Plane (UCP) в Docker ЕЕ o RedHat OpenShift и OKD (ранее OpenShift Origin) o IBM Cloud Private o GKE Anthos o Надстройки для оркестрации кластеров: o Rancher 2 o Pivotal Container Service (PKS) o …
Plane (UCP) в Docker ЕЕ o RedHat OpenShift и OKD (ранее OpenShift Origin) o IBM Cloud Private o GKE Anthos o Надстройки для оркестрации кластеров: o Rancher 2 o Pivotal Container Service (PKS) o …
не заниматься ерундой • eсли используется openshift/okd или Docker EE выбора нет :) • воспользоваться kops (AWS only) • kube-spray • kubeadm • hand-made Ansible-роли
+ Меньше цена ошибки - Сложнее жизнь эксплуатации + Легче эксплуатация - Крупнее failure-domain - Более критичные сервисы мешают жить менее важным (PCI DSS vs весь мир) • dev / test и prelive – кластеры (минимально возможное количество) • 1 prod. кластер на каждый класс критичности (MC/BC/…)
+ Меньше цена ошибки - Сложнее жизнь эксплуатации + Легче эксплуатация - Крупнее failure-domain - Более критичные сервисы мешают жить менее важным (PCI DSS vs весь мир) • dev / test и prelive – кластеры (минимально возможное количество) • 1 prod. кластер на каждый класс критичности (MC/BC/…)
Хост-порты на ingress-нодах (без k8s-сервисов, чтобы не терять source IP) • Железный аналог keepalived и haproxy/nginx для балансировки запросов к apiserver • Отдельный IP на нем же на каждое «приложение» (проект / сервис etc) в кластере
из коробки есть SecurityContextConstraints • и набор предопределенных классов «привилегированности» • В Kubernetes есть PodSecurityPolicy, но • чаще всего их контроль выключен • Описание политик и права в них надо составлять вручную • IBM Cloud заопенсорсил свой набор PSP-правил https://github.com/IBM/cloud-pak/tree/master/spec/security/psp
не ограничен • NetworkPolicy позволяет устранить эту «особенность» • Работают по принципу белого списка (запрещено все, что не разрешено) • От выбора CNI зависит, доступны ли NetworkPolicy вам :) • Flannel не поддерживает NetworkPolicy
нод после размещения (если нет нехватки ресурсов) • Descheduler позволяет повторно провести планирование • Запускается в качестве Job-ы (а лучше CronJob-ы ;) https://github.com/kubernetes-sigs/descheduler
git-репо и доверить автоматике весь процесс: • Создать Namespace и набор необходимых RBAC-объектов • Добавить в Namespace NetworkPolicy-объекты: • Изоляция от других NS • Доступ к общим инфраструктурным сервисам • …
/ ear – архив или статический бинарник на go? • Docker-образ c чем-то из предыдущего пункта? • Образ и набор манифестов для его развертывания в Kubernetes?
/ ear – архив или статический бинарник на go? • Docker-образ c чем-то из предыдущего пункта? • Образ и набор манифестов для его развертывания в Kubernetes?
/var/run/docker.sock - сразу нет • docker-in-docker пока еще есть, но мы от него уходим • Google Kaniko самый простой и незатейливый на подъем, но не без проблем • Хотим начать пробовать buildah от Red Hat
хорошо с безопасностью • Helm Tiller допустимо использовать только для развертывания инфраструктуры и проведения экспериментов в тестовых кластерах (БД / кеш / …) • Подробнее о Helm на заключительном докладе!
в k8s • Текущая логика CD (деплой в Mesos/Marathon) написана на Ansible • Helm – не лучший выбор • Мы пытаемся упростить миграцию в Kubernetes за счет обновления deployment-логики существующих ролей
CI-пайплайне проверяем их с помощью kubeval • Для прозрачности процесса деплоя и его синхронности используем kubedog • Если у вас OpenShift (OKD) и пользуетесь встроенными DeploymentConfig- объектами, можно деплоить и через oc.
selector в объектах Deployment – неизменяемое поле • selector в объекте сервис – поддерживает изменения • … • Использовать свой admission controller для верификации манифестов – хороший способ избежать подобных ситуаций
на учете доступности запрошенных гарантированных (resource.requests) ресурсов • ResourceQuota позволяет ограничить утилизацию ресурсов в пределах неймспейса: • Доступные ресурсы CPU и памяти (гарантированные и предельные (resource.limits)) • Доступный объем использования «диска»: постоянного и эфемерного хранилищ (v1.8 – alpha, v1.16 – beta) • Ограничение на количество объектов заданного типа
ВСЕ создаваемые POD-ы имели явно заданные requests и limits на ресурсы этого типа ресурса • Ресурс LimitRange позволяет задать допустимые диапазоны requests и limits для ресурса и их значения по-умолчанию
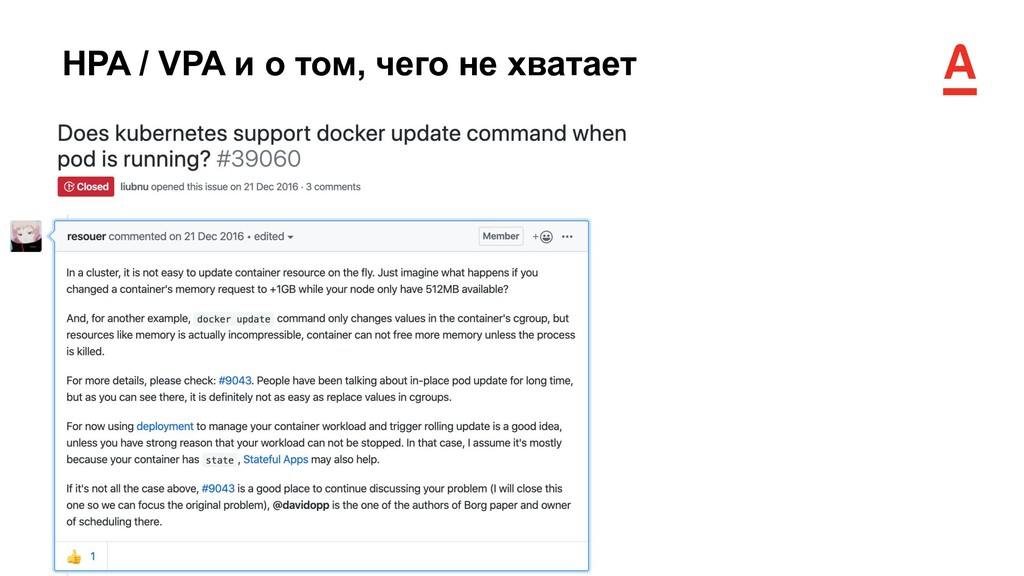
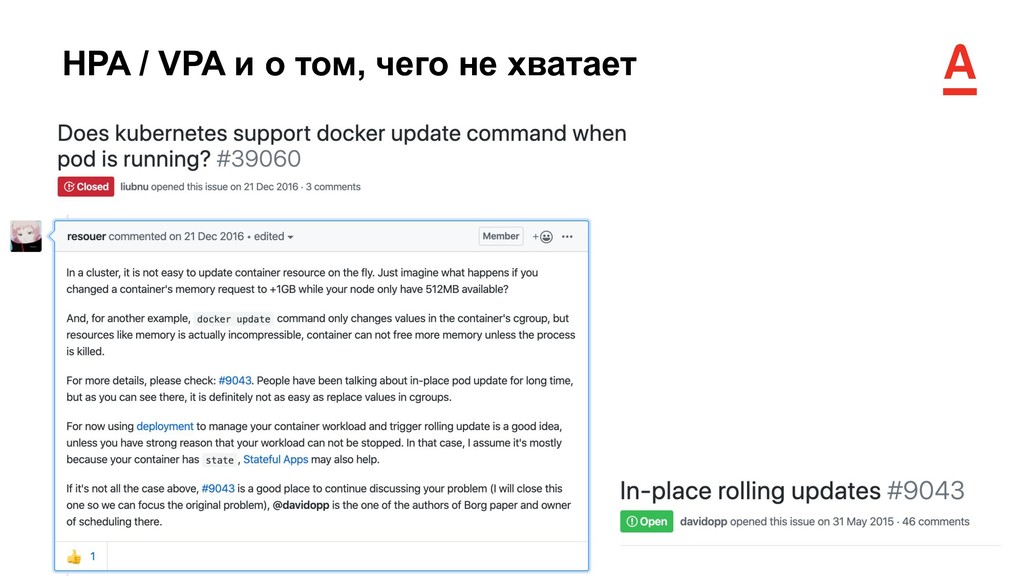
Pod Autoscaler (HPA) может автоматически изменять количество реплик объектов Deployment / StatefulSet, в зависимости от заданных метрик • Потребление CPU / памяти (базовая функциональность) • Любые кастомные метрики через интеграцию metrics-api кластера и Prometheus посредством prometheus-adapter • Vertical Pod Autoscaler (VPA) отслеживает фактическое потребление ресурсов контейнера и формирует рекомендации по оптимальным значениям requests и limits для CPU и памяти • VPA может автоматически применять рассчитанные рекомендации к ресурсу (Deployment / StatefulSet)
: Started Application in 48.276 seconds (JVM running for 50.597) 1 vCPU: 2019-10-19 13:42:51.678 INFO 1 --- [ main] ru.alfa.Application : Started Application in 22.755 seconds (JVM running for 24.199) 1.5 vCPU: 2019-10-19 14:38:19.440 INFO 1 --- [ main] ru.alfa.Application : Started Application in 14.429 seconds (JVM running for 15.244) 2 vCPU: 2019-10-19 13:48:45.784 INFO 1 --- [ main] ru.alfa.Application : Started Application in 10.687 seconds (JVM running for 11.284) Это Spring, сынок
k8s.af • Kubernetes Failure Stories, or: How to Crash Your Cluster - Zalando - ContainerDays EU 2019 • Build Errors of Continuous Delivery Platform - Zalando - postmortem 2019 • 10 Ways to Shoot Yourself in the Foot with Kubernetes, #9 Will Surprise You - Datadog - KubeCon Barcelona 2019 • Kubernetes Failure Stories - Zalando - KubeCon Barcelona 2019 • Let's talk about Failures with Kubernetes - Zalando - Hamburg meetup 2019 • Total DNS outage in Kubernetes cluster - Zalando - postmortem 2019 • How NOT to do Kubernetes - Sr.SRE Medya Ghazizadeh – Google • Running Kubernetes in Production: A Million Ways to Crash Your Cluster - Zalando - DevOpsCon Munich 2018 • Stories from the Playbook - Google - KubeCon Europe 2018
k8s.af • Kubernetes Failure Stories, or: How to Crash Your Cluster - Zalando - ContainerDays EU 2019 • Build Errors of Continuous Delivery Platform - Zalando - postmortem 2019 • 10 Ways to Shoot Yourself in the Foot with Kubernetes, #9 Will Surprise You - Datadog - KubeCon Barcelona 2019 • Kubernetes Failure Stories - Zalando - KubeCon Barcelona 2019 • Let's talk about Failures with Kubernetes - Zalando - Hamburg meetup 2019 • Total DNS outage in Kubernetes cluster - Zalando - postmortem 2019 • How NOT to do Kubernetes - Sr.SRE Medya Ghazizadeh – Google • Running Kubernetes in Production: A Million Ways to Crash Your Cluster - Zalando - DevOpsCon Munich 2018 • Stories from the Playbook - Google - KubeCon Europe 2018 (только Google и Zalando)
{kind=link}
![Дмитрий Гадеев [email protected] @kruft](https://files.speakerdeck.com/presentations/bd08ce4fd1a64ebaa162d1ced292cb55/slide_1.jpg){kind=link}
{kind=link}
![Выбор системы оркестрации в 2019 [ для молодой компании ]](https://files.speakerdeck.com/presentations/bd08ce4fd1a64ebaa162d1ced292cb55/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Что общего у такого приложения с ”production-ready” [ НИЧЕГО ]](https://files.speakerdeck.com/presentations/bd08ce4fd1a64ebaa162d1ced292cb55/slide_25.jpg){kind=link}
![Что общего у такого приложения с ”production-ready” [ НИЧЕГО ]](https://files.speakerdeck.com/presentations/bd08ce4fd1a64ebaa162d1ced292cb55/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![0.5 vCPU: 2019-10-19 13:54:27.481 INFO 1 --- [ main] ru.alfa.Application](https://files.speakerdeck.com/presentations/bd08ce4fd1a64ebaa162d1ced292cb55/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}