Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ndb
Search
spicyj
May 28, 2014
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ndb
spicyj
May 28, 2014
More Decks by spicyj
See All by spicyj
React: What Lies Ahead
spicyj
6
390
Creating interactive learning interfaces at Khan Academy
spicyj
0
130
Understanding state in React
spicyj
1
130
css
spicyj
2
890
Other Decks in Technology
See All in Technology
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
0
120
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
2
770
Making sense of Google’s agentic dev tools
glaforge
1
200
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
120
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.9k
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
510
SRE Lounge Hiroshimaへの招待
grimoh
0
640
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.5k
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
360
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
0
180
Featured
See All Featured
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
280
Automating Front-end Workflow
addyosmani
1370
210k
Producing Creativity
orderedlist
PRO
348
40k
Documentation Writing (for coders)
carmenintech
77
5.4k
First, design no harm
axbom
PRO
2
1.2k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
My Coaching Mixtape
mlcsv
0
170
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Speed Design
sergeychernyshev
33
1.9k
Transcript
ndb “NDB is a better datastore API for the Google
App Engine Python runtime.”
Part 1 of 2
Why ndb? 1. Less stupid by default 2. More flexible
queries 3. Tasklets with autobatching
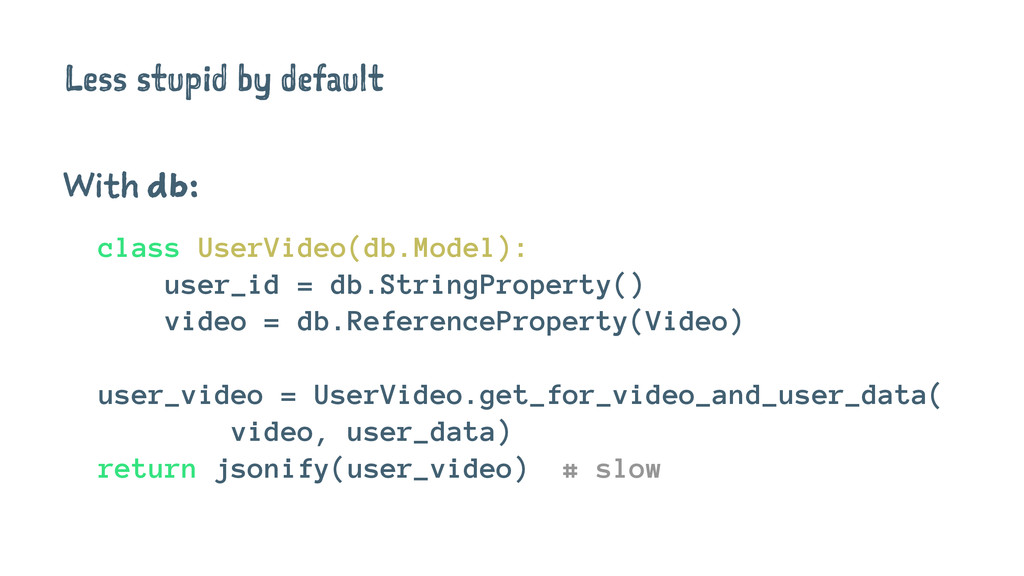
Less stupid by default With db: class UserVideo(db.Model): user_id =
db.StringProperty() video = db.ReferenceProperty(Video) user_video = UserVideo.get_for_video_and_user_data( video, user_data) return jsonify(user_video) # slow
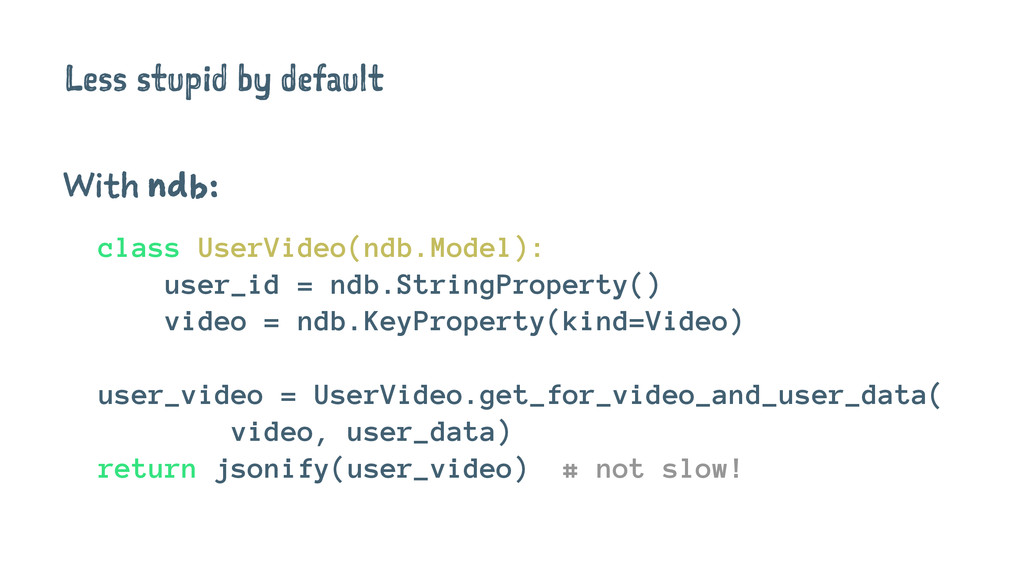
Less stupid by default With ndb: class UserVideo(ndb.Model): user_id =
ndb.StringProperty() video = ndb.KeyProperty(kind=Video) user_video = UserVideo.get_for_video_and_user_data( video, user_data) return jsonify(user_video) # not slow!
More flexible queries ndb lets you build filters using ndb.AND
and ndb.OR: questions = Feedback.query() .filter(Feedback.type == 'question') .filter(Feedback.target == video_key) .filter(ndb.OR( Feedback.is_visible_to_public == True, Feedback.author_user_id == current_id)) .fetch(1000) Magic happens.
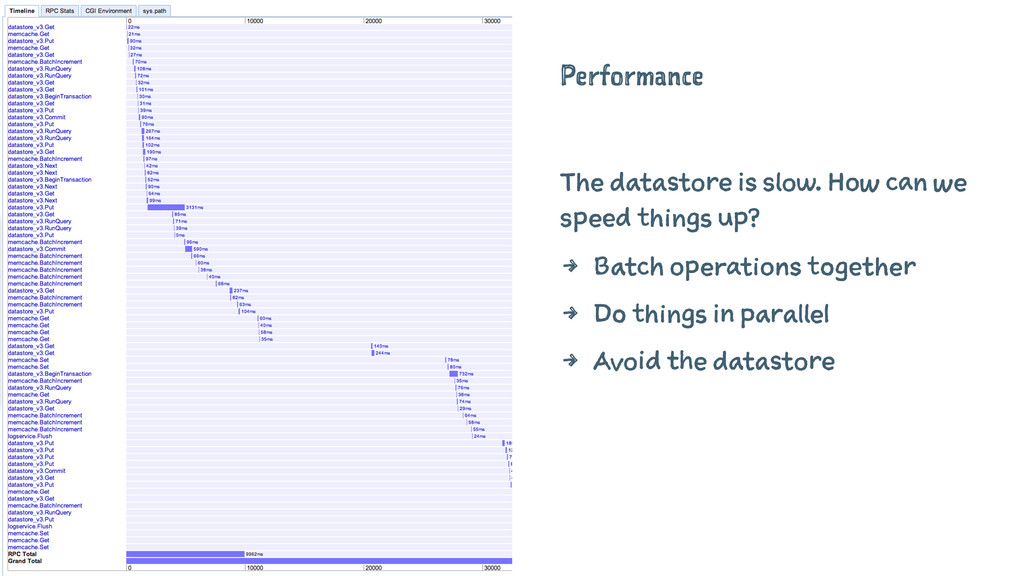
Performance The datastore is slow. How can we speed things
up? 4 Batch operations together 4 Do things in parallel 4 Avoid the datastore
Tasklets and autobatching def get_user_exercise_cache(user_data): uec = UEC.get_for_user_data(user_data) if not
uec: user_exercises = UE.get_all(user_data) uec = UEC.build(user_exercises) return uec def get_all_uecs(user_datas): return map(get_user_exercise_cache, user_datas)
Tasklets and autobatching @ndb.tasklet def get_user_exercise_cache_async(user_data): uec = yield UEC.get_for_user_data_async(user_data)
if not uec: user_exercises = yield UE.get_all(user_data) uec = UEC.build(user_exercises) raise ndb.Return(uec) @ndb.synctasklet def get_all_uecs(user_datas): uecs = yield map(get_user_exercise_cache_async, user_datas) raise ndb.Return(uecs)
Moral ndb is awesome. Use it.
Part 2 of 2
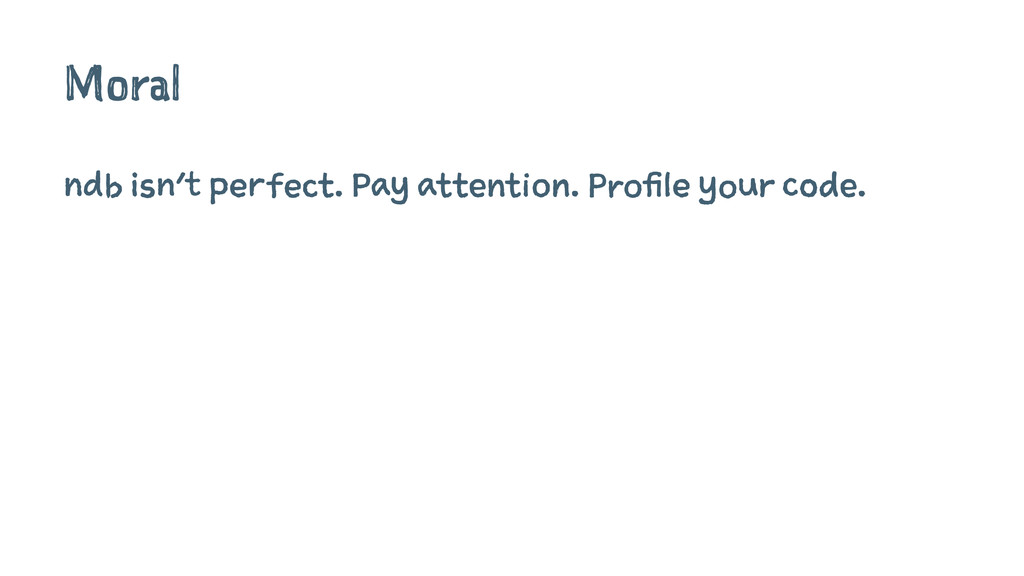
The sad truth ndb isn't perfect.
Mysterious errors You heard from Marcia about this gem back
in March: TypeError: '_BaseValue' object is not subscriptable
Q: What's worse than code that doesn't work at all?
A: Code that mostly works but breaks in subtle ways.
Secret slowness #1 Multi-queries, with IN and OR: answers =
Feedback.query() .filter(Feedback.type == 'answer') .filter(Feedback.in_reply_to.IN(question_keys)) .fetch(1000) Doesn't run in parallel!
Secret slowness #1 A not-horribly-slow multi-query: answers = Feedback.query() .filter(Feedback.type
== 'answer') .filter(Feedback.in_reply_to.IN(question_keys)) .order(Feedback.__key__) .fetch(1000)
Secret slowness #2 Query iterators: query = Feedback.query().filter( Feedback.topic_ids ==
'algebra') questions = [] for q in query.iter(batch_size=20): if q.is_visible_to(user_data): questions.append(q) if len(questions) >= 10: break
Secret slowness #2 Solution? Sometimes you have to do it
by hand.
Moral ndb isn't perfect. Pay attention. Profile your code.
The End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}