Session Em04. Transforming Domino Applications with LLMs: DominoIQ and Beyond from Engage User Group Conference 2025 in The Hague.
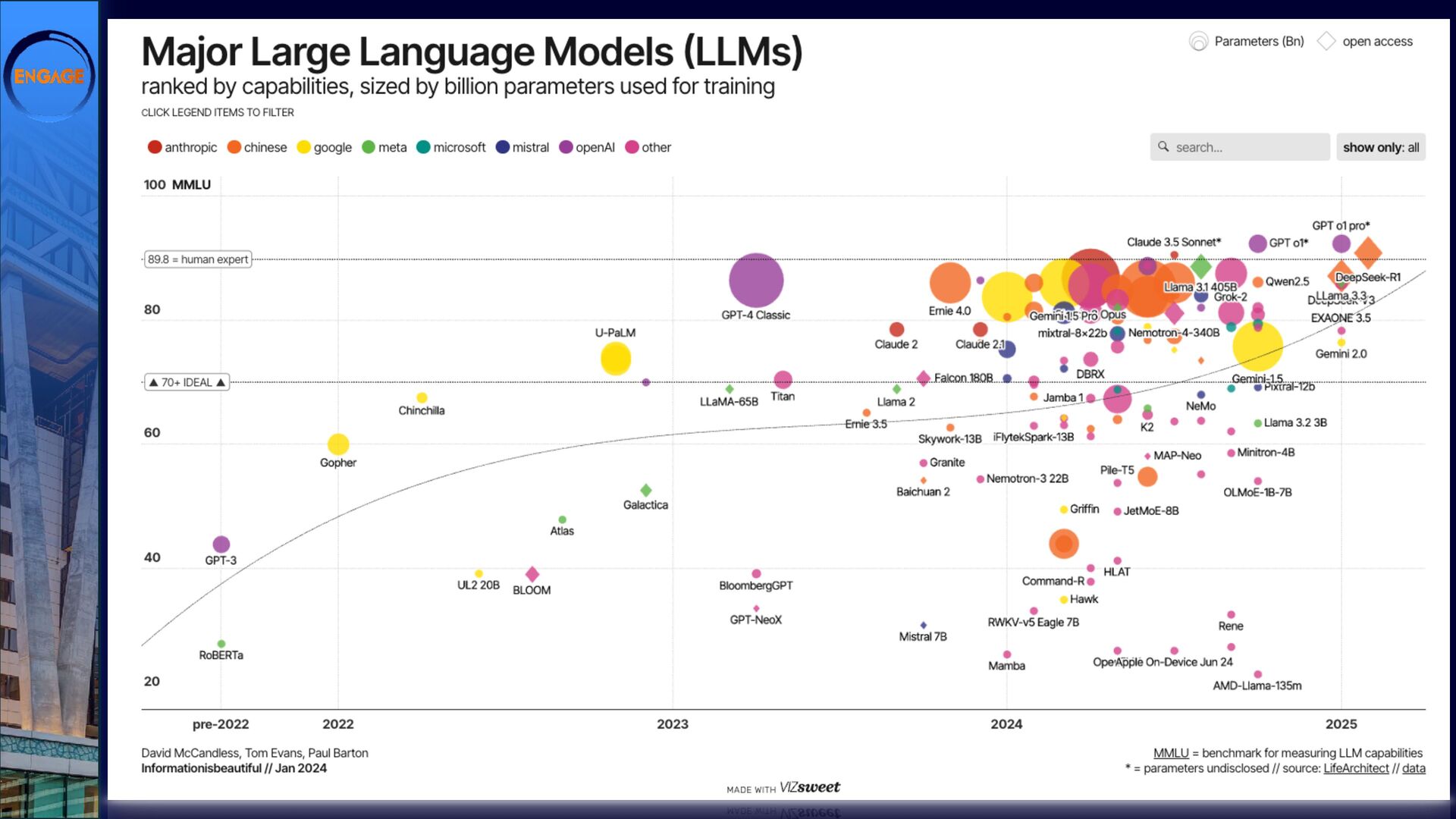
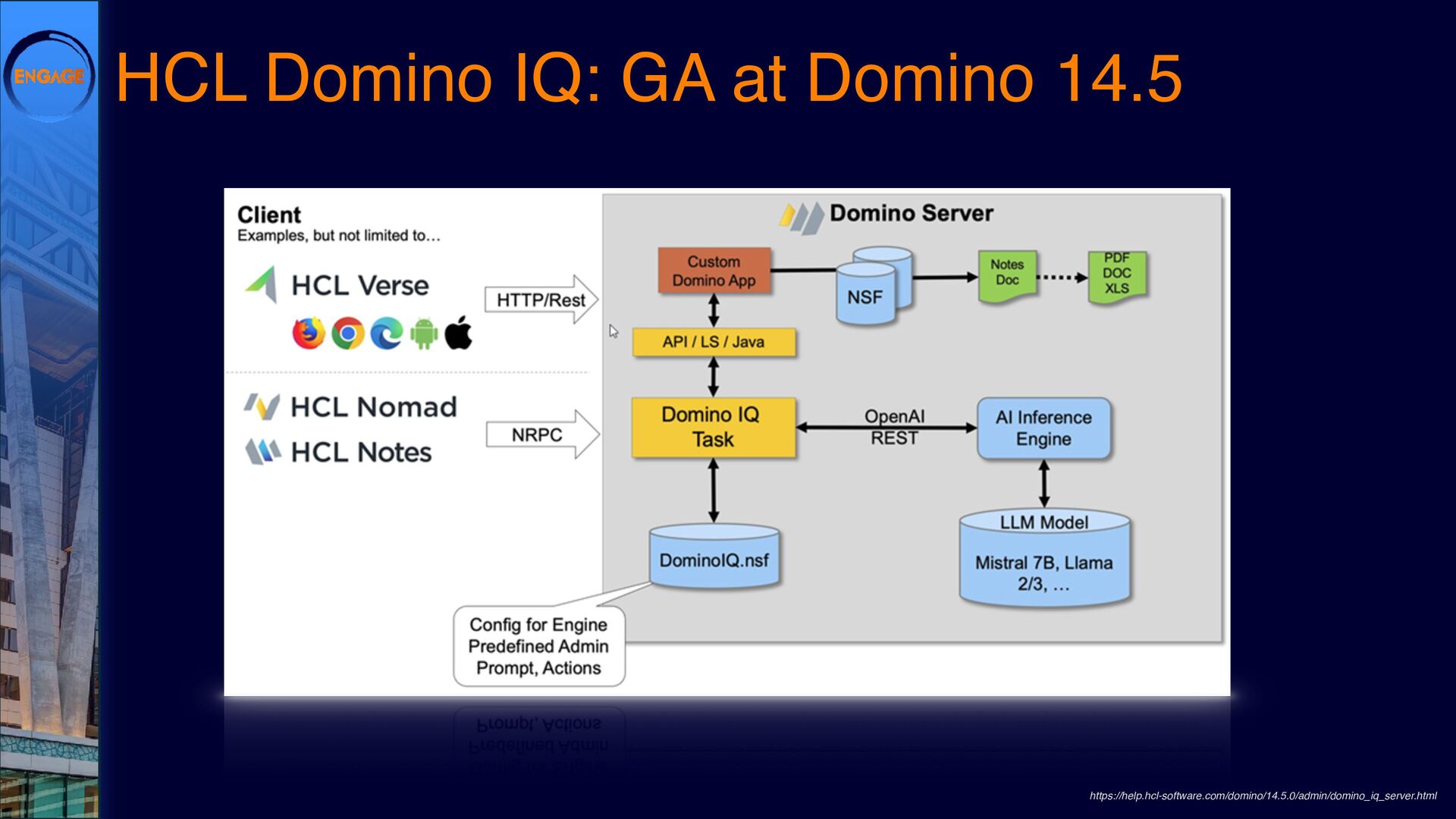
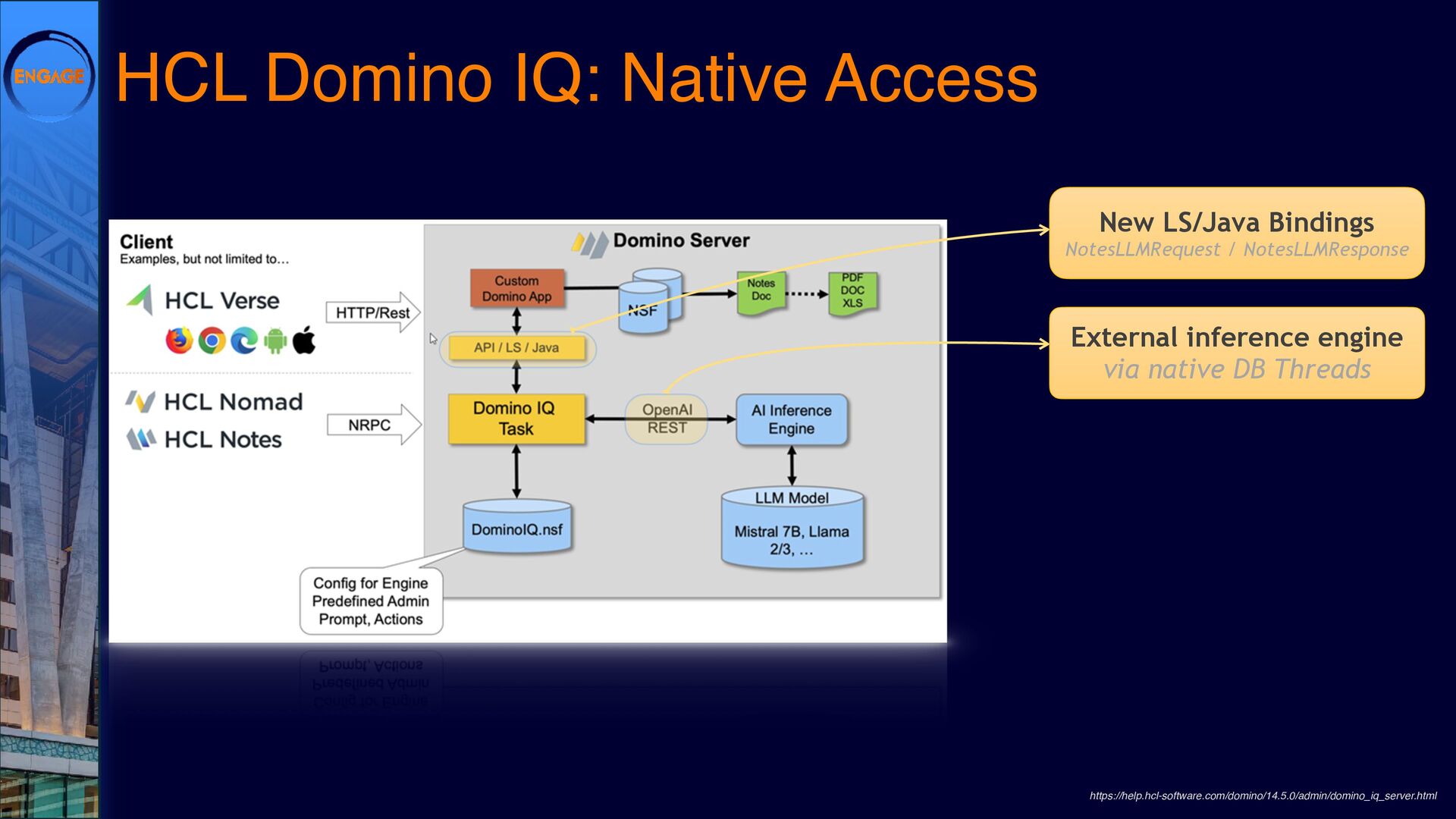
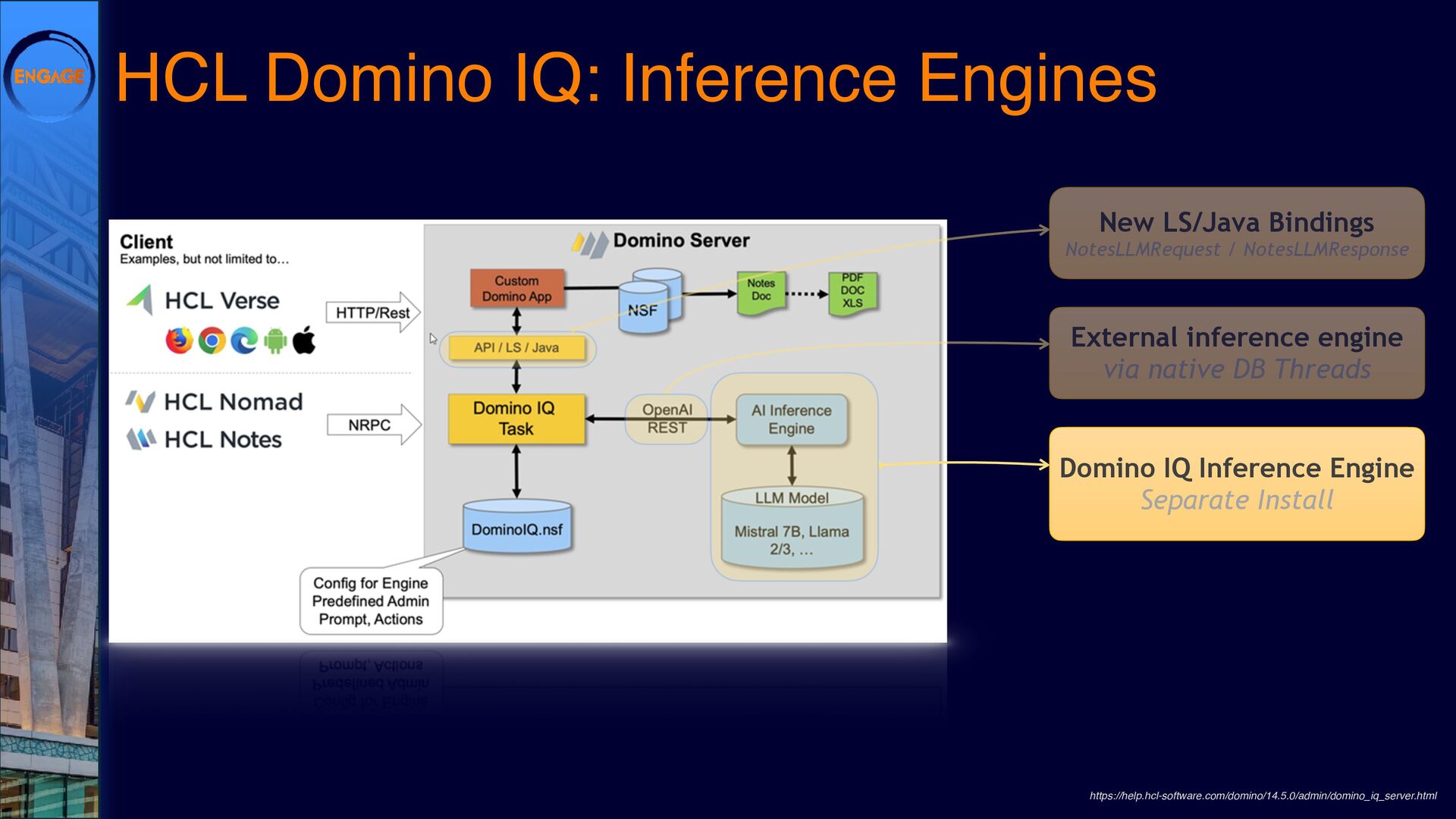
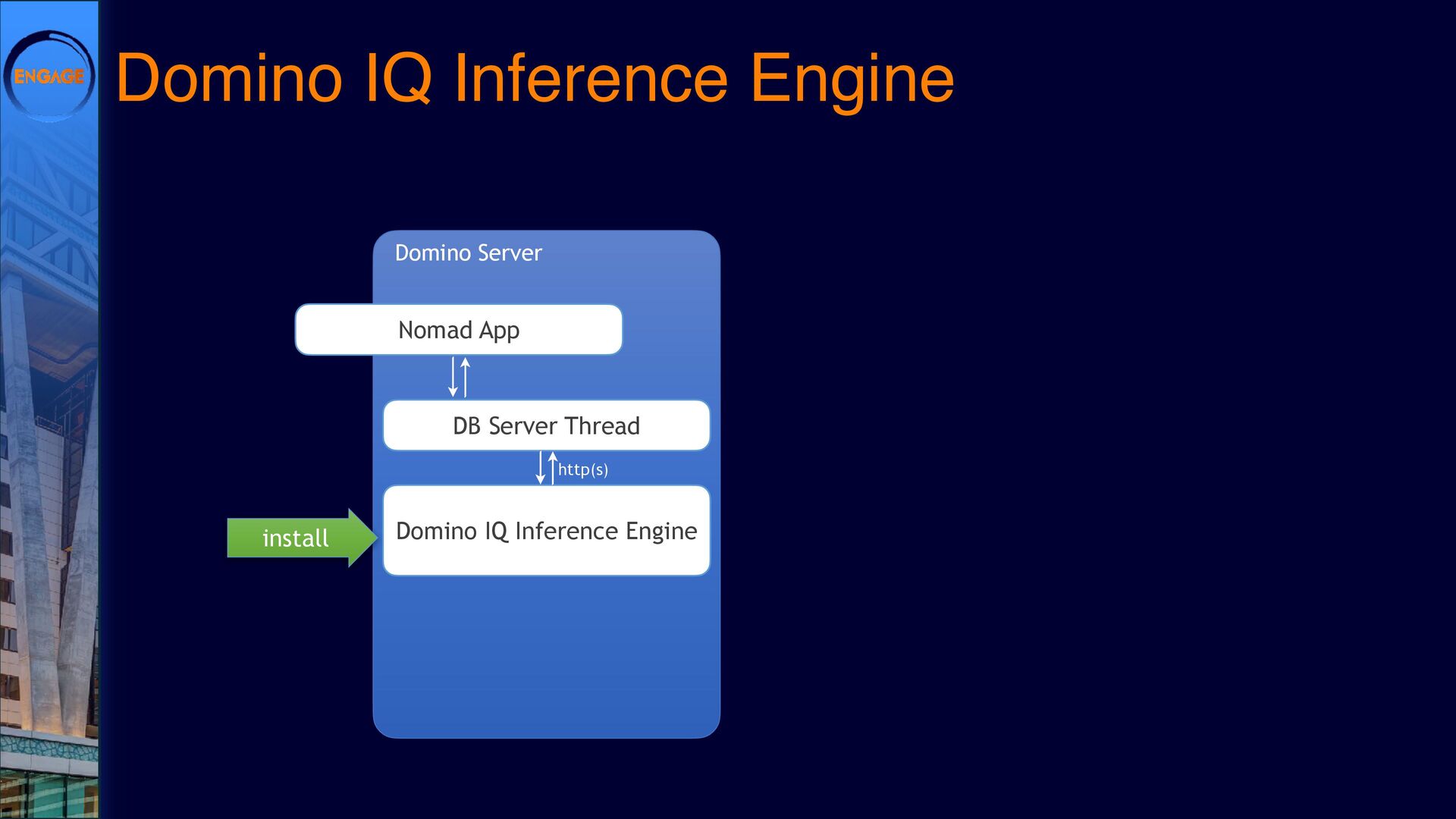
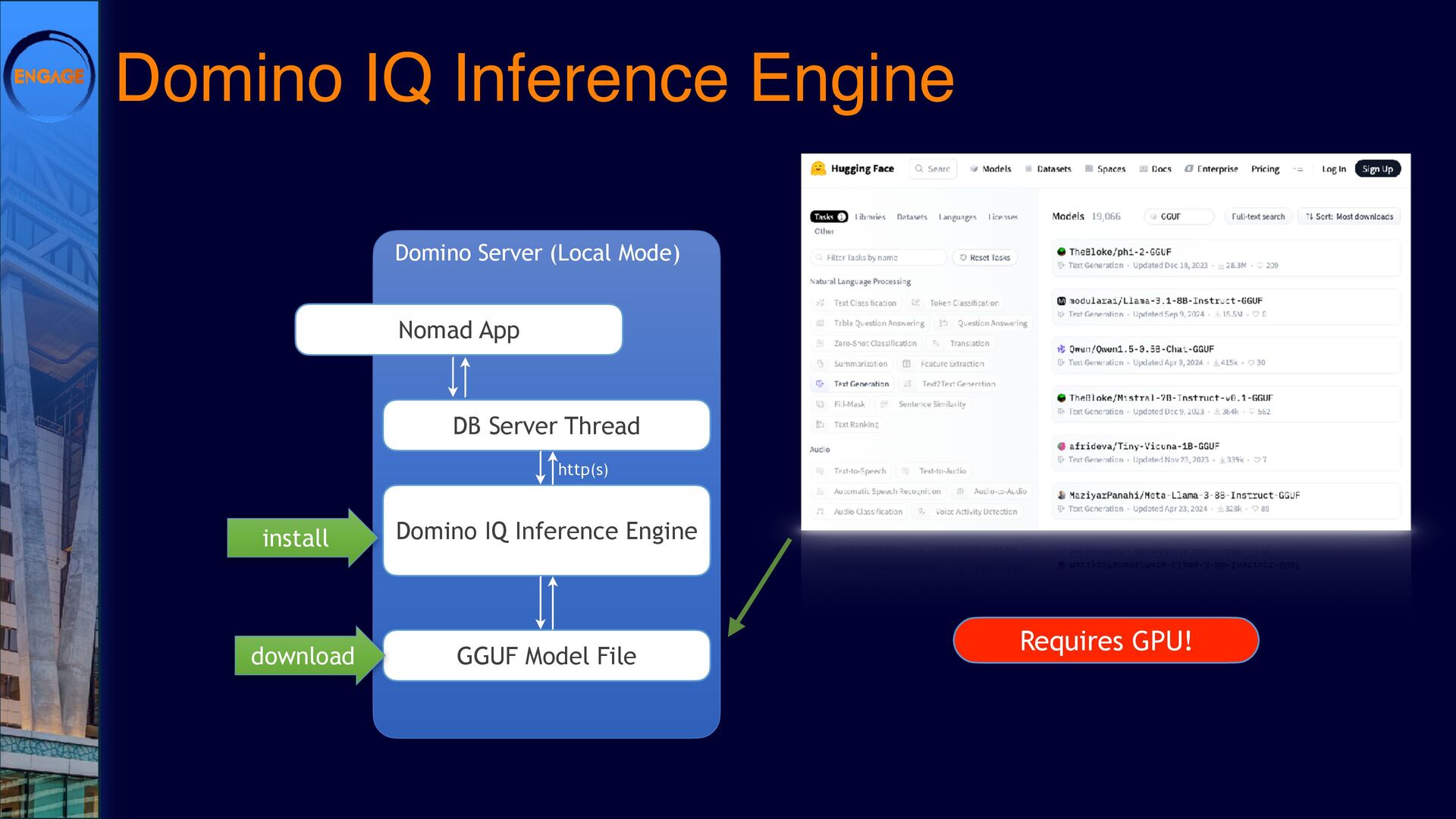
As Large Language Models (LLMs) gain traction, Domino is finding its own path forward. DominoIQ expands Notes development by enabling seamless LLM integration, but it’s just one piece of the puzzle. How do these capabilities translate into practical applications?
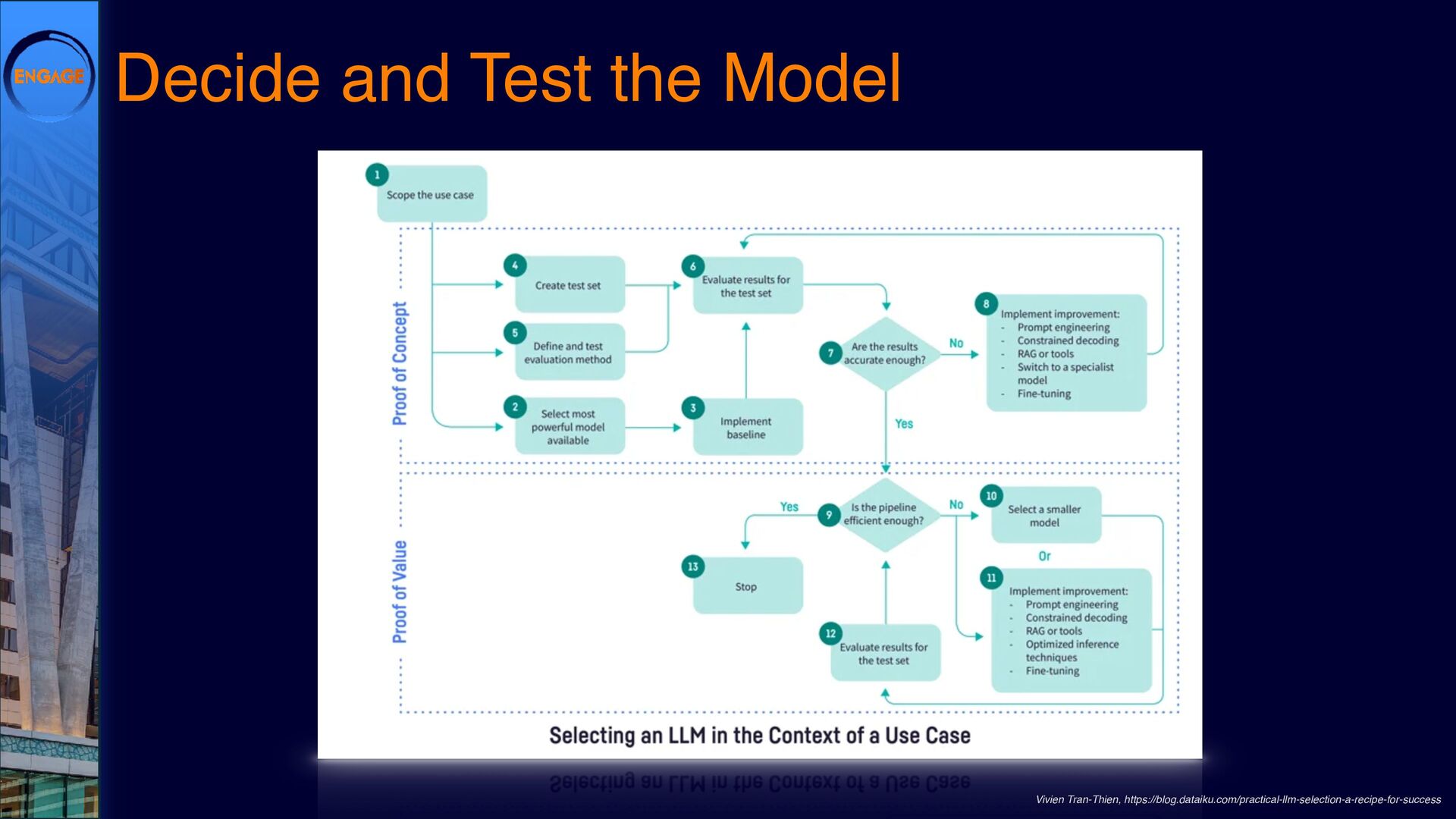
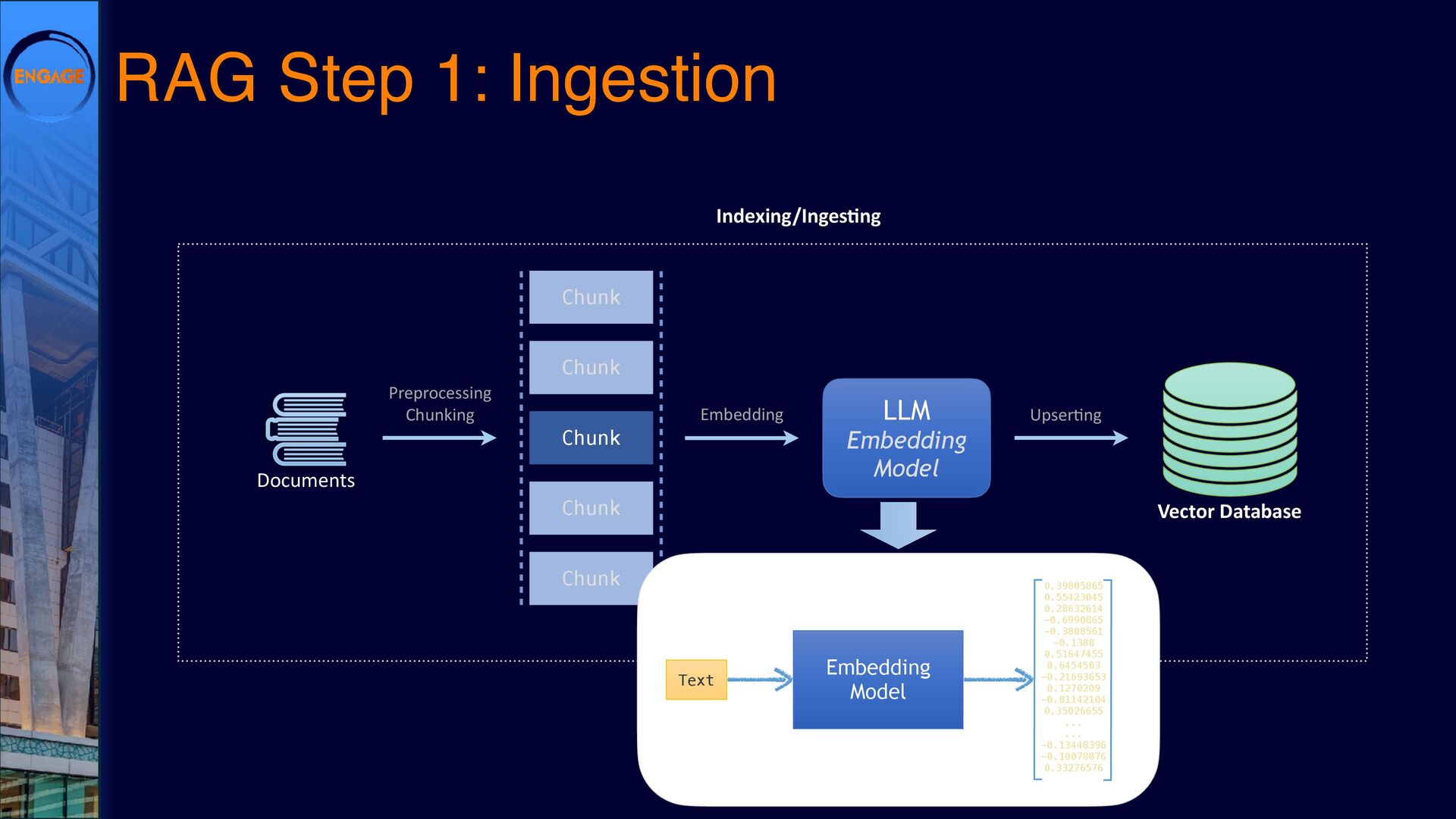
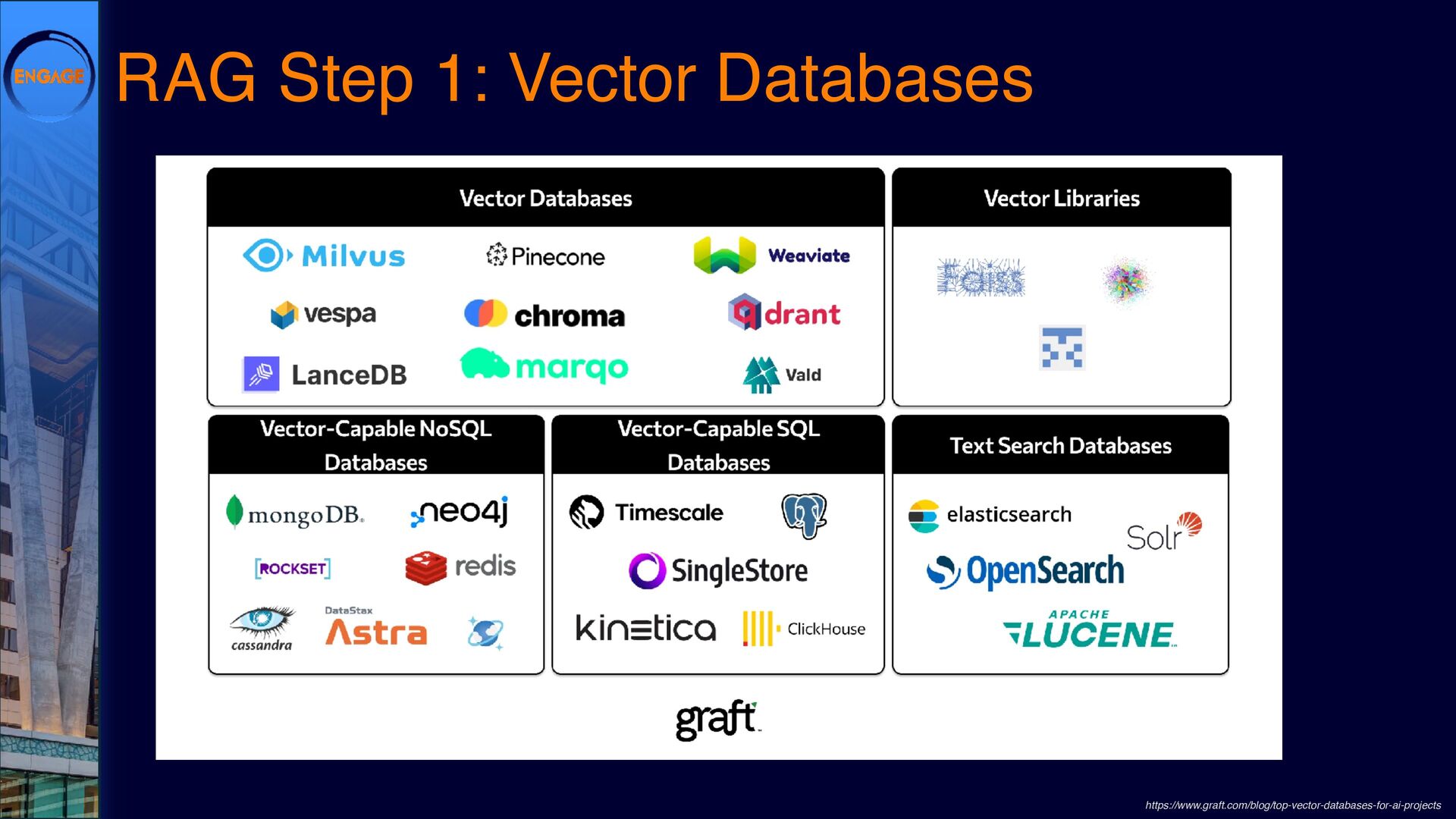
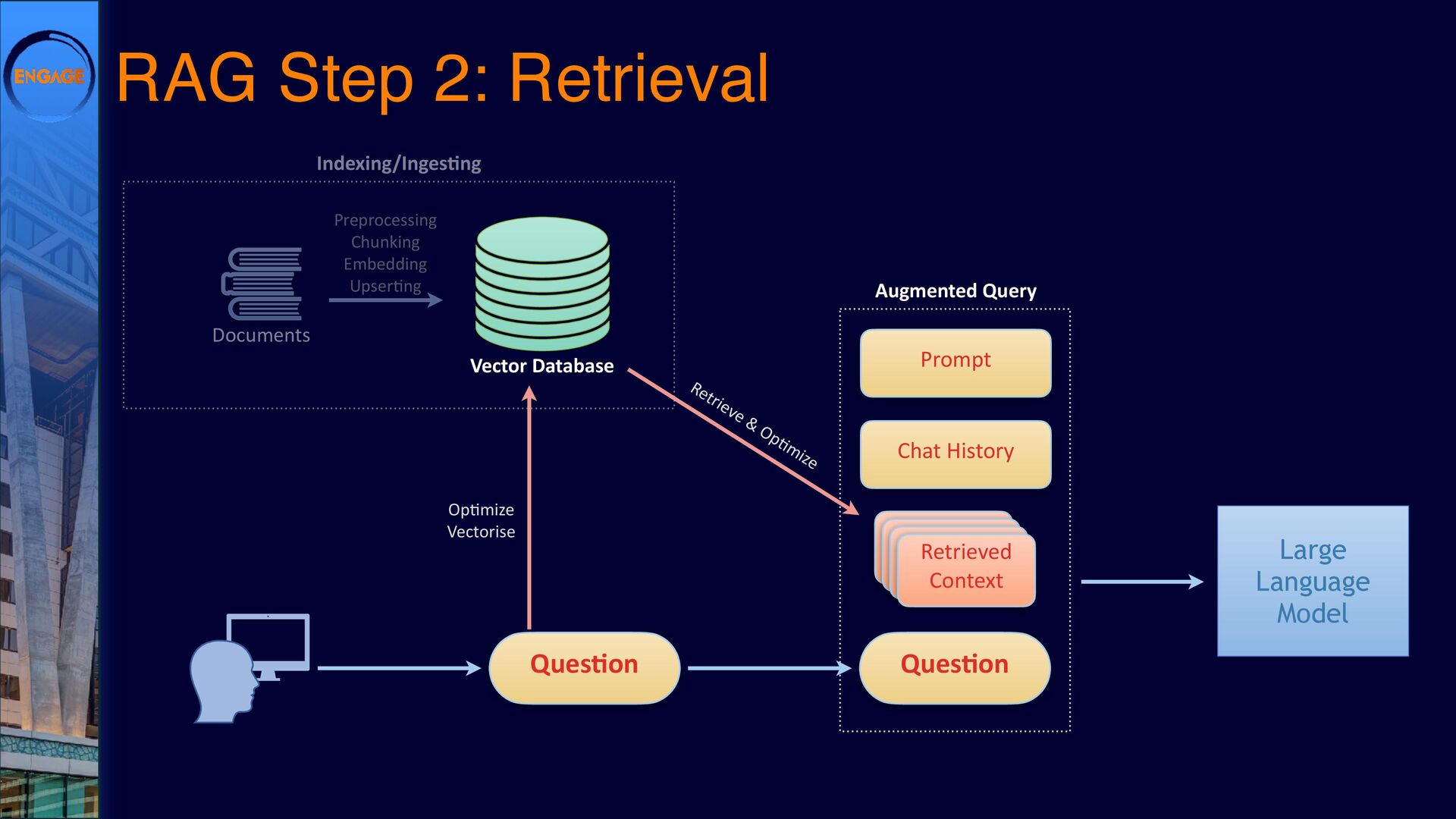
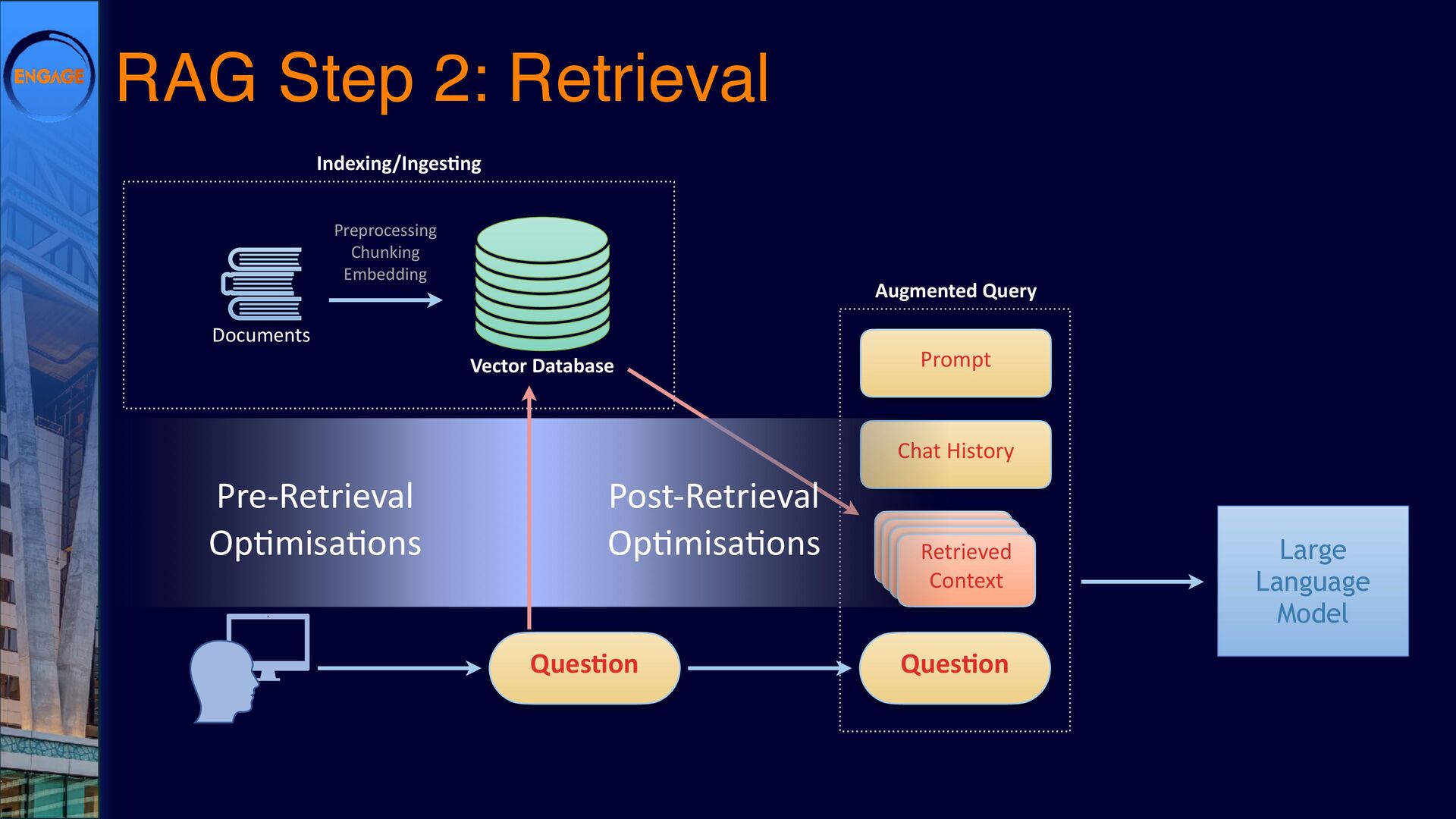
This session will explore various ways to integrate LLMs into Domino, from leveraging DominoIQ in Notes applications to broader implementations using Java, the Domino REST API, and more. We’ll walk through real-world use cases, from enhancing Notes forms and views to designing complex Retrieval-Augmented Generation (RAG) systems, illustrating where LLMs provide tangible value. Join us to dive into practical strategies and best practices, ensuring that LLMs make a meaningful impact on your Domino applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
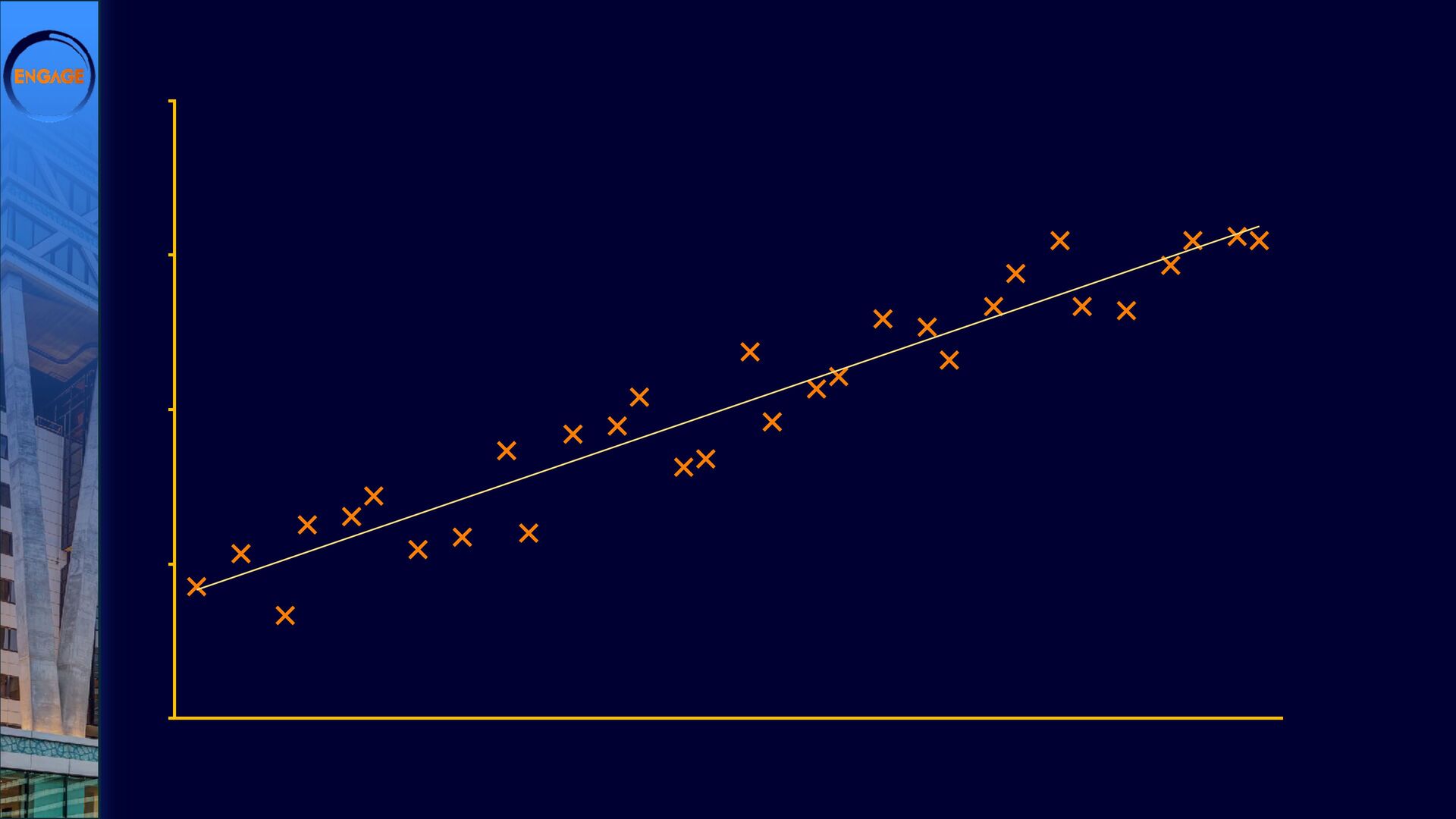{kind=link}
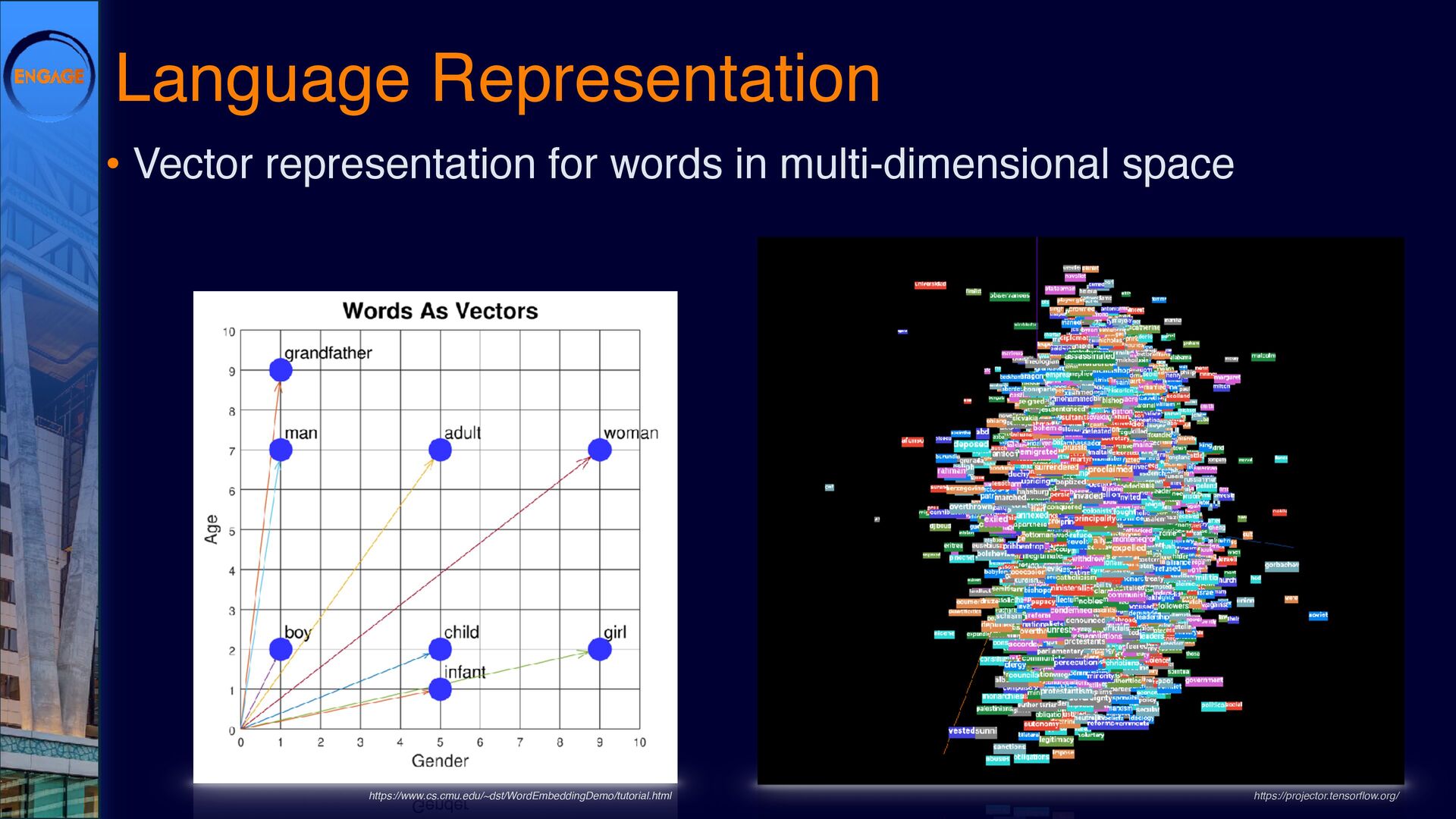{kind=link}
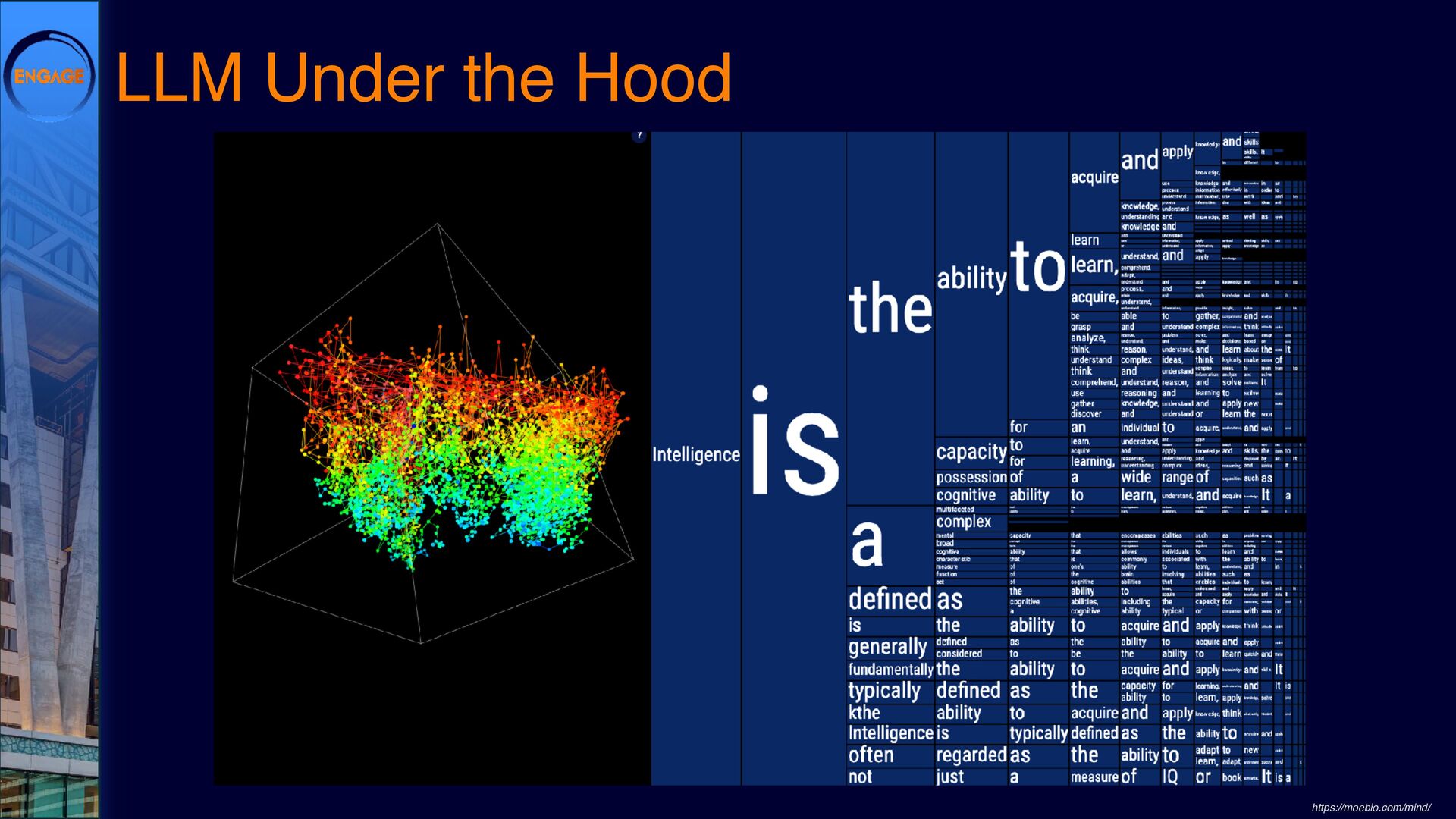{kind=link}
{kind=link}
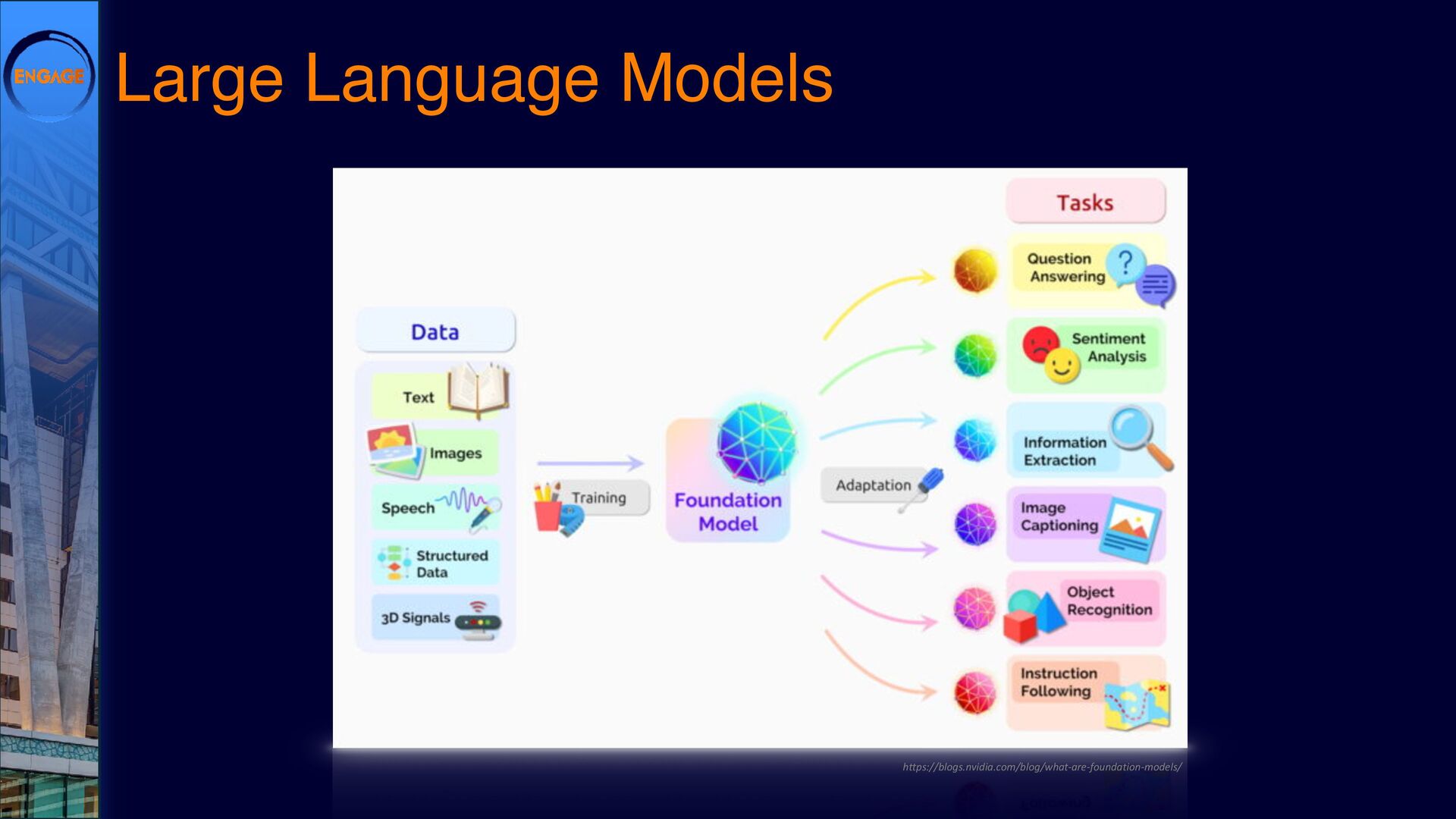{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
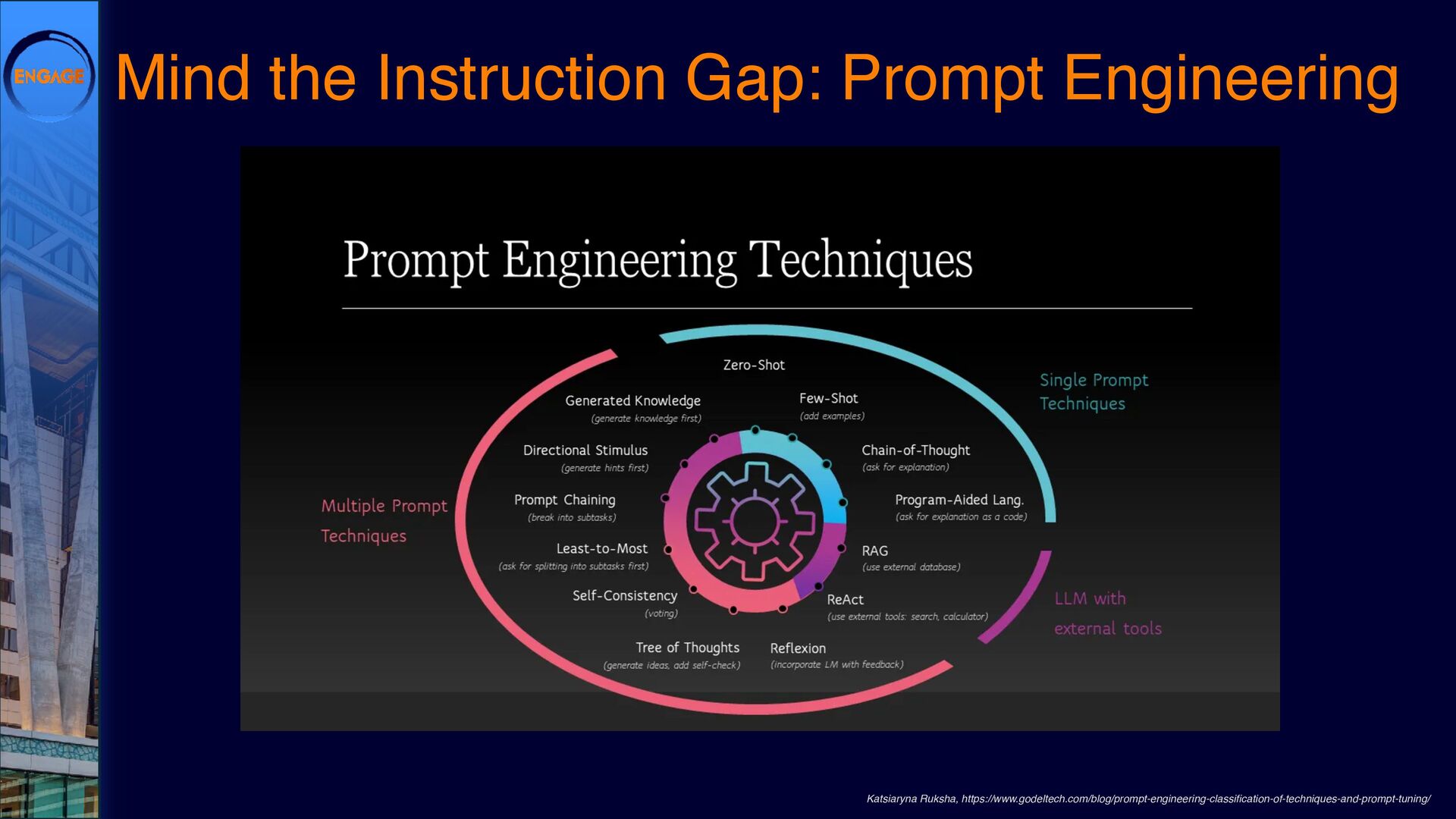{kind=link}
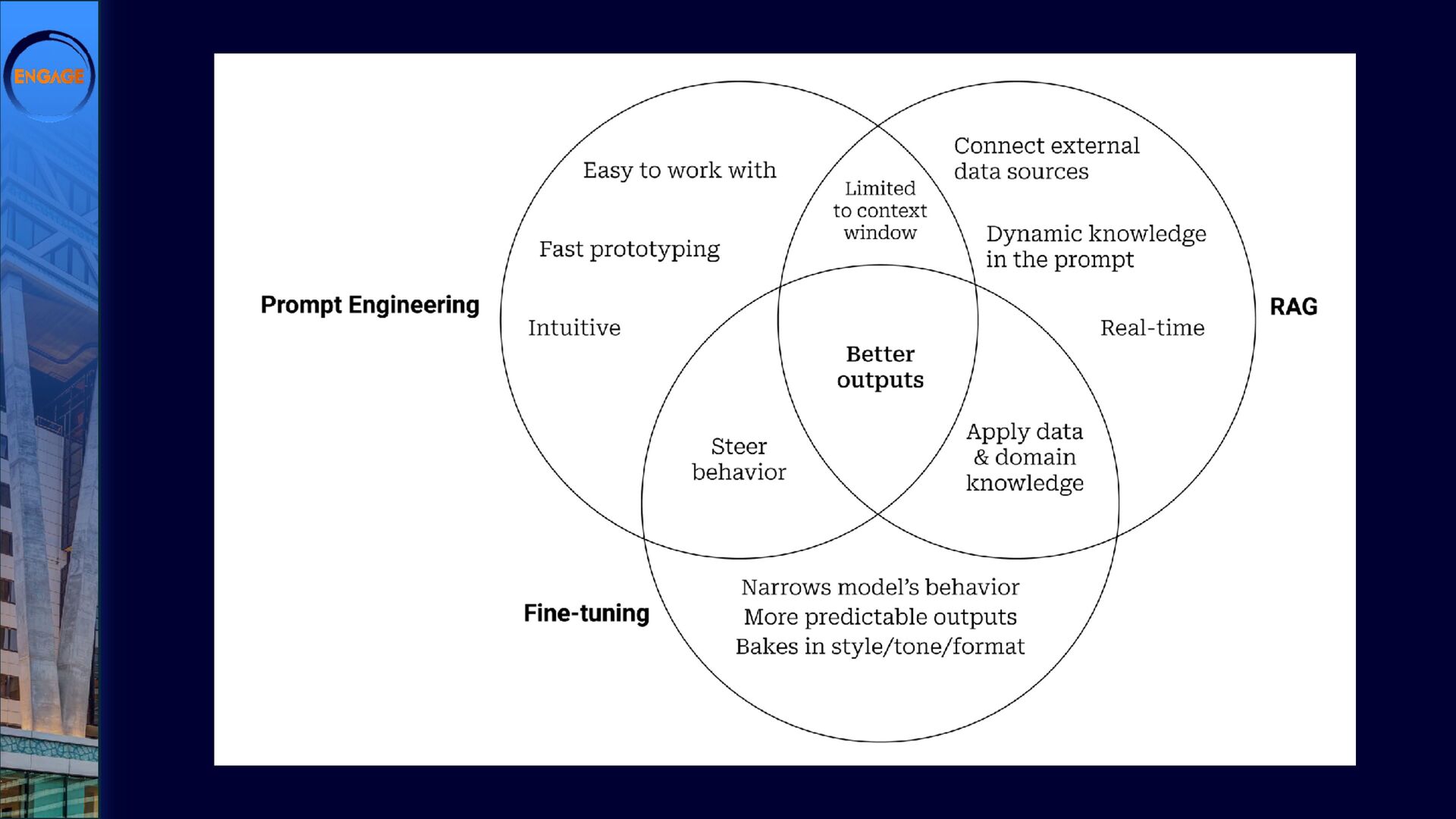{kind=link}
{kind=link}
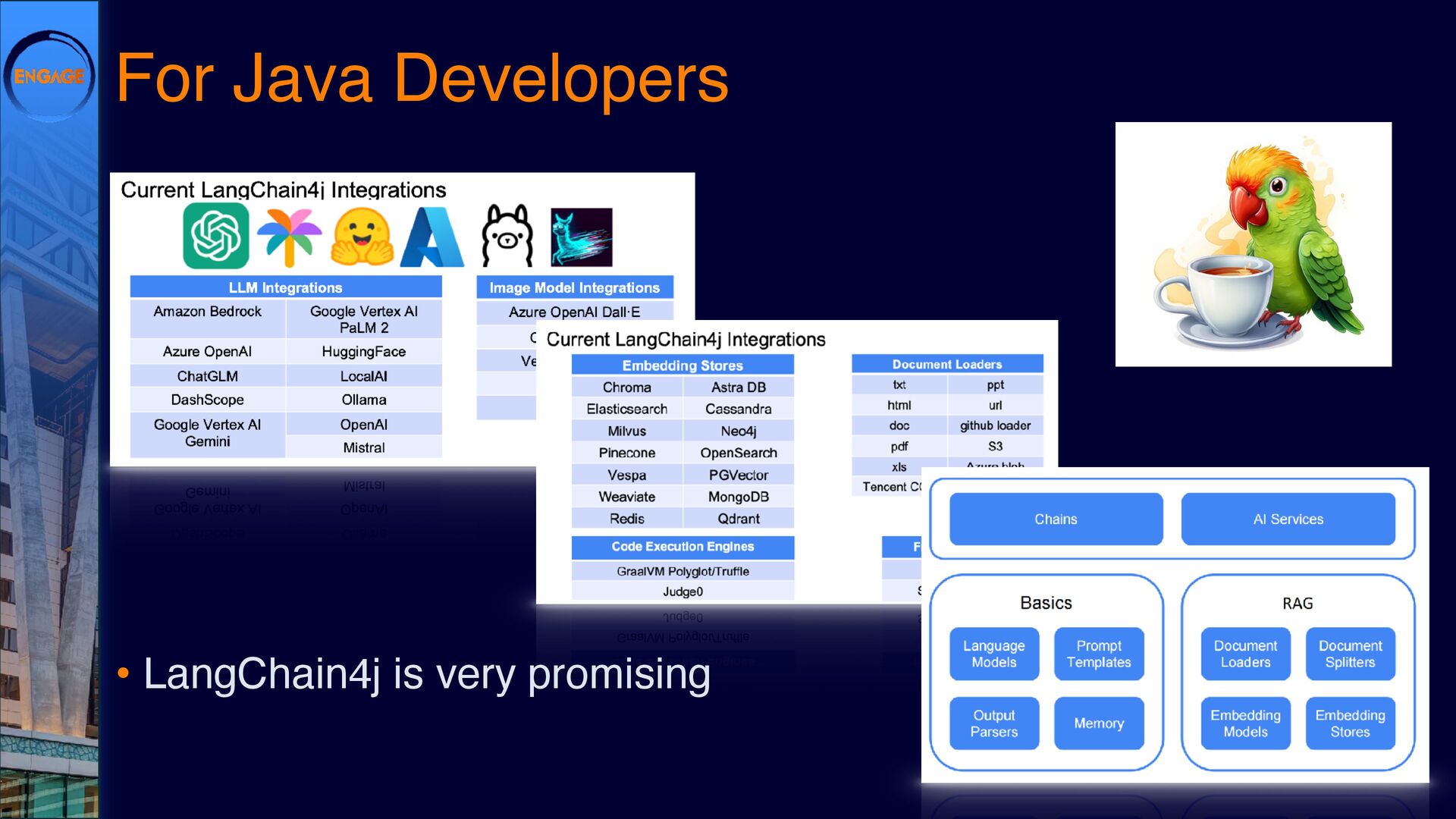{kind=link}
{kind=link}
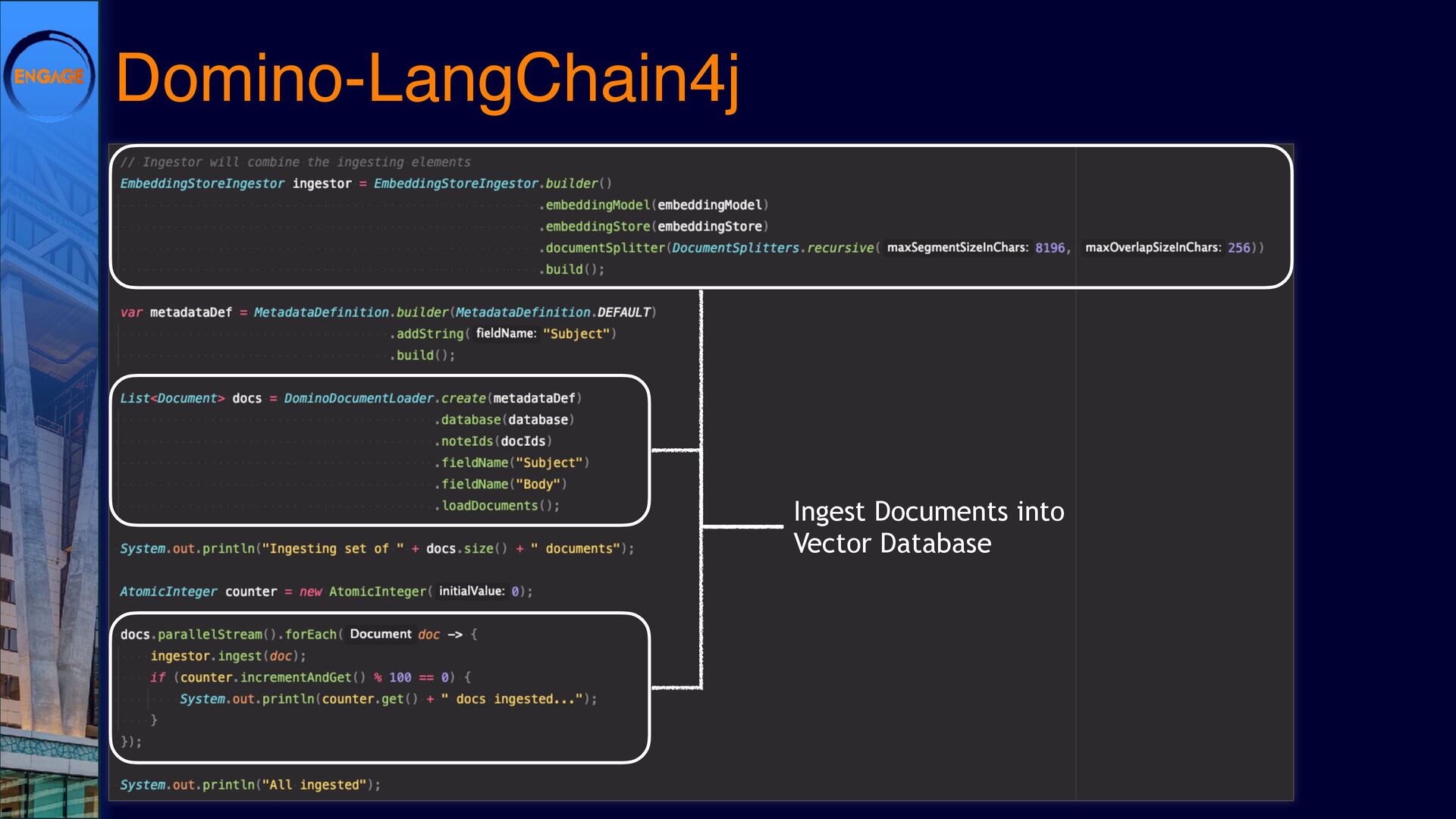{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}