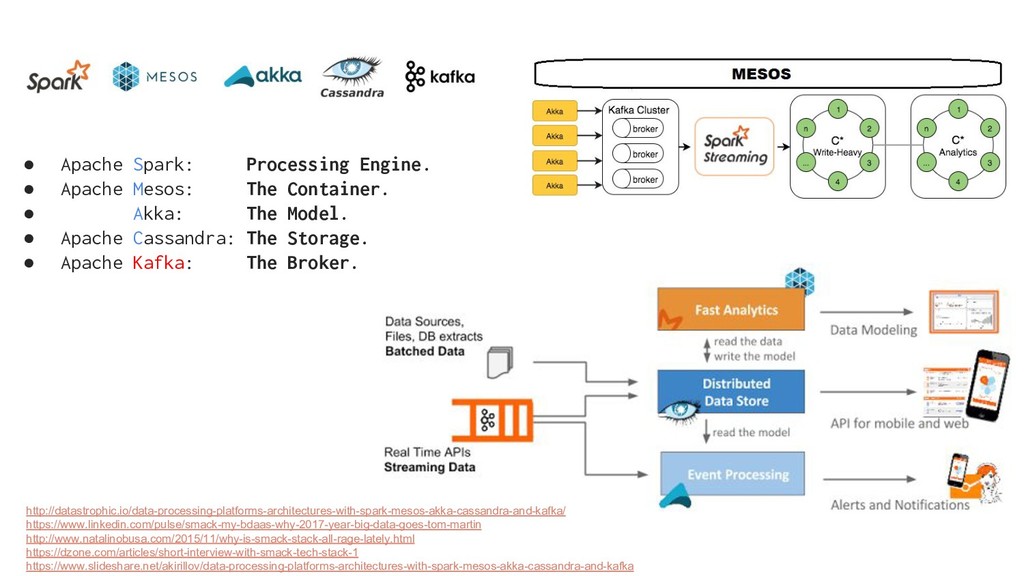
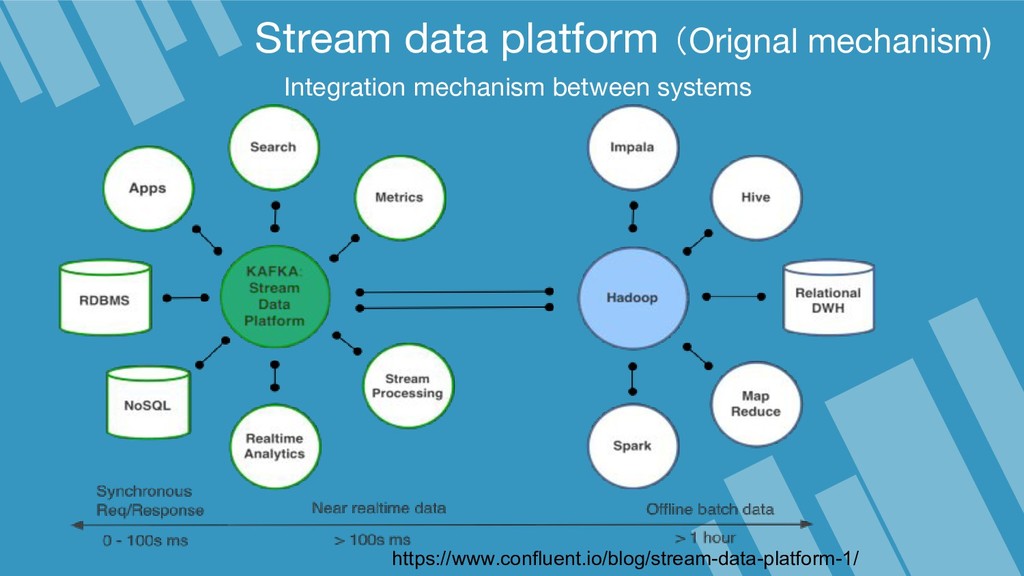
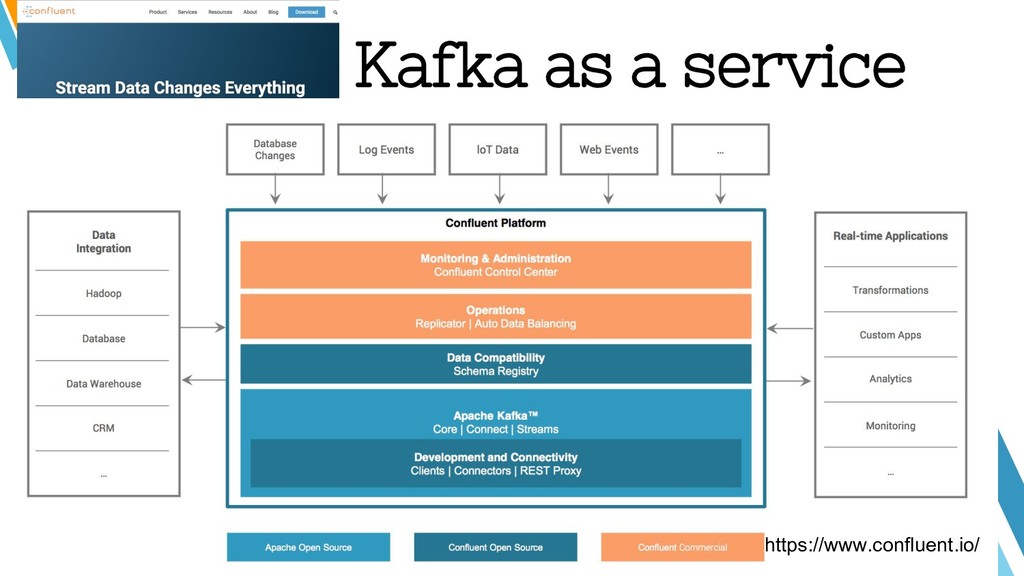
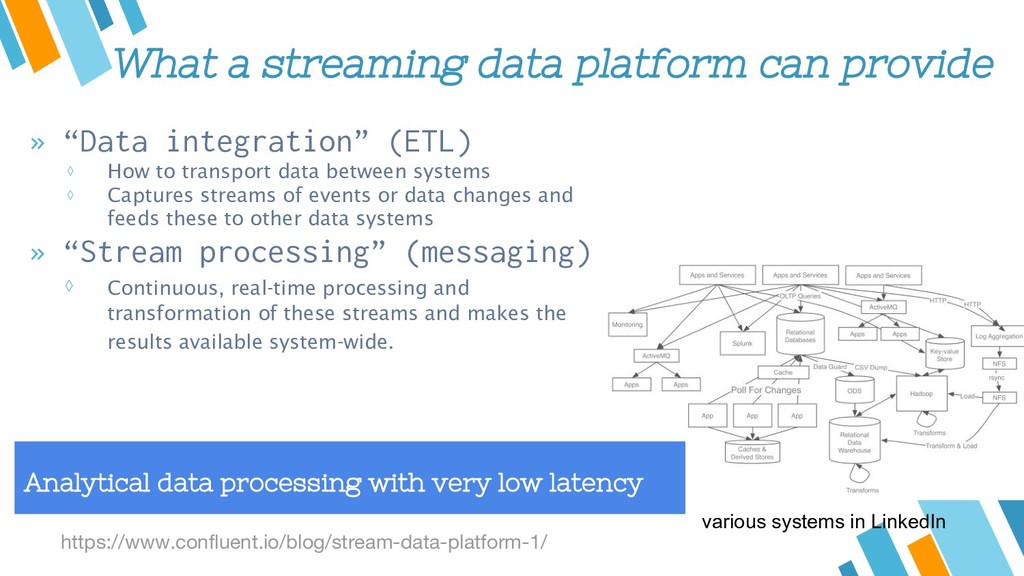
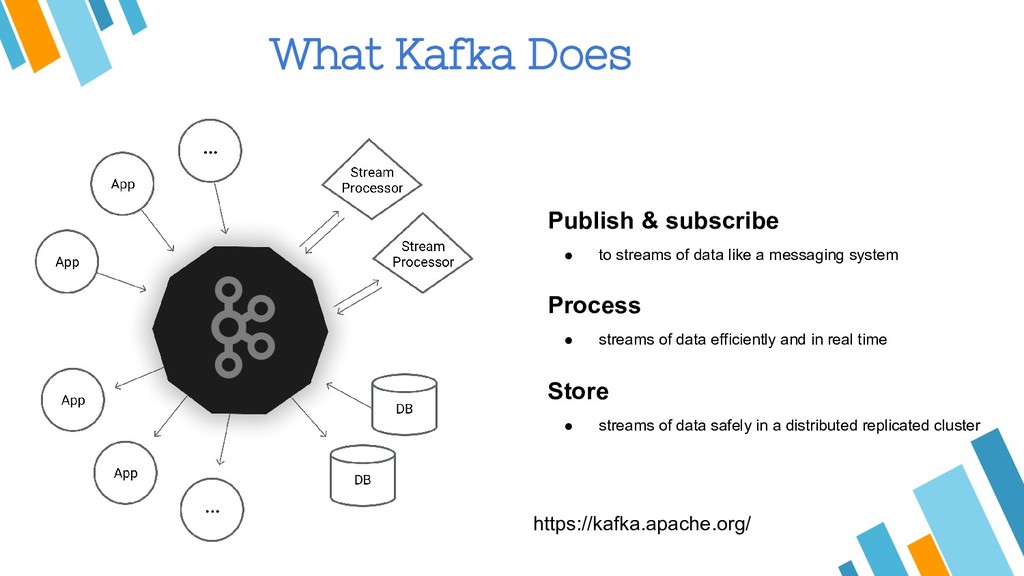
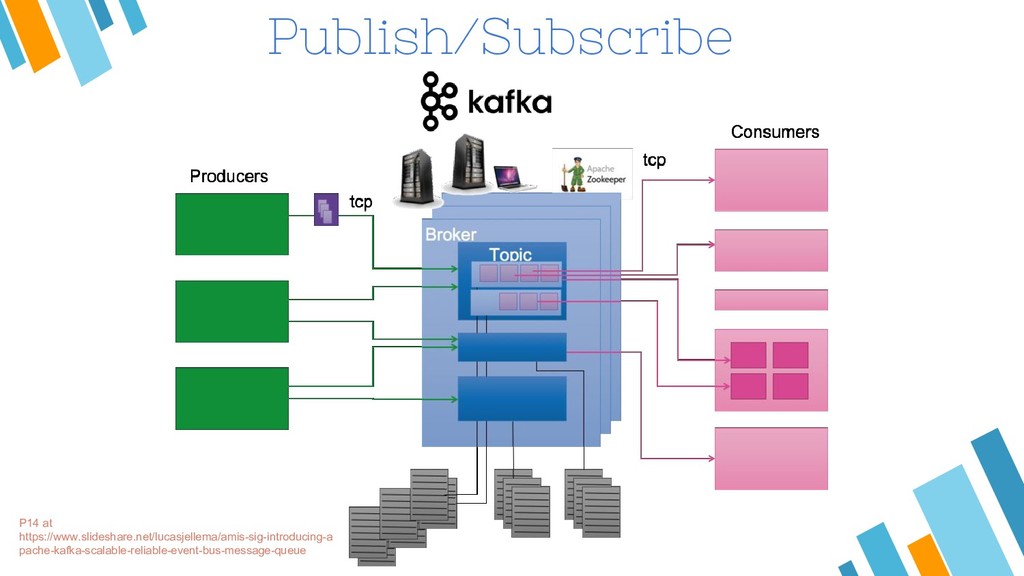
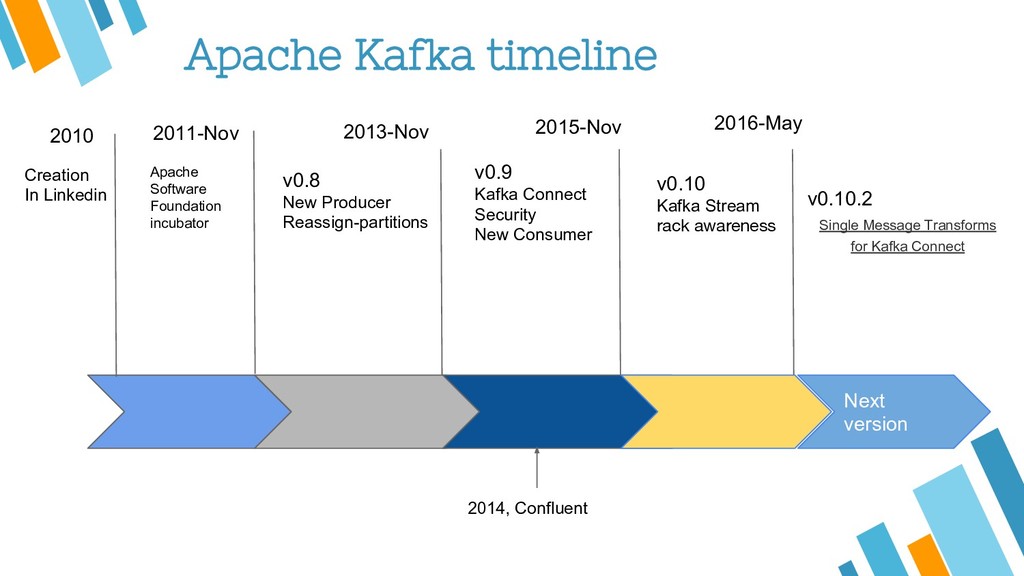
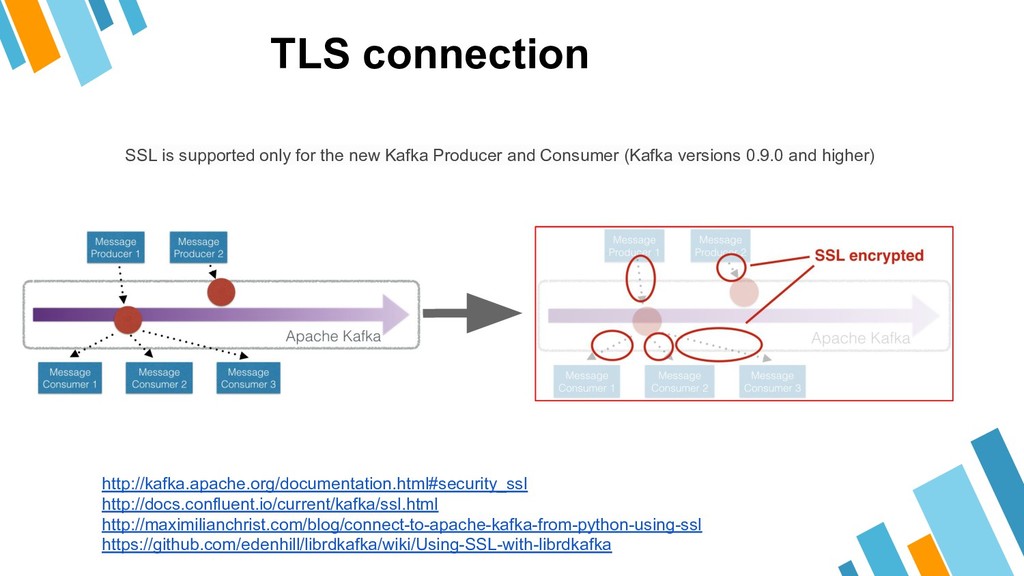
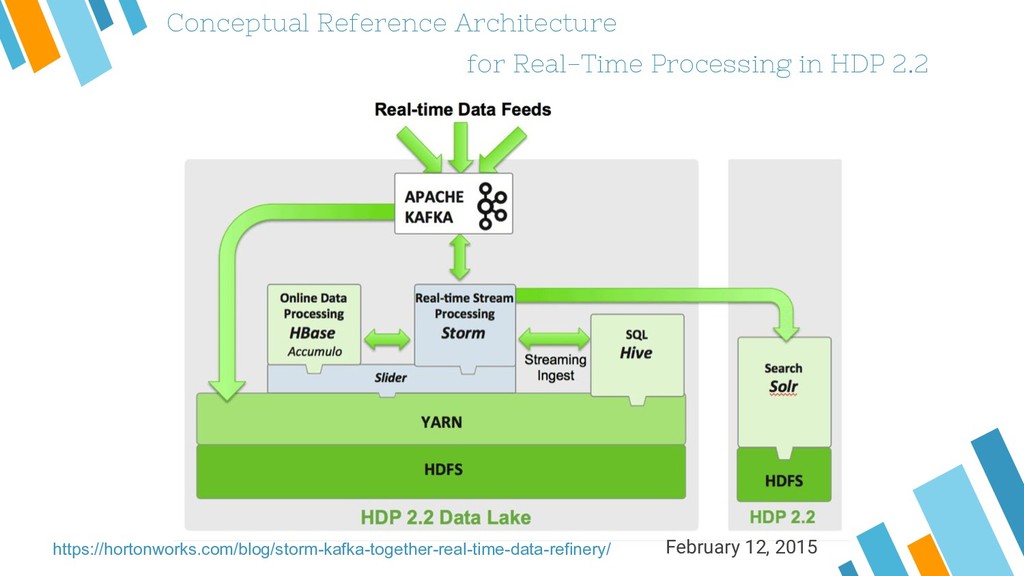
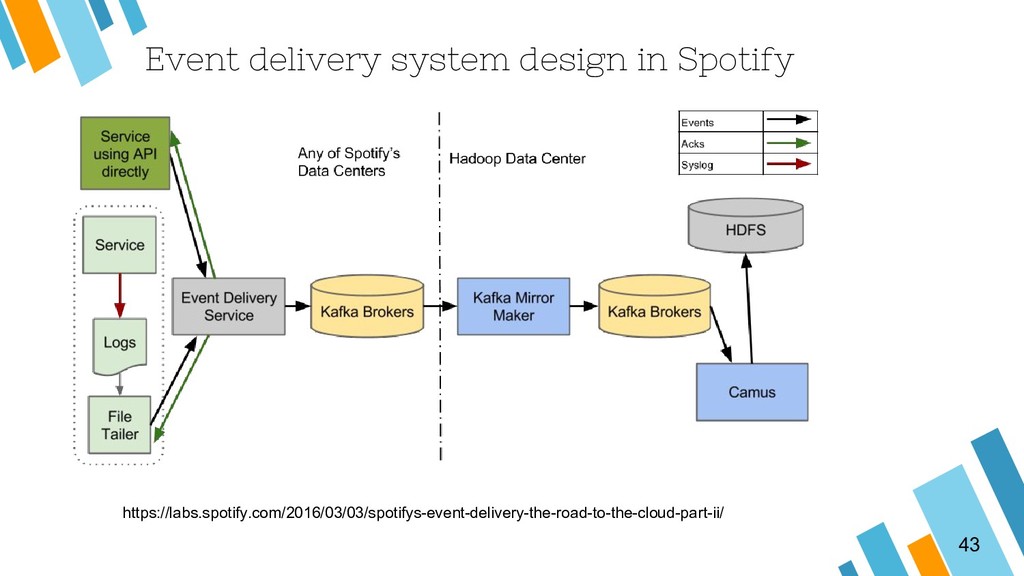
Apache Kafka is considered as a distributed streaming platform to a build real-time data pipelines and streaming apps. You can also take Kafka as commit log service with functions much like a publish/subscribe messaging system, but with better throughput, built-in partitioning, replication, and fault tolerance and runs in production in thousands of companies. Recently, Kafka has been widely applied as one component of SMACK stack because of it's role connected with Apache Hadoop, Apache Storm, and Spark Streaming in the data pipeline.
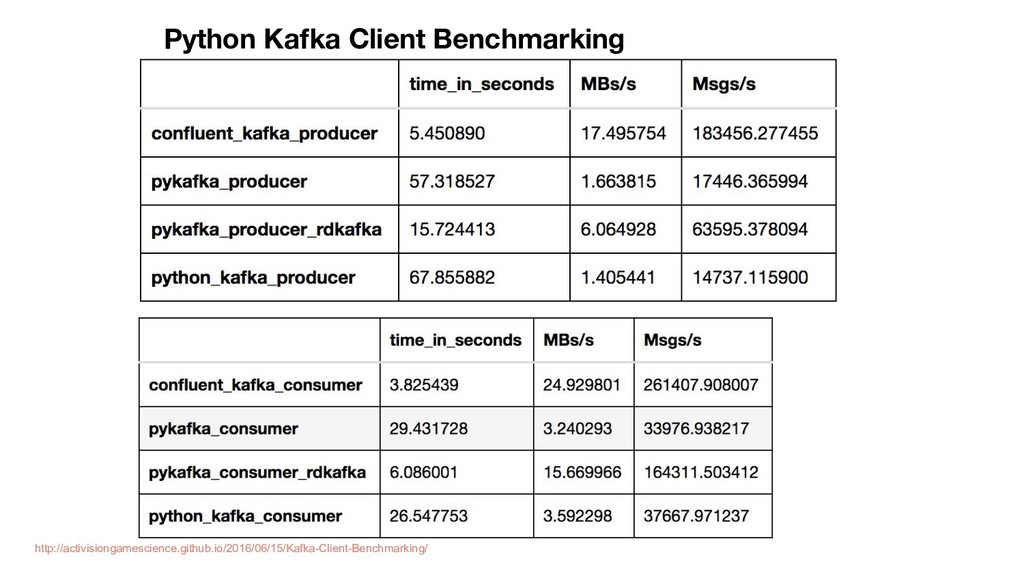
In this talk, I will start with introduce data stream processing and the general concept of Kafka's architecture and components by several use cases. Then, Kafka' API will be introduced by python clients with demo. Finally, the benchmark, comparison and limitation of different python clients will be discussed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
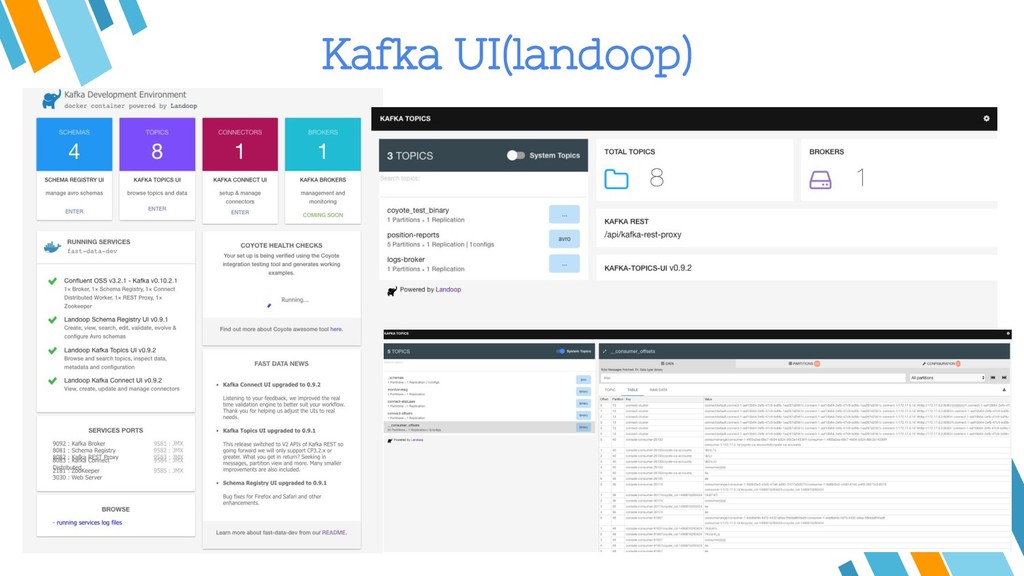{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
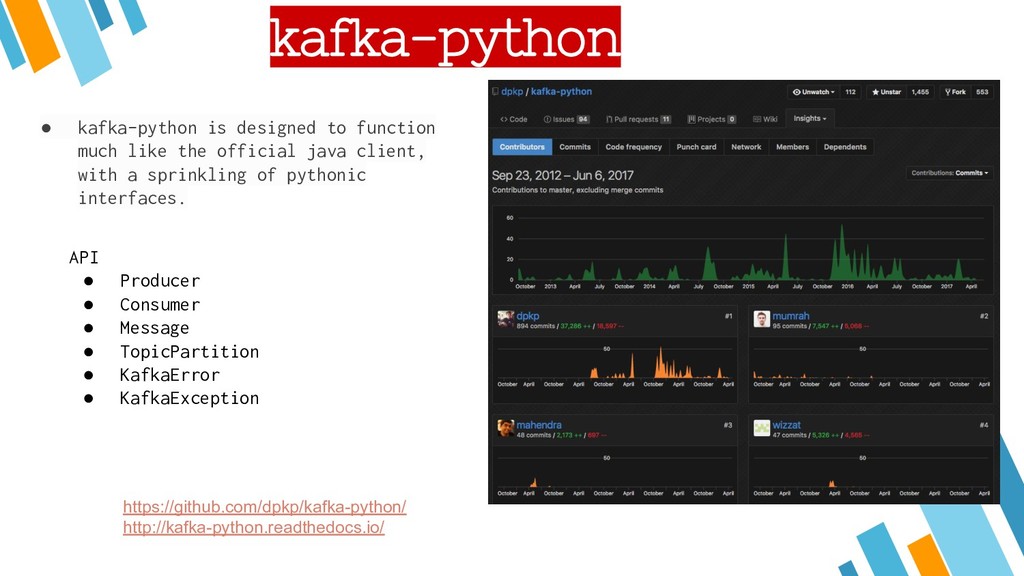{kind=link}
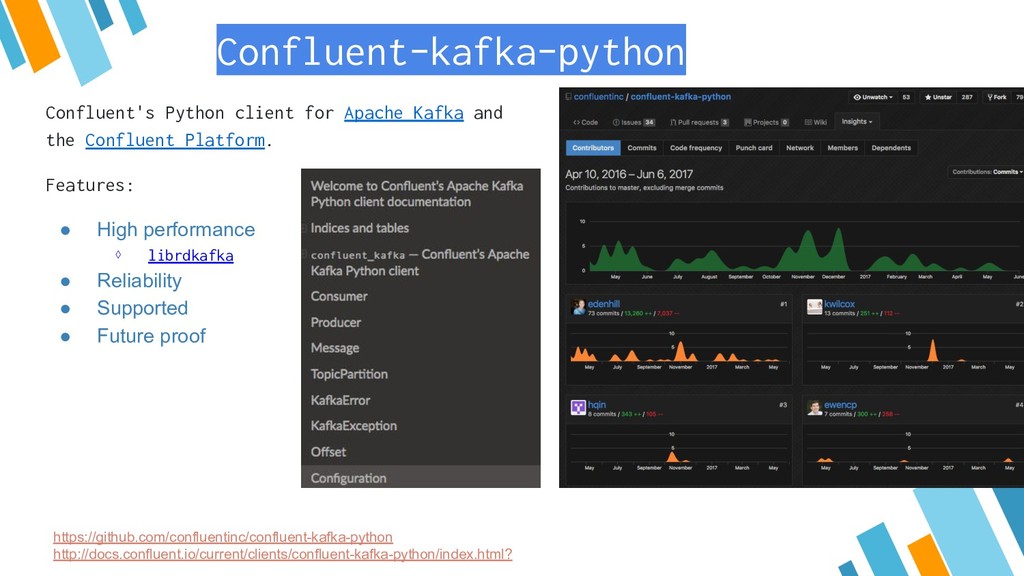{kind=link}
{kind=link}
{kind=link}
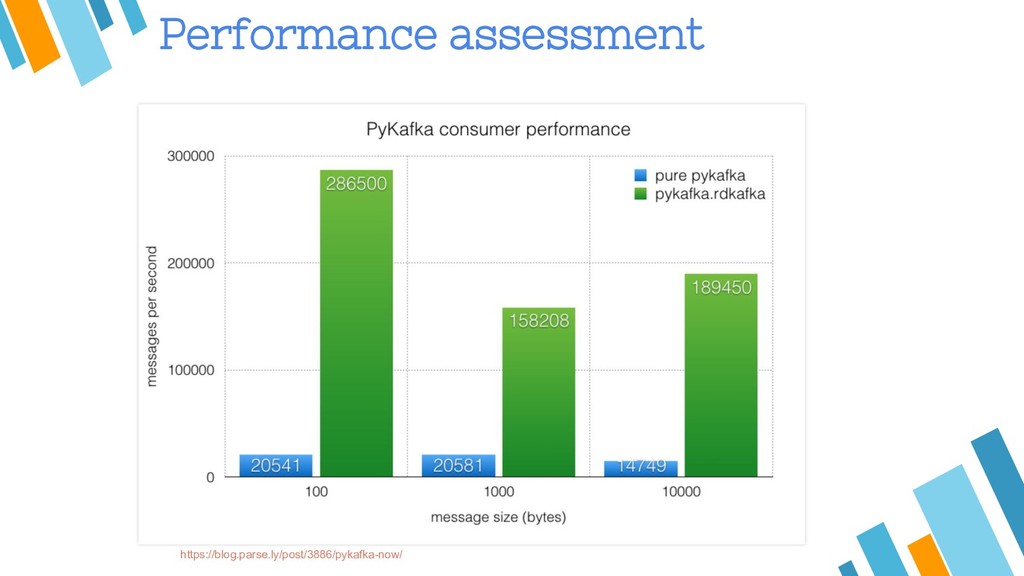{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}