Search a large web corpus – Search a web-search engine – Clueweb12 • Mine other forum datasets – TREC KBA corpus • Spam community maintains lists – Download one • Other?
– Scraping violates TOS – Impractical limits on # of results • inurl operator not implemented by most • Blekko: – query “forumdisplay.php” – 43 unique domains in results – Cost per query too high • Spam-lists – Poor quality of seeds
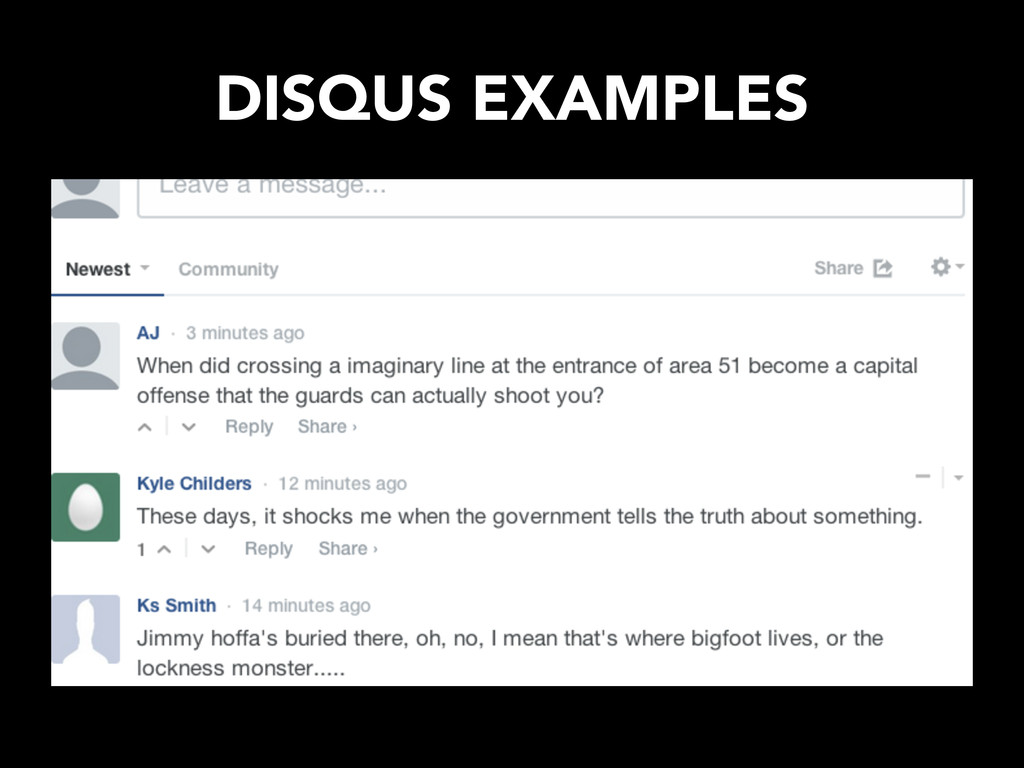
• Mined forum directories (common URL subdomains / domains), large discussion sources • Statistics about scale of crawl needed – ~50,000 discussion forums supplied 30 million discussions – Largest discussion sources are social media sites – vBulletin most used forum software – Largest contributor is 4chan • Truly ephemeral – posts 404 after a certain time period • Impossible for us to crawl
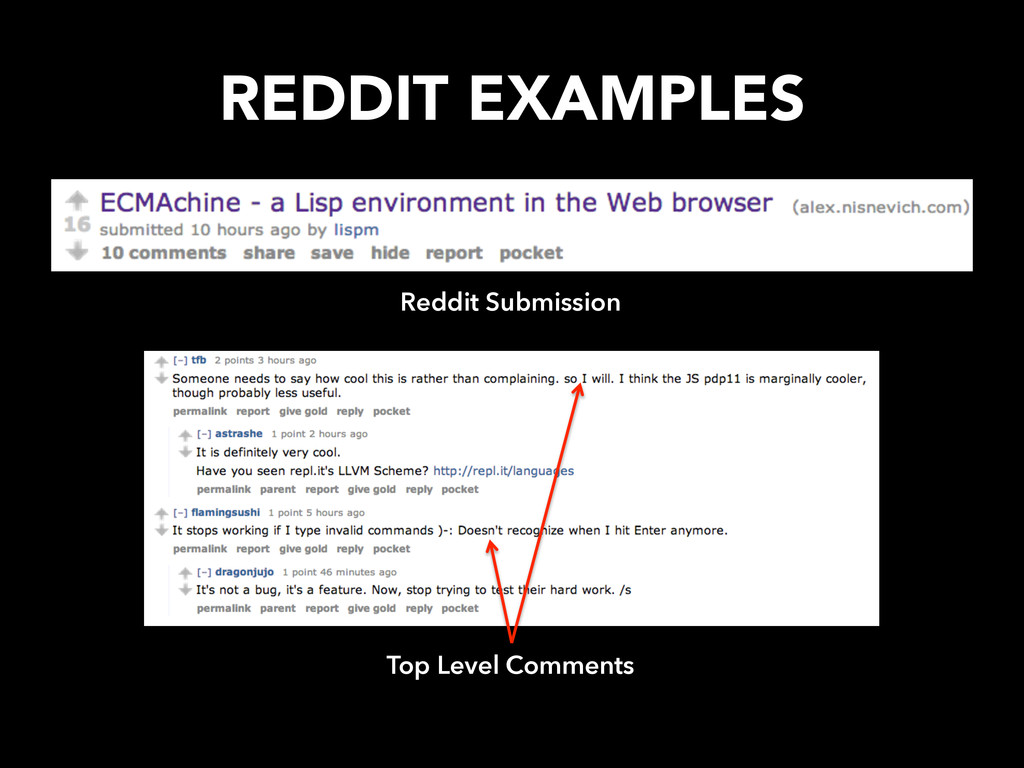
DOESN’T WORK – Content desired is from specific time-frame – Large sites get several hundred entries per hour • Reddit – 200,000 submissions in a week – Need several thousand hops to get content – Massive bandwidth / storage costs
in desired time-range • Forums can be used as CMS • A 2000-hops crawl collects posts, (potentially) articles, blogs and other content that we don’t need from time- frames we are not interested in
to API calls used to extract exactly the data wanted • Issues: – How to store data • Deeply nested data unraveled and stored in relational-db • Flat data stored in flat-files
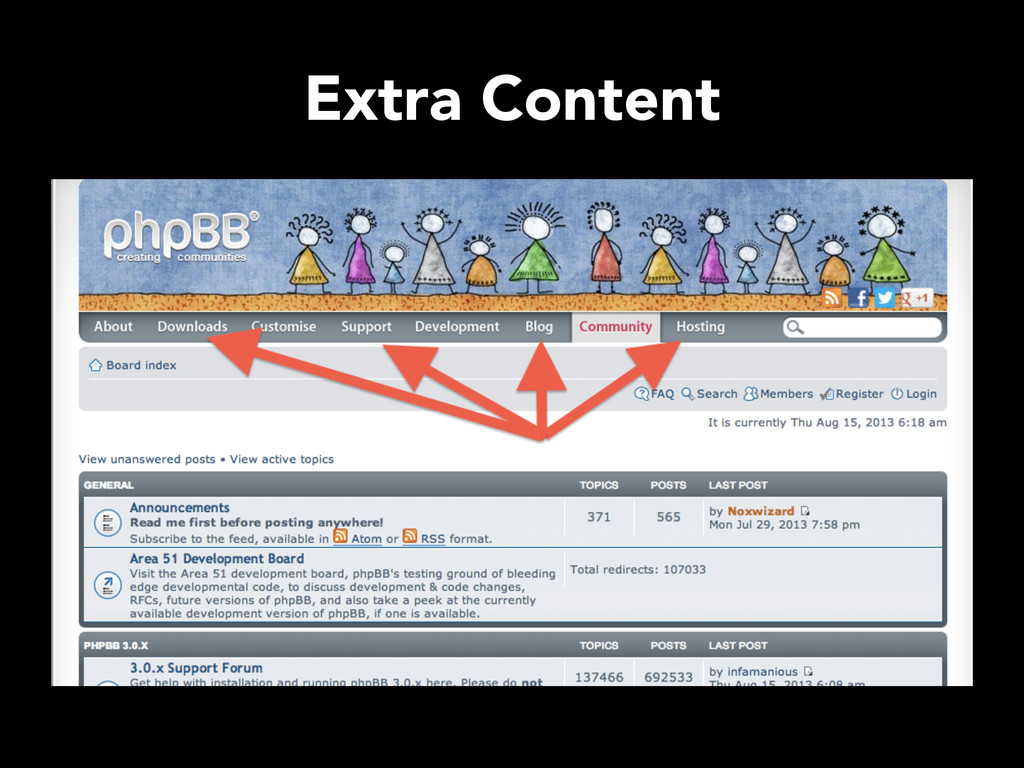
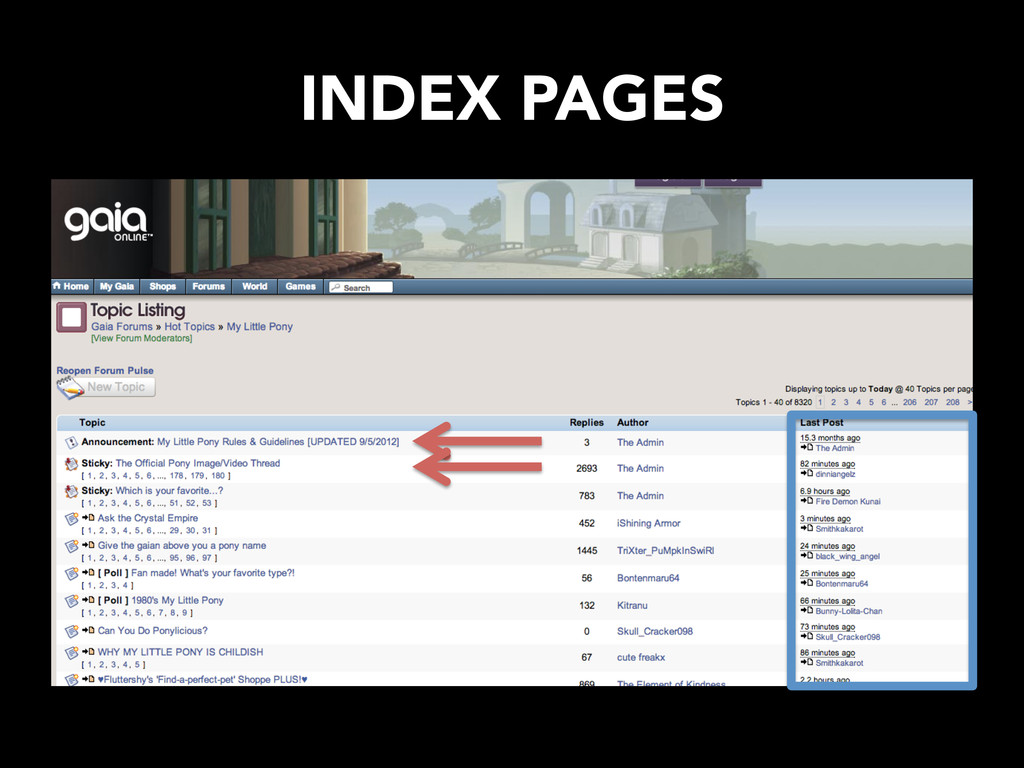
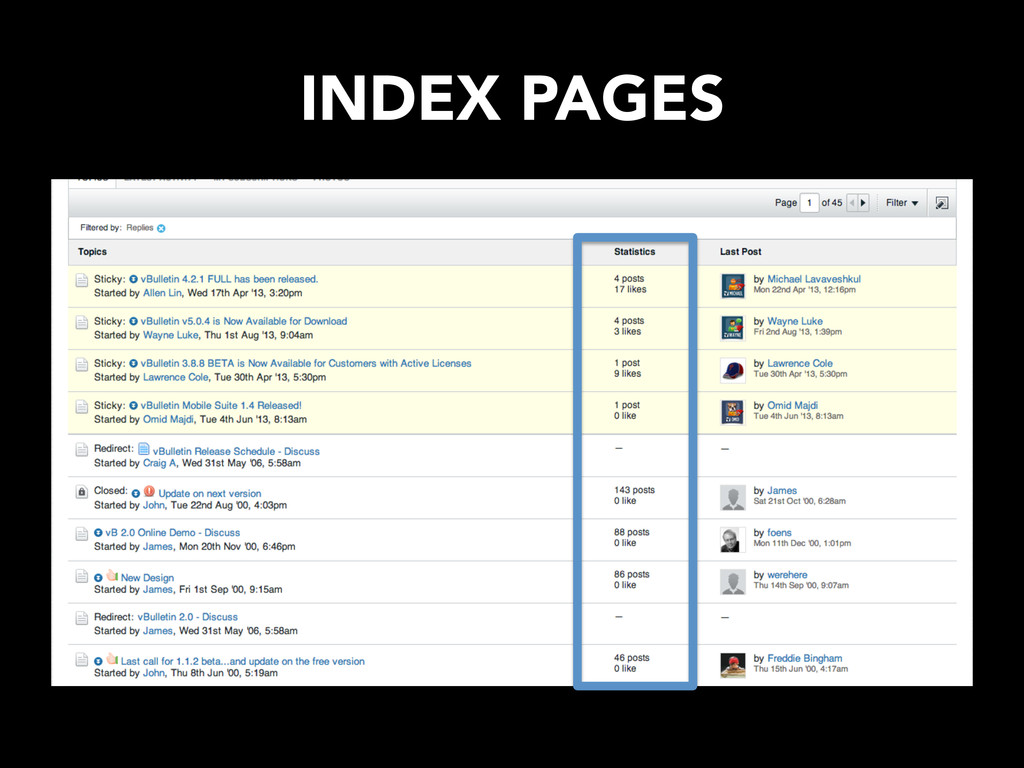
thread.php, t.php, showthread.php • robots.txt: – Points to sitemap.xml – Provides a path for a search-engine bot to follow (update-frequency, path to page) – Index pages have high update frequency • Identify pagination for exhaustive index page crawl
a list of URL modifiers (path / query) that lead to reordering • ?sort=replies , /sort_REPLIES_## , – List built by eyeballing some initial crawls – “prev” page link might be different • Current page: http://a.b.c/pg=3 • Next page: http://a.b.c/pg=4 • Prev page: http://a.b.c/pg=-1 • Not a very frequent problem • But frequent enough to require attention • Not handling these can cause same content to be downloaded 5x or 6x
entire collection of index pages • Yield not gauged till entire index-page set is done – 1 Month of Yahoo Groups crawls led to less than 100,000 posts (very spammy) • Cannot easily distribute this crawl across machines • While index page crawl is running, cannot perform a discussion crawl in parallel (bandwidth restrictions)
![CLUEWEB12++ SHRIPHANI PALAKODETY [email protected]](https://files.speakerdeck.com/presentations/ec1069c0e8d10130d58342aa3a8e614d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS FEATURE-REQUESTS SUGGESTIONS NOW OR OFFLINE ([email protected])](https://files.speakerdeck.com/presentations/ec1069c0e8d10130d58342aa3a8e614d/slide_37.jpg){kind=link}