of audio and video streams accurately during an Audio Visual Recognition (AVR) process. • A coupled 3D Convolutional Neural Network analyses spatial and temporal data to match and correlate information. • The usage of a smaller dataset for training enhances the accuracy of the algorithm in mapping the two modalities into a single space and evaluate correspondence in information. 3
Recognition (AVR), which is used as a mechanism to detect audio using lip movements of a video, is the matching of corresponding audio and video streams perfectly. An algorithm to analyse and match spatial and temporal data to find the correlation in information accurately is desired. 4
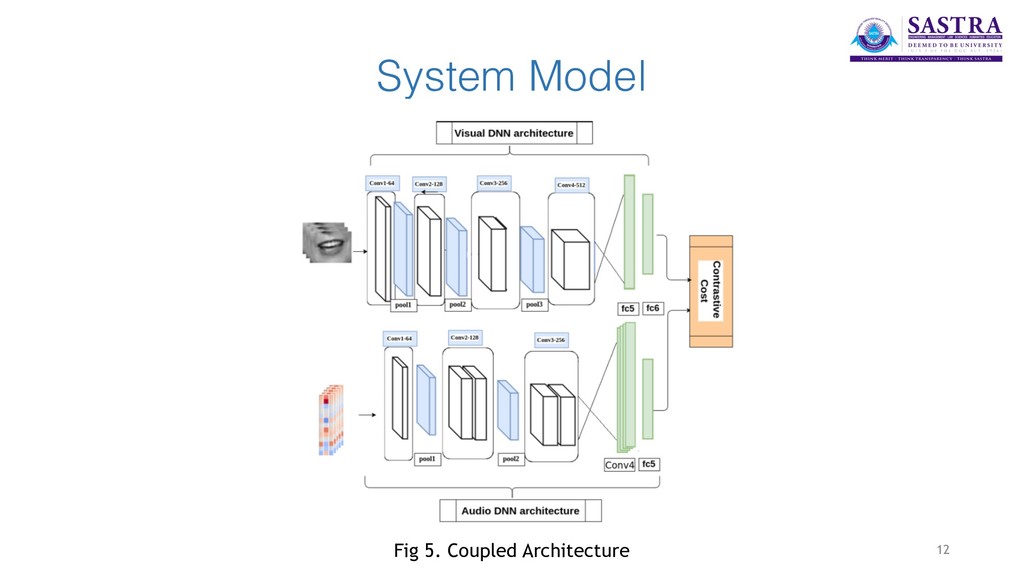
speech recognition tasks when the audio is corrupted as well as a visual recognition method used for speaker verification in multi speaker scenarios. • But it is important to map the audio and video streams accurately to achieve the desired results. • A coupled 3D Convolutional Neural Network architecture can map both spatial and temporal modalities into a representation space to evaluate the correspondence of audio-visual streams using multimodal features. 5
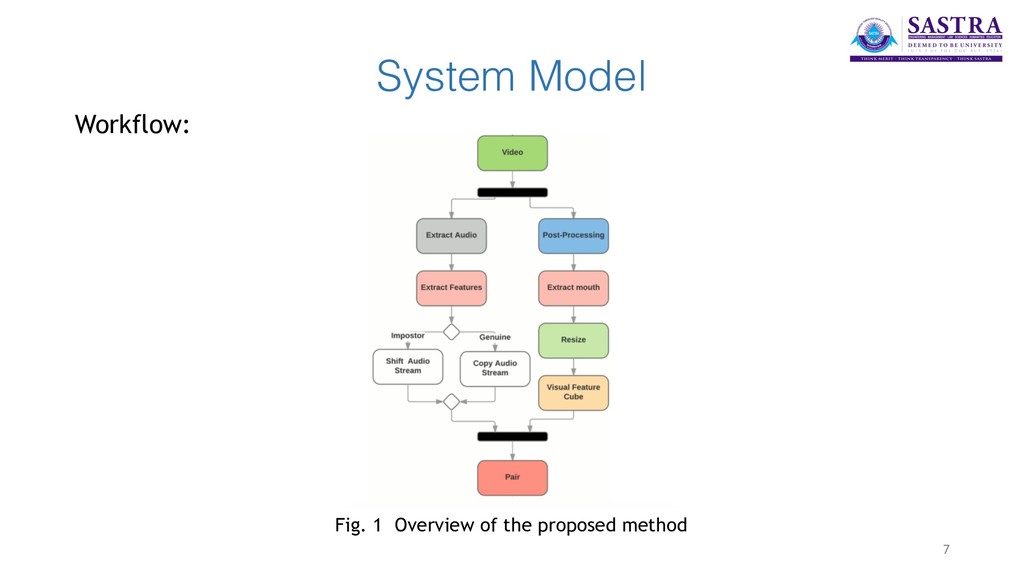
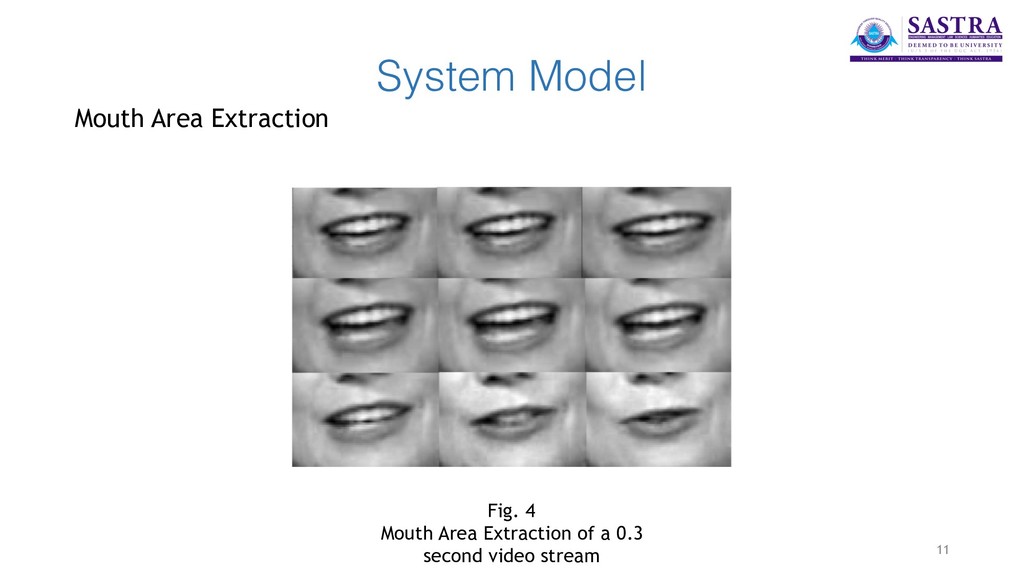
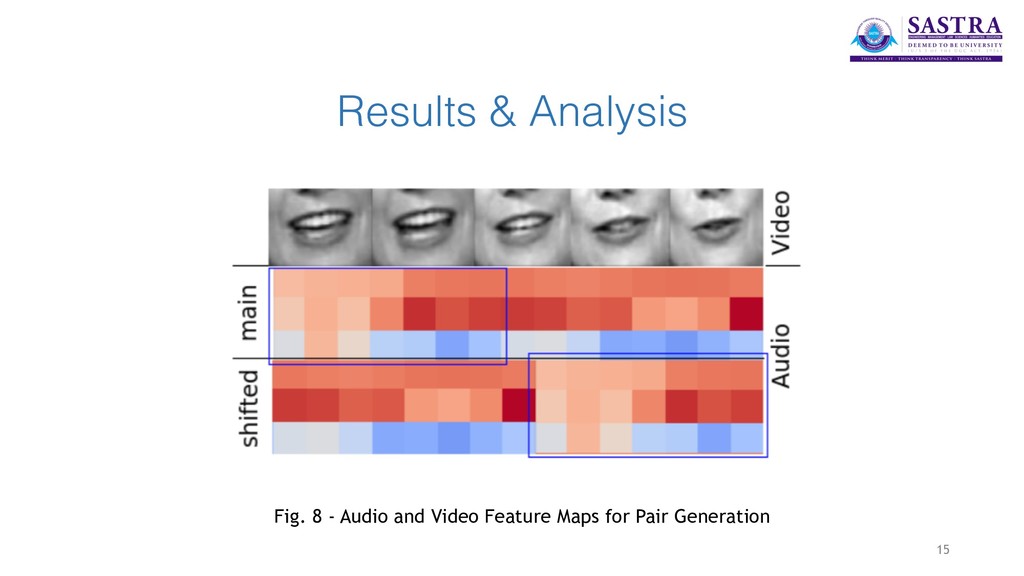
stream and extracts the features of the audio file. • The Mouth Extraction module processes the input video file and recognises the regions of the video portraying the mouth of an individual. Those areas of the video are extracted separately for further processing. • The Lip Tracking module maps the visual extracted video streams with the audio features to accurately determine and pair the audio and video. 6
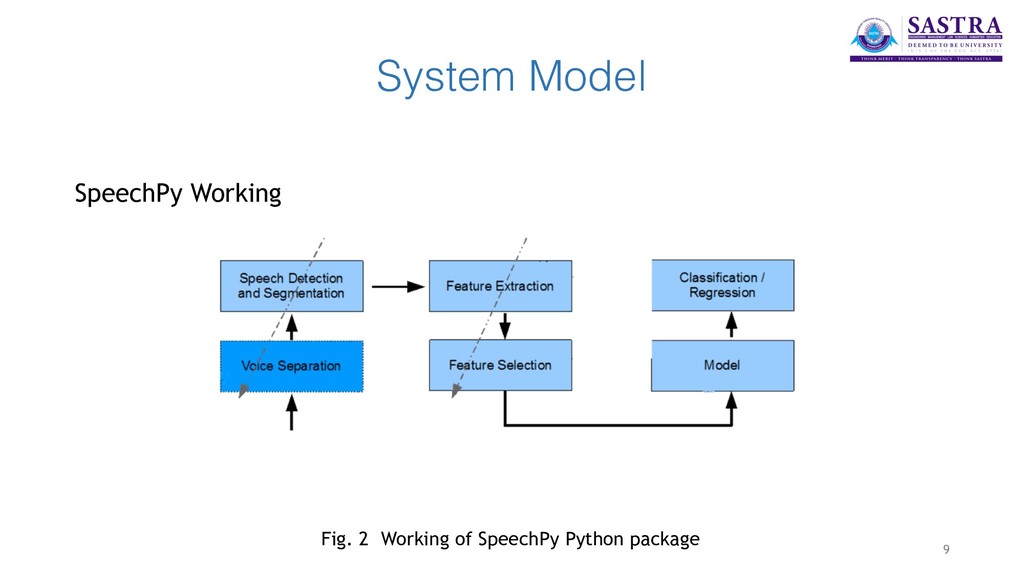
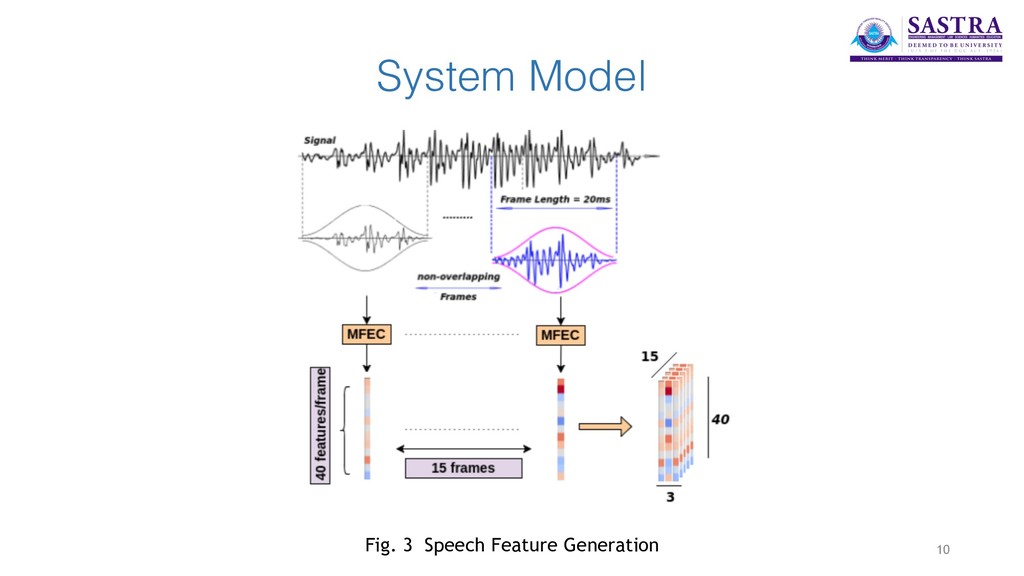
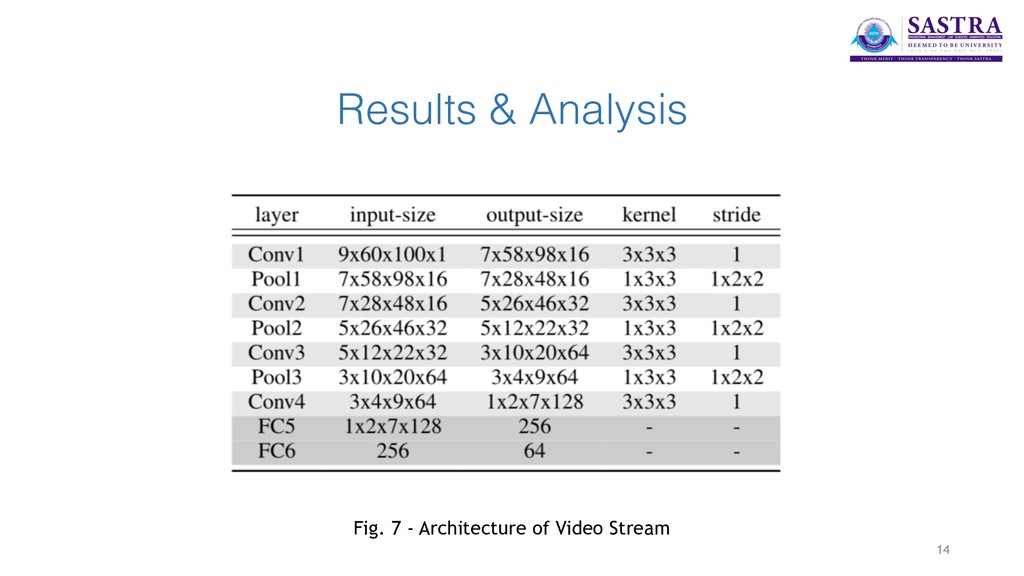
extracted from the audio files using SpeechPy package. MFEC (Mel Frequency Energy Coefficients) are used to represent the speech features. • In the visual section, the videos are post-processed to have equal frame rates of 30 f/s. Mouth area extraction is performed on the videos using the dlib library and the extracted areas are resized to have the same size and concatenated to form the input feature cube. • The two networks are coupled at the last level. A Contrastive Loss is used as a discriminative distance metric to optimise the coupling process. 8
stream networks is presented. • The proposed architecture outperforms existing audio-visual matching methods. • Joint learning of spatial and temporal information using 3D convolution is highly effective. • The extraction of local audio features are shown to be promising for audio-visual recognition using convolutional neural networks. 16
modeling in speech recognition: The shared views of four research groups", IEEE Signal Process. Mag., vol. 29, pp. 82-97, Nov. 2012 [2]Q. V. Le et al., "Building high-level features using large scale unsupervised learning", Proc. IEEE Int. Conf. Acoust. Speech Signal Process., pp. 8595-8598, May 2013 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1]G. Hinton et al., "Deep neural networks for acoustic](https://files.speakerdeck.com/presentations/8783211904be4e9790e8d35d37ee0c6a/slide_16.jpg){kind=link}