Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Web Scale with NoSQL
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Sergejus
April 09, 2011
Technology
88
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Web Scale with NoSQL
Sergejus
April 09, 2011
More Decks by Sergejus
See All by Sergejus
Bringing Developers to the Next Level
sergejusb
0
230
True story of re-architecting website for scale on Windows Azure
sergejusb
1
71
Continuous Happiness by Continuous Delivery
sergejusb
2
3.9k
Windows Azure from practical point of view
sergejusb
1
82
Windows Azure Web Sites: new cloud hosting offering
sergejusb
2
77
Intro to Big Data using Hadoop
sergejusb
2
140
Optimizing ASP.NET application performance: tough but necessary
sergejusb
2
68
Release Often, Release Safely
sergejusb
1
61
NoSQL – What’s that.pdf
sergejusb
1
75
Other Decks in Technology
See All in Technology
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.5k
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.4k
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
240
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
210
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
710
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
5k
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
390
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
DatabricksにおけるMCPソリューション
taka_aki
1
270
OPENLOGI Company Profile for engineer
hr01
1
74k
Featured
See All Featured
GraphQLとの向き合い方2022年版
quramy
50
15k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Odyssey Design
rkendrick25
PRO
2
730
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Deep Space Network (abreviated)
tonyrice
0
230
How to Talk to Developers About Accessibility
jct
2
380
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Transcript
Web Scale with NoSQL Sergejus Barinovas (@sergejusb) http://sergejus.blogas.lt
None
Who Am I? Architect at Running NoSQL servers
in production Blogger (http://sergejus.blogas.lt, @sergejusb) Community member (http://dotnetgroup.lt) Contact me via
[email protected]
Powered by RDBMS Used everywhere… …even where it
shouldn’t Used for 30+ years!
Back to 1980’s…
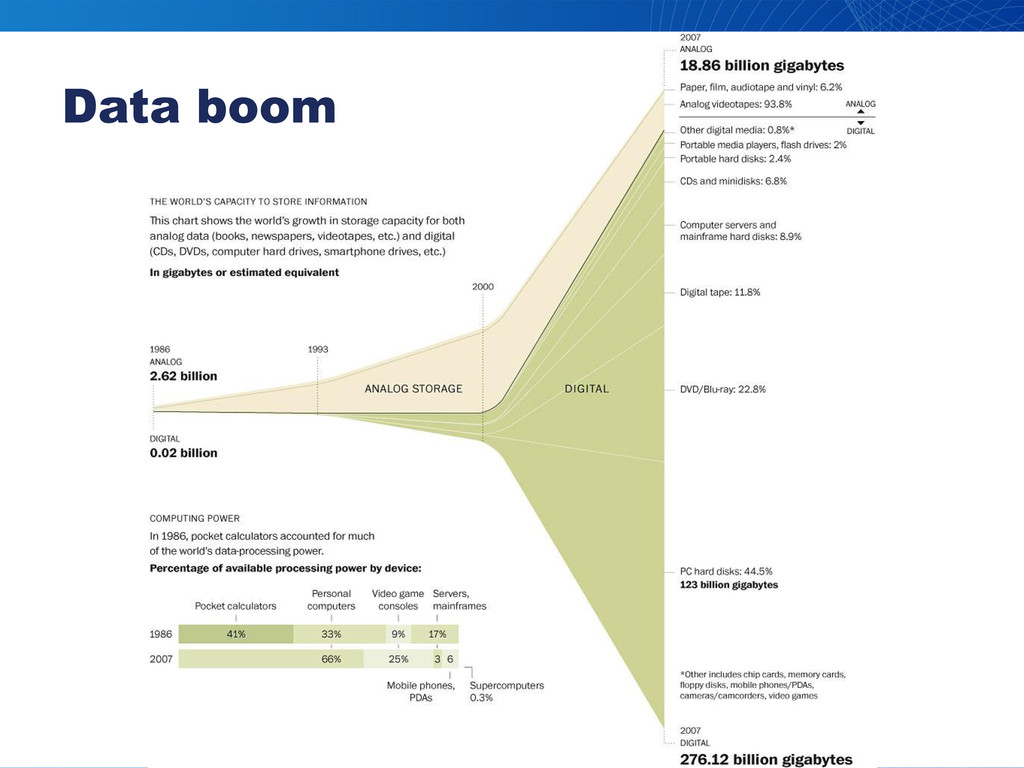
Data boom
in numbers 600 000 000 users 30 000
servers 20+ TB raw data per day >20 PB stored data
You really think they use RDBMS?
RDBMS Scaling Example
Simple usage Customers Reads / Writes master
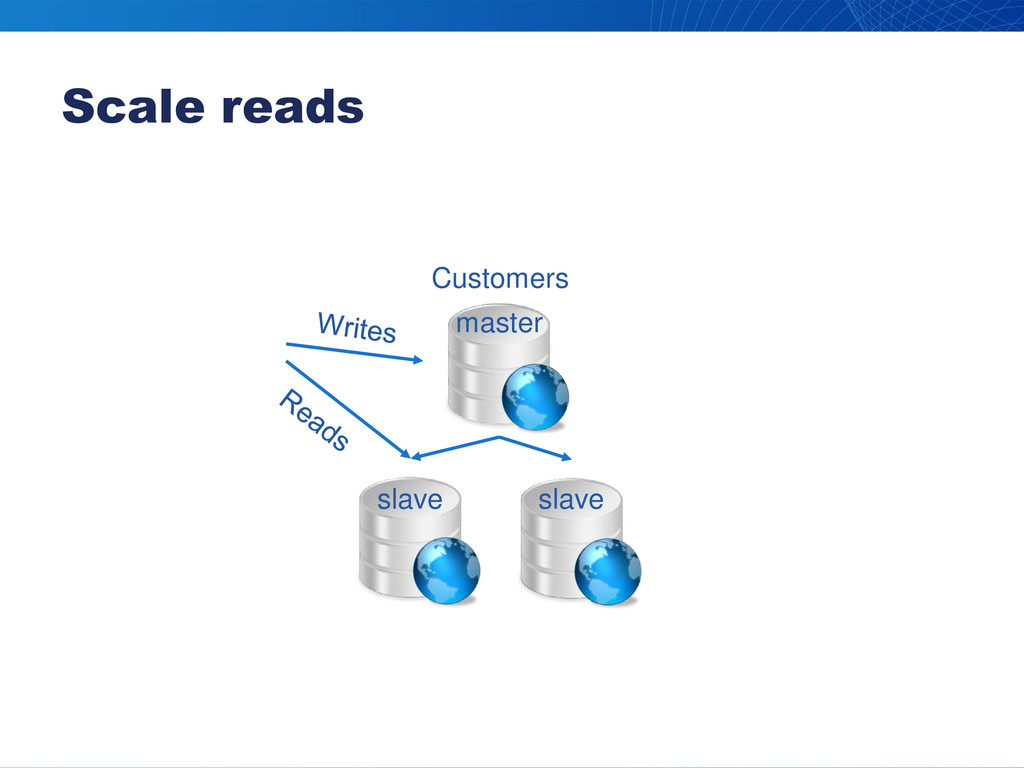
Scale reads Customers master slave slave
Scale writes Customers [A-M] master master Customers [N-Z]
Scale reads / writes Customers [A-M] master slave slave master
Customers [N-Z] slave slave
Pray your system won’t fail
None
Why NoSQL Limited SQL scalability Sharding and vertical
partitioning Limited SQL availability Master / slave configuration Limited SQL speed of read operations Multiple read replicas SQL limitations for huge amount of data Key / value / type columns
NoSQL history 2009, Eric Evans, no:sql(est) NoSQL –
open source distributed databases, not relational SQL databases NoSQL – not only SQL NoSQL → Big Data
NoSQL characteristics (1/2) Scalability The ability to horizontally
scale simple- operation throughput over many servers BASE A “weaker” concurrency model than the ACID transactions in most SQL systems
NoSQL characteristics (2/2) Distributed Efficient use of distributed
indexes and RAM for data storage Schema-less The ability to dynamically define new attributes or data schema
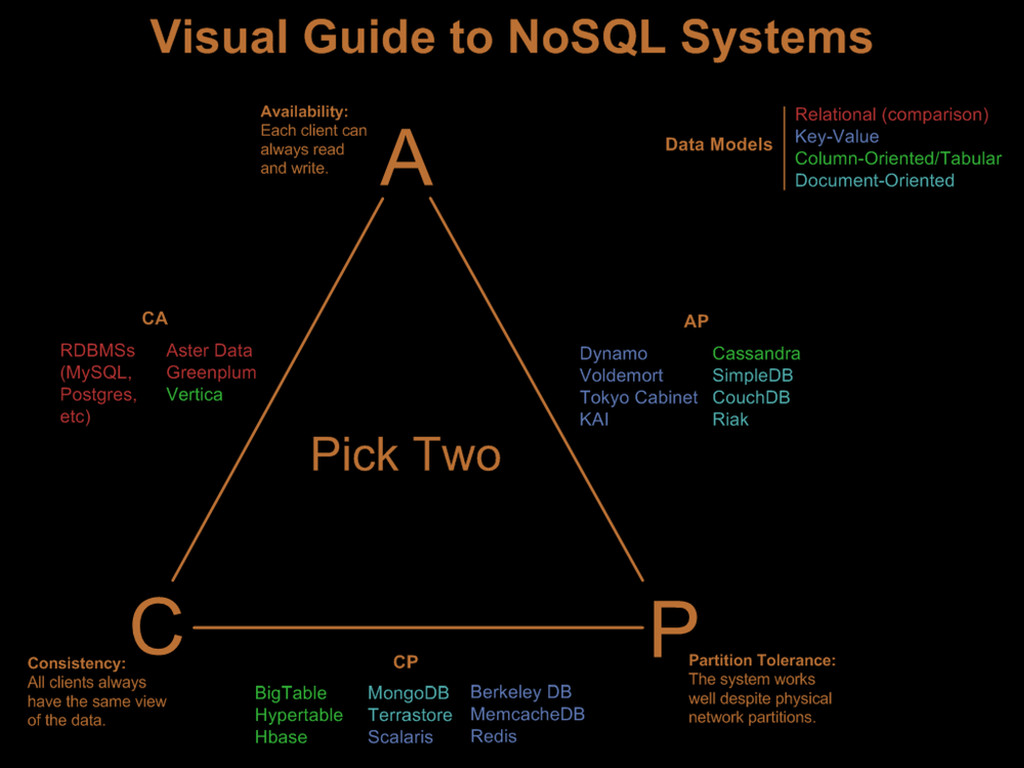
CAP theorem 2000, Eric Brewer It is impossible
for a distributed computer system to simultaneously provide all three of the following guarantees: Consistency Availability Partition tolerance
None
NoSQL Databases
NoSQL categories Key / value store Document database
Graph database Columnar database
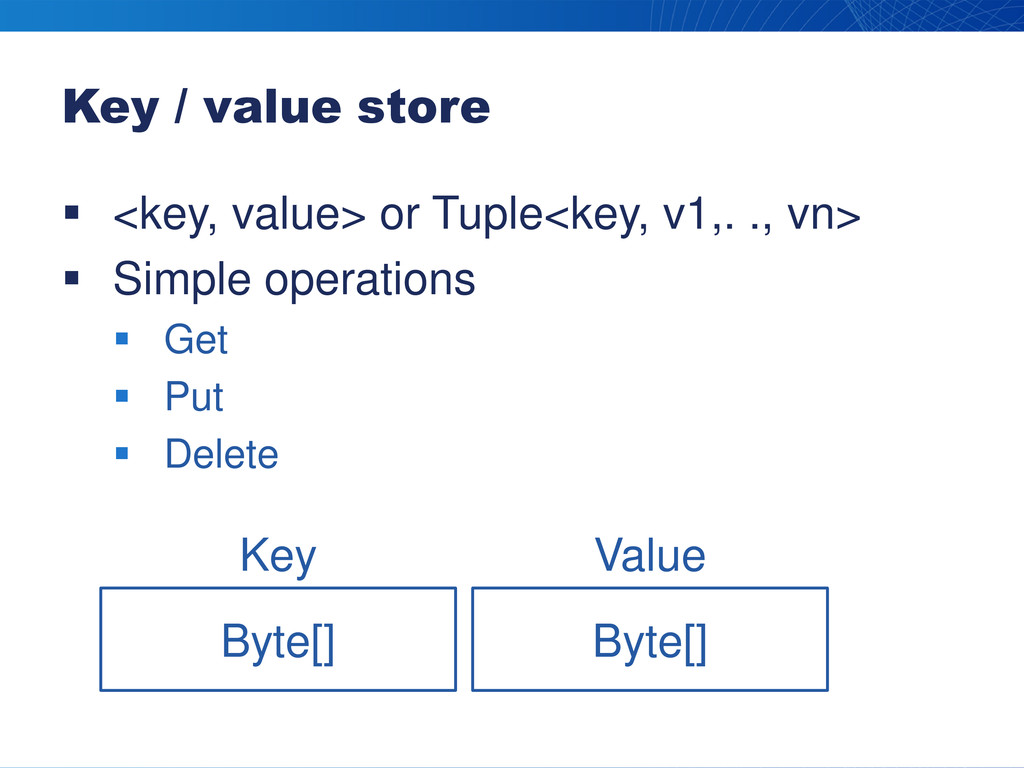
Key / value store <key, value> or Tuple<key, v1,.
., vn> Simple operations Get Put Delete Byte[] Byte[] Key Value
Key / value store Key Value “current_date” 2013.02.01 “sergejusb” Binary
Object “sergejusb” JSON Object
Key / value stores Redis (+)messaging (-)no
shards Voldermort Membase (+)memcache interface Riak
Document database Document == complex object XML
YAML JSON / BSON Support for secondary indexes Schema can be defined at runtime Optional support for simple querying using Map / Reduce
Document databases MongoDB (+)shards CouchDB (+)master
/ master replication
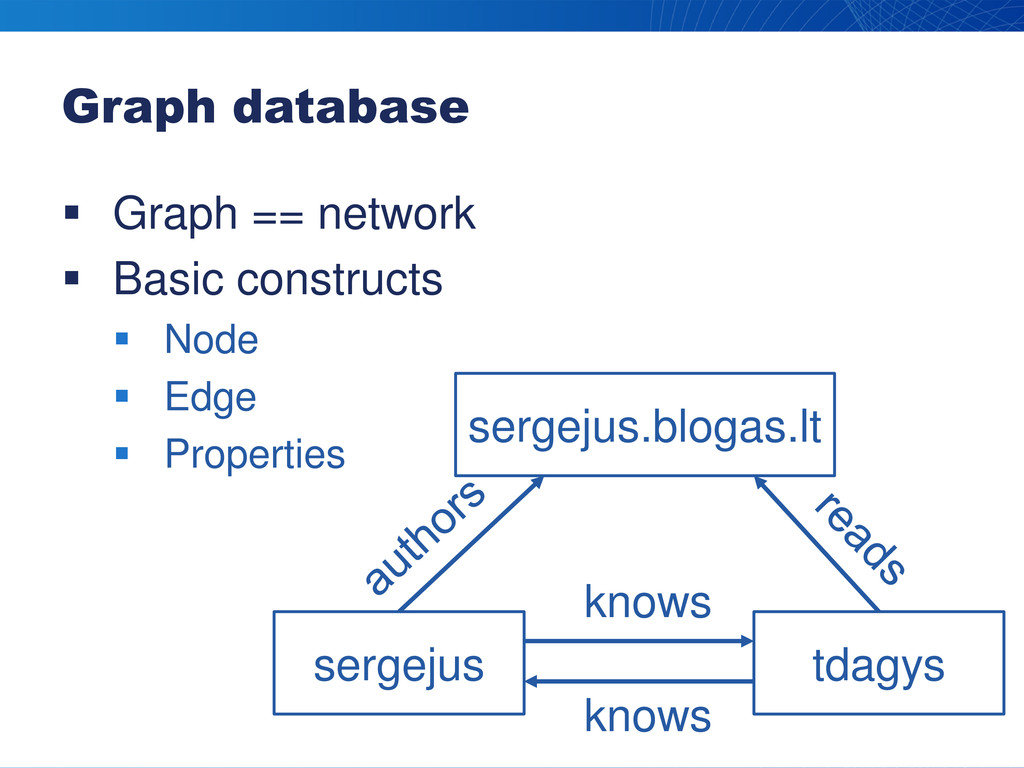
Graph database Graph == network Basic constructs
Node Edge Properties sergejus sergejus.blogas.lt tdagys knows knows
Graph databases Neo4j (-)paid version required for scaling
FlockDB (+)fast (-)limited functionality
Columnar database For HUGE amount of data Columns
are added at a runtime Great scalability Horizontal Vertical
Columnar database Unusual data model Key Space →
Database Column Family → Table Columns and Super Columns Super Column → array of Columns Column → Tuple<Key, Value, Timestamp, TTL>
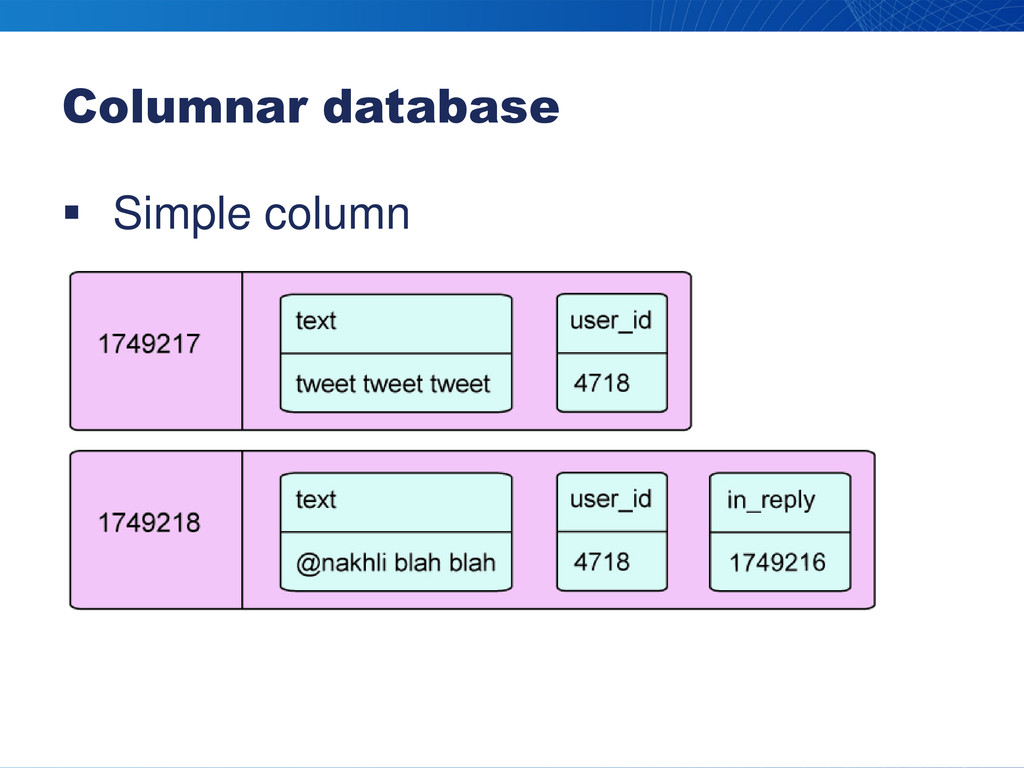
Columnar database Simple column
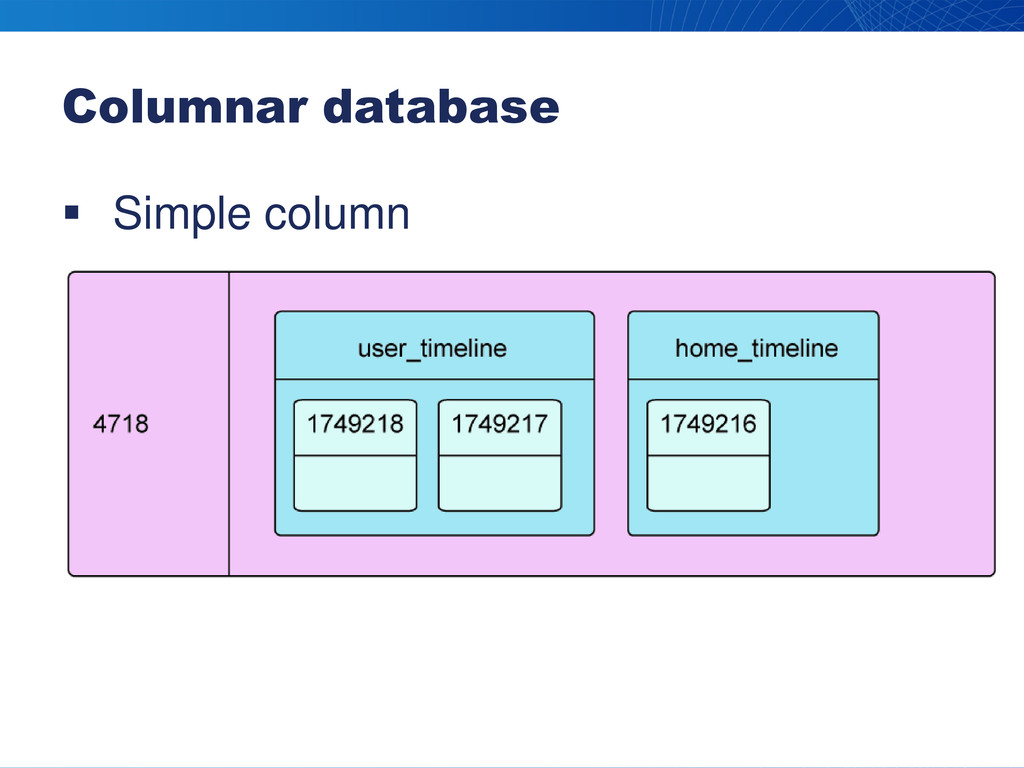
Columnar database Simple column
Columnar database Cassandra (+)easy scalable HBase
(+)consistent (+)part of Hadoop Hypertable
NoSQL is Cool! But…
None
NoSQL limitations ORDER BY ? Natural key order
GROUP BY ? Map / Reduce* JOIN ? Multiple Map / Reduce* SELECT * ? Multi-machine Map / Reduce* *if possible
NoSQL Limitations Maturity Tooling Specificity
SQL vs. NoSQL Choose the right tool for the
task You can use BOTH
Thank you! Sergejus Barinovas (@sergejusb)
[email protected]
http://sergejus.blogas.lt
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Scale writes Customers [A-M] master master Customers [N-Z]](https://files.speakerdeck.com/presentations/62143ce04e8c01307d291231381548c0/slide_11.jpg){kind=link}
![Scale reads / writes Customers [A-M] master slave slave master](https://files.speakerdeck.com/presentations/62143ce04e8c01307d291231381548c0/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Sergejus Barinovas (@sergejusb) [email protected] http://sergejus.blogas.lt](https://files.speakerdeck.com/presentations/62143ce04e8c01307d291231381548c0/slide_40.jpg){kind=link}