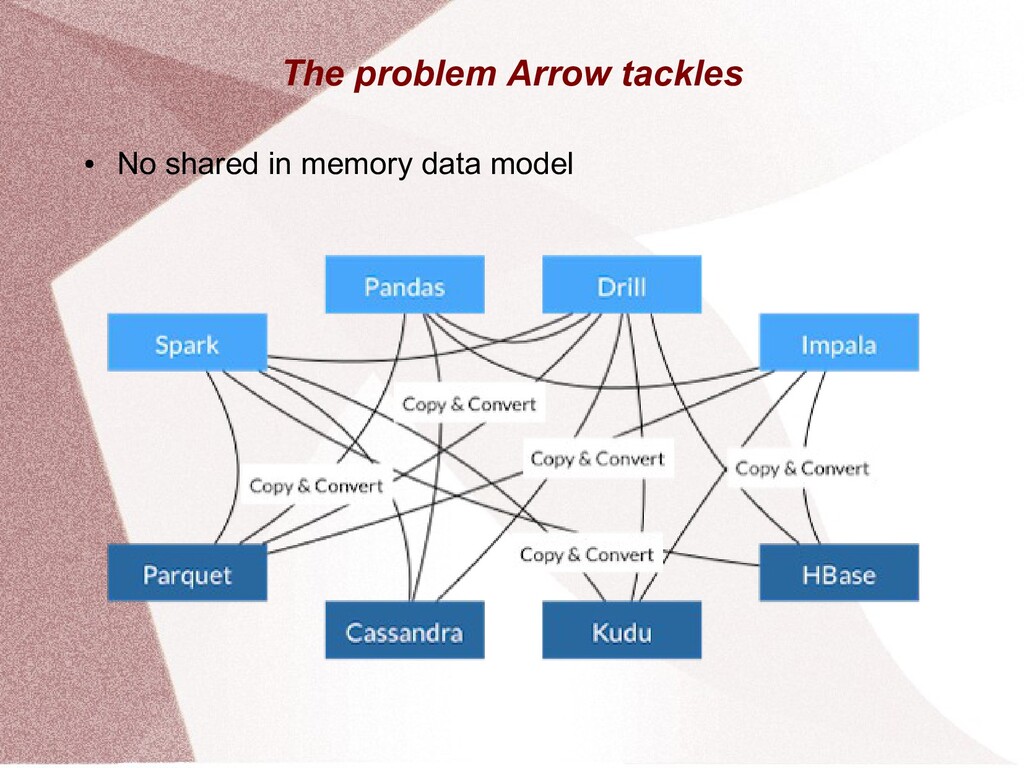
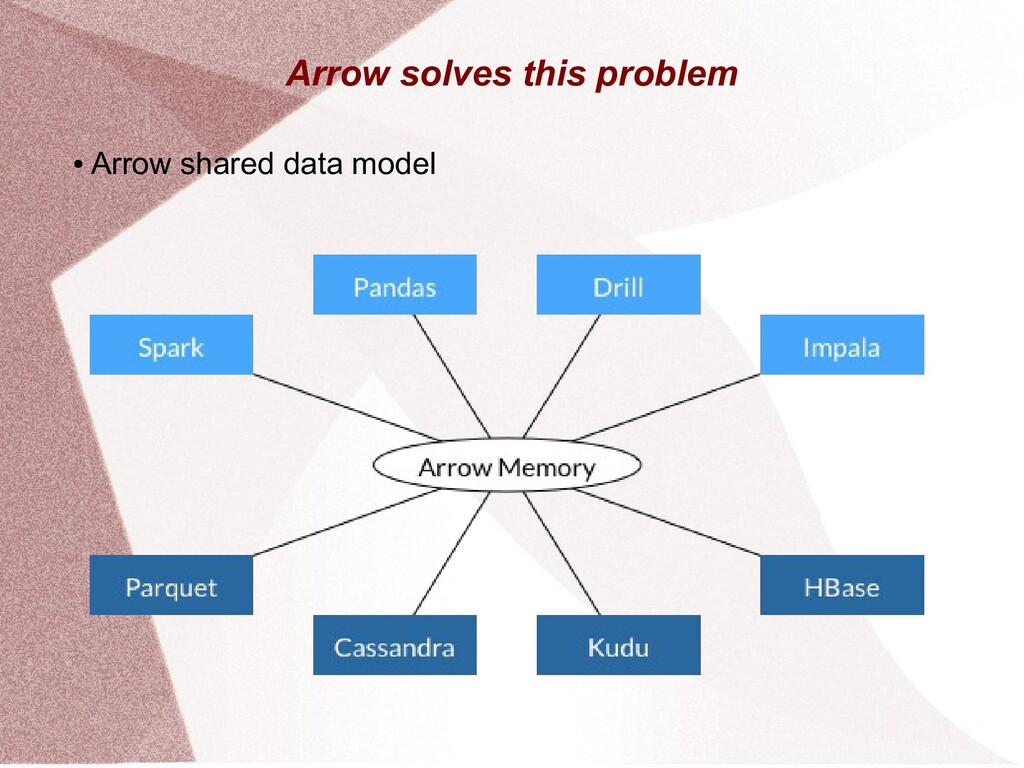
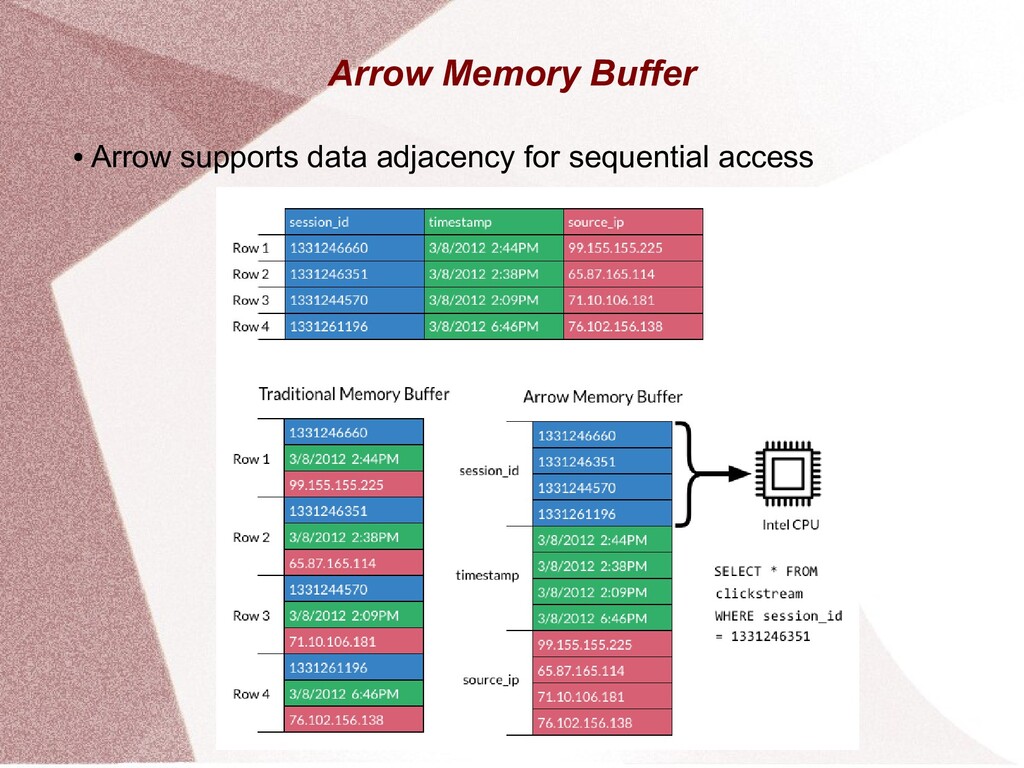
This presentation gives an overview of the Apache Arrow project. It explains the Arrow project in terms of its in memory structure, its purpose, language interfaces and supporting projects.
Links for further information and connecting
http://www.amazon.com/Michael-Frampton/e/B00NIQDOOM/
https://nz.linkedin.com/pub/mike-frampton/20/630/385
https://open-source-systems.blogspot.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}