location from index • Seek to location, retrieve full row Row–orientated Columnar • Columns stored separately on disk • Read full column • Compression (run–length) is easier with columns of a single type
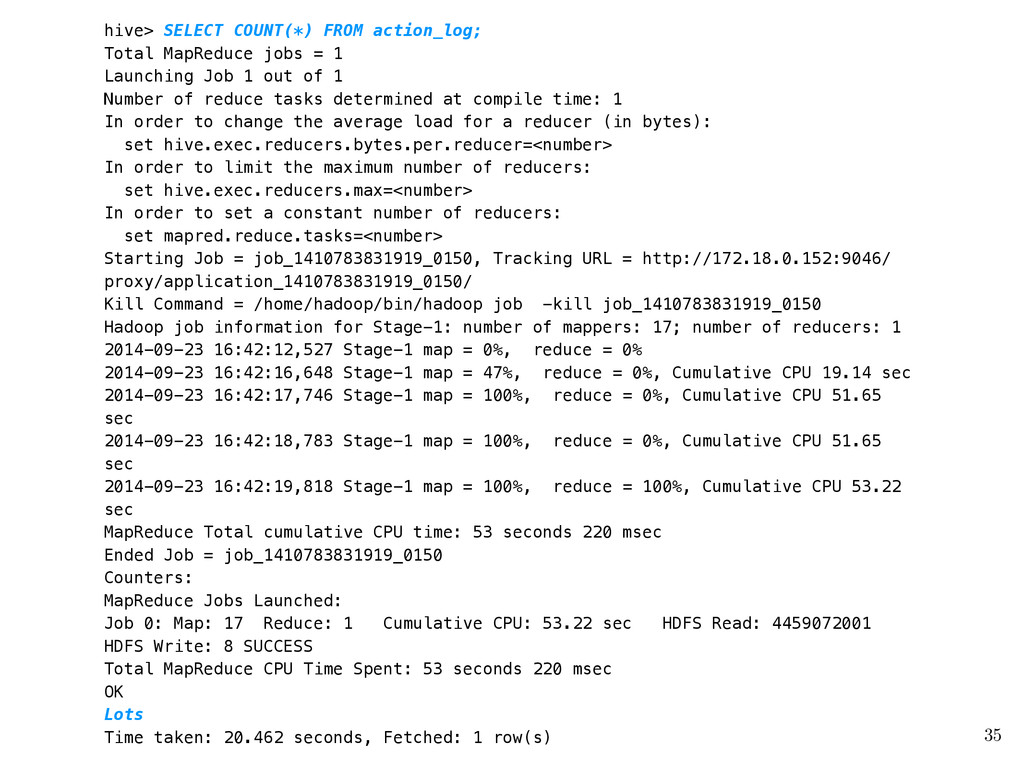
Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapred.reduce.tasks=<number> Starting Job = job_1410783831919_0150, Tracking URL = http://172.18.0.152:9046/ proxy/application_1410783831919_0150/ Kill Command = /home/hadoop/bin/hadoop job -kill job_1410783831919_0150 Hadoop job information for Stage-1: number of mappers: 17; number of reducers: 1 2014-09-23 16:42:12,527 Stage-1 map = 0%, reduce = 0% 2014-09-23 16:42:16,648 Stage-1 map = 47%, reduce = 0%, Cumulative CPU 19.14 sec 2014-09-23 16:42:17,746 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 51.65 sec 2014-09-23 16:42:18,783 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 51.65 sec 2014-09-23 16:42:19,818 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 53.22 sec MapReduce Total cumulative CPU time: 53 seconds 220 msec Ended Job = job_1410783831919_0150 Counters: MapReduce Jobs Launched: Job 0: Map: 17 Reduce: 1 Cumulative CPU: 53.22 sec HDFS Read: 4459072001 HDFS Write: 8 SUCCESS Total MapReduce CPU Time Spent: 53 seconds 220 msec OK Lots Time taken: 20.462 seconds, Fetched: 1 row(s) 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 id email email_confirmed 1 [email protected] TRUE 2 [email protected] TRUE](https://files.speakerdeck.com/presentations/012548102c4c0132389e4274f6195918/slide_22.jpg){kind=link}
![Row–orientated 1,[email protected],TRUE\n↩ 2,[email protected],TRUE\n↩ 3,[email protected],TRUE\n↩ 4,[email protected],TRUE\n↩ 5,[email protected],FALSE\n↩ 6,[email protected],FALSE 24 Columnar 1,2,3,4,5,6](https://files.speakerdeck.com/presentations/012548102c4c0132389e4274f6195918/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
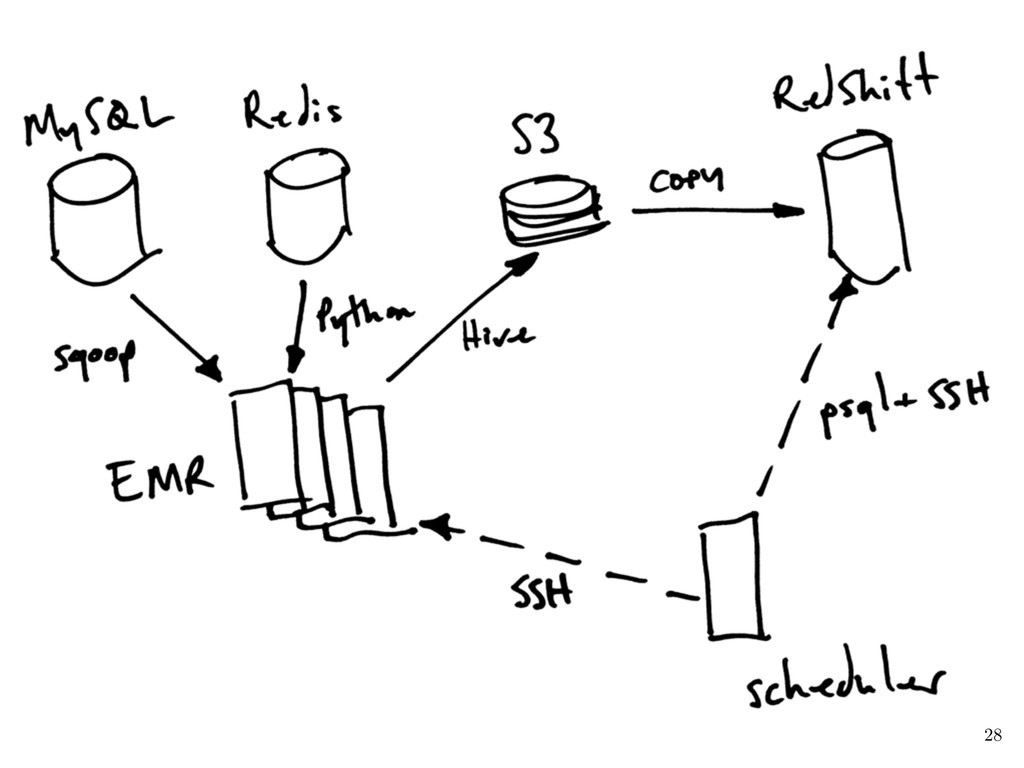{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}