Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DGX Sparkを2台つないで 最強ローカルLLM環境を動かしてみた話
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
そのだ
June 19, 2026
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DGX Sparkを2台つないで 最強ローカルLLM環境を動かしてみた話
コーディングのためのローカルLLM勉強会 in 福岡
https://connpass.com/event/395614/
そのだ
June 19, 2026
More Decks by そのだ
See All by そのだ
AGENTS.mdとSkillsで始めるAIエージェント活用
sonoda_mj
3
240
Google_ADKのSub_AgentをAgentic_Workflowに移行し_遷移成功率を改善した話.pdf
sonoda_mj
1
140
仕事はAIに任せてラスベガスへ行きたいのでDSPyで自分のクローンを作った
sonoda_mj
1
170
ハッカソンから社内プロダクトへ AIエージェント「ko☆shi」開発で学んだ4つの重要要素
sonoda_mj
6
2.8k
RAGの基礎から実践運用まで:AWS BedrockとLangfuseで実現する構築・監視・評価
sonoda_mj
1
2.1k
Amazon Bedrock Knowledge Basesに Data Autometionを導入してみた
sonoda_mj
1
250
Amazon Bedrock Knowledge basesにLangfuse導入してみた
sonoda_mj
2
1.2k
AIエージェントに脈アリかどうかを分析させてみた
sonoda_mj
2
440
Amazon Bedrock Knowledge Basesのアップデート紹介
sonoda_mj
2
890
Featured
See All Featured
Why Our Code Smells
bkeepers
PRO
340
58k
The Invisible Side of Design
smashingmag
301
52k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
4 Signs Your Business is Dying
shpigford
187
22k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
480
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
200
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Transcript
1 © 2025 Leverages Co., Ltd. DGX Sparkを2台つないで 最強ローカルLLM環境を動かし てみた話
2 © 2025 Leverages Co., Ltd. 自己紹介
3 © 2025 Leverages Co., Ltd. 苑田 朝彰 普段の業務内容 •
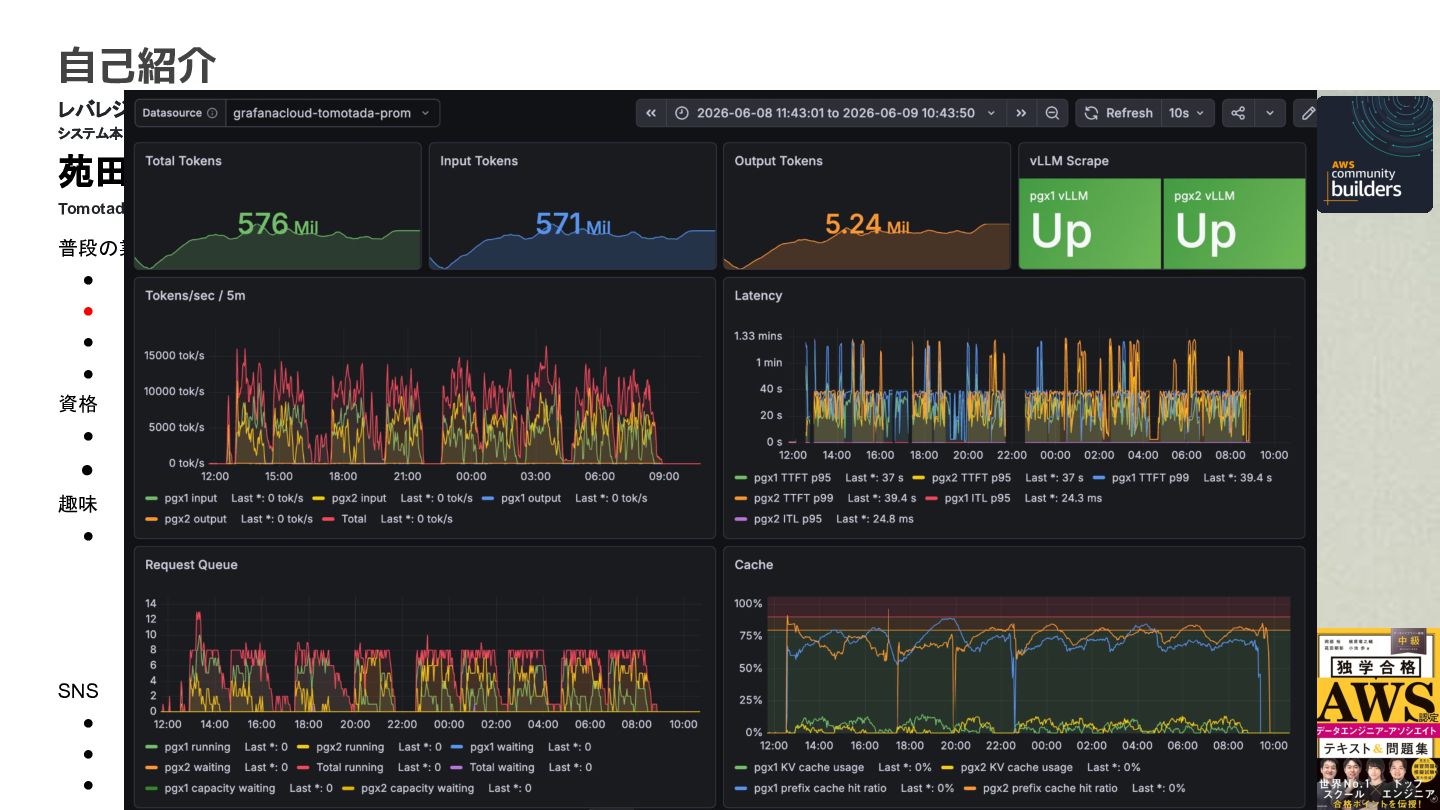
AI エージェント開発(Google ADK, Strands Agent) • ローカルLLM歴4ヶ月(KDD Cup参加中) • 社内AI推進(AI駆動開発、Agent開発) • クラウド(AWS, Google Cloud) 資格 • AWS Community Builders(ML) • 甲賀流忍者検定(中級) 趣味 • 月一で面白いことをするのにハマってます ◦ Spartanレース ◦ 100kmウォーキング ◦ 無人島かくれんぼ ◦ 滝行 SNS • https://x.com/sonoda_mj • https://zenn.dev/tomomj • https://note.com/sonoda_mj Tomotada Sonoda レバレジーズ株式会社 システム本部/テクノロジー戦略室/AIエージェント開発チーム 自己紹介
4 © 2025 Leverages Co., Ltd. 苑田 朝彰 普段の業務内容 •
AI エージェント開発(Google ADK, Strands Agent) • ローカルLLM歴4ヶ月(KDD Cup参加中) • 社内AI推進(AI駆動開発、Agent開発) • クラウド(AWS, Google Cloud) 資格 • AWS Community Builders(ML) • 甲賀流忍者検定(中級) 趣味 • 月一で面白いことをするのにハマってます ◦ Spartanレース ◦ 100kmウォーキング ◦ 無人島かくれんぼ ◦ 滝行 SNS • https://x.com/sonoda_mj • https://zenn.dev/tomomj • https://note.com/sonoda_mj Tomotada Sonoda レバレジーズ株式会社 システム本部/テクノロジー戦略室/AIエージェント開発チーム 自己紹介
5 © 2025 Leverages Co., Ltd. Contents 背景 DGX Sparkとは
DeepSeek-V4-Flashとは 実際に動かしてみた まとめ 01. 02. 03. 04. 05.
6 © 2025 Leverages Co., Ltd. 背景
7 © 2025 Leverages Co., Ltd. 背景 ローカルLLMは、小さいモデルであれば比較的簡単に動かすことが可能です。 一方で、コーディング用途で本格的に使おうとすると、より大きく高性能なモデルを使いたくなります。 今回は「巨大モデルをローカルで動かせるか」だけでなく、「Coding
Agentとして実用できるか」を検 証します。 モデル規模 ローカル実行の感覚 Coding Agent用途 7B〜14B 比較的動かしやすい。 軽い補助・小さめの修正なら使いやすい 30B前後 量子化やGPUメモリを意識する必要がある。 実用感が出てくるライン 70B級 大容量VRAM / 統合メモリがあれば現実的。量子化 ・context長・並列数が重要。 本格的なCoding Agent用途で試したくなる 100B+ / MoE 大容量メモリや分散構成が重要。総パラメータ数と active parameterを分けて見る必要がある。 今回の検証対象 Grok調べ
8 © 2025 Leverages Co., Ltd. DGX Sparkとは
9 © 2025 Leverages Co., Ltd. DGX Sparkとは DGX Sparkは、机の上に置けるNVIDIAのAI開発マシンです。
1台あたり128GBの統合メモリを持ち、ローカル環境で大きめのLLMを動かしやすい構成になっていま す。今回はLenovo製のThinkStation PGXを使用します。 引用: - https://www.nvidia.com/en-us/products/workstations/dgx-spark/ - https://www.lenovo.com/jp/ja/p/workstations/thinkstationpseries/lenovo-thinkstation-pgx-sff/len102s0023 項目 スペック 製品 Lenovo ThinkStation PGX チップ NVIDIA GB10 Grace Blackwell Superchip 統合メモリ 128GB LPDDR5x / 256-bit / 273GB/s ストレージ 1TB / 4TB NVMe M.2 SSD AI性能 最大 1 PFLOP / 1000 TOPS(FP4) ネットワーク RJ-45 10GbE / 2x QSFP(ConnectX-7 各200Gbps) サイズ 約150 × 150 × 50.5mm / 約1.2kg 値段 75万〜93万円( Lenovo PGX / 2026年6月時点)
10 © 2025 Leverages Co., Ltd. 僕のThinkStation PGX PGXは排熱性能があまり良くない気がするので、サーキュレーターで風を送りまくっています。 あと、重ねるとかっこいい。
11 © 2025 Leverages Co., Ltd. DeepSeek-V4-Flashとは
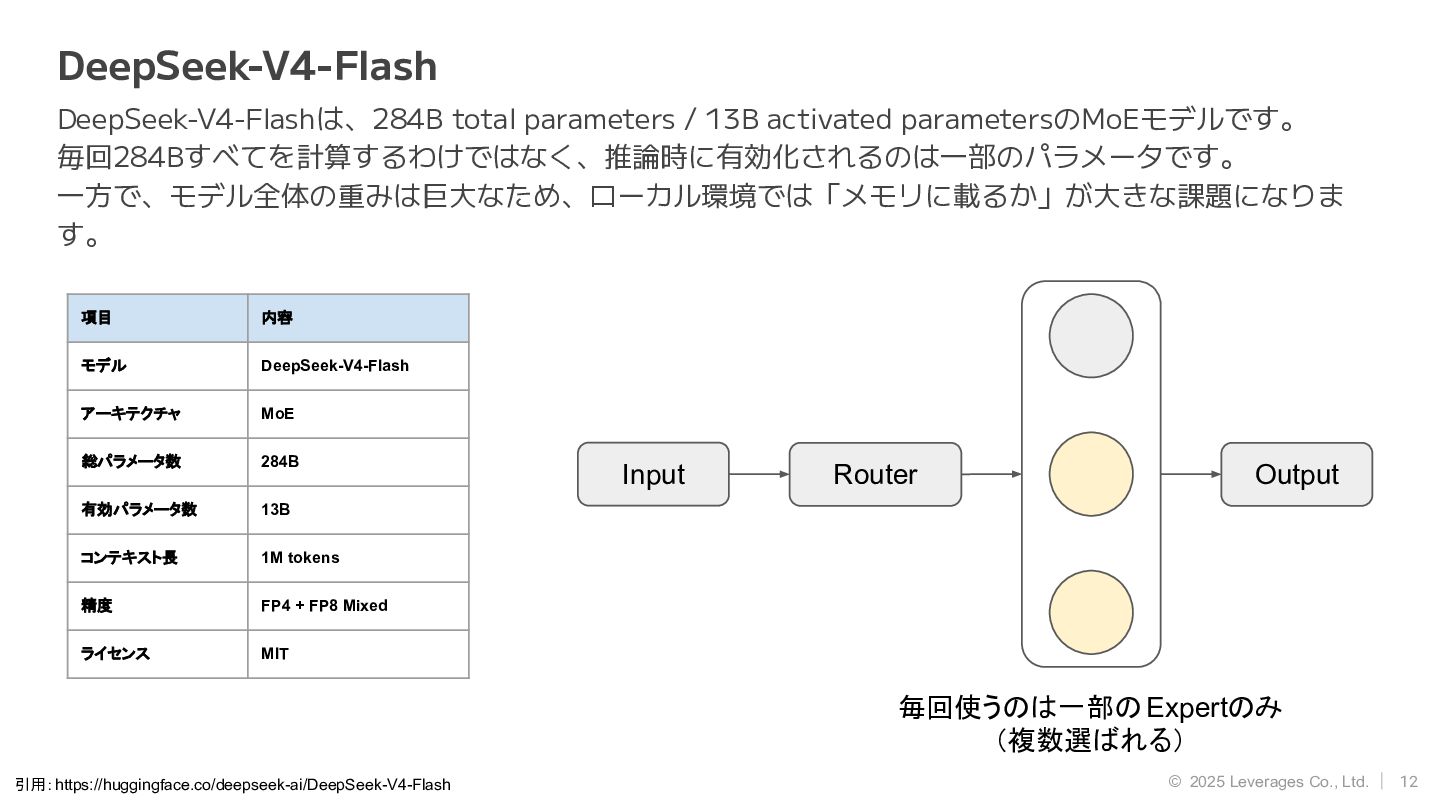
12 © 2025 Leverages Co., Ltd. DeepSeek-V4-Flash DeepSeek-V4-Flashは、284B total parameters
/ 13B activated parametersのMoEモデルです。 毎回284Bすべてを計算するわけではなく、推論時に有効化されるのは一部のパラメータです。 一方で、モデル全体の重みは巨大なため、ローカル環境では「メモリに載るか」が大きな課題になりま す。 引用:https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash 毎回使うのは一部の Expertのみ (複数選ばれる) 項目 内容 モデル DeepSeek-V4-Flash アーキテクチャ MoE 総パラメータ数 284B 有効パラメータ数 13B コンテキスト長 1M tokens 精度 FP4 + FP8 Mixed ライセンス MIT Router Output Input
13 © 2025 Leverages Co., Ltd. 実際に動かしてみた
14 © 2025 Leverages Co., Ltd. ds4は、DeepSeek-V4系モデル向けに最適化された推論エンジンです。 README上でもDGX Spark GB10での実行例があるため、今回はDeepSeek-V4-Flashをds4で検証しま
す。 ※ q2/q4 は2bit級/4bit級のimatrix付きGGUF量子化 ds4を使用する 引用:https://github.com/antirez/ds4 README掲載ベンチマーク
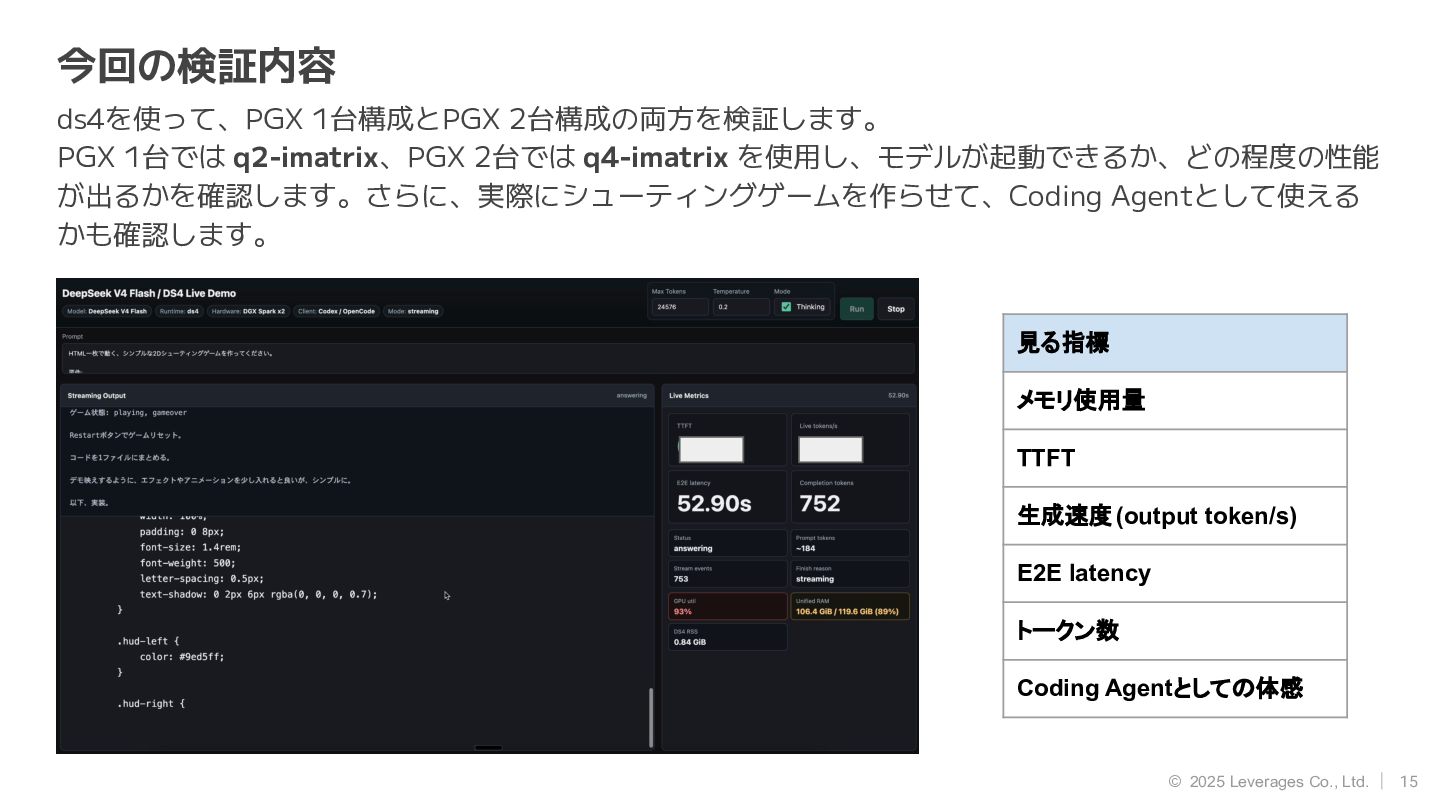
15 © 2025 Leverages Co., Ltd. 今回の検証内容 ds4を使って、PGX 1台構成とPGX 2台構成の両方を検証します。
PGX 1台では q2-imatrix、PGX 2台では q4-imatrix を使用し、モデルが起動できるか、どの程度の性能 が出るかを確認します。さらに、実際にシューティングゲームを作らせて、Coding Agentとして使える かも確認します。 見る指標 メモリ使用量 TTFT 生成速度(output token/s) E2E latency トークン数 Coding Agentとしての体感
16 © 2025 Leverages Co., Ltd. PGX1台(q2-imatrix)
17 © 2025 Leverages Co., Ltd. PGX1台(q2-imatrix) 観点 結果 メモリ使用量
93 GB / 128GB TTFT 0.88 秒 生成速度 14 tokens/s E2E latency 443.61 秒 体感 簡単なものは使える トークン数 6135 Token 感想 結構速いし、意外とゲーム 作れてて感動! PGX 1台(q2-imatrix)の結果
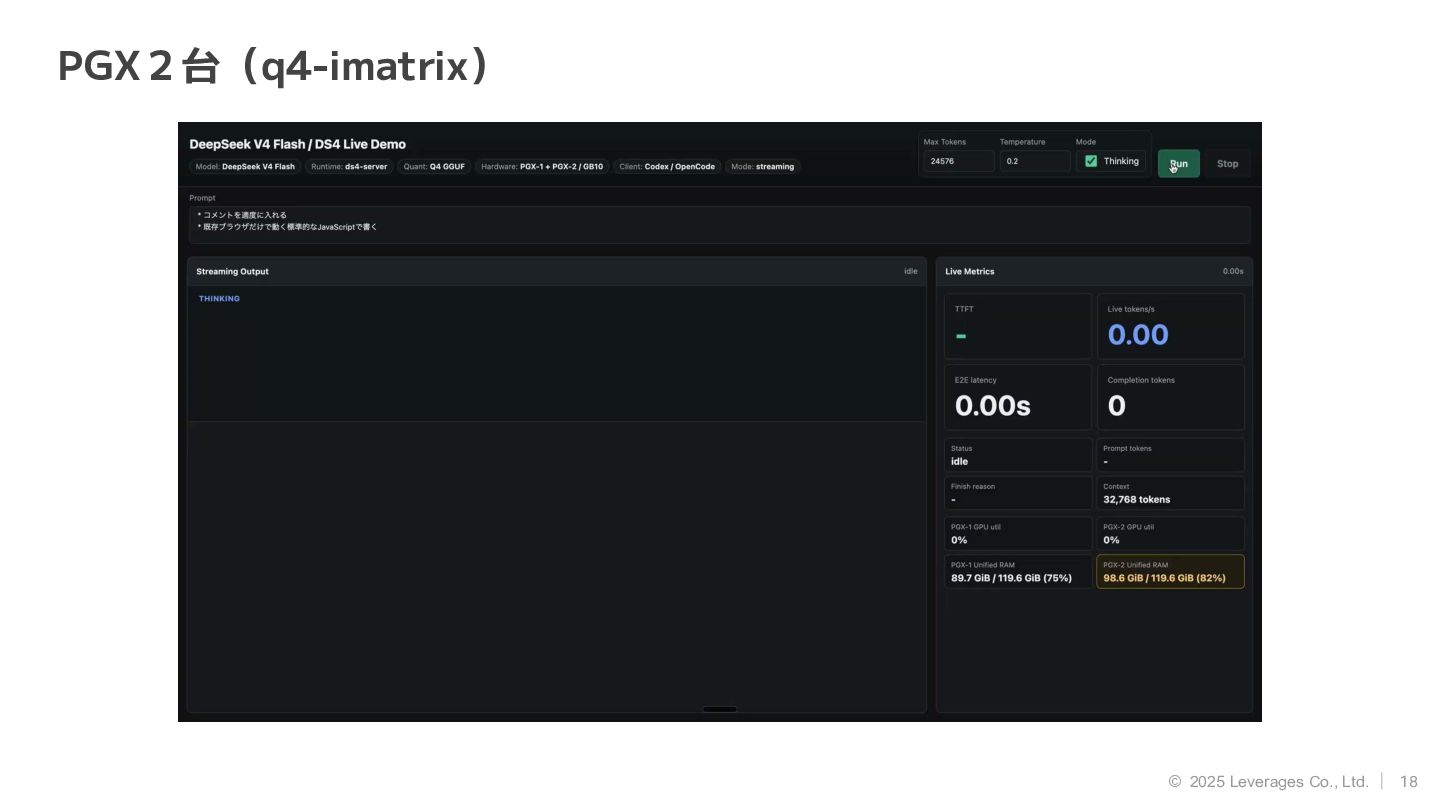
18 © 2025 Leverages Co., Ltd. PGX2台(q4-imatrix)
19 © 2025 Leverages Co., Ltd. PGX2台(q4-imatrix) 観点 結果 メモリ使用量
(PGX-1) 0 ~ 92 GB / 128GB メモリ使用量 (PGX-2) 43 ~ 57 GB / 128GB TTFT 4.92秒 生成速度 9.2 tokens/s E2E latency 1820.29 秒 トークン数 17039 Token 体感 使えるが遅い 感想 速度は遅いが、生成物の品質は かなり良い! PGX 2台(q4-imatrix)の結果
20 © 2025 Leverages Co., Ltd. おまけ その1:PGX2台(q4-imatrix) Thinking無しで作ってみました。一生ゲームオーバーから進まなくてゲームができませんでした。
21 © 2025 Leverages Co., Ltd. おまけ その2:PGX2台(q4-imatrix) フェーズやボス戦、強化アイテムなどを追加しても、きちんと動くコードが生成されました。 大体4分くらいでできた。
22 © 2025 Leverages Co., Ltd. おまけ その3:Codex(参考) めっちゃクオリティ高い!ノーマルフェーズは難易度高いが、ボス戦は難易度が低かった。 生成時間は4分くらい。
23 © 2025 Leverages Co., Ltd. ぶっちゃけどう?? 実際にDeepSeek-V4-FlashをPGX上で起動し、コード生成まで試すことはできました。 なので、PGXのようなローカルAIマシンでも、Coding Agent用途に使える可能性は十分あると思いま
す。 ただし、今すぐ実用で使うなら、安定性・速度・運用面ではクラウドの方が扱いやすいです。 組織で使う場合は、サーバー運用、冷却、リソース管理、モデル更新、障害対応なども考える必要があり ます。 それでも、ローカルLLMでここまでできるようになってきたのはかなり面白いです。 今後、ハードウェアや推論エンジンが進化すれば、ローカルCoding Agentの現実味はさらに増していく と思います。
24 © 2025 Leverages Co., Ltd. まとめ
25 © 2025 Leverages Co., Ltd. まとめ 1. PGXでも、巨大MoEモデルをローカルで動かし、Coding Agentとして使うことはでき
た。 2. ただし、2台構成でも速さ・安定性・運用面にはまだ課題がある。 3. 現時点ではクラウド版の方が実用的だが、ローカルCoding Agentの可能性は十分に感 じられた。
26 © 2025 Leverages Co., Ltd. ご清聴ありがとう ございました!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}