• Distributed • Column-oriented • Fault tolerant • Linear scaling by adding more servers • Runs on commodity (not crappy) hardware • Not an RDBMS o No joins o No secondary indexes o No SQL
family:column, timestamp) = cell • Rows keys are sorted in lexicographical order o i.e. 1, 12, 15, 2, 23, 3, 4 • Row key and Cell contents are byte[] o No data types • Timestamp specifies different versions • Tunings and storage specifications are done per column family o Compression, version retention, bloom filters etc.
millions of smallish rows • Variable schema • High write volume • Key based access • Sequential reads • Can you live without some RDBMS features o typed columns, secondary indexes, cross record transactions, joins, SQL • Make sure you have enough hardware
o http://www.cloudera.com/blog/2011/02/avoiding-full-gcs-in-hbase-with- memstore-local-allocation-buffers-part-1/ o http://www.cloudera.com/blog/2011/04/hbase-dos-and-donts/ o http://www.cloudera.com/resource/hadoop-world-2011-presentation-video- advanced-hbase-schema-design/ • Mailing lists o http://hbase.apache.org/mail-lists.html • Lars George o http://www.larsgeorge.com/ • HBase road map o http://www.slideshare.net/cloudera/apache-hbase-road-map-jonathan-gray- facebook
![Simon Kelly [email protected]](https://files.speakerdeck.com/presentations/4fe171266590c50407013c13/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
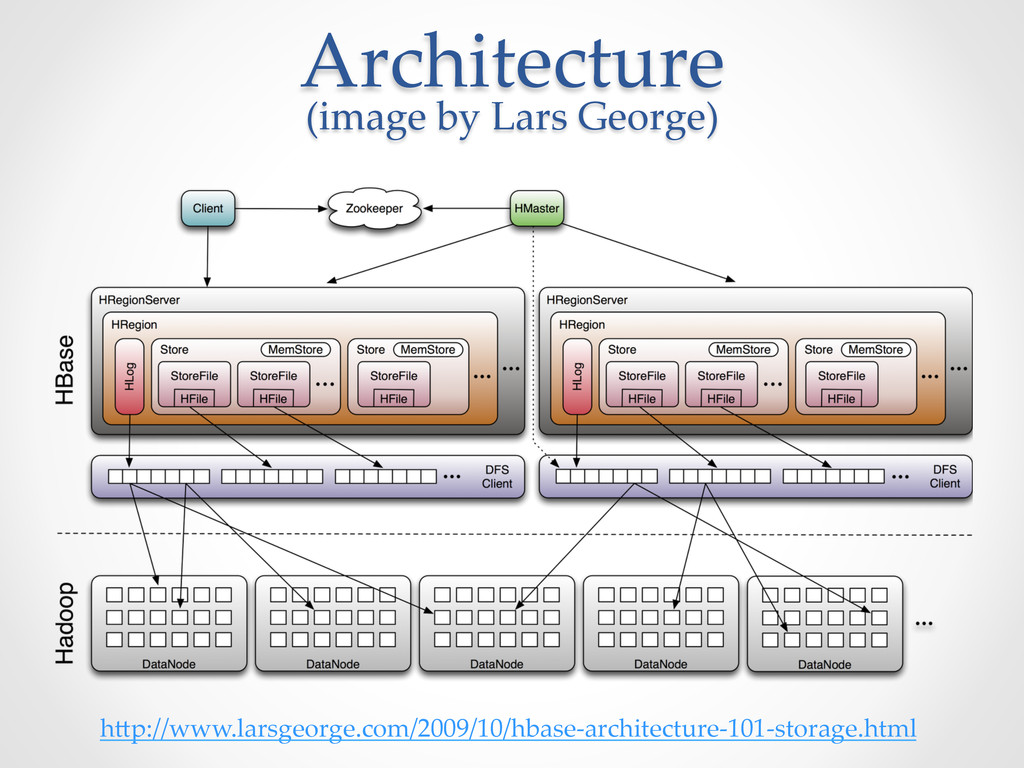{kind=link}
{kind=link}
{kind=link}
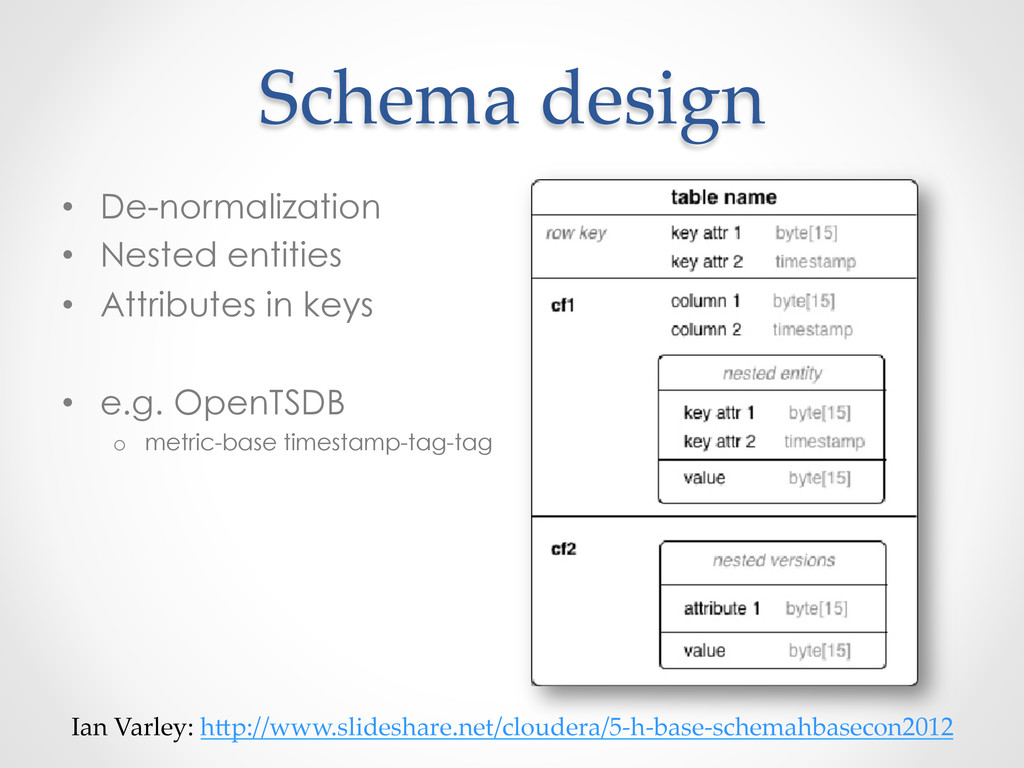{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}