Share
2020/2/29(土)に開催した、Kaggle DSBコンペ振り返り会の発表資料です。 チーム:shirokane_friends コンペURL:https://www.kaggle.com/c/data-science-bowl-2019/overview
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
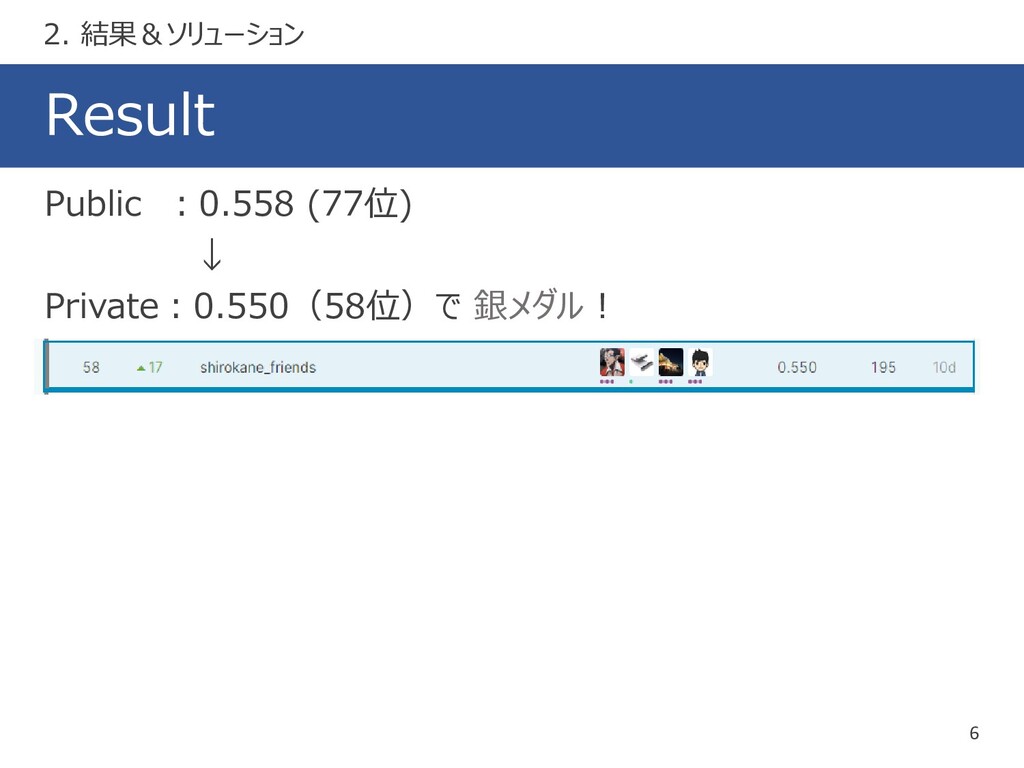{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
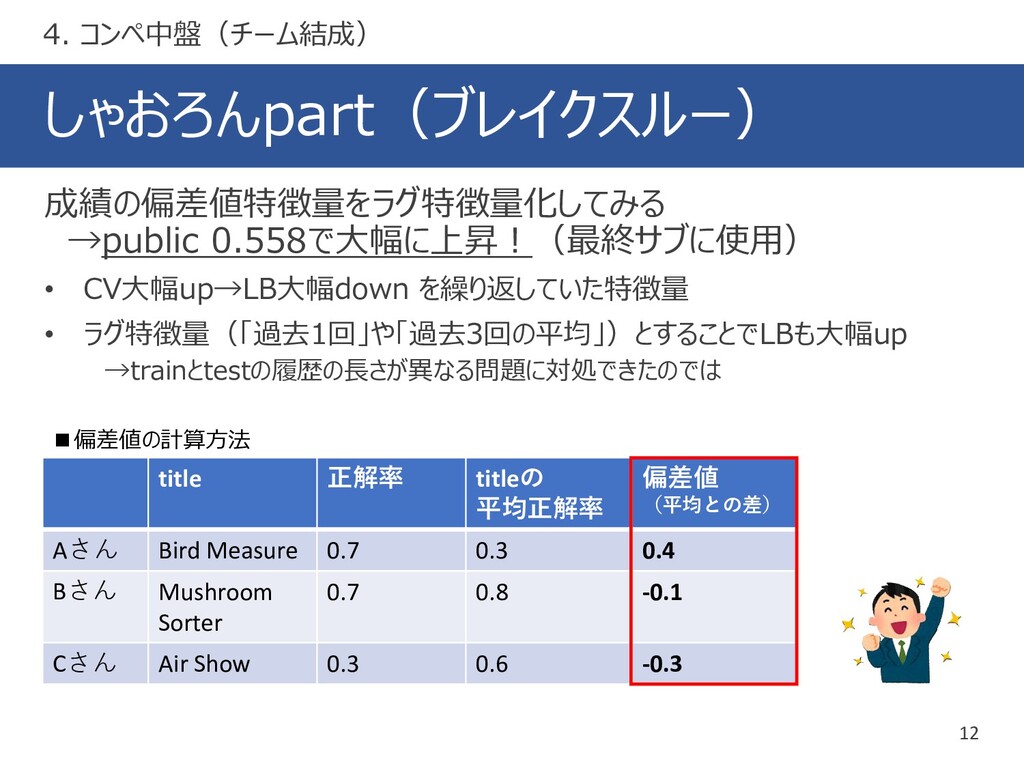{kind=link}
{kind=link}
![Idem part 14 [KDD 2018]xDeepFM: Combining Explicit and Implicit Feature](https://files.speakerdeck.com/presentations/76c562da03d04832868add70c4492298/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
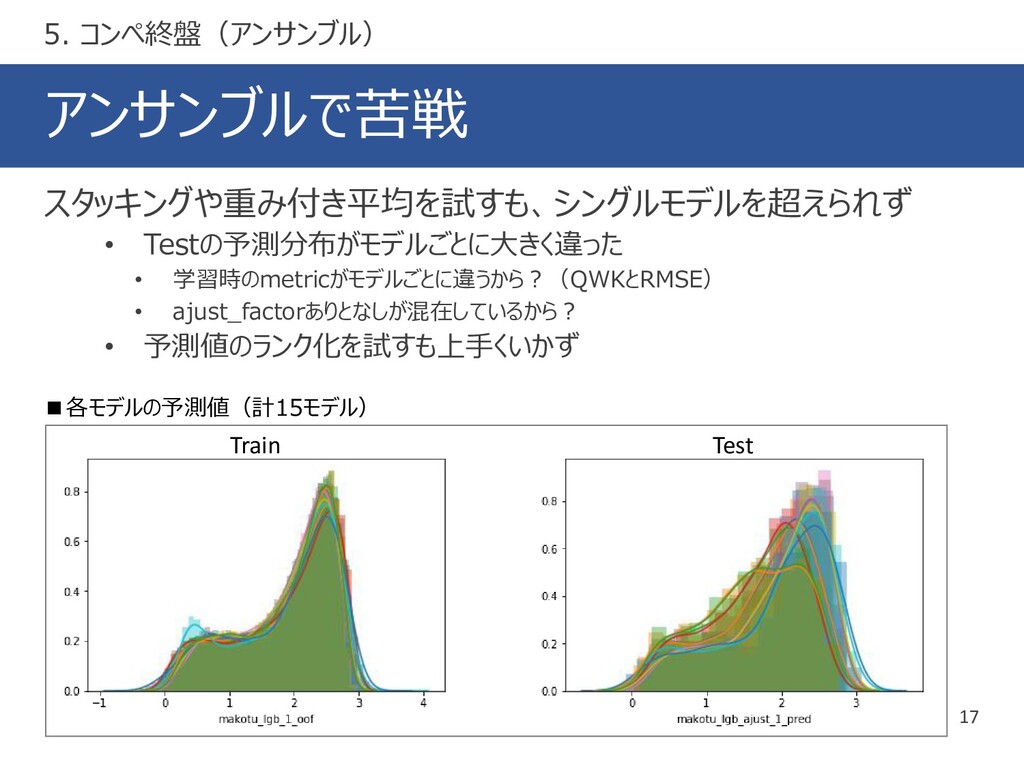{kind=link}
{kind=link}
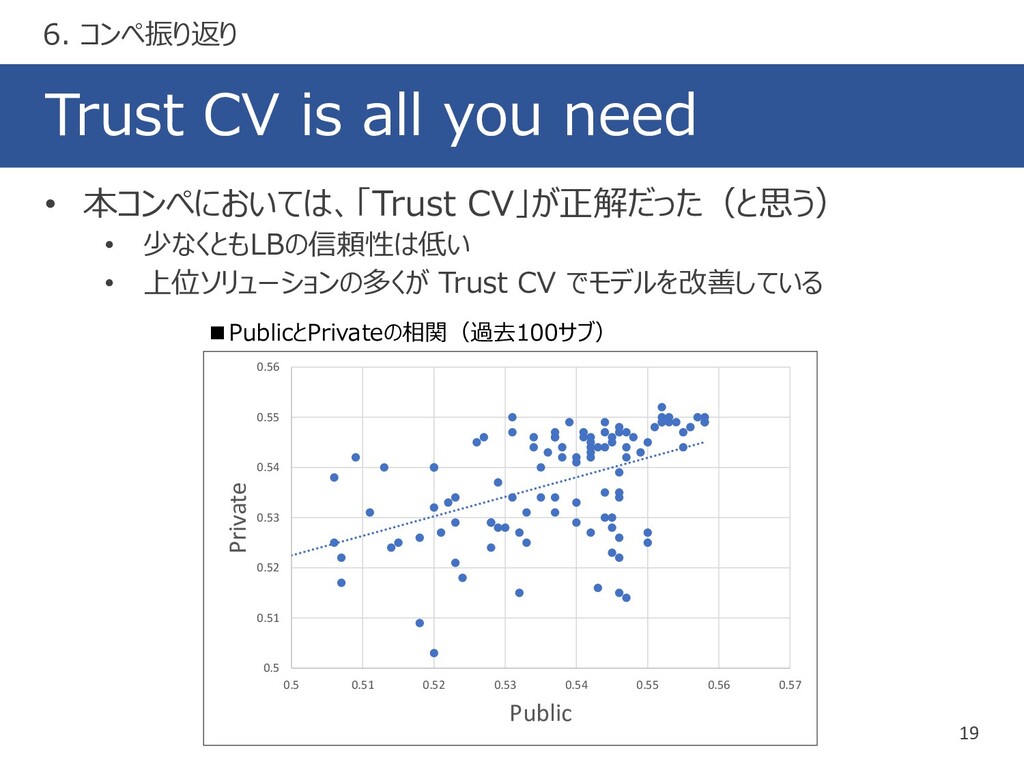{kind=link}
{kind=link}
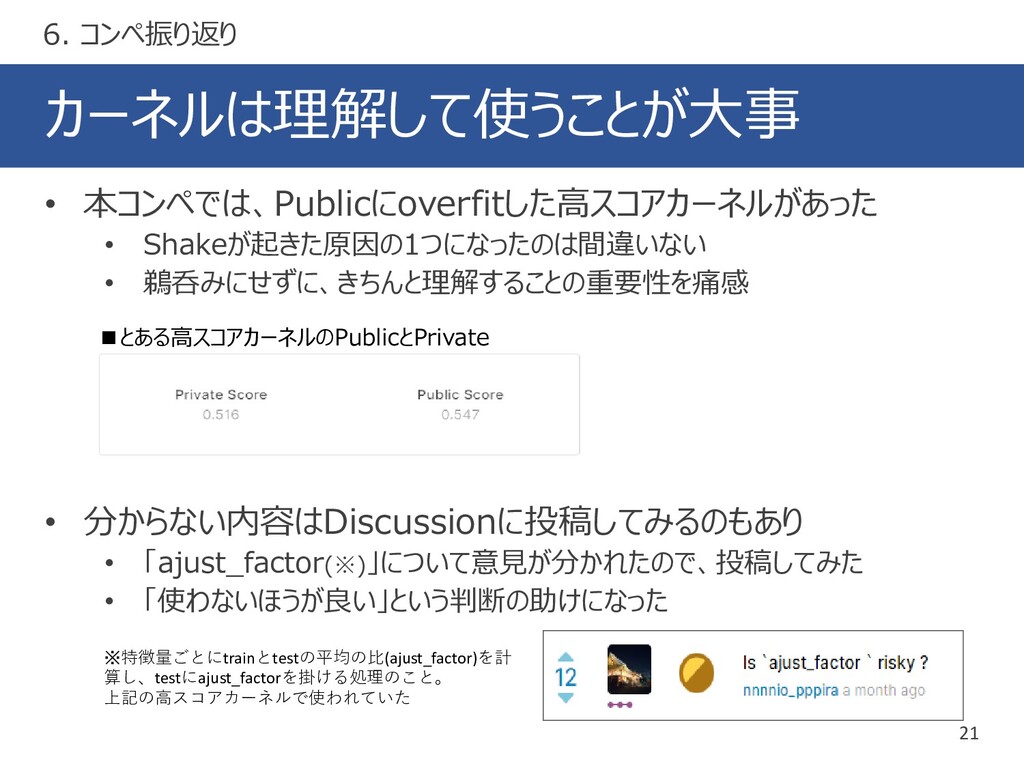{kind=link}
{kind=link}