We are well into multiple years of NoSQL databases, whether its MongoDB, or Cassandra or CouchDB, while still holding to patterns and practices that we learnt from Oracle and MySQL and PostgreSQL. Whatever your buzzword fancy – whether its “cloud” or “BigData”, we as Builders are building towers and mansions atop increasing layers of abstraction, regardless of your favorite programming language or framework of choice, and becoming both producers and consumers of exponential quantities of data.
Anyone stop to think about what the data model actually is? Do we still need one? Should we just throw things into MongoDB collections, and of course, there will be some piece of data analytics technology that will give you the best visualization of what’s actually in there? Do we even need to worry about many-to-many relationships, and integrity constraints, and domain models any more? What about the transactional vs. the conceptual vs. the logical use cases for the data? And of course, you need to have indexes on your database otherwise it won’t run fast – do people even understand why any more?
Unstructured, voluminous data does not obviate the need for a data structure. Whether you’d like to call it a schema or a model or just a napkin sketch of what’s actually behind the code – the art of data modeling is eroding away. Perhaps it is no longer needed, but one would beg to differ.
This talk is about provoking a return to when required reading from the likes of Aho or Horowitz was necessary before jumping into HeadFirst Java – which is the recommended CS college textbook at UC for a course on Data Structures.
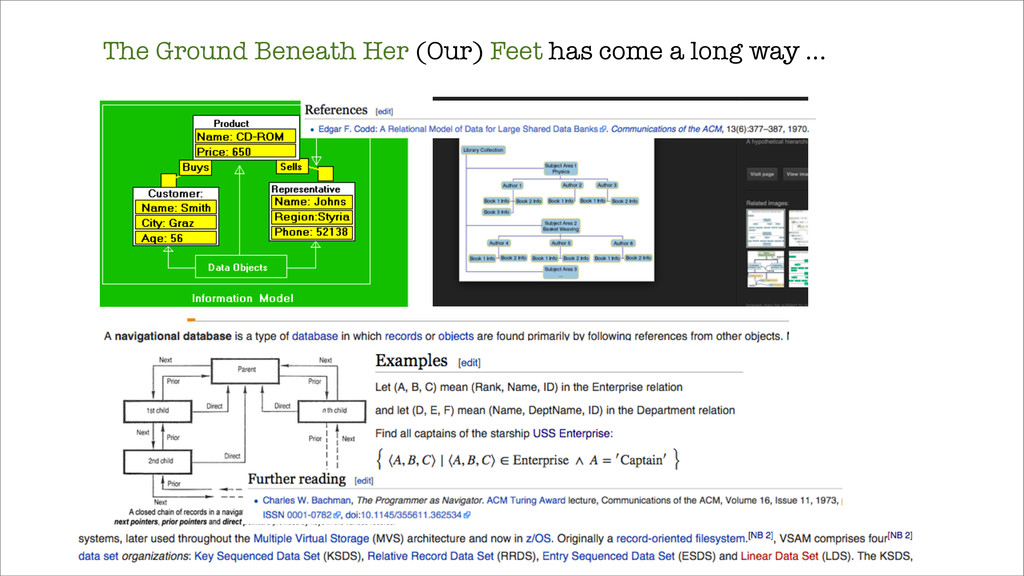
From MySQL and cursors and overloading Redis queues as a persistent data store (!) to MongoDB with a return to principles drawn from VSAM and CODASYL, this is less of a talk and more of a plea -
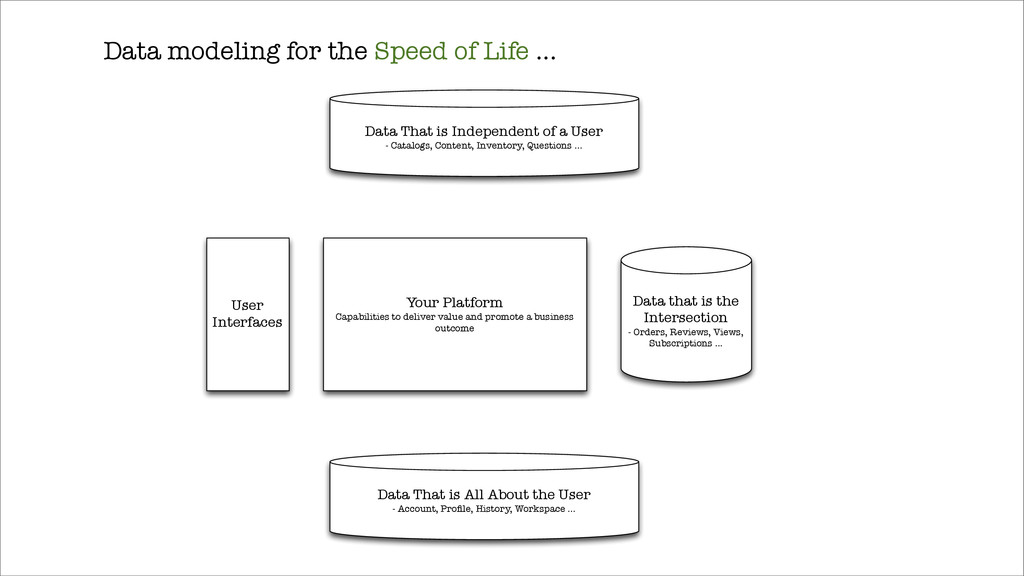
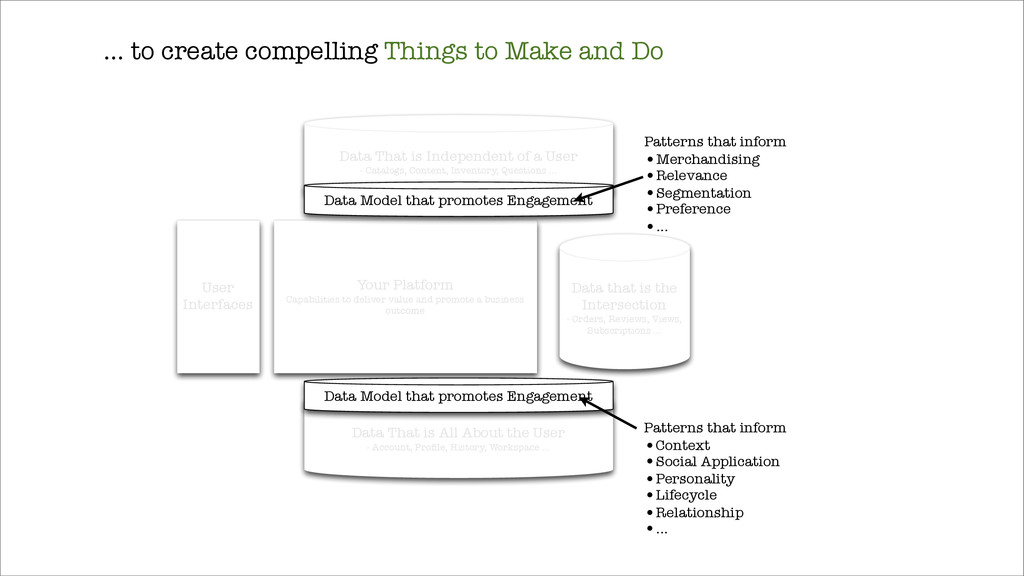
To think about the Model in the Data even as we rush to Build it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}