Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSで実現した大規模日本語VLM学習用データセット "MOMIJI" 構築パイプライン/bu...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
開発室Graph
September 02, 2025
Research
1.5k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSで実現した大規模日本語VLM学習用データセット "MOMIJI" 構築パイプライン/buiding-momiji
Data-Centric AI 勉強会での登壇資料です。
開発室Graph
September 02, 2025
More Decks by 開発室Graph
See All by 開発室Graph
運転動画を検索可能にする〜Cosmos-Embed1とDatabricks Vector Searchで〜/cosmos-embed1-databricks-vector-search
studio_graph
3
1.2k
技術を楽しもう/enjoy_engineering
studio_graph
1
590
めちゃくちゃ悩んでクックパッドに新卒入社して1年経った/newgrads_event2020
studio_graph
7
5.7k
クックパッドでの機械学習開発フロー/ml-ops-in-cookpad
studio_graph
9
15k
DWHを活用した機械学習プロジェクト/ml-with-dwh
studio_graph
6
5.3k
無理をしない機械学習プロジェクト2/step_or_not2
studio_graph
9
11k
知識グラフのリンク予測におけるGANを用いたネガティブサンプルの生成
studio_graph
4
4.2k
機械学習を使ったレシピ調理手順の識別
studio_graph
2
2.2k
Other Decks in Research
See All in Research
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
IA for theory
gpeyre
0
270
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
210
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
110
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
150
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
160
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
Featured
See All Featured
Balancing Empowerment & Direction
lara
6
1.2k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
How to build a perfect <img>
jonoalderson
1
5.8k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
420
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Odyssey Design
rkendrick25
PRO
2
730
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
How to make the Groovebox
asonas
2
2.3k
Transcript
AWSで実現した⼤規模⽇本語VLM 学習⽤データセット “MOMIJI” 構築 パイプライン @stu3dio_graph Turing株式会社 開発部 シニアエンジニア
⾃⼰紹介 2
チューリング株式会社 累計調達額: 68億円 従業員数: 111名 会社概要 事業 完全⾃動運転⾞の開発 基盤AIによる実現を⽬指す 設⽴:
2021年8⽉ 代表取締役: ⼭本⼀成 3
もくじ • 完全⾃動運転のためには • 完全⾃動運転とVLM • MOMIJI の紹介 • MOMIJIパイプラインと課題
• 巨⼤なCommon Crawl • パイプライン詳細 • 並列実⾏ • うまくいったこと/困難だったこと • MOMIJIで学習したVLM 4
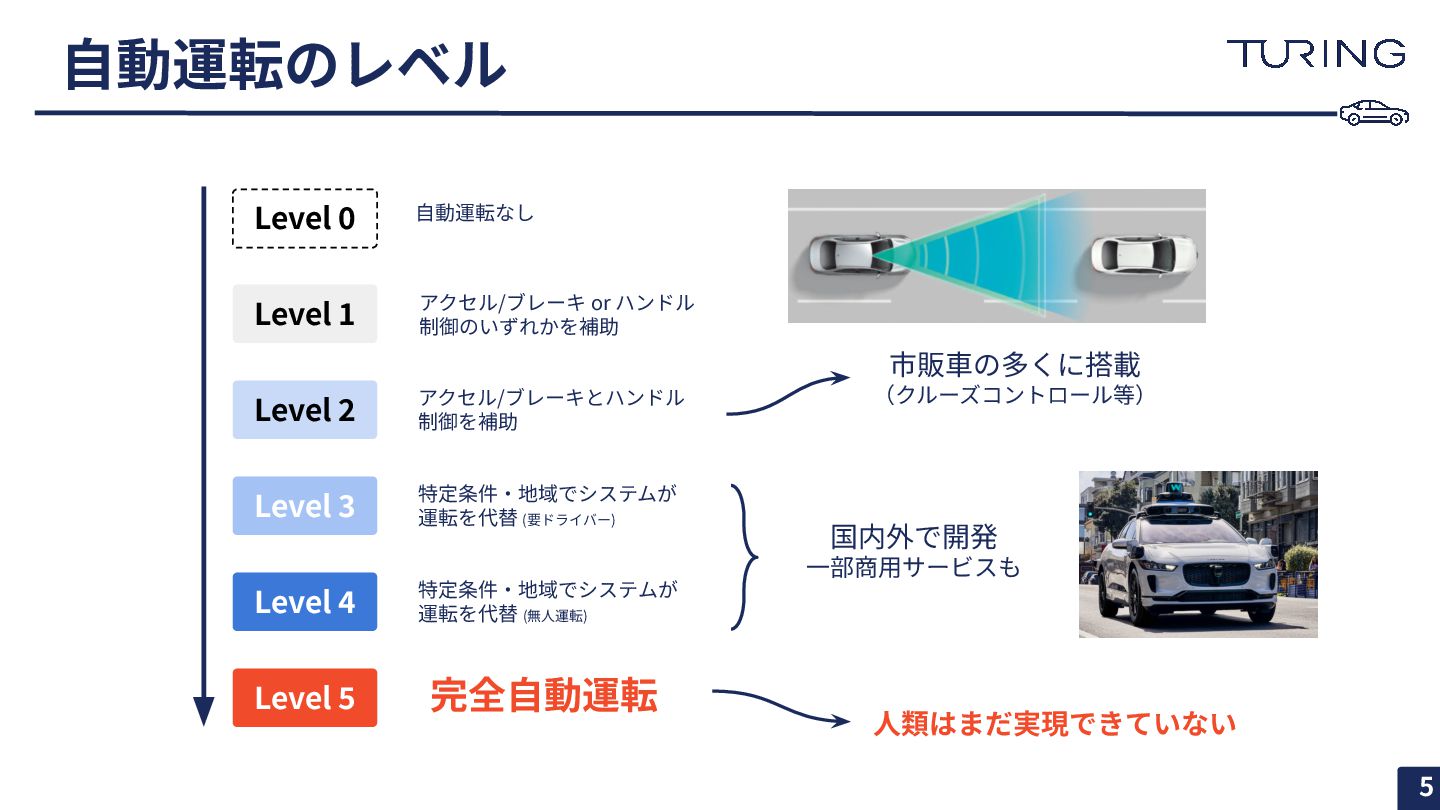
⾃動運転のレベル Level 0 Level 1 Level 2 Level 3 Level
4 Level 5 ⾃動運転なし アクセル/ブレーキ or ハンドル 制御のいずれかを補助 アクセル/ブレーキとハンドル 制御を補助 特定条件‧地域でシステムが 運転を代替 (要ドライバー) 特定条件‧地域でシステムが 運転を代替 (無⼈運転) 完全⾃動運転 市販⾞の多くに搭載 (クルーズコントロール等) 国内外で開発 ⼀部商⽤サービスも ⼈類はまだ実現できていない 5
運転シーンと⼈間の思考 この状況で左折したい どこを見ればよい? 6
運転シーンと⼈間の思考 ローカルの言語 と記号の理解 複雑な三者の 関係の理解 カラーコーン 配置の意味 人間の身体的 指示の理解 人間は無意識のうちに多くの「文
脈」を理解している。 高度な自動運転には 視覚情報と言語的理解 の融合 (=マルチモーダル的理解)が必要 7
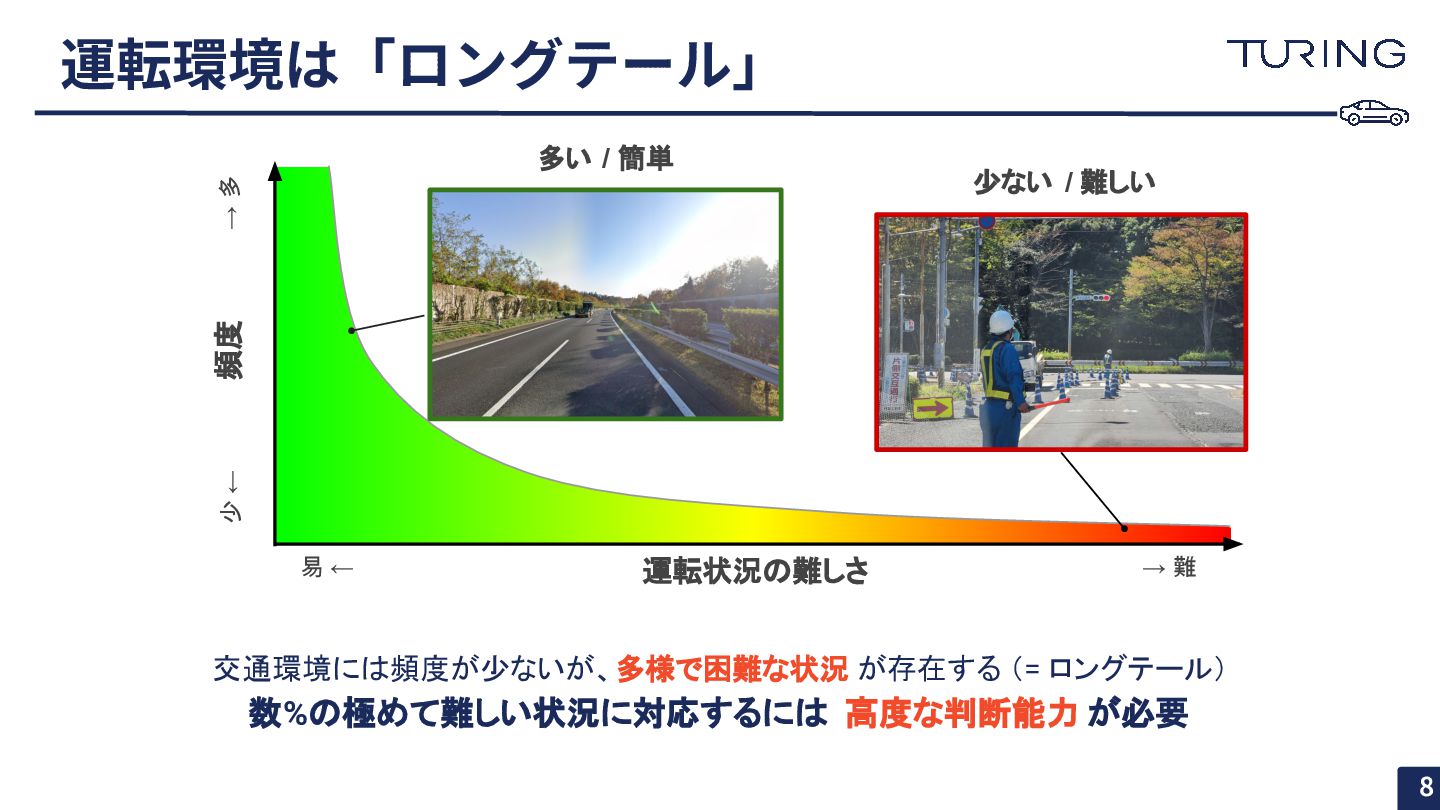
運転環境は「ロングテール」 運転状況の難しさ 頻度 少 ← → 難 易 ← →
多 多い / 簡単 少ない / 難しい 交通環境には頻度が少ないが、多様で困難な状況 が存在する (= ロングテール) 数%の極めて難しい状況に対応するには 高度な判断能力 が必要 8
第3世代の⾃動運転タスク (2023~) 深層学習ベースの自動運転の学習データは、大規模生成 AIをターゲットとした 自然言語による状況理解 に移行しつつある [Li+ 2024] 第1世代 (CNN,
2012~) 第2世代 (Transformer, 2019~) 第3世代 (LLM, 2023~) • 前方カメラ • LiDAR • 複数カメラ • LiDAR • Radar • HDマップ • 周囲カメラ • 言語による質問 /応答 DriveLM [Sima+ 2023] nuScenes [Caesar+ 2019] KITTI [Geiger+ 2012] 9
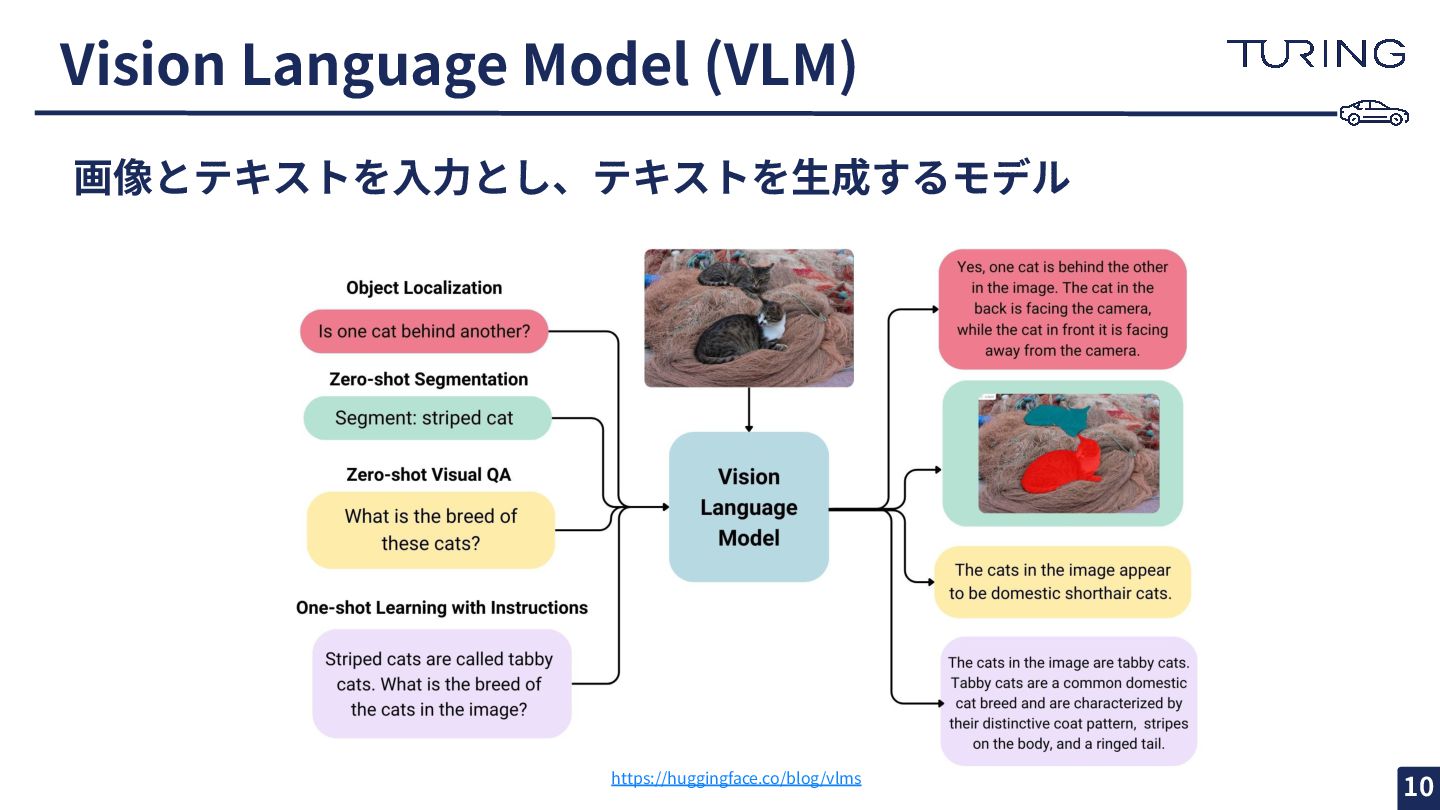
Vision Language Model (VLM) https://huggingface.co/blog/vlms 画像とテキストを⼊⼒とし、テキストを⽣成するモデル 10
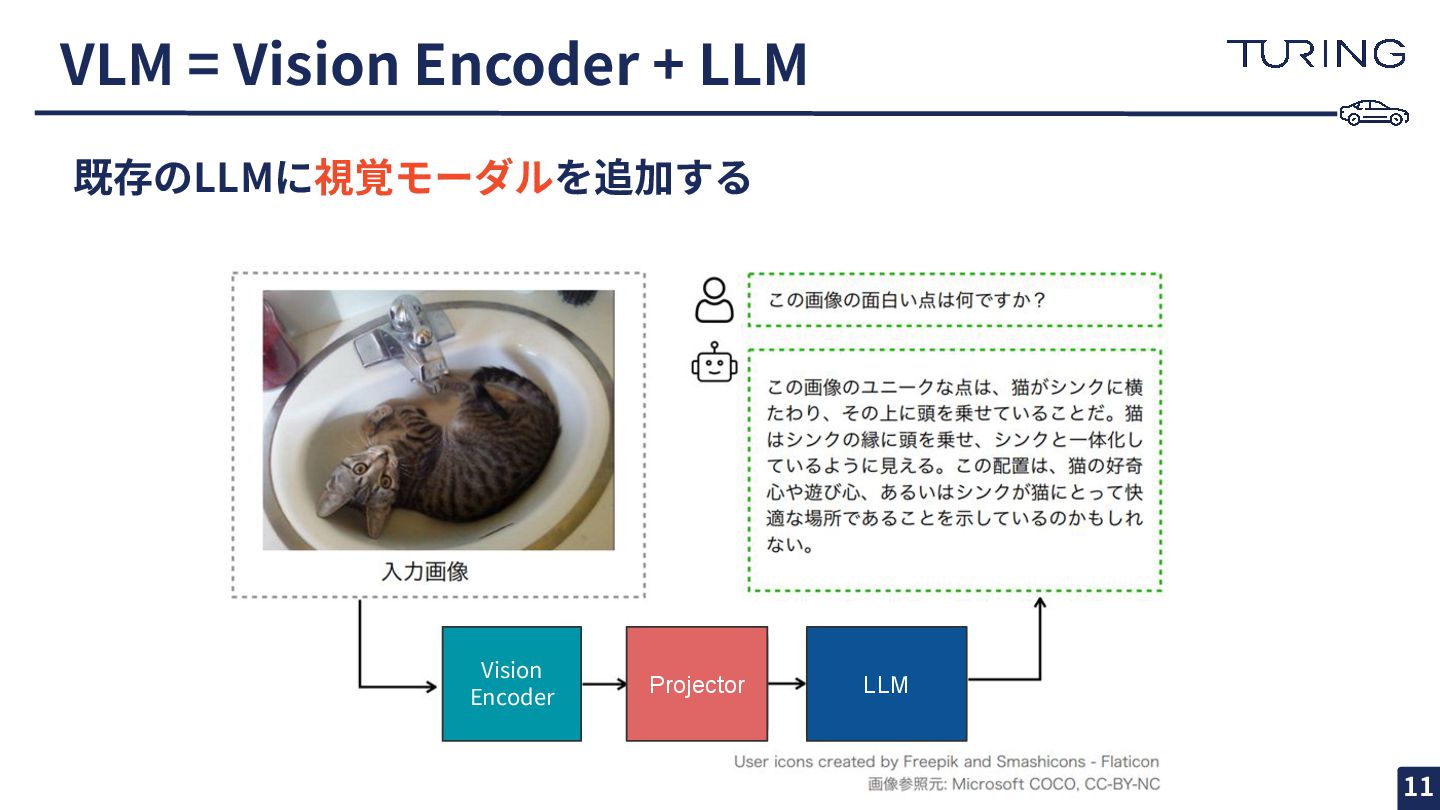
VLM = Vision Encoder + LLM 既存のLLMに視覚モーダルを追加する Vision Encoder Projector
LLM 11
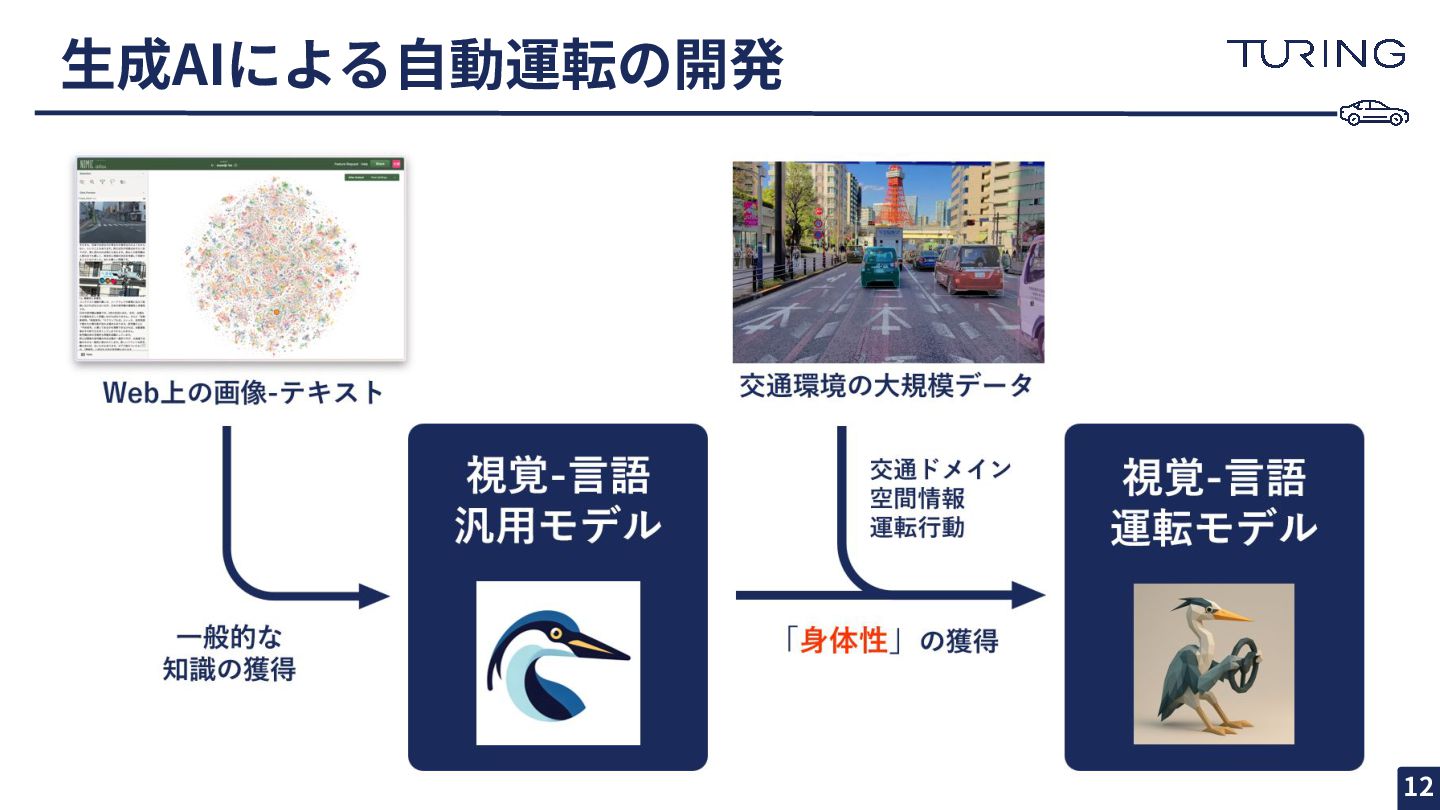
⽣成AIによる⾃動運転の開発 12
完全⾃動運転とVLM • 賢いAIで⾃動運転するには? ◦ 視覚情報と⾔語情報の統合→VLMが有効 • ⾼度なVLMを作るには? ◦ 実世界の情報を備えていることが重要 •
実世界の情報を獲得するには? ◦ ⽇本の運転環境をよく知るデータセットで学習 ◦ ⼤量の画像-テキストデータが必要 ◦ インターネットの網羅性を利⽤する • ⼤量かつ⾼品質な⽇本語 画像-テキストデータセット が必要 13
MOMIJI (Modern Open Multimodal Japanese filtered Dataset) Common Crawl から抽出した⽇本語データセット
• 5,600万Webページ, 2.49億枚の画像を含む⼤規模‧⾼品質な インターリーブ形式 100 万件のデータを⽤いて UMAP で可視化 MOMIJIに含まれるデータ例 14 画像とテキスト が交互に出現
Common Crawl ってなに? • 世界中のWebページをクロールし続ける ⾮営利プロジェクト • 毎⽉テラバイト級のHTMLを収集 • だれでもダウンロードできる形で収集し公開
◦ 実体はS3のpublic bucket (us-west-1) にある ◦ 概ね1ヶ⽉おき程度でスナップショット として公開 • WARCファイル (HTMLページ本⽂+HTTPヘッダ) 15
MOMIJIパイプラインの全体図 • 元となるデータセット(Common Crawl) から段階的にフィルタリング • 段階的に処理を実⾏ ◦ ダウンロード ◦
フィルタリング ◦ パース 16
MOMIJI構築での課題 • 元となるデータセットがペタバイト級で取り回しづらい • 数百万ファイルの画像やテキストをダウンロードし解析 • 処理対象のファイル数も数百万件 ◦ ひとつひとつの処理が軽くても… •
多段なフィルタリング ◦ 順番に適応し管理する必要 • 限られた時間内でデータセットを完成させる必要 ◦ GENIACプロジェクト内での完成 17 →AWS Lambda + Step Functions で構築する
巨⼤なCommon Crawl 18 スナップショットの1つ CC-MAIN-2025-05 の例 • 1スナップショットで100TB弱 ◦ 1年分処理しようとするとダ
ウンロードだけで1PB超え • 巨⼤なCommon Crawl全体を どう効率よくフィルタリングす るかが重要
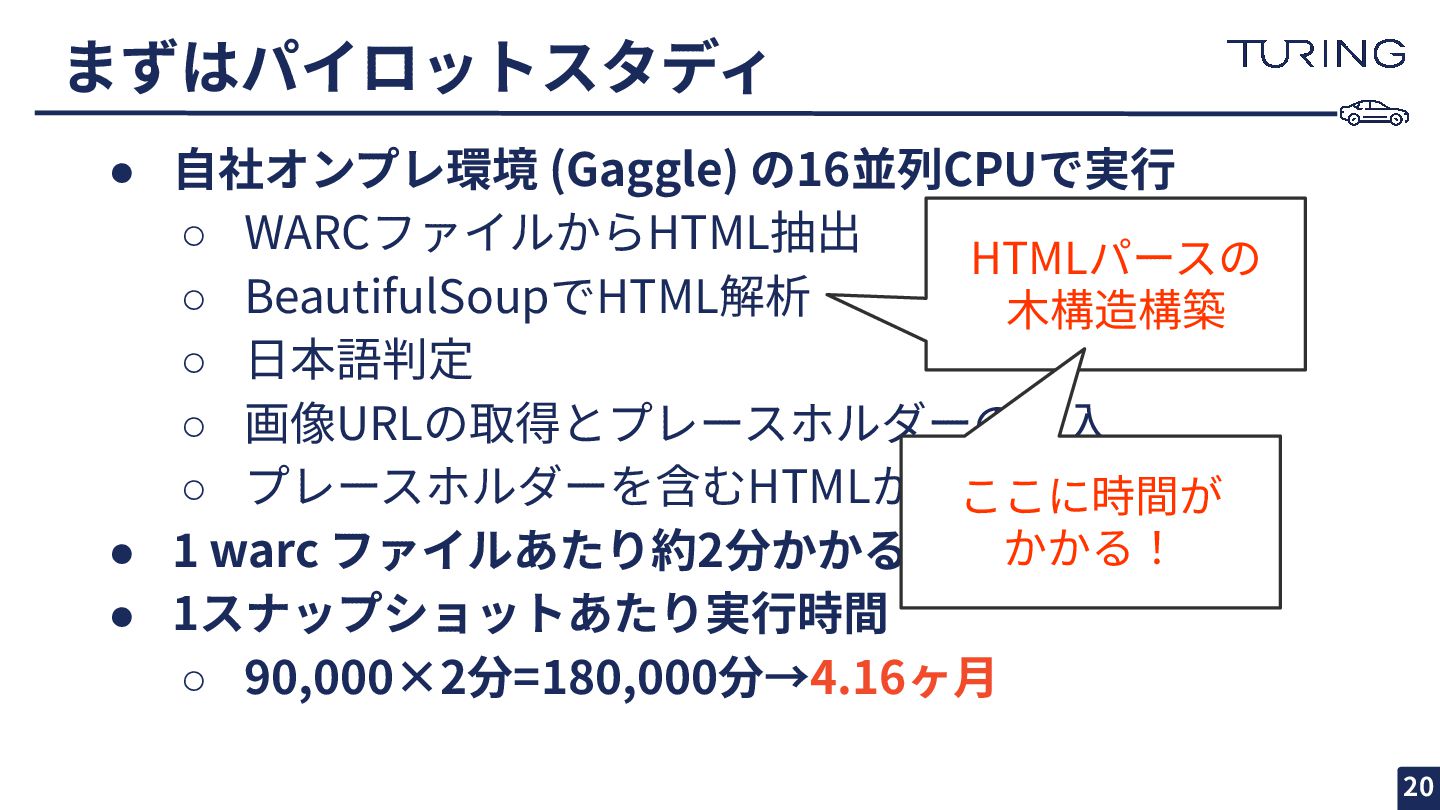
まずはパイロットスタディ • ⾃社オンプレ環境 (Gaggle) の16並列CPUで実⾏ ◦ WARCファイルからHTML抽出 ◦ BeautifulSoupでHTML解析 ◦
⽇本語判定 ◦ 画像URLの取得とプレースホルダーの挿⼊ ◦ プレースホルダーを含むHTMLからテキスト抽出 • 1 warc ファイルあたり約2分かかることがわかった • 1スナップショットあたり実⾏時間 ◦ 90,000×2分=180,000分→4.16ヶ⽉ 19
まずはパイロットスタディ • ⾃社オンプレ環境 (Gaggle) の16並列CPUで実⾏ ◦ WARCファイルからHTML抽出 ◦ BeautifulSoupでHTML解析 ◦
⽇本語判定 ◦ 画像URLの取得とプレースホルダーの挿⼊ ◦ プレースホルダーを含むHTMLからテキスト抽出 • 1 warc ファイルあたり約2分かかることがわかった • 1スナップショットあたり実⾏時間 ◦ 90,000×2分=180,000分→4.16ヶ⽉ 20 HTMLパースの ⽊構造構築 ここに時間が かかる!
⾼速に⽇本語以外を捨てる • Common Crawl に⽇本語は5%程度しか含まれない ◦ ⽇本語以外を捨てればその後の処理を減らせる • まずは簡易かつ⾼速な⽇本語判定で量を減らす ◦
下流でより⾼精度な⽇本語判定をすれば⼗分 • 簡易な⽇本語判定 ◦ ⽇本語で書かれているWebページはひらがな, カタカナ, 漢字のいずれかを含むはず ◦ HTMLの lang タグは未設定もあり不⼗分 ◦ 実際には中国語, 韓国語, 多⾔語圏を含むが⾼速 ◦ Python標準ライブラリの正規表現だけで動作 • 並列化なしで1warcファイルあたり2分で動作 21
フィルタリングパイプライン設計 • ひとつひとつの処理は軽いが⼤量のデータが存在 ◦ クラウド環境で処理するのに向いている • AWS Lambda + AWS
Step Functions で設計 ◦ Common Crawl の実体がS3にある ◦ 1 warc file が 1 URL を持っており静的 ◦ 多段のフィルタリングが必要 ◦ 簡単に並列度を数千程度まで上げられる ◦ 設計がシンプルで済む • AWS Batch / ECS Fargate や EMR /Glueを使うことも検討 ◦ I/O待ちがなくS3を読み書きすればOK ◦ 再実⾏もURL単位で⼗分 22
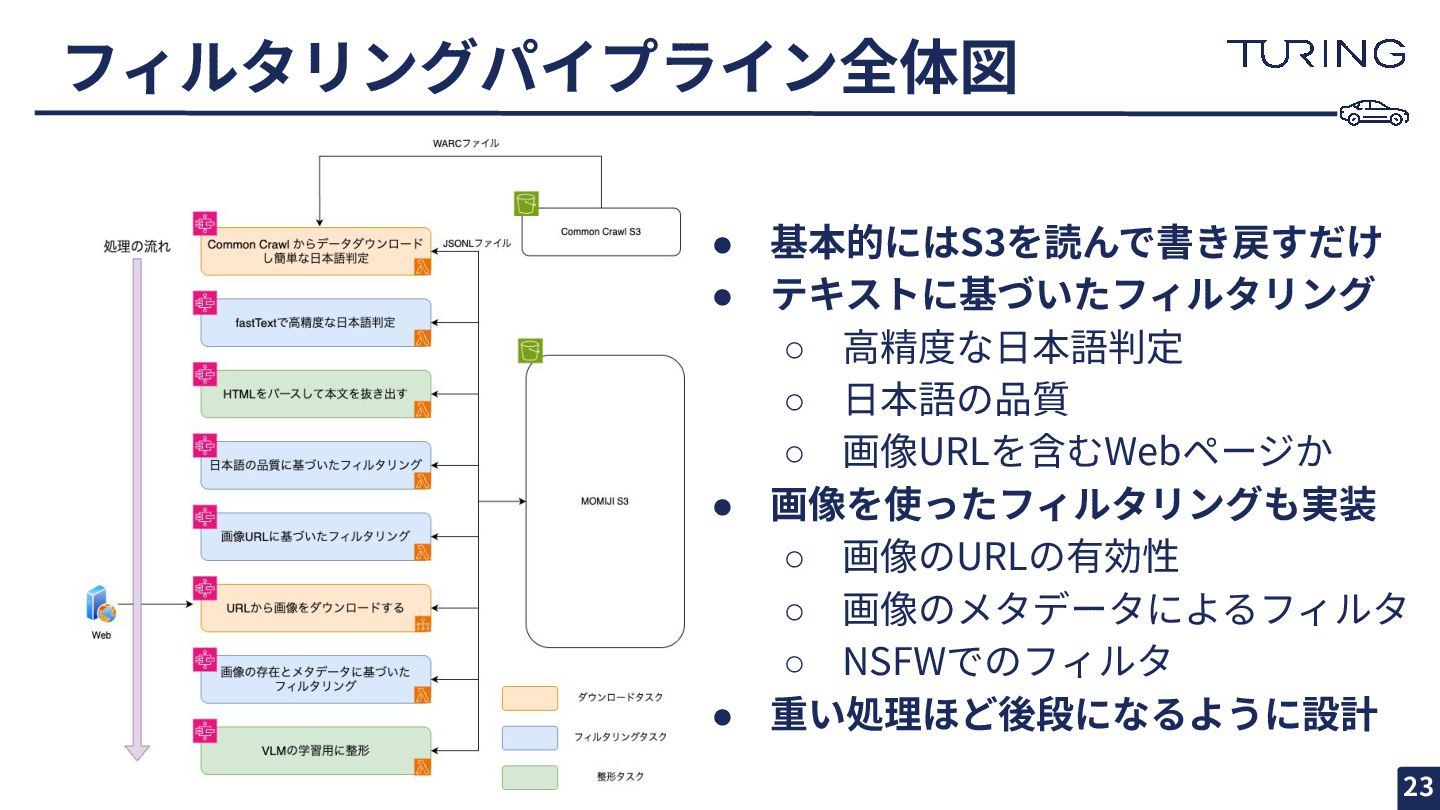
フィルタリングパイプライン全体図 23 • 基本的にはS3を読んで書き戻すだけ • テキストに基づいたフィルタリング ◦ ⾼精度な⽇本語判定 ◦ ⽇本語の品質
◦ 画像URLを含むWebページか • 画像を使ったフィルタリングも実装 ◦ 画像のURLの有効性 ◦ 画像のメタデータによるフィルタ ◦ NSFWでのフィルタ • 重い処理ほど後段になるように設計
パイプライン内部実装 • パイプライン内部は⾮常に シンプル ◦ S3のURLを受け取る ◦ ファイルダウンロード ◦ フィルタリング実⾏
◦ ファイルに書き出して圧縮 ◦ S3にファイルアップロード • フィルタリング処理以外はすべ て共通 ◦ クラスに切り出して取り回 しやすく 24
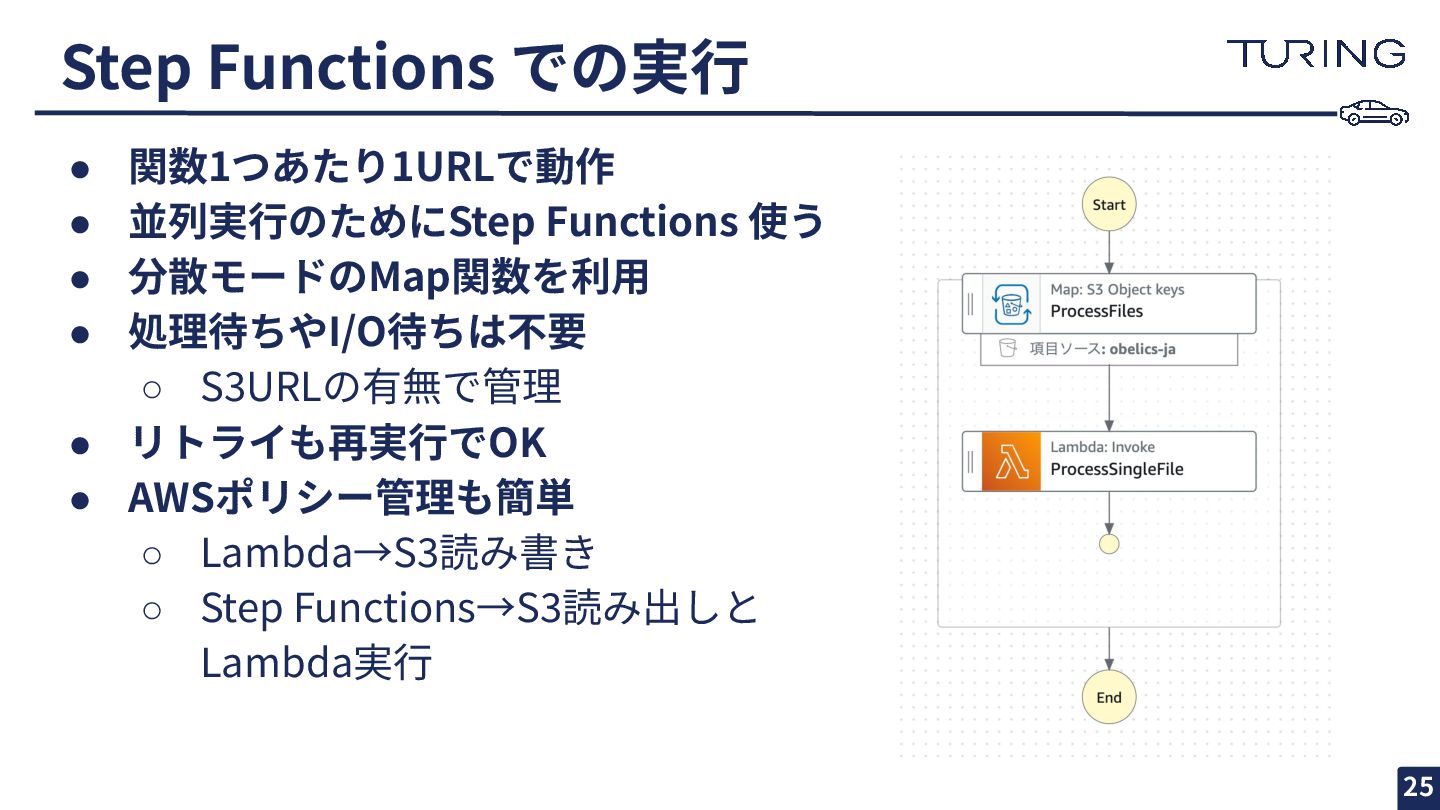
Step Functions での実⾏ • 関数1つあたり1URLで動作 • 並列実⾏のためにStep Functions 使う •
分散モードのMap関数を利⽤ • 処理待ちやI/O待ちは不要 ◦ S3URLの有無で管理 • リトライも再実⾏でOK • AWSポリシー管理も簡単 ◦ Lambda→S3読み書き ◦ Step Functions→S3読み出しと Lambda実⾏ 25
⾼い並列度での実⾏ • StepFunctionsを呼び出す StepFunctionsを実装 • 4,000並列でLambdaを実⾏ • 1スナップショットあたり 6-8.5時間で完了 ◦
画像ダウンロードを含む • MOMIJIは⼤規模データセット ◦ 11スナップショットで構成 ◦ 計算時間としては 4営業⽇程度 26
うまくいったこと • パイプライン設計と実装 ◦ フィルタリングの処理の単位にうまく分けたこと ◦ 処理同⼠の依存がなかったこと • いきなり⼤量のwarcファイルを処理しようとしない ◦
まずは1warcファイルで実験し⾒積もる ◦ 1warcファイルごとのLambda関数として実装したこ と • パイプラインごとの依存を減らして並列度⾼く 実⾏できた 27
困難だったこと • Pythonライブラリや環境の依存問題 ◦ Lambda環境でうまく動かないライブラリが存在 ◦ 並列処理はLambdaランタイムでは利⽤できない ▪ ライブラリによっては要求してくるものも ◦
Dockerfileやモンキーパッチで解決 ◦ 研究関連ライブラリはメンテされていないものも 多い • 設計段階で察知するのは⾮常に困難 28
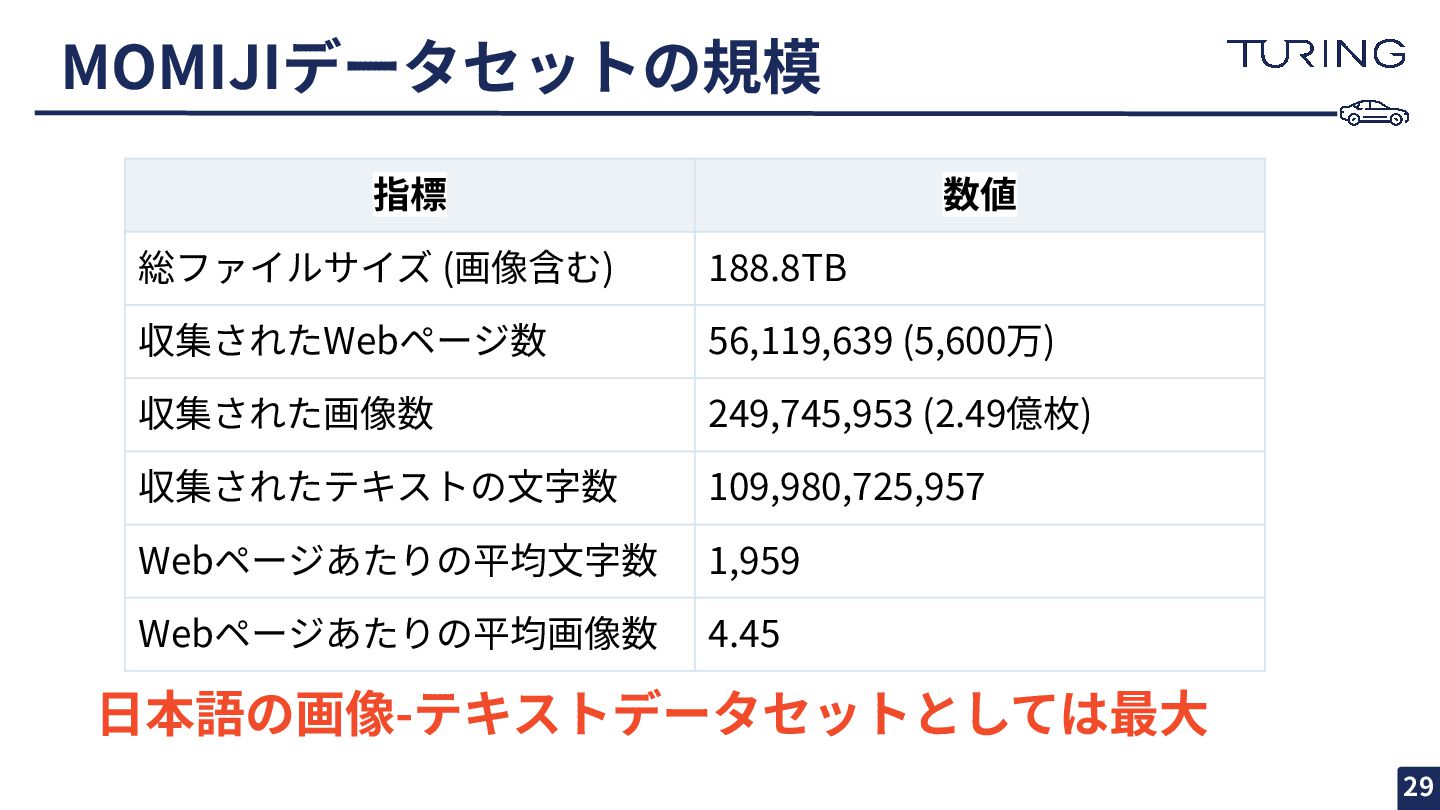
MOMIJIデータセットの規模 29 指標 数値 総ファイルサイズ (画像含む) 188.8TB 収集されたWebページ数 56,119,639 (5,600万)
収集された画像数 249,745,953 (2.49億枚) 収集されたテキストの⽂字数 109,980,725,957 Webページあたりの平均⽂字数 1,959 Webページあたりの平均画像数 4.45 ⽇本語の画像-テキストデータセットとしては最⼤
30 • 視覚-⾔語モデルHeron-NVILA-14B を学習 • HeronVLM Leaderboard 4.88とこれまでのHeron (2.81) を⼤幅に上回る性能を達成
◦ オープンな⽇本語VLMでは最⾼クラスに この場所の制限速度は40キロメートル 毎時(km/h)です。 Q: この場所における制限速度はいくつですか? 現在地からニセコまでは12kmです。 Q: 現在地からニセコまで何kmでしょうか? 視覚-⾔語モデル 「Heron」
⽇本語ベンチマーク評価 llm-jp-eval-mm (gpt-4o-2024-11-20) で評価 31
まとめ • 完全⾃動運転のためには賢いVLMが必要 ◦ 視覚情報と⾔語的理解の融合 • ⽇本の運転環境をよく知るデータセットでの学習が必要 • Common Crawl
から⾼品質な⽇本語-画像テキストデー タセット「MOMIJI」を構築 ◦ 軽いフィルタを上流,重いフィルタを下流へ ◦ AWSをフル活⽤し効率的かつ⾼い並列度で構築 • MOMIJIで学習した Heron-NVILA-14Bの性能 ◦ オープンな⽇本語VLMとして最⾼クラスの性能 32
参考資料 • Common Crawl - Open Repository of Web Crawl
Data https://commoncrawl.org/ • Webスケールの⽇本語-画像のインターリーブデータセット 「MOMIJI」の構築 /巨⼤テキストデータをAWSで⾼速に処理す るパイプライン https://zenn.dev/turing_motors/articles/37903518293c40 • ⽇本語VLM「Heron-NVILA」公開 ─ Qwen2.5-VL-7B‧Gemma3-12Bに匹敵する性能 https://zenn.dev/turing_motors/articles/7ac8ebe8756a3e 33
We’re Hiring ❤ https://tur.ing/jobs 34
35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![第3世代の⾃動運転タスク (2023~) 深層学習ベースの自動運転の学習データは、大規模生成 AIをターゲットとした 自然言語による状況理解 に移行しつつある [Li+ 2024] 第1世代 (CNN,](https://files.speakerdeck.com/presentations/379dee7d1b754ba0b2d85a738b1c3ddc/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}