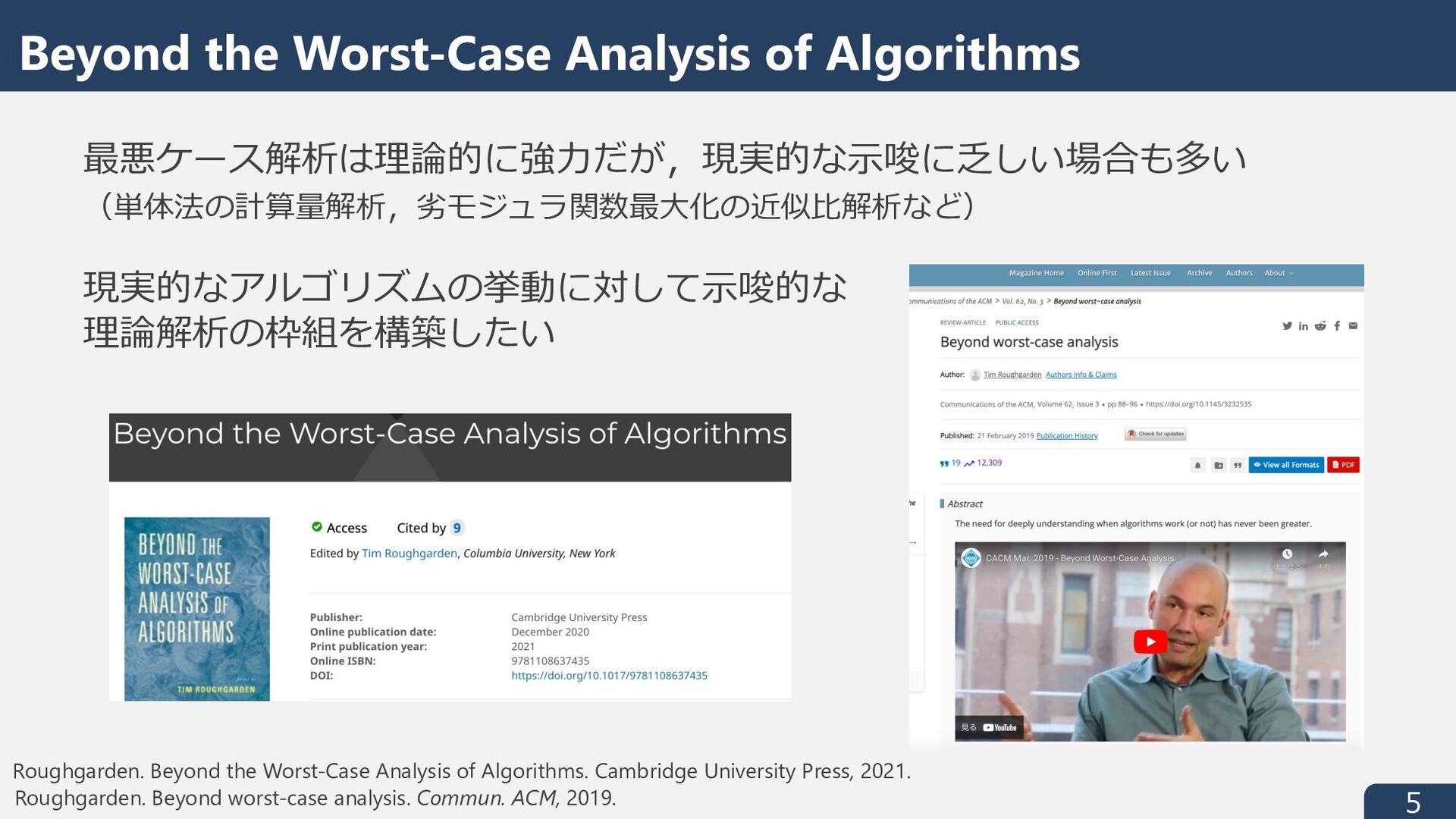
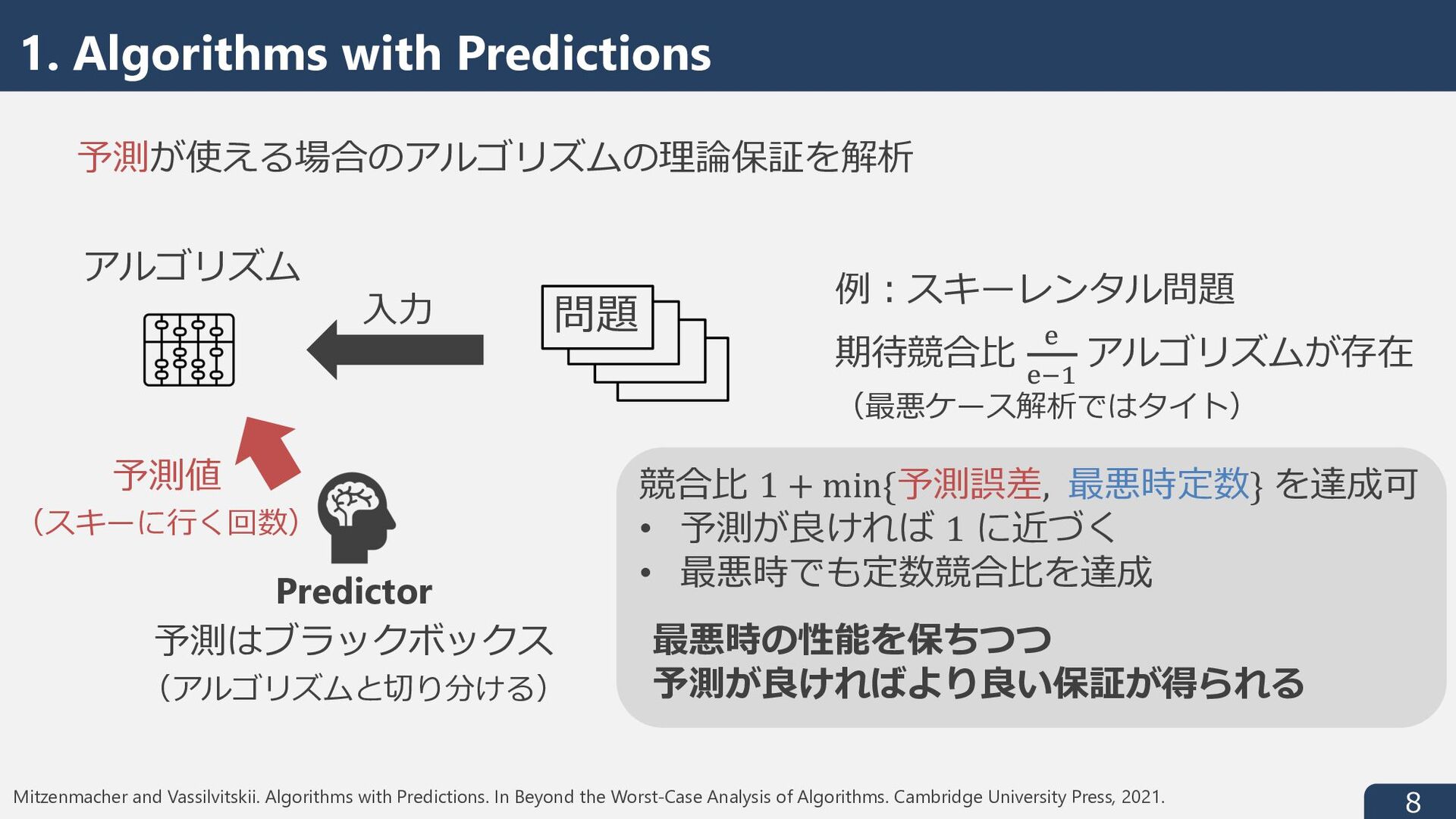
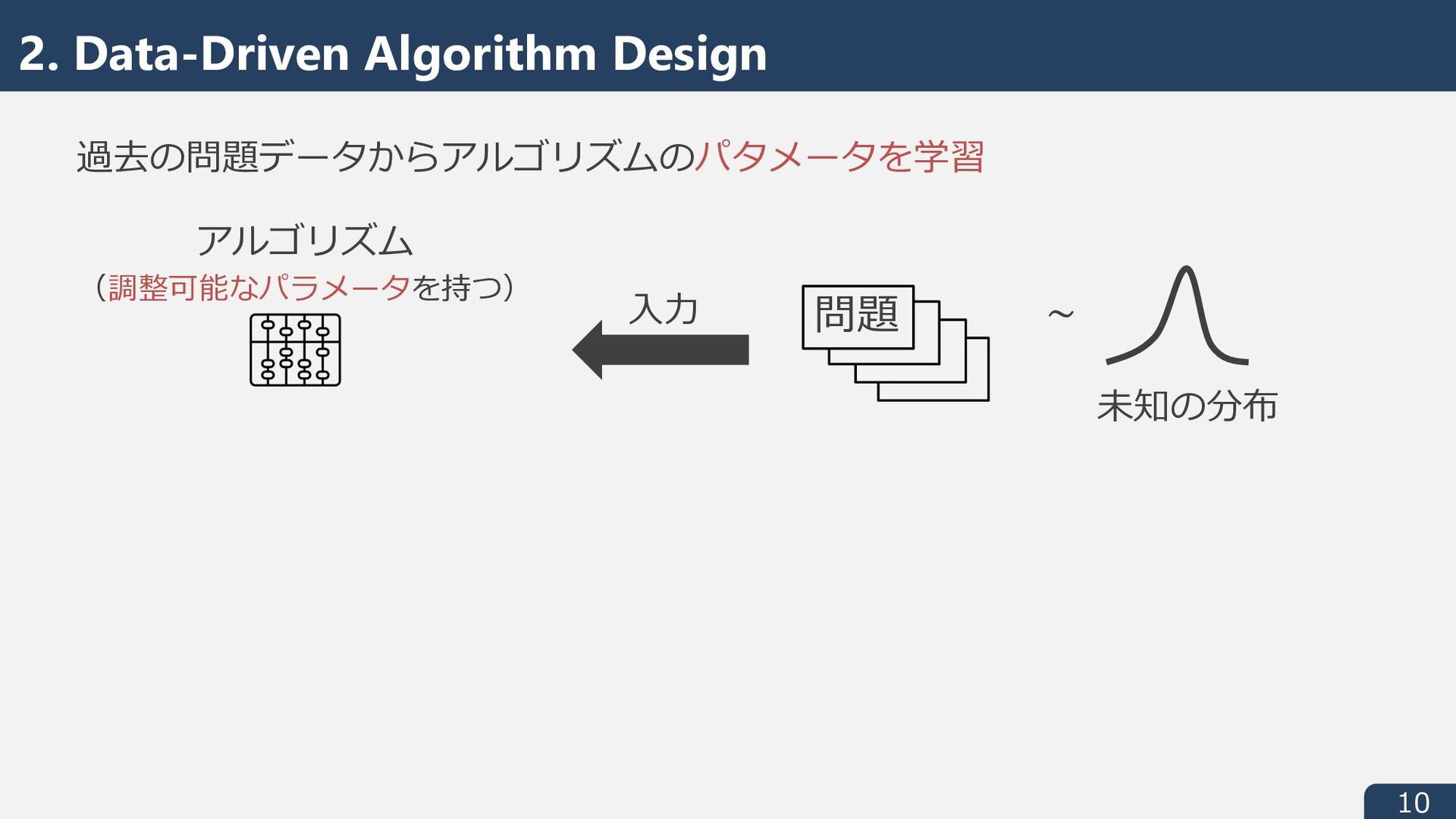
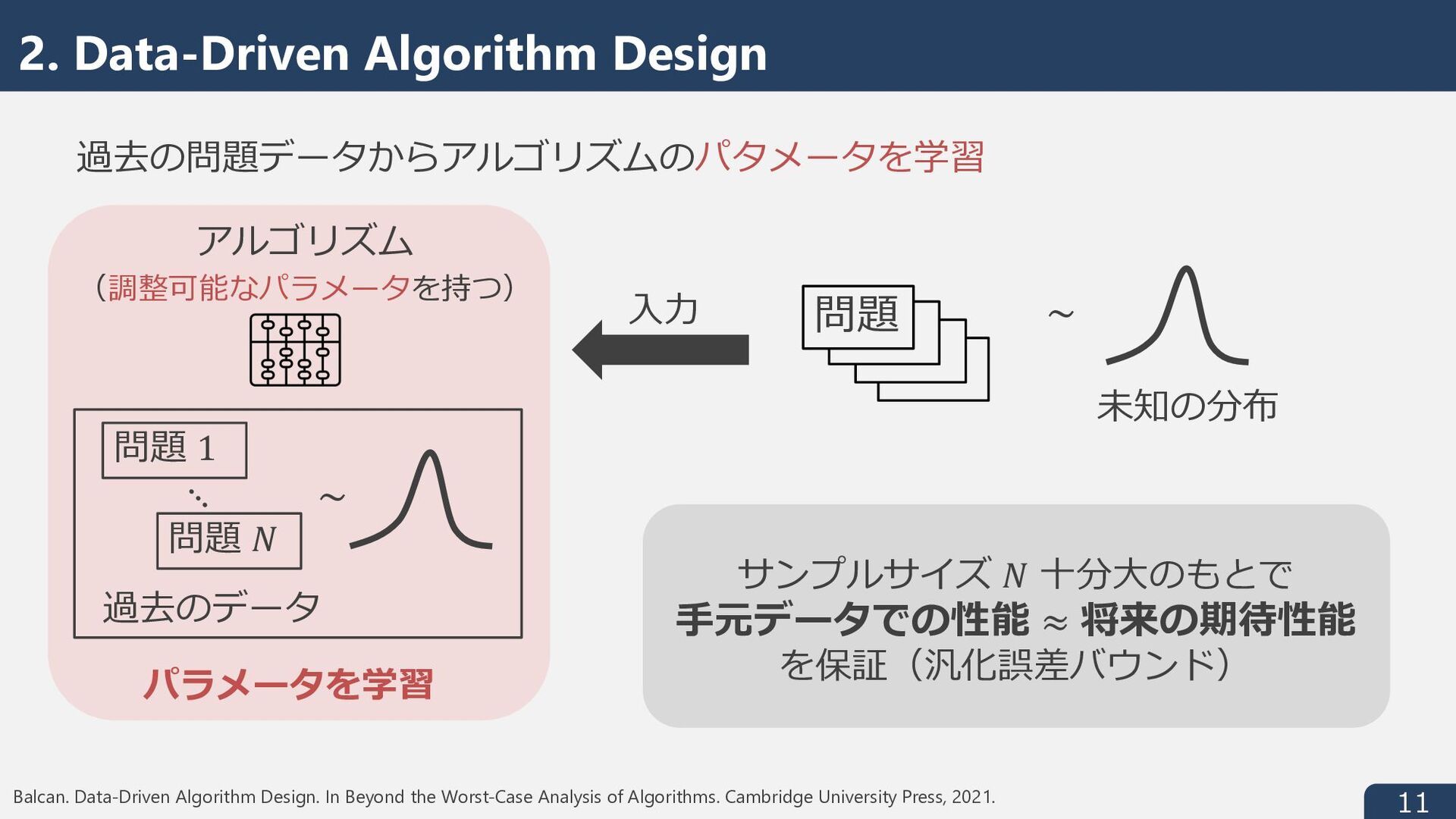
Mitzenmacher and Vassilvitskii. Algorithms with Predictions. In Beyond the Worst-Case Analysis of Algorithms. Cambridge University Press, 2021. Balcan. Data-Driven Algorithm Design. In Beyond the Worst-Case Analysis of Algorithms. Cambridge University Press, 2021. Beyond the Worst-Case Analysis of Algorithms さまざまな Beyond the Worst-Case の⽅針の中で 機械学習・学習理論寄りの2つの⽅針について紹介
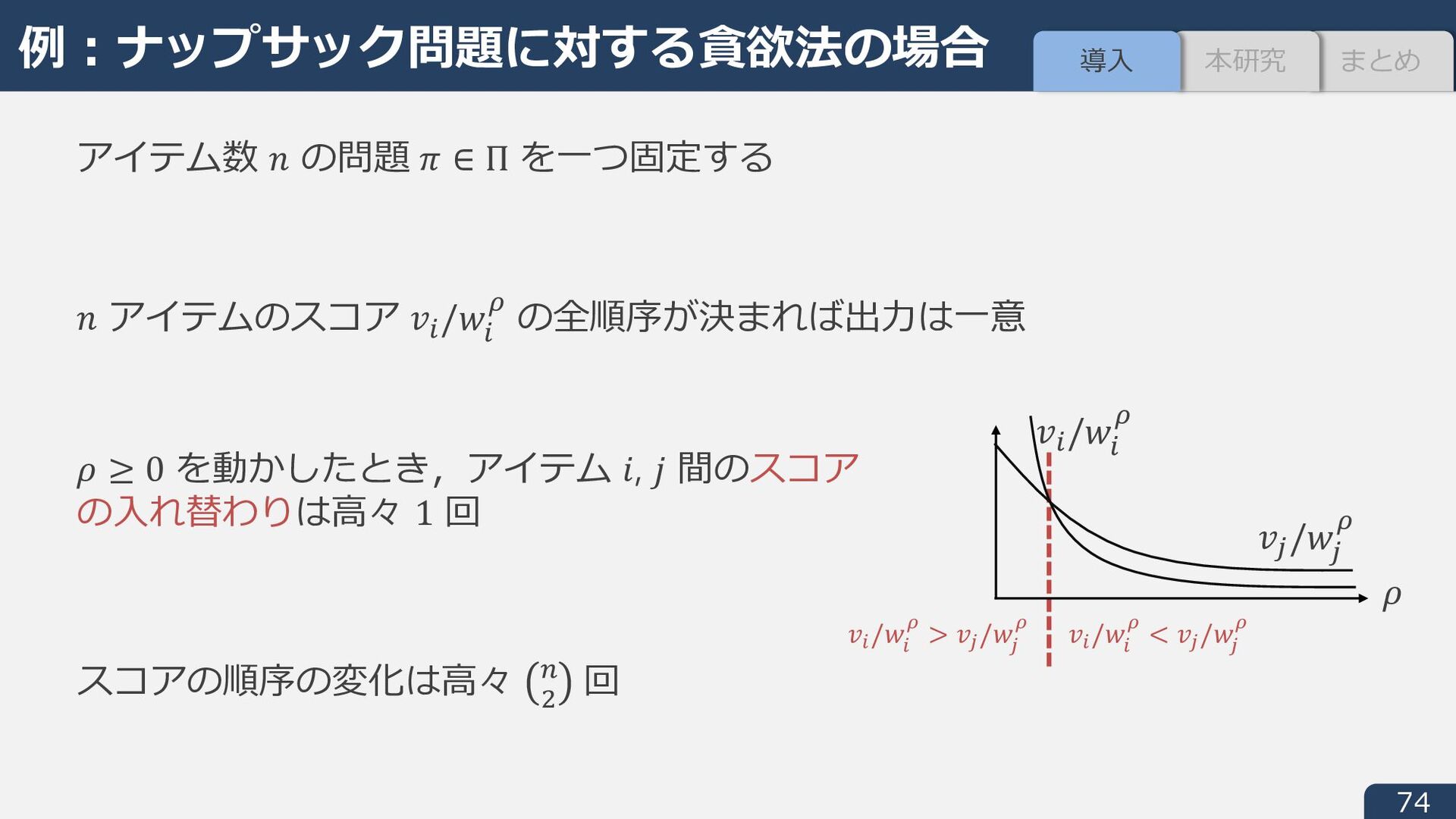
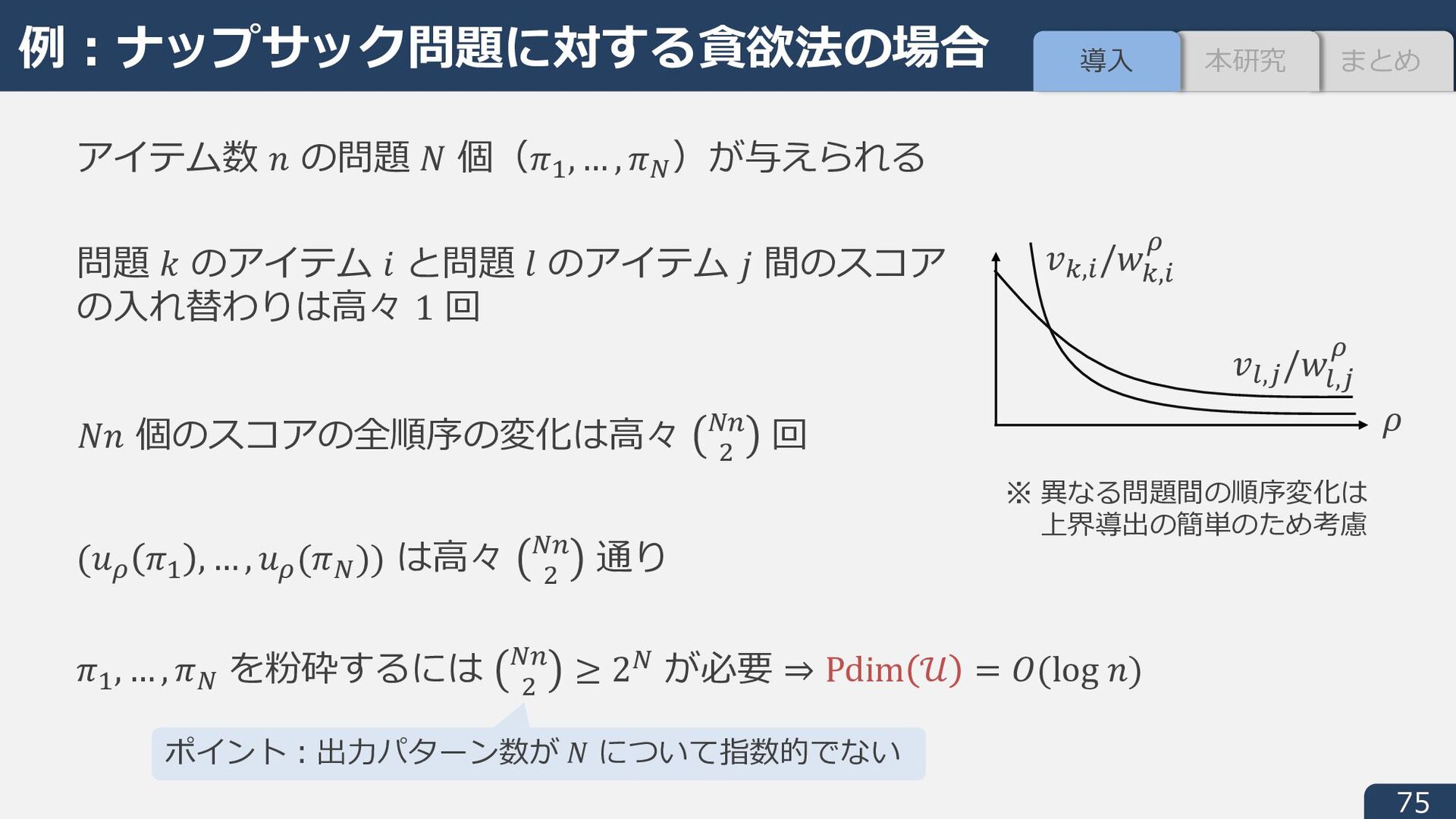
Oki. Discrete-convex-analysis-based framework for warm-starting algorithms with predictions, NeurIPS, 2022. 2. 最適解の⾮⼀意性を考慮した L 凸関数最⼩化のウォームスタート学習 - S and Oki. Rethinking warm-starts with predictions: Learning predictions close to sets of optimal solutions for faster L-/L♮ -convex function minimization, ICML, 2023. 3. M 凸関数最⼩化のウォームスタート学習 - Oki and S. Faster discrete convex function minimization with predictions: The M-convex case, NeurIPS, 2023. Data-Driven Algorithm Design 1. 貪欲・A* 探索におけるヒューリスティック関数の学習の汎化誤差解析 - S and Oki. Sample complexity of learning heuristic functions for greedy-best-first and A* search, NeurIPS, 2022. 2. 低ランク近似におけるスケッチング⾏列の学習の汎化誤差解析 - S and Oki. Improved generalization bound and learning of sparsity patterns for data-driven low-rank approximation, AISTATS, 2023. 3. 線形計画法における次元削減射影⾏列の学習の汎化誤差解析と学習⽅法 - S and Oki. Generalization Bound and Learning Methods for Data-Driven Projections in Linear Programming, arXiv:2309.00203, 2023. 本⽇の発表内容
S and Oki. Discrete-convex-analysis-based framework for warm-starting algorithms with predictions, NeurIPS, 2022. 2. 最適解の⾮⼀意性を考慮した L 凸関数最⼩化のウォームスタート学習 - S and Oki. Rethinking warm-starts with predictions: Learning predictions close to sets of optimal solutions for faster L-/L♮ -convex function minimization, ICML, 2023. 3. M 凸関数最⼩化のウォームスタート学習 - Oki and S. Faster discrete convex function minimization with predictions: The M-convex case, NeurIPS, 2023. Data-Driven Algorithm Design 1. 貪欲・A* 探索におけるヒューリスティック関数の学習の汎化誤差解析 - S and Oki. Sample complexity of learning heuristic functions for greedy-best-first and A* search, NeurIPS, 2022. 2. 低ランク近似におけるスケッチング⾏列の学習の汎化誤差解析 - S and Oki. Improved generalization bound and learning of sparsity patterns for data-driven low-rank approximation, AISTATS, 2023. 3. 線形計画法における次元削減射影⾏列の学習の汎化誤差解析と学習⽅法 - S and Oki. Generalization Bound and Learning Methods for Data-Driven Projections in Linear Programming, arXiv:2309.00203, 2023. 本⽇の発表内容
i: ℤ5 → ℝ ∪ {+∞} が L 凸 ⇔ 以下を満たす︓ 劣モジュラ性.i 9 + i n ≥ i 9 ∨ n + i(9 ∧ n) Q ⽅向線形性.∃q ∈ ℝ,i 9 + Q = i 9 + q 集合 M ⊆ ℤ5 が L 凸 ⇔ 以下を満たす︓ 9, n ∈ M ⇒ 9 ∨ n, 9 ∧ n ∈ M and 9 ∈ M ⇒ 9 ± Q ∈ M Murota. Discrete Convex Analysis. Discrete Mathematics and Applications. SIAM, 2003. Murota ’03 L 凸関数・L 凸集合 まとめ 本研究 導⼊ 概要
i: ℤ5 → ℝ ∪ {+∞} が L 凸 ⇔ 以下を満たす︓ 劣モジュラ性.i 9 + i n ≥ i 9 ∨ n + i(9 ∧ n) Q ⽅向線形性.∃q ∈ ℝ,i 9 + Q = i 9 + q 重要な性質 • L 凸 + L 凸 = L 凸 • L が L 凸関数 ⇒ dom L ≔ * ∈ ℤ 4 L * < +∞},及び argmin L は L 凸集合 • L 凸集合の不等式系表現︓& = * ∈ ℤ 4 | *$ − *! ≤ [!$ ∀], ^ ∈ _; ] ≠ ^ for some [!$ ∈ ℤ ∪ {+∞} • ℤ! を ℝ! に置き換えると P の凸包 集合 M ⊆ ℤ5 が L 凸 ⇔ 以下を満たす︓ 9, n ∈ M ⇒ 9 ∨ n, 9 ∧ n ∈ M and 9 ∈ M ⇒ 9 ± Q ∈ M Murota. Discrete Convex Analysis. Discrete Mathematics and Applications. SIAM, 2003. Murota ’03 L 凸関数・L 凸集合 まとめ 本研究 導⼊ 概要
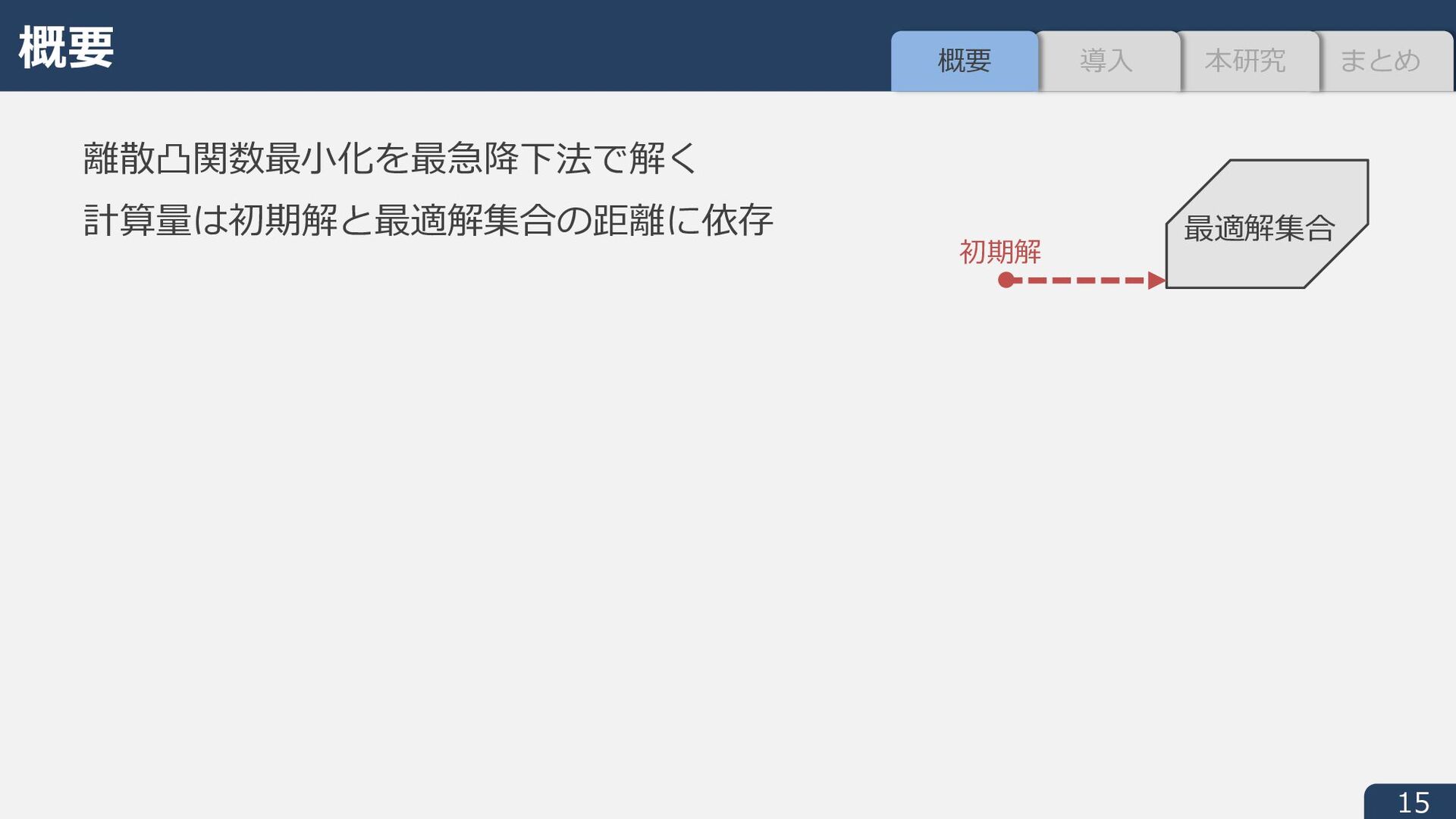
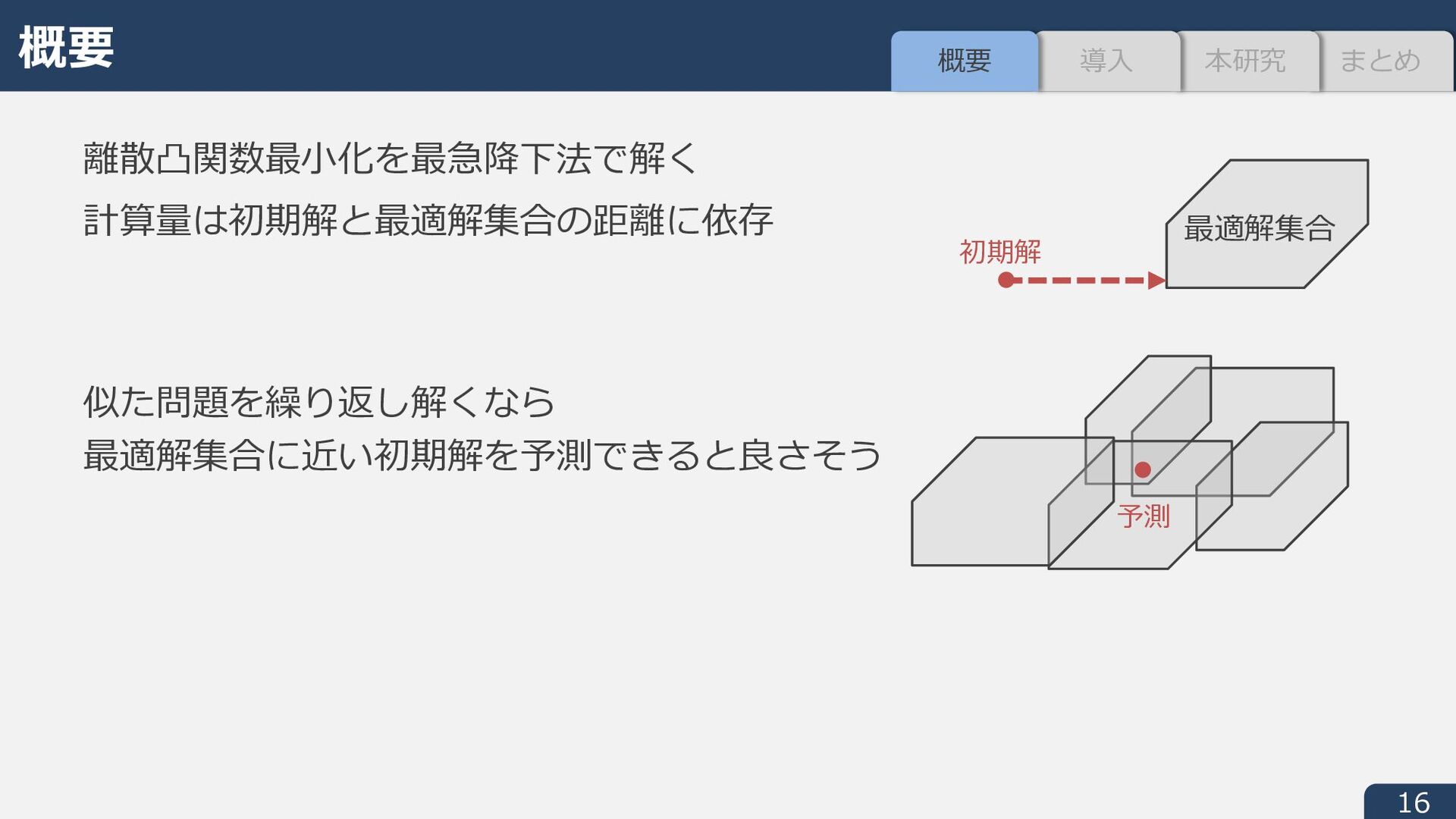
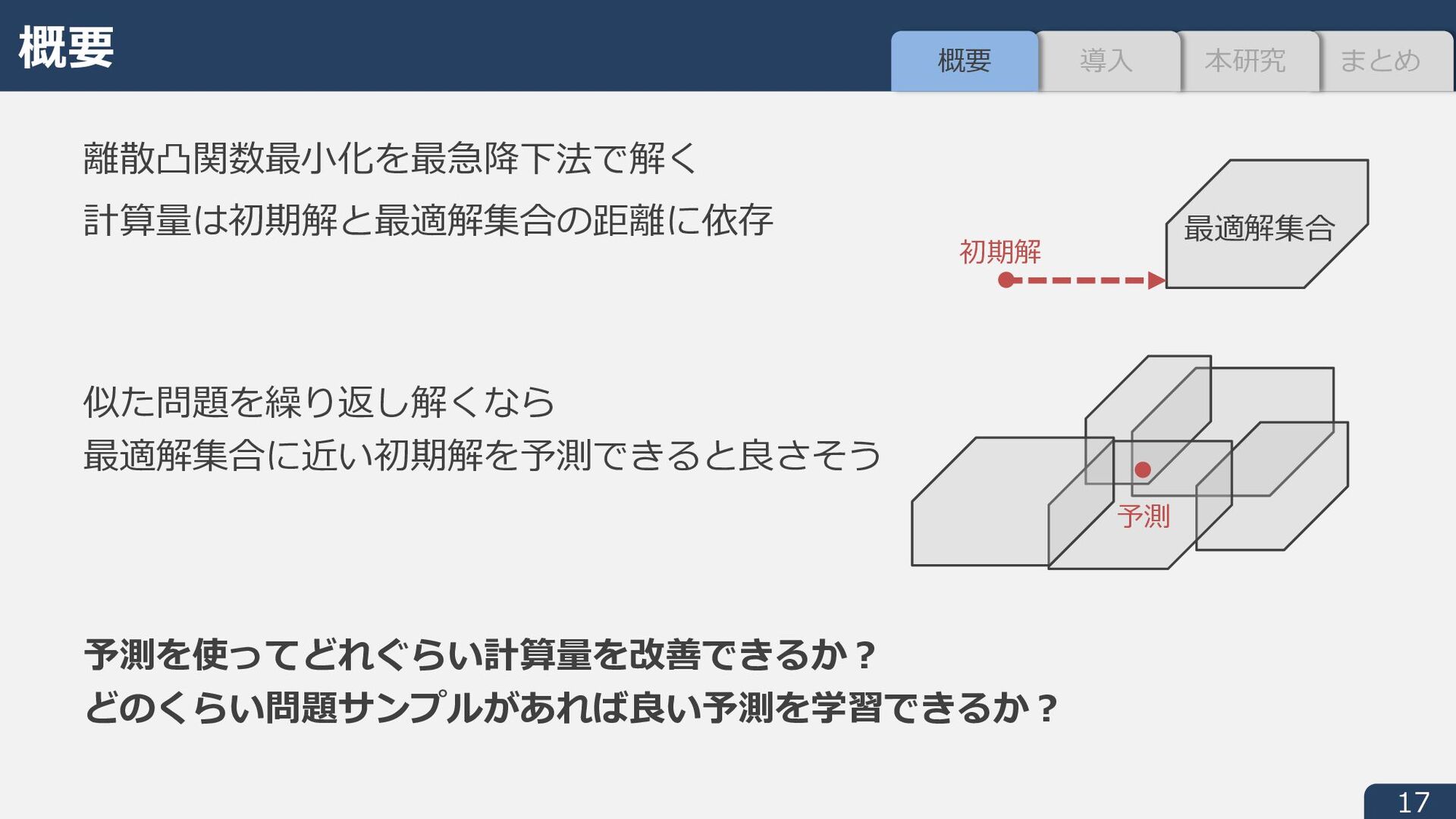
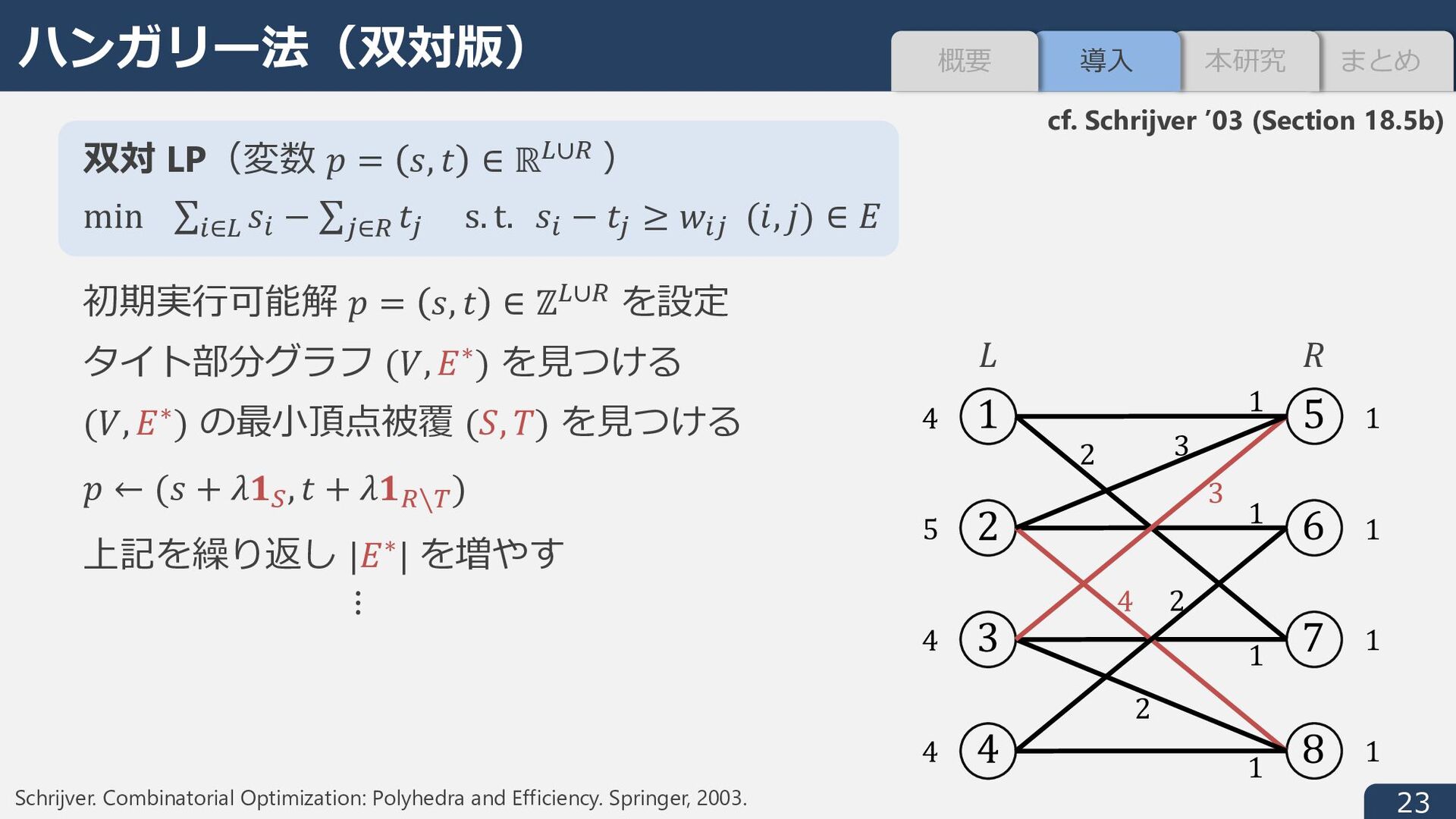
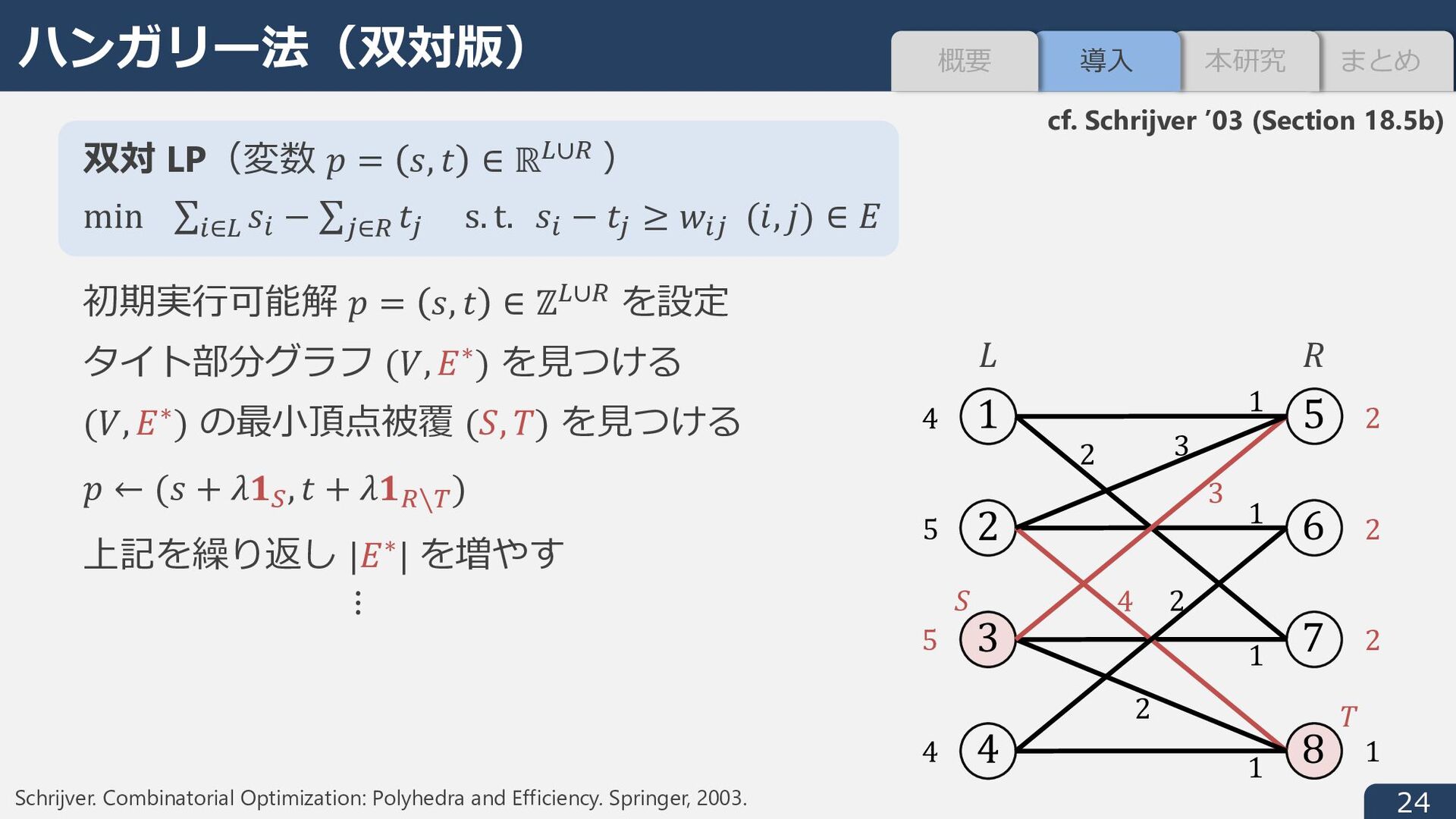
± -射影 y n を以下で定義︓ y n ∈ argmin n − ̂ 9 I ± n ∈ conv(dom i) w の連続版 ̅ w: ℝ5 → ℝ を定義︓ ℓI ± -射影の時間を NCDCE, 最急降下⽅向の計算時間 (Step 3) を NFGH とすると 総計算量 S(NCDCE + NFGH × ̅ w ̂ 9 ) (任意の * ∗ ∈ argmin L に対し ̅ o ̂ * ≤ o ̂ * ≤ * ∗ − ̂ * ) ± ≤ 2 * ∗ − ̂ * )) 1. 9∘ = y n ∈ dom i が成⽴(射影の四捨五⼊は実⾏可能解) 2. 9∘ を初期点とする最急降下法の反復回数は⾼々 2 ̅ w ̂ 9 + 2 ̅ w n ≔ min 9∗ − n I ± 9∗ ∈ conv(argmin i) (≤ w n ) まとめ 本研究 導⼊ 概要
I ± + 1 ≤ 9∗ − ̂ 9 I ± + ̂ 9 − y n I ± + 1 ≤ 2 ̅ w ̂ 9 + 1 39 (Murota and Shioura ’14) より反復回数は w 9∘ + 1. 整数点上では w = ̅ w だから w 9∘ = ̅ w 9∘ ≤ 9∗ − 9∘ I ± .右辺を上から抑える︓ w 9∘ ≤ 2 ̅ w ̂ 9 + 1 を⽰す(9∘ = y n , y n ∈ argmin n − ̂ 9 I ± n ∈ conv(dom i) ). 9∗ ∈ conv(argmin i) を ̅ w ̂ 9 = 9∗ − ̂ 9 I ± を達成するように定義. * ∗ − ̂ * ) ± = ̅ o ̂ * conv dom L ⊇ conv(argmin L) より ̂ * − s l ) ± ≤ ̂ * − * ∗ ) ± = ̅ o ̂ * * ∘ = s l 三⾓不等式 2の証明 まとめ 本研究 導⼊ 概要
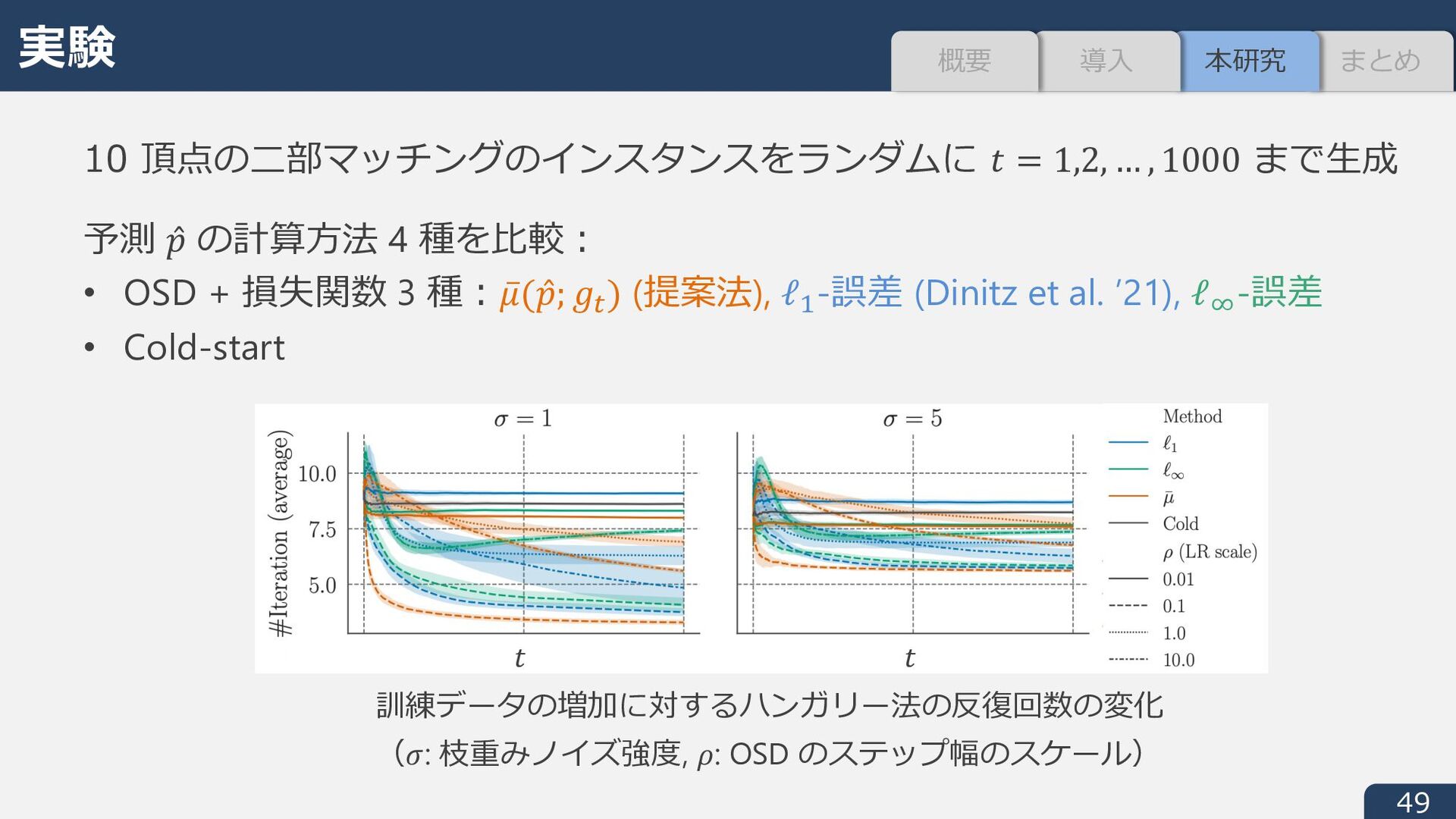
̅ w ̂ 9; i に⽐例 ̅ w ̂ 9; i は ̂ 9 ∈ ℝ5 について凸関数であり,オンライン凸最⼩化によって 観測された i#, i;, … の最適解集合に近くなるように学習可能 M 凸関数最⼩化についても類似の結果が得られる (Oki and S ’23) (だたしタイブレイクの扱いについては未解決) Oki and S. Faster discrete convex function minimization with predictions: The M-convex case, NeurIPS, 2023. Part 1 まとめ まとめ 本研究 導⼊ 概要 今後の展開 • L 凸,M 凸以外の問題への適⽤(特に⼀般マッチング) • 平均計算時間以外の指標(CVaR, ⼀定時間内に解ける問題数, など) • 予測モデルの学習(新たなインスタンスに対し適切な予測を⽣成)
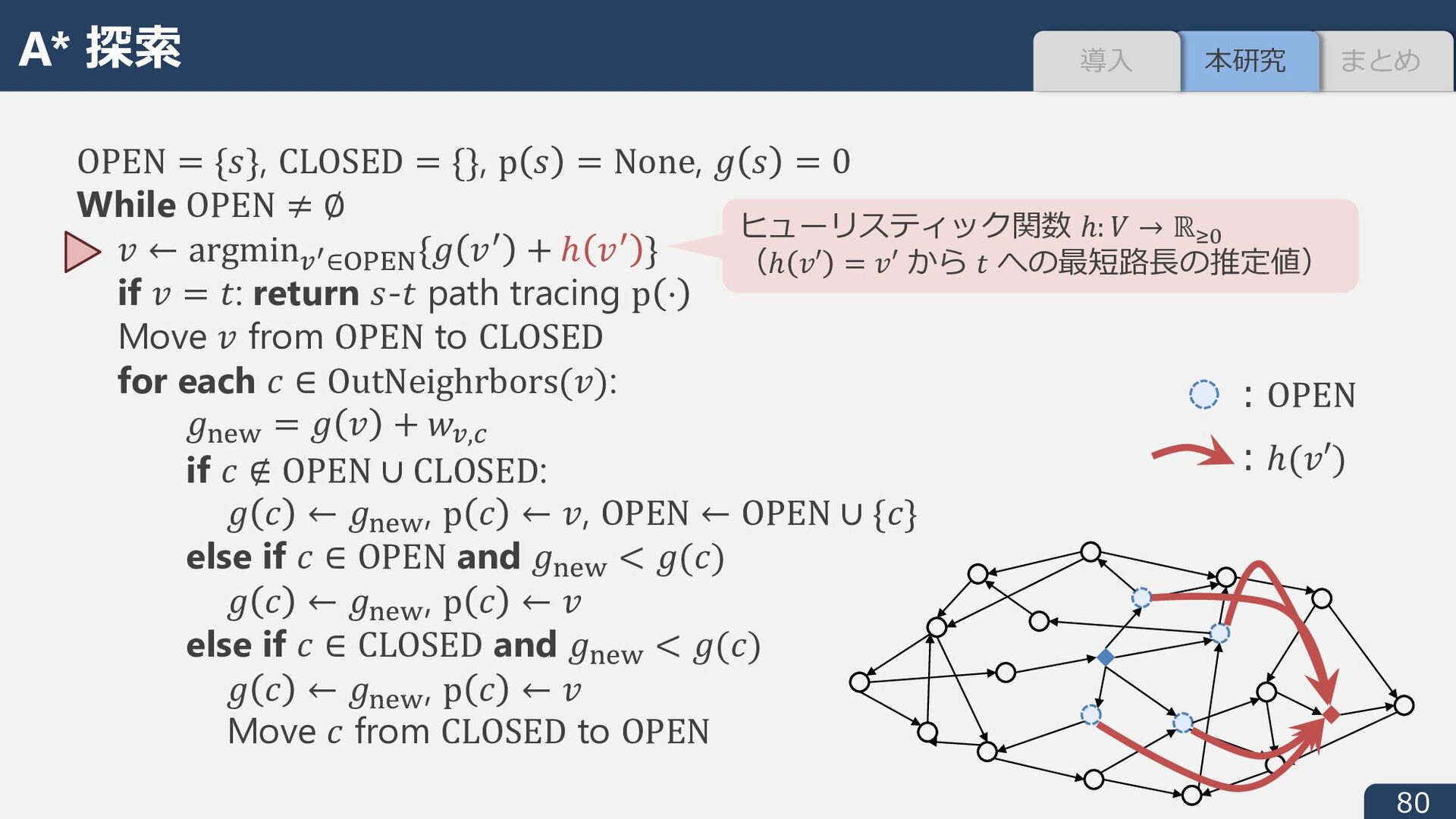
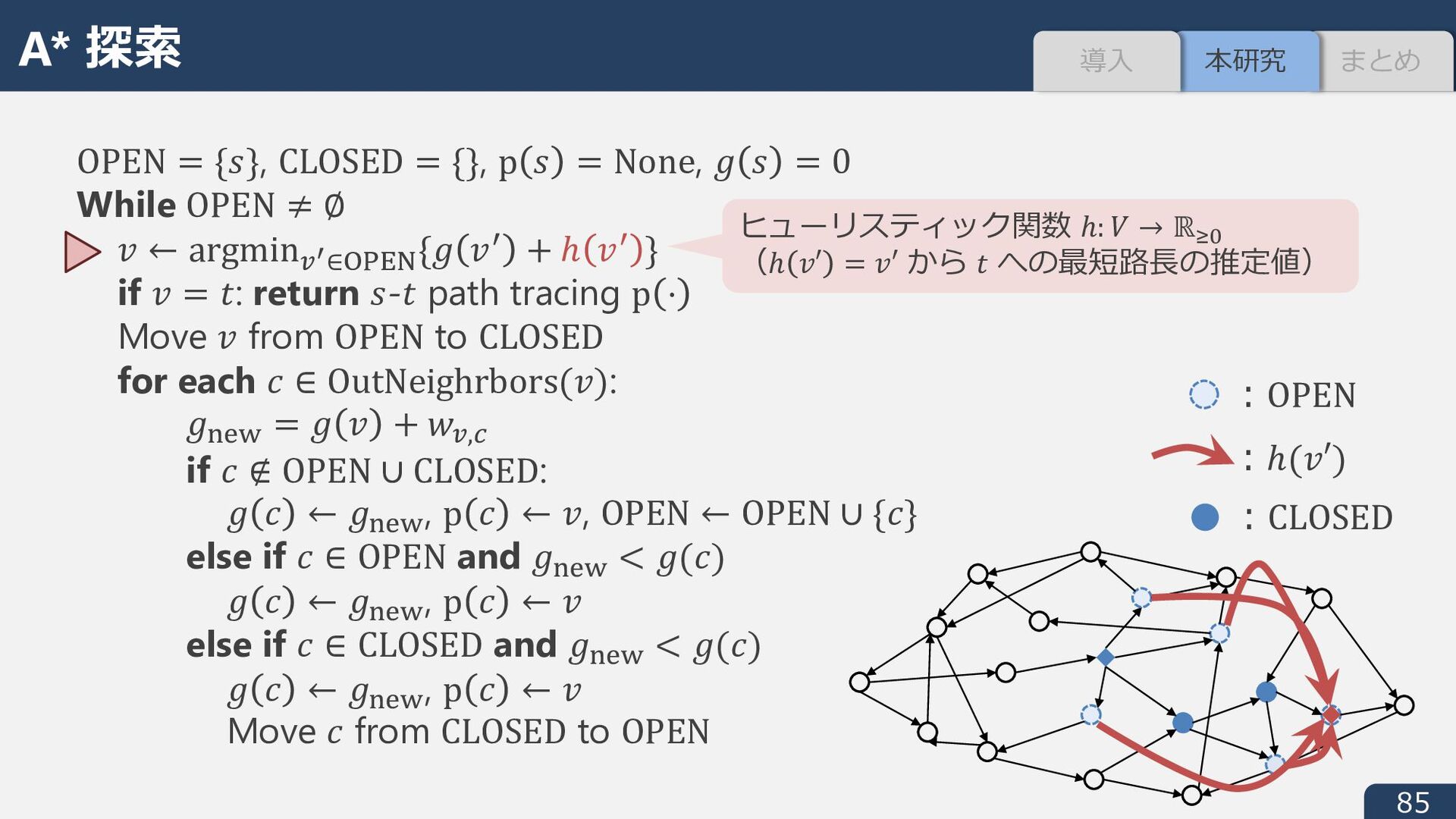
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
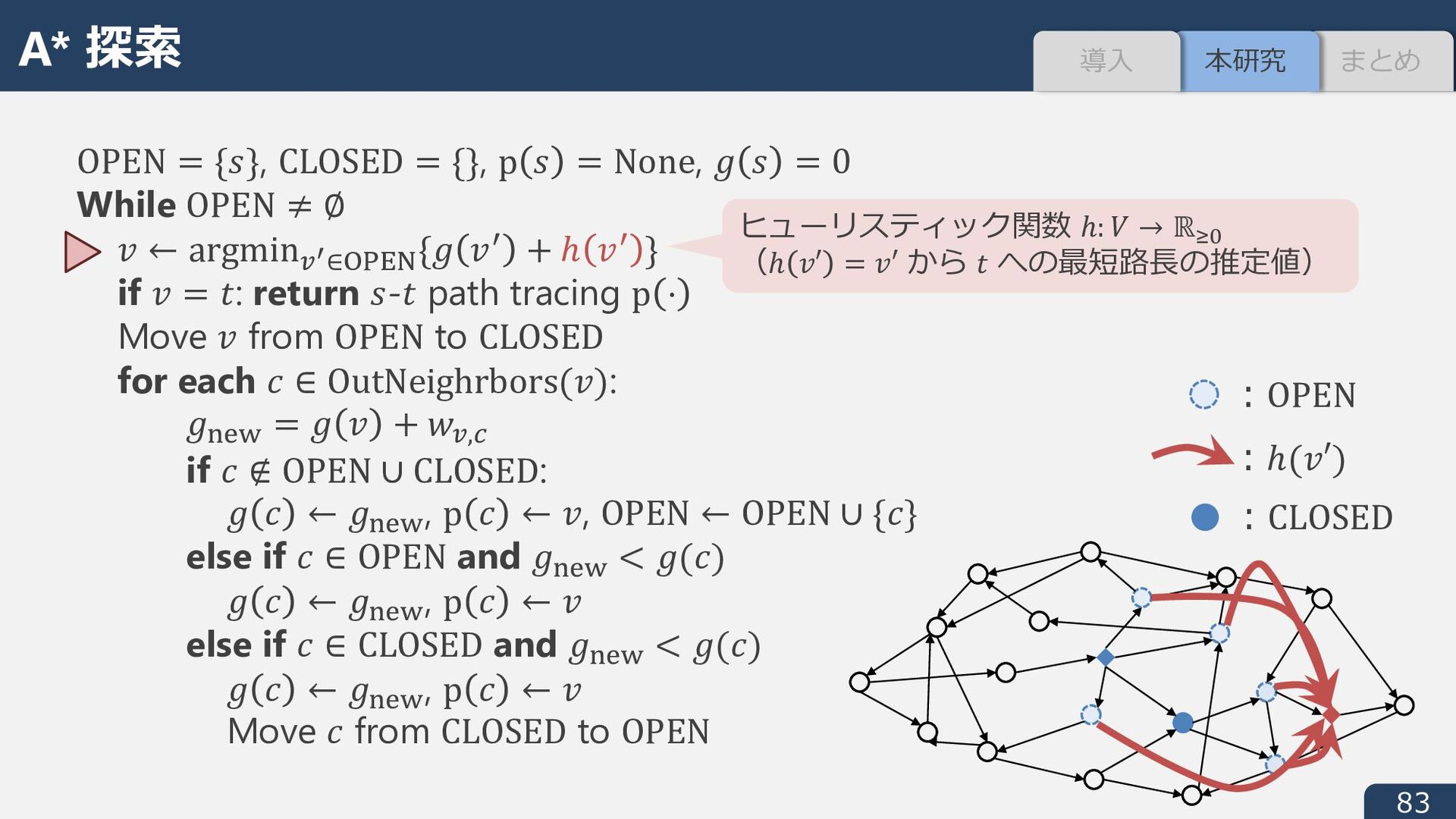
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
None, i : = 0 While OPEN ≠ ∅ J ← argmin.* ∈åçéè{i Jê + ℎ Jê } if J = ;: return :-; path tracing p ⋅ Move J from OPEN to CLOSED for each ∏ ∈ OutNeighrbors(J): iD!ë = i J + 1.,í if ∏ ∉ OPEN ∪ CLOSED: i ∏ ← iD!ë , p ∏ ← J, OPEN ← OPEN ∪ {∏} else if ∏ ∈ OPEN and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J else if ∏ ∈ CLOSED and iD!ë < i(∏) i ∏ ← iD!ë , p ∏ ← J Move ∏ from CLOSED to OPEN ︓OPEN ︓ℎ(J′) ︓CLOSED ヒューリスティック関数 ℎ: _ → ℝBC (ℎ é′ = é′ から / への最短路⻑の推定値) A* 探索 まとめ 本研究 導⼊
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}