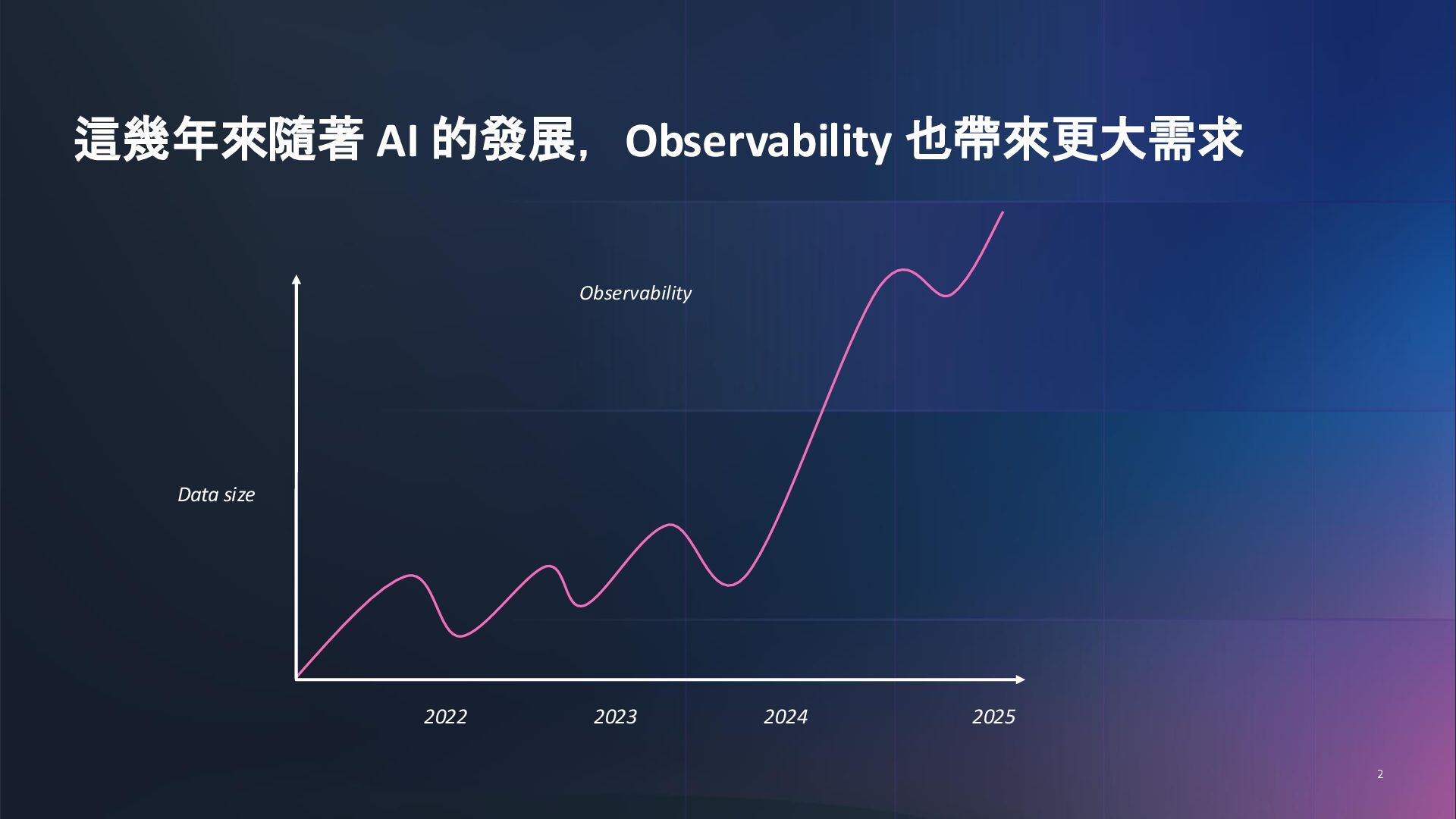
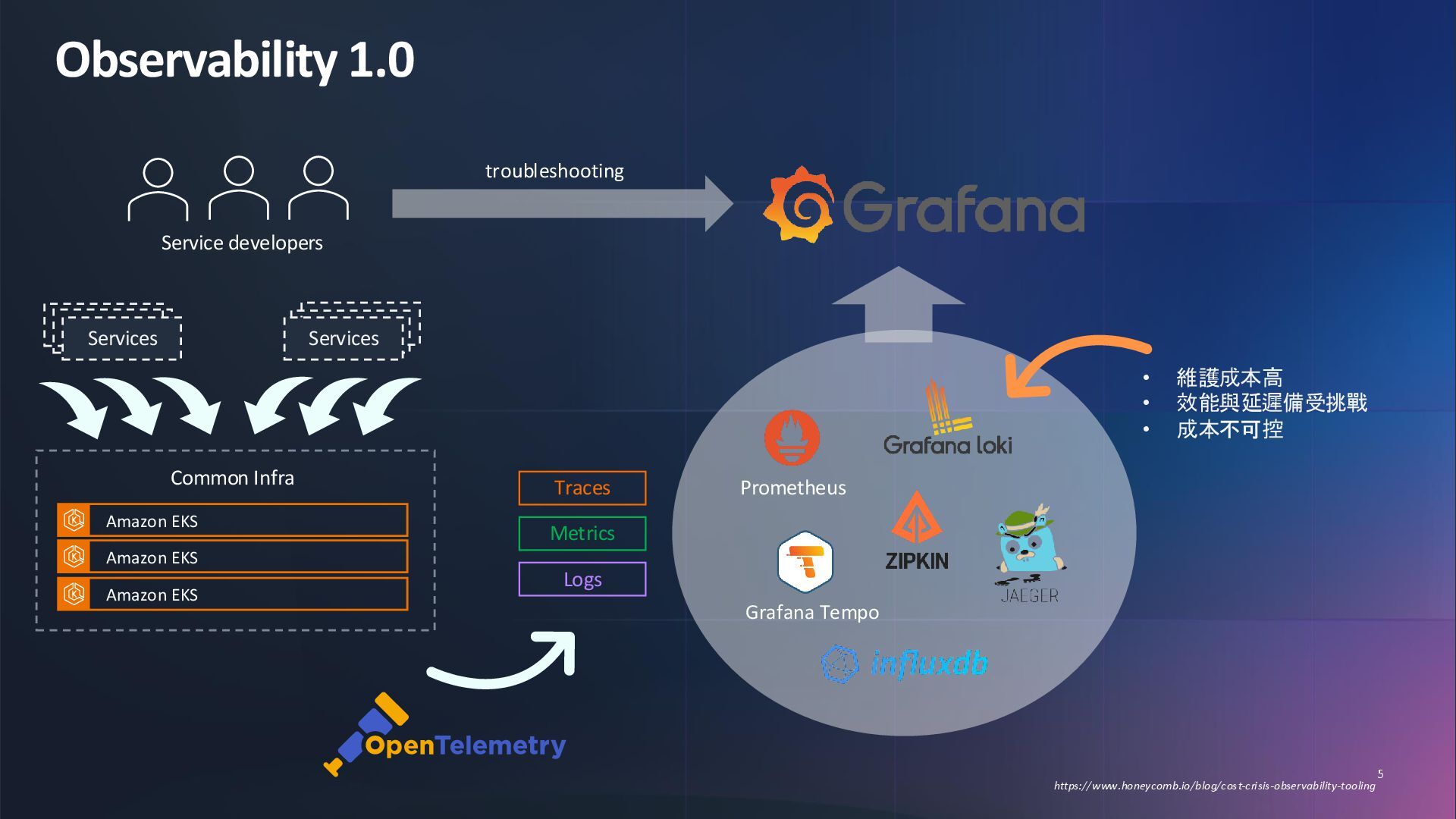
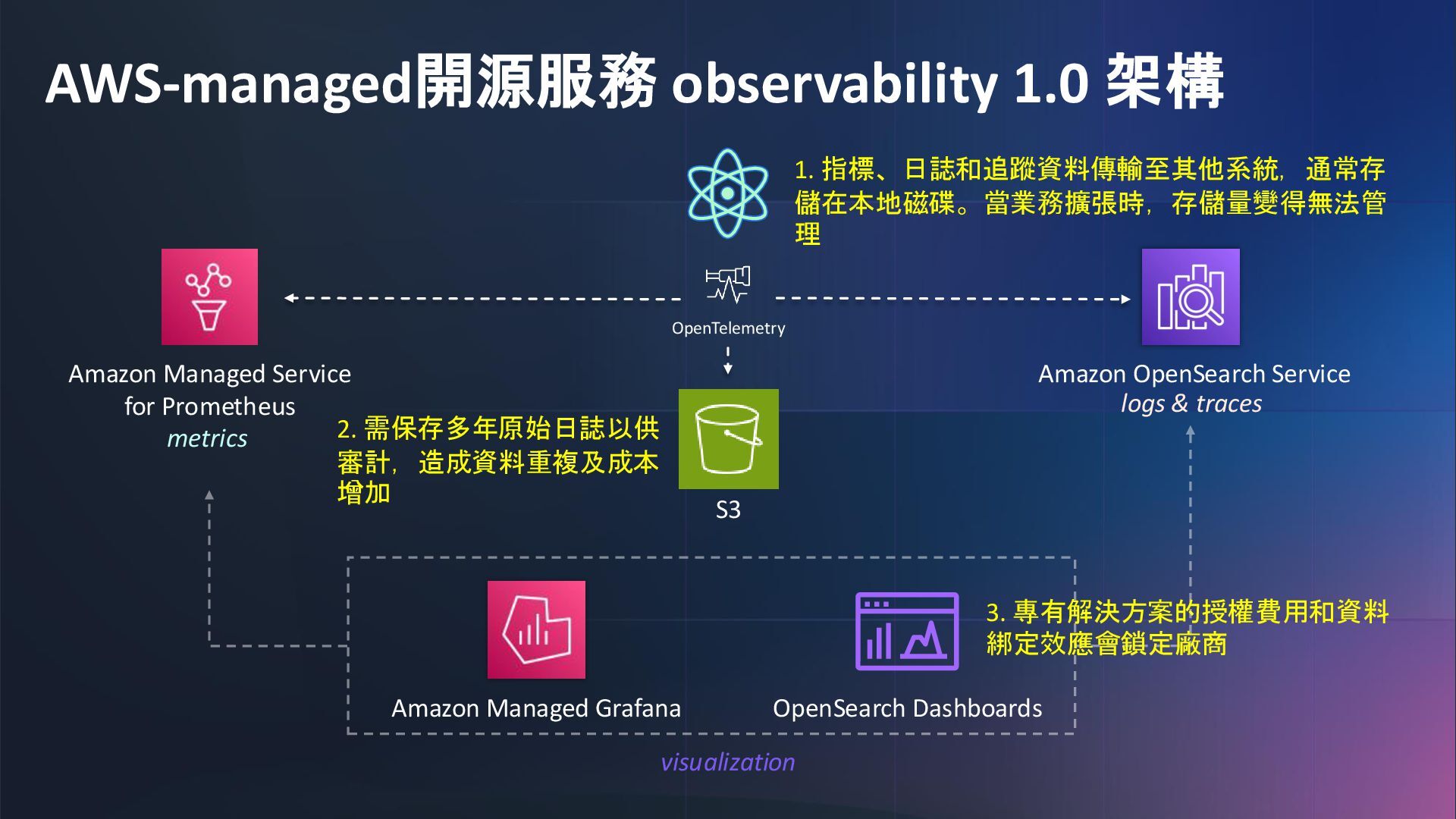
對 GenAI 膩了嗎?在 Observability 的世界悄悄的正在進行一場變革,在這場議程中講者將分享企業中如何面對大型架構下產生的大量 log & metrics 追求更高效率以及低成本的可觀測性,Observability 2.0 的時代即將來臨,你準備好了嗎?
Tired of GenAI? A quiet revolution is taking place in the world of Observability. In this session, the speaker will share how enterprises can achieve more efficient and cost-effective observability when dealing with massive logs and metrics generated from large-scale architectures. The era of Observability 2.0 is coming - are you ready?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
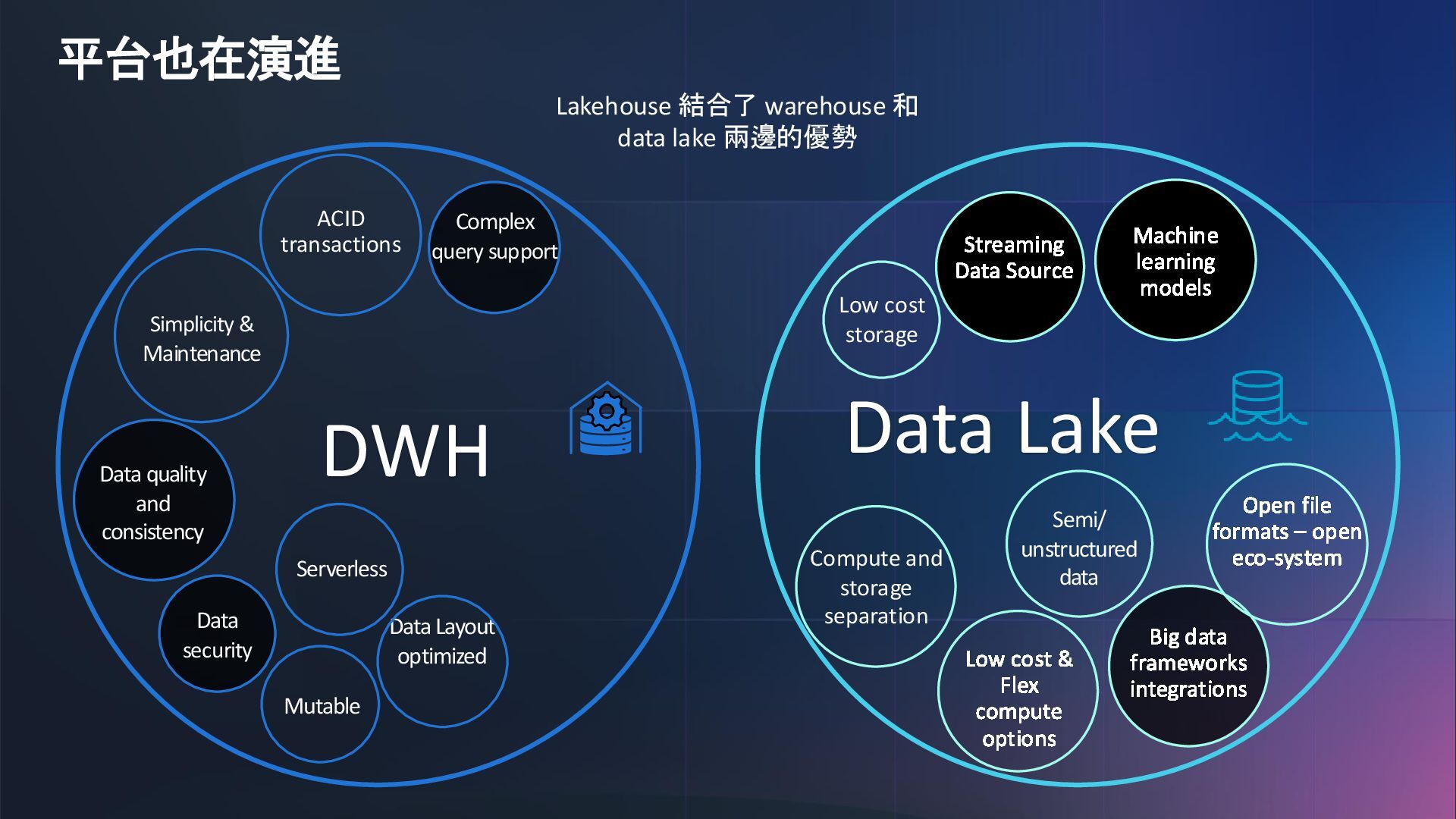{kind=link}
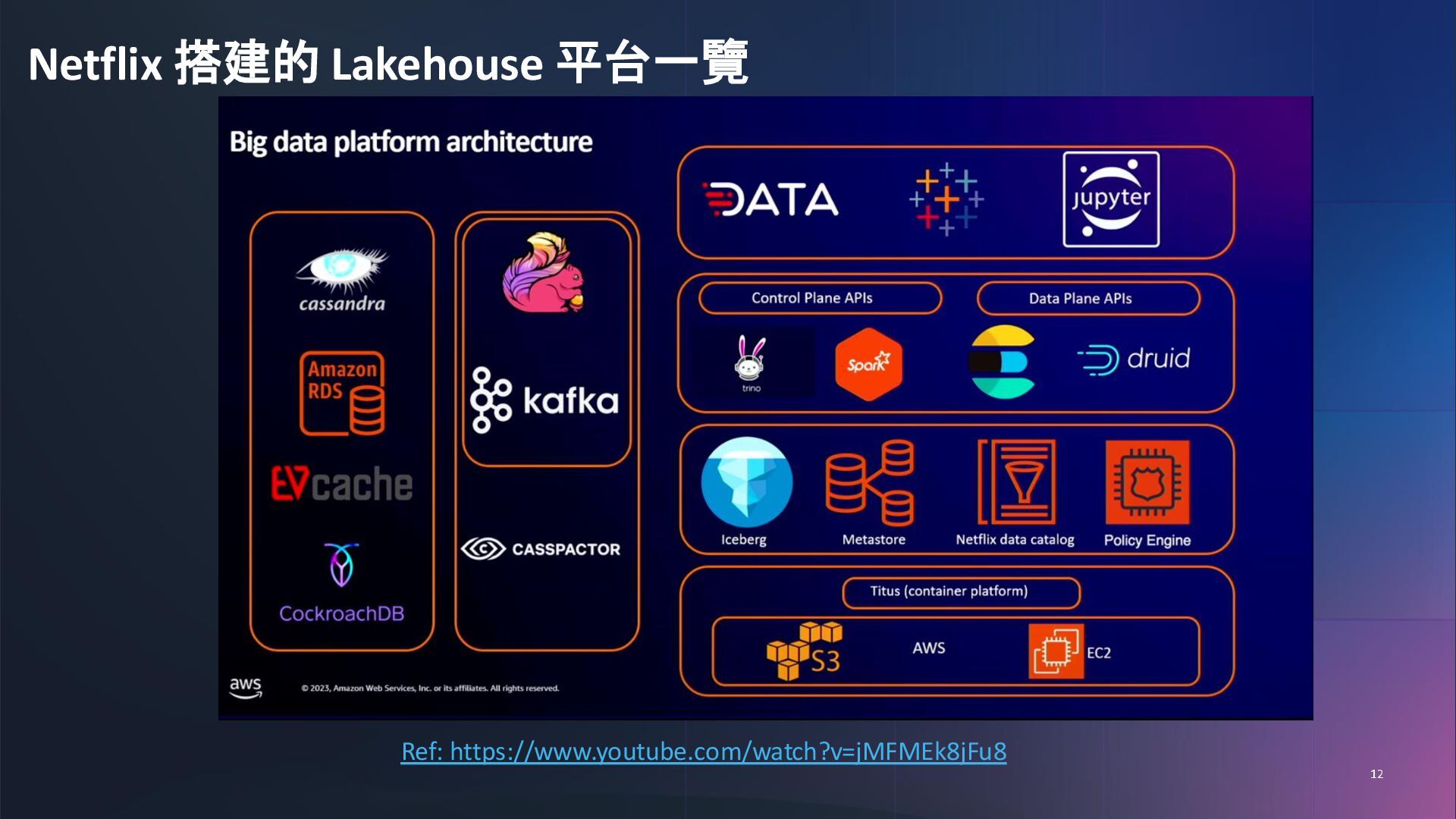{kind=link}
{kind=link}
{kind=link}
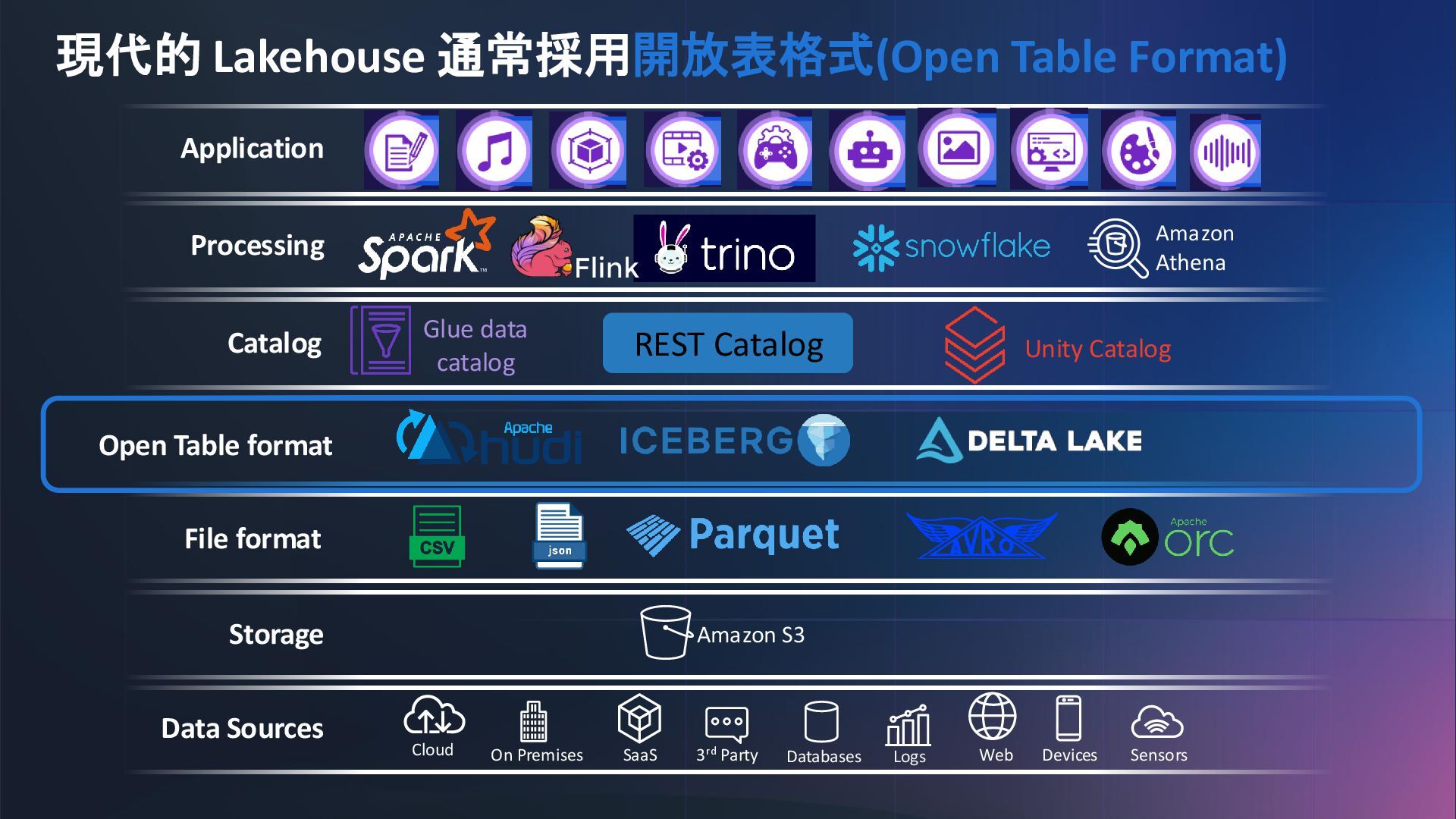{kind=link}
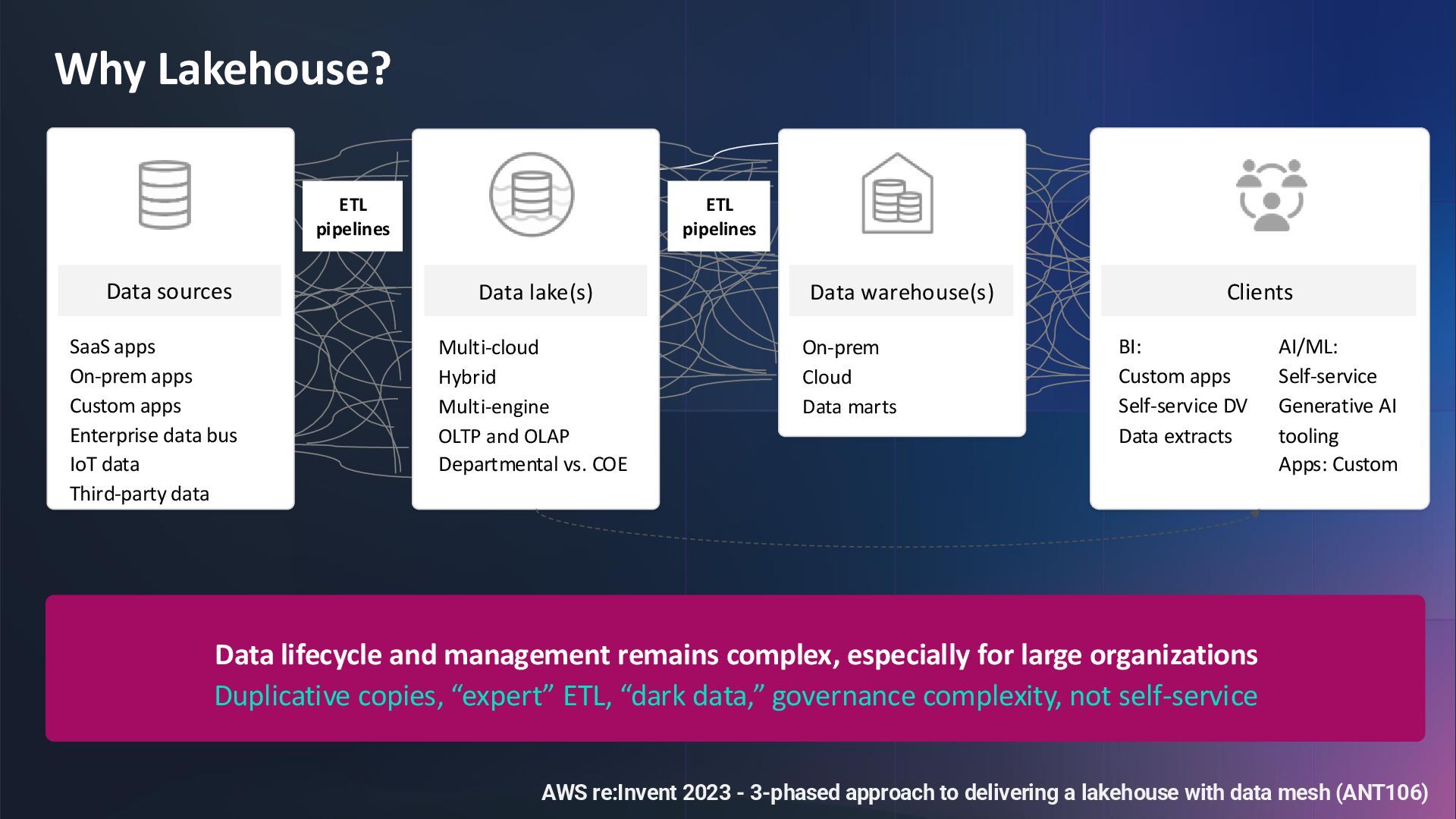{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}