Apache Lucene has grown to one of the most widely used Open Source search technologies. For more than a decade Lucene has been used to retrieve search results for millions of users from mobile phones to world scale applications with billions of queries every day. This talk introduces the current state of the Lucene eco-system from a technical perspective and tries to provide a future vision of the project even beyond the next revolutionary major release.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
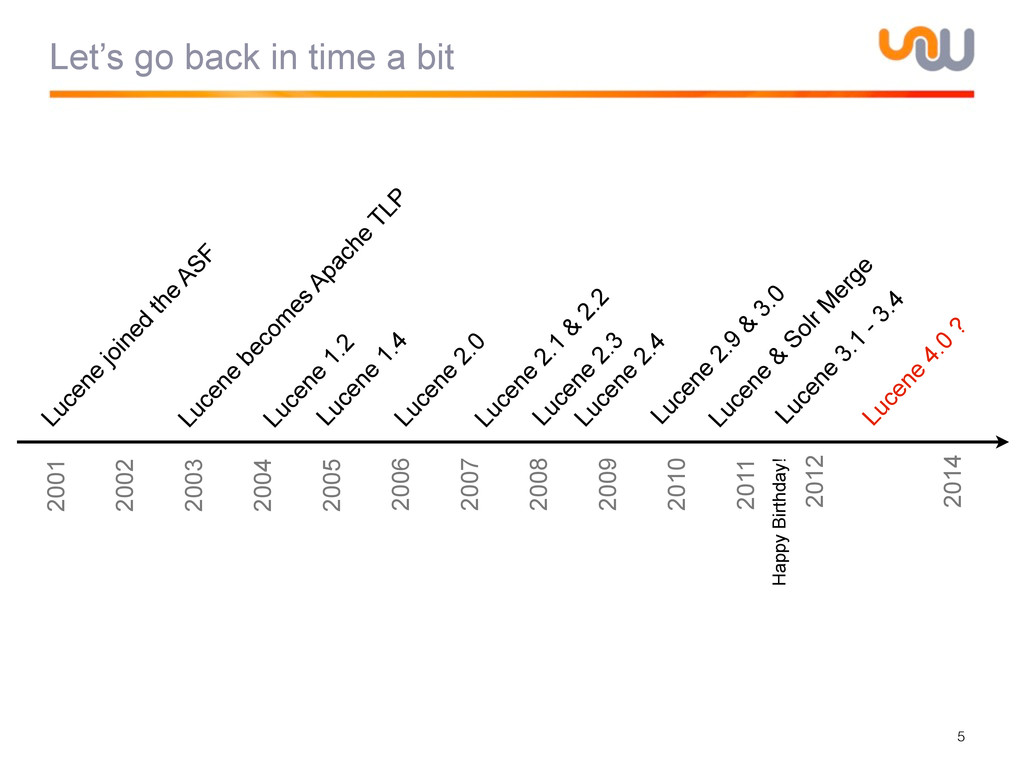{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
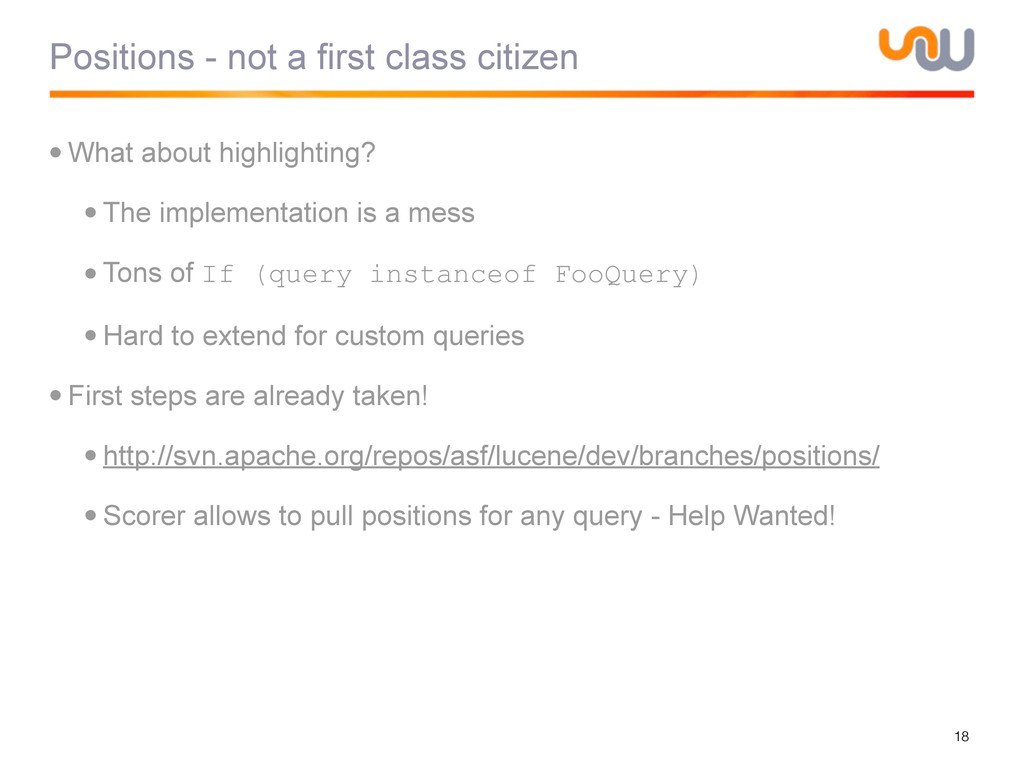{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
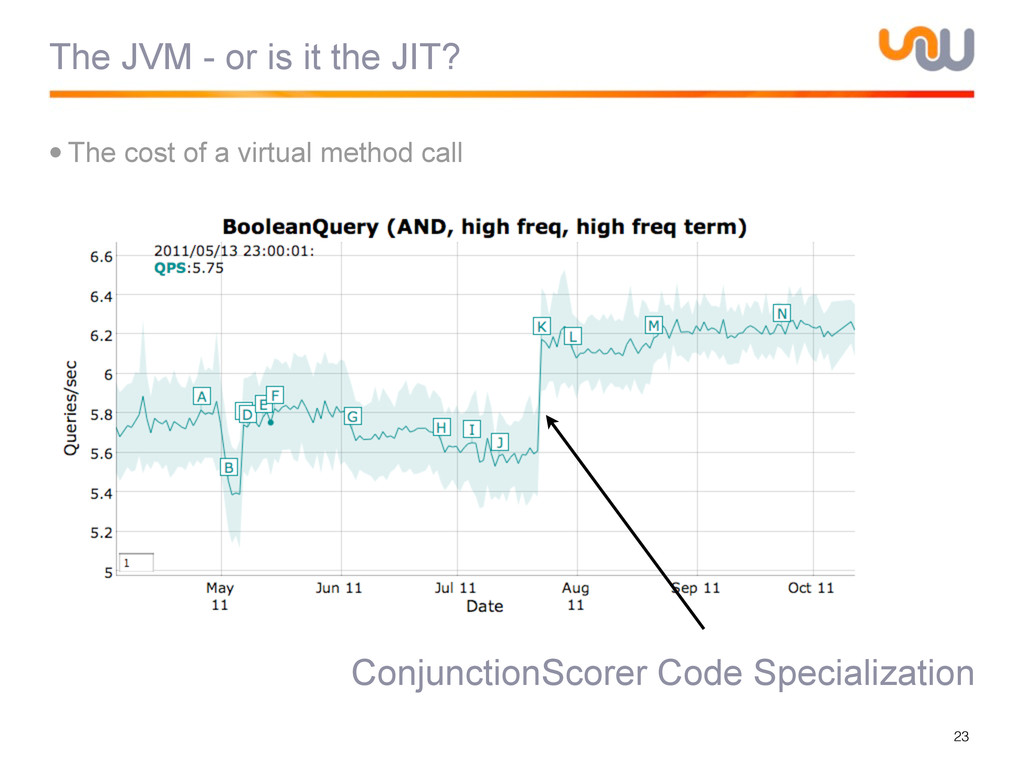{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
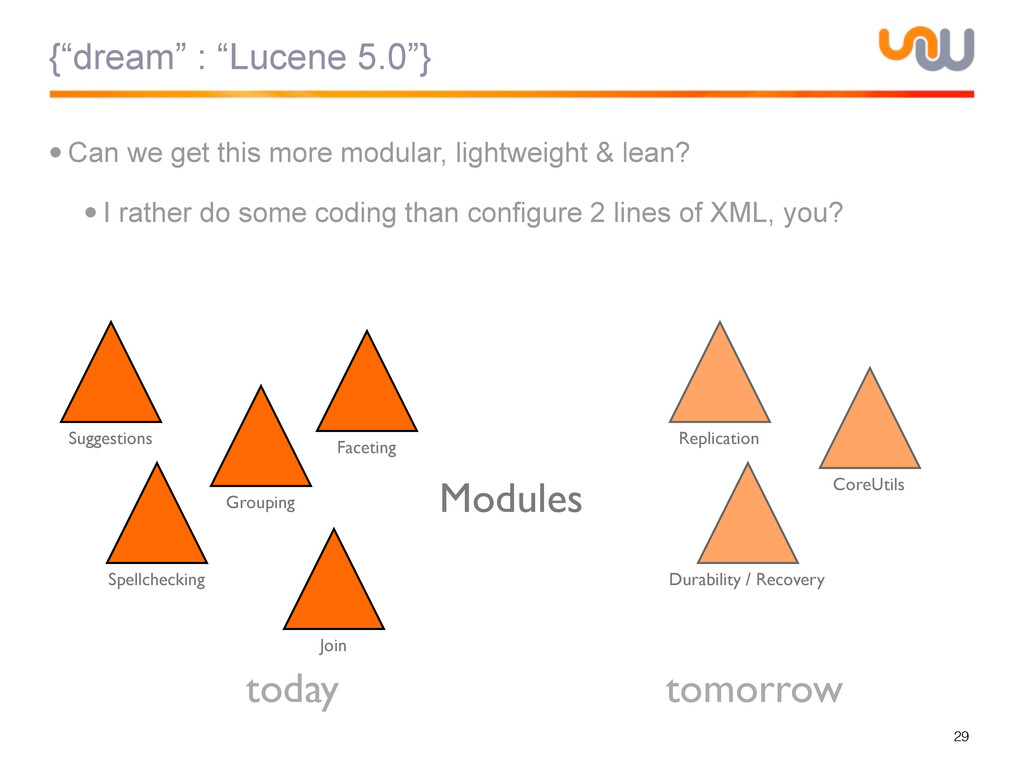{kind=link}
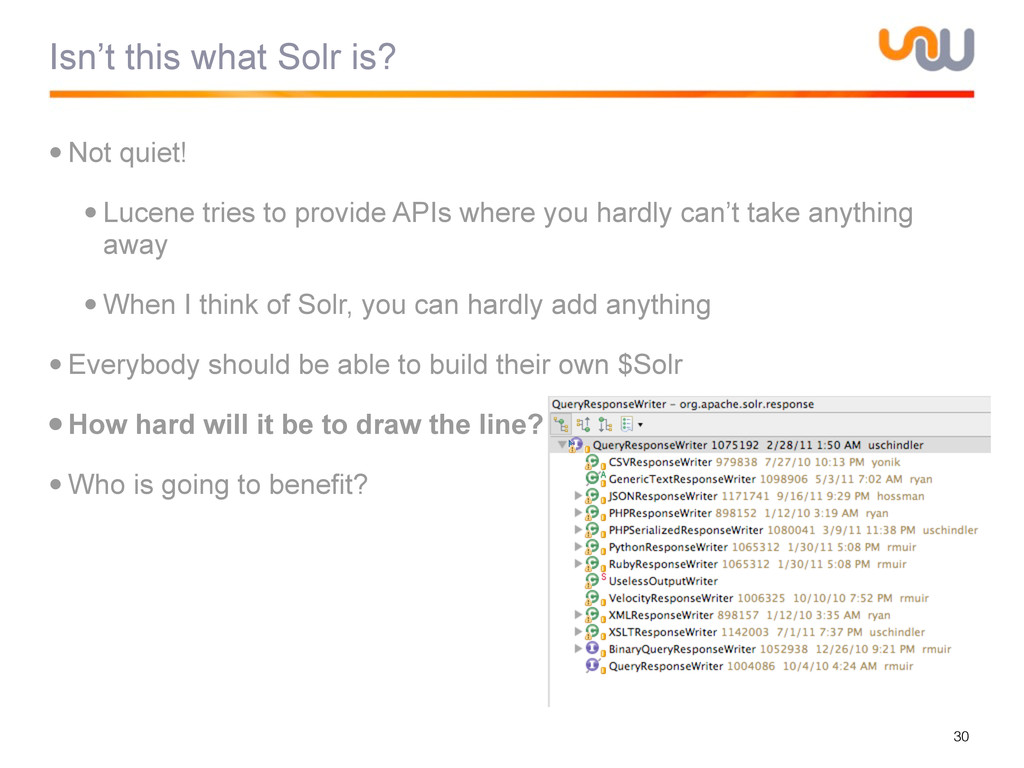{kind=link}
{kind=link}
{kind=link}
{kind=link}