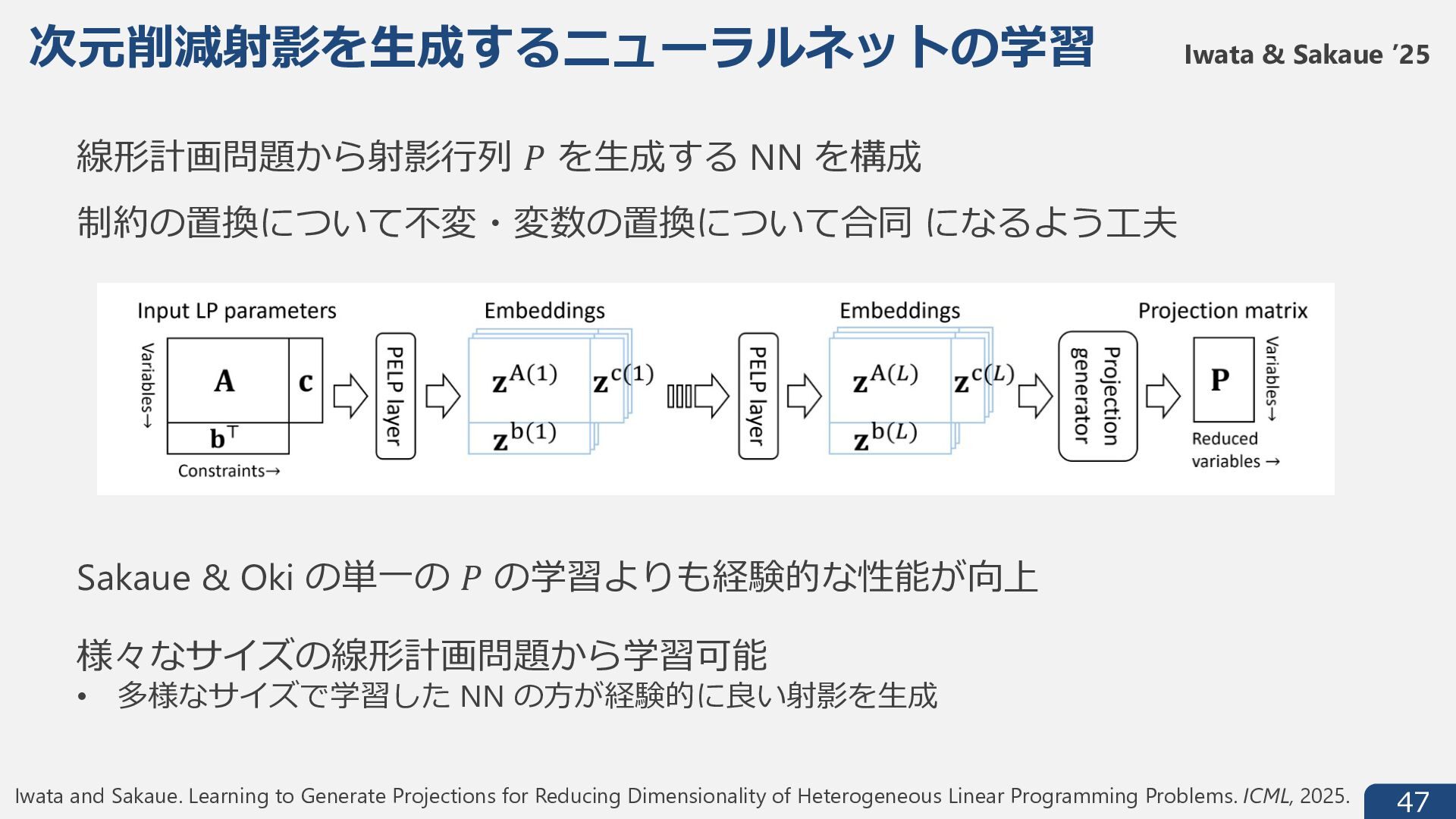
𝑏 の⼊⼒ (𝑐, 𝐴, 𝑏) が i.i.d. で⽣成される Sakaue & Oki ’24 𝐴 𝑐1 𝑃 ≤ max s. t. 𝑦 𝑏 𝑃 𝑦 射影⾏列 𝑃 ∈ ℝ6×; で 𝑘 次元に射影して効率的に解く (cf. Vu et al. 2018) Vu, Poirion and Liberti. Random Projections for Linear Programming. Math of OR, 2018. Sakaue and Oki. Generalization Bound and Learning Methods for Data-Driven Projections in Linear Programming. NeurIPS, 2024. データから 𝑃 を学習し経験的に良い解を得ることを⽬指す 射影⾏列 低次元
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
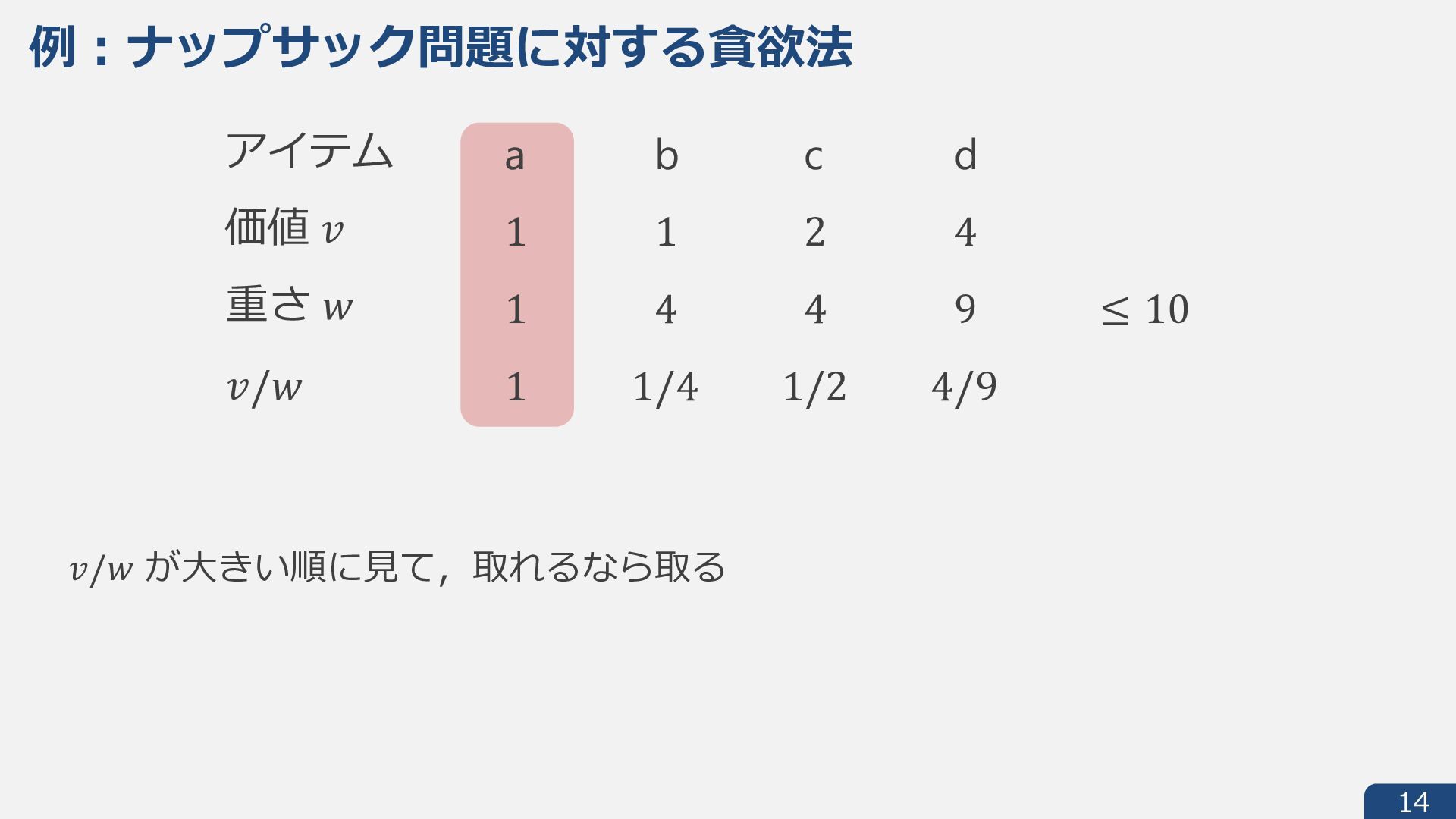{kind=link}
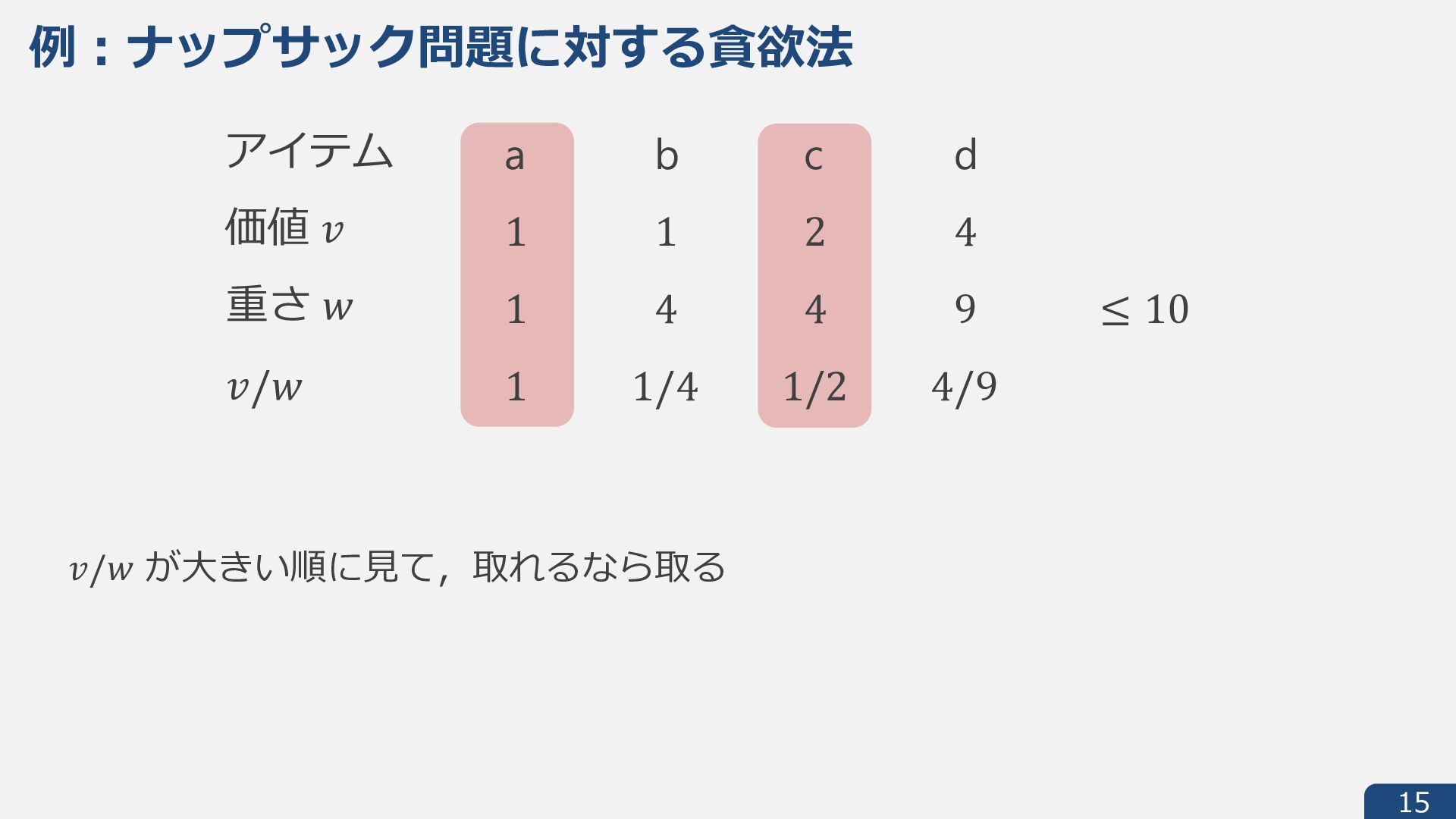{kind=link}
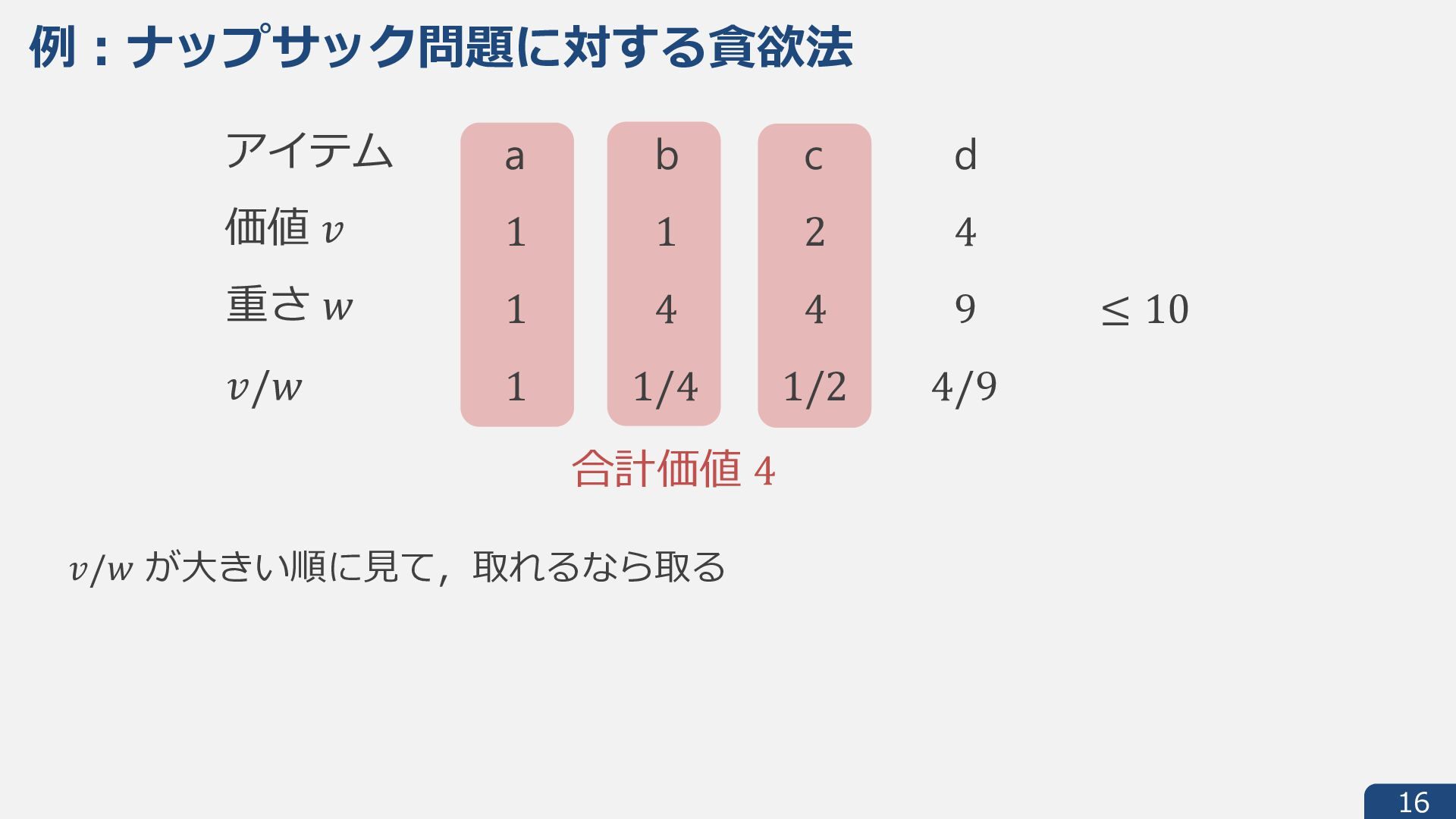{kind=link}
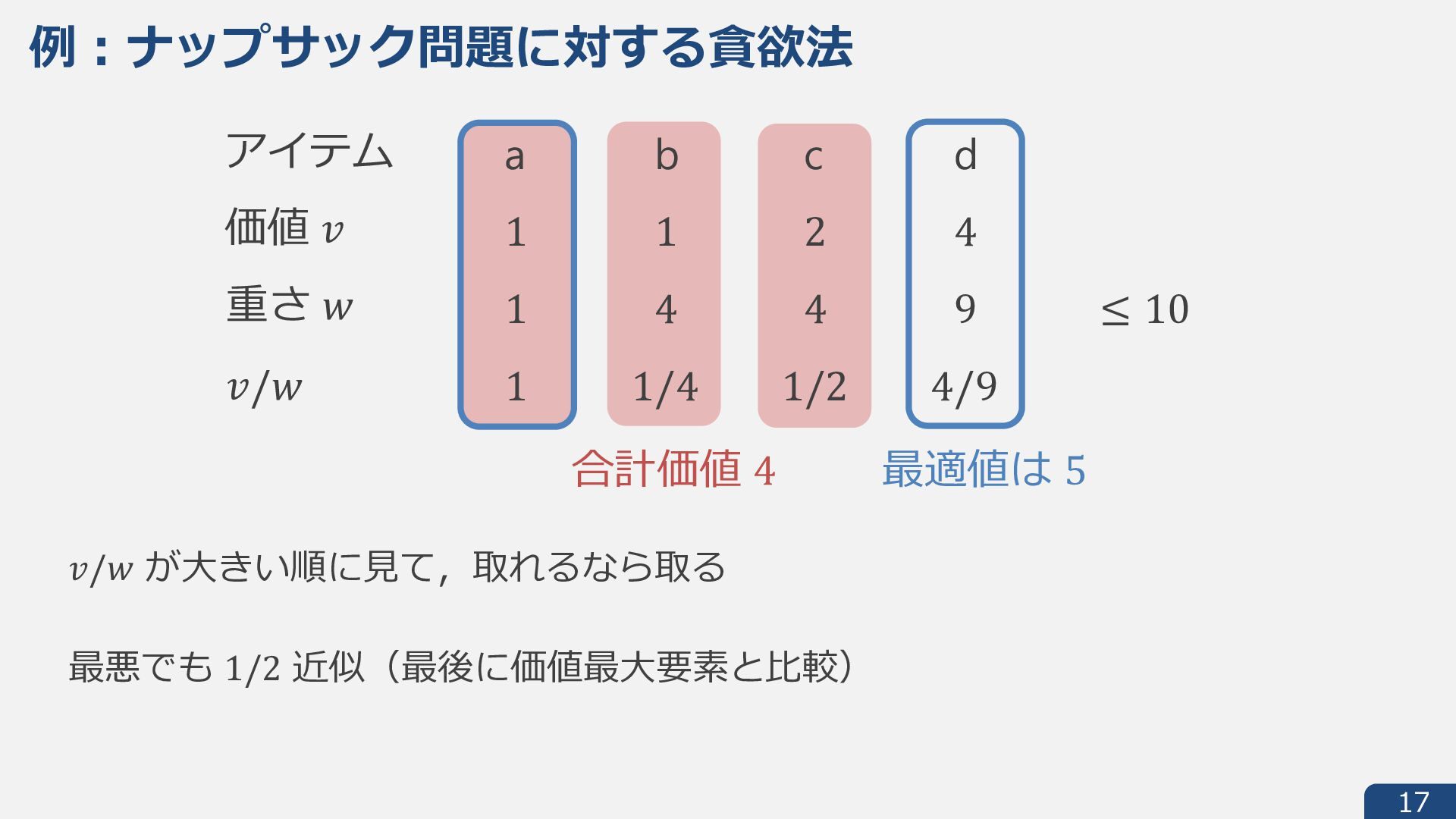{kind=link}
{kind=link}
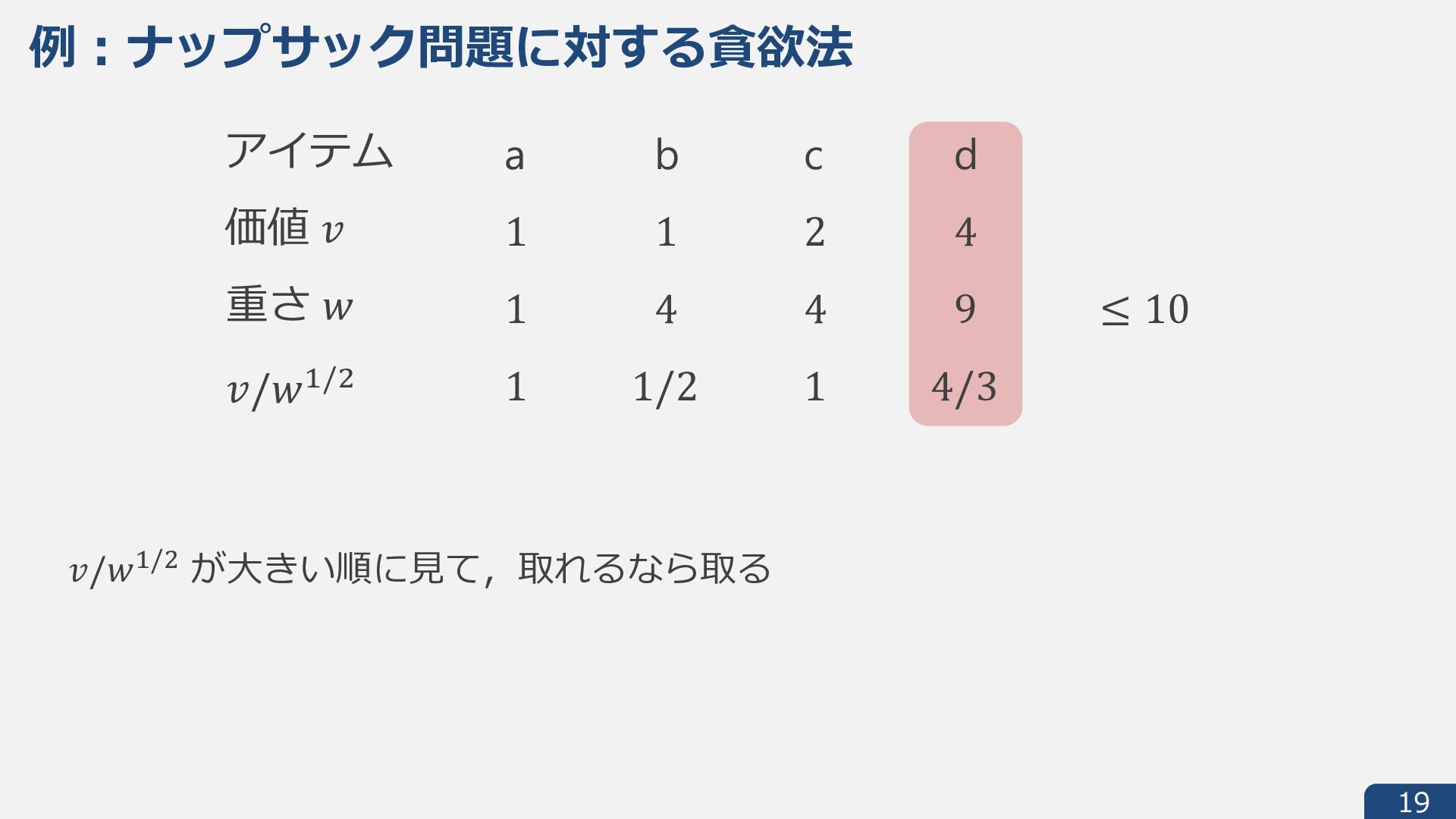{kind=link}
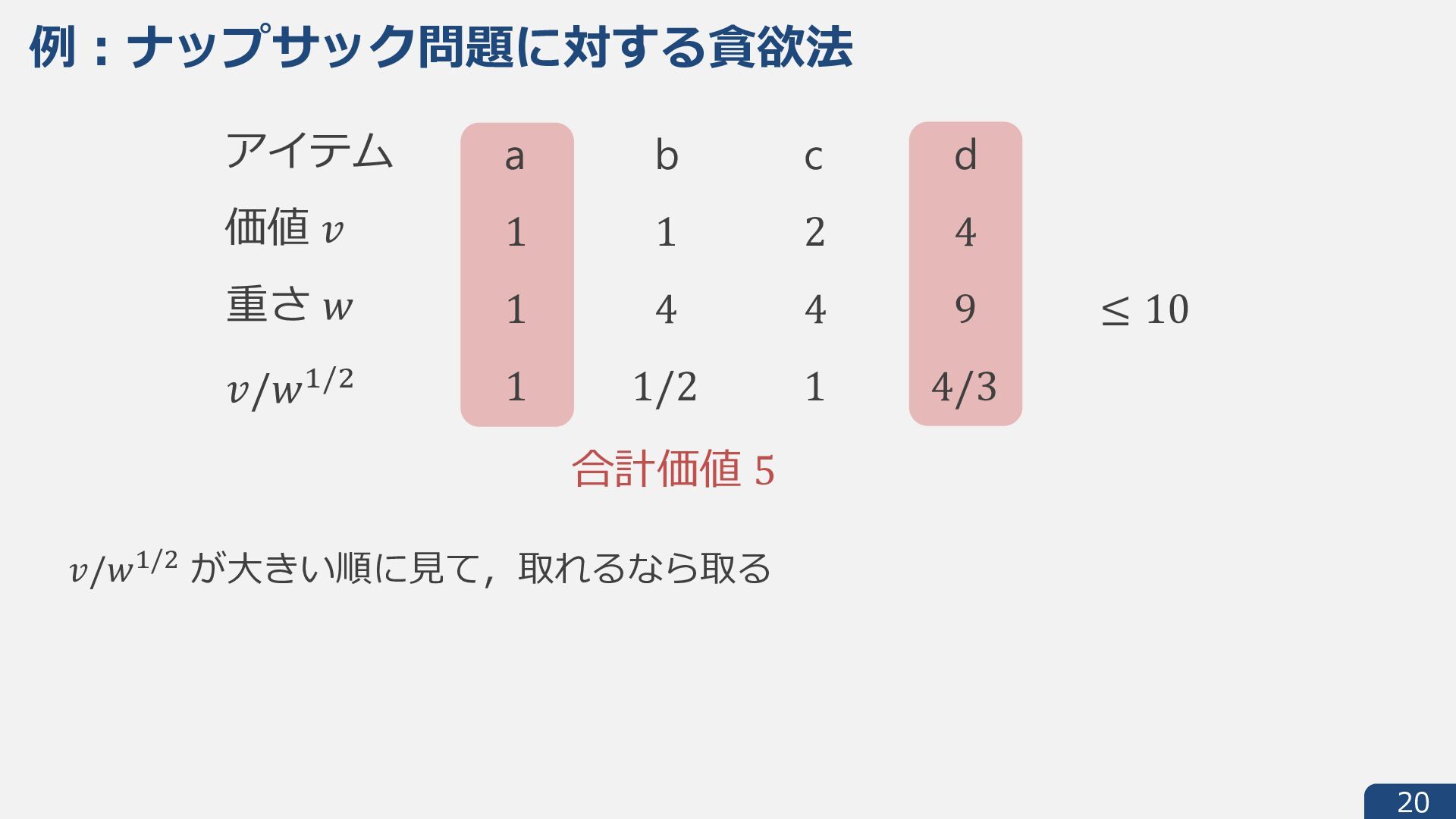{kind=link}
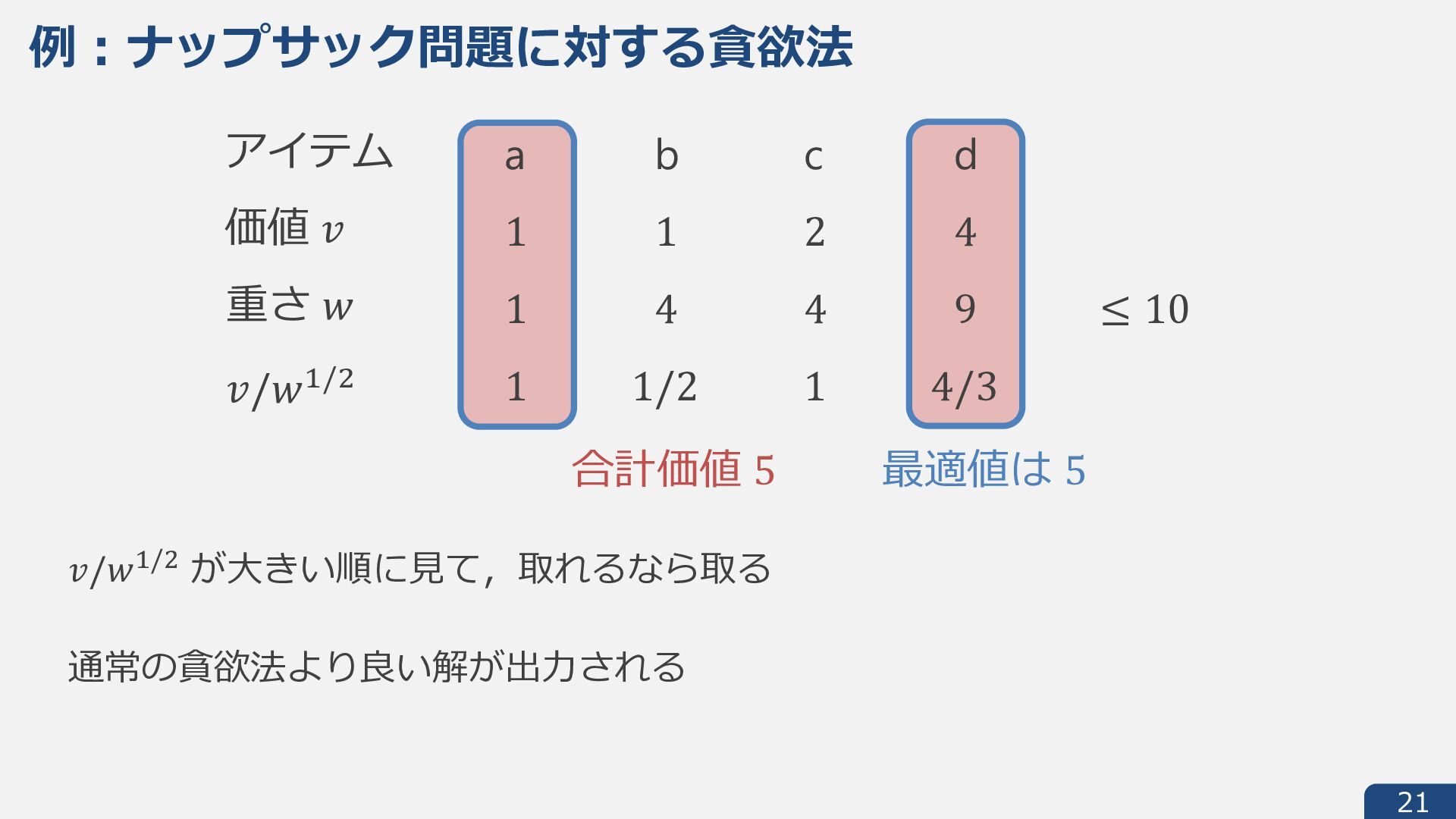{kind=link}
{kind=link}
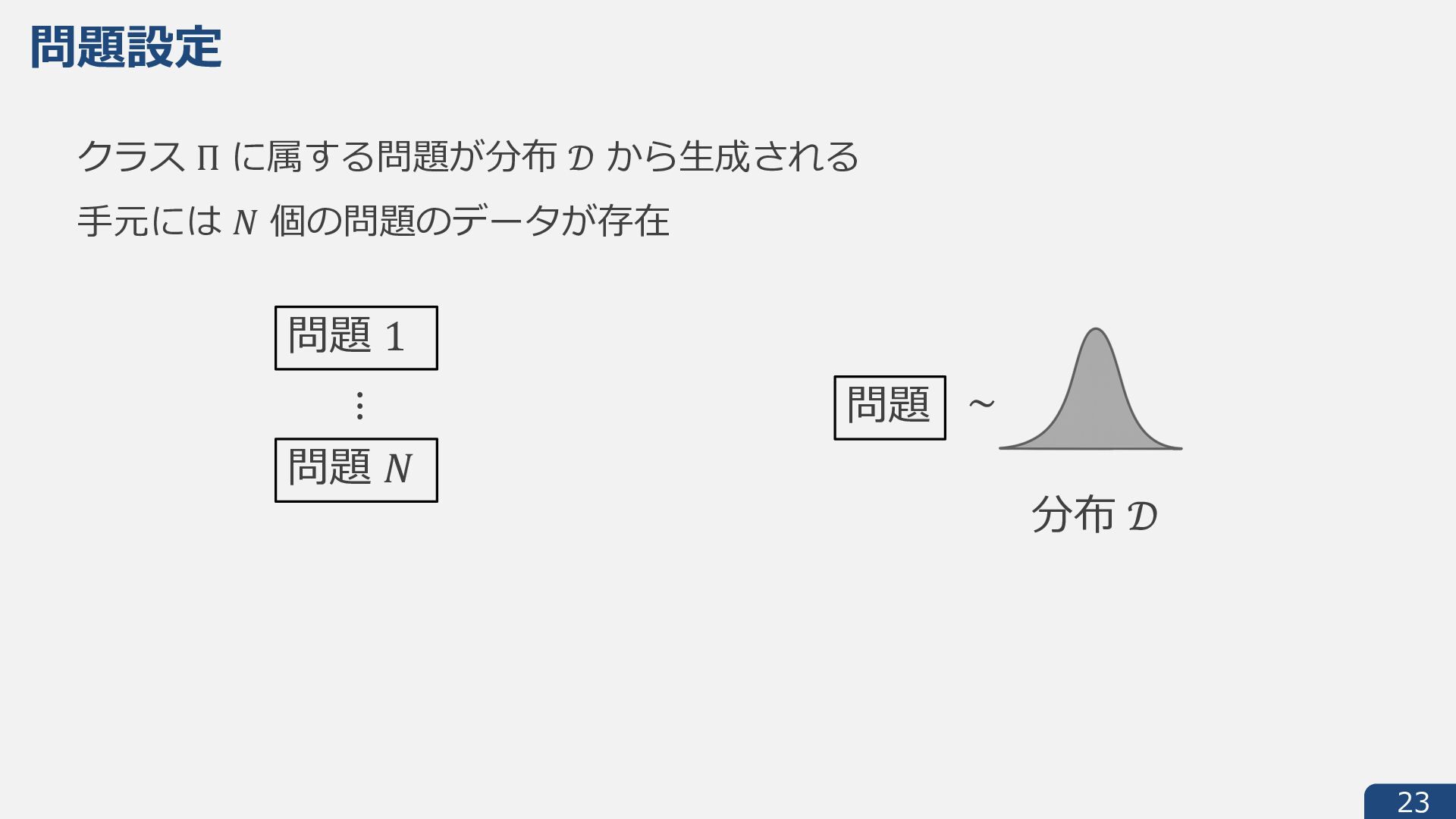{kind=link}
{kind=link}
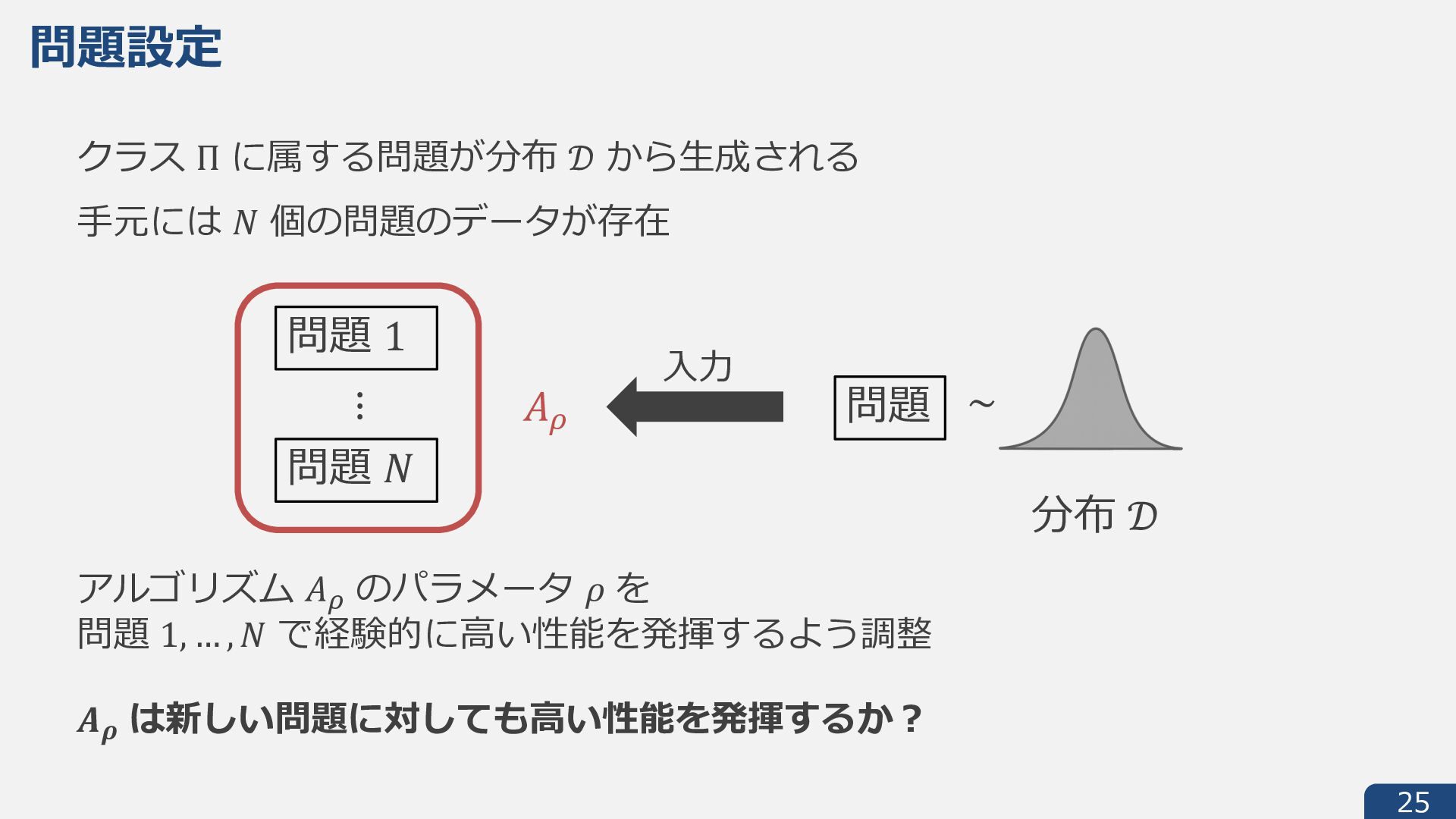{kind=link}
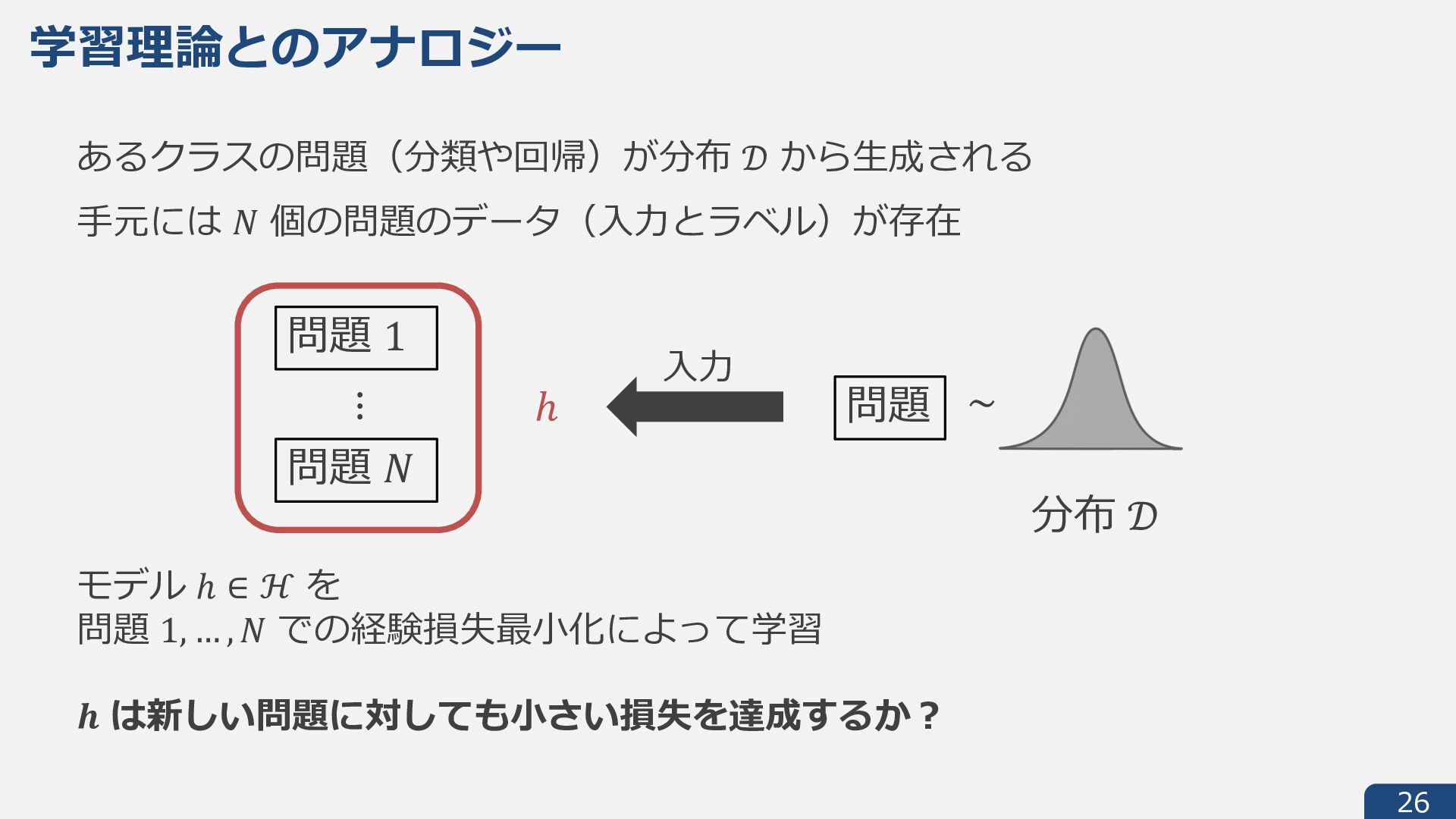{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
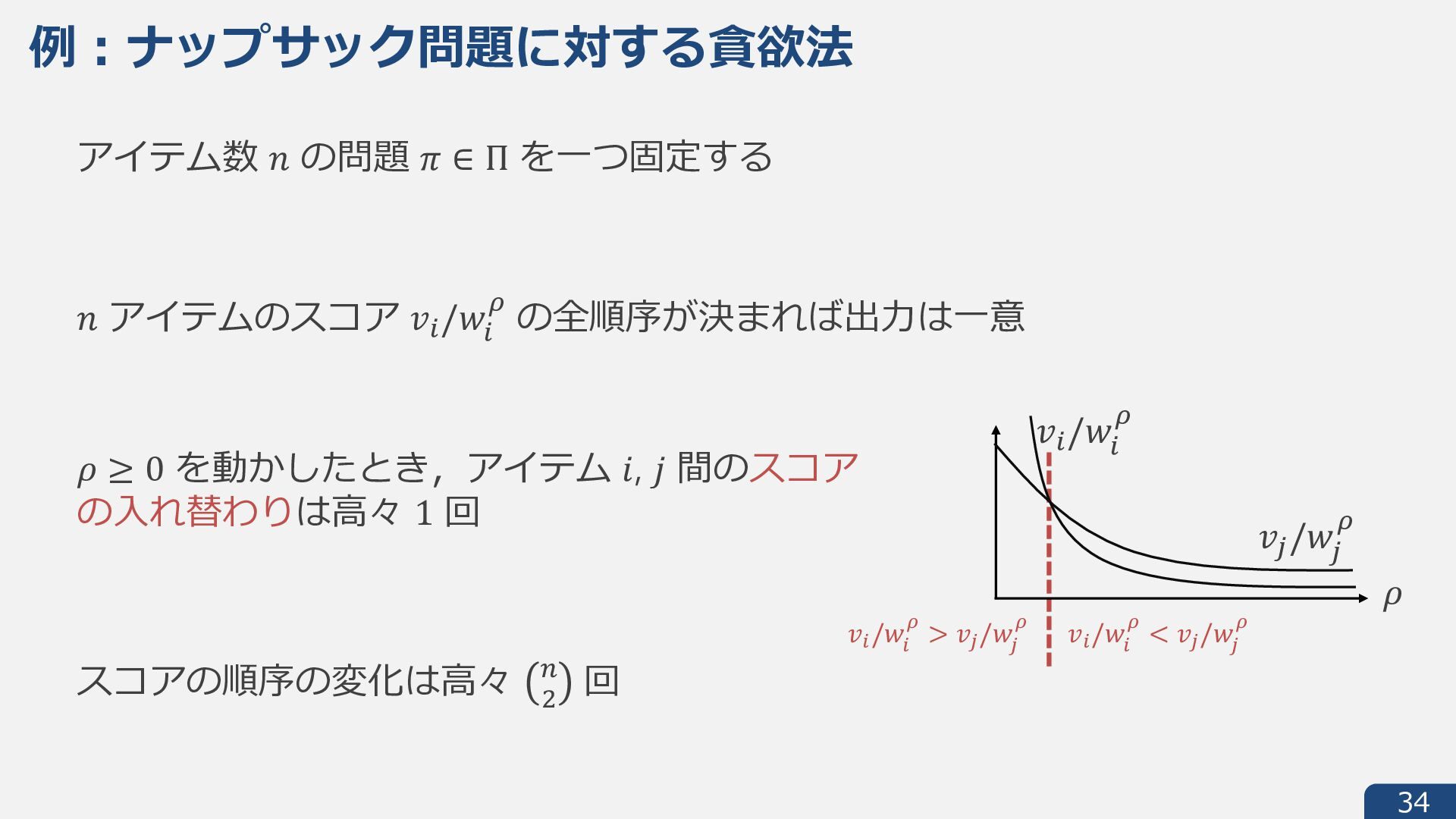{kind=link}
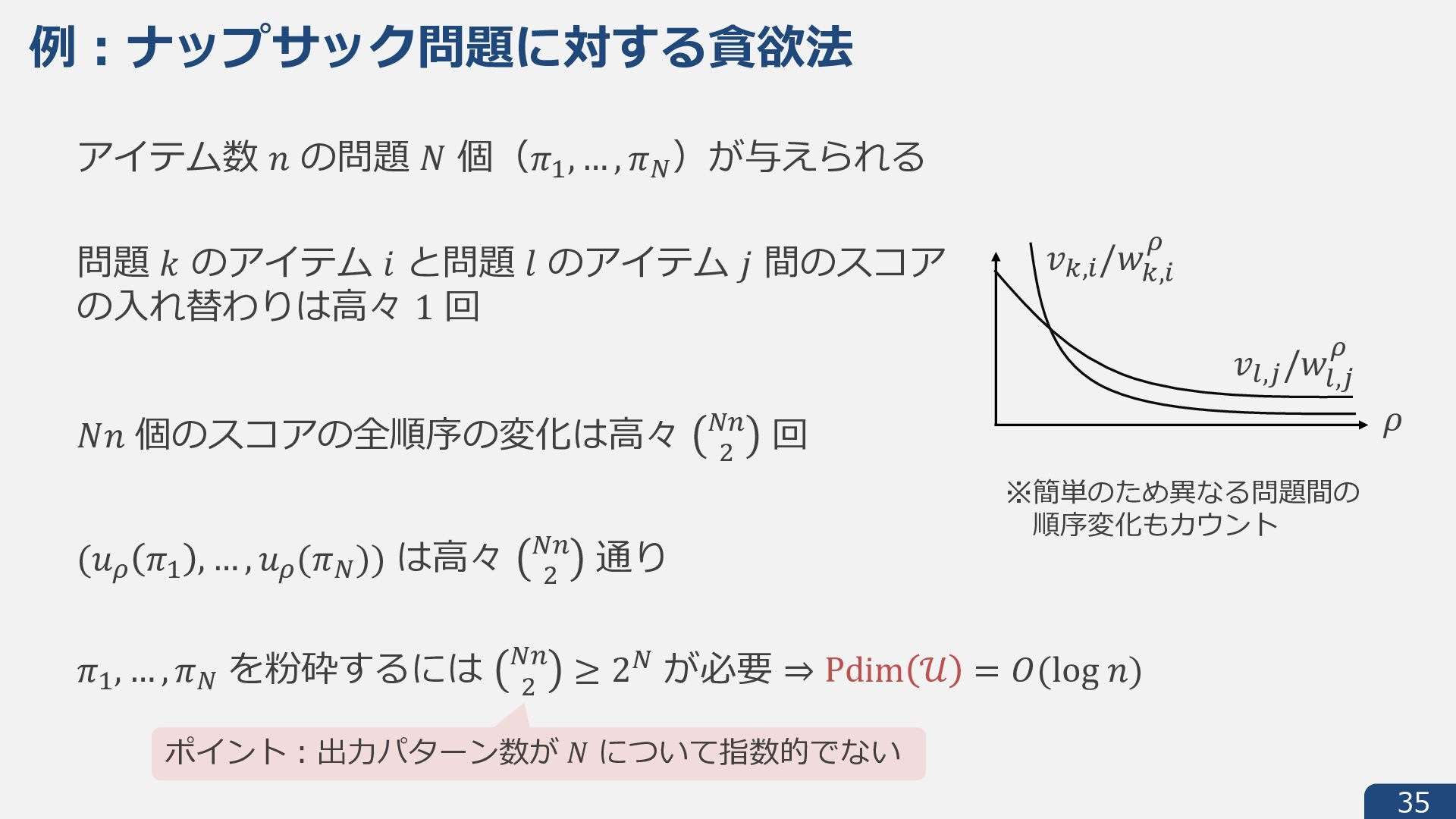{kind=link}
{kind=link}
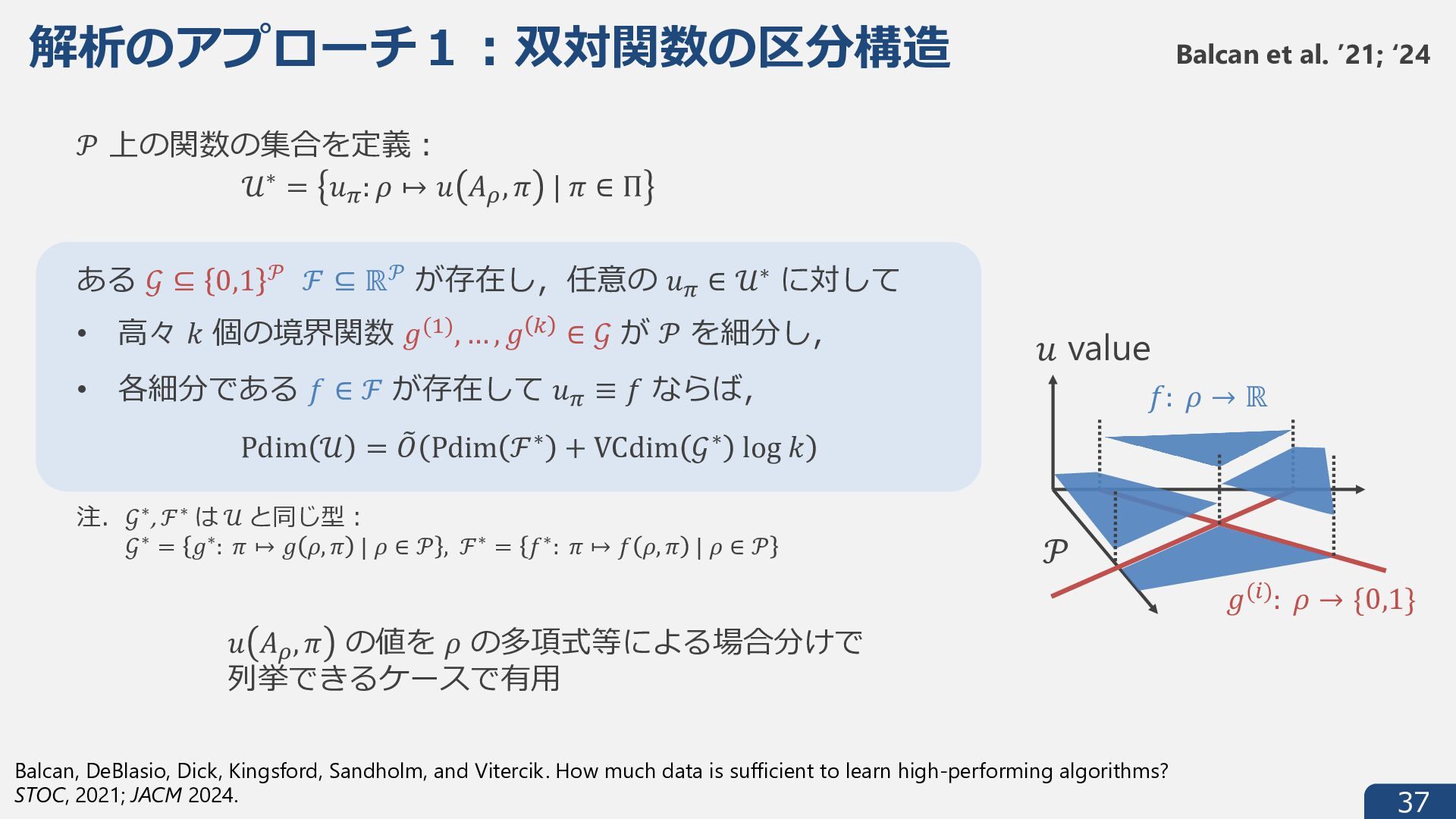{kind=link}
{kind=link}
{kind=link}
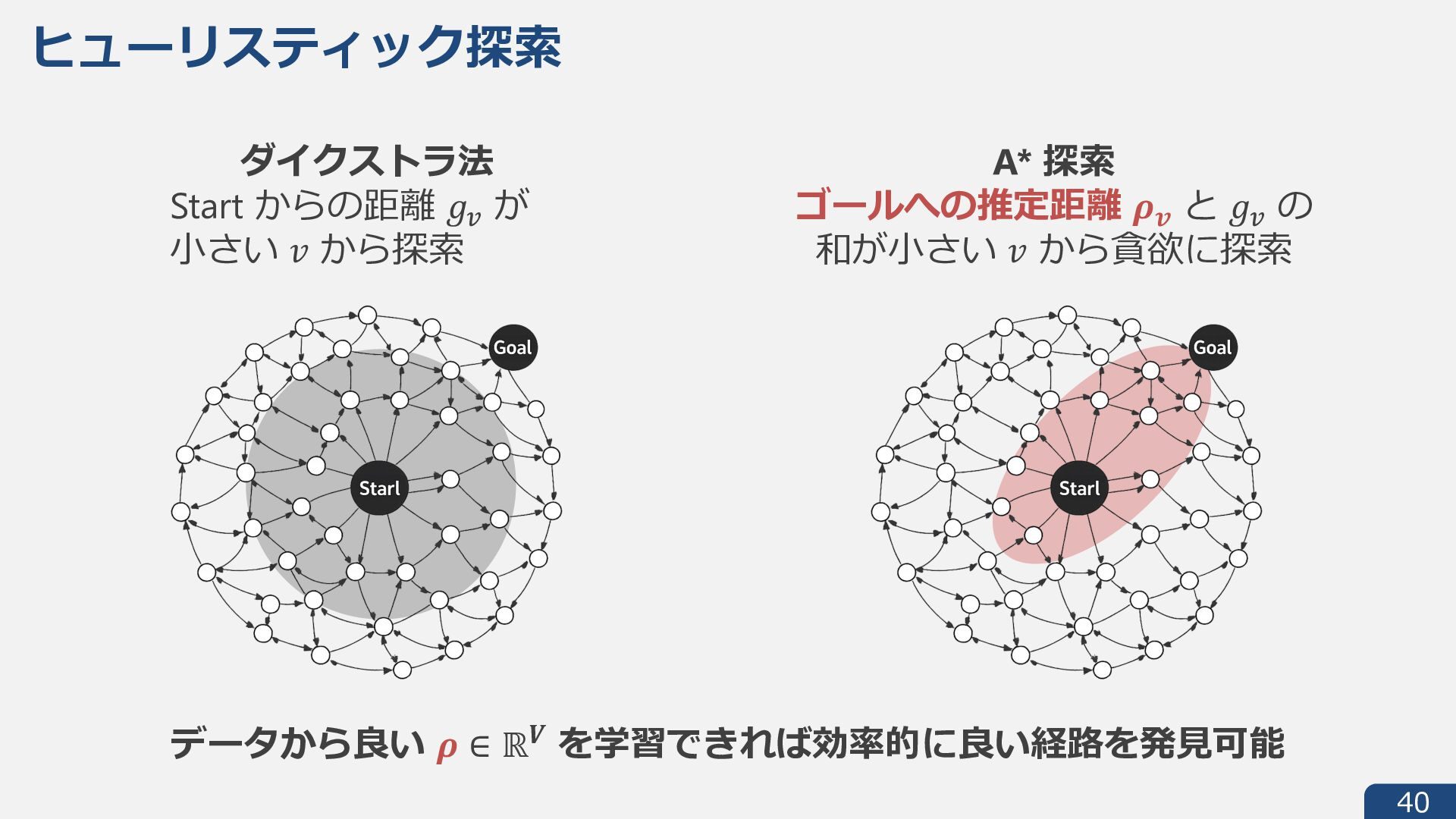{kind=link}
{kind=link}
{kind=link}
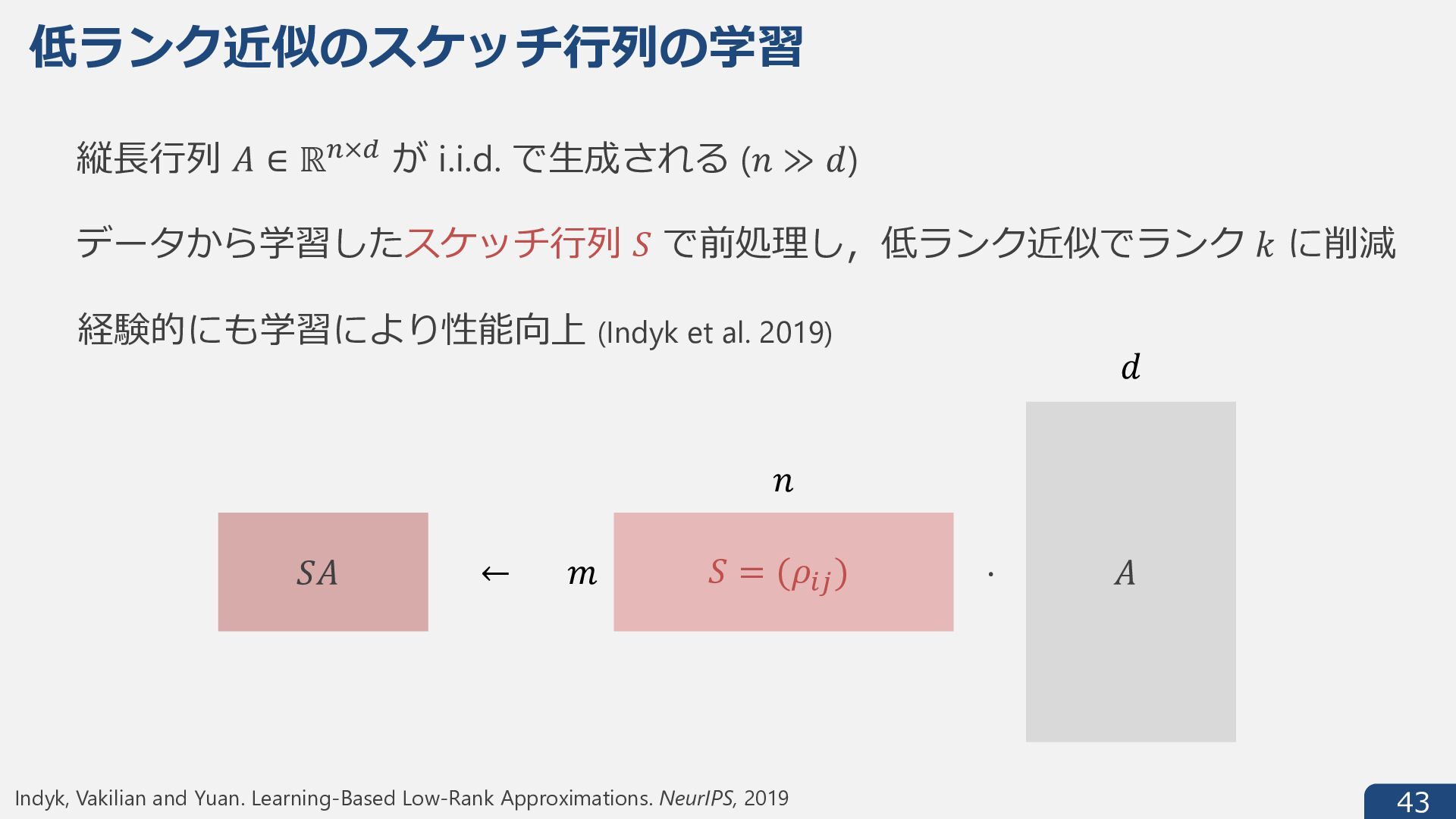{kind=link}
{kind=link}
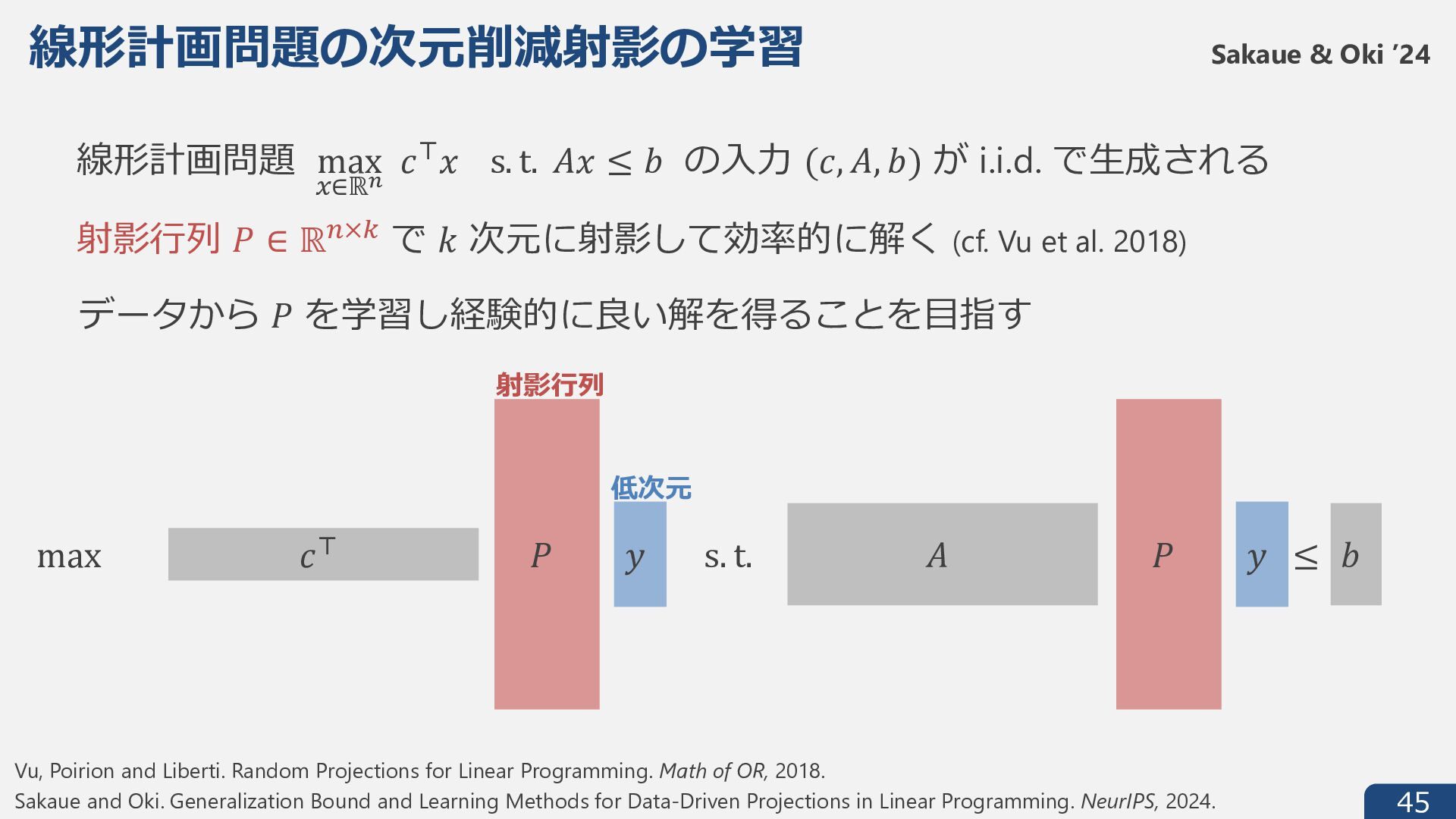{kind=link}
{kind=link}
{kind=link}
{kind=link}