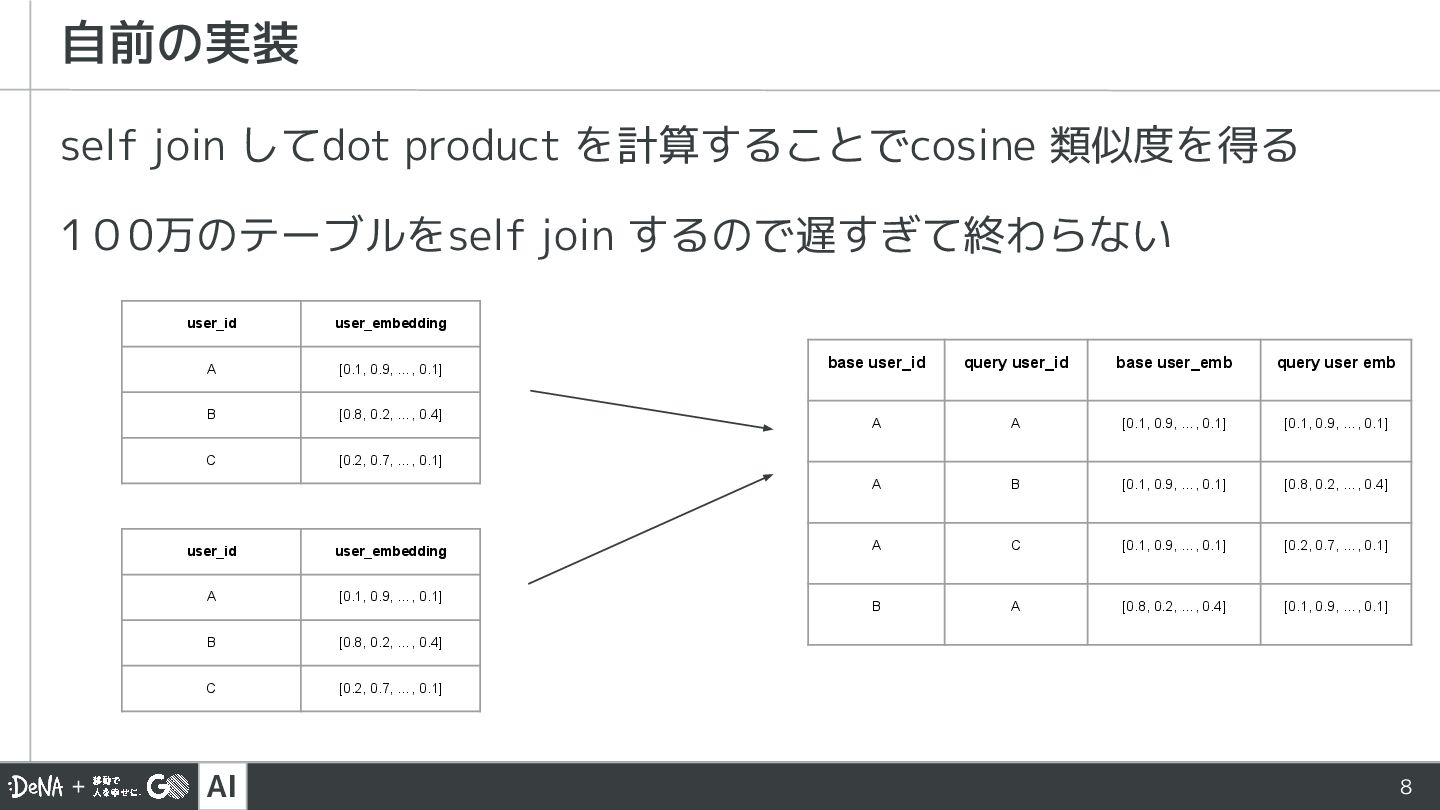
するので遅すぎて終わらない 自前の実装 user_id user_embedding A [0.1, 0.9, …, 0.1] B [0.8, 0.2, …, 0.4] C [0.2, 0.7, …, 0.1] user_id user_embedding A [0.1, 0.9, …, 0.1] B [0.8, 0.2, …, 0.4] C [0.2, 0.7, …, 0.1] base user_id query user_id base user_emb query user emb A A [0.1, 0.9, …, 0.1] [0.1, 0.9, …, 0.1] A B [0.1, 0.9, …, 0.1] [0.8, 0.2, …, 0.4] A C [0.1, 0.9, …, 0.1] [0.2, 0.7, …, 0.1] B A [0.8, 0.2, …, 0.4] [0.1, 0.9, …, 0.1]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
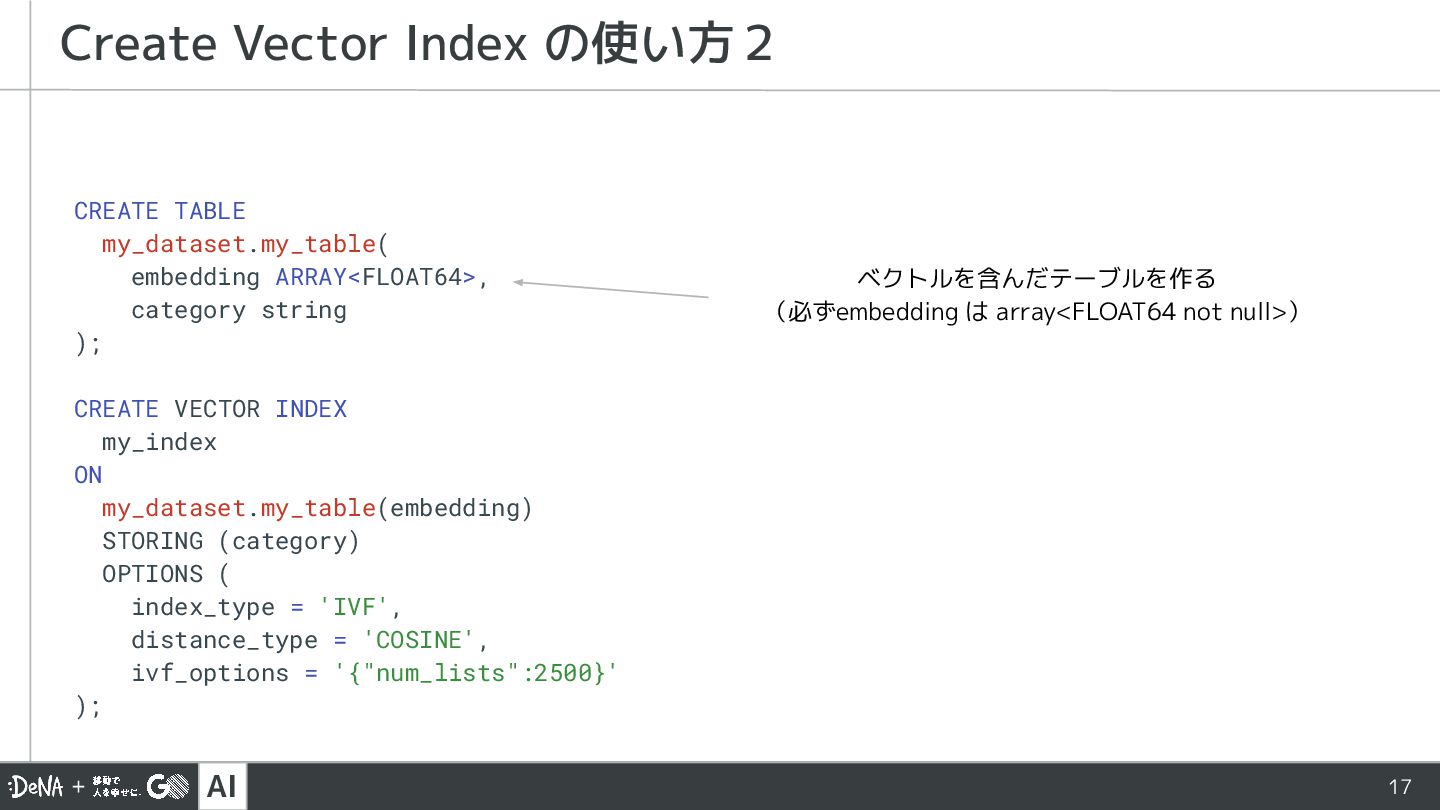{kind=link}
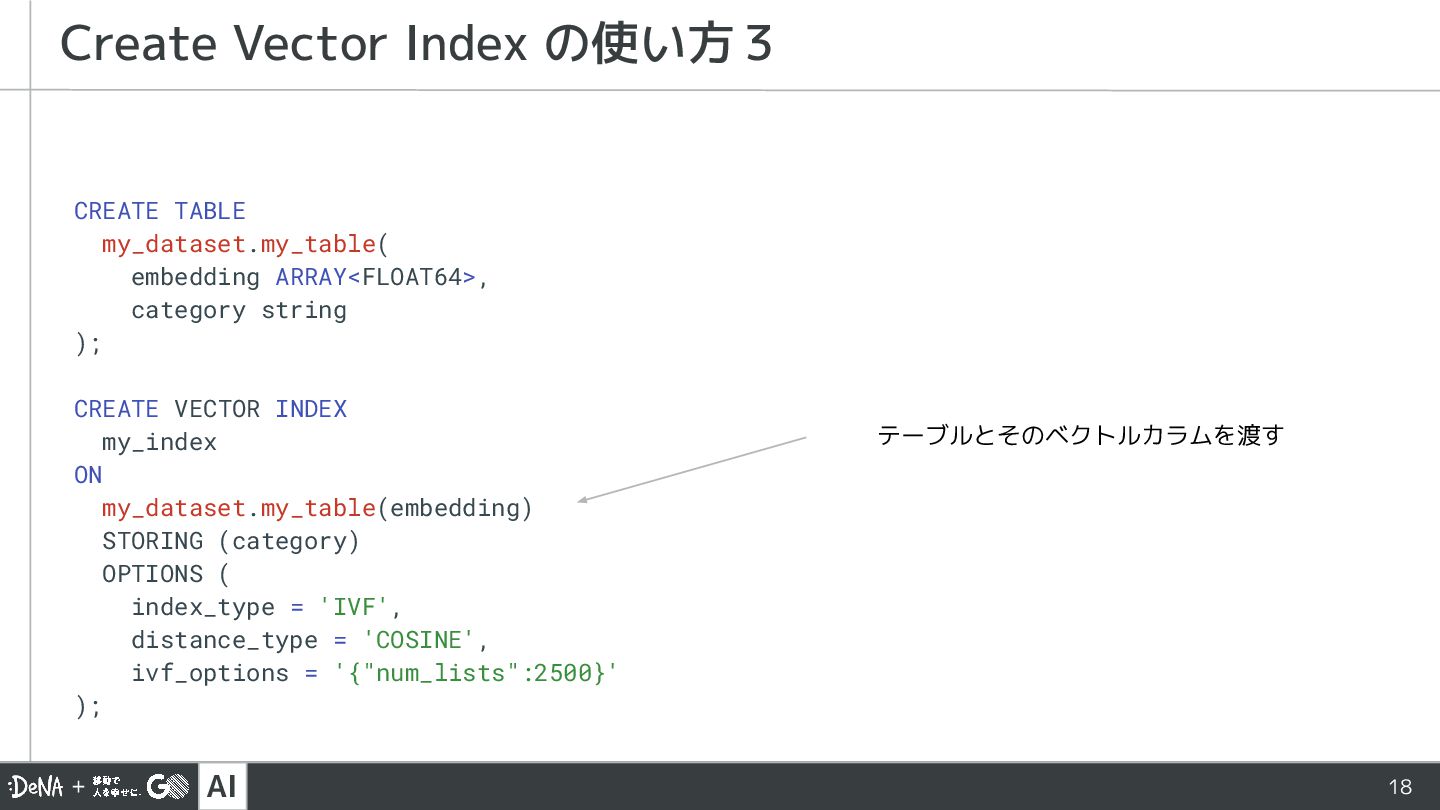{kind=link}
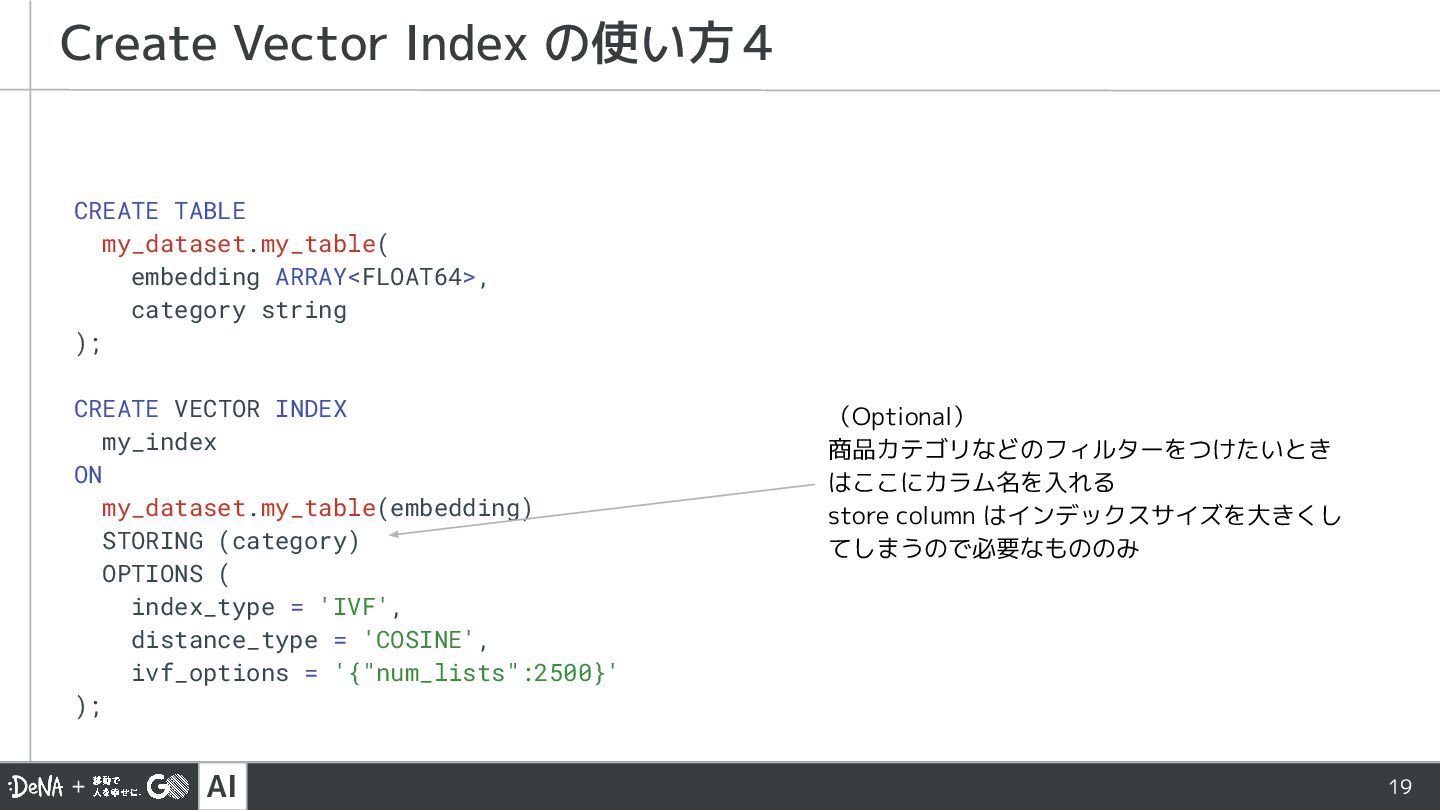{kind=link}
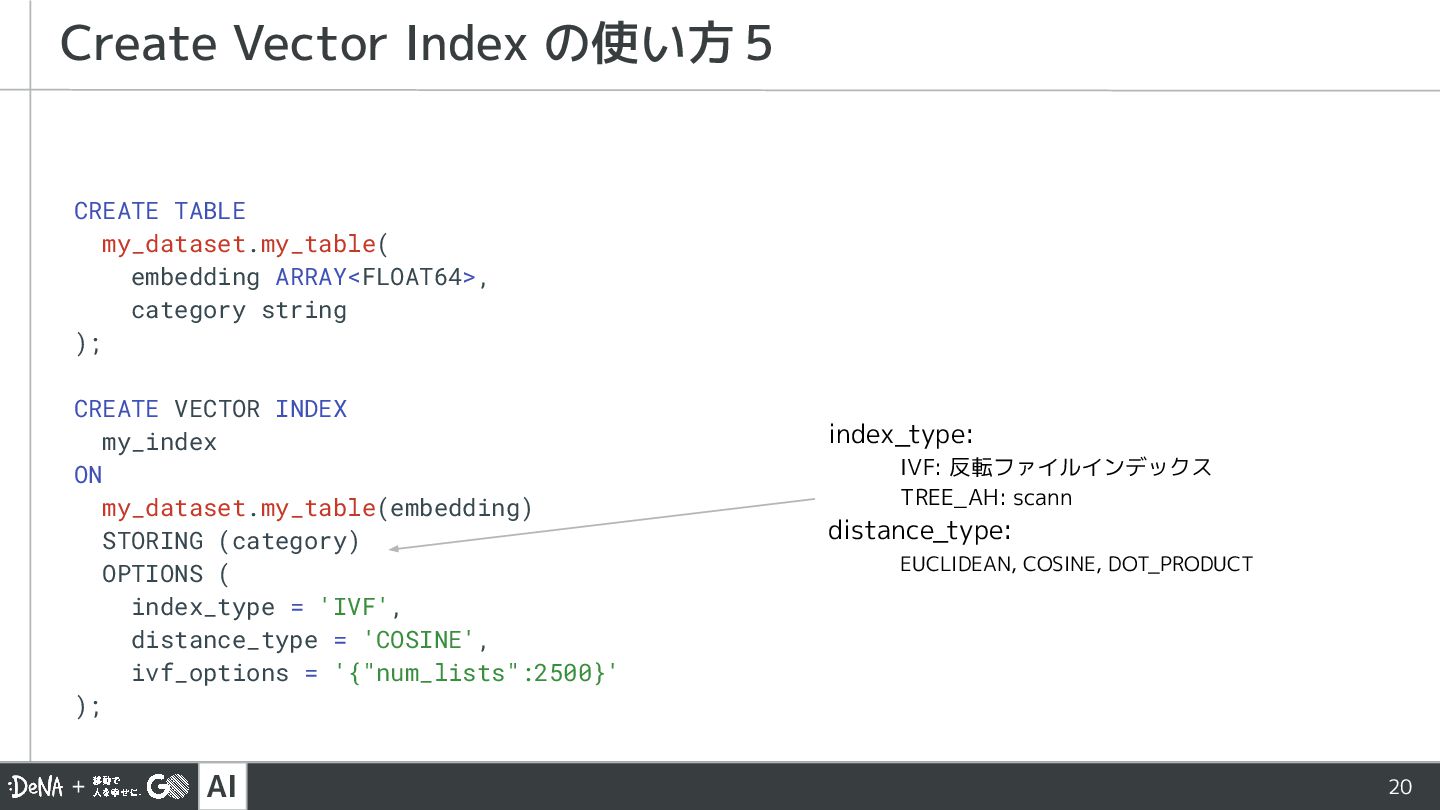{kind=link}
{kind=link}
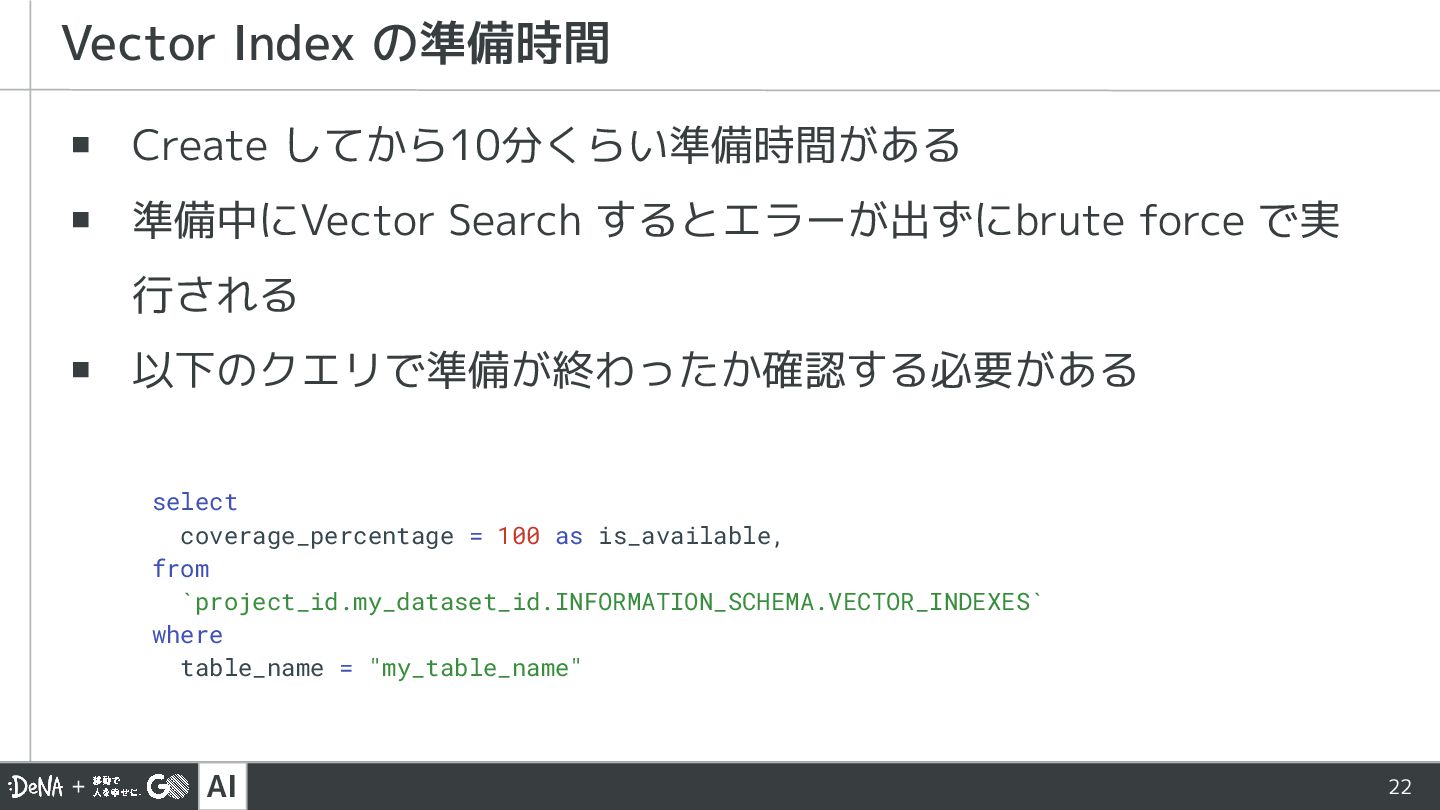{kind=link}
{kind=link}
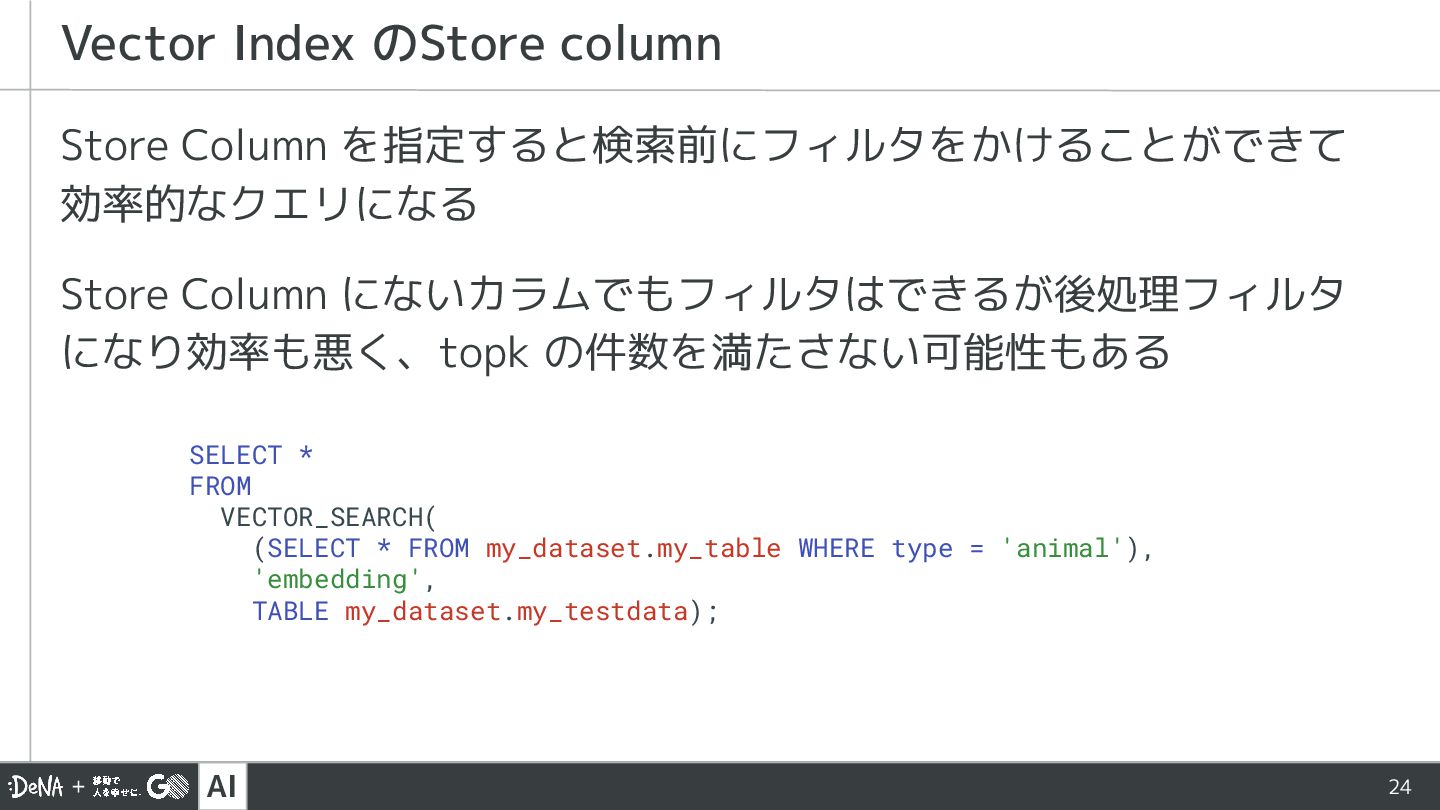{kind=link}
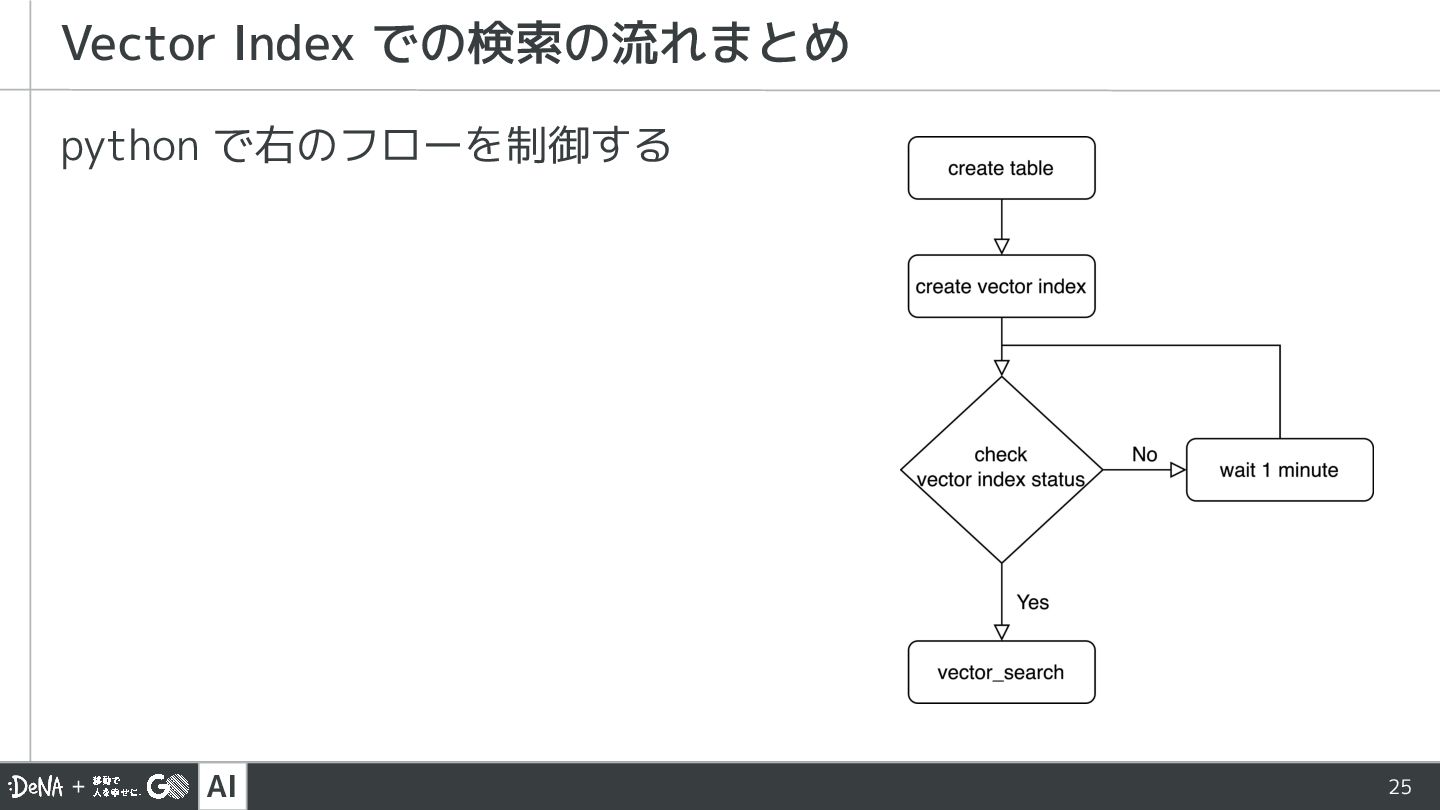{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}