what a generalist can use Tensorflow for, - what can it teach us about a good product. What's this talk is not about: - ex%nc%on or salva%on by AI, - coding tutorial, - pitching a Google product. 4
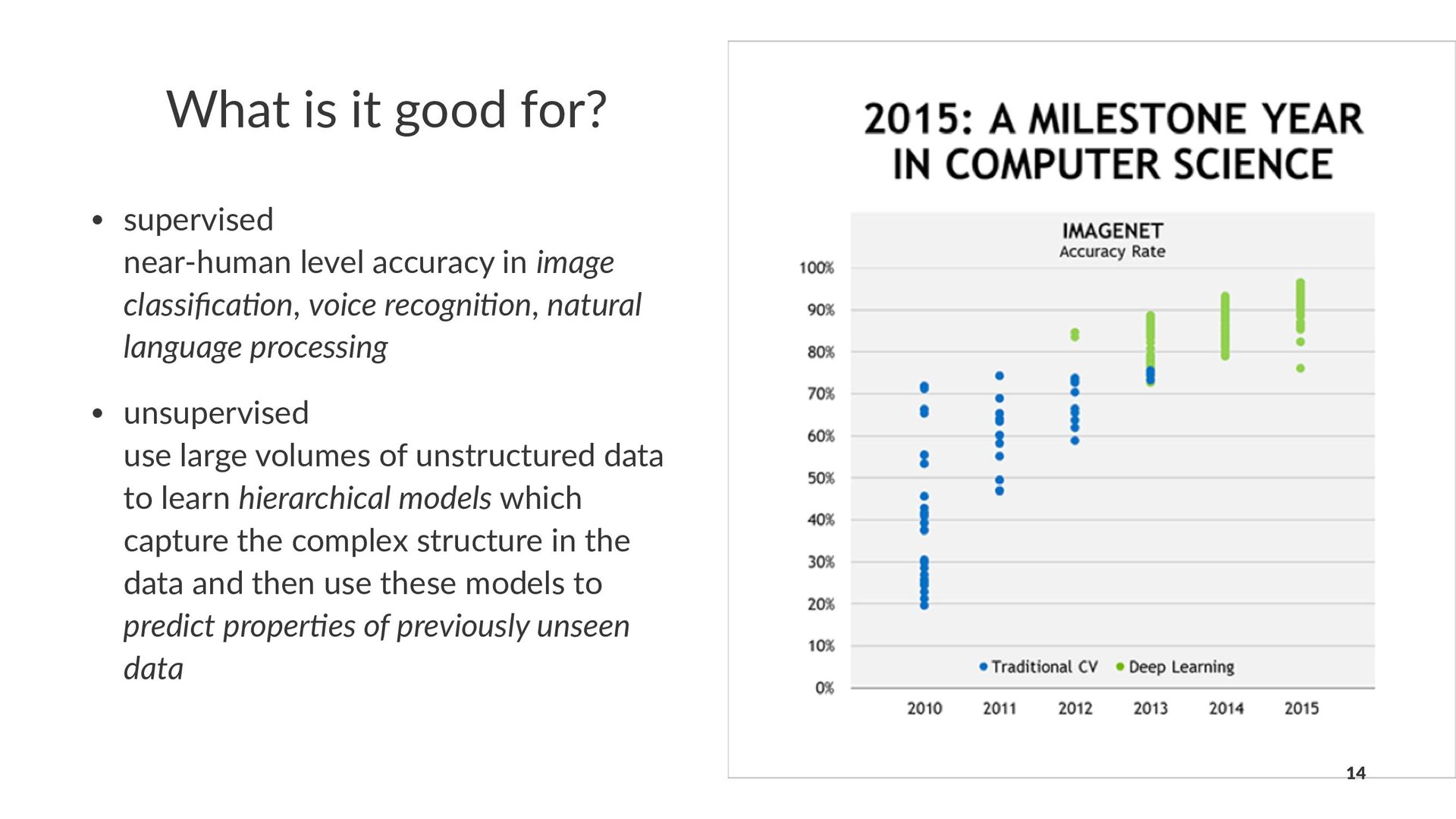
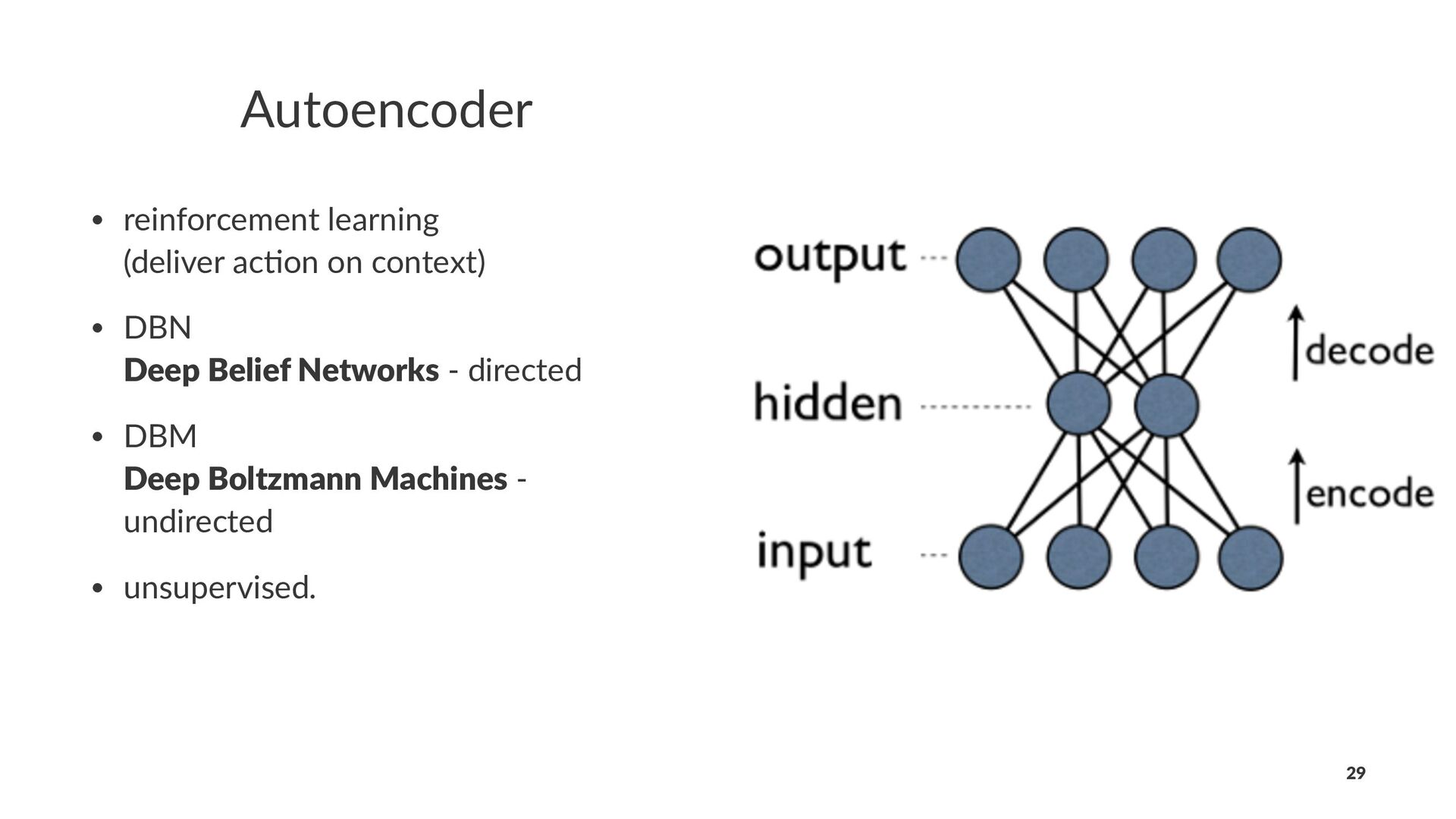
in image classifica+on, voice recogni+on, natural language processing • unsupervised use large volumes of unstructured data to learn hierarchical models which capture the complex structure in the data and then use these models to predict proper+es of previously unseen data 14
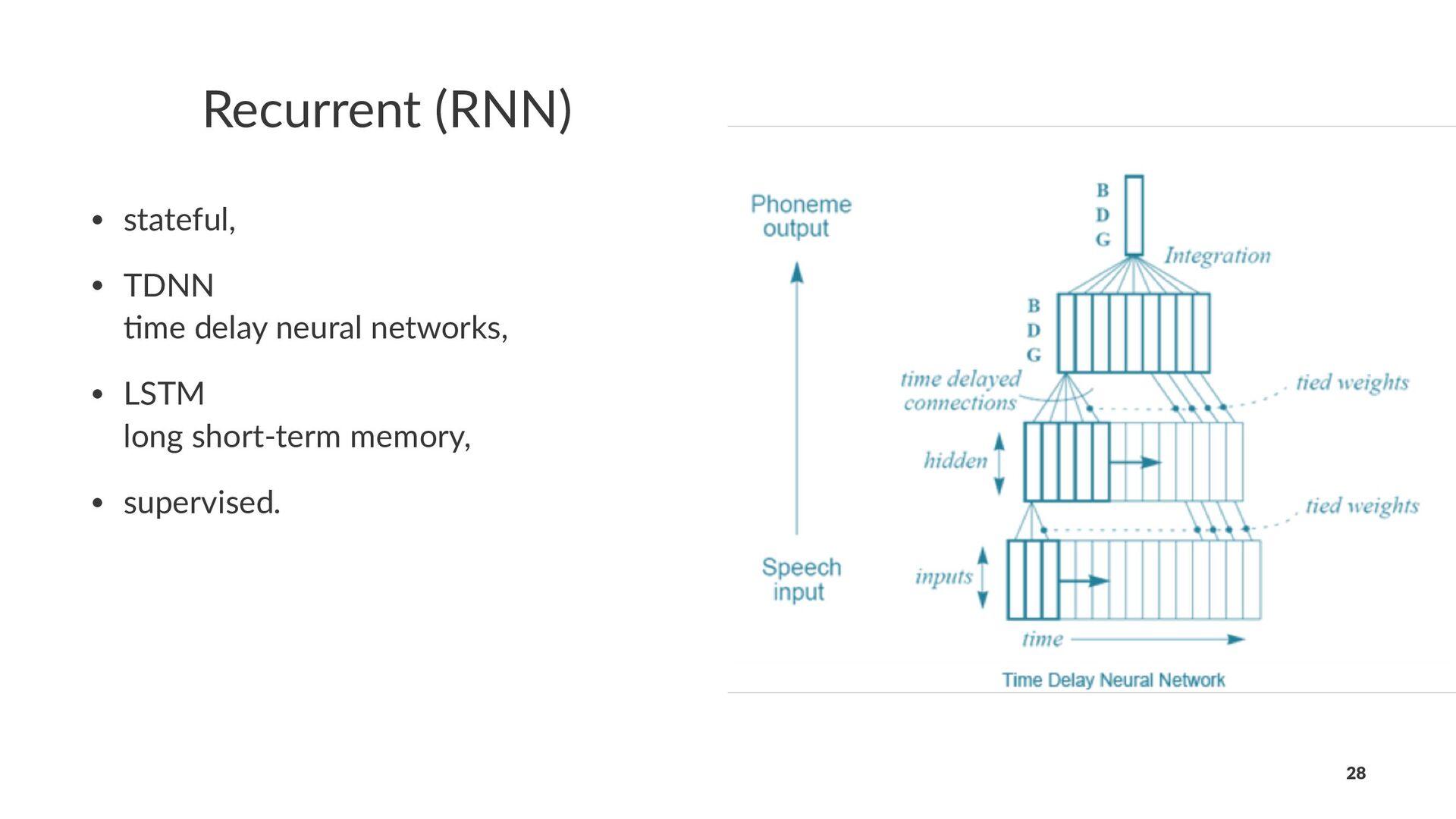
neural networks with many layers, • weighs can be n dimensional arrays (tensors), • high level way of defining predic0on code or forward pass, • framework figures the deriva<ves (backwards pass). 16
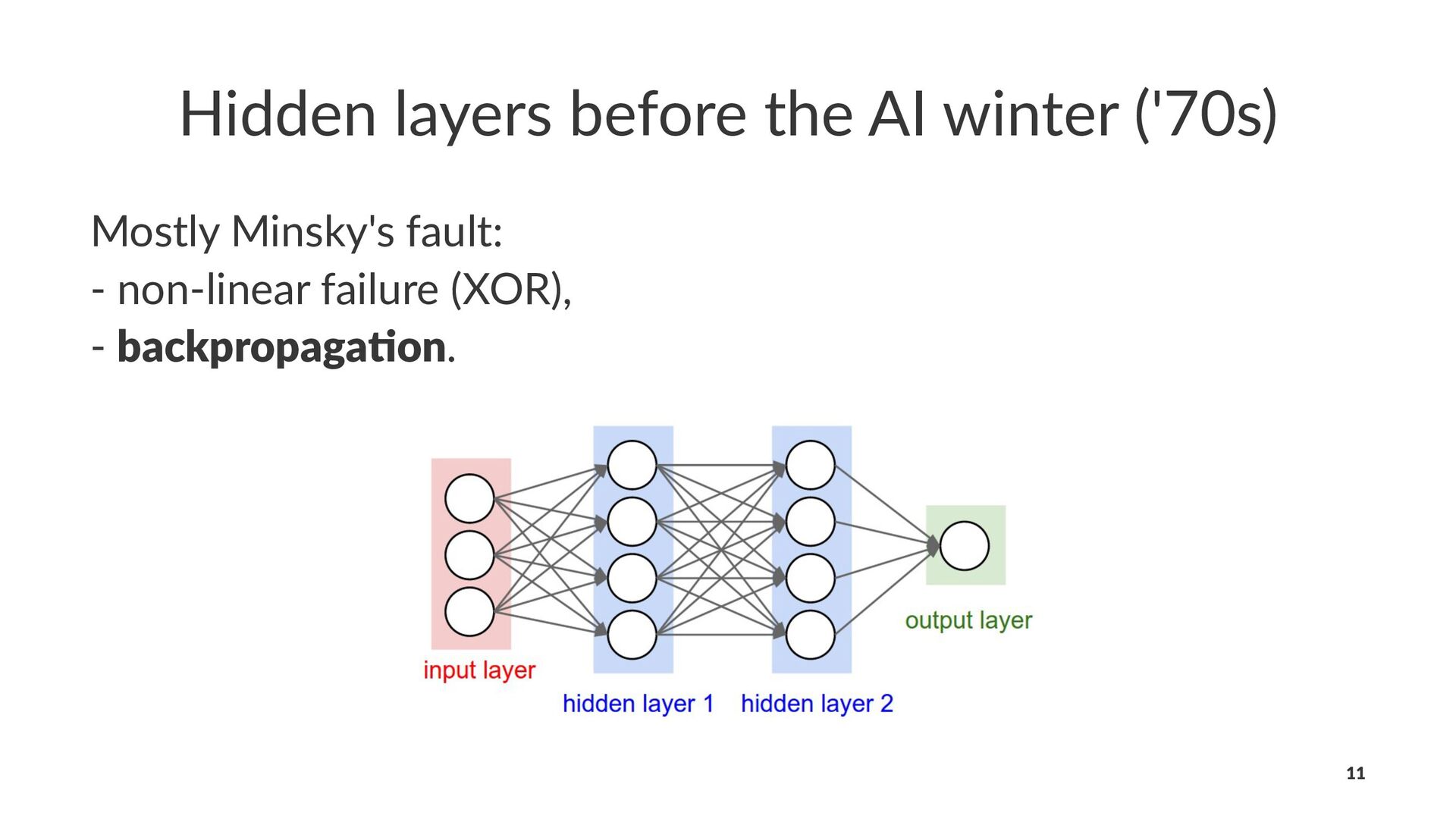
in the past: - our labeled datasets were thousands of 9mes too small, - our computers were millions of 9mes too slow, - we ini1alized the weights in a stupid way, - we used the wrong type of non-linearity. 17
closely, • pip packages are now PyPI compliant, • high-level API includes a new *.keras module (almost halve the boilerplate), • Sonnet, a new high level API from DeepMind. 33
Projector high level model understanding via visualiza:on, • XLA domain-specific compiler for TF graphs (CPUs and GPUs), • Fold for dynamic batching, • TensorFlow Serving to serve TF models in produc:on, 35
RasPI preven1ng skin cancer and blindness in diabe1cs LSTM (transla)on, speech recogni)on) language transla1on RNN (genera)on, )me series analysis) text, image and doodle genera1on in style or from text Reinforcement learning (control and play, autonomous driving) OpenAI Lab 38
predic-on model • device downloads current model, • improves it by learning from local data (retrain), • summarizes changes of model as small focused update, • update, but no data, is sent to the cloud encrypted, • averaged with other user updates to improve the shared model. 41
really need it? • Prepare data (small data < transfer learning + domain adapta9on, cover problem space, balance classes, lower dimensionality). • Find analogy (CNN, RNN/LSTM/GRU, RL). • Create a simple, small & easy baseline model, visualize & debug. • Fine-tune (evalua9on metrics - test data, loss func9on - training). (Smith: Best Prac0ces for Applying Deep Learning to Novel ... , 2017) 42
commodity, • AI is cleantech 2.0 for VCs, • MLaaS dies a second death, • full stack verCcal AI startups actually work. (Cross: Five AI Startup Predic6ons for 2017) 44
History of Neural Nets and Deep Learning, Part 1-4 • Adam Geitgey: Machine Learning is Fun! • TensorFlow and Deep Learning – Without a PhD (1 and 3 hour version) • Pete Warden: Tensorflow for Poets 45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}