tasks to learn new, related tasks efficiently • Typically, a set of training tasks is assumed given or randomly chosen • However, exploring the task domain is impractical in many real-world application and uniform sampling is often sub-optional 4 / 33
• Tasks T i (i = 1, ... , N) • Observations DT i = {(xi j , yi j )} (j = 1, ... , Mi ) • Each distribution T i ∼ p(T), DT i ∼ p(Yi|Xi, T i ) • Xi, Yi: A matrix of data • The joint distribution over task T i and data DT i : The Joint Distribution p(Yi, T i |Xi) = p(Yi|T i, Xi)p(T i ) (1) 7 / 33
variable • Made distinct from global model parameters 𝜃 • 𝜃 are shared among all tasks • Learn a continuous latent representation hi ∈ RQ of task T i 8 / 33
to make predictions Y∗ given test inputs X∗ at the test time, as faced with unseen task T ∗ (Scenario: Few-shot learning) Predictions with Optimized Parameters p𝜃 (Y∗|X∗) = Eq𝜙 (h∗) [p𝜃 (Y∗|X∗, h∗)] (6) • Without any observations from new task, it’s possible to make zero-shot predictions by replacing the variational posterior q𝜙(h∗) with the prior p(h∗) 14 / 33
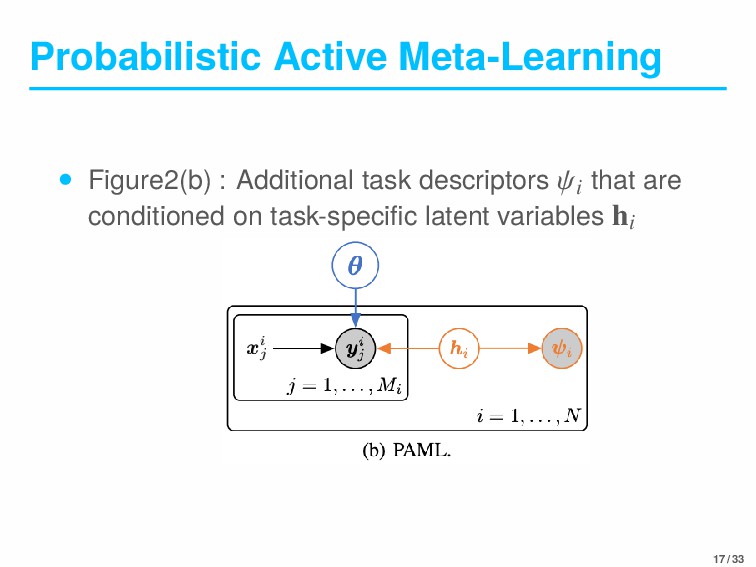
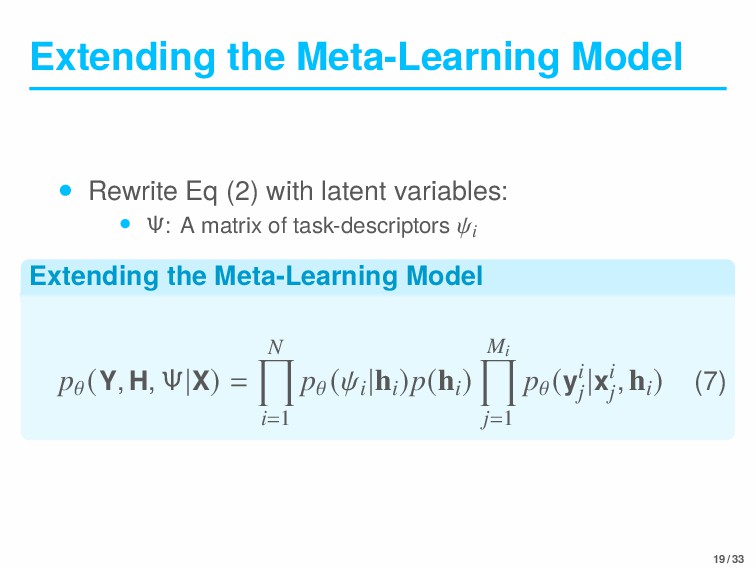
Task-descriptors(task-descriptive observations): it’s possible to select which task to learn next • Task-descriptors of task T i : 𝜓i • The algorithm for active meta-learning • To make a discrete selection from a set of task-descriptors • To generate a valid continuous parameterization 16 / 33
similarities/differences that represents the full task configuration T • Eq (10) : Two tasks that are similar are encouraged to be closer in latent space 21 / 33
latent space, we define the utility of a candidate h∗ as the self-information/surprisal associated with h∗ : Utility Function u(h∗) := − log N ∑ i=1 q𝜙i (h∗) + log N (11) 22 / 33
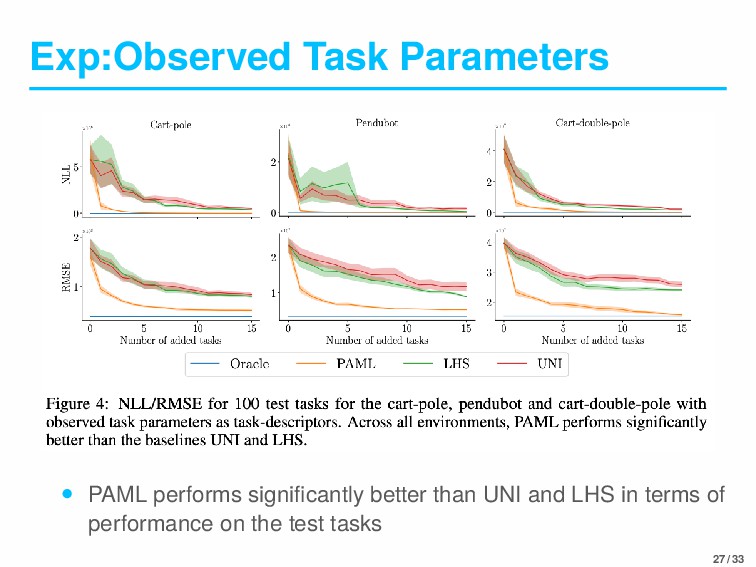
by learning a meta-model for the dynamics of simulated robotics systems • Performance measures: • Negative Log-Likelihood(NLL): considers the full posterior predictive distribution at a test input • The Root Mean Squared Error (RMSE): considers only the predictive mean 24 / 33
errors in fewer trials than the baselines • The error after one added task of our methods is approximately matched by the baselines after about five added tasks • In Figure5(b), PAML performed better prediction than baselines 28 / 33
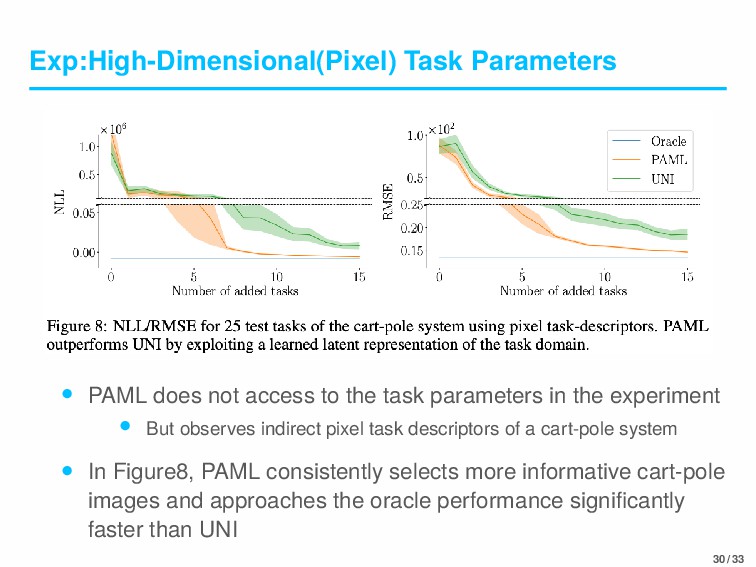
task parameters in the experiment • But observes indirect pixel task descriptors of a cart-pole system • In Figure8, PAML consistently selects more informative cart-pole images and approaches the oracle performance significantly faster than UNI 30 / 33
ideas from active and meta-learning • Extend ideas from meta-learning to incorporate task descriptors for active learning of a task domain • where the algorithm can choose which task to learn next by taking advantage of prior experience • Take advantage of learned latent task embeddings to find a meaningful space to express task similarities 32 / 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}