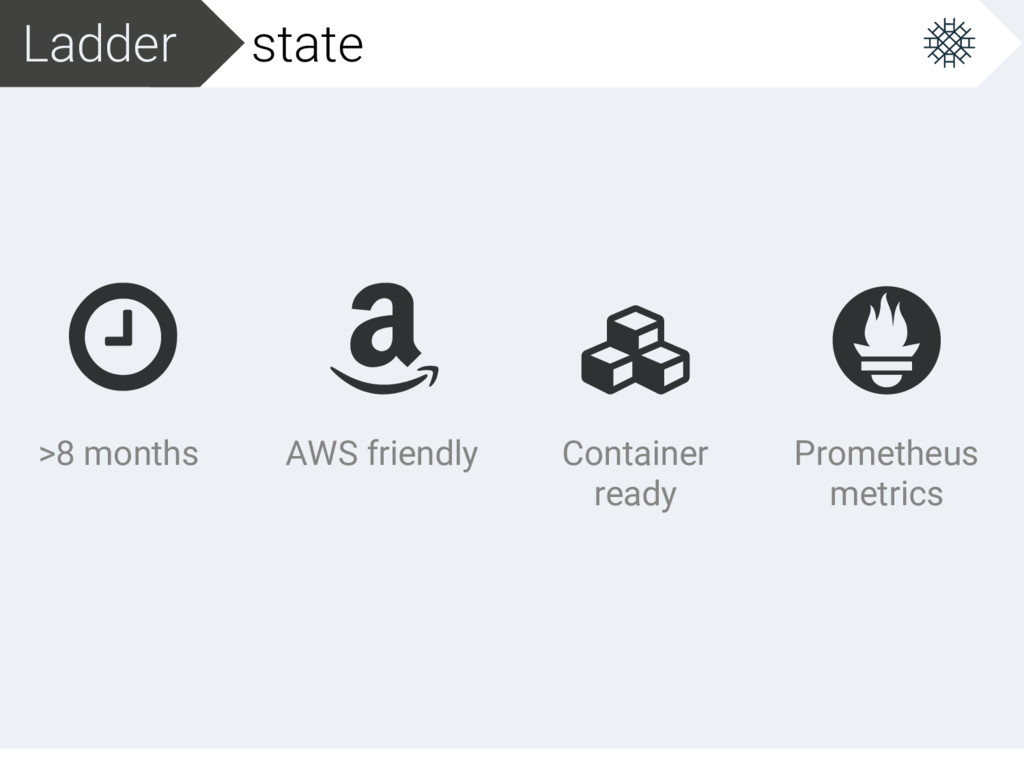
Introduction to autoscaling infrastructure and how an autoscaler is implemented, in this case Ladder, a general purpose autoscaler. https://github.com/themotion/ladder
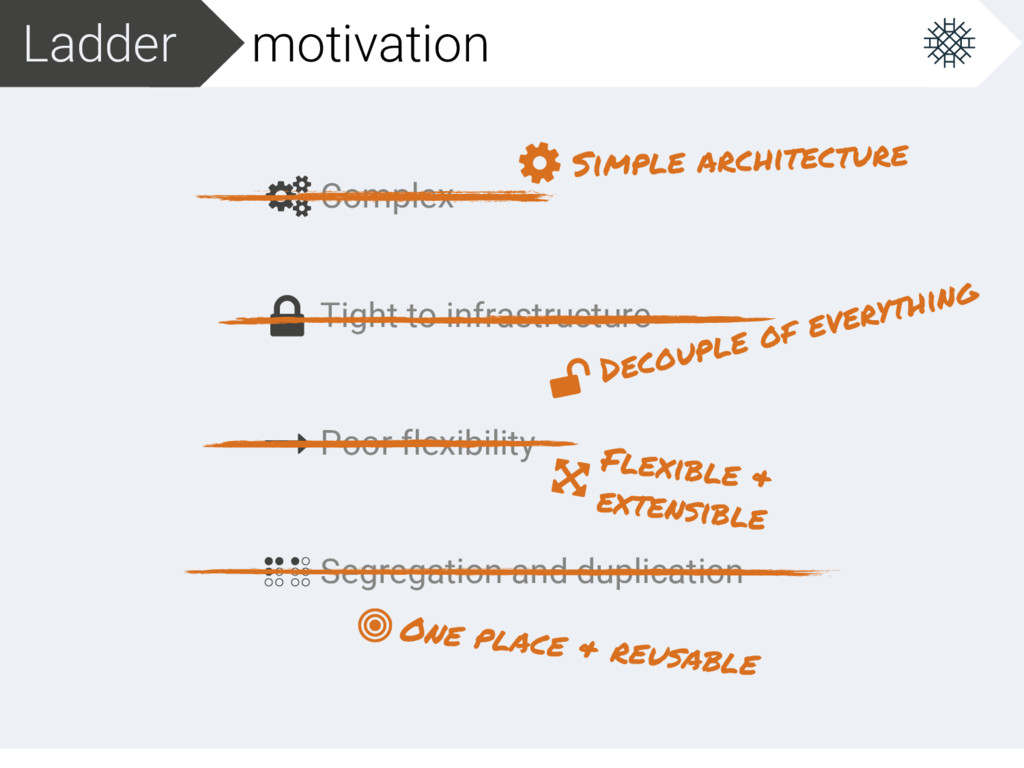
amount of computational resources in a server farm, typically measured in terms of the number of active servers, scales automatically based on the load on the farm.
amount of computational resources in a server farm, typically measured in terms of the number of active servers, scales automatically based on the load on the farm. Meet contract requirements in the cheapest way
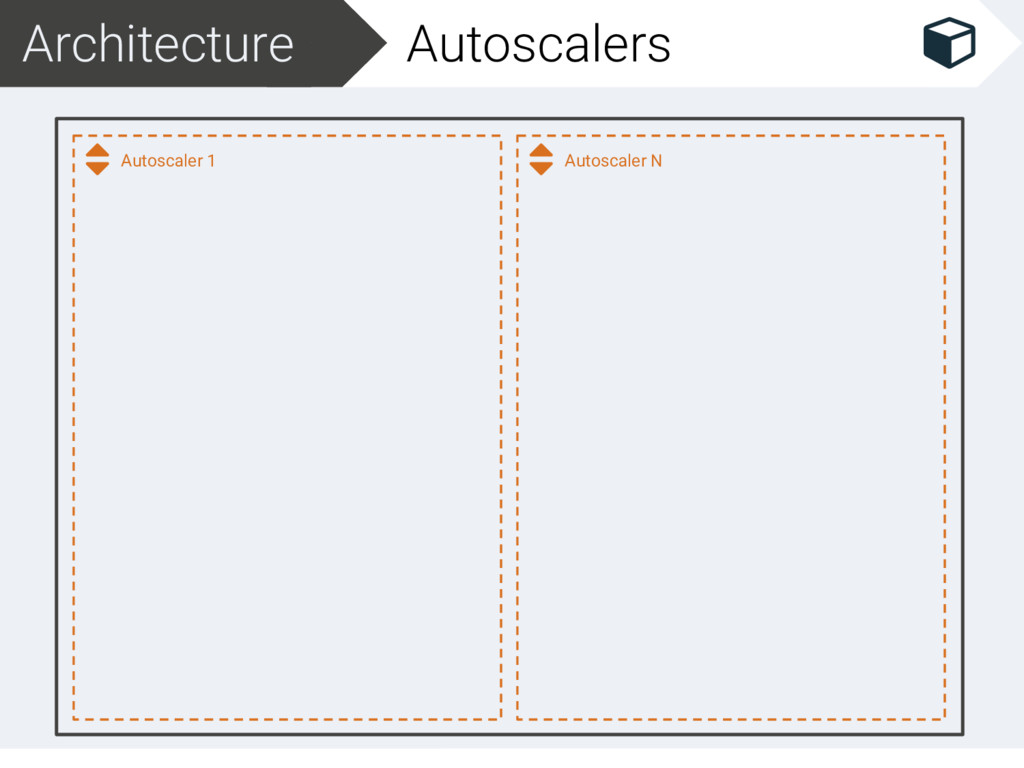
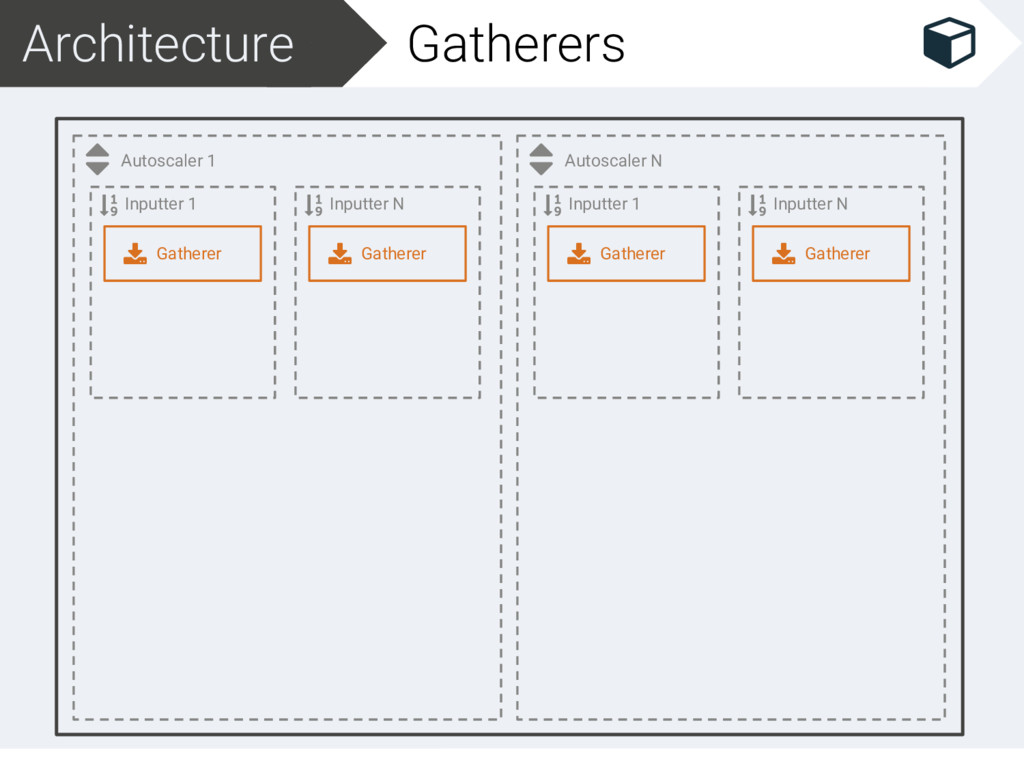
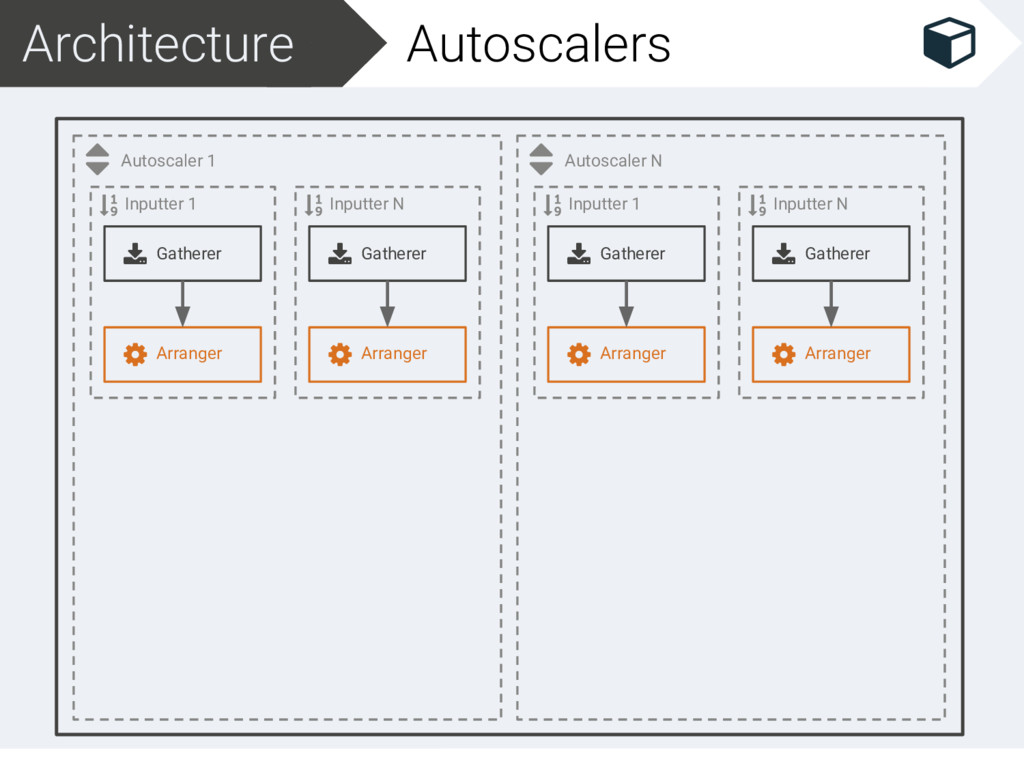
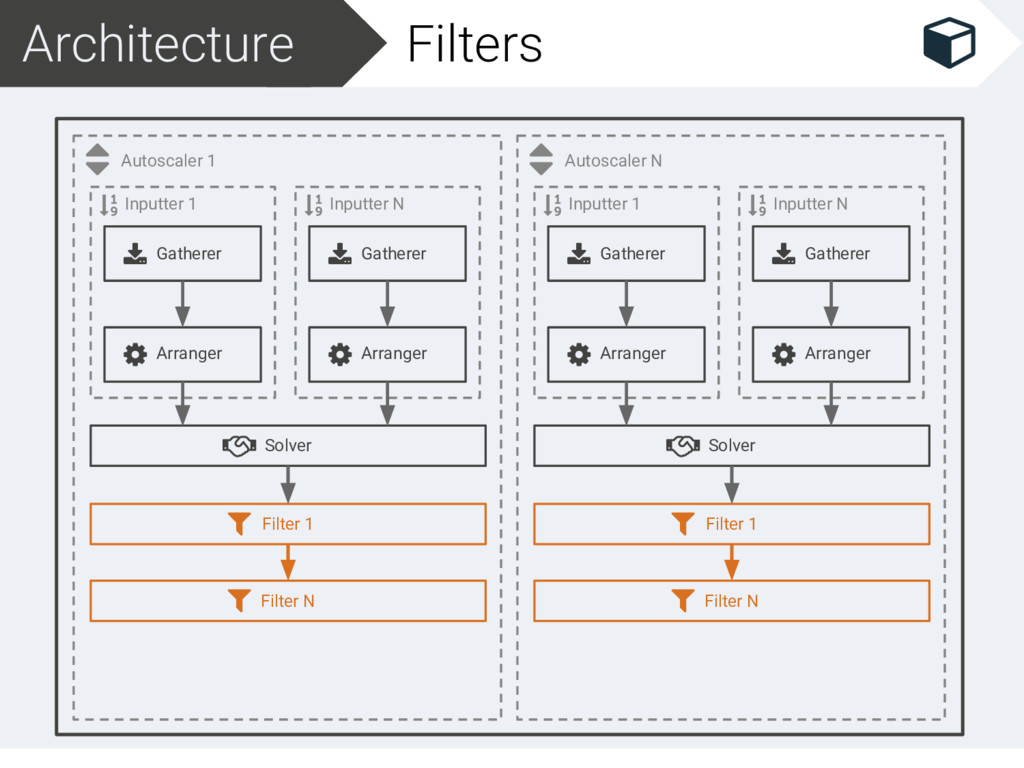
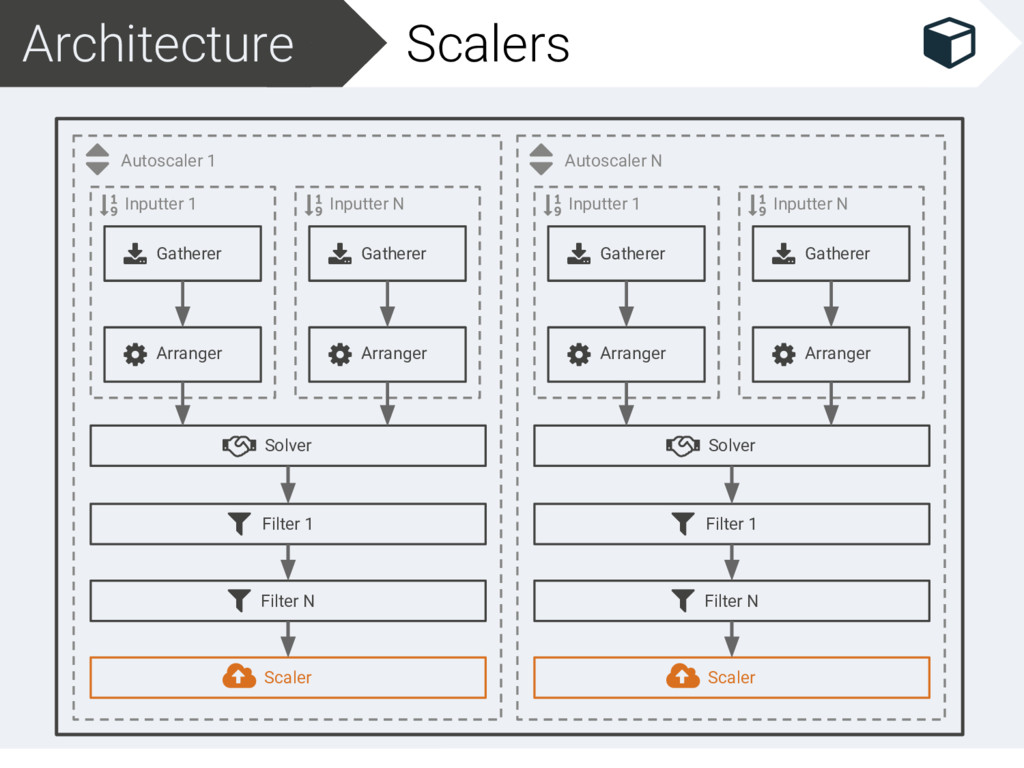
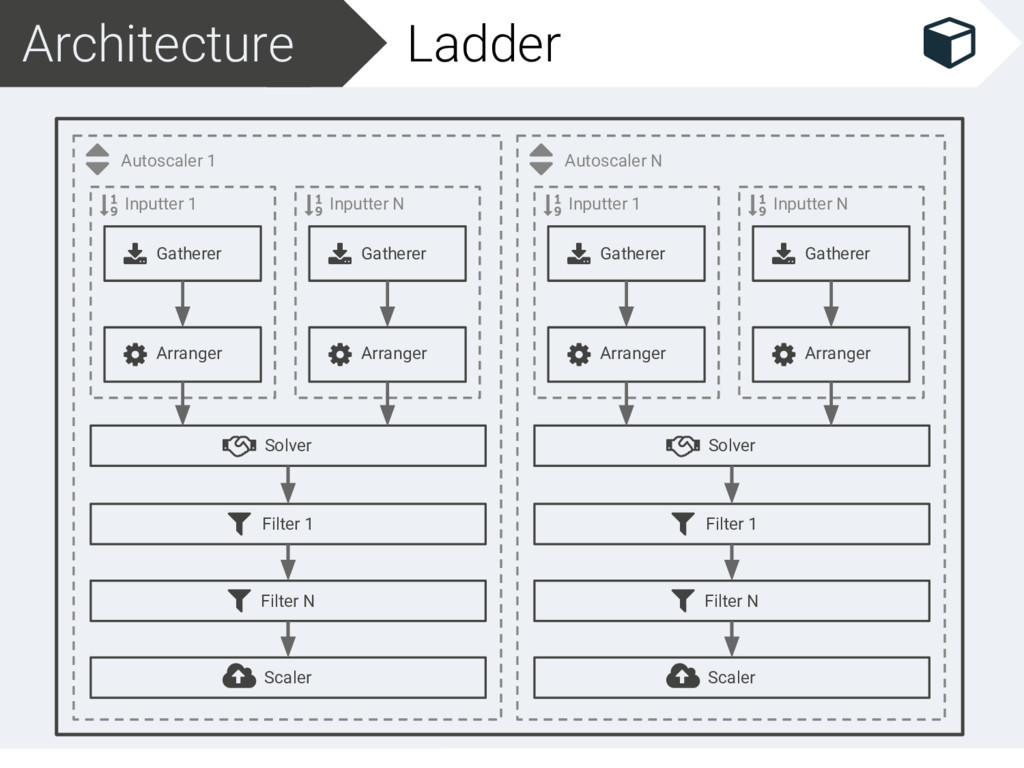
Filter 1 Filter N Scaler Inputter N Gatherer Arranger Autoscaler N Inputter 1 Gatherer Arranger Solver Filter 1 Filter N Scaler Inputter N Gatherer Arranger
Filter 1 Filter N Scaler Inputter N Gatherer Arranger Autoscaler N Inputter 1 Gatherer Arranger Solver Filter 1 Filter N Scaler Inputter N Gatherer Arranger
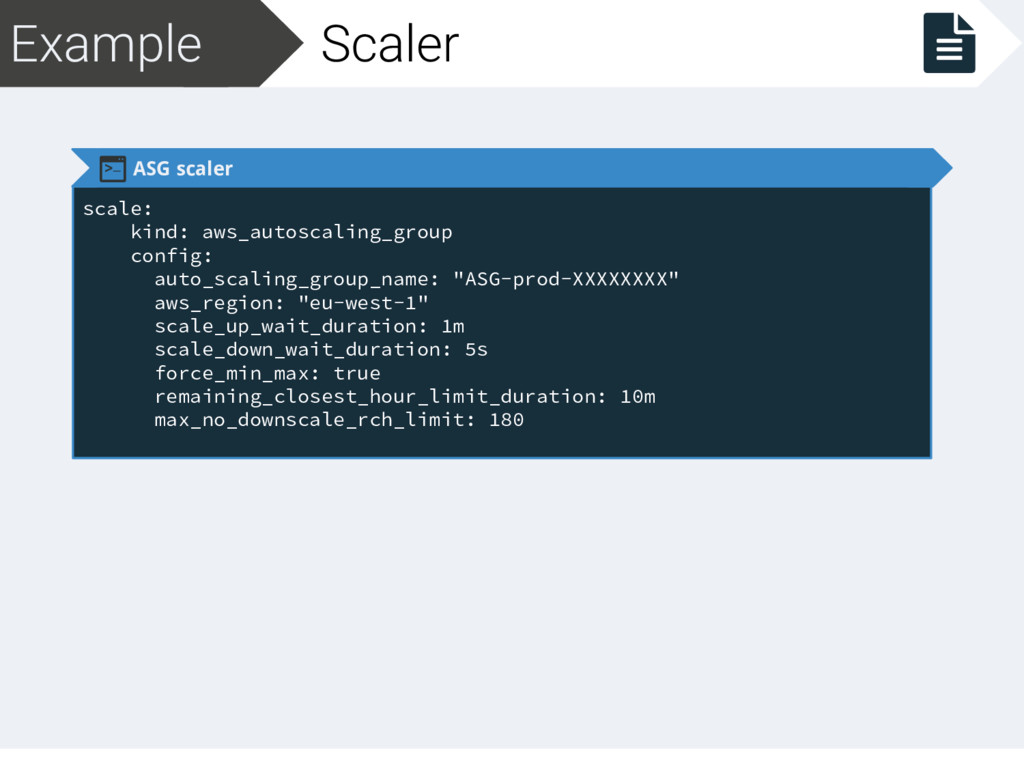
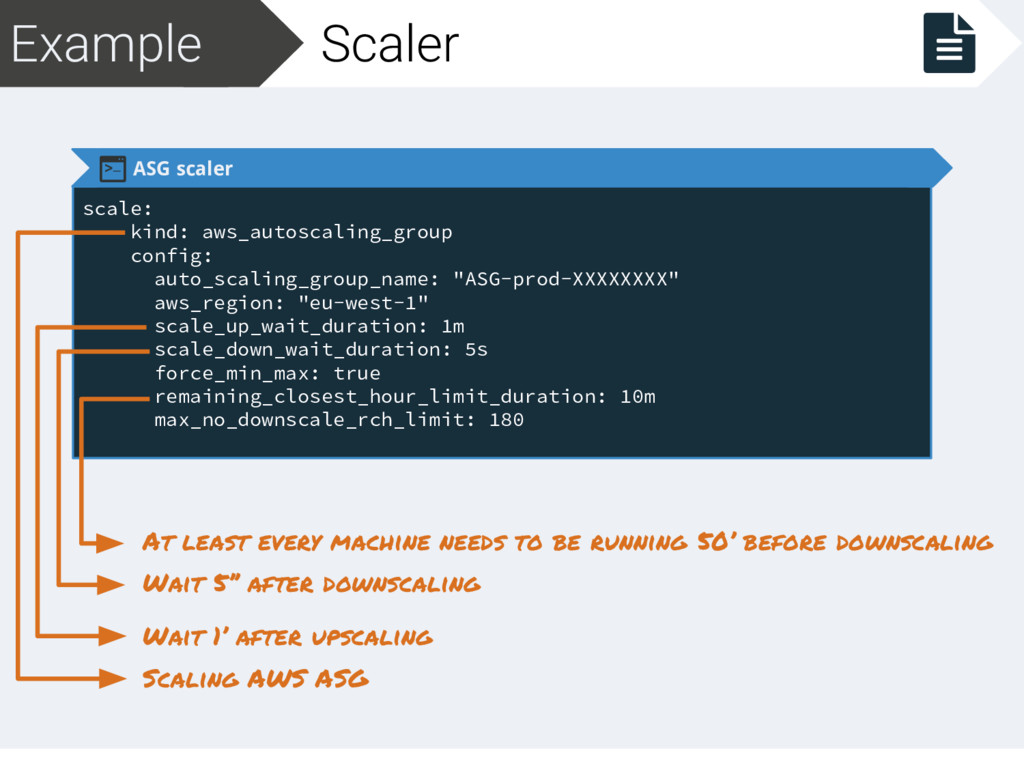
aws_region: "eu-west-1" scale_up_wait_duration: 1m scale_down_wait_duration: 5s force_min_max: true remaining_closest_hour_limit_duration: 10m max_no_downscale_rch_limit: 180 Scaling AWS ASG Wait 1’ after upscaling Wait 5’’ after downscaling At least every machine needs to be running 50’ before downscaling
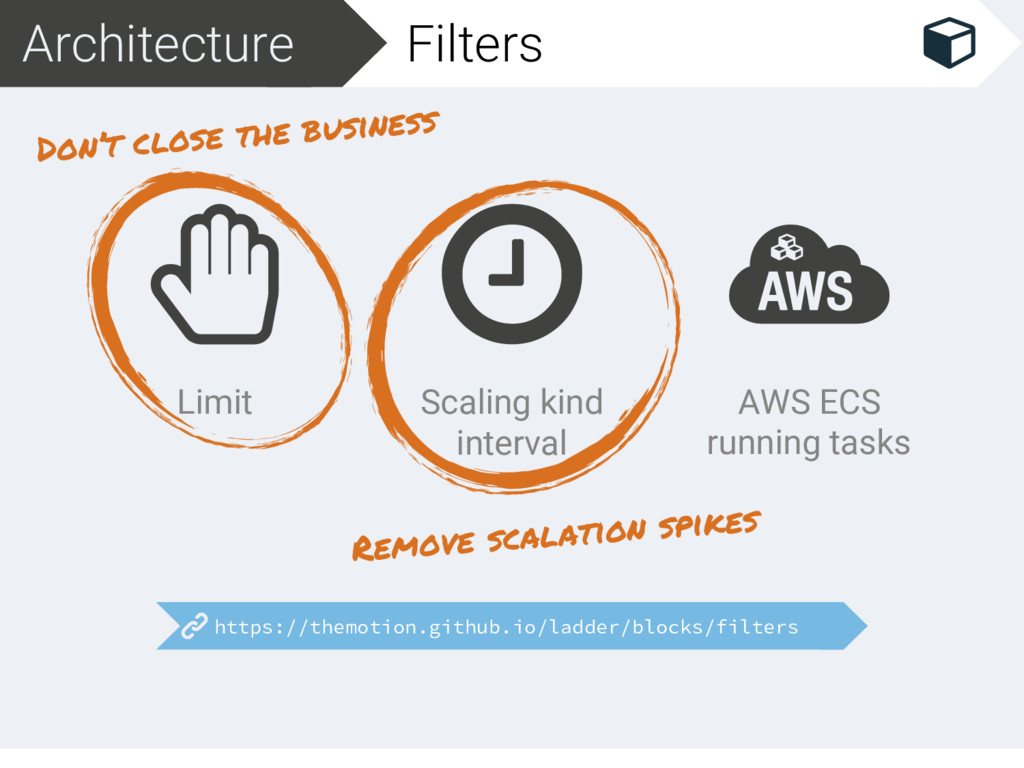
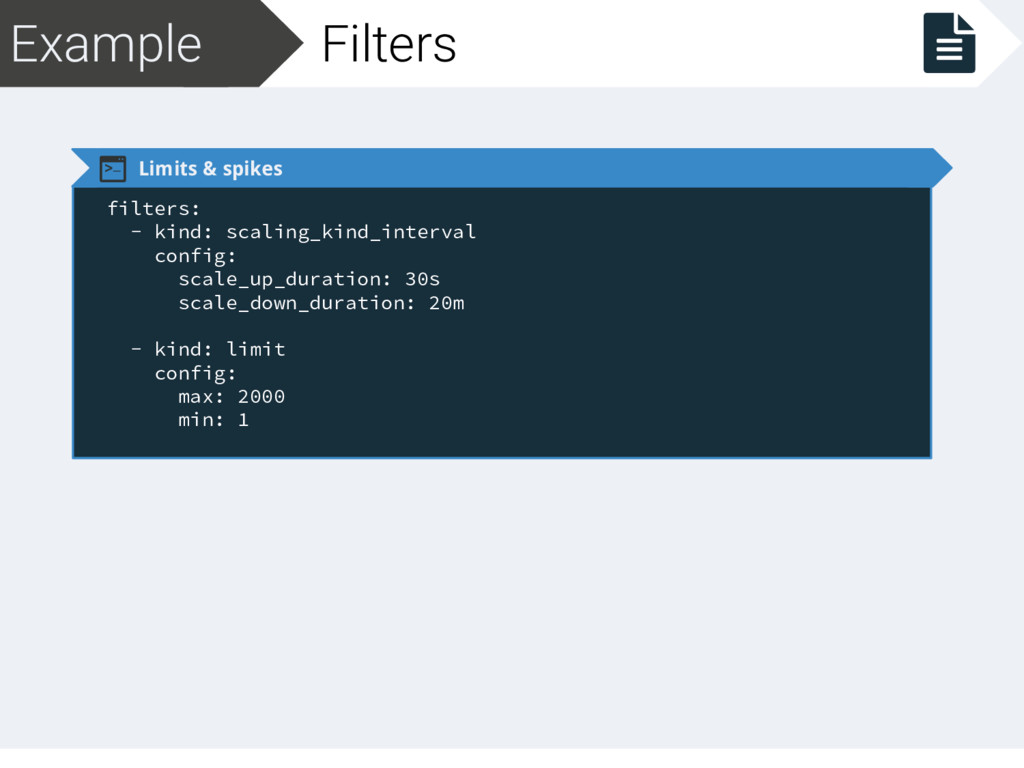
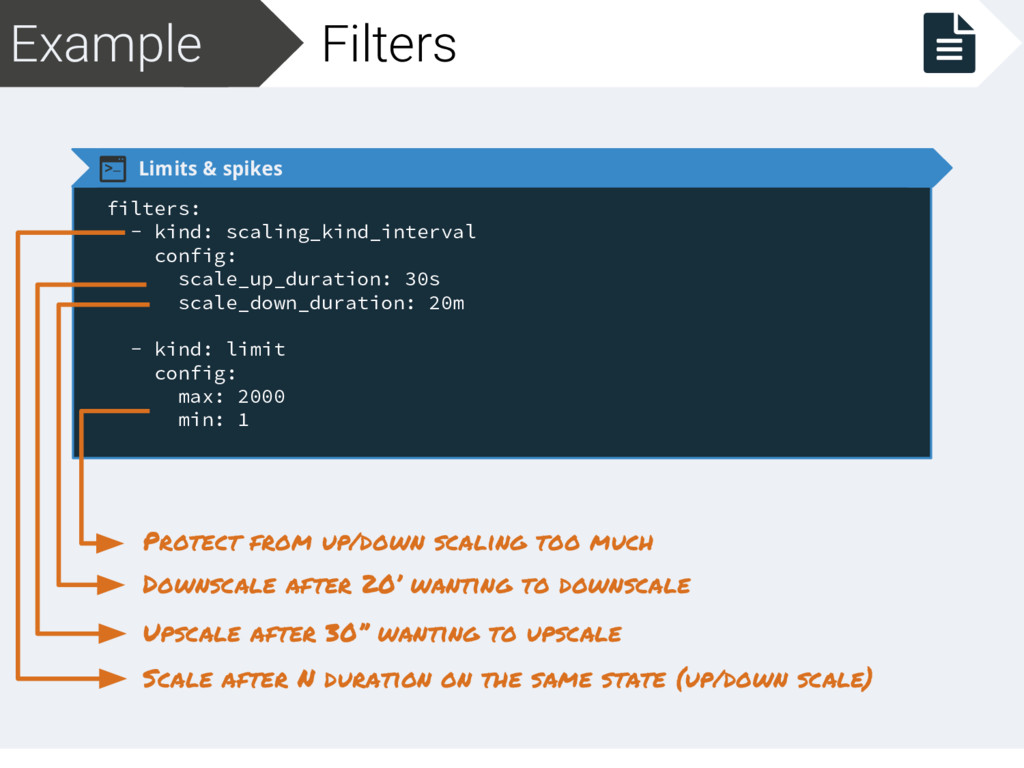
scale_up_duration: 30s scale_down_duration: 20m - kind: limit config: max: 2000 min: 1 Scale after N duration on the same state (up/down scale) Upscale after 30’’ wanting to upscale Downscale after 20’ wanting to downscale Protect from up/down scaling too much
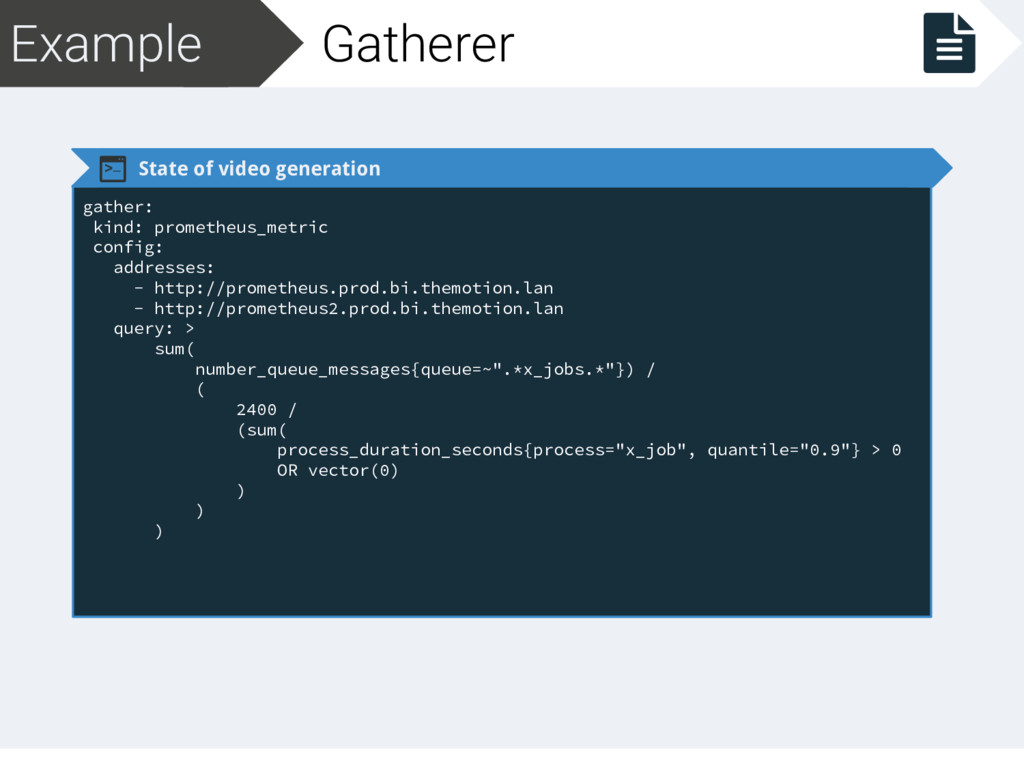
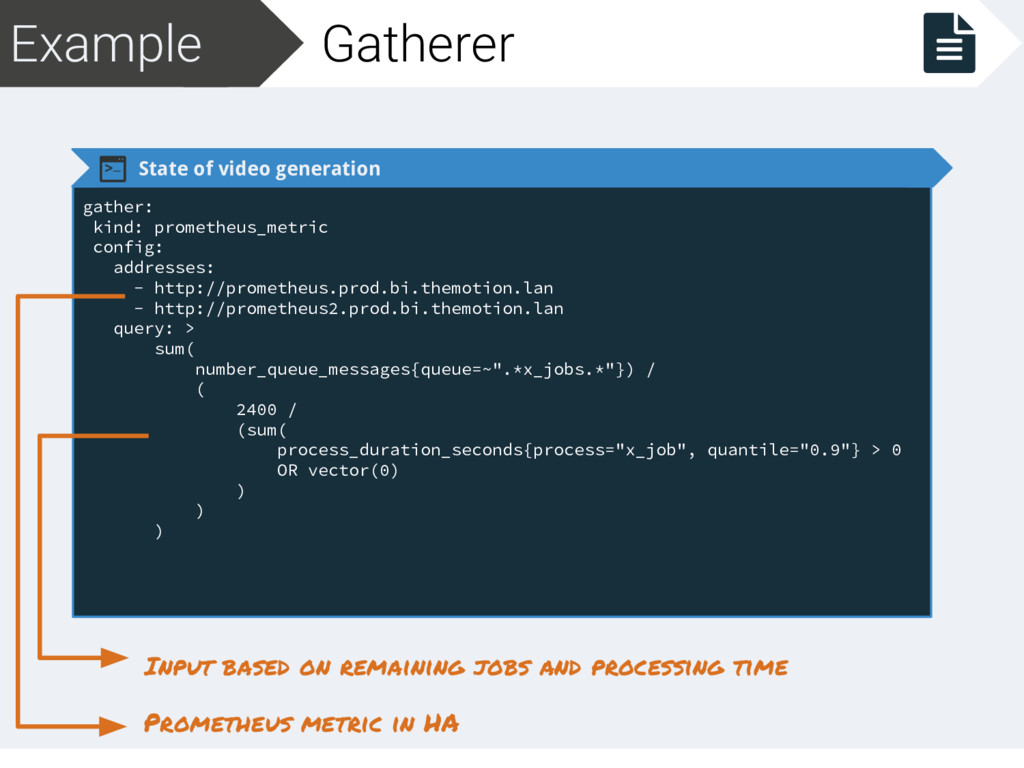
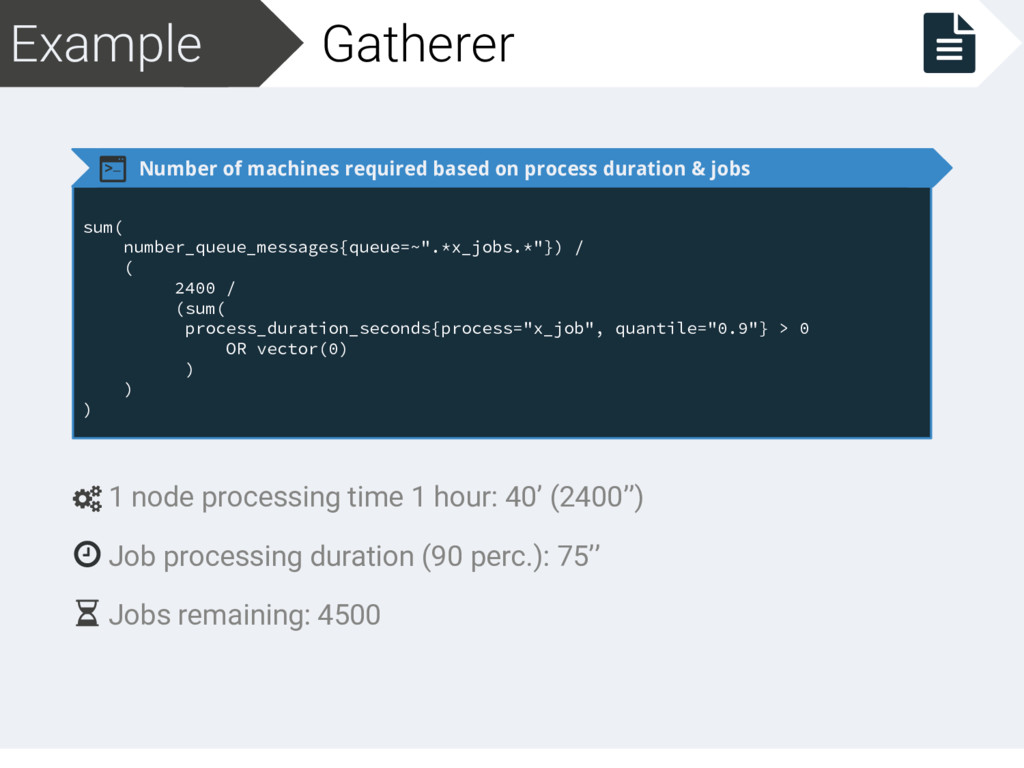
addresses: - http://prometheus.prod.bi.themotion.lan - http://prometheus2.prod.bi.themotion.lan query: > sum( number_queue_messages{queue=~".*x_jobs.*"}) / ( 2400 / (sum( process_duration_seconds{process="x_job", quantile="0.9"} > 0 OR vector(0) ) ) ) Prometheus metric in HA Input based on remaining jobs and processing time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
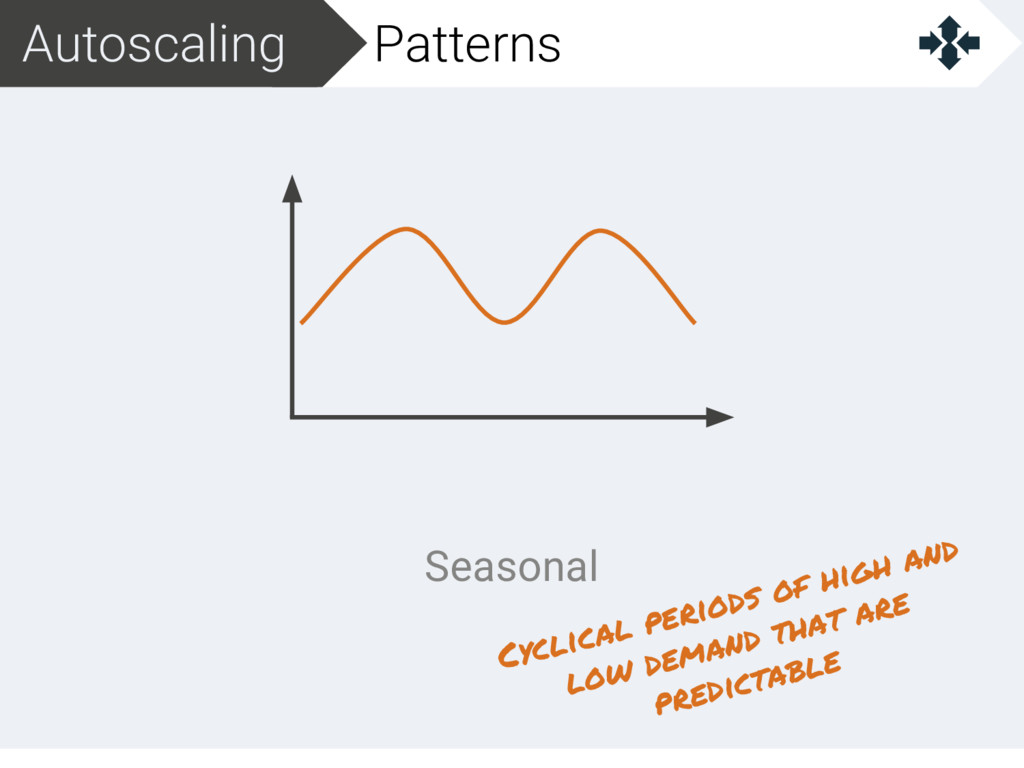{kind=link}
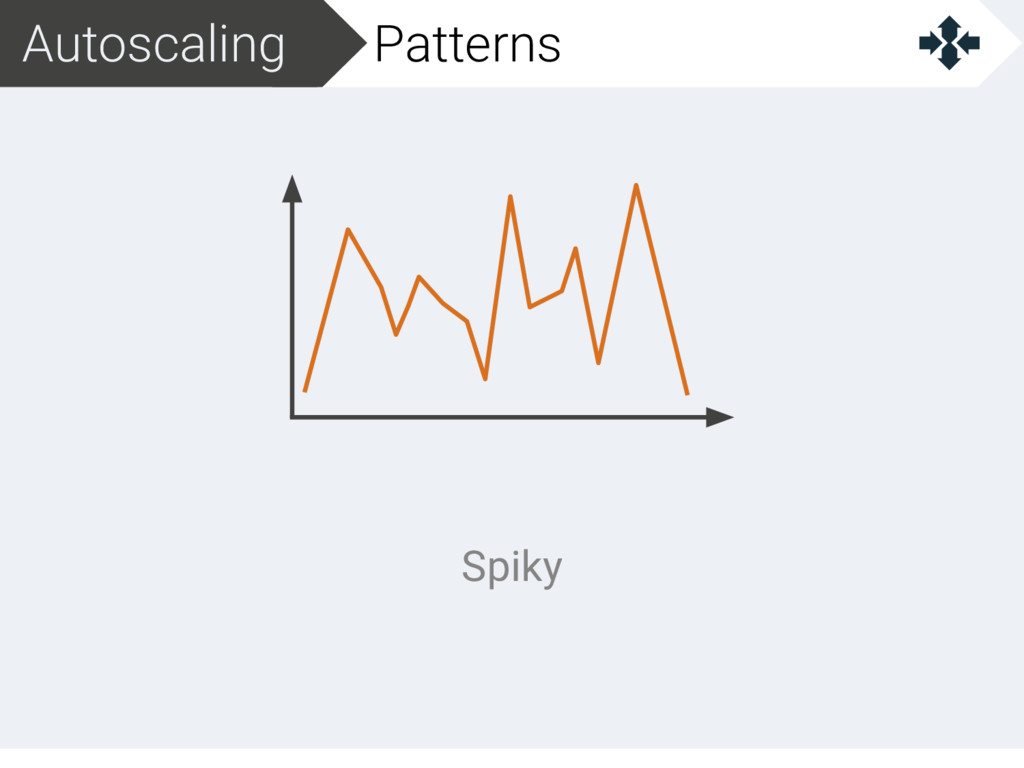{kind=link}
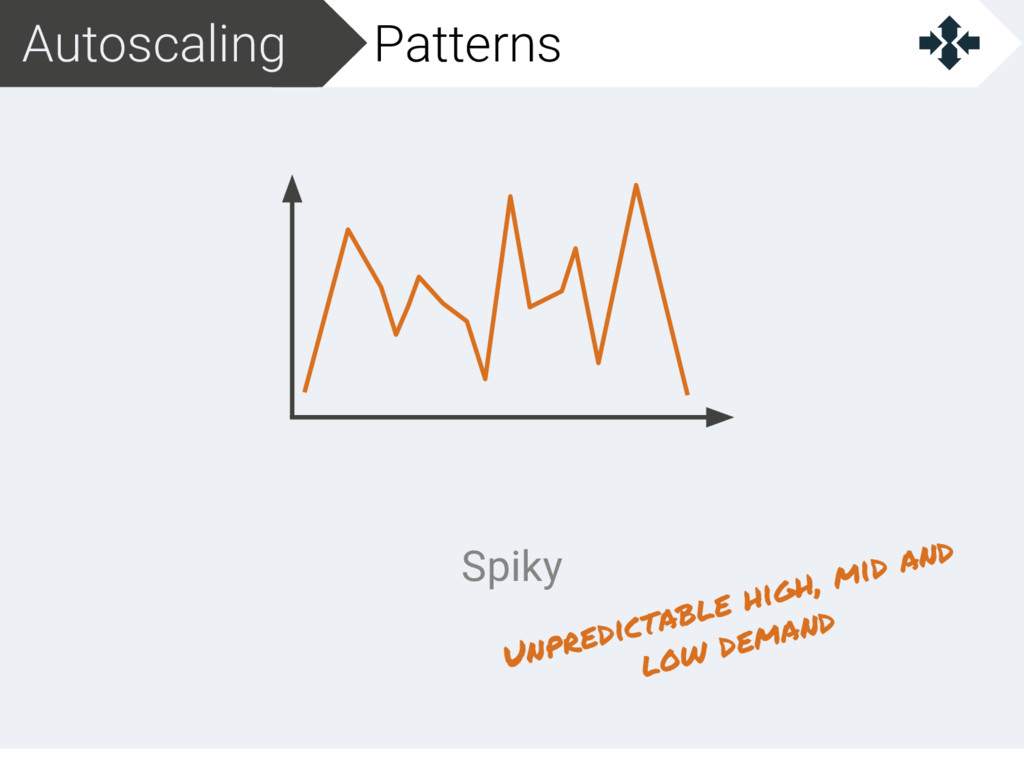{kind=link}
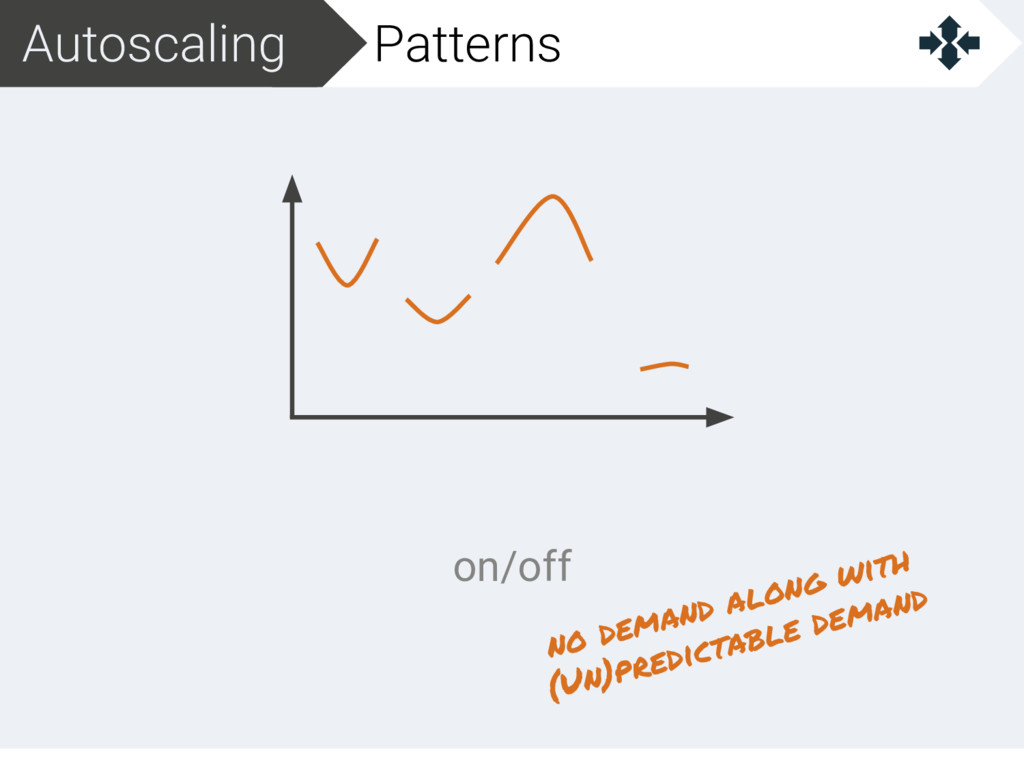{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
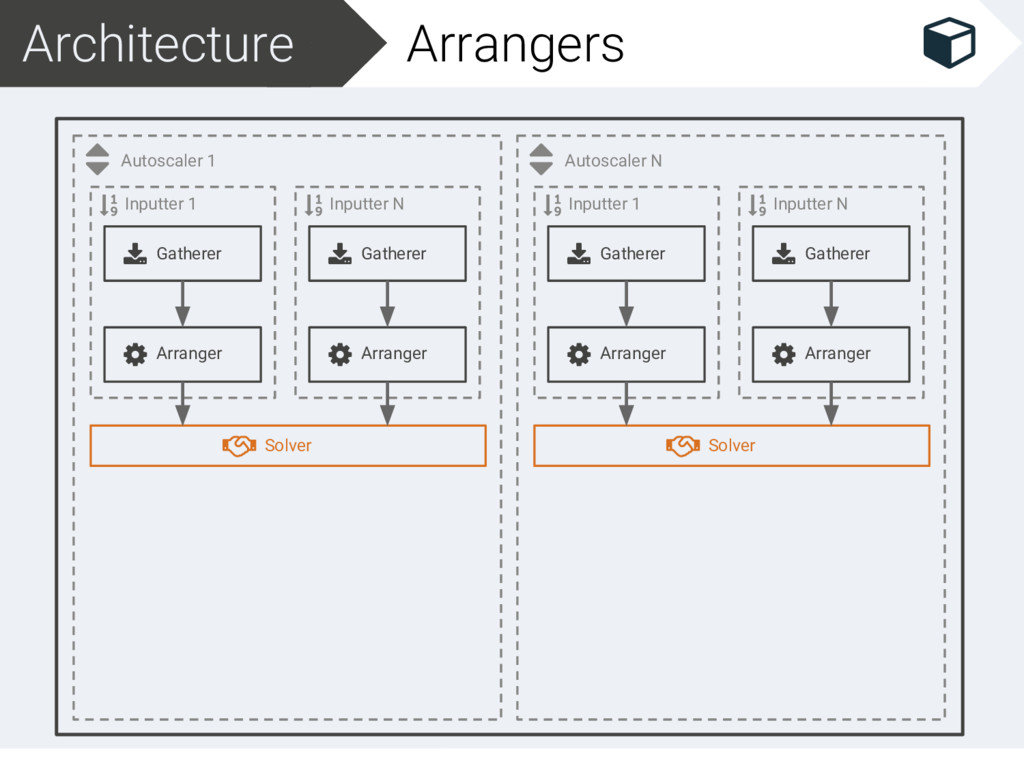{kind=link}
{kind=link}
{kind=link}
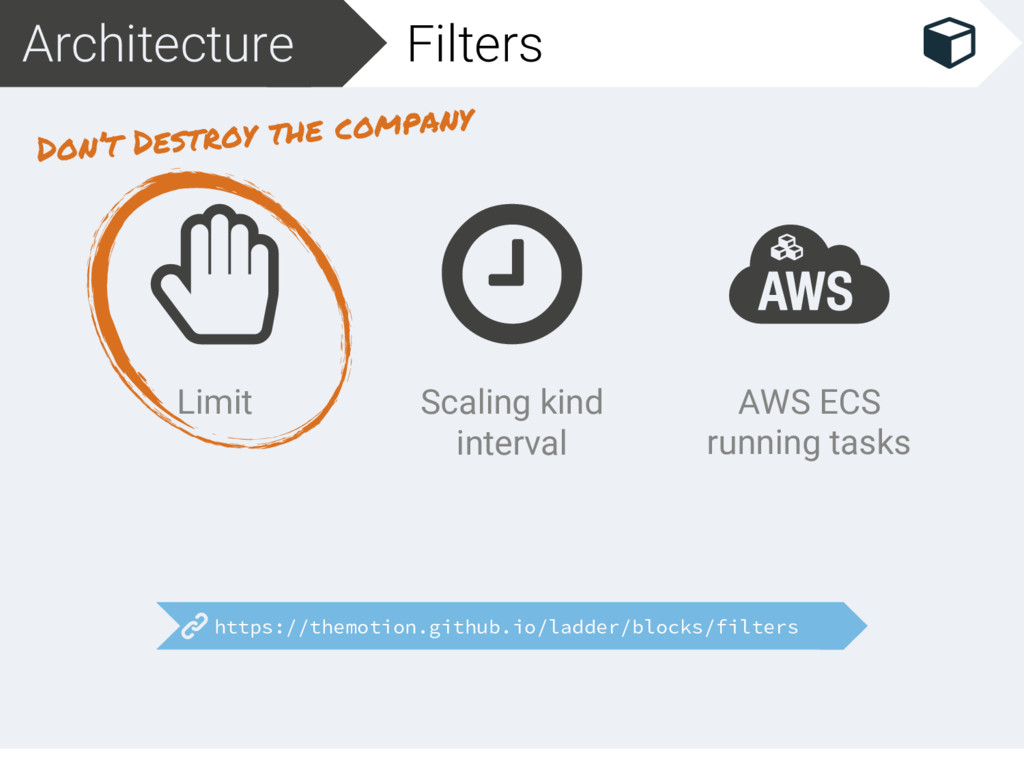{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}