Lucene 4.0 is the next intentionally backwards incompatible release of Apache Lucene bringing a large set of fundamental API changes, performance enhancements, new features and revised algorithm. Motivated by state-of-the-art information retrieval research Lucene 4.0 exploits an entire new low-level Codec-Layer, Automaton based inexact search, low-latency realtime-search, Column-Stride Fields and new highly-concurrent indexing capabilities. This talk will introduce Lucene's new major features, briefly explains their implementation, introduces their capabilities and several performance improvements up to 20000% compared to previous versions of Lucene.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
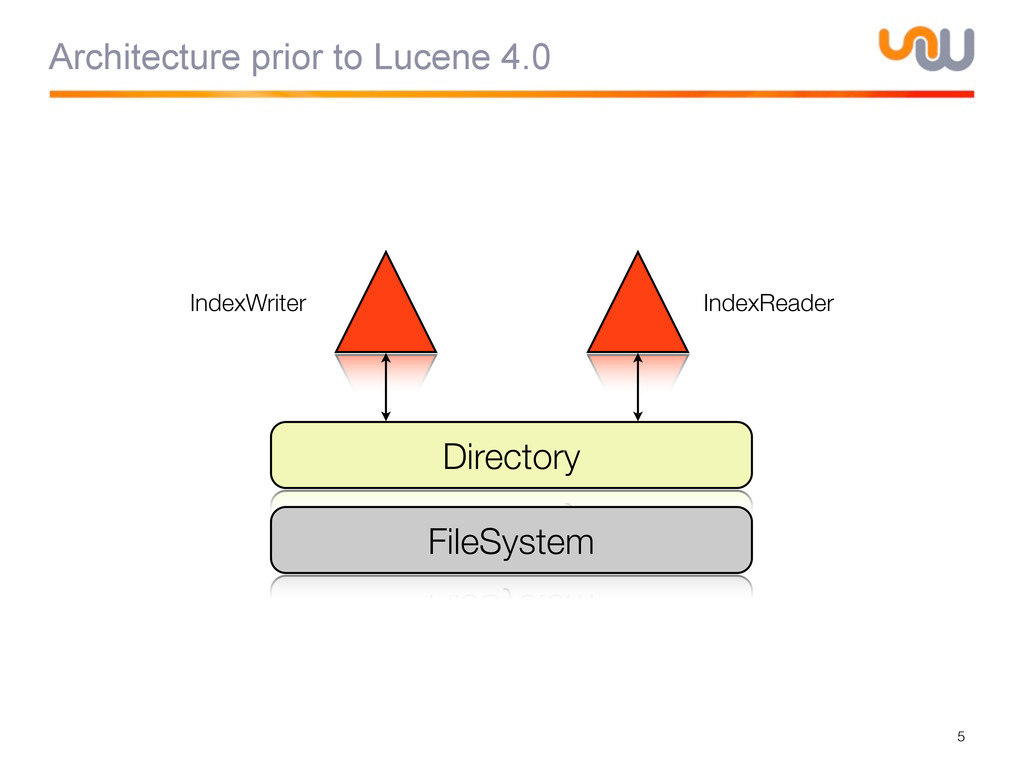{kind=link}
{kind=link}
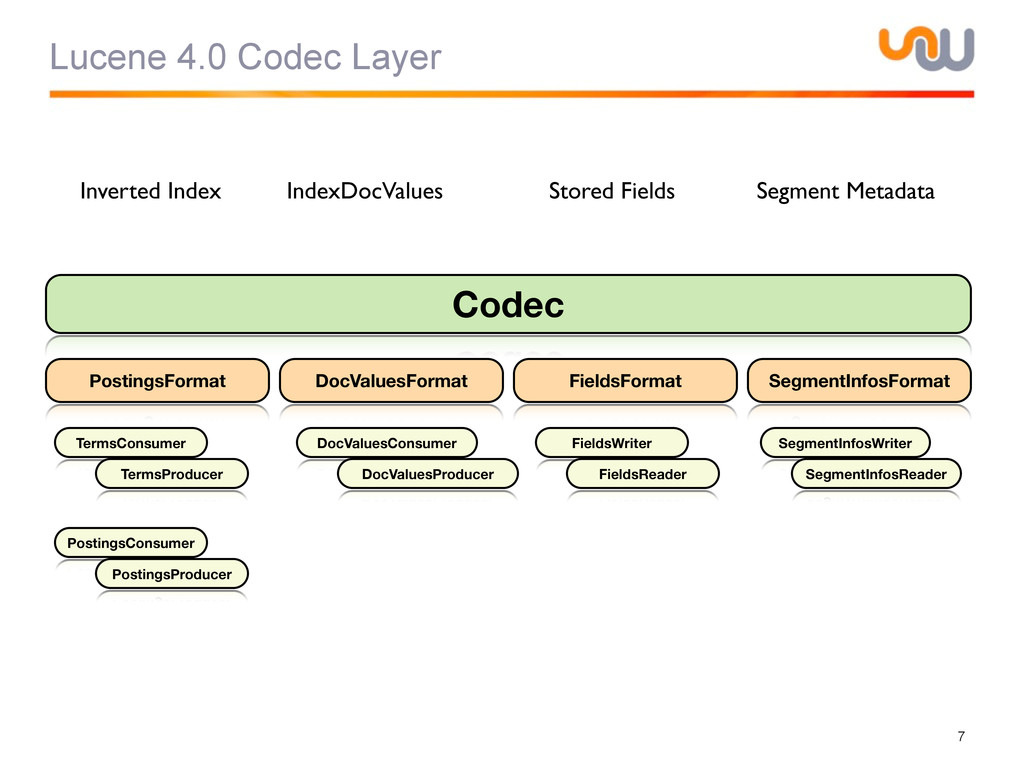{kind=link}
{kind=link}
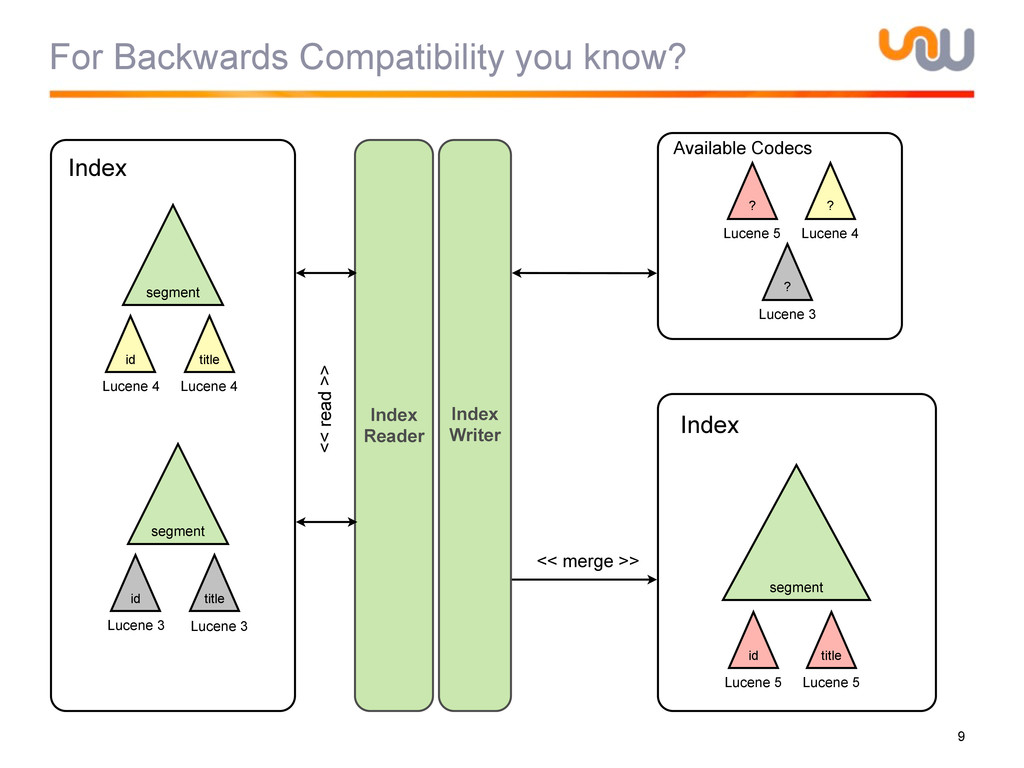{kind=link}
{kind=link}
{kind=link}
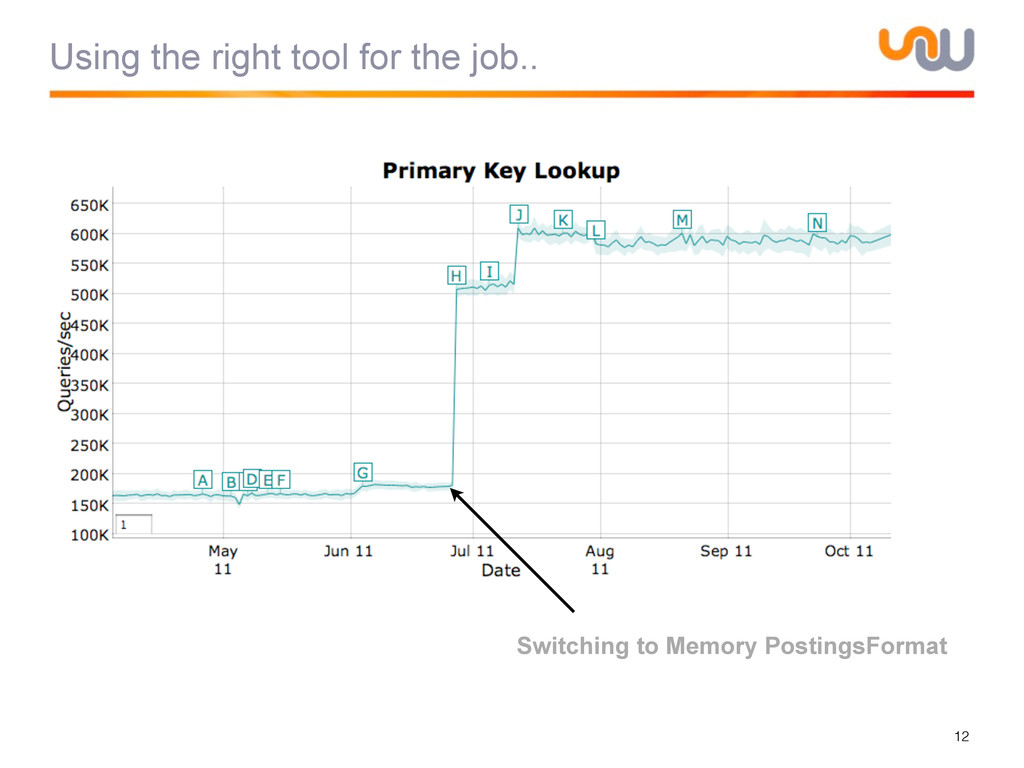{kind=link}
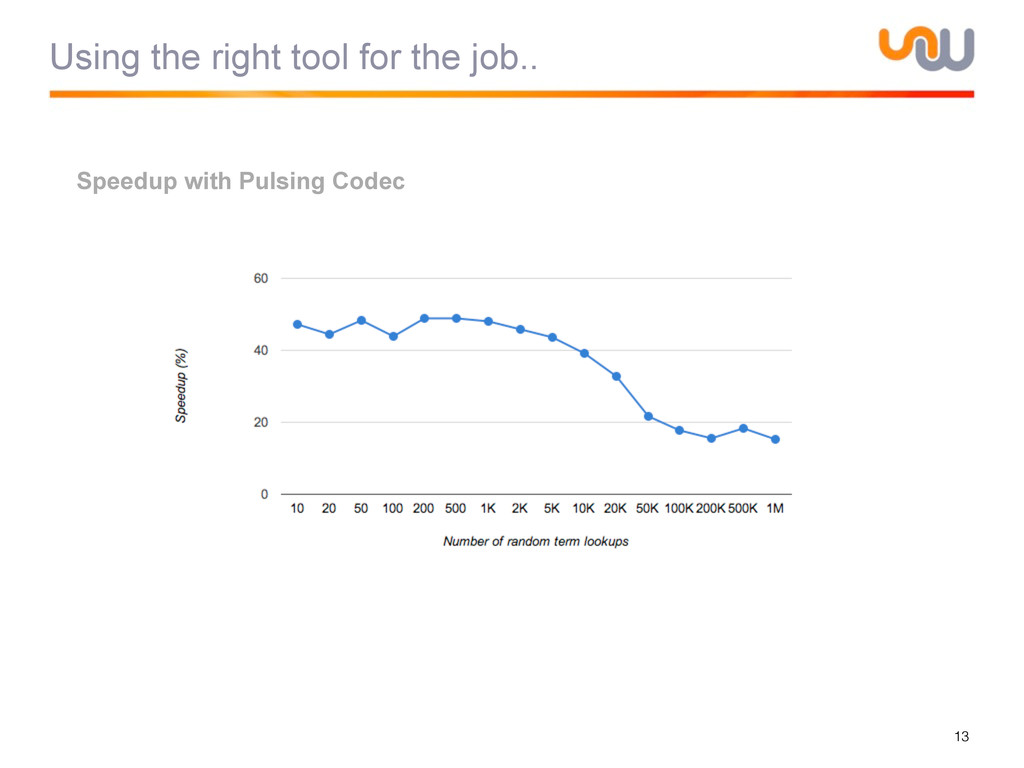{kind=link}
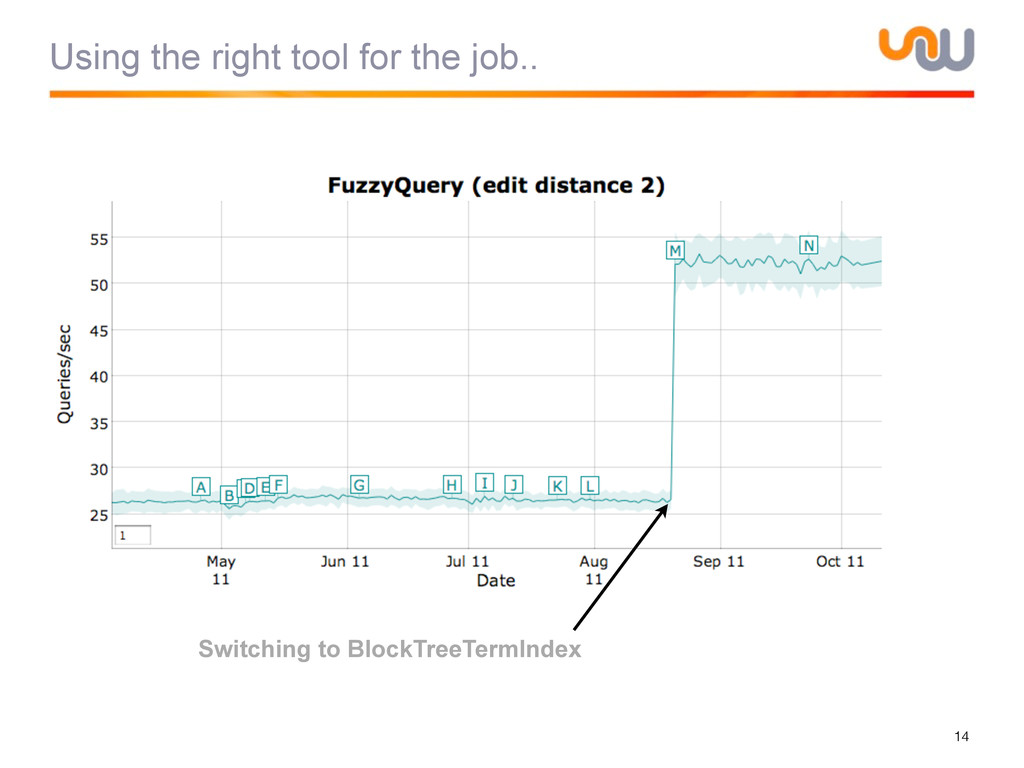{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
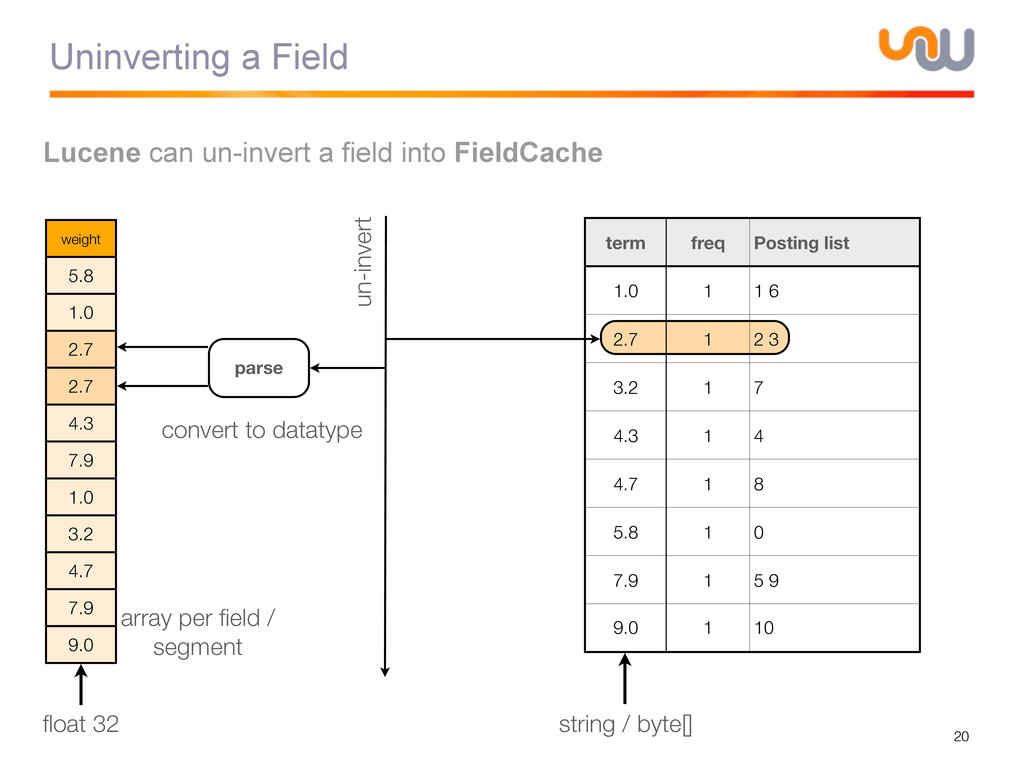{kind=link}
{kind=link}
{kind=link}
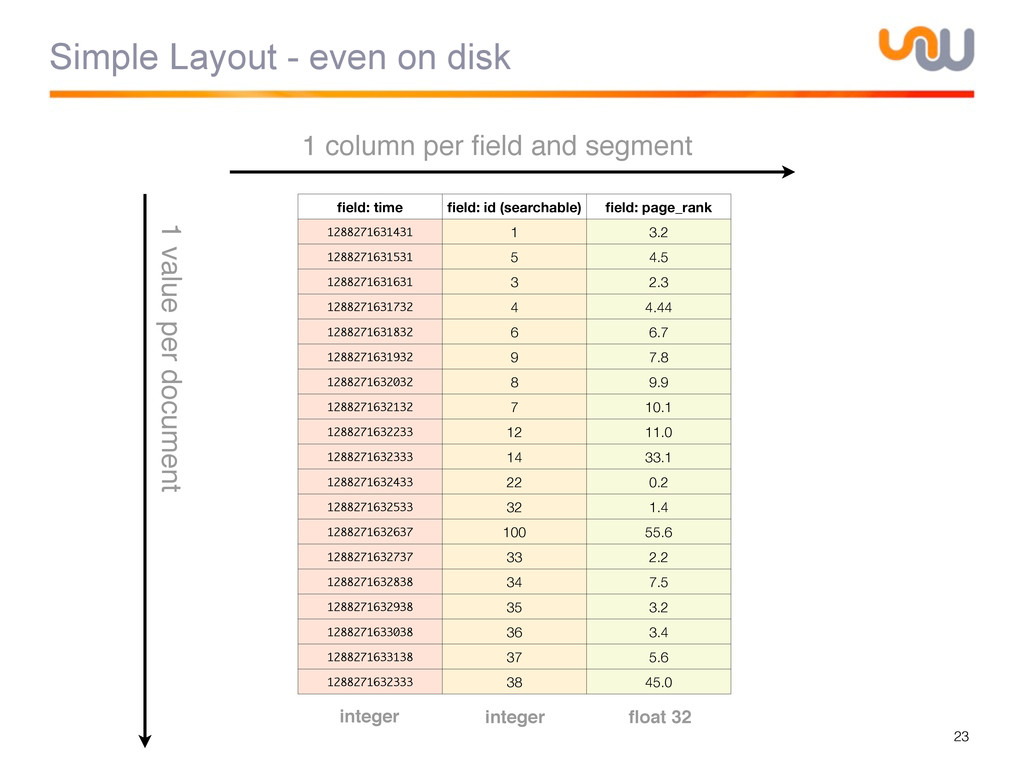{kind=link}
![Arbitrary Values - The byte[] variants •Length Variants: •Fixed /](https://files.speakerdeck.com/presentations/072e02102ab90130898a12313d035c57/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
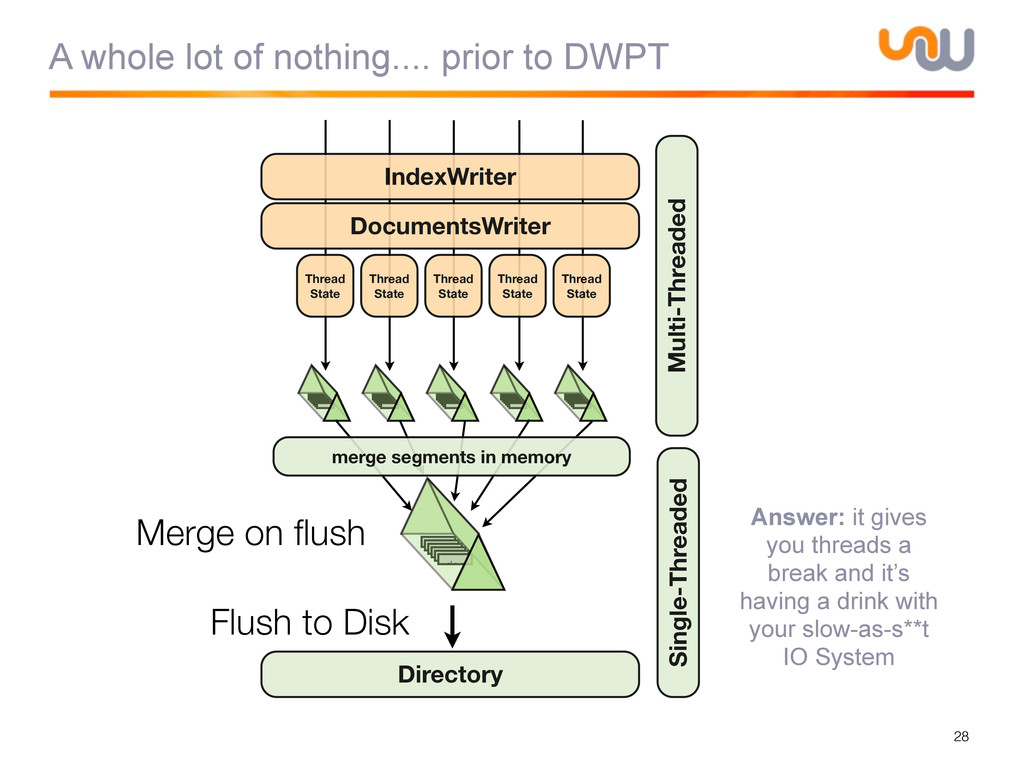{kind=link}
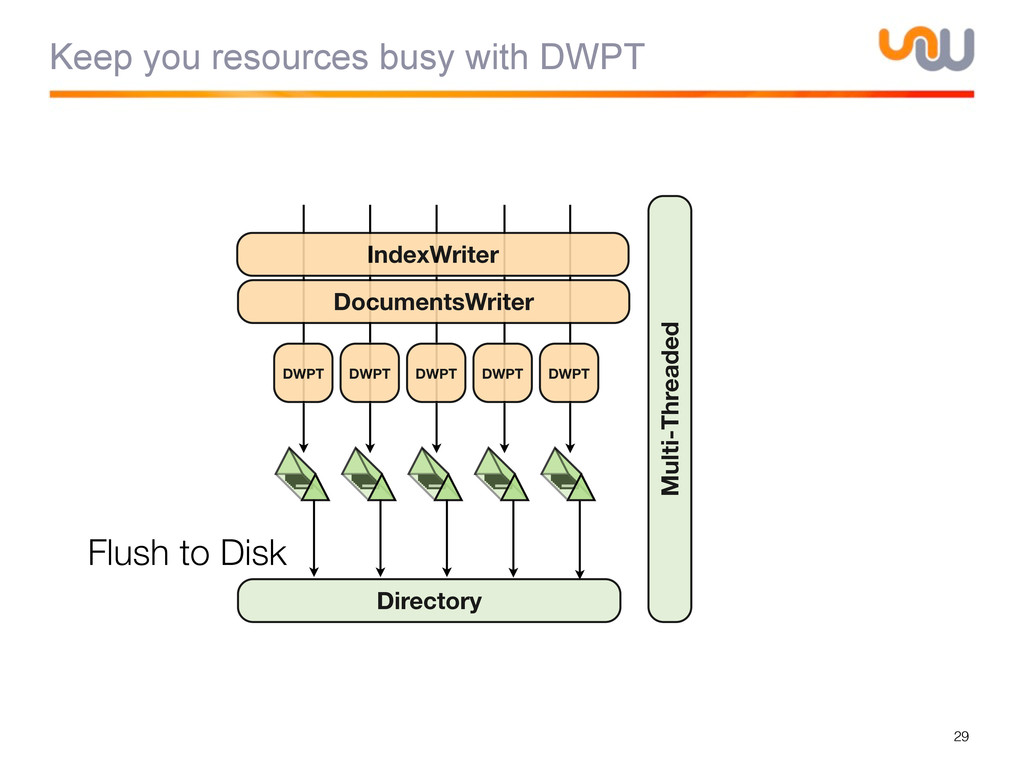{kind=link}
{kind=link}
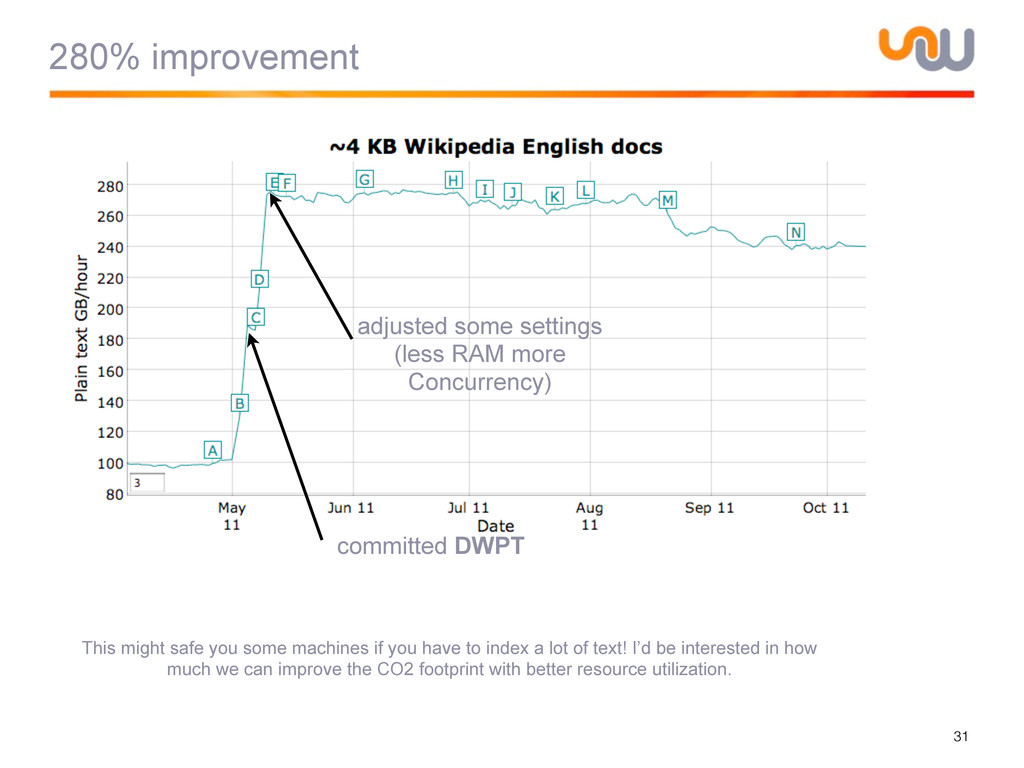{kind=link}
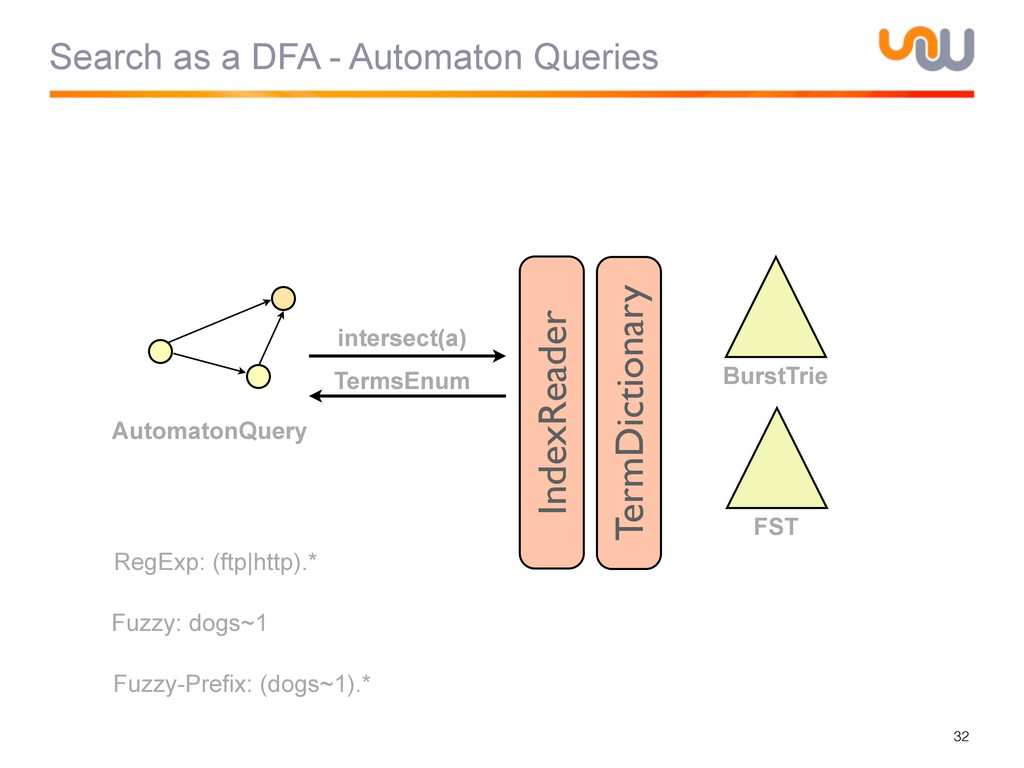{kind=link}
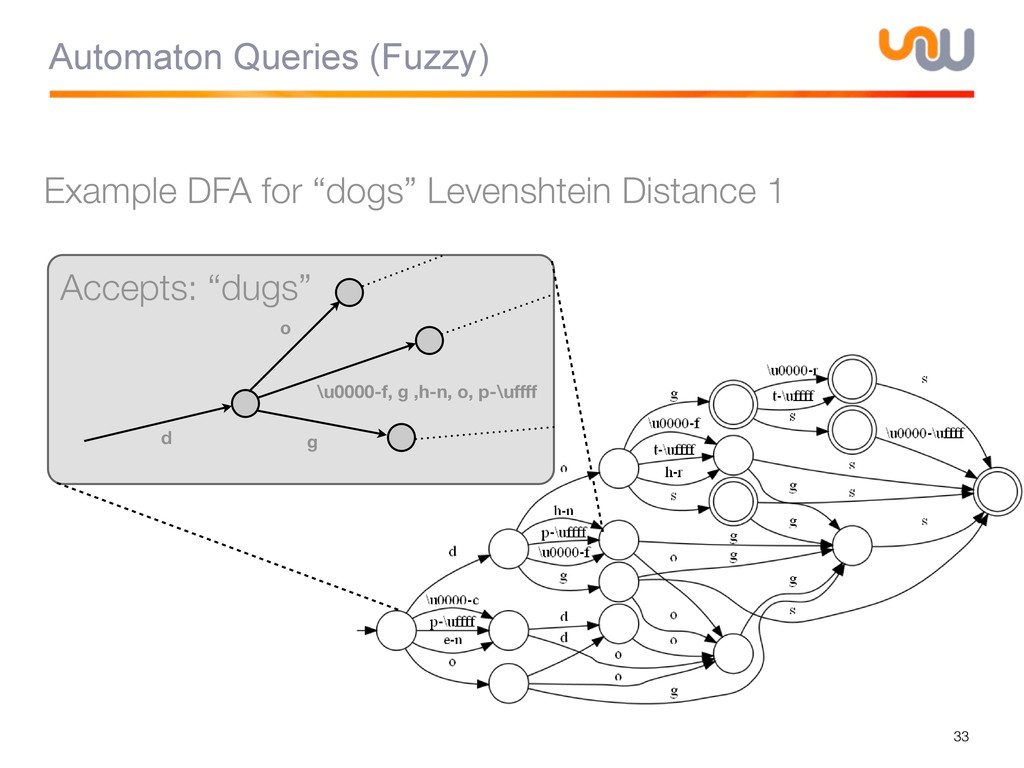{kind=link}
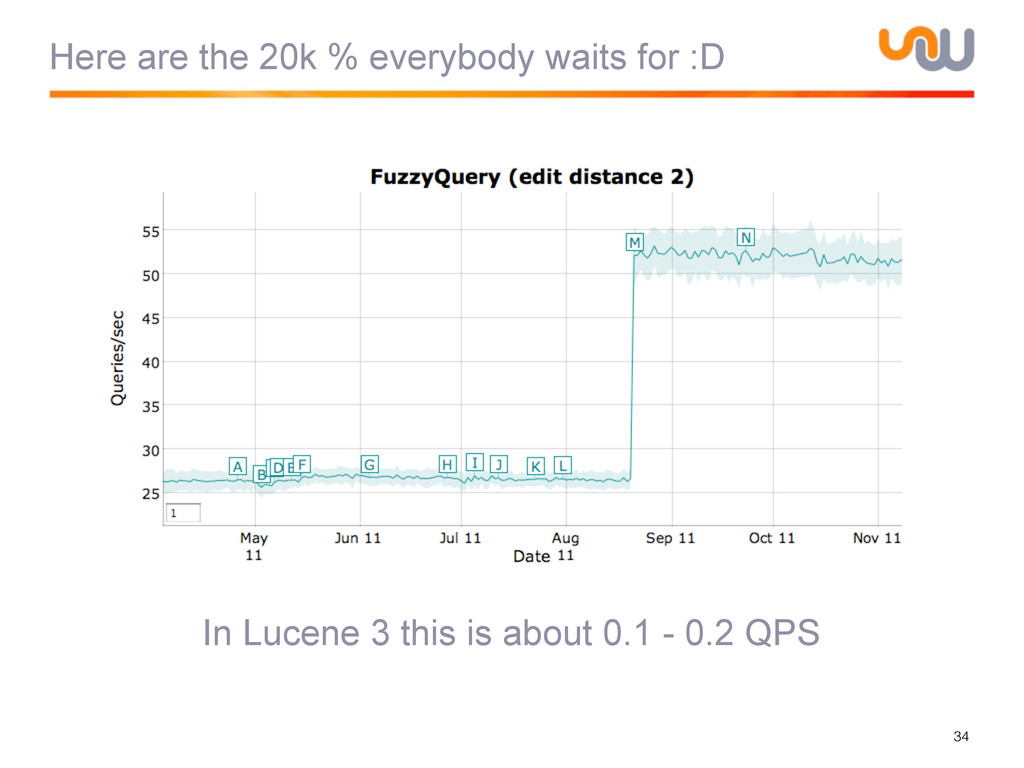{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}