is strictly prohibited What is this guy talking about? • Shard Allocation • What is this and why do I need it? • Is it new? • What is new? • Improvements in the pipeline • “new stuff in Lucene 4” ...wait, in what? • things you care that will come soon in ES
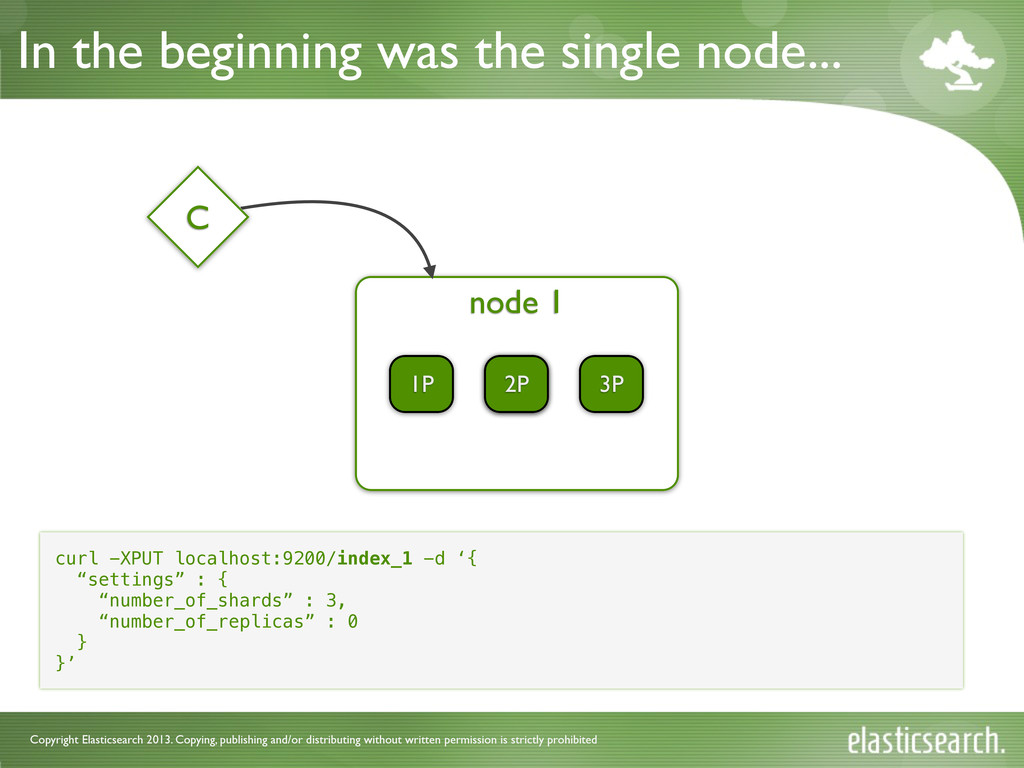
is strictly prohibited In the beginning was the single node... node 1 1P 2R 2P C curl -XPUT localhost:9200/index_1 -d ‘{ “settings” : { “number_of_shards” : 3, “number_of_replicas” : 0 } }’ 3P
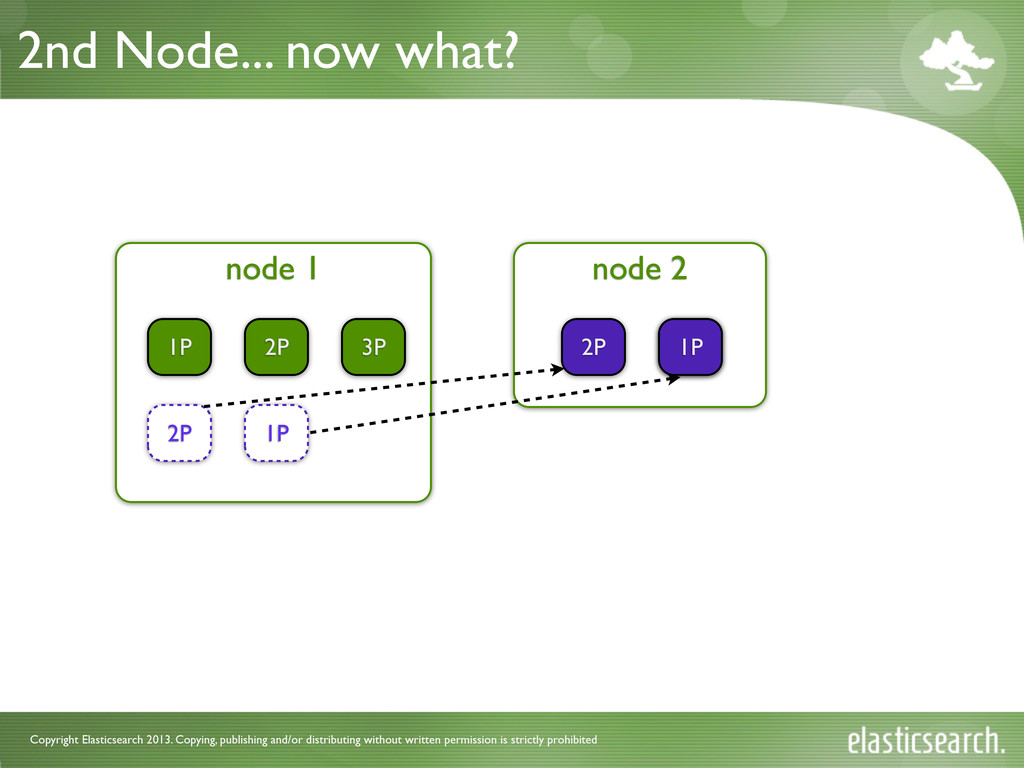
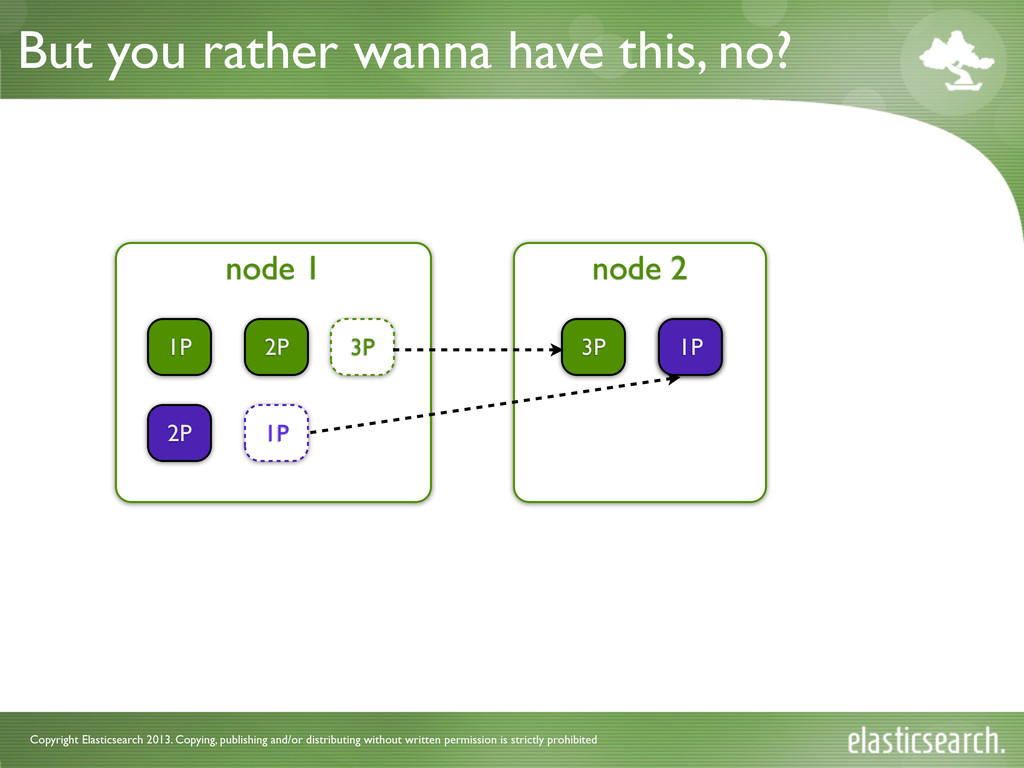
is strictly prohibited What changed? • EvenShardCountAllocator • balanced across shards and nodes • no notion of an index • tries to put same amount of shards on each node • BalancedShardsAllocator • based on a weight function • weights are calculated per node in an index context • users can influence the weight of an attribute
is strictly prohibited What can I adjust • how important for you is • balance over # of shards • balance over indices • balance over primaries • how aggressive rebalance acts • a threshold defining the minimum delta between 2 nodes to issue a rebalance operation. Default is 1.0f • ...more to come
is strictly prohibited Future Work? • Ways to expand the weight function • size of a shard • average number of request on a shard • number of docs in the shard • <your requirement goes here> • Eventually we want the weight function to be customizable to be able to allow users to balance their cluster based on their needs.
is strictly prohibited Lucene 4.0 / 4.1 • Many features under the hood • Massive improvements in terms of memory consumption internally • Compression build in. • Fast FuzzyQuery • Faster Batch-Indexing • Bloom Filters build at index time • refresh might be much cheaper now • Default encoding on disk is based on blocks...
is strictly prohibited FieldData? • Used for Faceting, Sorting, Scoring • Until 0.20 not very flexible • Implementation details leaked the interface • 0.21 adds a new interface in order to improve memory and runtime performance • new FieldData will allow specialized implementations / data-structures per field • Defaults will be much more memory efficient (UTF-8 bytes vs. UTF-16 chars) • Future implementations can even read from MemoryMaps etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}