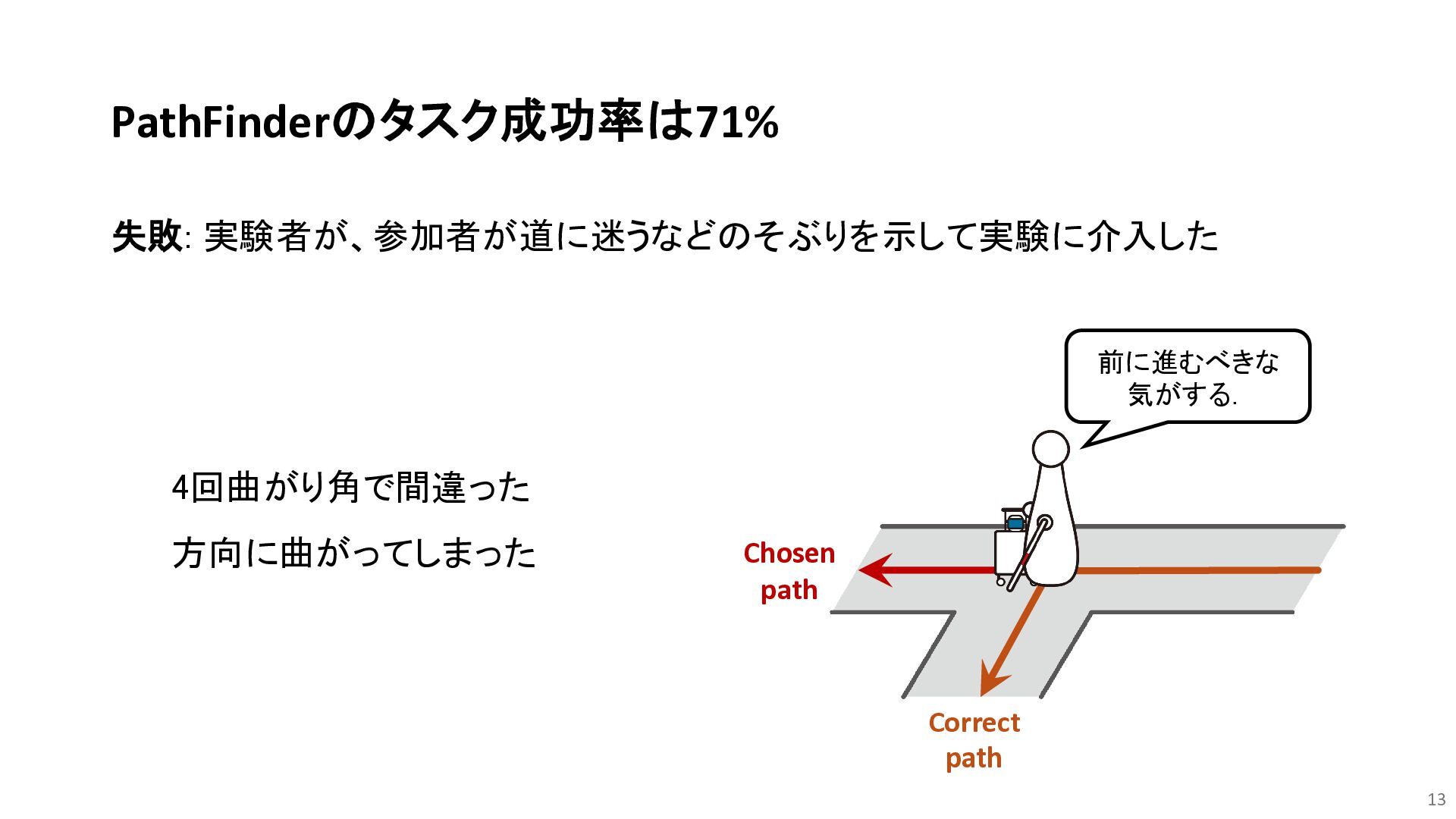
Hwang et al., “Towards Robotic Companions: Understanding Handler-Guide Dog Interactions for Informed Guide Dog Robot Design,” CHI2024 Go straight. Turn right. Can go right and forward! There is a sign saying...
al., “Graph-based topological exploration planning in large-scale 3d environment” [2] Kuribayashi et al., “Textual and Directional Sign Recognition Algorithm for People with Visual Impairment by Linking Texts and Arrows” 10 Video Video
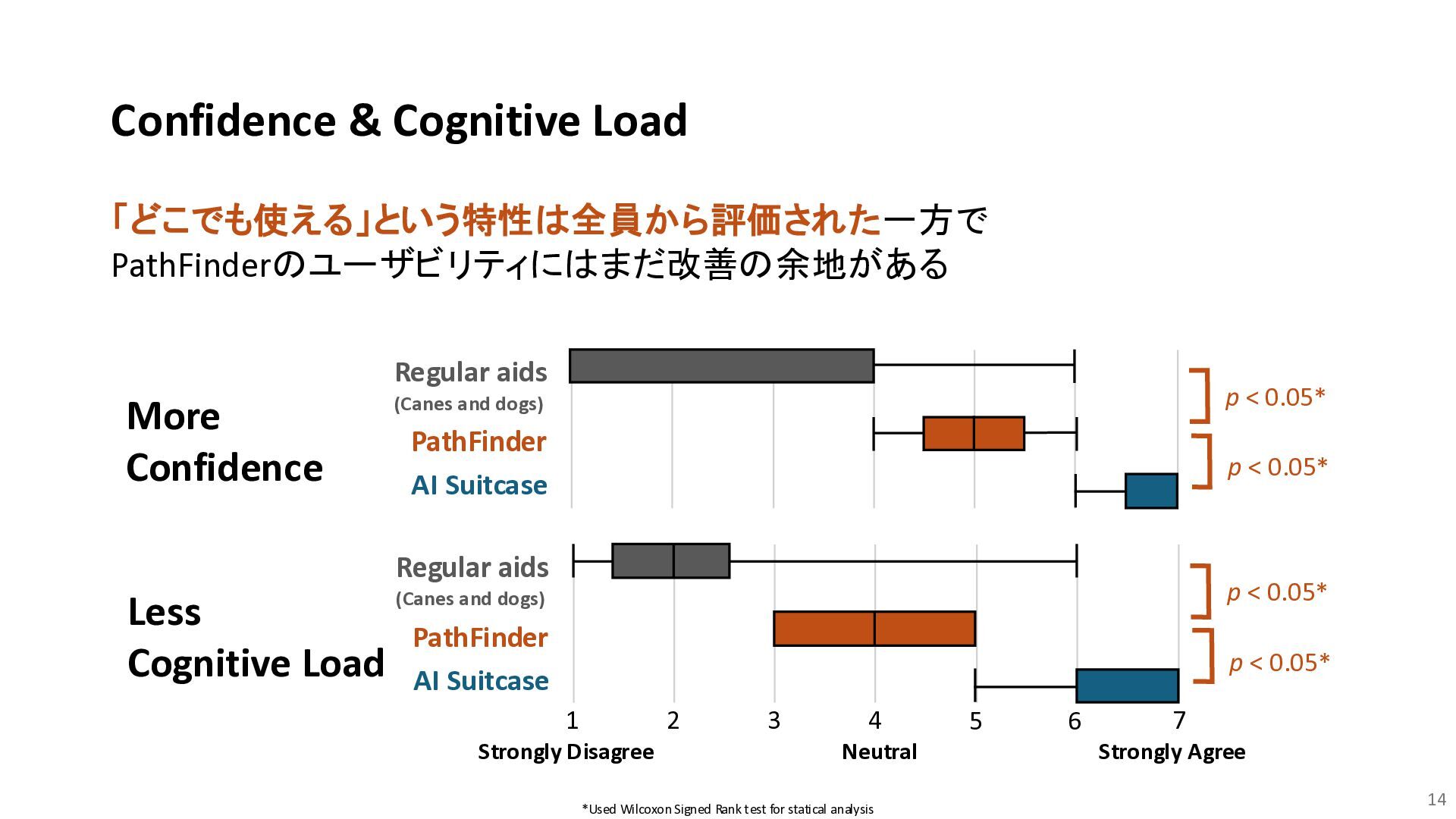
and dogs) PathFinder p < 0.05* AI Suitcase p < 0.05* *Used Wilcoxon Signed Rank test for statical analysis 「どこでも使える」という特性は全員から評価された一方で PathFinderのユーザビリティにはまだ改善の余地がある Less Cognitive Load 1 2 3 4 5 6 7 Regular aids (Canes and dogs) PathFinder Strongly Agree Strongly Disagree p < 0.05* AI Suitcase p < 0.05* Neutral
Blind People Masaki Kuribayashi*1, Kohei Uehara*2, Allan Wang2, Daisuke Sato3, Renato Ribero2, Simon Chu3, Shigeo Morishima1 *Equal Contribution 1Waseda University, 2Miraikan - The National Museum of Emerging Science and Innovation 3Canegie Mellon University *RA-L paper presented at ICRA2026
目的シナリオ 実地で説明 17 [1] Anderson et al, “Vision-and-language Navigation: Interpreting Visually-grounded Navigation Instructions in Real Environments,” CVPR2018
left. And then turn left. There will be a hall connecting Scott Hall and this is... Wait, this is... Newell Simon Hall.[…] If you turn right, there is a small... You can cross it, but it's probably like one to two meters opening there. […] And then cross that hall. And then I think you can just go straight downstairs, probably like 10 steps, and then you will be there, the cafe.” Memory-based Instructions 92.17 Words (x1.15) 33.76% Errors (x4.19) 30.17% Alt. Routes “Go a little way down this road, then continue straight after turning left. Along the way, you will pass through a path lined with glass on both sides. After that, turn right at the dead end and follow the road, then turn right again before the stairs. Continue straight to reach your destination.” Observation-based Instructions 80.35 Words 8.06% Errors
Score (↑) NavGPT[1] 0% 5% NaVid[2] 0% 2% Proposed 8% 44% [3] Chi et al, “Just Ask: An Interactive Learning Framework for Vision and Language Navigation,” AAAI2020 Correct path 確かに ここは右では ないでしょうか Future Work: 相互補助的な意思決定 • モデルがユーザの判断を確認 • ユーザがモデルを補助[1] VLNモデル評価結果 (当時のVLNモデルが)記憶に基づいた 経路説明に対処するのは困難 [1] Zhou et al, “Navgpt: Explicit Reasoning in Vision-and-language Navigation with Large Language Models,” AAAI2024 [2] Zhang et al,“NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation,” RSS2024
Masaki Kuribayashi1,2, Kohei Uehara2, Allan Wang2, Shigeo Morishima1, Chieko Asakawa2 1 : Waseda University 2: Miraikan - The National Museum of Emerging Science and Innovation 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![人の判断力とセンシングの相互活用が必要である 7 課題:地図なしという設定ではシステムは方向の判断等ができない 盲導犬を模倣した協調インタラクション 盲導犬がモビリティを担い ユーザを指示・判断をする[1] 人の意思決定を支えるセンシング どんな情報をセンシングし、 どう伝えるべきなのか? [1]](https://files.speakerdeck.com/presentations/4659bf66131742f690b4037afe89dce5/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
![PathFinderの機能とインタフェース 看板の読み上げ[2] 後ろボタンを押すと看板に 書かれていることを読み上げる 交差点検出[1] 前ボタンを押して次の交差点まで行き, 左右のボタンで曲がる方向を指定する [1] Yang et](https://files.speakerdeck.com/presentations/4659bf66131742f690b4037afe89dce5/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存のVLNベンチマークをそのまま適用するのは困難 環境の違い 指示方法の違い 既存シナリオ[1] R2Rの豪邸など 目的シナリオ 公共空間 既存シナリオ[1] AMT等を用いた アノテーション](https://files.speakerdeck.com/presentations/4659bf66131742f690b4037afe89dce5/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5名の当事者を対象とした本実験を通じて有効性を確認 28 “[...] もうまさに欲しいのはこれなんですよ。なんか行きたいところにしか 行けないんじなくて[...] 、(このシステムを使って)例えばショッピングモー ルに今日は行って、なんか全部回ってみたいなみたいなとか、その時気 分で気ままに動けることが自由だと思ってるんです。” Video](https://files.speakerdeck.com/presentations/4659bf66131742f690b4037afe89dce5/slide_27.jpg){kind=link}
{kind=link}
{kind=link}