During the last decade Apache Lucene became the de-facto standard in open source search technology. Thousands of applications from Twitter Scale Webservices to Computers playing Jeopardy rely on Lucene, a rock-solid, scaleable and fast information-retrieval library entirely written in Java. Maintaining and improving such a popular software library reveals tough challenges in testing, API design, data-structures, concurrency and optimizations. This talk presents the most demanding technical challenges the Lucene Development Team has solved in the past. It covers a number of areas of software development including concurrency & parallelism, testing infrastructure, data-structures, algorithms, API designs with respect to Garbage Collection, and Memory efficiency and efficient resource utilization. This talk doesn’t require any Apache Lucene or information-retrieval background in general. Knowledge about the Java programming language will certainly be helpful while the problems and techniques presented in this talk aren’t Java specific.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
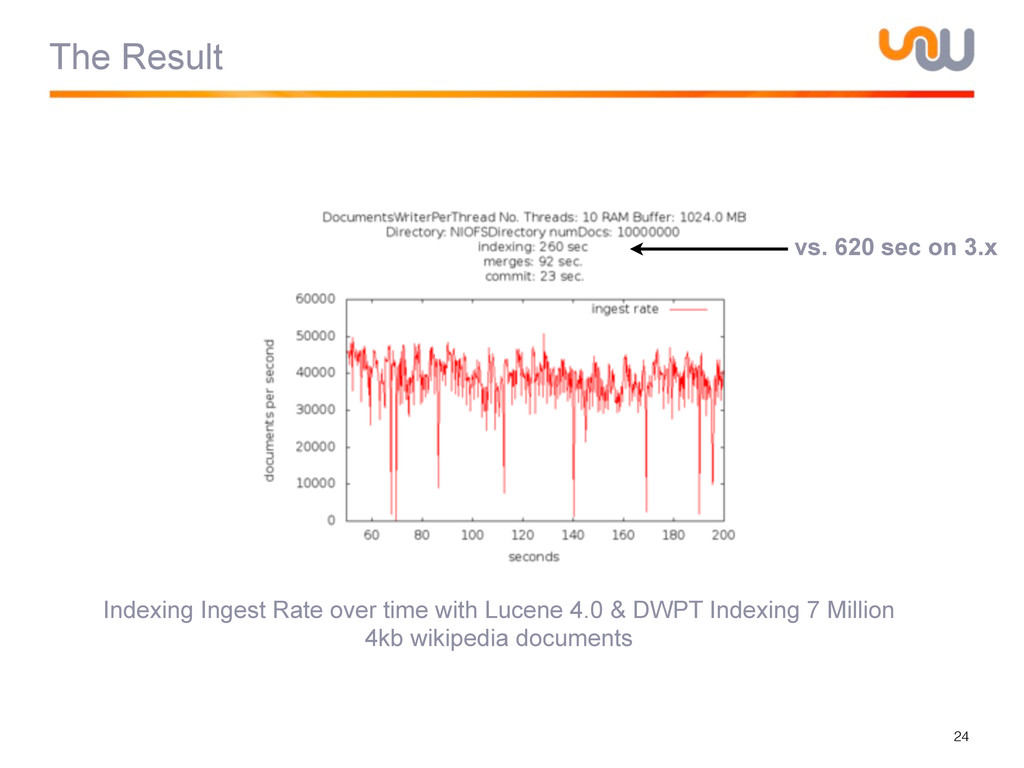{kind=link}
{kind=link}
{kind=link}
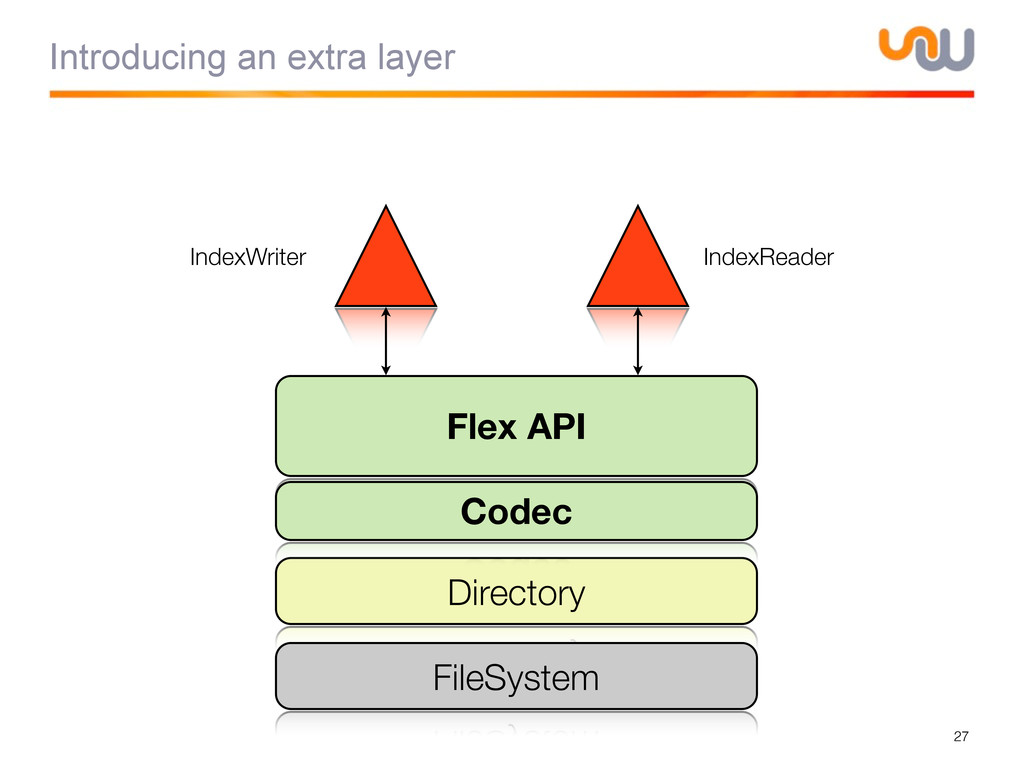{kind=link}
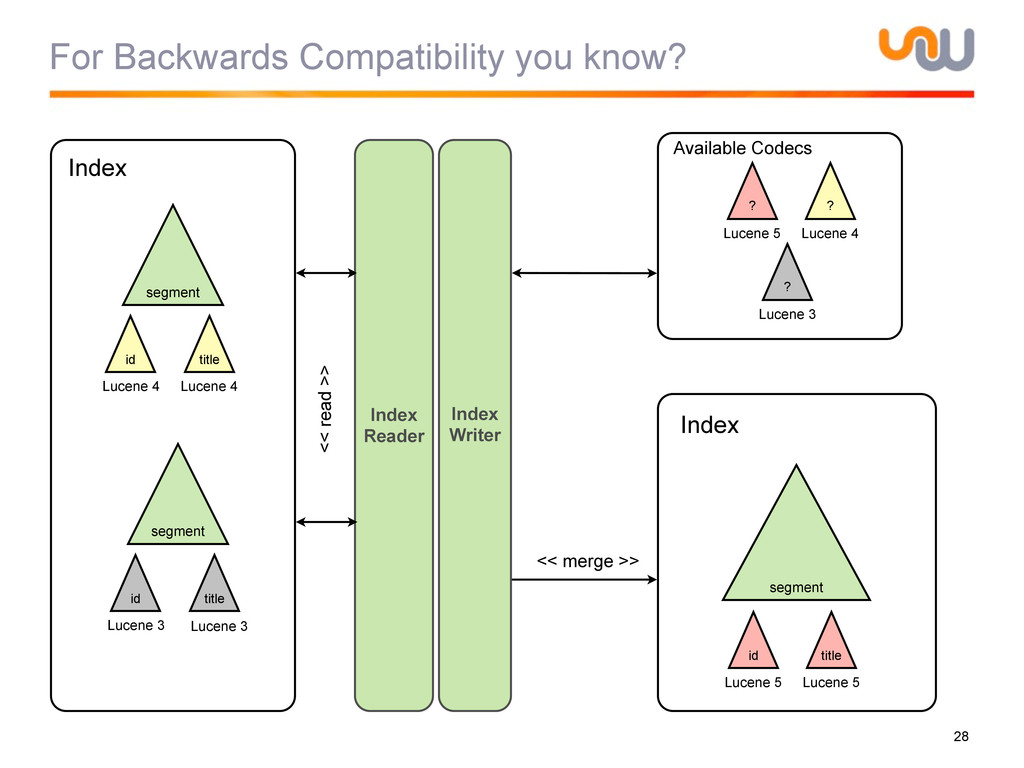{kind=link}
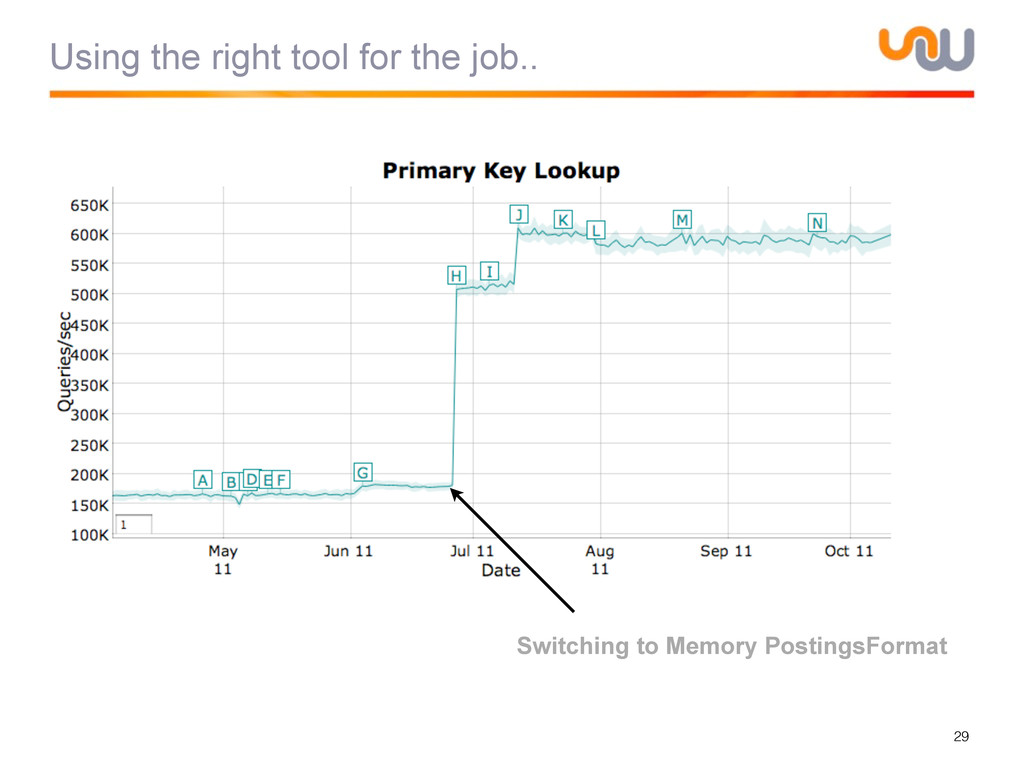{kind=link}
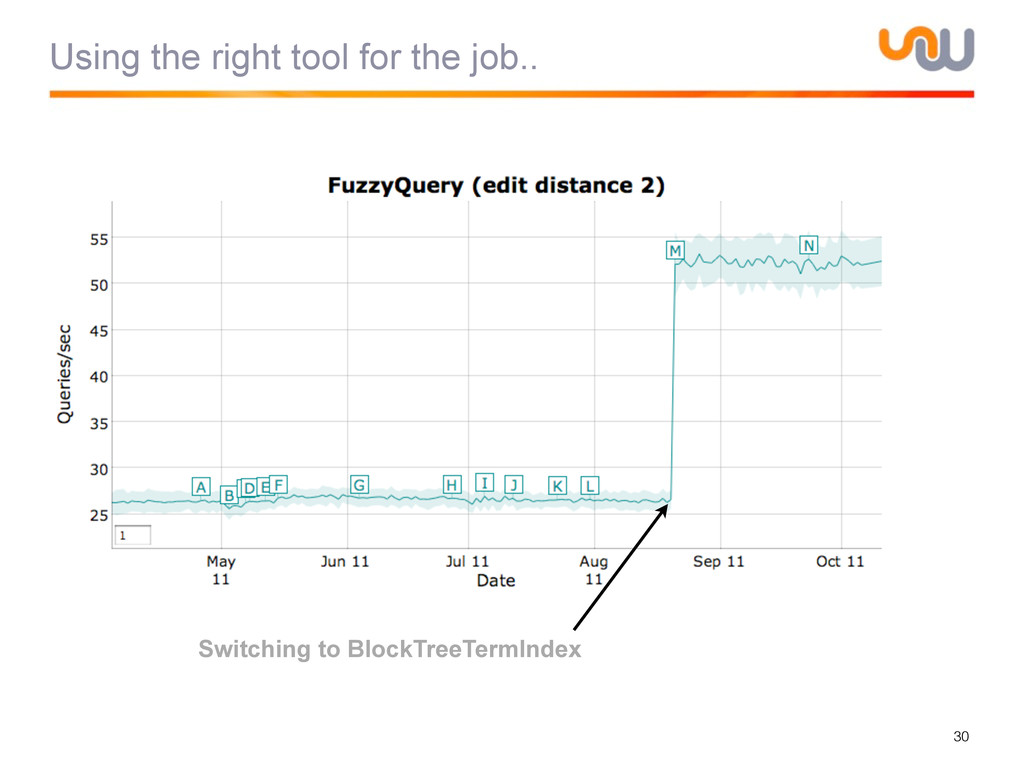{kind=link}
{kind=link}
{kind=link}
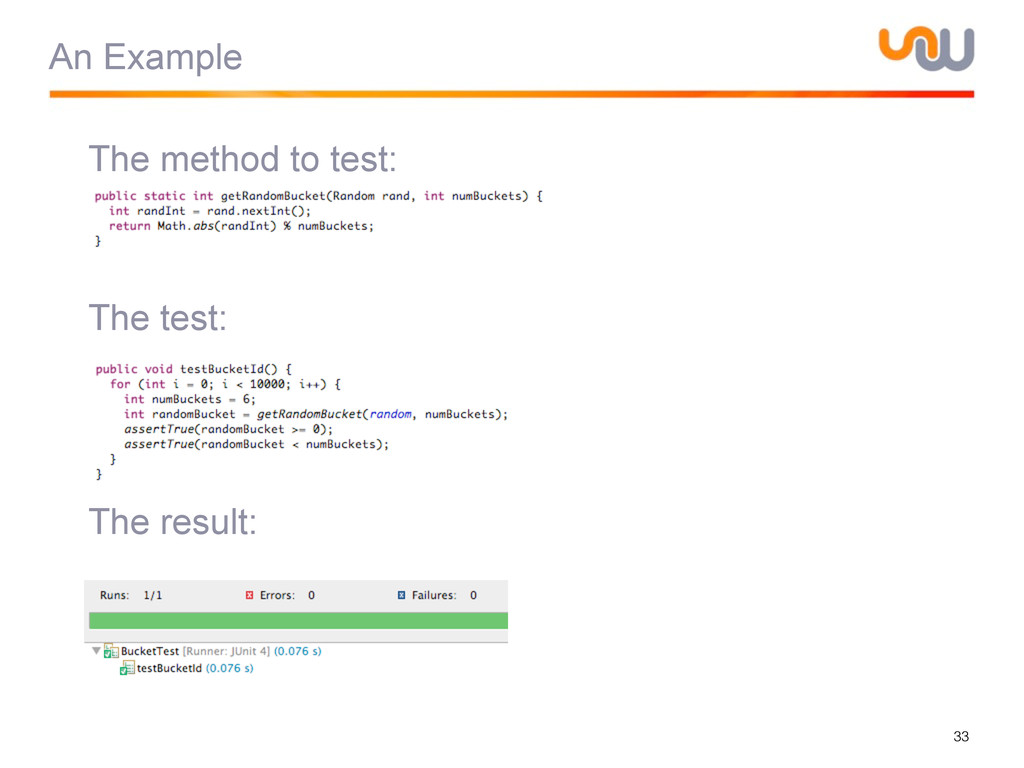{kind=link}
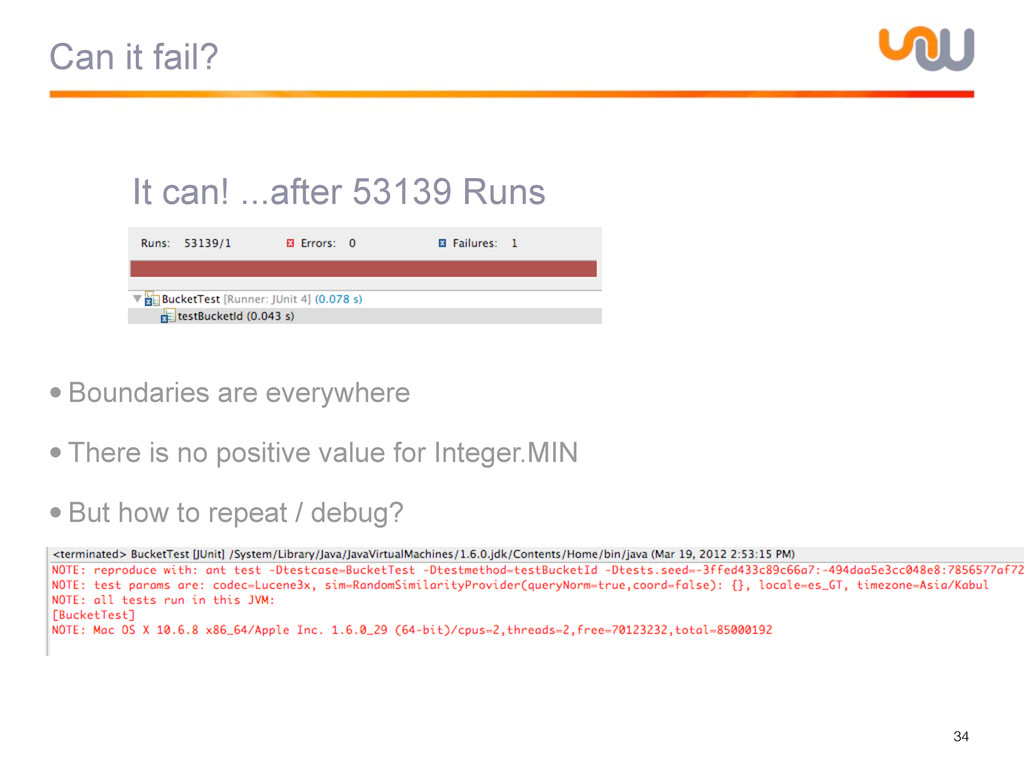{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
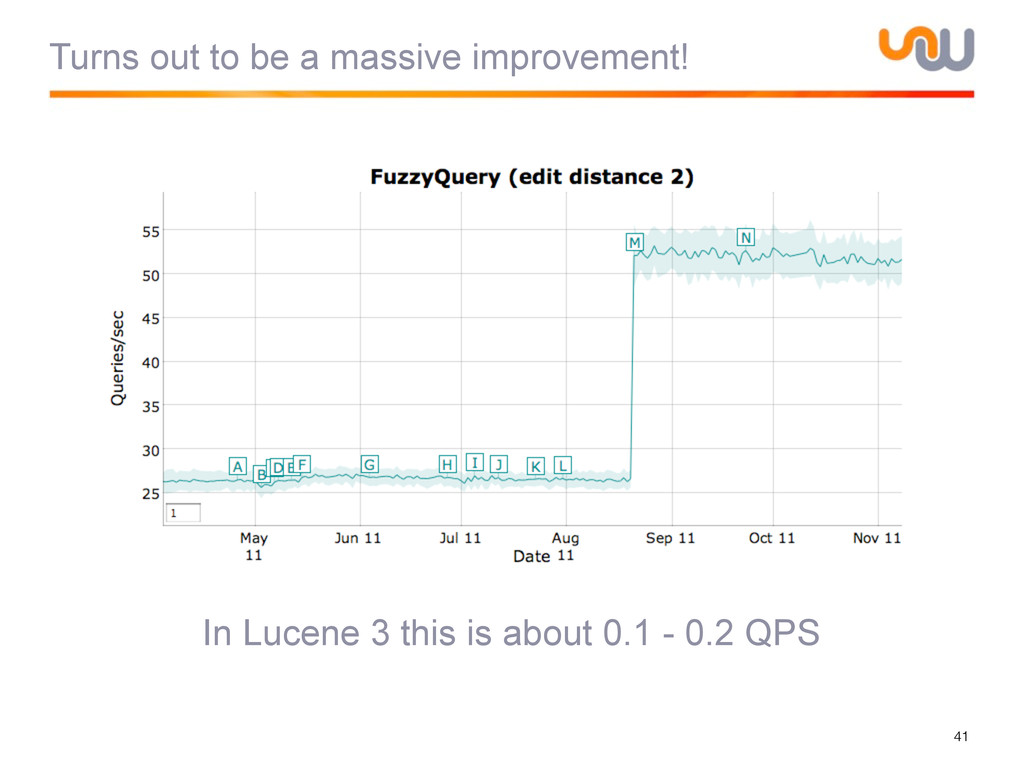{kind=link}
{kind=link}
{kind=link}
{kind=link}