RisingStack's journey about breaking down a monolith application into microservices.
Presented at https://nodeconf.risingstack.com in 2017 January.
Contact speaker here: https://twitter.com/slashdotpeter
Included topics:
- Business and technology benefits and drawbacks of microservices
- Why we moved
- Service principles: versioning and documenting
- Automation
- Proxy and API Gateway approaches
- Fault tolerance: Caching, CQRS
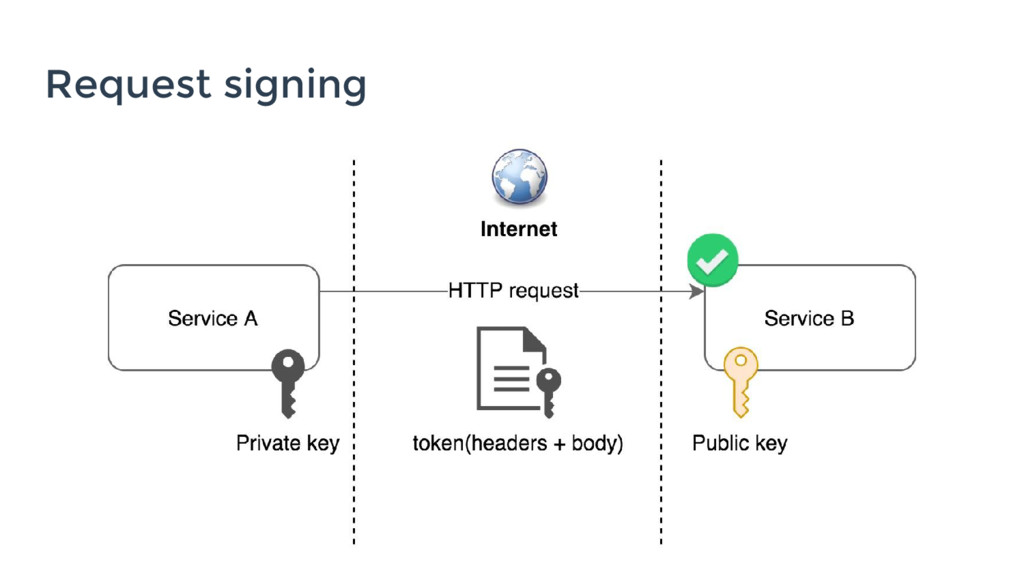
- Request Signing
- Zero downtime deployment: Kubernetes, Graceful shutdown, Rolling deployment, Self-healing
- Microservices monitoring and debugging challenges
- Distributed Tracing
- Network Delay use-case
What's next?
https://blog.risingstack.com/tag/node-js-at-scale
https://www.martinfowler.com/microservices
https://microserviceweekly.com/
https://trace.risingstack.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}