Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
顧客体験を加速させるチャットボットで始めるAIエージェント入門 / Introduction ...
Search
shuntaka
November 27, 2025
4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
顧客体験を加速させるチャットボットで始めるAIエージェント入門 / Introduction to AI Agents: Starting with Chatbots to Accelerate Customer Experience
shuntaka
November 27, 2025
More Decks by shuntaka
See All by shuntaka
GitHub Copilot CLI が マッスルに馴染むまで / Until GitHub Copilot CLI Becomes Second Nature
shuntaka
1
14k
Claude Code活用時のつらみと隙間を埋めるツール / Tools to bridge the gaps and pains of using Claude Code
shuntaka
0
15k
CloudFront OAC × Lambda Function URLs で作る認証付き簡易サイト / Simple Authenticated Website Built with CloudFront OAC and Lambda Function URLs
shuntaka
0
3.9k
AI SDKで作るチャットボット開発 / Chatbot Development with AI SDK
shuntaka
0
1.8k
Claude Codeチーム活用の現在地 〜小さな実践と今後の展望〜 / Current State of Claude Code Team Adoption - Small Practices and Future Prospects
shuntaka
2
8.6k
Claude Codeをdotfiles管理しよう! / Let's Manage Claude Code with Dotfiles!
shuntaka
8
21k
個人プロジェクトをKiroベースに 乗り換えてみた / I Tried Migrating My Personal Project to Kiro-based
shuntaka
0
2.9k
AI駆動開発がもたらす革新と実践 / Innovation and Practice Brought by AI-Driven Development
shuntaka
2
2.3k
リモートMCP + MCP業務取り組み例 / Remote MCP + MCP Business Initiative Examples
shuntaka
0
2.3k
Featured
See All Featured
A designer walks into a library…
pauljervisheath
211
24k
From π to Pie charts
rasagy
0
240
Prompt Engineering for Job Search
mfonobong
0
380
Exploring anti-patterns in Rails
aemeredith
3
450
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
640
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Thoughts on Productivity
jonyablonski
76
5.3k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Making the Leap to Tech Lead
cromwellryan
135
10k
Transcript
2025/11/27 髙橋 俊⼀ (a.k.a shuntaka) 顧客体験を加速させるチャットボッ トで始めるAIエージェント⼊⾨
⾃⼰紹介 2 • 2016年 ⾦融情報ベンダー⼊社 バックエンド ◦ 株価配信Web API開発 • 2019年 クラスメソッド⼊社
◦ CX/IoT事業部にてIoT案件を複数 • 2024年 製造ビジネステクノロジー部担当 ◦ R&D業務/サーバーサイド/RAG/AI Agent開発 • 部署 ◦ 製造ビジネステクノロジー部 • 名前(shuntaka) ◦ 髙橋 俊⼀ • 出⾝‧住まい ◦ 東京 詳細はhttps://shuntaka.dev/whoを⾒てね
⽬次 3 ‧AIエージェントとは ‧AIエージェントとチャットボット ‧事例①: 業務⽀援のPoC (4⽉頃 ~ 現在) ‧事例②:
SaaS組み込みのプロダクト開発(7⽉頃 ~ 現在) ‧まとめ
注意事項 4 事例の温度感としては以下です。まだ初歩的な内容です 🔰 ‧約1⼈でアプリ、インフラ含めて構築するくらい規模感 ‧構築期間 ‧事例①: 1週間で構築、PoCの段階で現在も利⽤中 ‧事例②: 4ヶ⽉の製品開発で来年リリース予定(精度評価は本格的にまだ)
‧記憶(メモリ)、コード実⾏などは未利⽤
AIエージェントとは
AIエージェントとは 6 自律的を分解すると Reasoning(推論) + Action(行動) という要素がより強い [GoogleCloud|AI エージェントとは](https://cloud.google.com/discover/what-are-ai-agents) 簡単に言えば自律的に目標を達成
するために行動できるAIシステム [OpenAI AGI 5段 階](https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-su perintelligent-ai) アシスタントとエージェントの境界は 特に連続的でグラデーションがあると 言える
AIエージェントとチャットボット
AIエージェントとチャットボット 8 AIエージェントは高度なタスクをこなせるので表現の幅も大きいです。 プロダクトに組み込むならチャットアプリ+MCPより体験が良いものにしたい。 クライアント、サーバともにここら辺の体験向上をサポートしてくれるSDKがあります。今回 は簡単に2つ紹介します。 ・AI SDK ・CopilotKit
AI-SDK 9 ‧TypeScript向けAIツールキット ‧Next.jsの開発元のVercelが提供 ‧AIプロダクト構築に必要な機能を揃えたOSS SDK ‧⼤体9ヶ⽉毎にv1→v3 v3→v4 v4→v5と約9ヶ ⽉ごとにメジャーが進み、機能とAPI設計が継
続的に最適化 メジャー リリース時期 ※1 v1 2023-06-15 v2 2023年後半 ~ 2024年初頭 v3 2024-03-01 v4 2024-11-18 v5 2025-07-31 ※ 公開告知を参考としており、Alpha/Beta段階は含みません
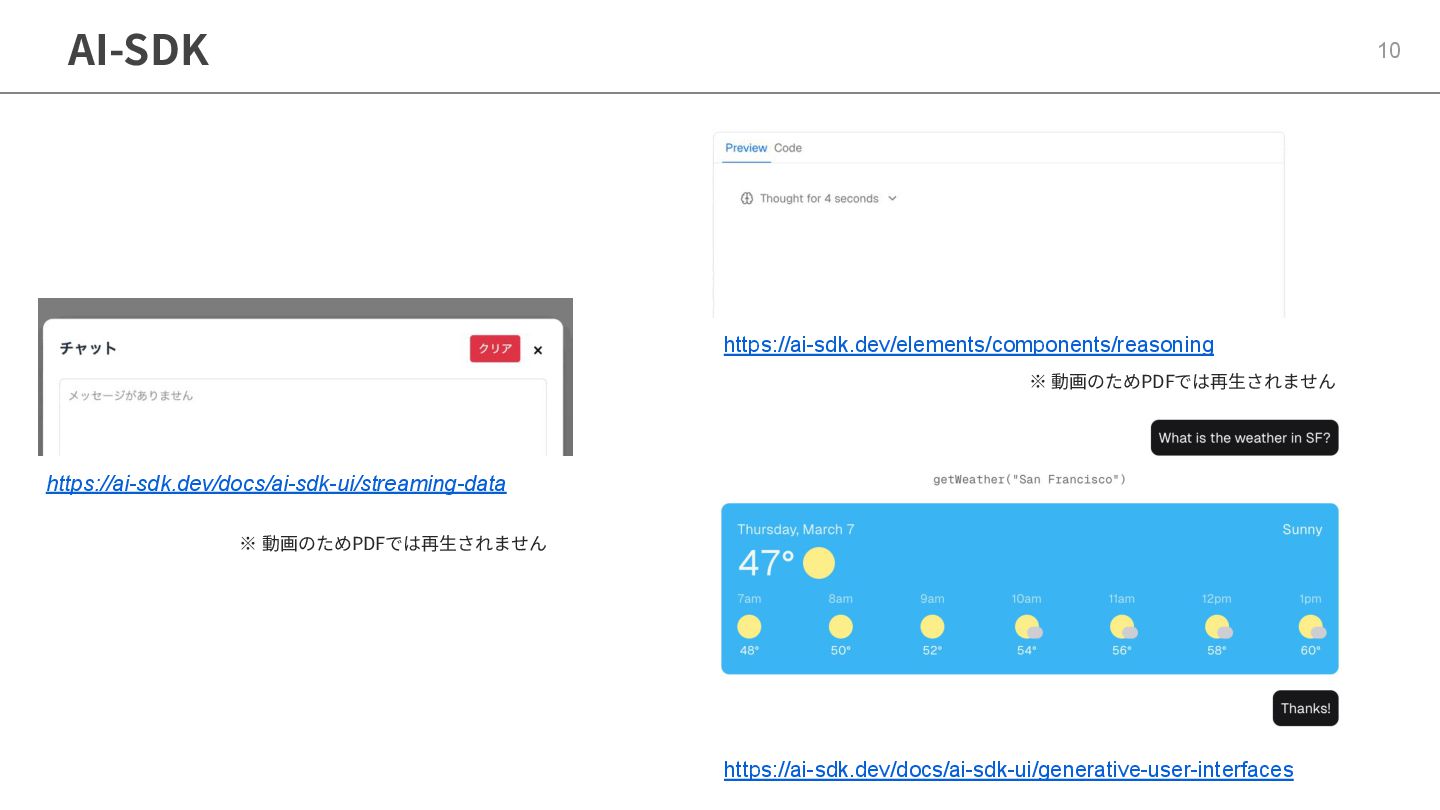
AI-SDK 10 https://ai-sdk.dev/docs/ai-sdk-ui/generative-user-interfaces https://ai-sdk.dev/elements/components/reasoning ※ 動画のためPDFでは再⽣されません https://ai-sdk.dev/docs/ai-sdk-ui/streaming-data ※ 動画のためPDFでは再⽣されません
CopilotKit 11 https://docs.copilotkit.ai/langgraph これはより、エージェントシステムとUIの統合が 可能なFWです。 https://www.copilotkit.ai/ag-ui モックがあるので試すとイメージがつきやすいです👇 CopilotKit: ユーザー向けアプリにAIエージェント を統合するためのフレームワーク
(AG-UI,MCP,A2A) AG-UI: AIエージェントとフロントエンドUI間の通 信を標準化したオープンプロトコル ※ 動画のためPDFでは再⽣されません
事例: 社内業務⽀援のPoC (4⽉頃 ~ 7⽉頃)
前提 13 ‧製造業のお客様、⼯場で利⽤するWebアプリを弊社で構築済み ‧Webアプリに関わる⼈の便利ツールとして構築(社内情報システム) ‧時期は25年4⽉頃 〜 現在
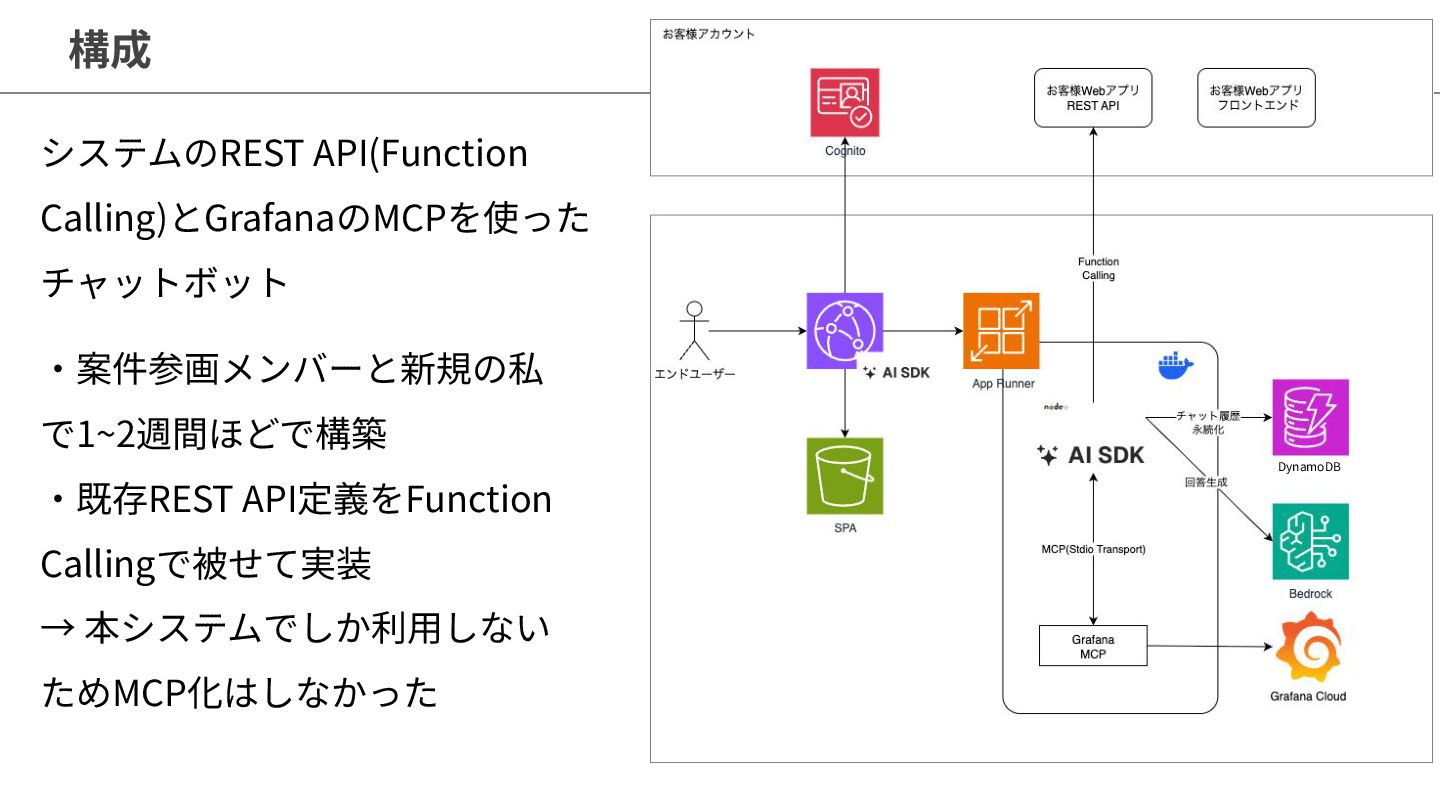
構成 14 ‧案件参画メンバーと新規の私 で1~2週間ほどで構築 ‧既存REST API定義をFunction Callingで被せて実装 → 本システムでしか利⽤しない ためMCP化はしなかった
システムのREST API(Function Calling)とGrafanaのMCPを使った チャットボット DynamoDB
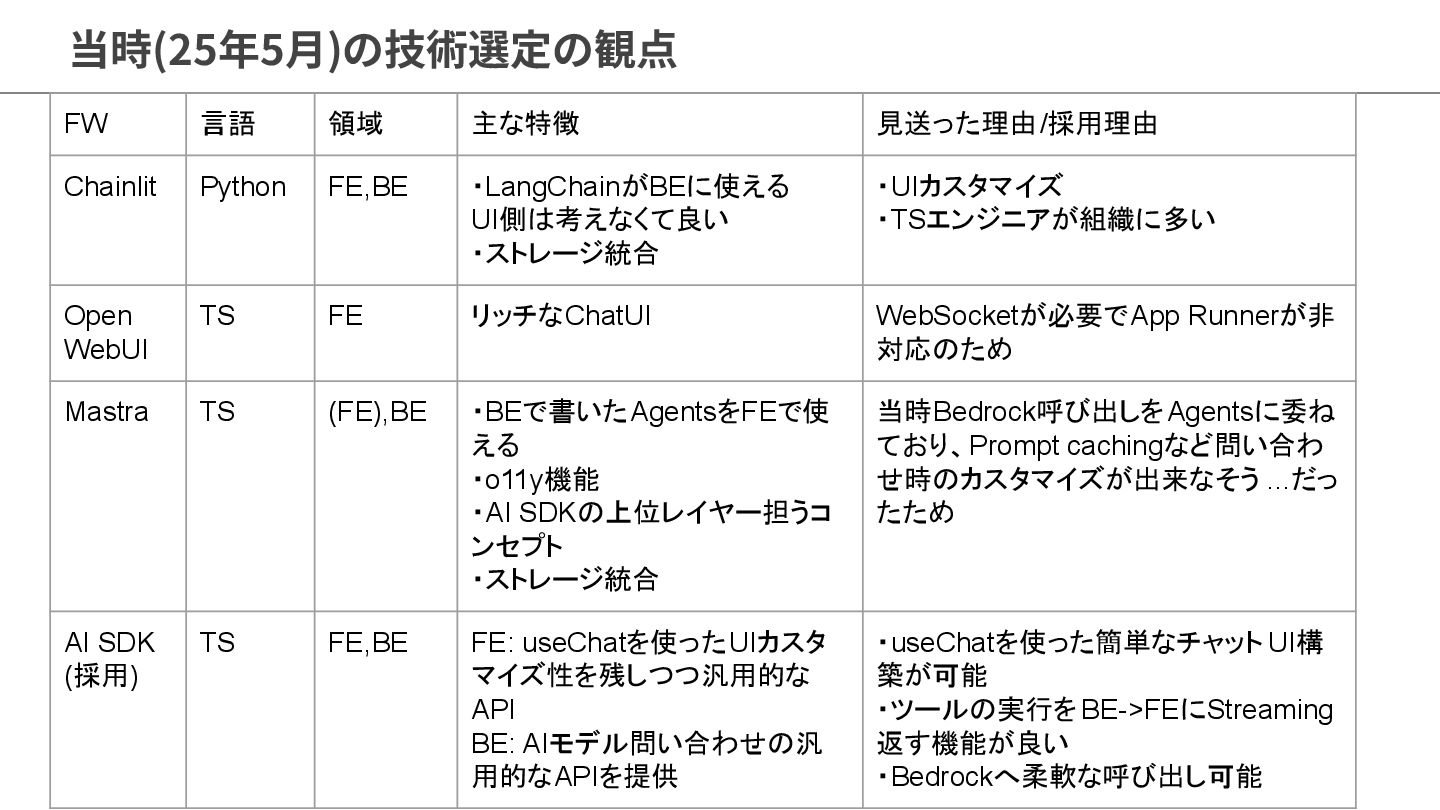
当時(25年5⽉)の技術選定の観点 FW 言語 領域 主な特徴 見送った理由/採用理由 Chainlit Python FE,BE ・LangChainがBEに使える
UI側は考えなくて良い ・ストレージ統合 ・UIカスタマイズ ・TSエンジニアが組織に多い Open WebUI TS FE リッチなChatUI WebSocketが必要でApp Runnerが非 対応のため Mastra TS (FE),BE ・BEで書いたAgentsをFEで使 える ・o11y機能 ・AI SDKの上位レイヤー担うコ ンセプト ・ストレージ統合 当時Bedrock呼び出しをAgentsに委ね ており、Prompt cachingなど問い合わ せ時のカスタマイズが出来なそう ...だっ たため AI SDK (採用) TS FE,BE FE: useChatを使ったUIカスタ マイズ性を残しつつ汎用的な API BE: AIモデル問い合わせの汎 用的なAPIを提供 ・useChatを使った簡単なチャット UI構 築が可能 ・ツールの実行をBE->FEにStreaming 返す機能が良い ・Bedrockへ柔軟な呼び出し可能
16 AWS App RunnerをAIチャットボットで使う上で注意点 技術選定⾯ ‧120秒タイムアウト制約 ‧WebSocket未対応 費⽤⾯ ‧ゼロスケールしない(プロビジョンド課⾦) ‧ARMビルドコンテナ使⽤不可
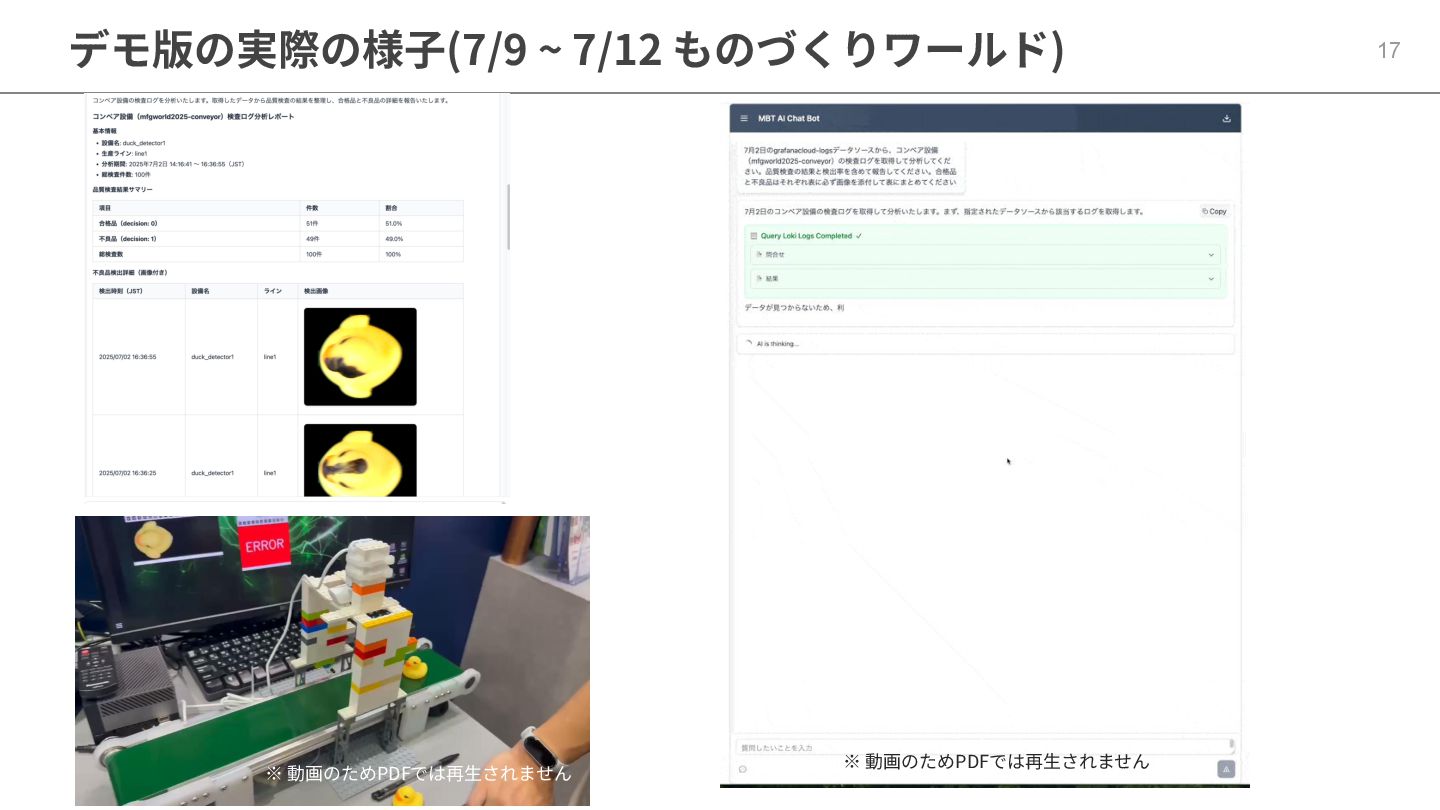
17 デモ版の実際の様⼦(7/9 ~ 7/12 ものづくりワールド) ※ 動画のためPDFでは再⽣されません ※ 動画のためPDFでは再⽣されません
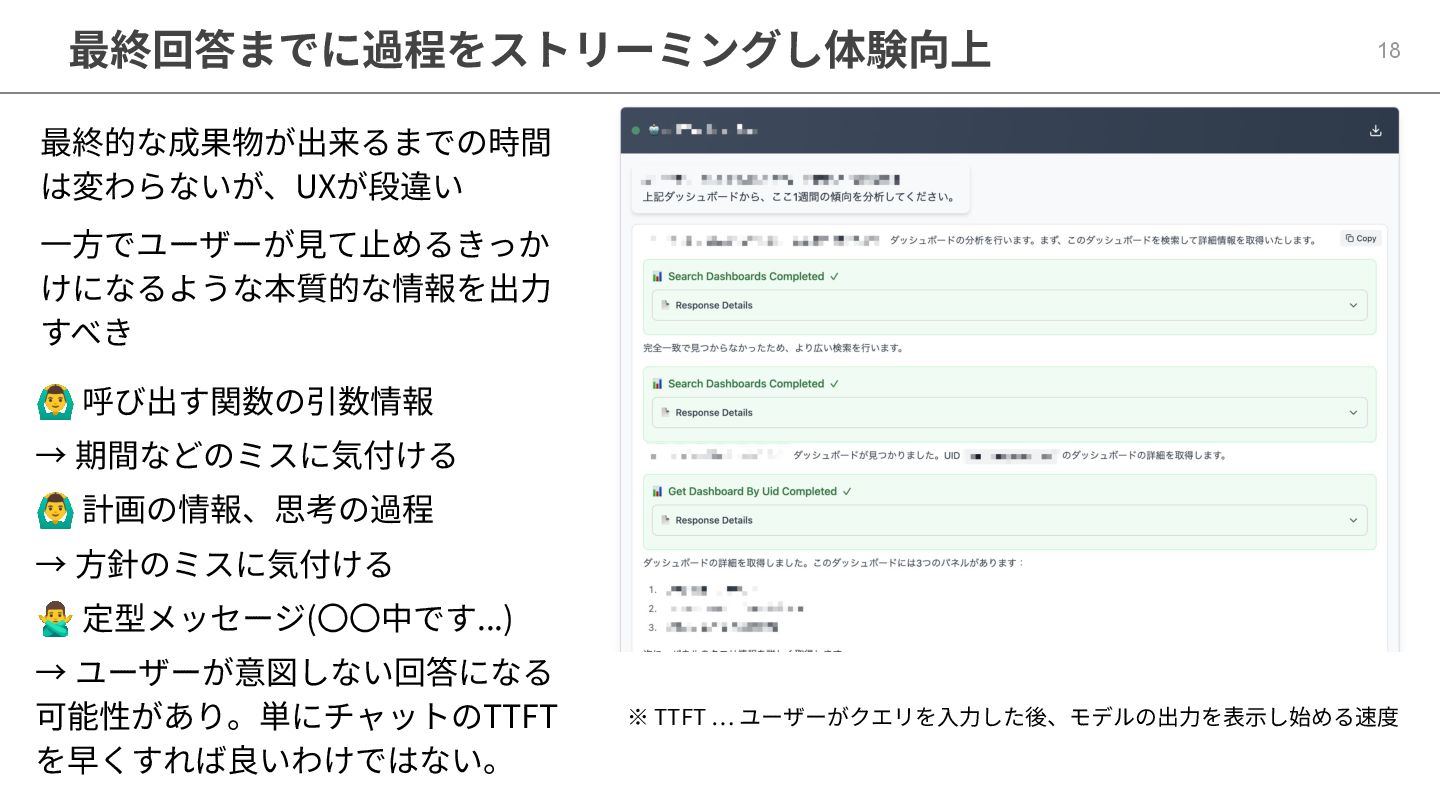
18 最終回答までに過程をストリーミングし体験向上 最終的な成果物が出来るまでの時間 は変わらないが、UXが段違い ⼀⽅でユーザーが⾒て⽌めるきっか けになるような本質的な情報を出⼒ すべき ※ TTFT …
ユーザーがクエリを⼊⼒した後、モデルの出⼒を表⽰し始める速度 呼び出す関数の引数情報 → 期間などのミスに気付ける 計画の情報、思考の過程 → ⽅針のミスに気付ける 定型メッセージ(〇〇中です...) → ユーザーが意図しない回答になる 可能性があり。単にチャットのTTFT を早くすれば良いわけではない。
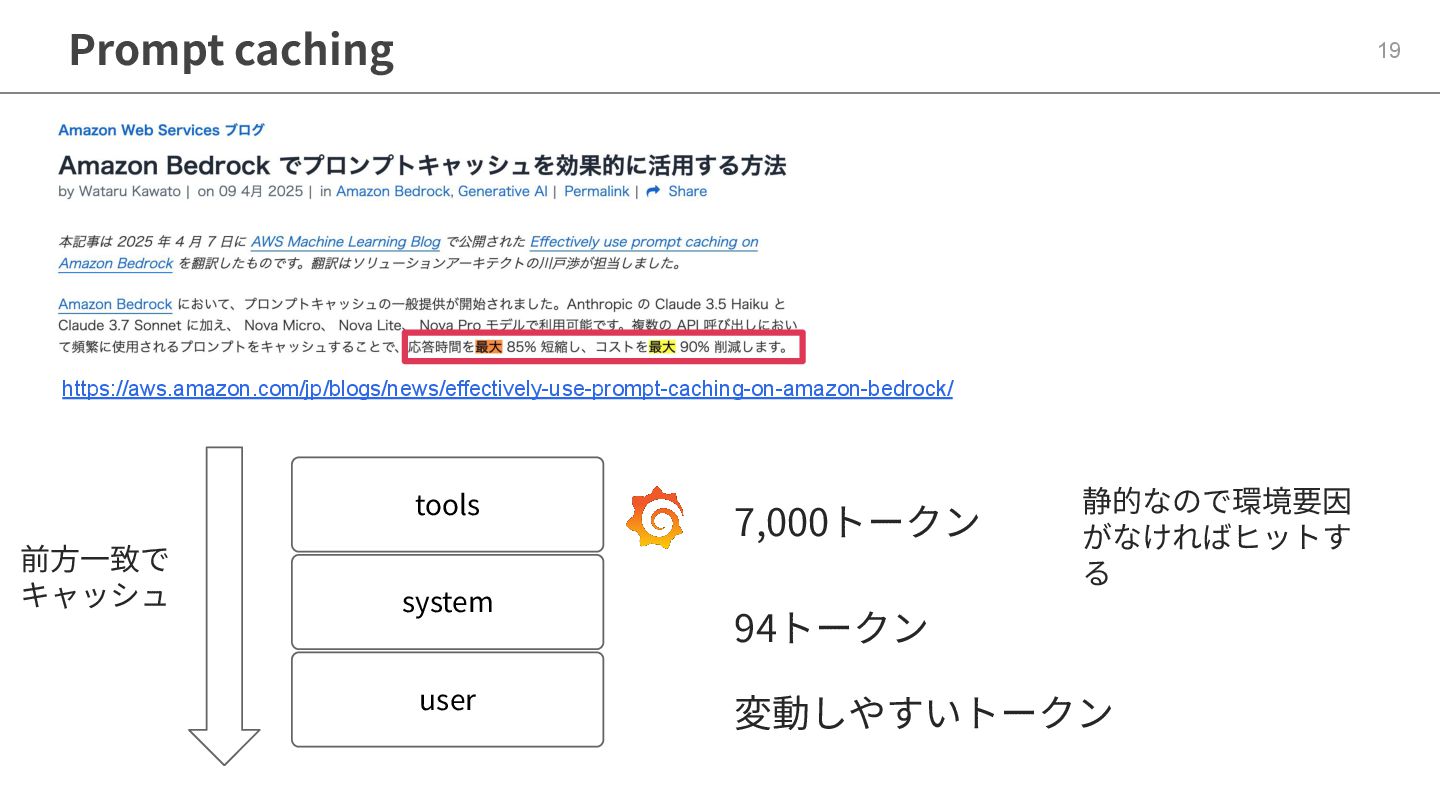
Prompt caching 19 tools 前⽅⼀致で キャッシュ 7,000トークン 94トークン 変動しやすいトークン 静的なので環境要因
がなければヒットす る https://aws.amazon.com/jp/blogs/news/effectively-use-prompt-caching-on-amazon-bedrock/ system user
CRIPだとキャッシュが散らばる 20 tools → systemまででキャッシュポイント を⽣成し、キャッシュを確認 クロスリージョンプロファイルだとキャッ シュ書き込んだリージョンに刺さらないと キャッシュが読み込まれない挙動も確認し た
> プロンプトキャッシュは、クロスリージョン推論( CRIS)と併用できます。(中略 ) 需要が集中する時間帯 には、これらの最適化によりキャッシュ書き込みが増加する可能性があります。
6⽉ Sonnet4 Bedrock利⽤料(開発や利⽤) 21 約3割程度は削減効果があった (削減額 = Cache Read ×
$2.70 − Cache Write × $0.75 = 13.6M × $2.70 − 1.4M × $0.75 = $36.7 − $1.1 ≒ $35.6)
事例: SaaS組み込みのプロダクト開発(7⽉頃 ~ 現在)
構成 23 製造現場の動画やマニュアルを検索するB to B向け SaaSアプリケーションに搭載されるチャットボット マニュアルの検索や動画内部の物体検出を⾏い、ユー ザーの課題を解決するための機能を提供
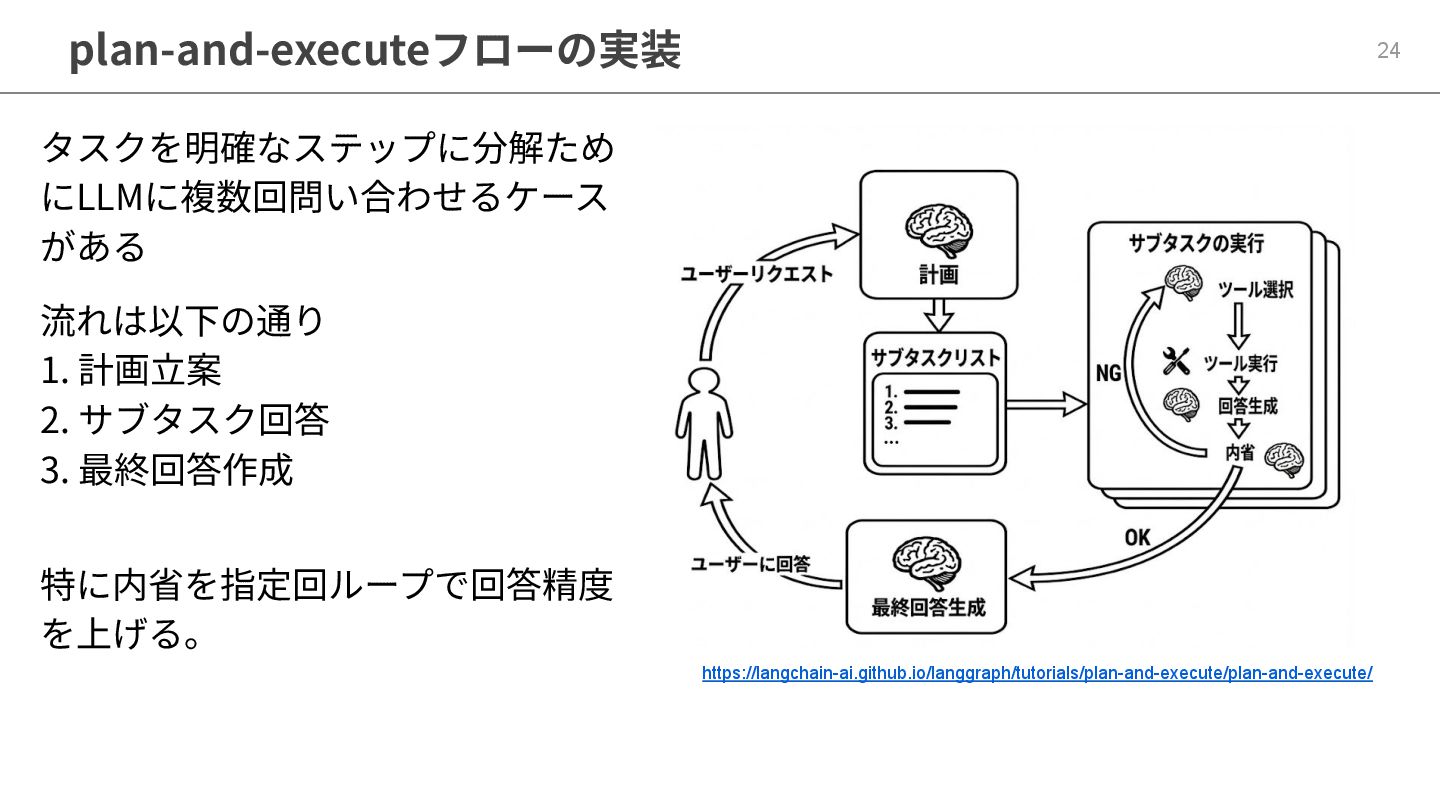
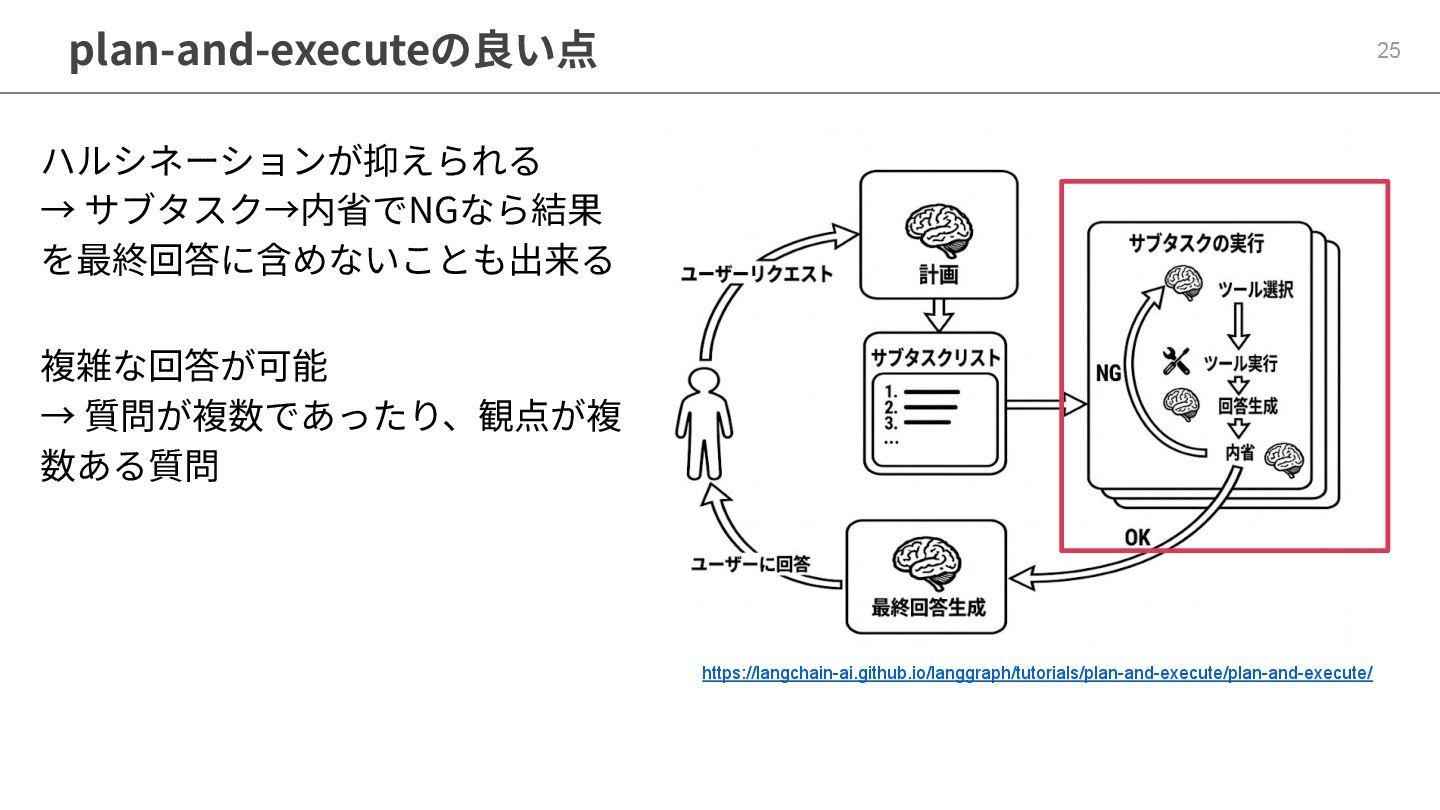
plan-and-executeフローの実装 24 https://langchain-ai.github.io/langgraph/tutorials/plan-and-execute/plan-and-execute/ 流れは以下の通り 1. 計画⽴案 2. サブタスク回答 3. 最終回答作成
タスクを明確なステップに分解ため にLLMに複数回問い合わせるケース がある 特に内省を指定回ループで回答精度 を上げる。
plan-and-executeの良い点 25 https://langchain-ai.github.io/langgraph/tutorials/plan-and-execute/plan-and-execute/ ハルシネーションが抑えられる → サブタスク→内省でNGなら結果 を最終回答に含めないことも出来る 複雑な回答が可能 → 質問が複数であったり、観点が複
数ある質問
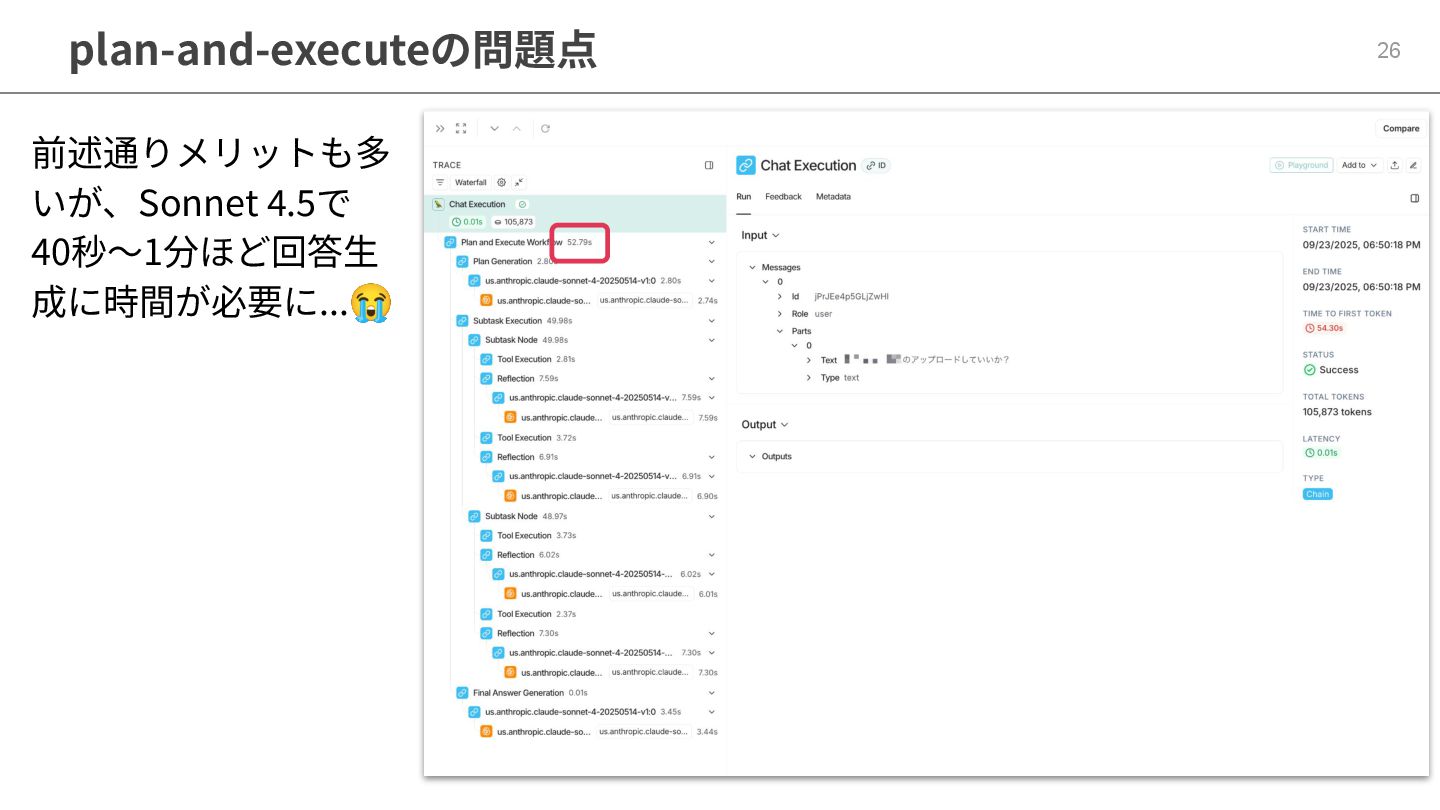
plan-and-executeの問題点 26 前述通りメリットも多 いが、Sonnet 4.5で 40秒〜1分ほど回答⽣ 成に時間が必要に...😭
精度とユーザー体験 27 ・本当にハルシネーションがなく、精度が高いけど遅いのがユーザーへの価値なのか ・プロダクトデータと密に連携し、荒いが素早い回答を求めているケースもある ・ある特定のケースの精度をあげた結果導入された複雑な処理が全体に影響を与えてし まうこともある → 回避策はあるが(タスクを分類や各フェーズでのモデルの最適化)、評価や保守し続け ることも考慮が必要
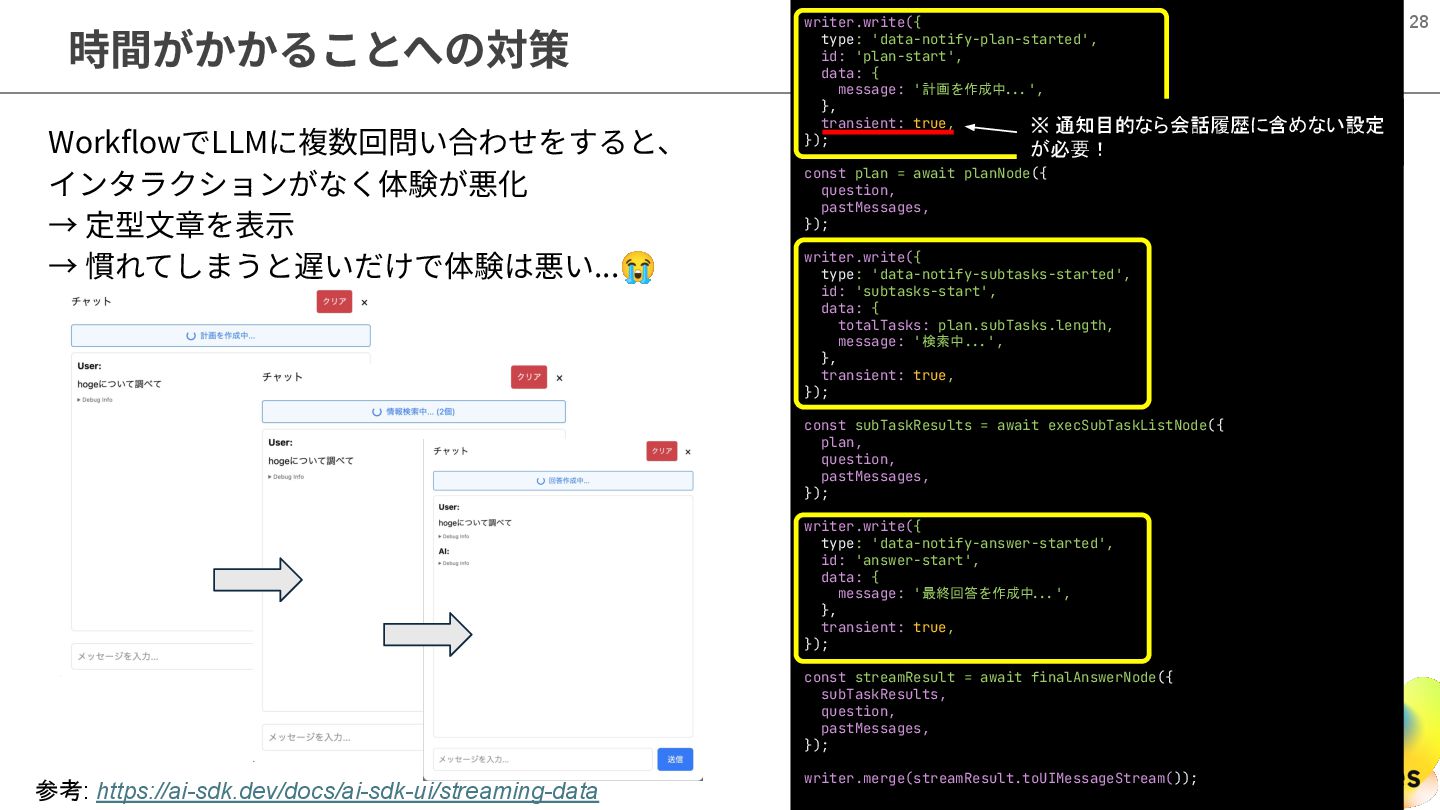
時間がかかることへの対策 28 28 WorkflowでLLMに複数回問い合わせをすると、 インタラクションがなく体験が悪化 → 定型⽂章を表⽰ → 慣れてしまうと遅いだけで体験は悪い...😭 参考:
https://ai-sdk.dev/docs/ai-sdk-ui/streaming-data writer.write({ type: 'data-notify-plan-started', id: 'plan-start', data: { message: '計画を作成中 ...', }, transient: true, }); const plan = await planNode({ question, pastMessages, }); writer.write({ type: 'data-notify-subtasks-started', id: 'subtasks-start', data: { totalTasks: plan.subTasks.length, message: '検索中...', }, transient: true, }); const subTaskResults = await execSubTaskListNode({ plan, question, pastMessages, }); writer.write({ type: 'data-notify-answer-started', id: 'answer-start', data: { message: '最終回答を作成中 ...', }, transient: true, }); const streamResult = await finalAnswerNode({ subTaskResults, question, pastMessages, }); writer.merge(streamResult.toUIMessageStream()); ※ 通知目的なら会話履歴に含めない設定 が必要!
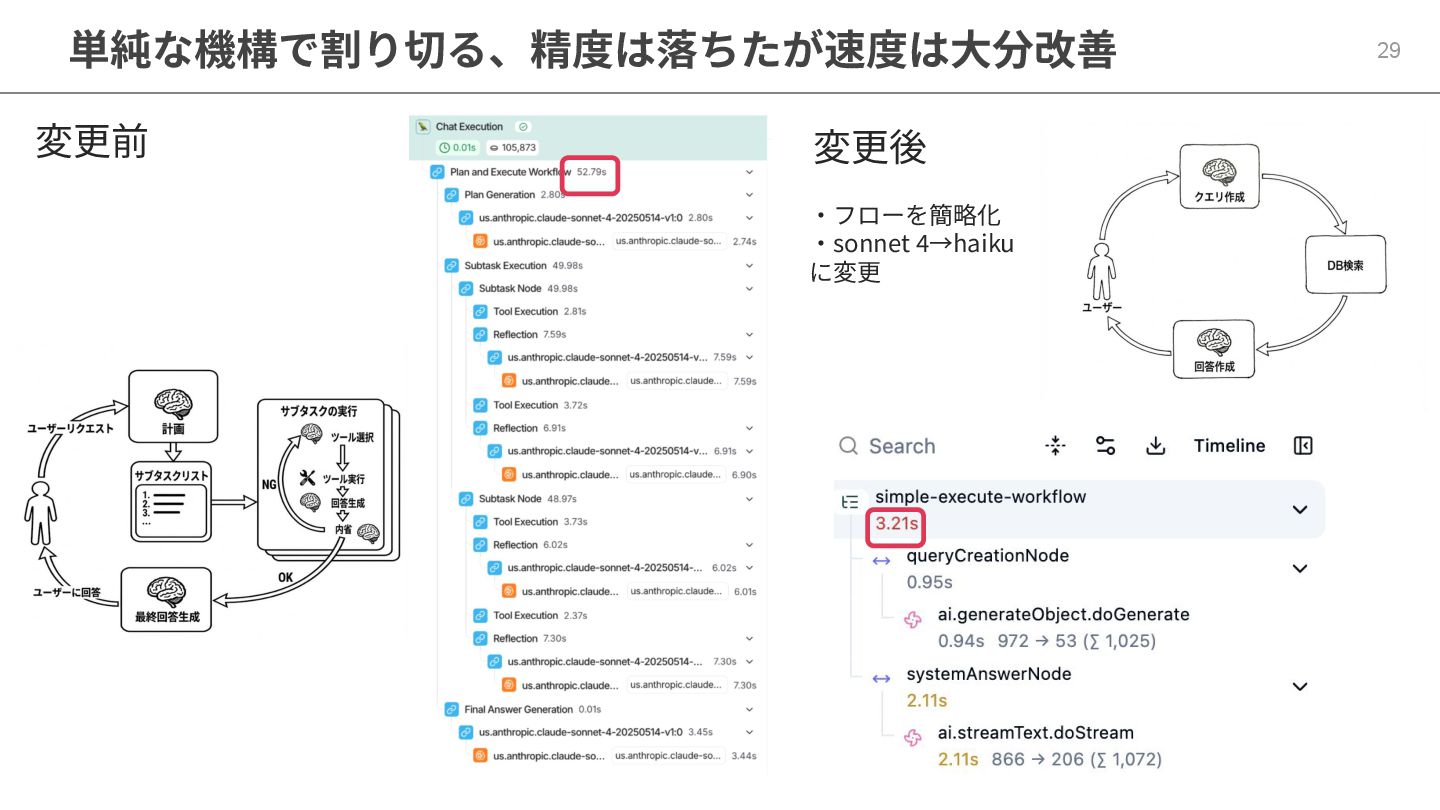
単純な機構で割り切る、精度は落ちたが速度は⼤分改善 29 変更前 変更後 ‧フローを簡略化 ‧sonnet 4→haiku に変更
評価やデバッグをするならo11yツールは必須 30 +import * as ai from 'ai'; import {
convertToModelMessages, - generateObject, type ModelMessage, - streamText, type UIMessage, type UIMessageStreamWriter, } from 'ai'; +import { wrapAISDK } from 'langsmith/experimental/vercel'; +const { streamText, generateObject } = wrapAISDK(ai); 後⼊れでもimport差し替えとAPIキーの環境変数登録 で対応完了 👉 ただ、LLM呼び出しを⼀つのトレースにまとめたりは 多少実装が必要だが、AIコーディングエージェントを 使えばすぐ実装してくれる。 デバッグはエラーメッセージを読むのとは異なる⼤量 の⾃然⾔語を読むことになる。⾃然⾔語をJSONロガー で読むのはかなり負荷が⾼い。複雑であるほど必須。 langfuseはdocker composeでローカルにたてられる ので、最低ローカルは⼊れた⽅が良い。
まとめ 31 ‧AIエージェント開発はUI、体感時間などの体験、精度、コストのそれぞれのパラ メータを柔軟にトレードオフしながら作っていく必要がある。 ‧全てのケースに最適化するより、割り切って多くのケースを確実に体験よく作る という判断も⼤事 。全てに対応すると開発、保守、評価でROIが悪化する可能性も ある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 簡単に言えば自律的に目標を達成](https://files.speakerdeck.com/presentations/593c1a212de34f4493cd36befc4a2d4c/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}