Presentation from ApacheCon Europe 2012
Apache Lucene has undergone a major overhaul influencing many of the key characteristics dramatically. New features and modification allow for new as well as fundamentally different ways of tuning the engine for best performance.
Tuning performance is essential for almost every Lucene based application these days - Search & Performance almost a synonyms. Knowing the details of the underlying software provides the basic tools to get the best out of your application. Knowing the limitations can safe you and your company a massive amount of time and money. This talks tries to explain design decision made in Lucene 4 compared to older versions and provide technical details how those implementations and design decisions can help to improve the performance of your application. The talk will mainly focus on core features like:
Realtime & Batch Indexing
Filter and Query performance
Highlighting and Custom Scoring
The talk will contain a lot of technical details that require a basic understanding of Lucene, datastructures and algorithms. You don't need to be an expert to attend but be prepared for some deep dive into Lucene. Attendees don't need to be direct Lucene users, the fundamentals provided in this talk are also essential for Apache Solr or elasticsearch users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
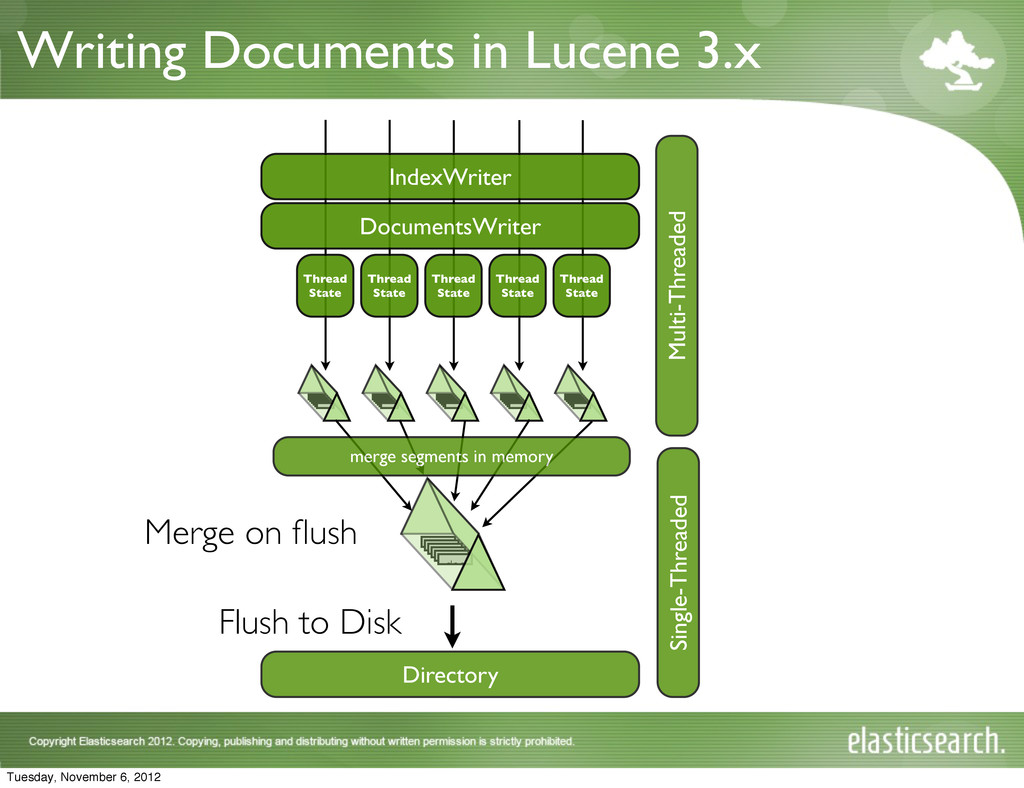{kind=link}
{kind=link}
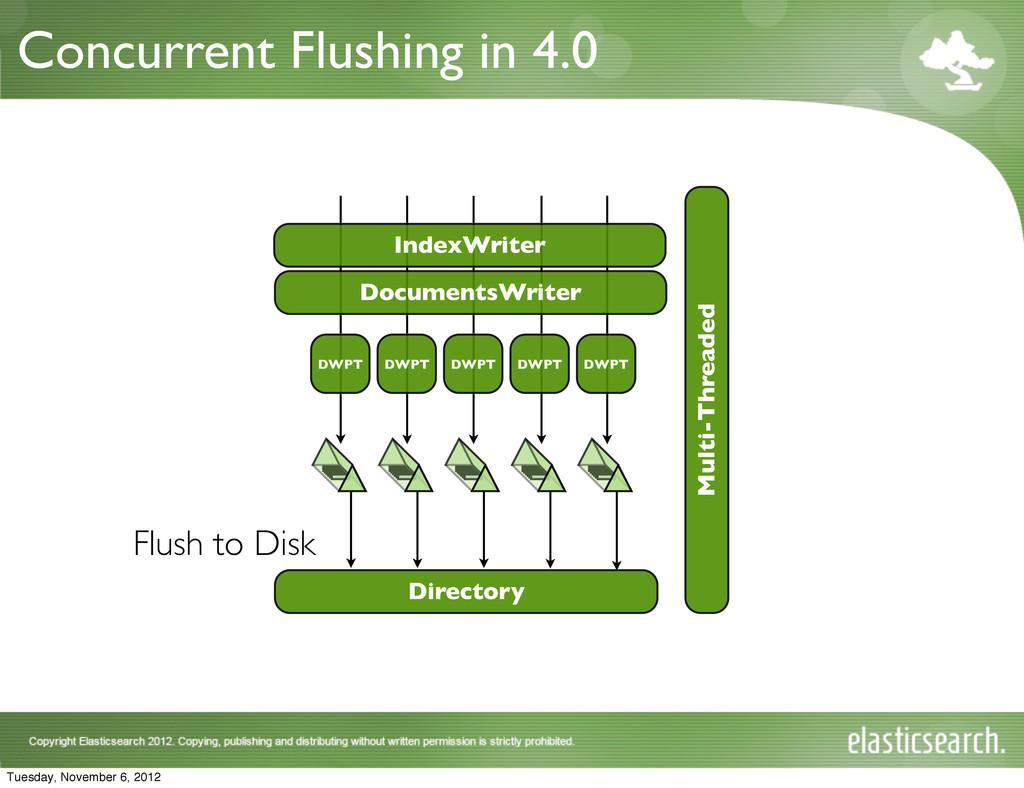{kind=link}
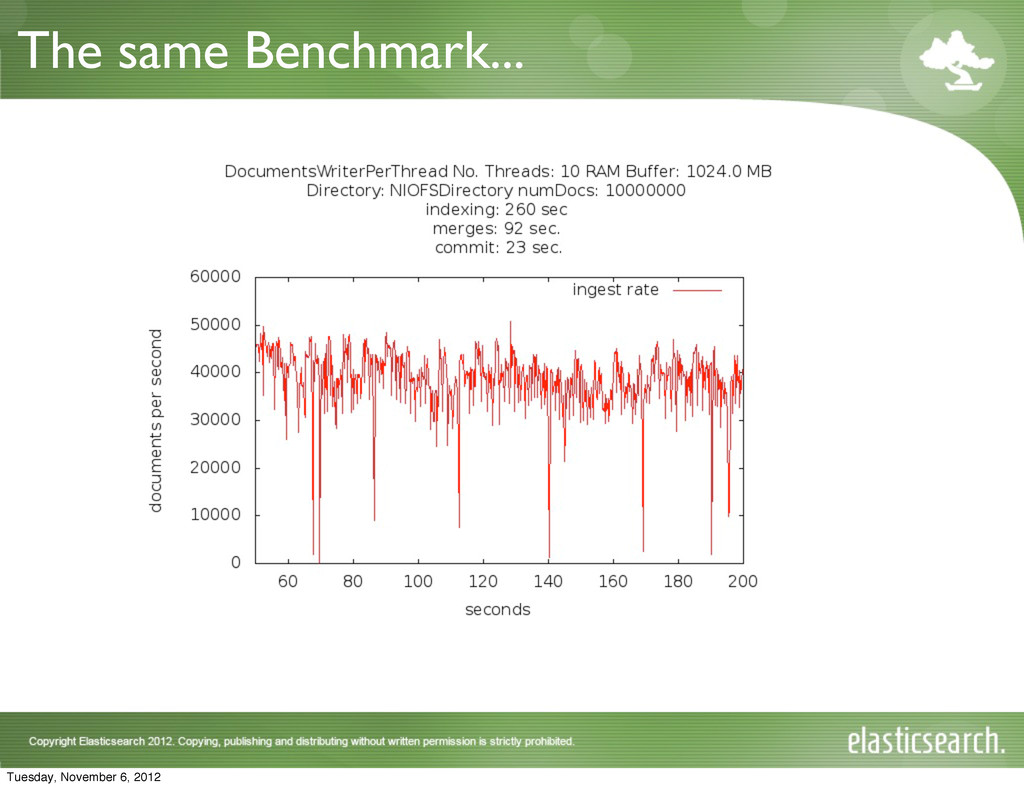{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}