Lucene 4.0 is on its way to deliver a tremendous amount of new features and improvements. Beside Real-Time Search & Flexible Indexing DocValues aka. Column Stride Fields is one of the "next generation" features. DocValues enable Lucene to efficiently store and retrieve type-safe Document & Value pairs in a column stride fashion either entirely memory resident random access or disk resident iterator based without the need to un-invert fields. It's final goal is to provide a independently update-able per document storage for scoring, sorting or even filtering. This talk will introduce the current state of development, implementation details, its features and how DocValues have been integrated into Lucene's Codec API for full extendability.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
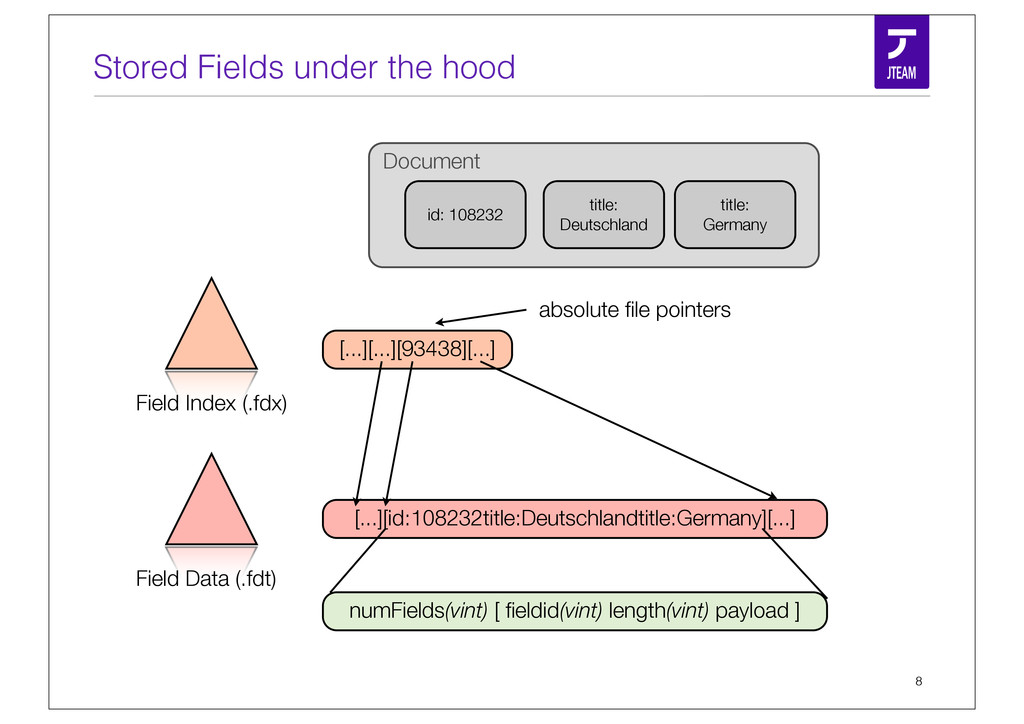{kind=link}
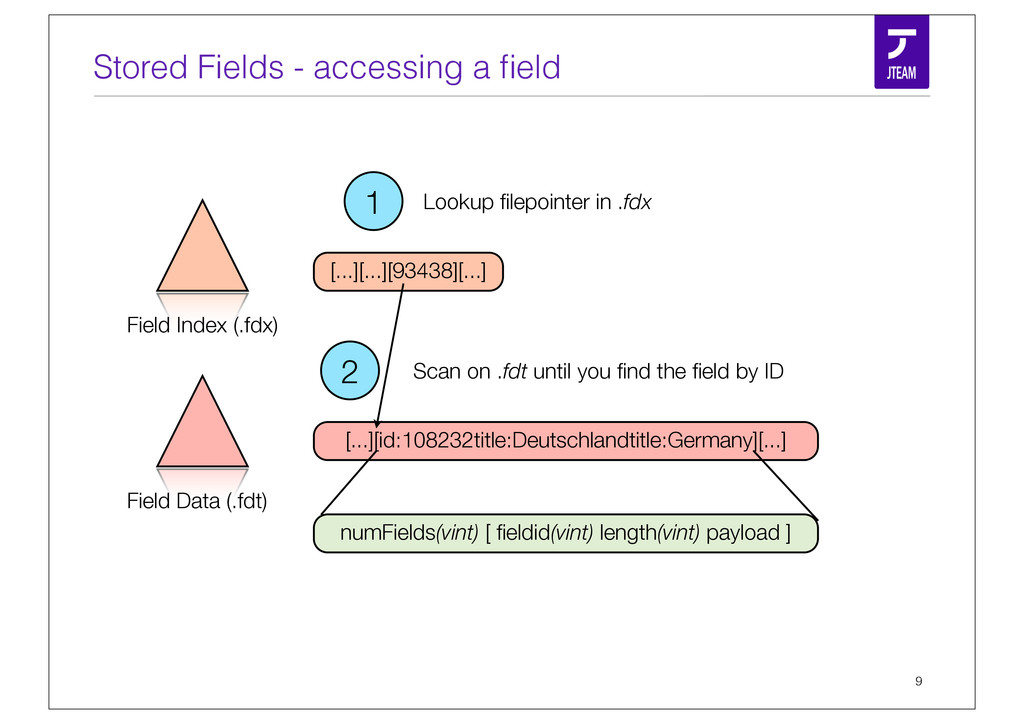{kind=link}
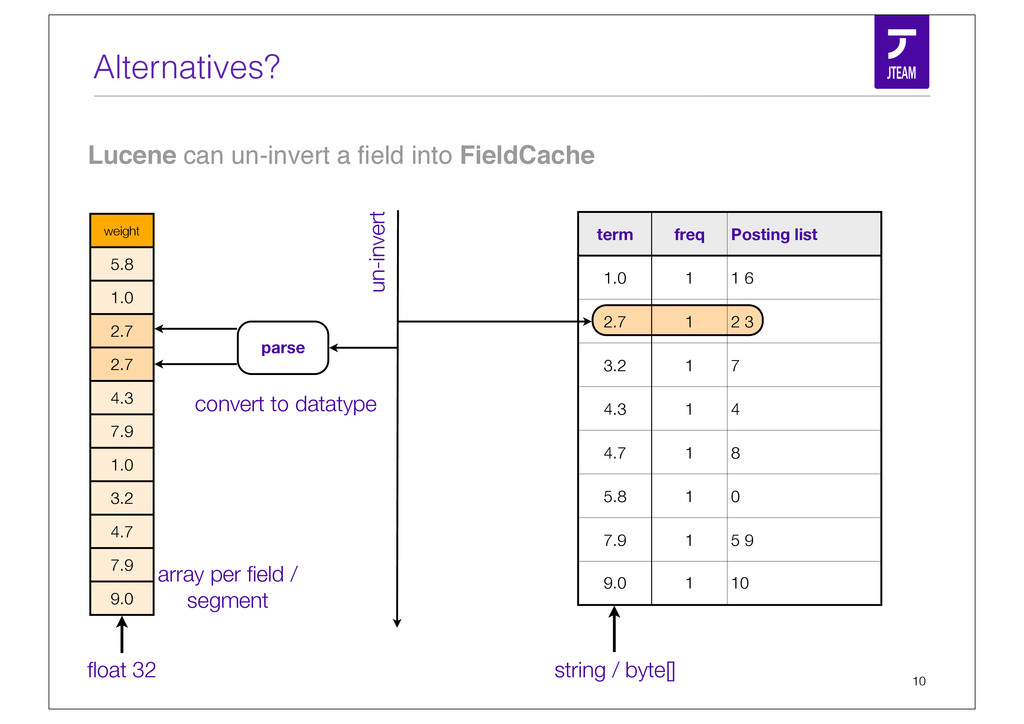{kind=link}
{kind=link}
{kind=link}
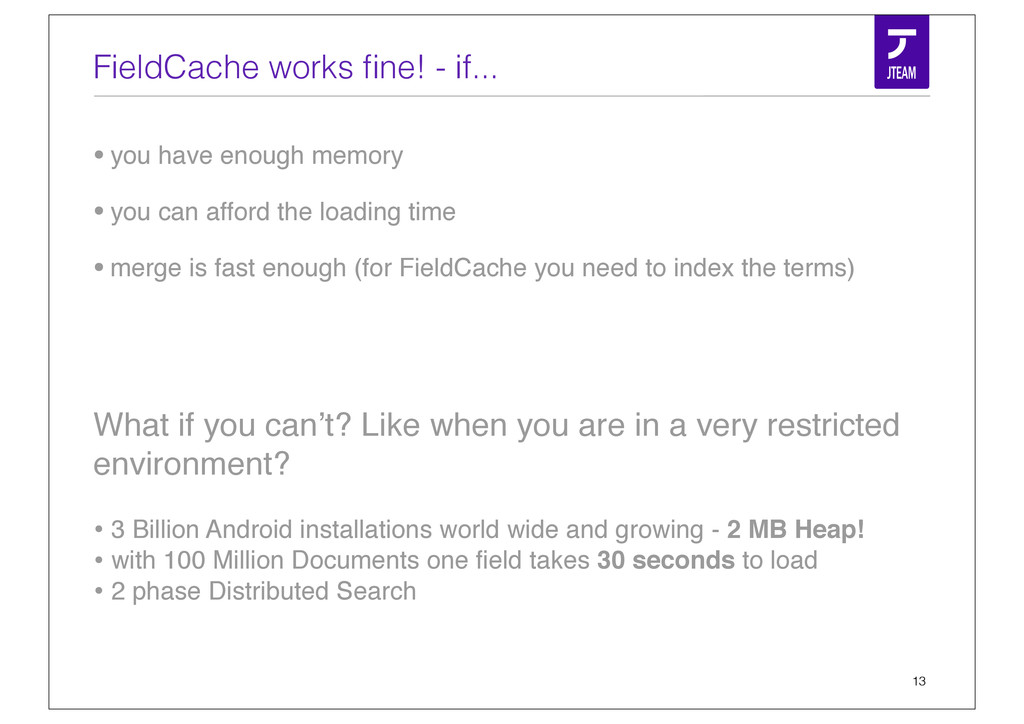{kind=link}
{kind=link}
{kind=link}
{kind=link}
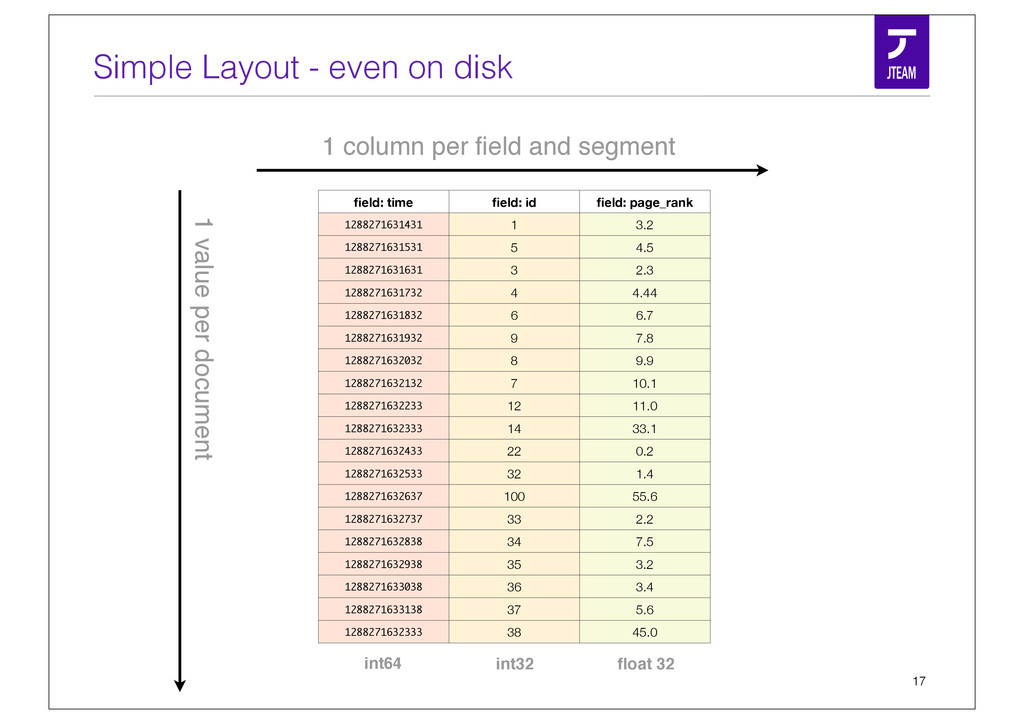{kind=link}
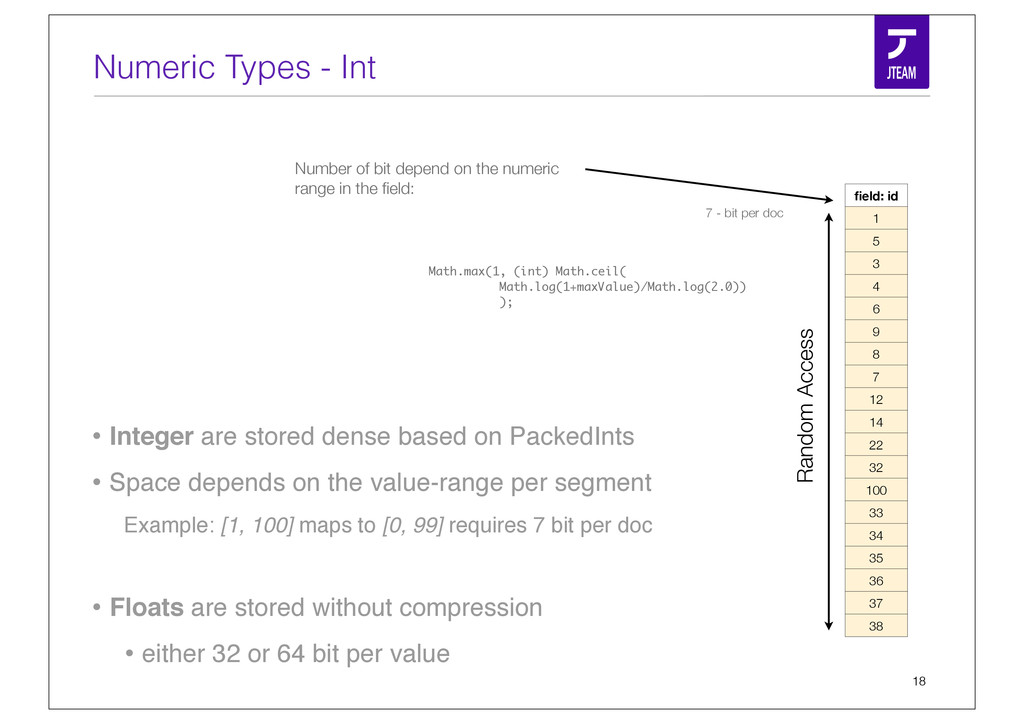{kind=link}
![Arbitrary Values - The byte[] variants •Length Variants: •Fixed /](https://files.speakerdeck.com/presentations/ba854fe02ab70130be4b1231381b1195/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
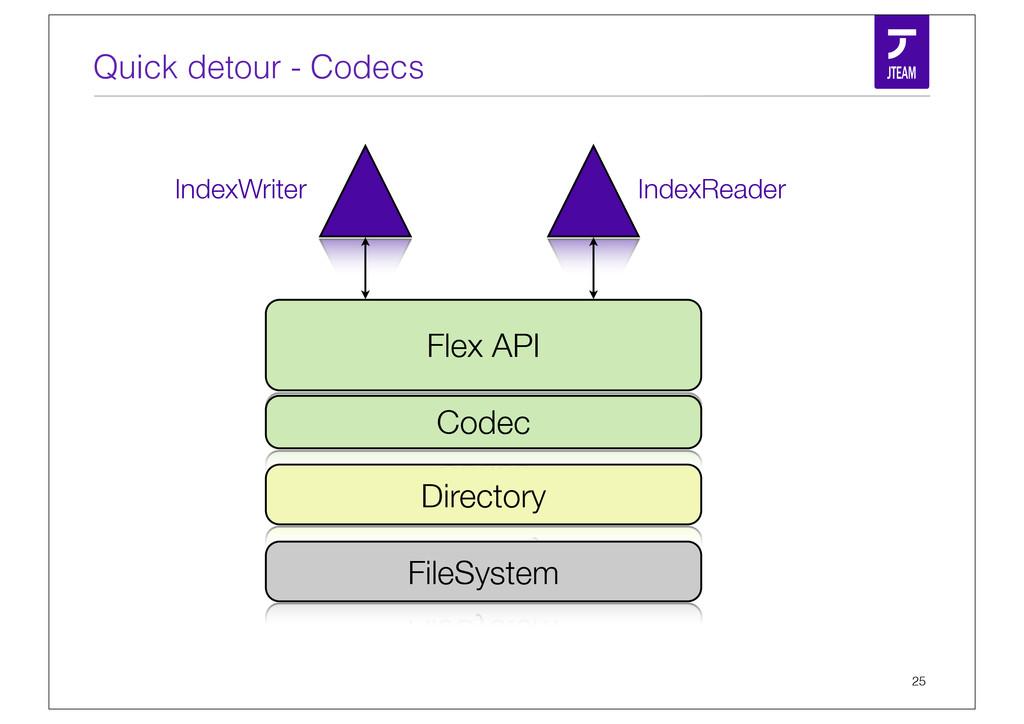{kind=link}
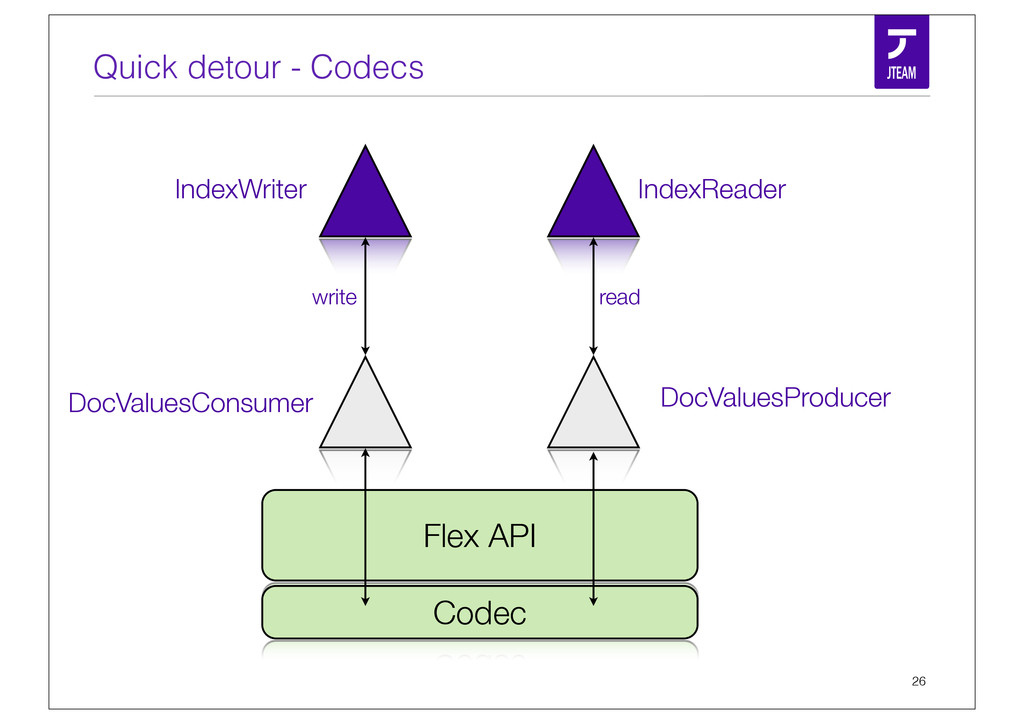{kind=link}
{kind=link}
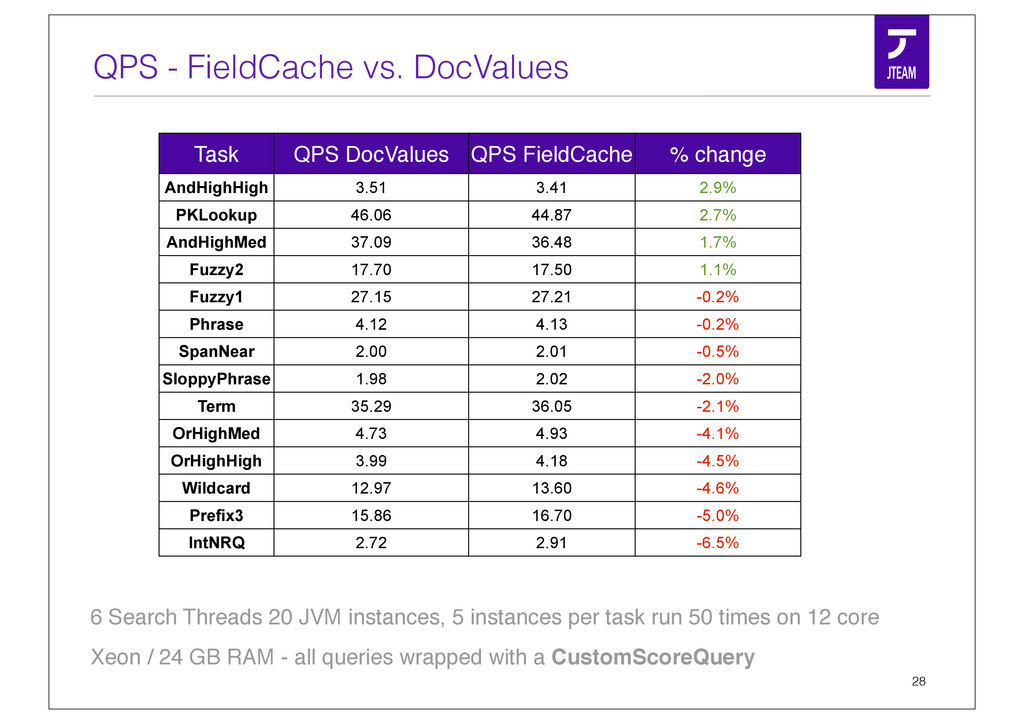{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}