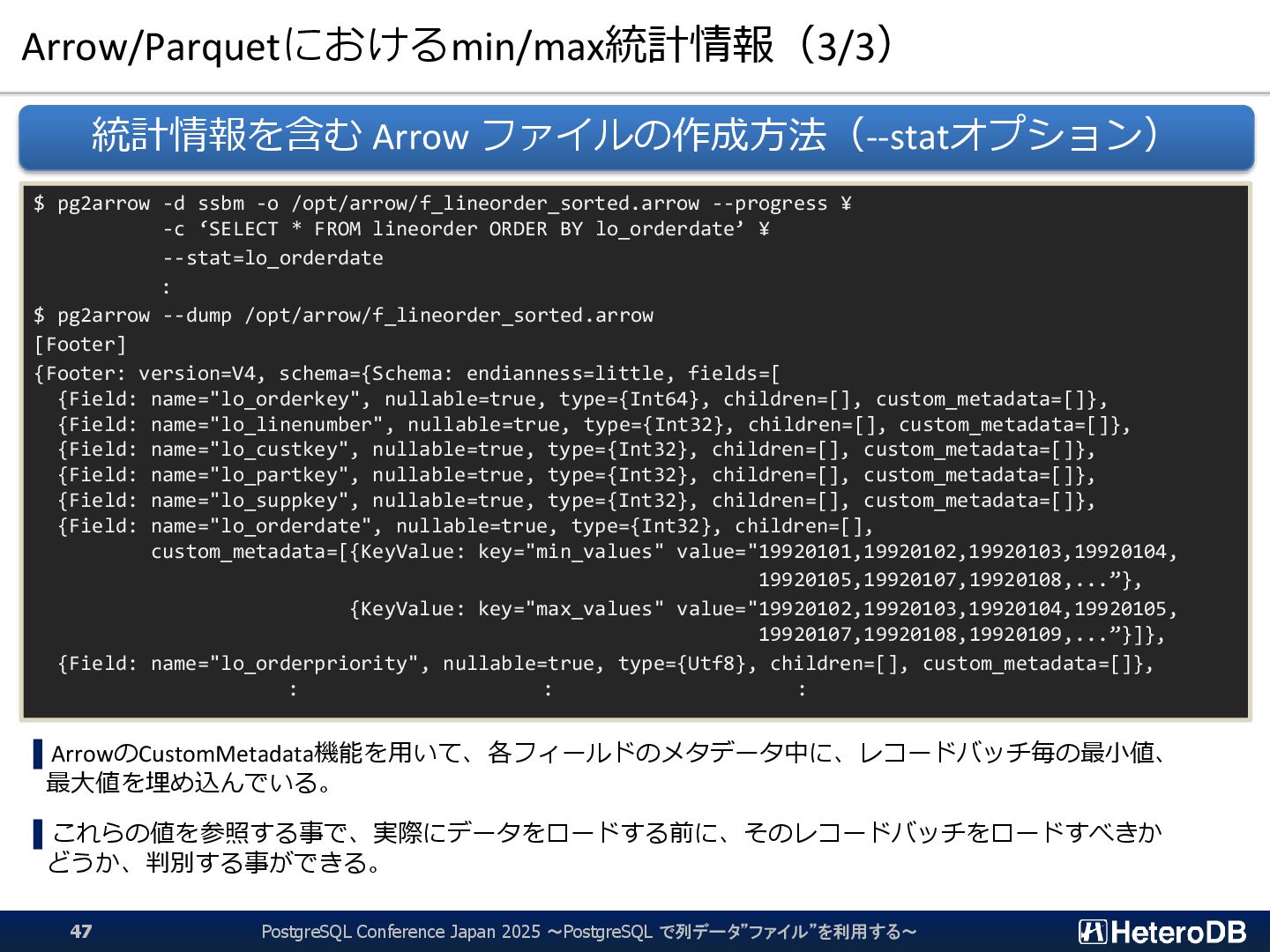
-d ssbm -o /opt/arrow/f_lineorder_sorted.arrow --progress ¥ -c ‘SELECT * FROM lineorder ORDER BY lo_orderdate’ ¥ --stat=lo_orderdate : $ pg2arrow --dump /opt/arrow/f_lineorder_sorted.arrow [Footer] {Footer: version=V4, schema={Schema: endianness=little, fields=[ {Field: name="lo_orderkey", nullable=true, type={Int64}, children=[], custom_metadata=[]}, {Field: name="lo_linenumber", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="lo_custkey", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="lo_partkey", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="lo_suppkey", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="lo_orderdate", nullable=true, type={Int32}, children=[], custom_metadata=[{KeyValue: key="min_values" value="19920101,19920102,19920103,19920104, 19920105,19920107,19920108,...”}, {KeyValue: key="max_values" value="19920102,19920103,19920104,19920105, 19920107,19920108,19920109,...”}]}, {Field: name="lo_orderpriority", nullable=true, type={Utf8}, children=[], custom_metadata=[]}, : : : PostgreSQL Conference Japan 2025 ~PostgreSQL で列データ”ファイル”を利用する~ 47
{kind=link}
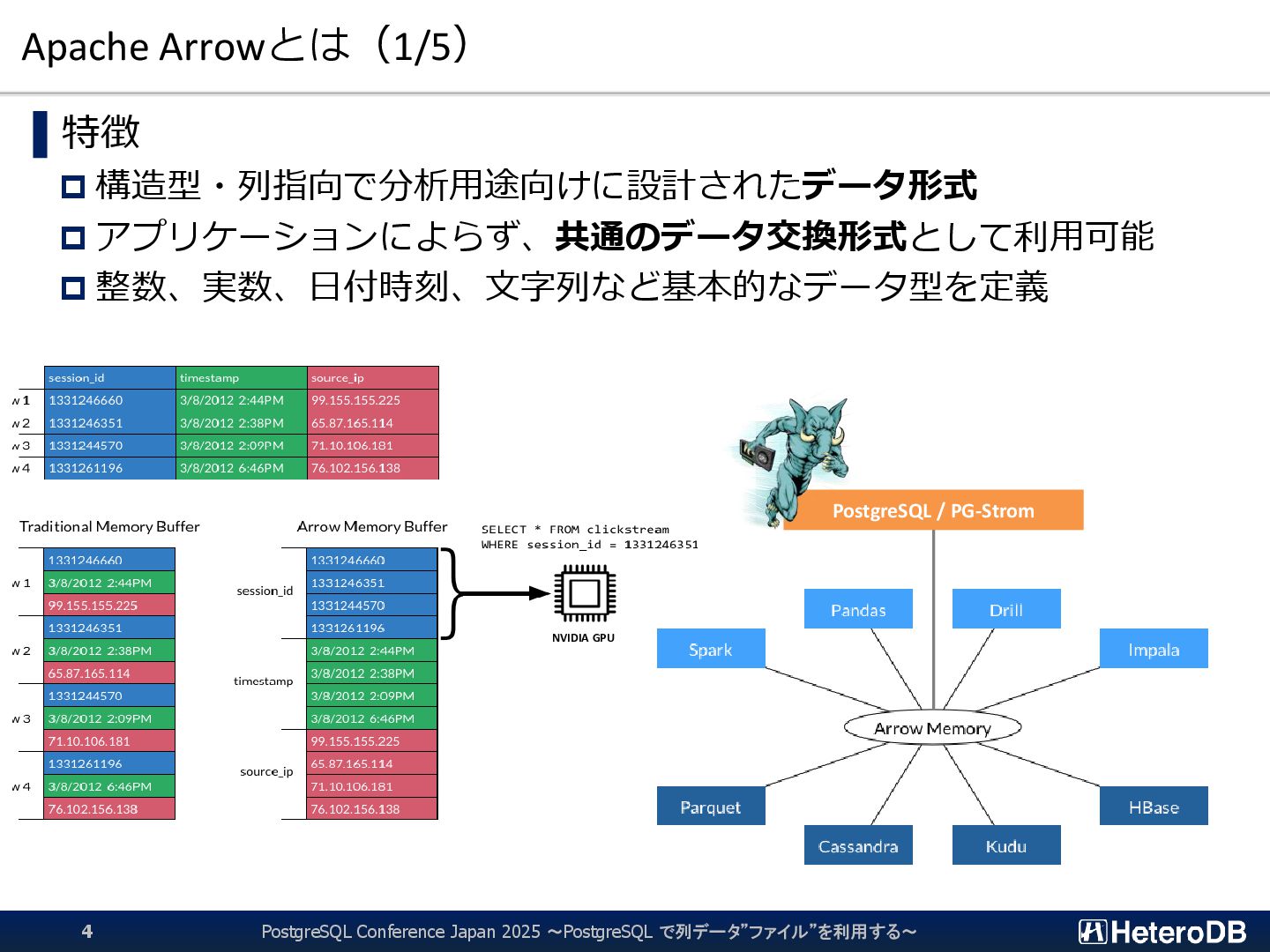
{kind=link}
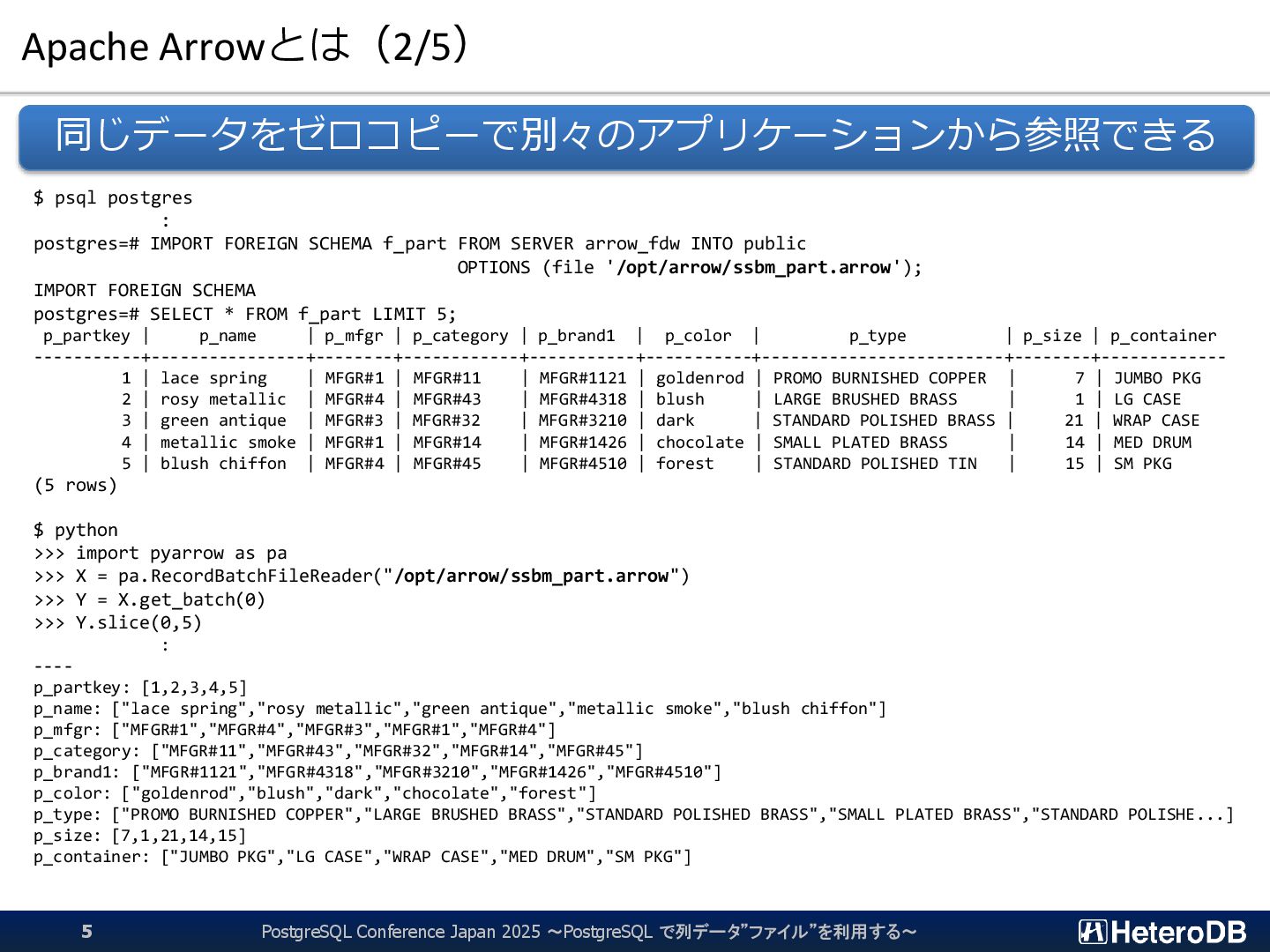
{kind=link}
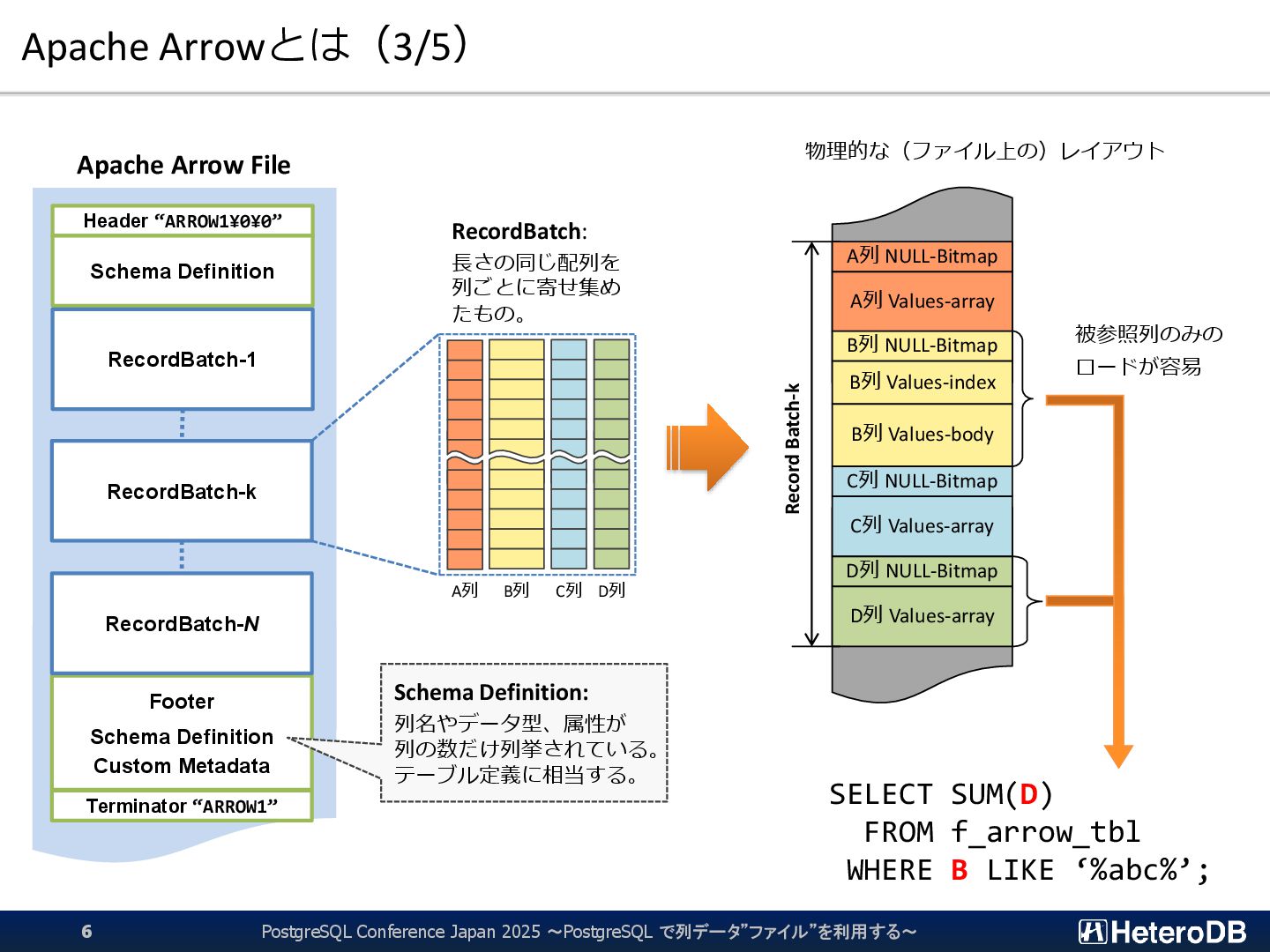
{kind=link}
{kind=link}
{kind=link}
![Apache Arrowとは(4/5) 補足:可変長データについて B[0] = ‘dog’ B[1] = ‘panda’ B[2]](https://files.speakerdeck.com/presentations/8b22c88dd71f430d820523944a9944a0/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
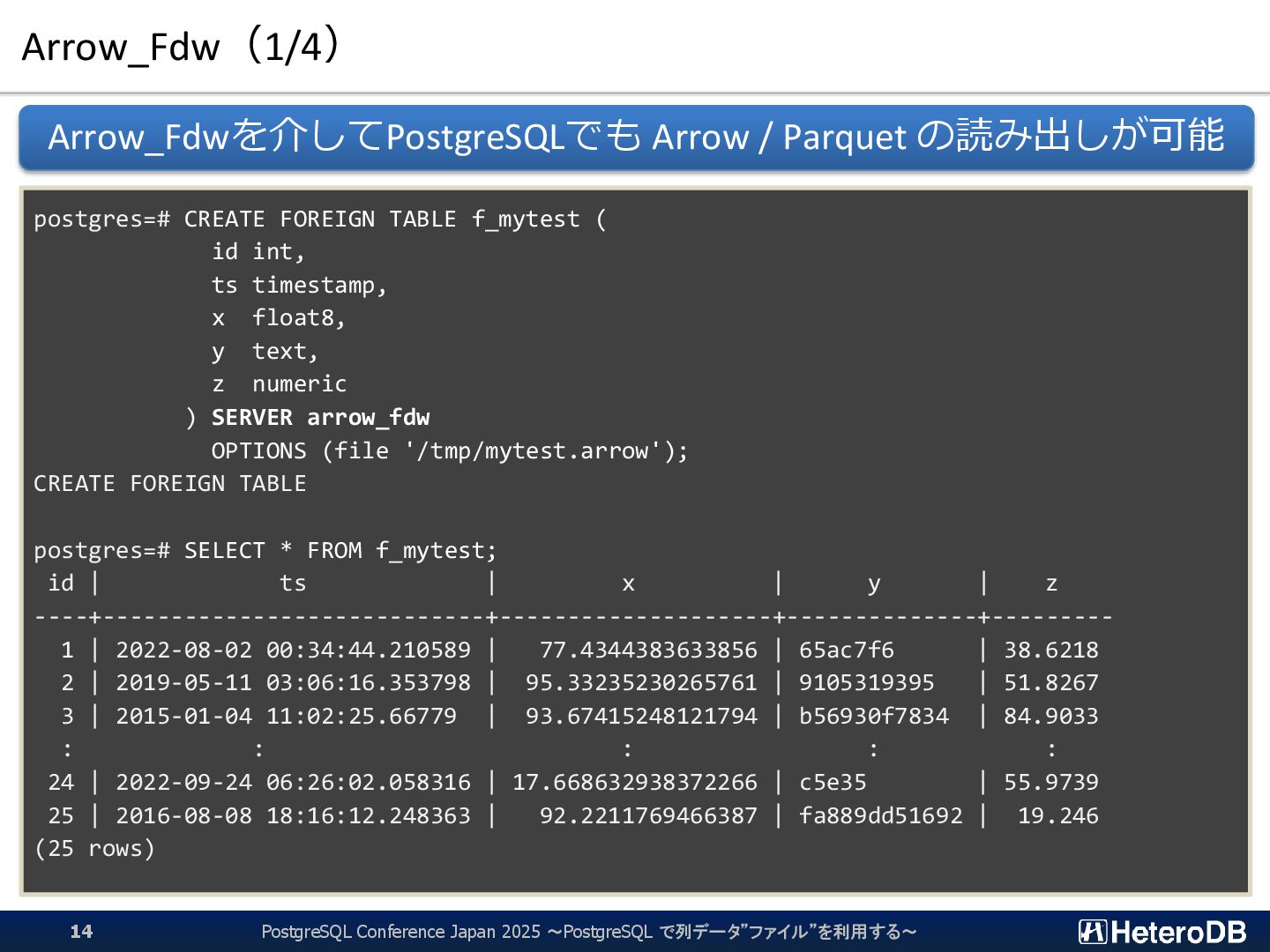{kind=link}
{kind=link}
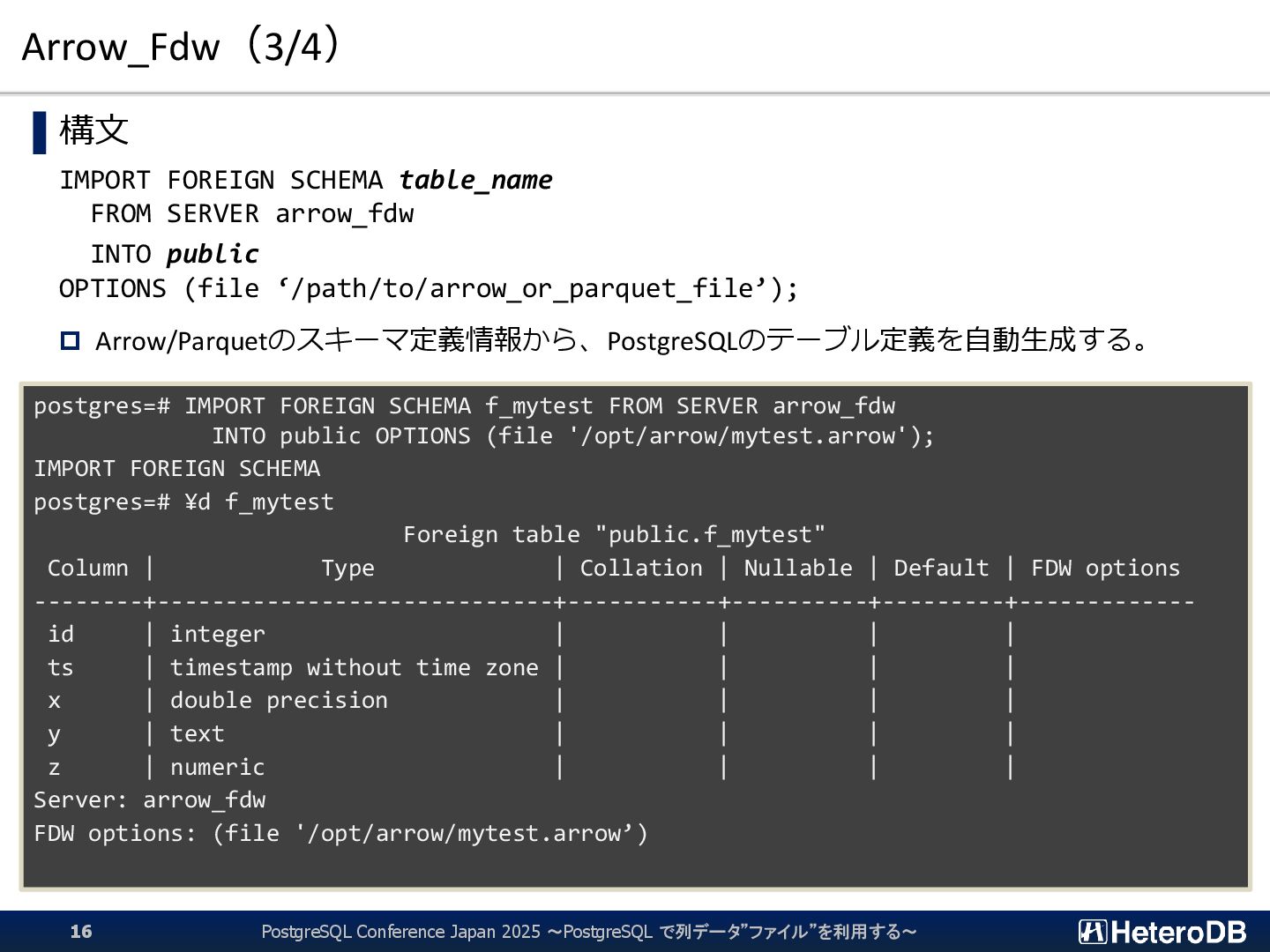{kind=link}
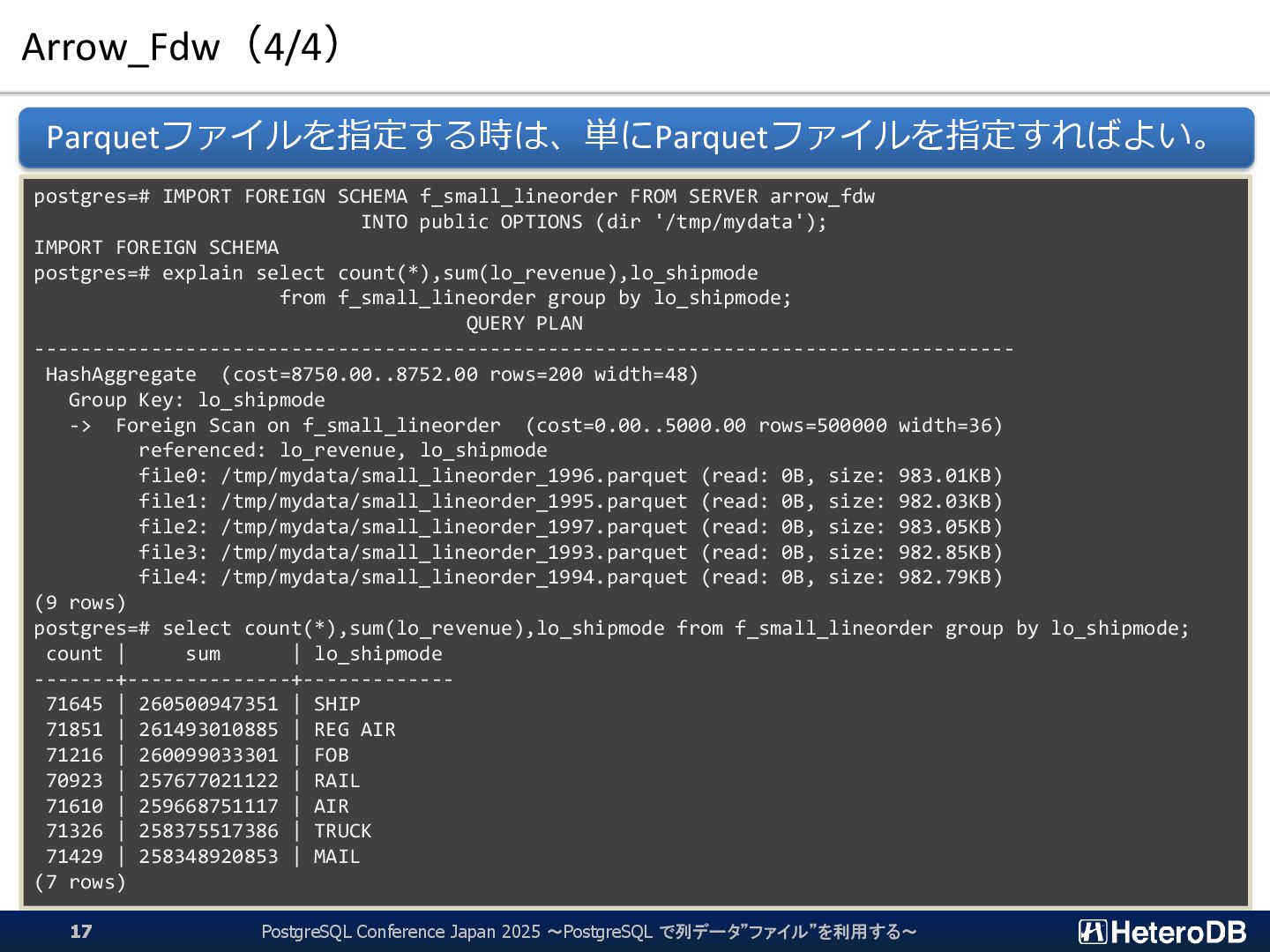{kind=link}
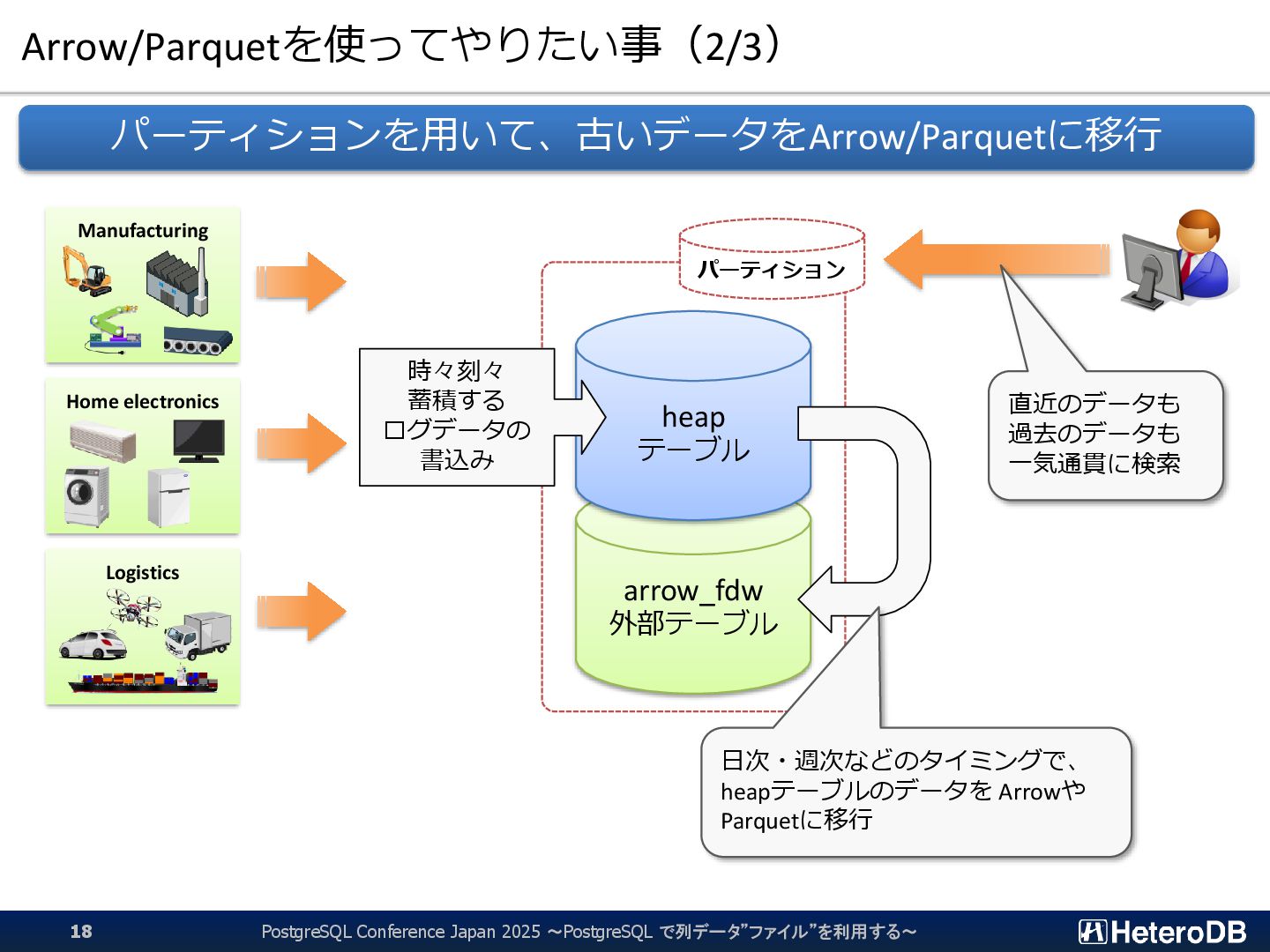{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
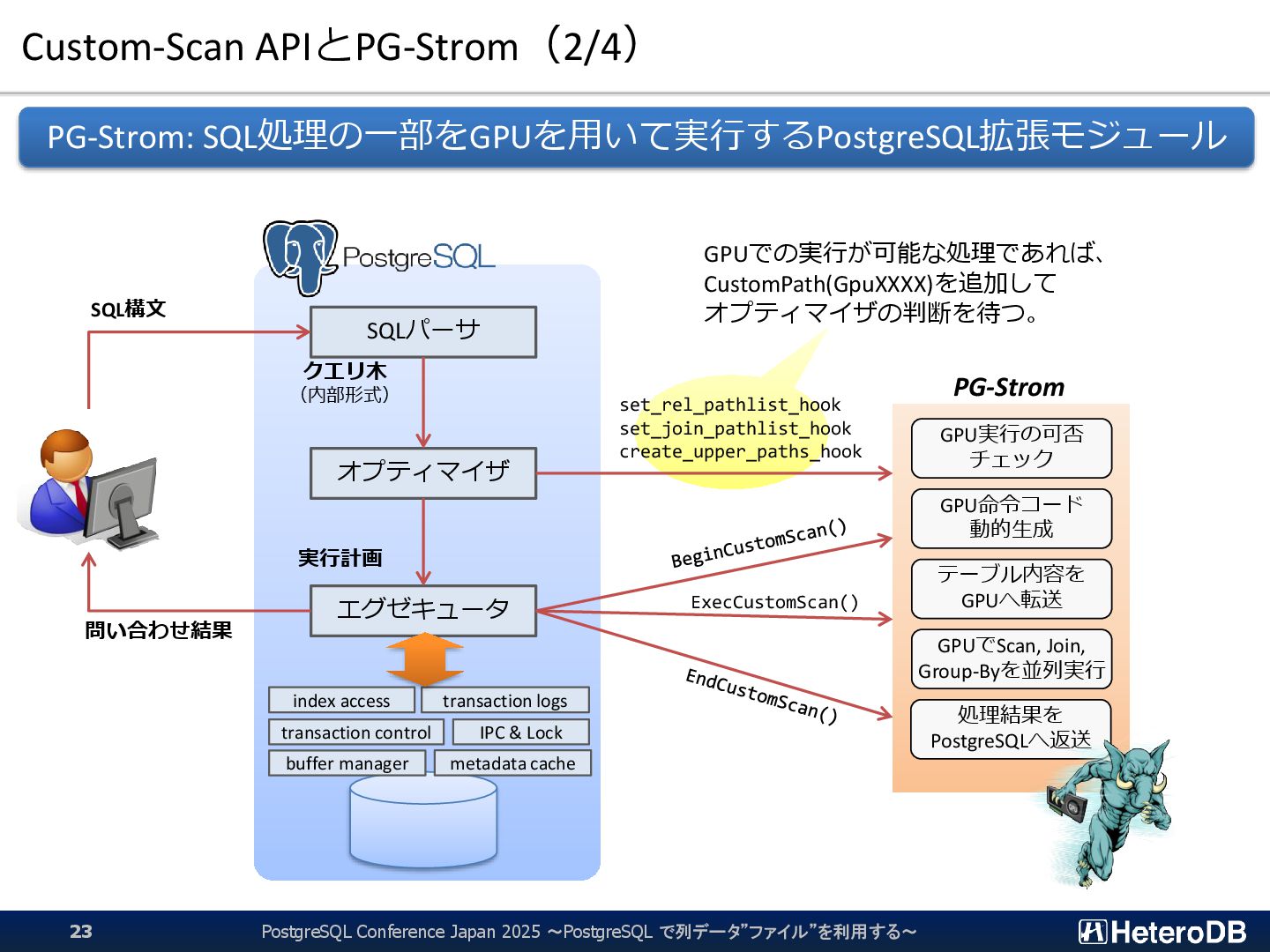{kind=link}
{kind=link}
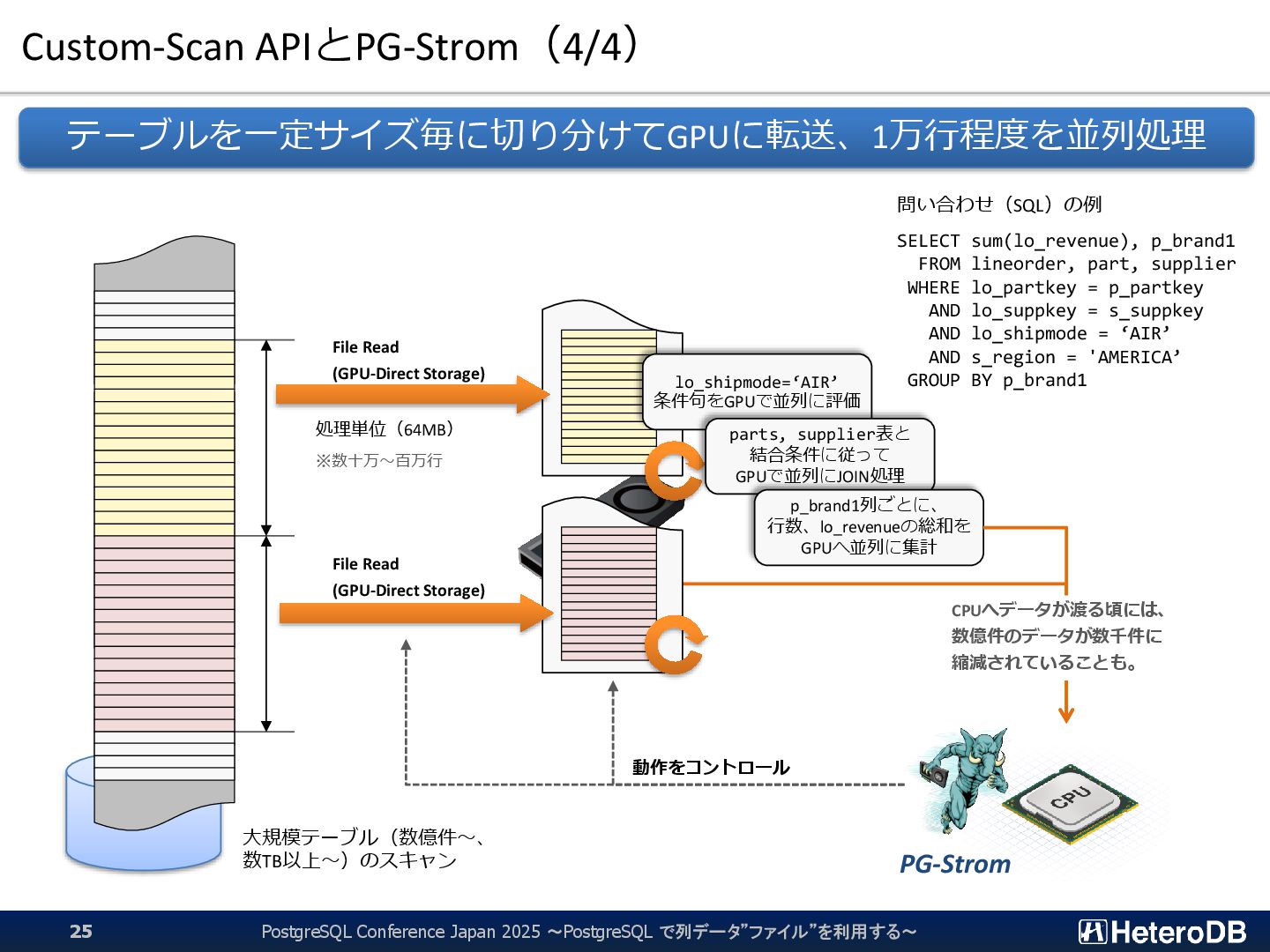{kind=link}
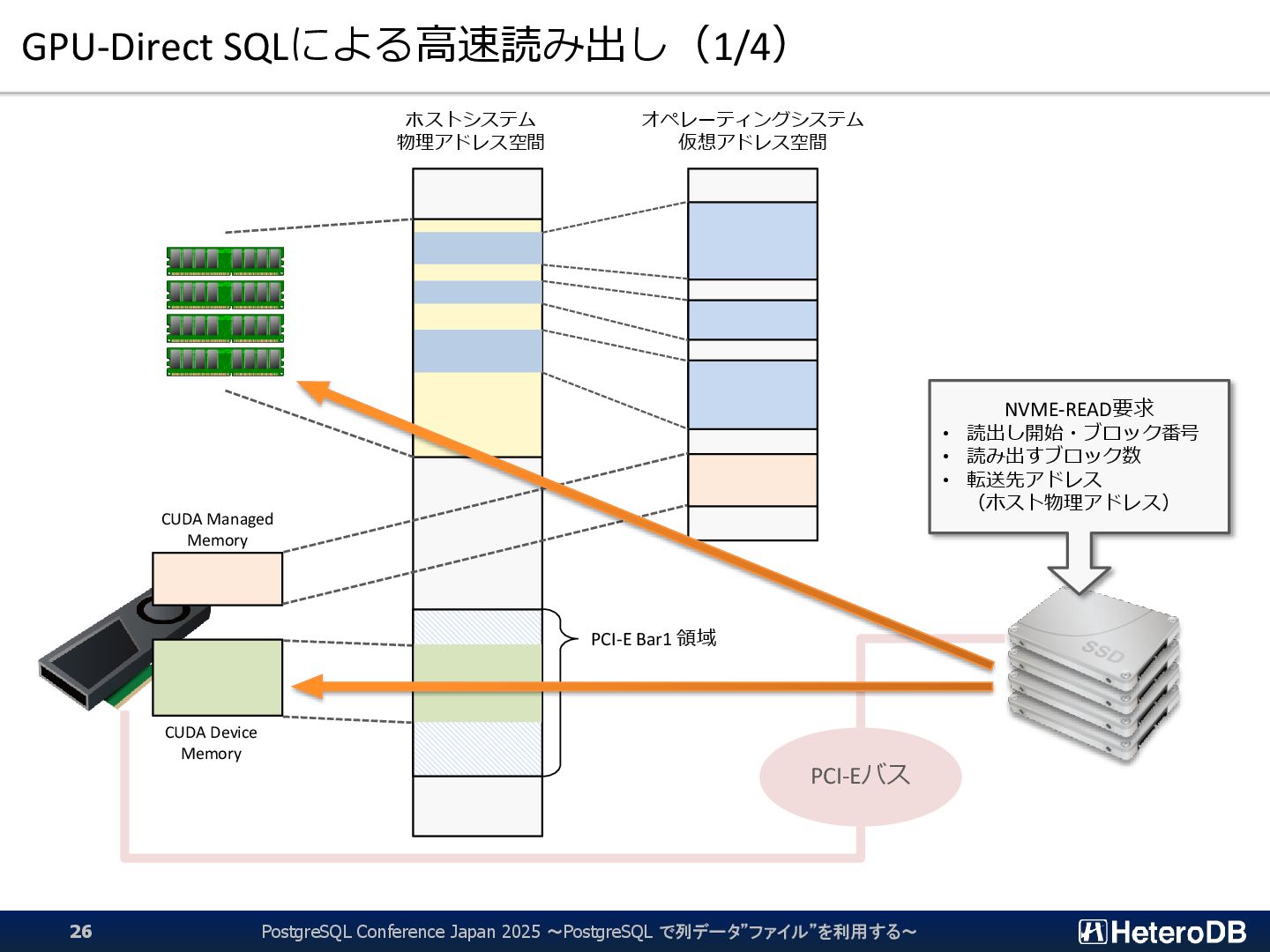{kind=link}
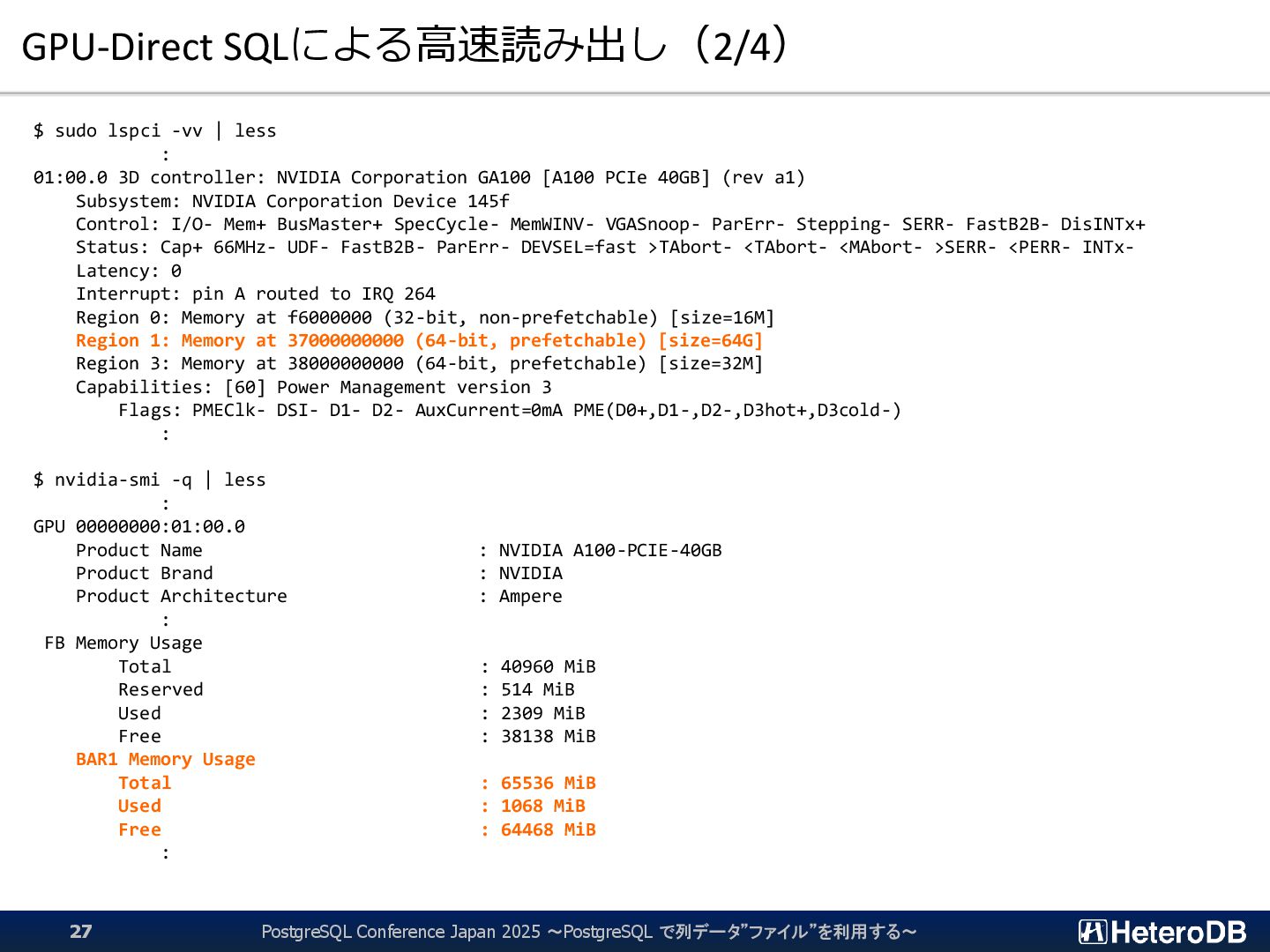{kind=link}
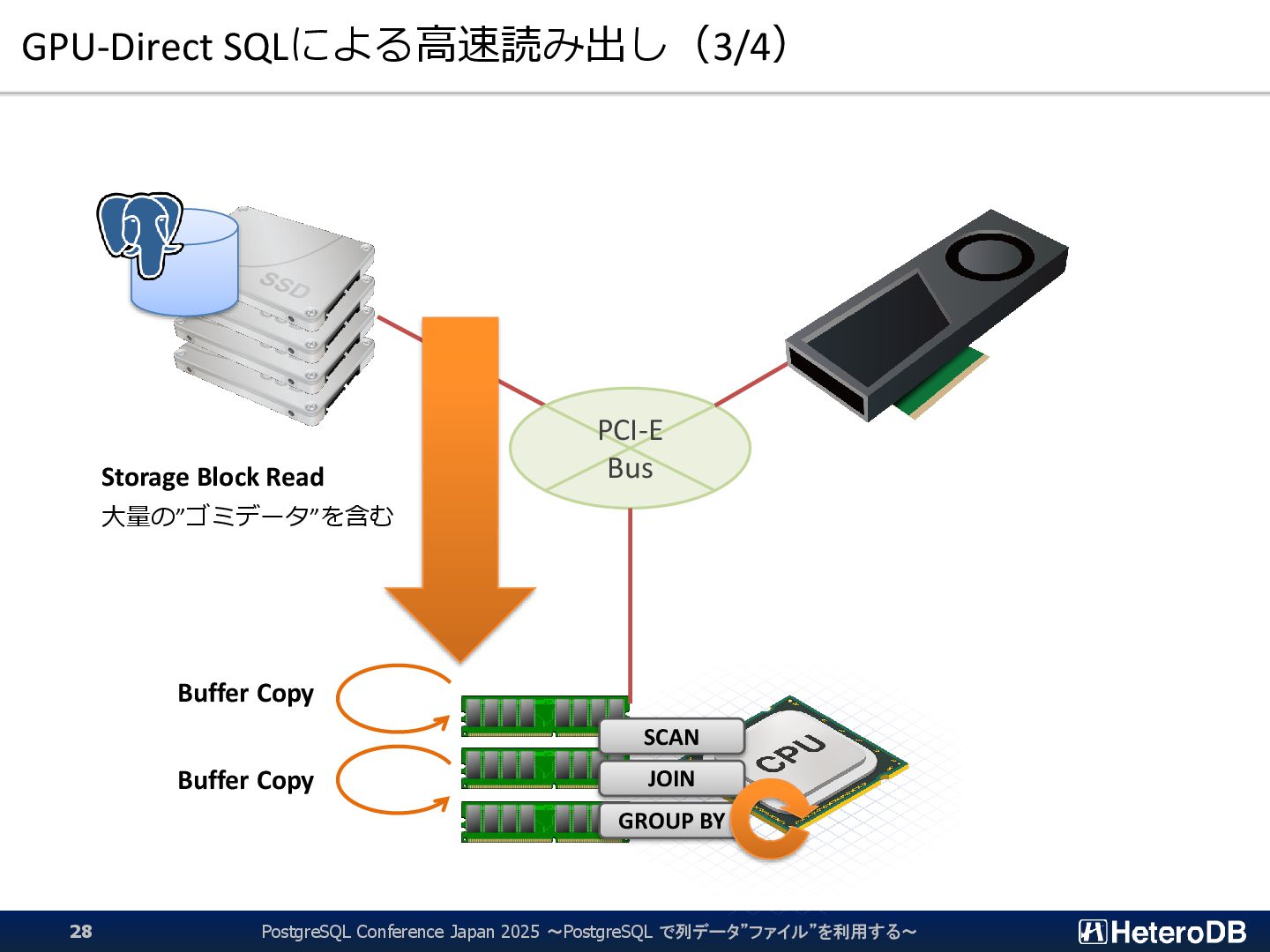{kind=link}
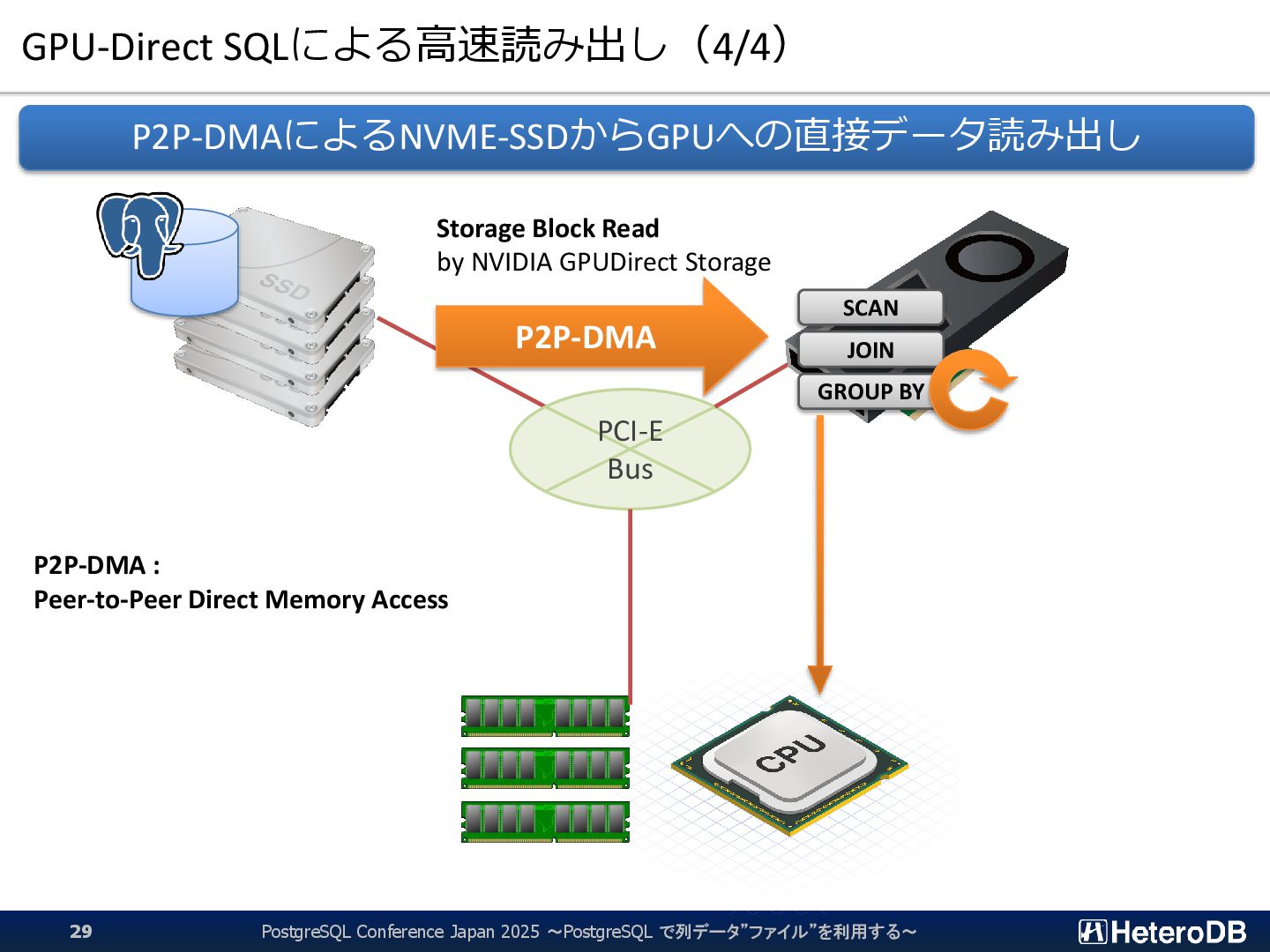{kind=link}
{kind=link}
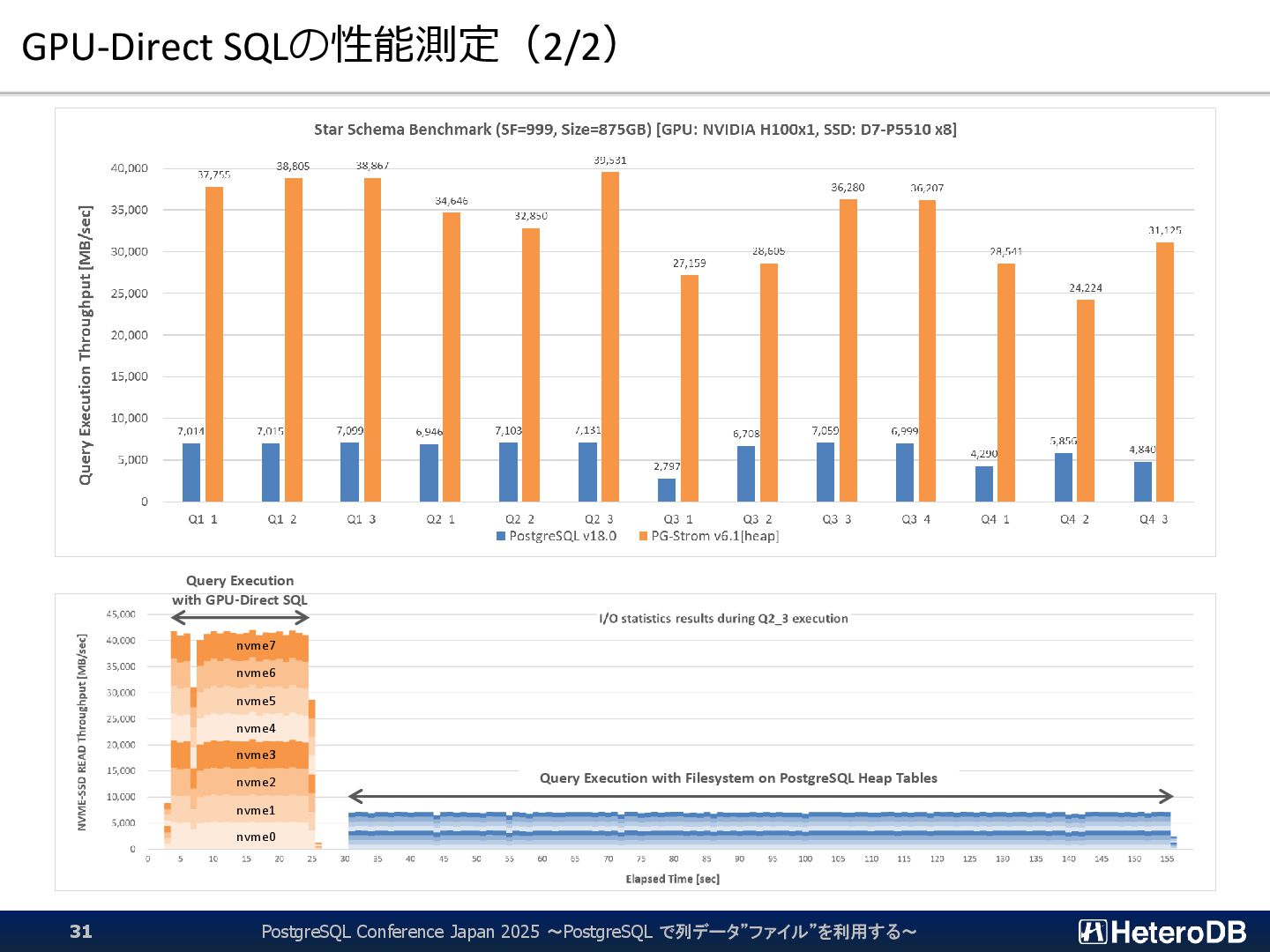{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GPUインスタンス上のArrow/Parquet(1/2) ▌PostgreSQL vs PG-Strom [heap] ほとんど速度差なし。EBSの帯域上限8Gbps(1GB/s)に抑えられている。 ▌PG-Strom [heap] vs](https://files.speakerdeck.com/presentations/8b22c88dd71f430d820523944a9944a0/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
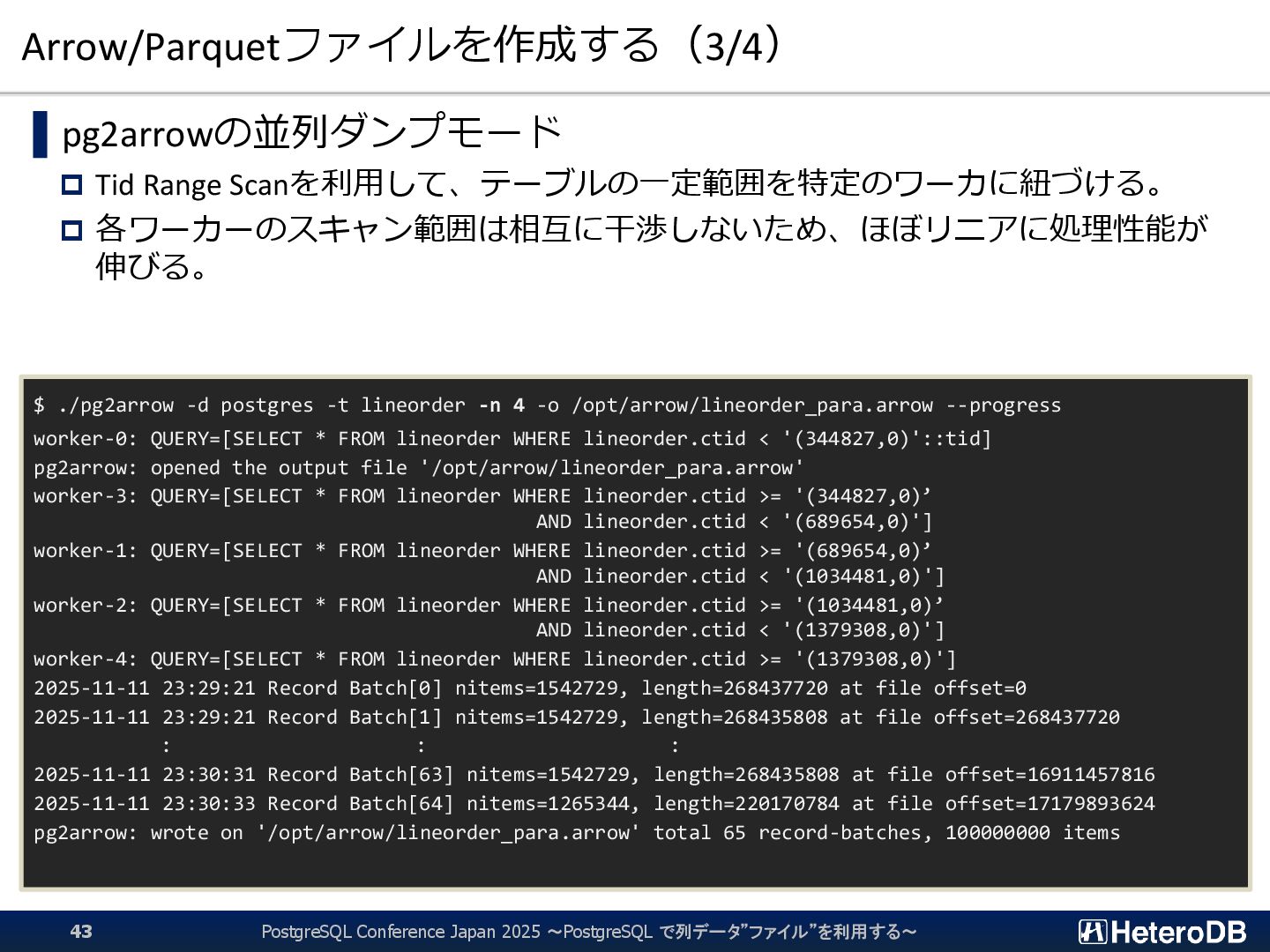{kind=link}
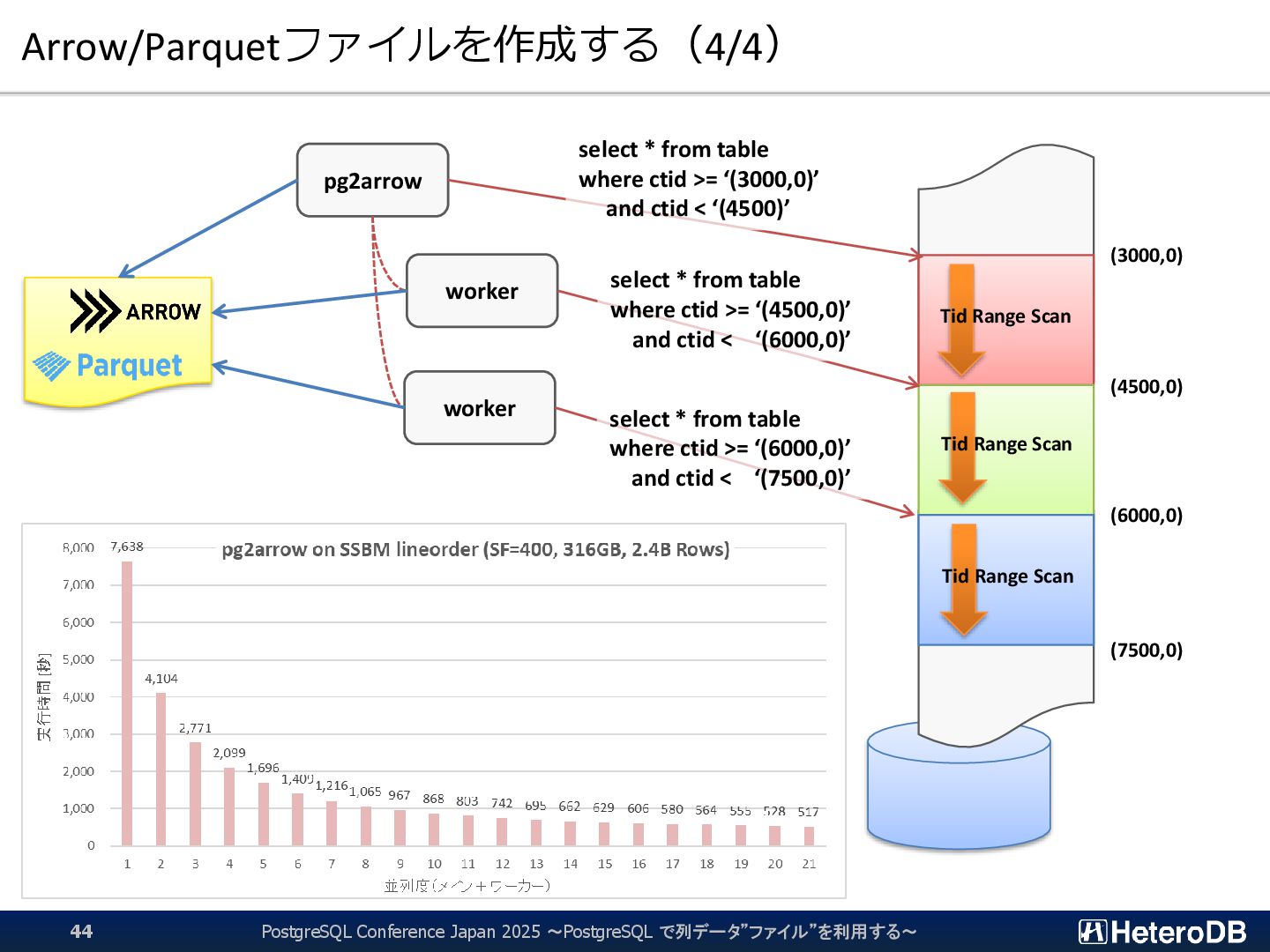{kind=link}
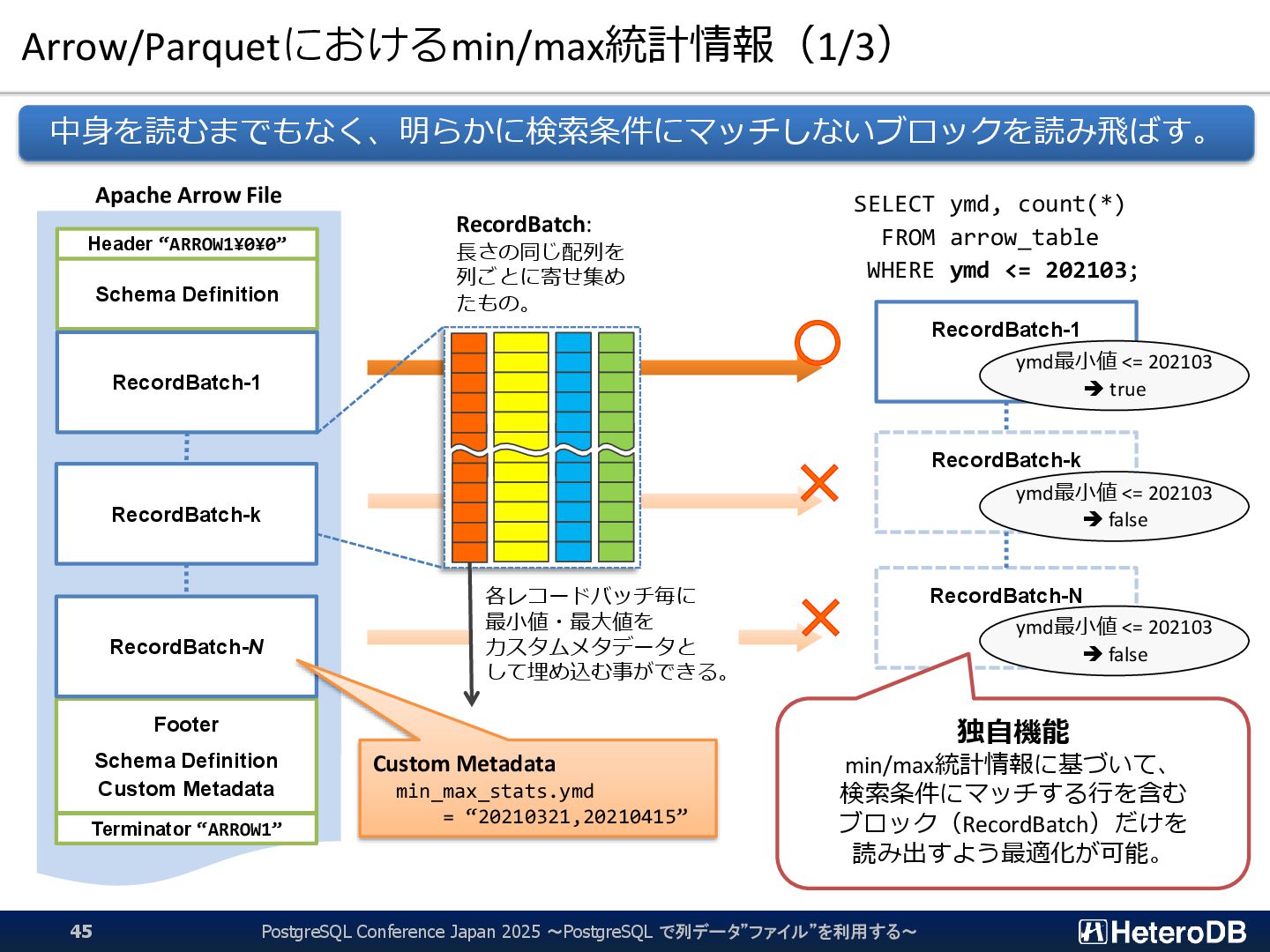{kind=link}
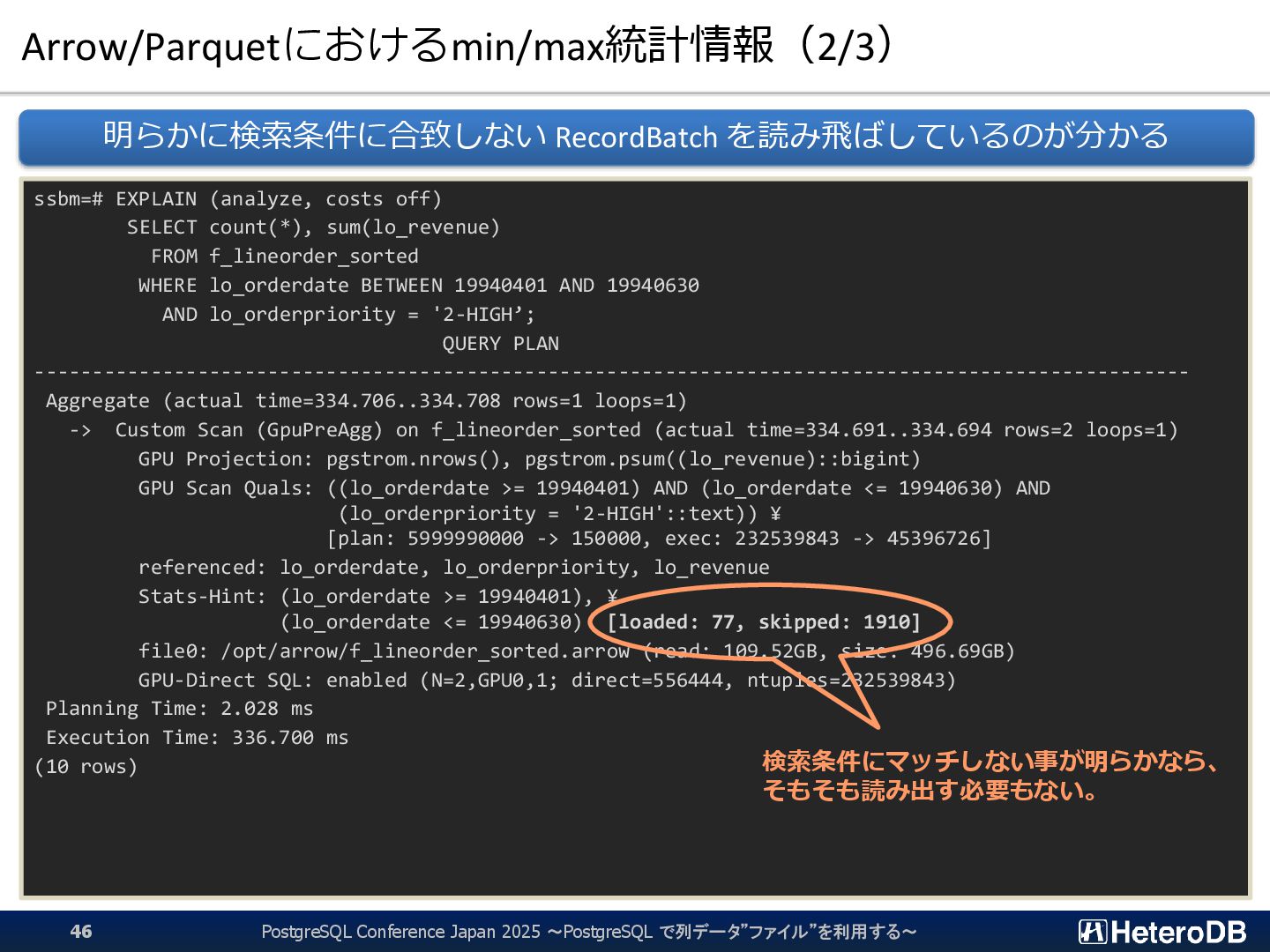{kind=link}
{kind=link}
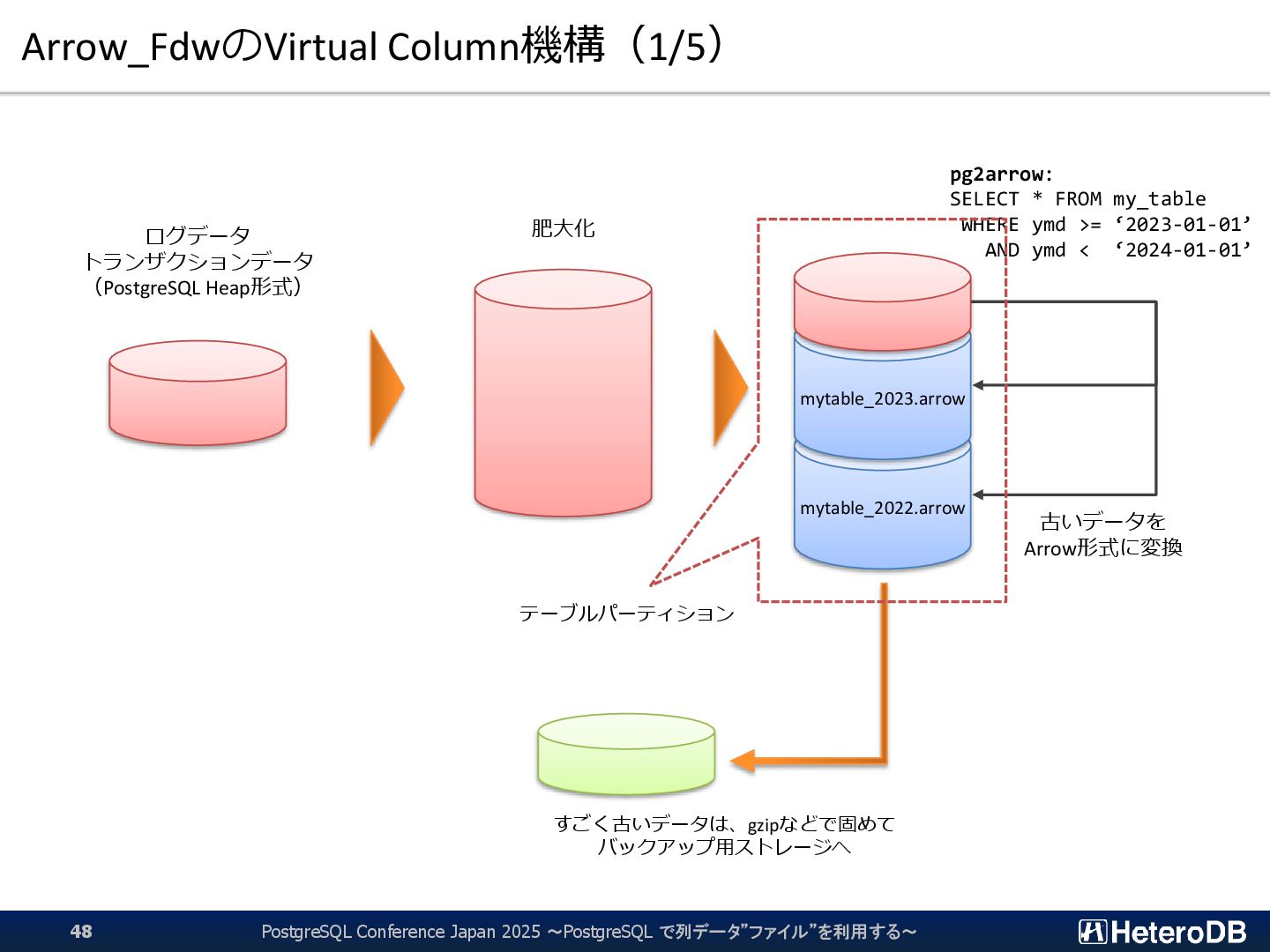{kind=link}
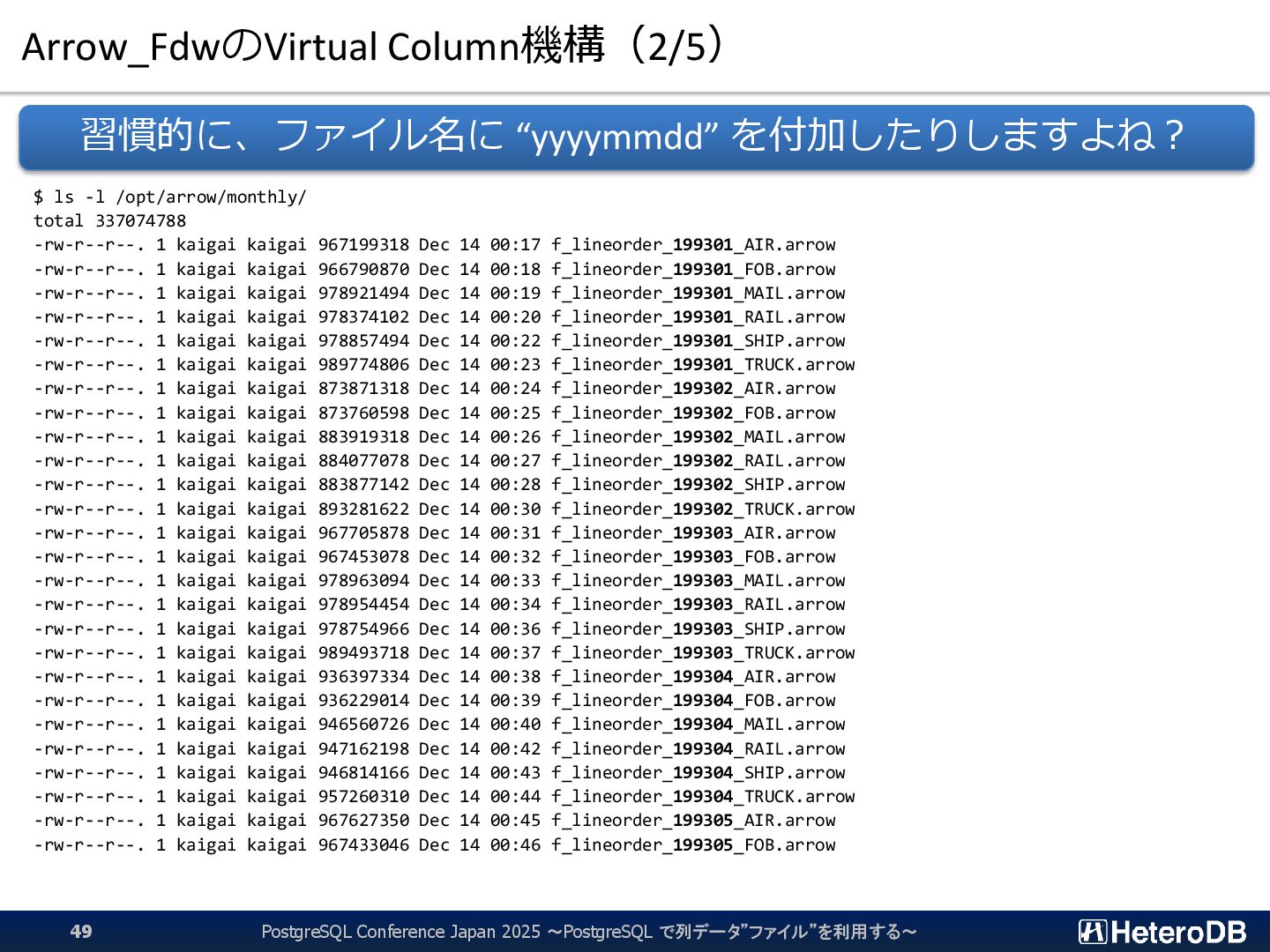{kind=link}
{kind=link}
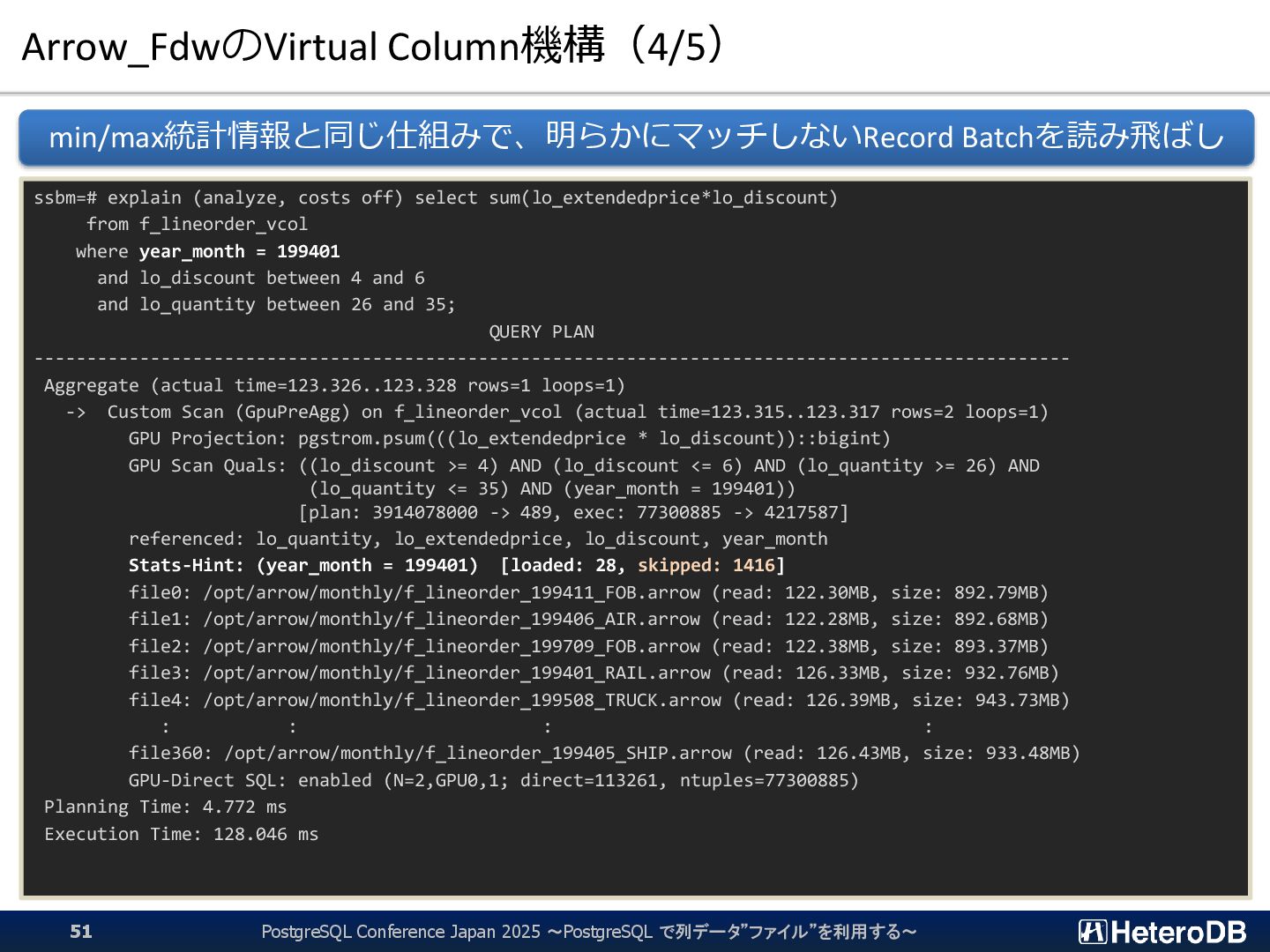{kind=link}
{kind=link}
{kind=link}
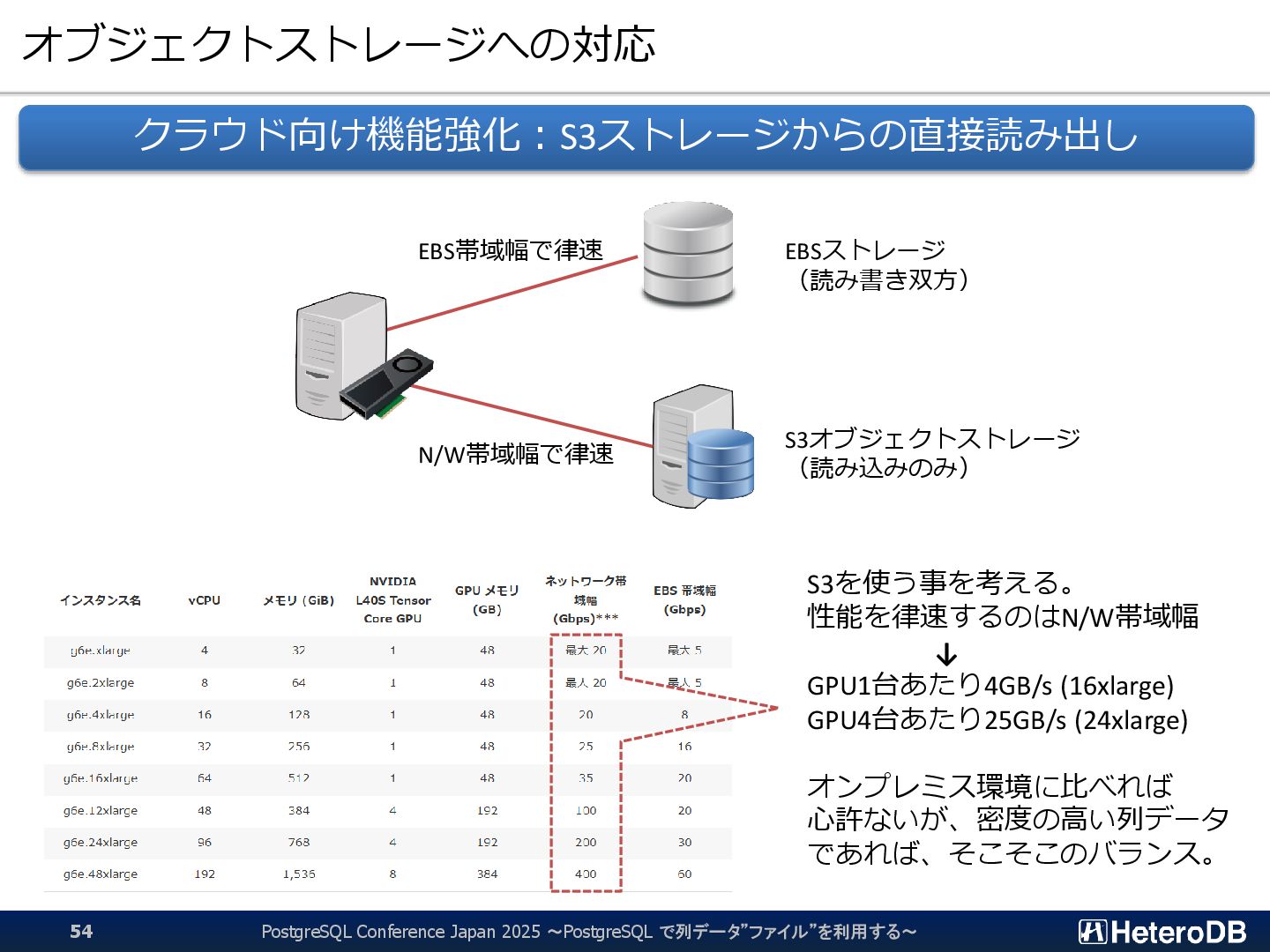{kind=link}
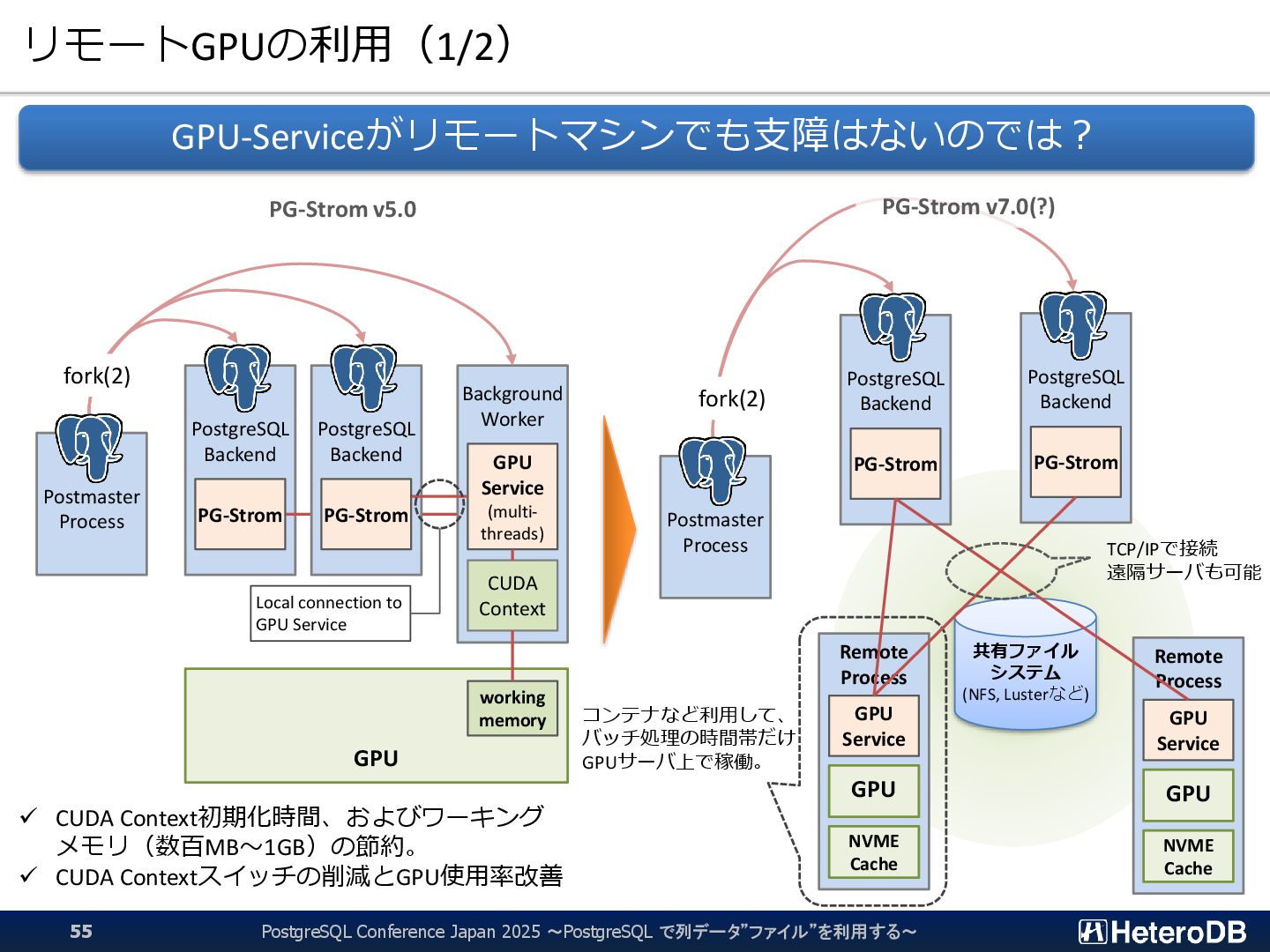{kind=link}
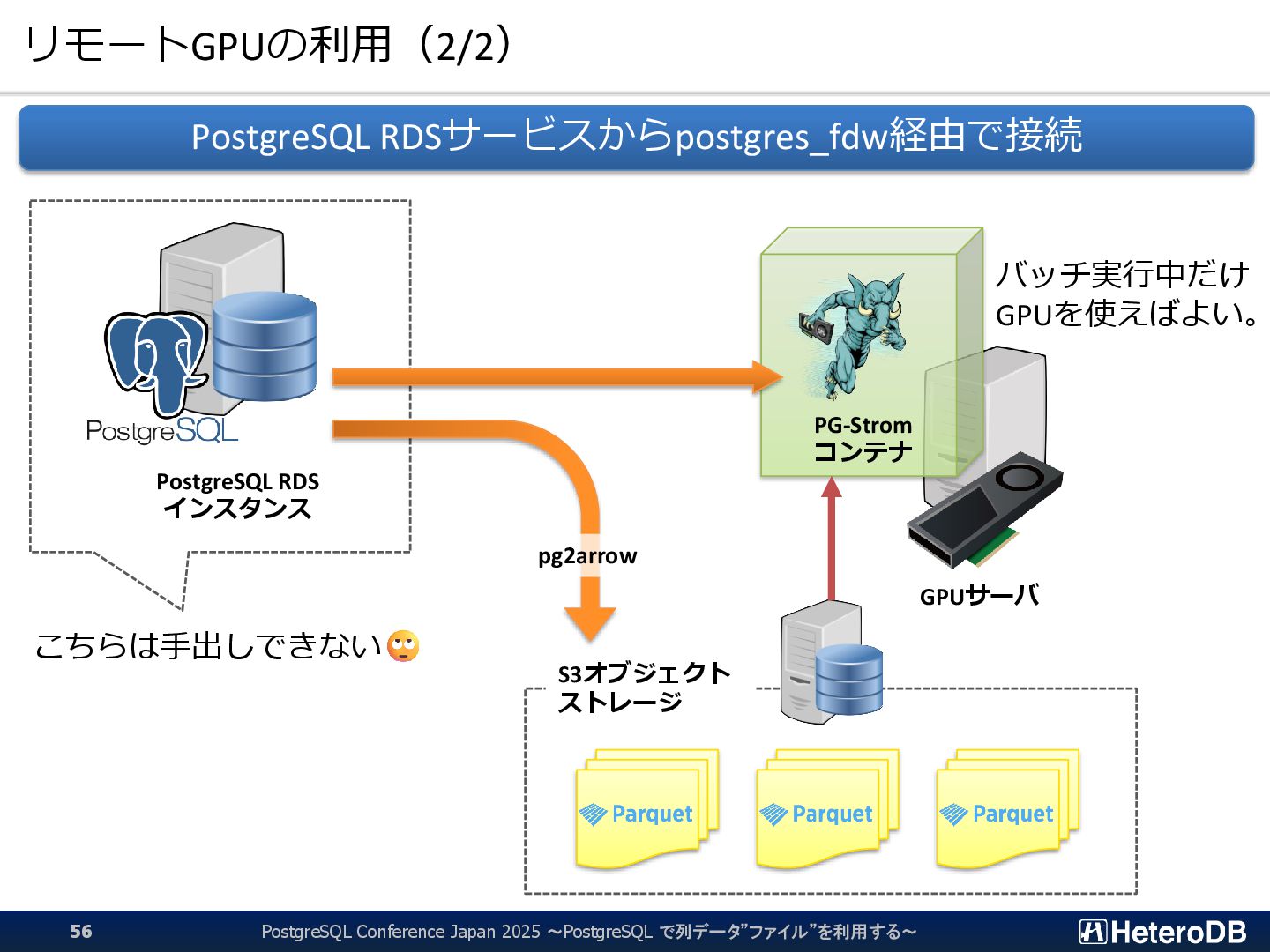{kind=link}
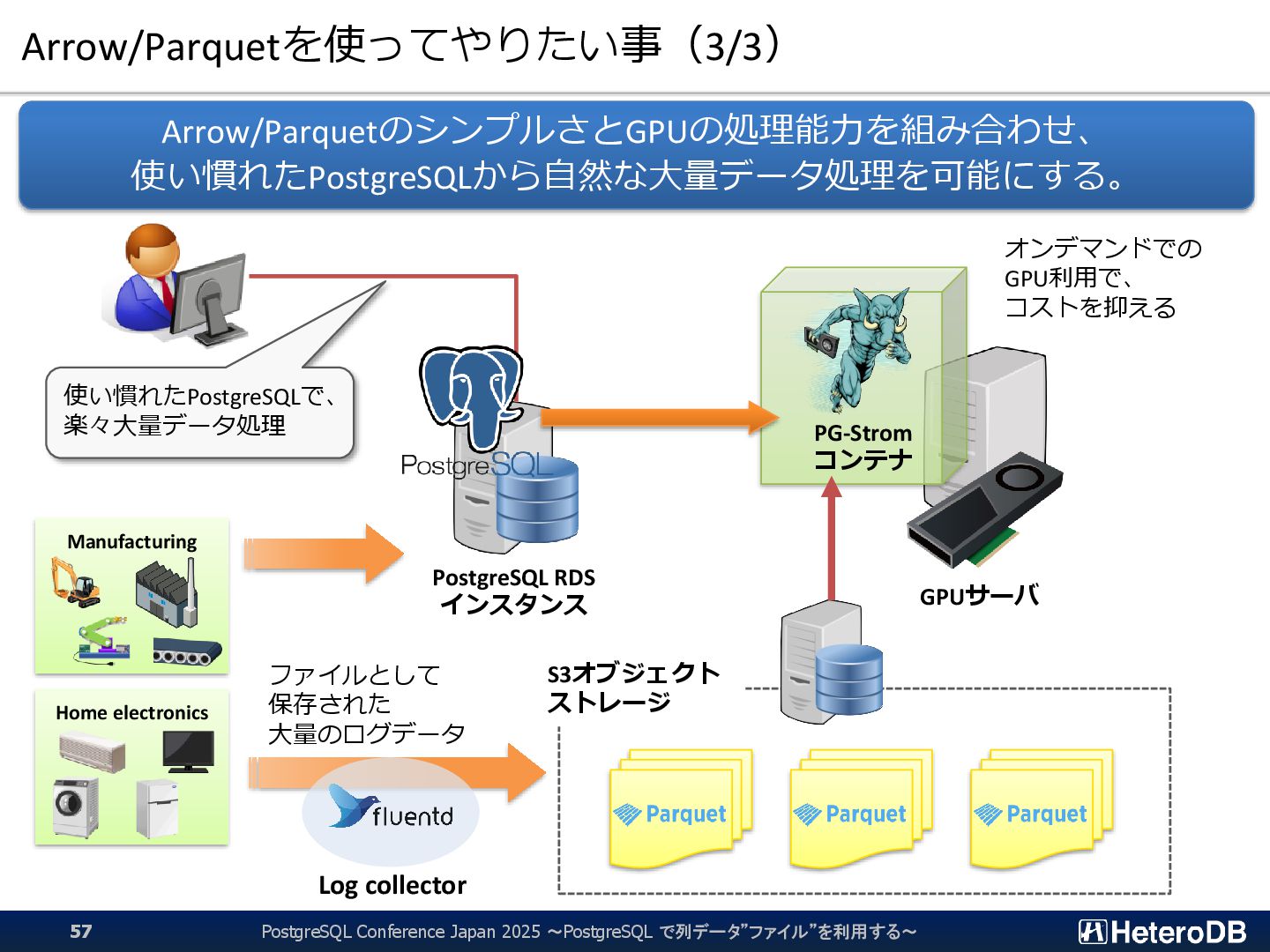{kind=link}
{kind=link}
{kind=link}