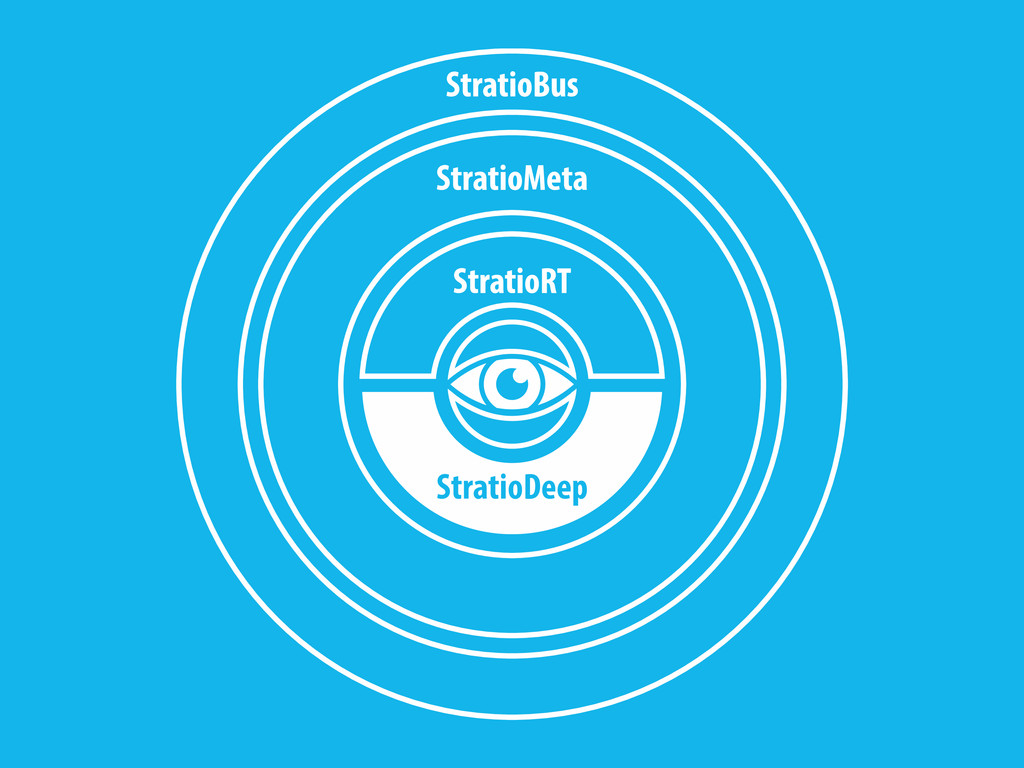
We present StratioDeep, an integration layer between the Spark distributed computing framework and Cassandra, a NoSQL distributed database.
Cassandra brings together the distributed system technologies from Dynamo and the data model from Google’s BigTable. Like Dynamo, Cassandra is eventually consistent and based on a P2P model without a single point of failure. Like BigTable, Cassandra provides a ColumnFamily-based data model richer than typical key/value systems. For these reasons, C* is one of the most popular NoSQL databases, but one of its handicaps is that it’s necessary to model the schema on the executed queries. This is because C* is oriented to search by key.
Integrating C* and Spark gives us a system that combines the best of both worlds.
Existing integrations between the two systems are not satisfactory: they basically provide an HDFS abstraction layer over C*. We believe this solution is not efficient because introduces an important overhead between the two systems.
The purpose of our work has been to provide an much lower-level integration that not only performs better, it also opens to Cassandra the possibility to solve a wide range of new use cases thanks to the powerfulness of the Spark distributed computing framework.
We’ve already deployed this solution in real applications with diverse clients: pattern detection, log mining, fraud detection, sentiment analysis and financial transaction analysis.
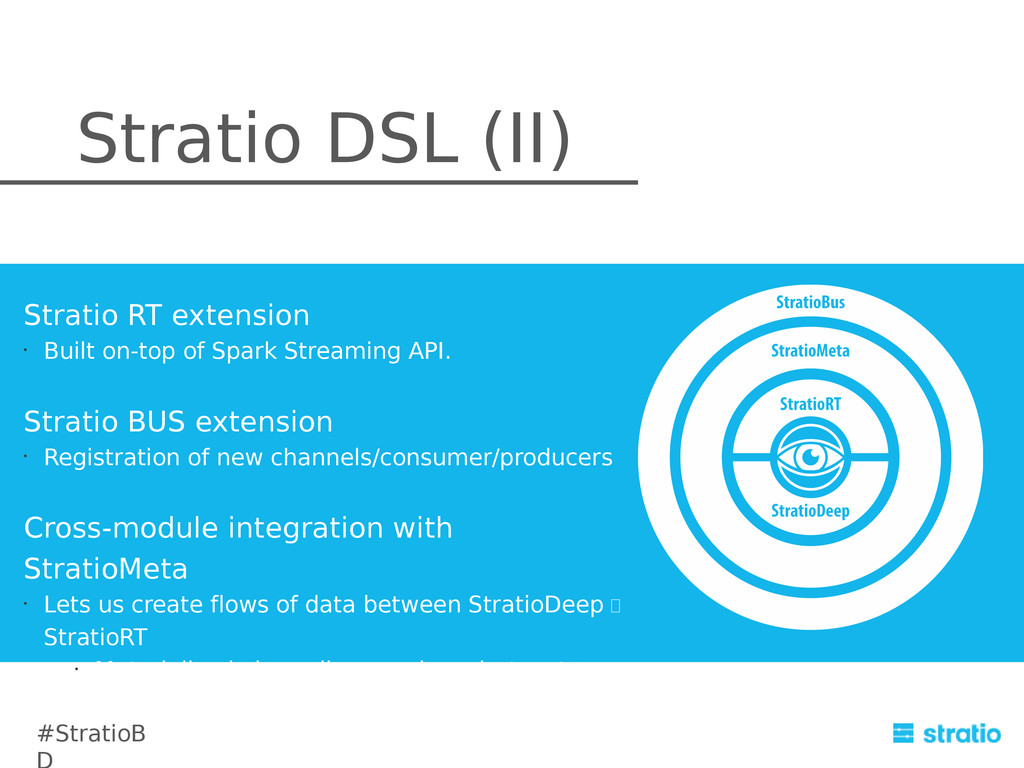
In addition this integration is the building block for our challenging and novel Lambda architecture completely based on Cassandra.
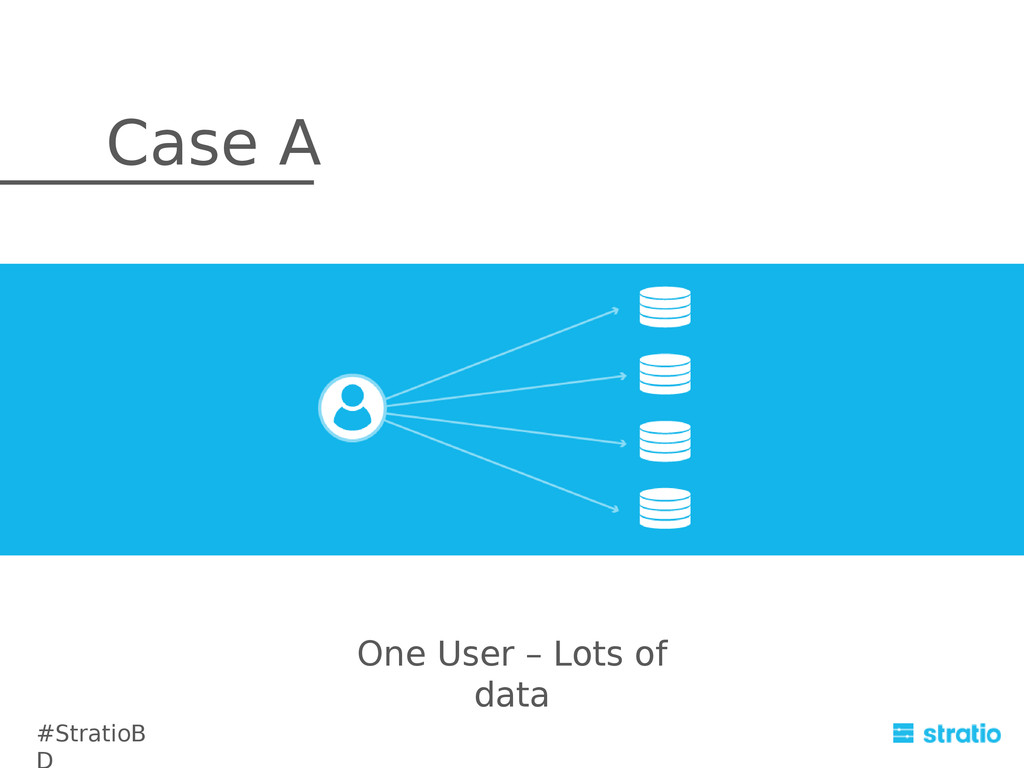
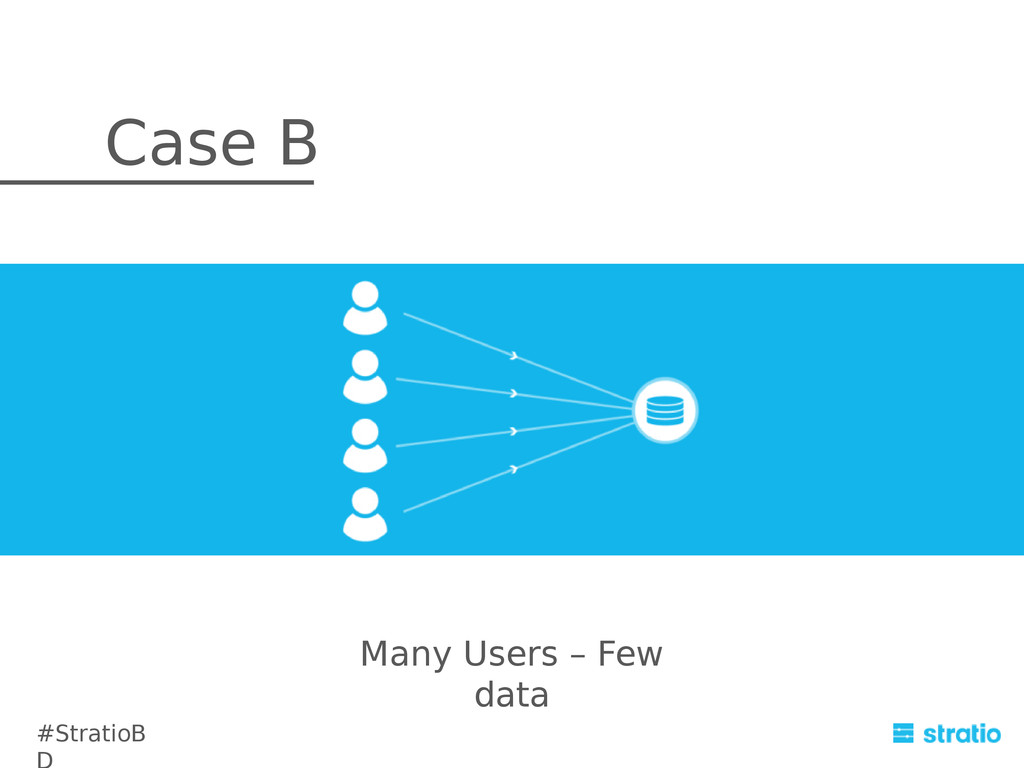
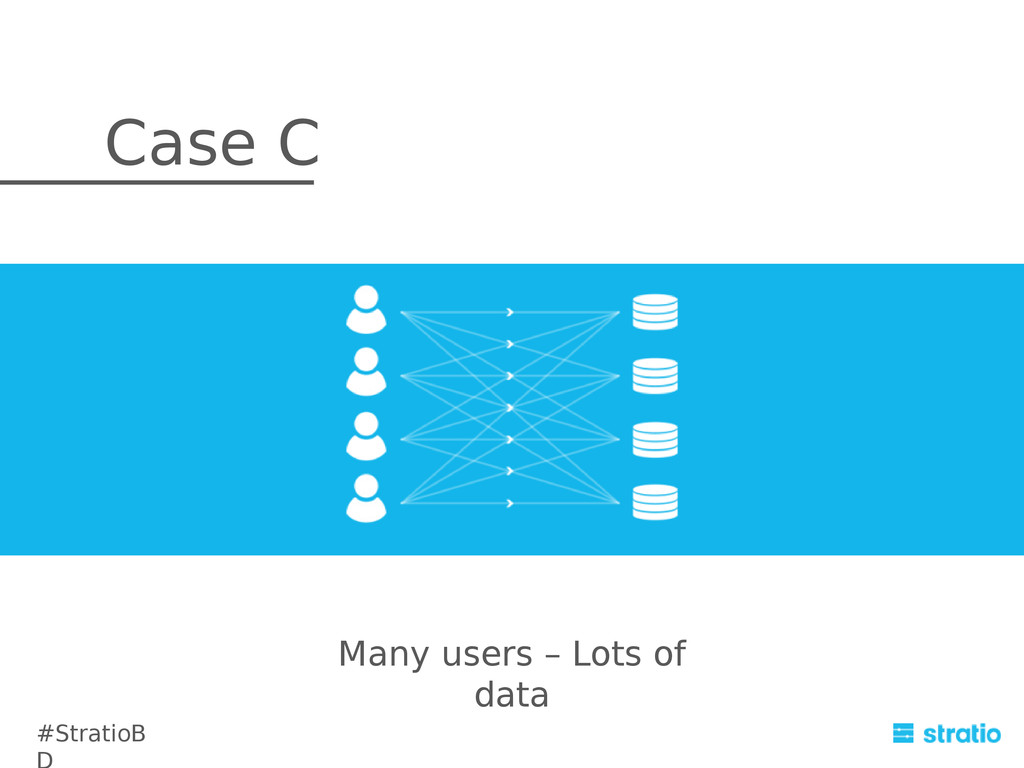
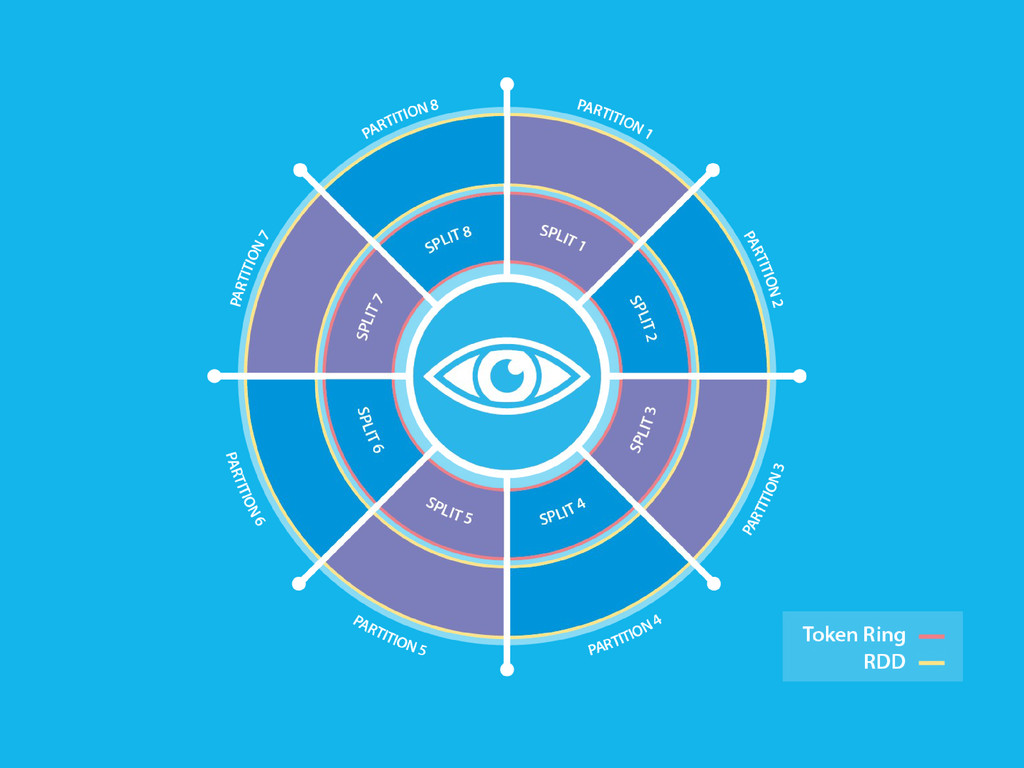
In order to complete the integration, we provide a seamless extension to the Cassandra Query Language: CQL is oriented to key-based search. As such, it is not a good choice to perform queries that move an huge amount of data. We’ve extended CQL in order to provide a user-friendly interface. This is a new approach for batch processing over C*. It consists in an abstraction layer that translates custom CQL queries to Spark jobs and delegates the complexity of distributing the query itself over the underlying cluster of commodity machines to Spark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}