitionsでcpuパラメーター(オプション扱い)が未設定だと起動エラー *1CPUより大きいリソースを期待する仕様の一部アプリで発生 *ECS タスク定義ドキュメント > Null、0、1 の CPU
値は Docker に 2 個の CPU 配分として渡されます。 https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/userguide/task_definition_parameters.html { "family": "front-api-task", "cpu": "2048", "memory": "12288", "containerDefinitions": [ { "name": "front-api", "cpu": 0, "cpu": 2048, 全体には十分なリソースがあるのに 起動エラーになるのは何故? 🤔 とハマってしまった 未設定で定義を登録すると「“cpu”: 0」として 登録される(この暗黙的な設定が敗因) 明示的に設定しないと制限に引っ張られてエラーになる (内部的に「“cpu”: 0」は「“cpu”: 2」として扱わる)
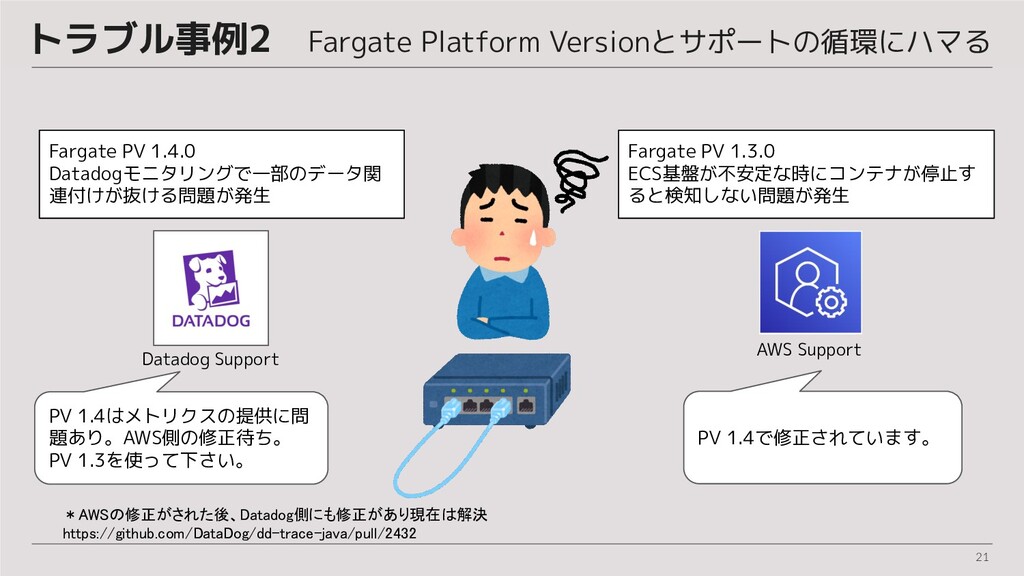
21 トラブル事例2 Fargate Platform Versionとサポートの循環にハマる Fargate PV 1.4.0 Datadogモニタリングで一部のデータ関 連付けが抜ける問題が発生 AWS
Support PV 1.4はメトリクスの提供に問 題あり。AWS側の修正待ち。 PV 1.3を使って下さい。 PV 1.4で修正されています。 Fargate PV 1.3.0 ECS基盤が不安定な時にコンテナが停止す ると検知しない問題が発生 Datadog Support *AWSの修正がされた後、Datadog側にも修正があり現在は解決 https://github.com/DataDog/dd-trace-java/pull/2432
22 トラブル事例3 サイドカーが巻き込み事故を起こす 一定の負荷が掛かると「failed container health checks」エラーが頻発 サイドカーのDatadog Agentコンテナのヘルスチェックコマンドが失敗して停止 起動必須にしているためメインのアプリコンテナを巻き込んで再起動が発生 *以下の変更前後で発生
Fargate PV 1.3.0 + Datadog Agent 7.24.0 から Fargate PV 1.4.0 + Datadog Agent 7.26.0 へ サイドカーのリソースきちんと見るの重要 *DatadogドキュメントのECS Fargate定義例 "name": "datadog-agent", "cpu": 10, "memoryReservation": 256, "essential": true, "healthCheck": { "command": [ "CMD-SHELL", "agent health" ], "interval": 30, "retries": 3, "startPeriod": 15, "timeout": 5 }, Datadog Agentコンテナのリソース不足により ヘルスチェックが時々失敗する状況が発生
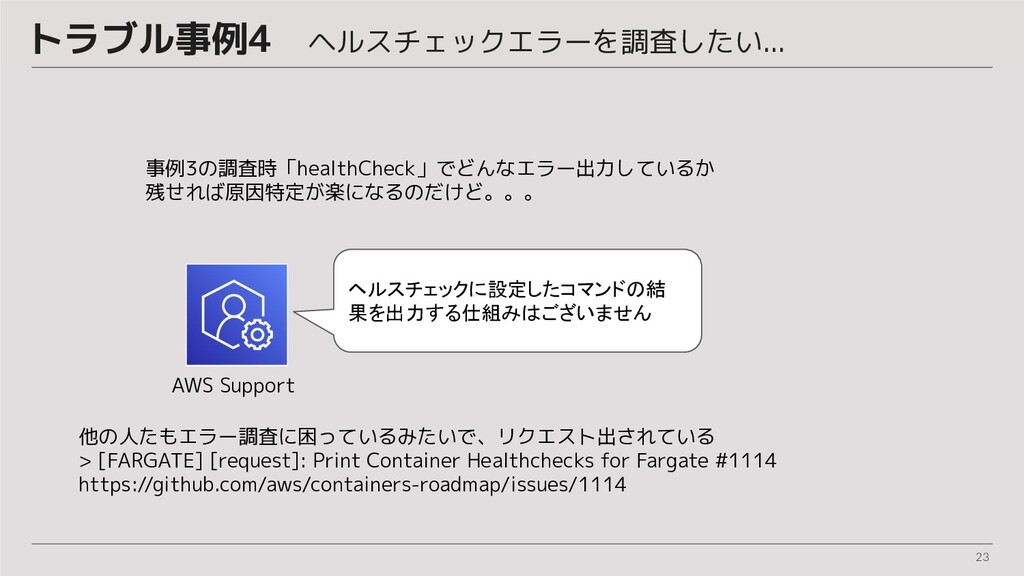
23 トラブル事例4 ヘルスチェックエラーを調査したい... 事例3の調査時「healthCheck」でどんなエラー出力しているか 残せれば原因特定が楽になるのだけど。。。 AWS Support ヘルスチェックに設定したコマンドの結 果を出力する仕組みはございません 他の人たもエラー調査に困っているみたいで、リクエスト出されている >
[FARGATE] [request]: Print Container Healthchecks for Fargate #1114 https://github.com/aws/containers-roadmap/issues/1114
24 ECSでの色々から感じること AWSに囲われている感は大いにある 不具合があった時に解決まで不透明でモヤモヤ サイドカー(Datadogなど)が重要な役割を担うようになっている 結果として、一番トラブル引き当てているのがサイドカー絡み GitHubにAWSコンテナサービス関連の機能とか不具合の情報が集まっている ので、issueとかカンバンを眺めてみると理解が進む https://github.com/aws/containers-roadmap AWSのブログでドキュメントより深掘された記事が投稿されているので、眺め
てみると理解が進む https://aws.amazon.com/blogs/containers/
25 まとめ ・ECS Fargateで楽になったの? 楽になった!(状況にマッチしているから) 次に行けばいい!(状況にマッチしなくなったら) 常に最適な環境を追い求める(王道) ・Cloud Nativeの取り組みって? Cloud
Nativeの定義に沿って課題を整理・検討してみる 「インパクトのある変更を最小限の労力で頻繁かつ予測どおりに行 う」方法を考える(王道)
26 We're Hiring! 最後に少しだけ
27 ユーザベースはインフラからアプリケーション開発まで、様々なスキルを持ったエンジニア たちが個々の強みを活かし、常に新しい技術に挑戦し信頼性を高める活動をしています。 SREチームでは様々な自社プロダクトを支える基盤の構築や運用を行ったり、パフォーマン スや信頼性、スケーラビリティを高めるエンジニアを募集しています。 あなたが興味のある分野で、技術を駆使して共に最高のプロダクトを作りませんか? *興味がありましたら、よろしくお願いします https://www.uzabase.com/jp/careers/ on-premise
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}