data store with optional durability. It is written in ANSI C. The development of Redis is sponsored by VMware. Redis is the most popular key-value store Repeat after me: "Thank you wikipedia" :)
• Key domains are splitted with ":" • Words are splitted with "." Key Example Correct? Linux SET Linux "Open source OS" ✔ Linux:{ID} HGETALL linux:5 ✔ Linux-{ID} ✘ Linux:debian.like:distros LLEN Linux:debian.like:distros ✔ Linux:RH like:distros ✘ Linux:{ID}:characteristics HGETALL Linux:5:characteristics ✔ Linux:characteristics:{ID} HGETALL Linux:characteristics:5 ✔
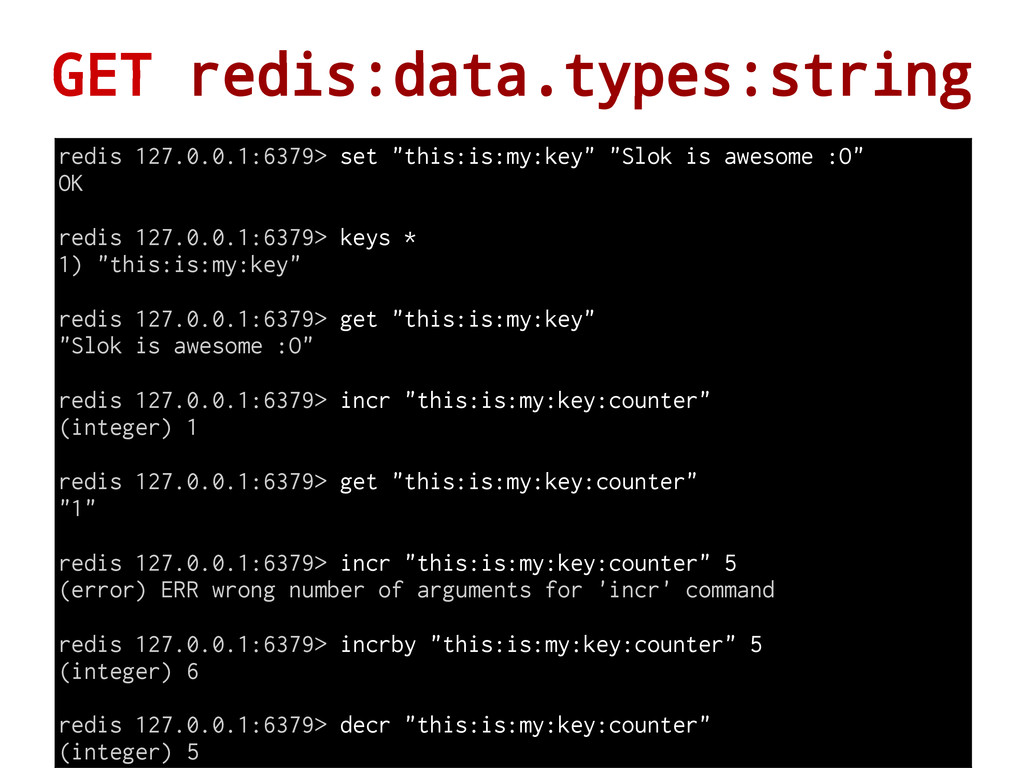
value. A value is mapped to a key We could use SET and GET commands to set and get keys Redis Strings are binary safe, this means that a Redis string can contain any kind of data, for instance a JPEG image or a serialized Python object. Thanks to this, we could use it for different types of use cases: • Integer/float: As a counter (INCR, DECR, INCRBY, INCRBYFLOAT...) • Bit: as bitmaps/binary stuff (SETBIT, GETBIT, BITCOUNT, BITOP...) • String: regular DB (APPEND, GETRANGE...) redis 127.0.0.1:6379> set "key" "value" OK redis 127.0.0.1:6379> get "key" "value" - A String value can be at max 512 Megabytes in length! - Integer commands (INCR, DECR...) in redis are Atomic!
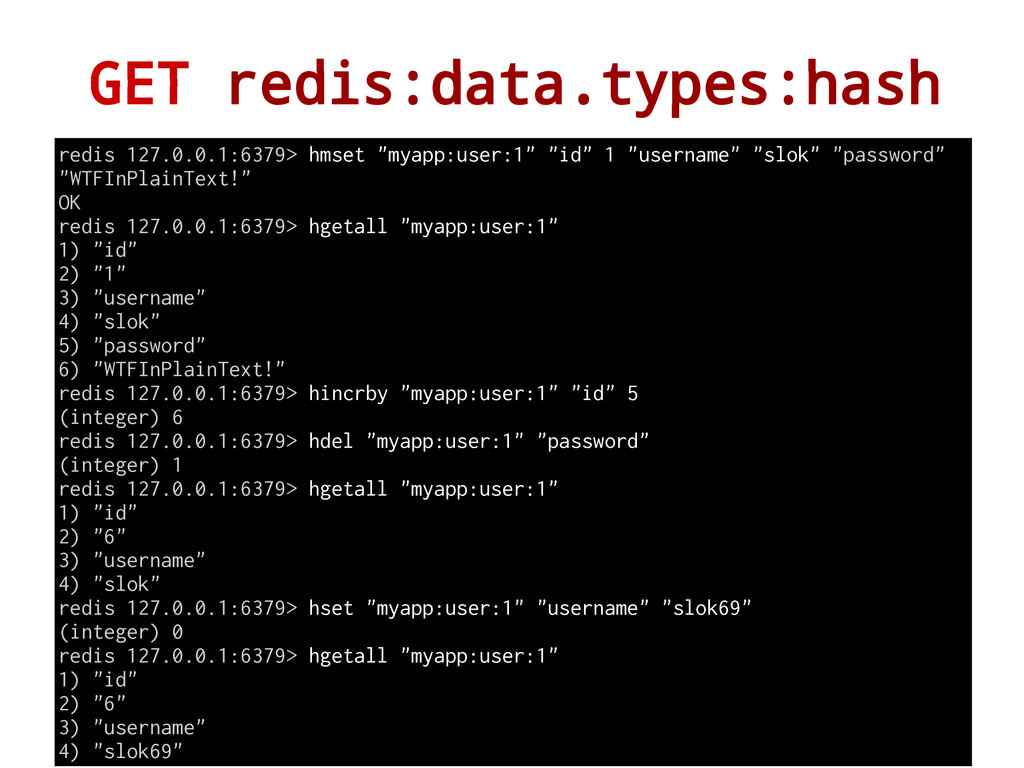
string values, so they are the perfect data type to represent objects Why use this instead of various String redis data structures? This has better performance, in memory access and data compression Every hash can store up to 232 - 1 field-value pairs (more than 4 billion) redis 127.0.0.1:6379> hset "myapp:person:1" "name" "Xabier" (integer) 1 redis 127.0.0.1:6379> hget "myapp:person:1" "name" "Xabier" redis 127.0.0.1:6379> hset "myapp:person:1" "last_name" "Larrakoetxea" OK redis 127.0.0.1:6379> hgetall "myapp:person:1" 1) "name" 2) "Xabier" 3) "last_name" 4) "Larrakoetxea" - Use Hash instead of strings if possible (If that make sense!). - Hash fields also could work as (atomic) counters!
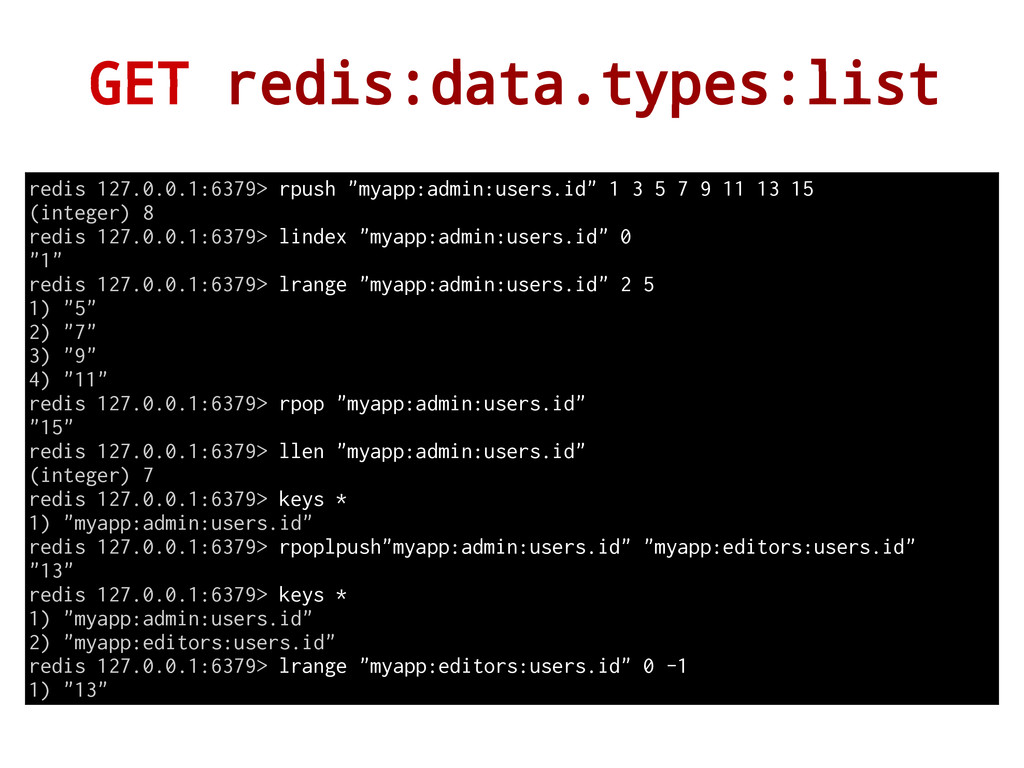
by insertion order. It is possible to add elements to a Redis List pushing new elements on the head (on the left) or on the tail (on the right) of the list. redis 127.0.0.1:6379> lpush "myapp:admin:users.id" 4 (integer) 1 redis 127.0.0.1:6379> lpush "myapp:admin:users.id" 6 (integer) 2 redis 127.0.0.1:6379> rpush "myapp:admin:users.id" 1 (integer) 3 redis 127.0.0.1:6379> lrange "myapp:admin:users.id" 0 -1 1) "6" 2) "4" 3) "1" - When we add an item it returns the length of the list. - Constant time insertion and deletion O(1). - Access by index is O(N) Very fast! (sides access: O(1)). - The max length of a list is 232 - 1 elements (> 4 billion).
It is possible to add, remove, and test for existence of members. Redis Sets have the desirable property of not allowing repeated members. Adding the same element multiple times will result in a set having a single copy of this element. redis 127.0.0.1:6379> sadd "myapp:admin:users.id" 1 2 3 4 5 6 7 8 (integer) 8 redis 127.0.0.1:6379> sadd "myapp:editors:users.id" 1 3 7 8 (integer) 4 redis 127.0.0.1:6379> sdiff "myapp:admin:users.id" "myapp:editors:users.id" 1) "2" 2) "4" 3) "5" 4) "6" - Supports unions, intersections, differences of sets very fast - The max length of a set is 232 - 1 elements (> 4 billion).
non repeating collections of Strings. The difference is that every member of a Sorted Set is associated with score, that is used in order to take the sorted set ordered, from the smallest to the greatest score. While members are unique, scores may be repeated. redis 127.0.0.1:6379> zadd "prog:langs:90" 1991 "Python" 1993 "Lua" 1995 "Ruby" 1995 "Java" (integer) 4 redis 127.0.0.1:6379> zrange "prog:langs:90" 0 -1 1) "Python" 2) "Lua" 3) "Java" 4) "Ruby" - You can get ranges by score or by rank (position) - The max length of a zset is 232 - 1 elements (> 4 billion).
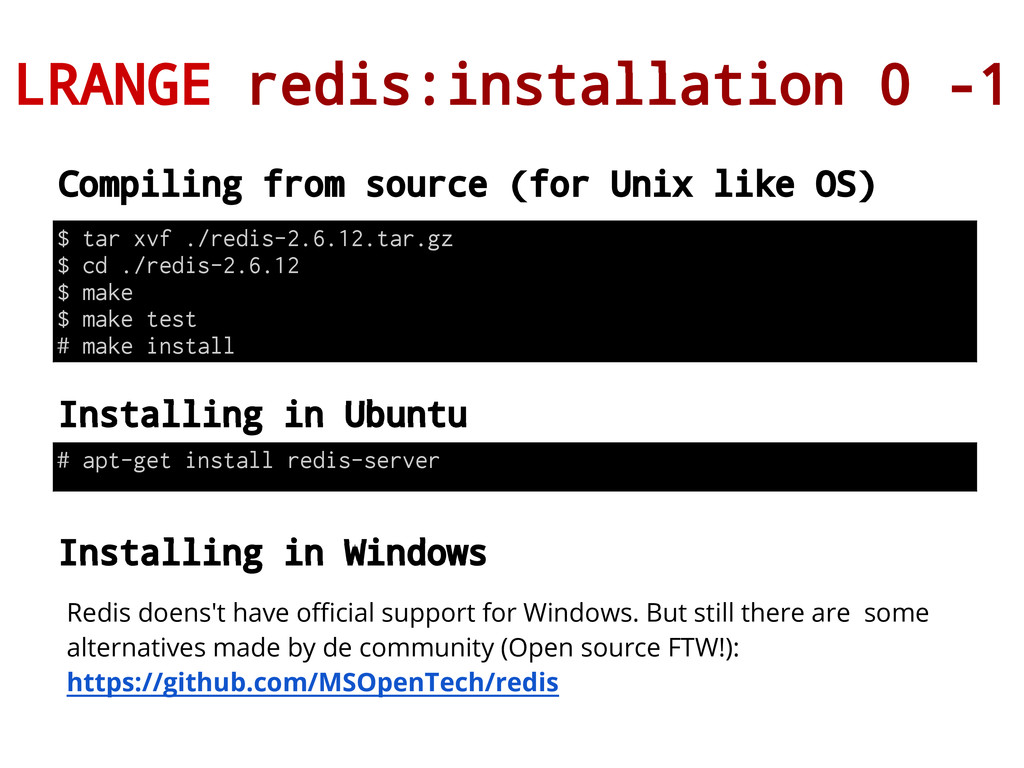
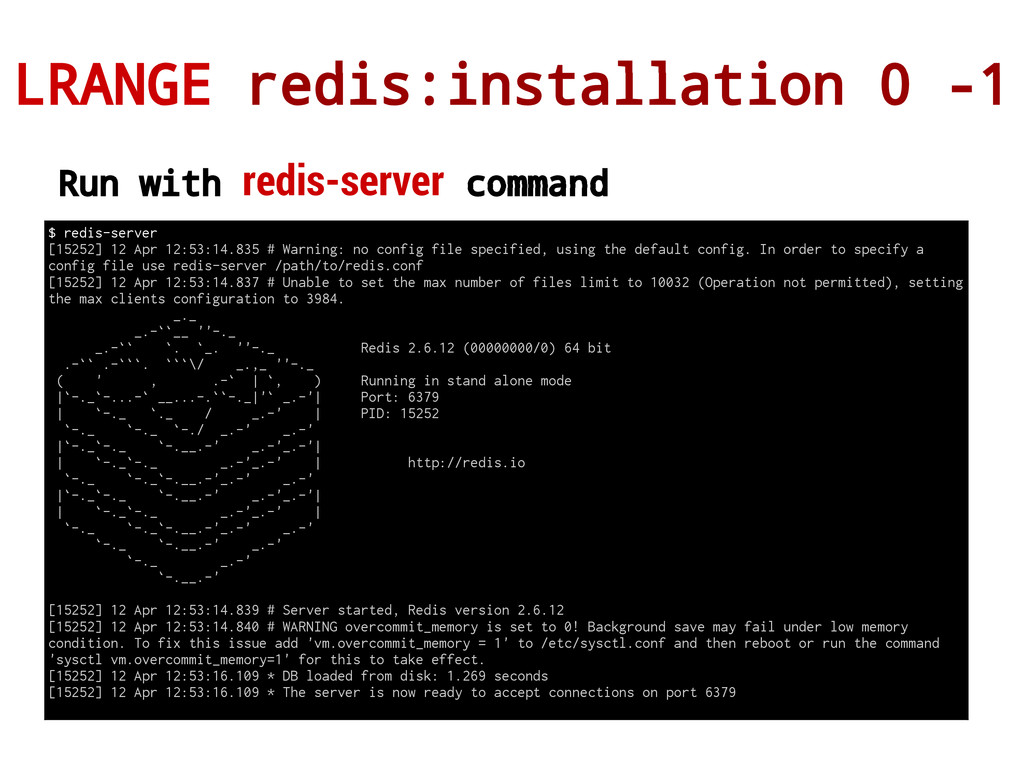
OS) $ tar xvf ./redis-2.6.12.tar.gz $ cd ./redis-2.6.12 $ make $ make test # make install Installing in Ubuntu # apt-get install redis-server Installing in Windows Redis doens't have official support for Windows. But still there are some alternatives made by de community (Open source FTW!): https://github.com/MSOpenTech/redis
[15252] 12 Apr 12:53:14.835 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf [15252] 12 Apr 12:53:14.837 # Unable to set the max number of files limit to 10032 (Operation not permitted), setting the max clients configuration to 3984. _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 2.6.12 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in stand alone mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 | `-._ `._ / _.-' | PID: 15252 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' [15252] 12 Apr 12:53:14.839 # Server started, Redis version 2.6.12 [15252] 12 Apr 12:53:14.840 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. [15252] 12 Apr 12:53:16.109 * DB loaded from disk: 1.269 seconds [15252] 12 Apr 12:53:16.109 * The server is now ready to accept connections on port 6379
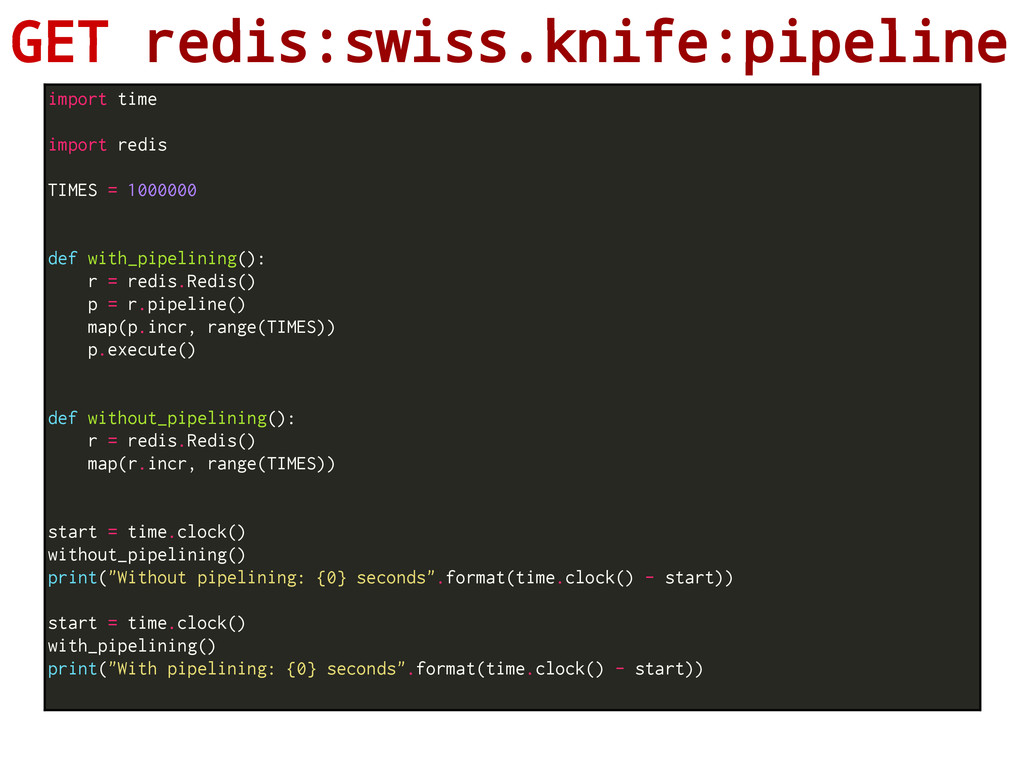
to the server without waiting for the replies at all, and finally read the replies in a single step. This is very powerful and reduces the time of request/response a lot Without pipelining: 125.34 seconds With pipelining: 24.8 seconds - The server will be forced to queue the replies, using memory. Split if mult. commands - No atomic execution. Between the list of commands the server could execute others For example this is the result for a loop that Increments 1 million new keys (not the same key, all the keys will finish with 1 value)
commands in a single step, with two important guarantees: • All the commands in a transaction are serialized and executed sequentially. It can never happen that a request issued by another client is served in the middle of the execution of a Redis transaction • Either all of the commands or none are processed, so a Redis transaction is also atomic. redis 127.0.0.1:6379> multi OK redis 127.0.0.1:6379> set "this" "will" "fail" QUEUED redis 127.0.0.1:6379> rpush "myList" 1 2 3 4 QUEUED redis 127.0.0.1:6379> exec 1) (error) ERR syntax error 2) (integer) 4 - Redis transactions doesn't support rollback - Transactions use more memory and are slower than pipelines
result: 100000 $ python ./redistransaction.py pipeline Executing pipeline result shouldn't be: 100000 result: 455 GET redis:transactions:vs:pipelines Pipelines and transactions are similar but not the same. Transactions are slower and requiere more memory, On the other side pipelines guarantee that the operations are atomic Transaction doesn't support rollback, like the SQL databases. Why? • Redis commands can fail only if called with a wrong syntax (and the problem is not detectable during the command queueing) • Redis is internally simplified and faster because it does not need the ability to roll back
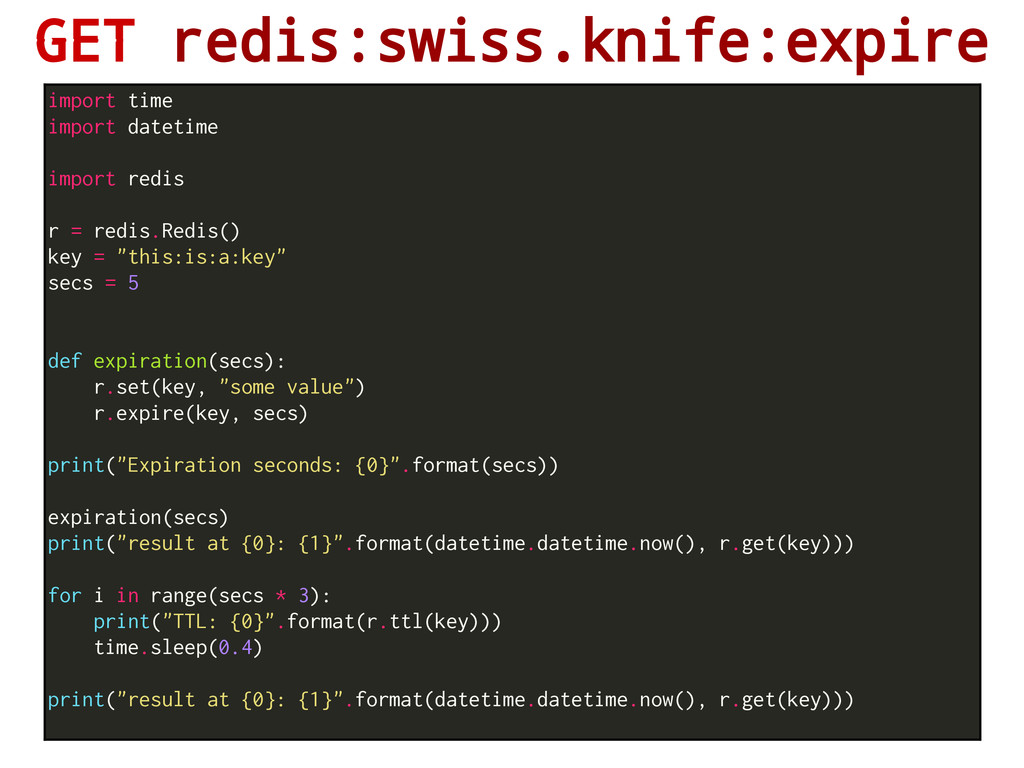
- Time is flowing even when the Redis instance is not active. - If you move an RDB file from two computers with a big desync in their clocks, funny things may happen Set a timeout on key. After the timeout has expired, the key will automatically be deleted. A key with an associated timeout is often said to be volatile in Redis terminology. redis 127.0.0.1:6379> set "myKey" "this will expire" OK redis 127.0.0.1:6379> expire "myKey" 5 (integer) 1 redis 127.0.0.1:6379> get "myKey" "this will expire" redis 127.0.0.1:6379> get "myKey" (nil)
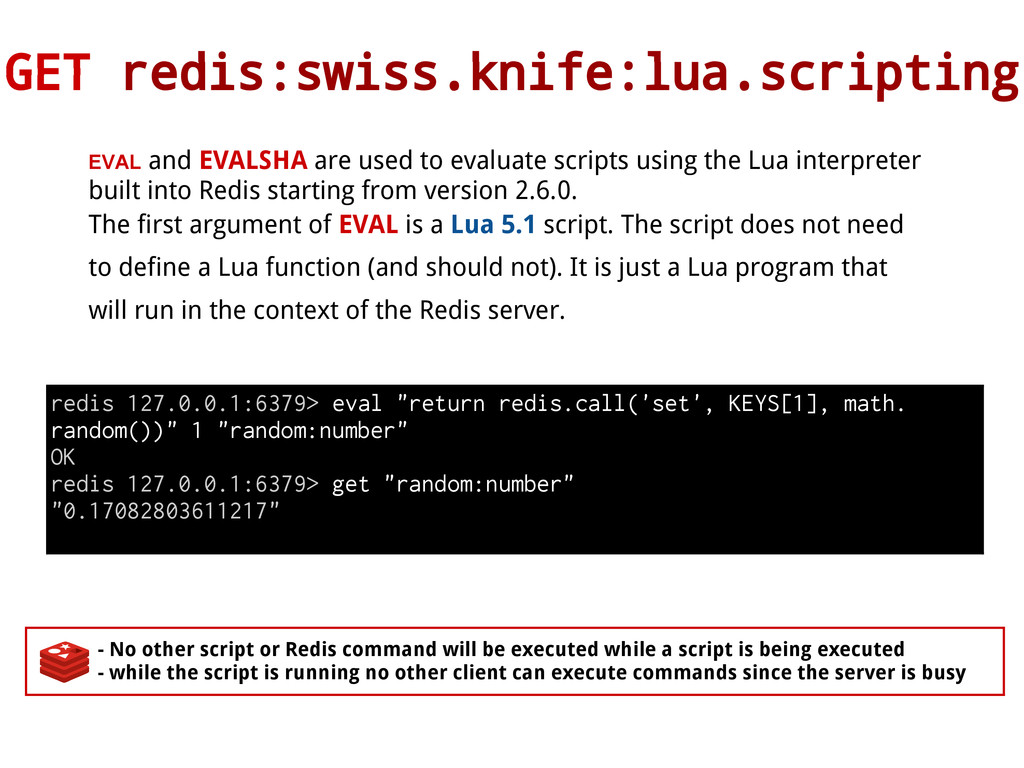
be executed while a script is being executed - while the script is running no other client can execute commands since the server is busy EVAL and EVALSHA are used to evaluate scripts using the Lua interpreter built into Redis starting from version 2.6.0. The first argument of EVAL is a Lua 5.1 script. The script does not need to define a Lua function (and should not). It is just a Lua program that will run in the context of the Redis server. redis 127.0.0.1:6379> eval "return redis.call('set', KEYS[1], math. random())" 1 "random:number" OK redis 127.0.0.1:6379> get "random:number" "0.17082803611217"
first = 0 local second = 1 local res local function fibo(x, y, max) if max ~= 0 then res = redis.call('rpush',KEYS[1],x) return fibo(y, x+y, max -1) else return res end end return fibo(first, second, i) """ r = redis.Redis() key = "fibonacci:example" fibo_digits = 100 r.flushdb() fibonacci = r.register_script(fiboLuaScript) result = fibonacci(keys=[key], args=[fibo_digits]) print("result of calling fibonacci with lua in Redis: {0}".format(result)) print("fibonacci result:\n{0}".format(r.lrange(key, 0, -1))) GET redis:swiss.knife:lua.scripting
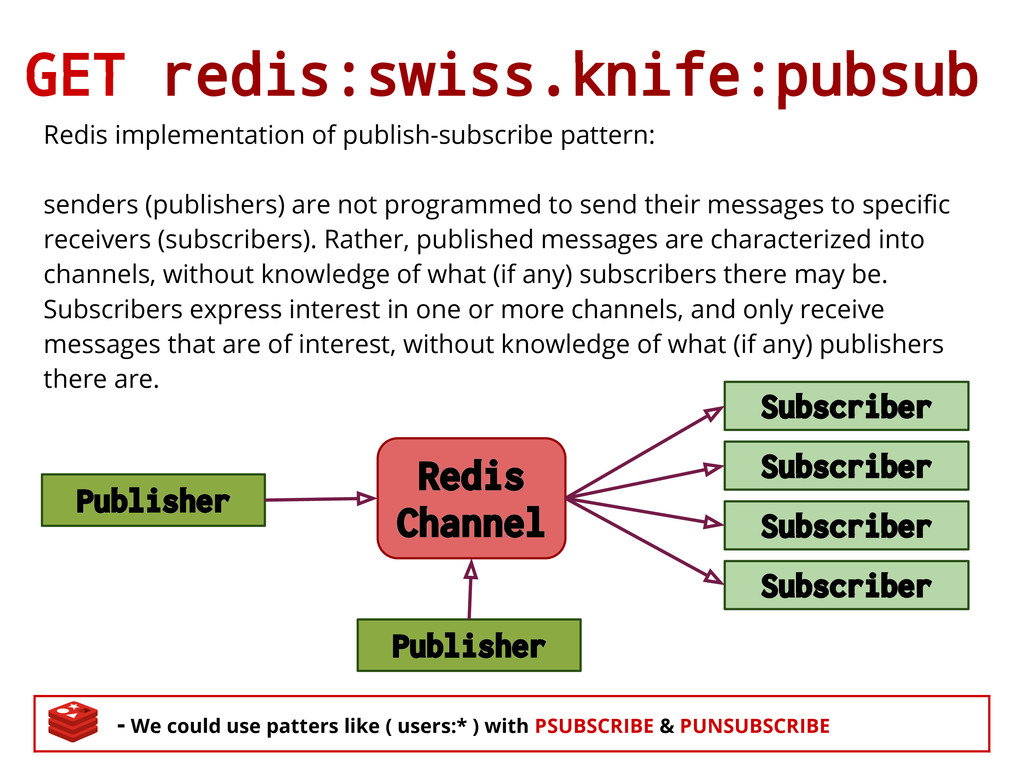
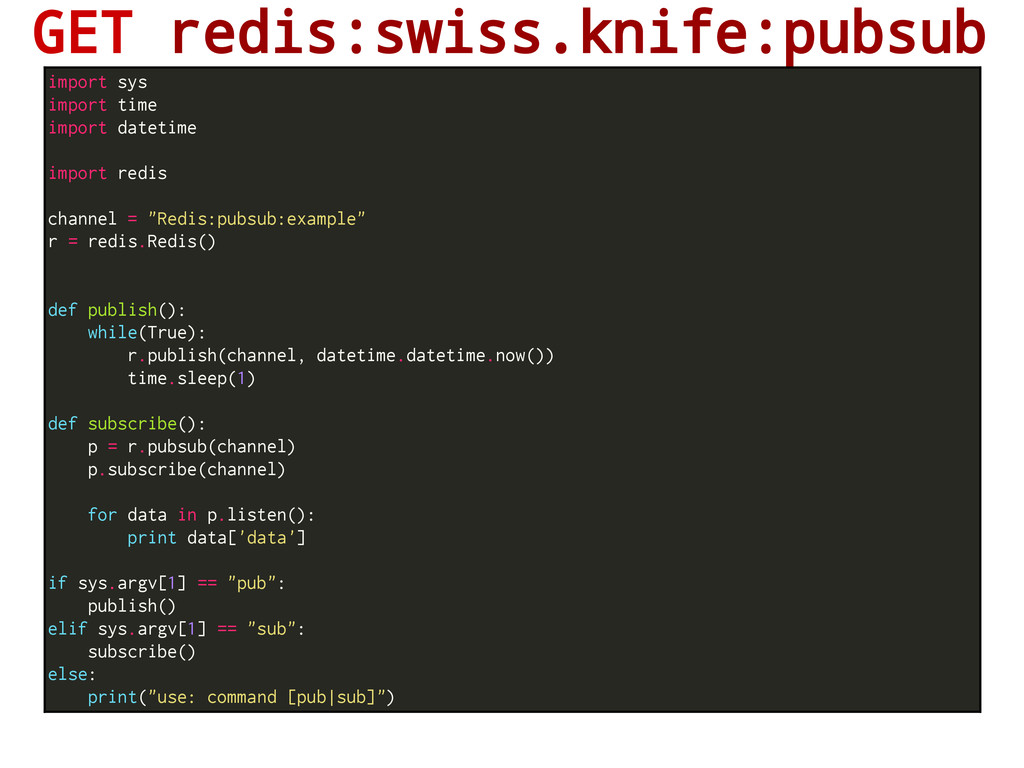
) with PSUBSCRIBE & PUNSUBSCRIBE Redis implementation of publish-subscribe pattern: senders (publishers) are not programmed to send their messages to specific receivers (subscribers). Rather, published messages are characterized into channels, without knowledge of what (if any) subscribers there may be. Subscribers express interest in one or more channels, and only receive messages that are of interest, without knowledge of what (if any) publishers there are. Redis Channel Subscriber Subscriber Subscriber Subscriber Publisher Publisher
instead of memcached. How? We would use the EXPIRE and TTL and configure redis to not persist the data. Take into account Redis for now (is in experimental state) doesn't support clustering. So we need to use our own algorithm of hashing for redirecting the data to the different instances of redis. Redis VS Memcached http://stackoverflow.com/questions/10558465/memcache-vs-redis
We would use bitmaps. A bit in the bitmap is a flag, so for example each bitmap is an user id, bitmap 1 is user 1, 2 is 2 and so on. we could use SETBIT and GETBIT So now apart from having a cheap/small and fast O(1) mechanism of statistics we could also do operations with BITCOUNT & BITOP For example keys like user:logins:YYYY-MM-DD Maximun bit lenght is 232 -1 == 512 MB == 4294967296 bits (more than 4 billion users!!) More information: http://blog.getspool.com/2011/11/29/fast-easy-realtime-metrics-using- redis-bitmaps/
normal databases we could do it. but we have to take into account some things: • Redis operates in memory. All the data needs to be in memory all the time • SQL DBs stores immediately, Redis no, so we have to be prepared if something bad happens (next point ->) • Set master/slave instances for each redis instance (read only and read/write) • Partition your data into instances (until redis cluster is released) based on a custom system. More information: http://moot.it/blog/technology/redis-as-primary-datastore-wtf.html
the pub/sub system. How? Using the commands SUBSCRIBE & PUBLISH and creating different channels for the different queues. for example user:admin:notifications, user:mod:notifications... So Redis would do the hard work of notifying things and our job would be to process of the notifications. More information: https://github.com/slok/redis-node-push-notifications-example
{kind=link}
![HGETALL that:tomatoeyes:guy github.com/slok @slok69 [email protected] http://xlarrakoetxea.org Xabier Larrakoetxea](https://files.speakerdeck.com/presentations/6a635da08ef0013032a312313d240de0/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![import redis fiboLuaScript = """ local i = tonumber(ARGV[1]) local](https://files.speakerdeck.com/presentations/6a635da08ef0013032a312313d240de0/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}