Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Machine Learning in Production with R or Python...
Search
szilard
June 08, 2017
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Machine Learning in Production with R or Python - Budapest Data Forum - June 2017
szilard
June 08, 2017
More Decks by szilard
See All by szilard
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - Data Con LA - Oct 2020
szilard
0
240
Make Machine Learning Boring Again: Best Practices for Using Machine Learning in Businesses - Albuquerque Machine Learning Meetup (Online) - Aug 2020
szilard
0
170
Better than Deep Learning: Gradient Boosting Machines (GBM) - eRum conference - invited talk - June 2020
szilard
0
150
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - LA Data Science Meetup - February 2020
szilard
0
140
A Random Walk in Data Science and Machine Learning in Practice - CEU, Business Analytics Masters - Budapest, Febr 2020
szilard
0
340
Better than My Meetup/Conference Talks: Going Deeper in Various GBM Topics - GBM Advanced Workshop - Budapest, Nov 2019
szilard
0
110
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - Budapest BI Forum, Budapest, Nov 2019
szilard
0
170
Make Machine Learning Boring Again: Best Practices for Using Machine Learning in Businesses - LA Data Science Meetup - Playa Vista, August 2019
szilard
0
160
Better than Deep Learning: Gradient Boosting Machines (GBM) / 2019 edition - Budapest R and Data Science Meetups - Budapest, June 2019
szilard
0
140
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
YesSQL, Process and Tooling at Scale
rocio
174
15k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
Chasing Engaging Ingredients in Design
codingconduct
0
240
A Tale of Four Properties
chriscoyier
163
24k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Transcript
Machine Learning in Production Szilárd Pafka, PhD Chief Scientist, Epoch
Budapest Data Forum June 2017
Machine Learning in Production with R Szilárd Pafka, PhD Chief
Scientist, Epoch Budapest Data Forum June 2017
Machine Learning in Production with R or Python Szilárd Pafka,
PhD Chief Scientist, Epoch Budapest Data Forum June 2017
Machine Learning in Production with R or maybe Python Szilárd
Pafka, PhD Chief Scientist, Epoch Budapest Data Forum June 2017
None
Disclaimer: I am not representing my employer (Epoch) in this
talk I cannot confirm nor deny if Epoch is using any of the methods, tools, results etc. mentioned in this talk
None
http://datascience.la/meetup-machine-learning-in-production-with-szilard-pafka/
None
None
None
None
None
None
None
None
None
None
None
None
None
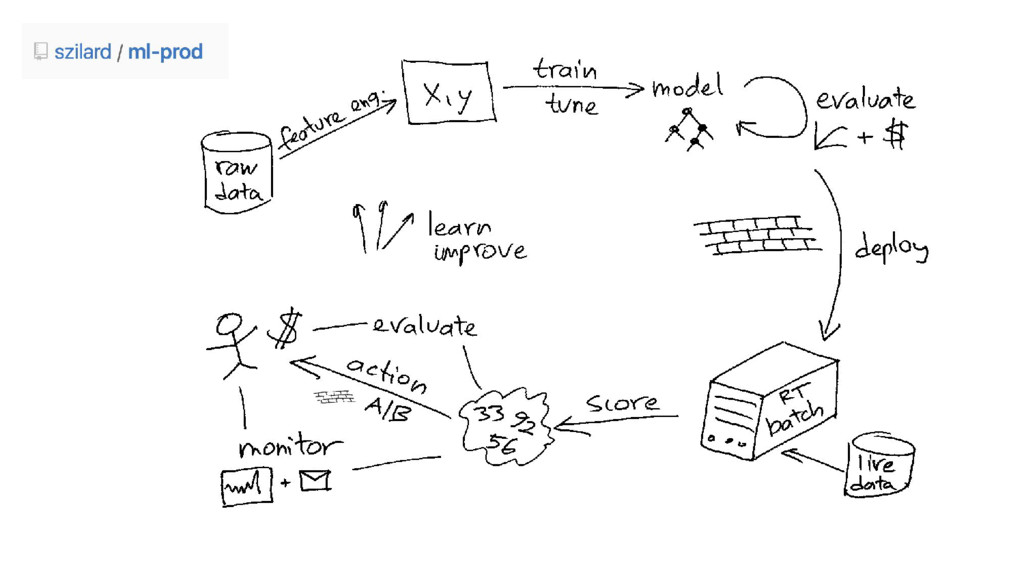
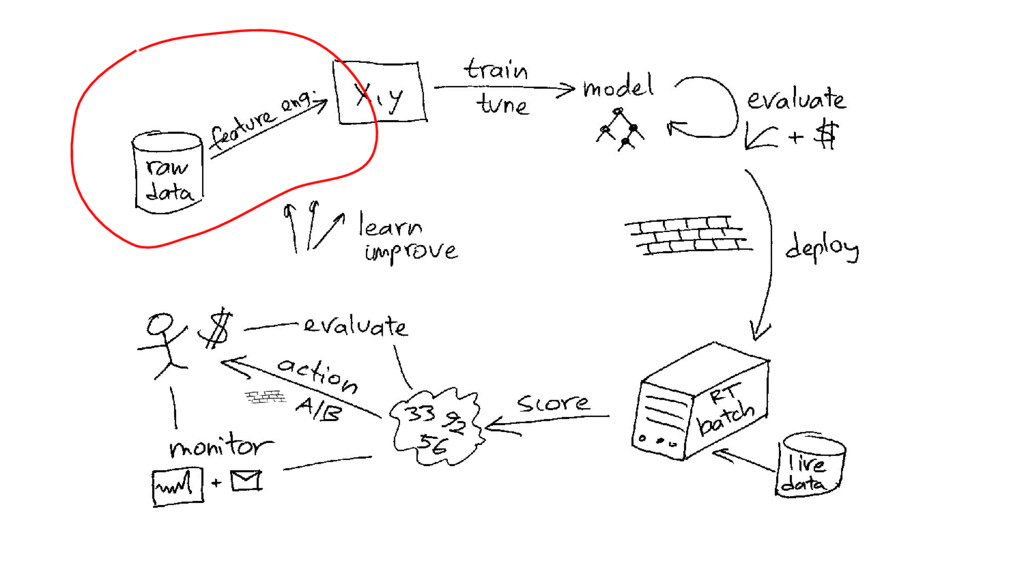
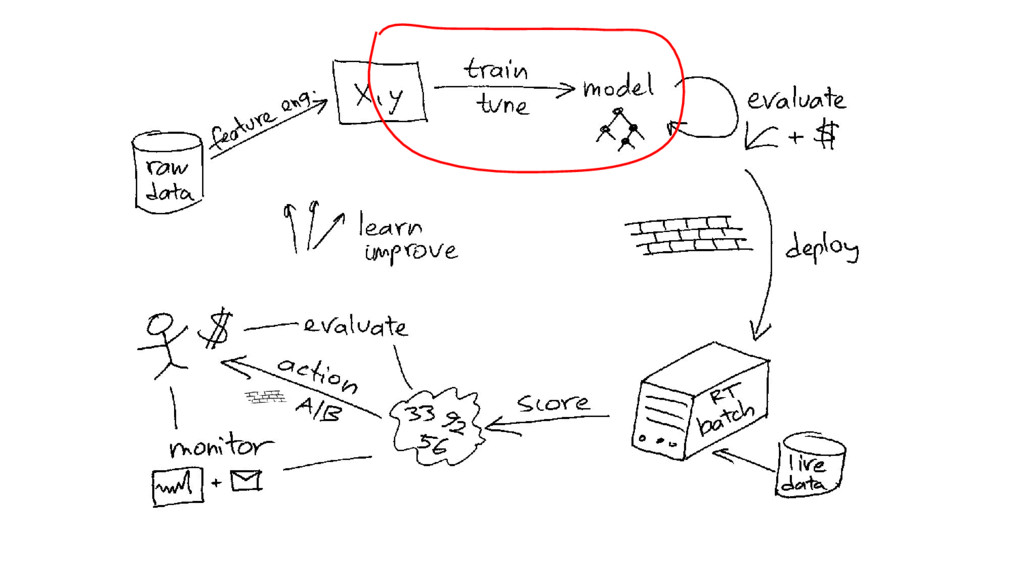
Aggregation 100M rows 1M groups Join 100M rows x 1M
rows time [s] time [s]
Aggregation 100M rows 1M groups Join 100M rows x 1M
rows time [s] time [s]
None
None
None
None
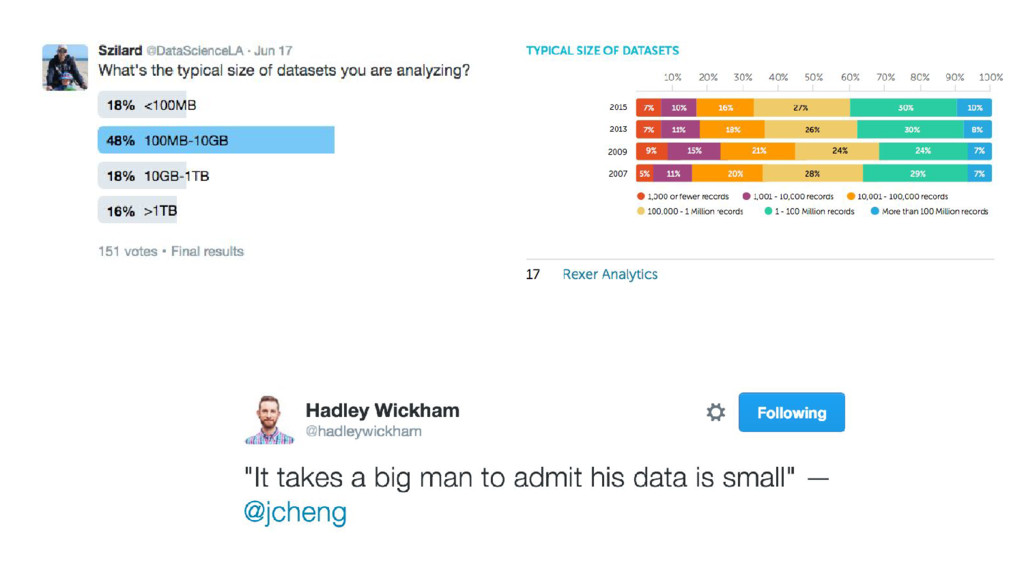
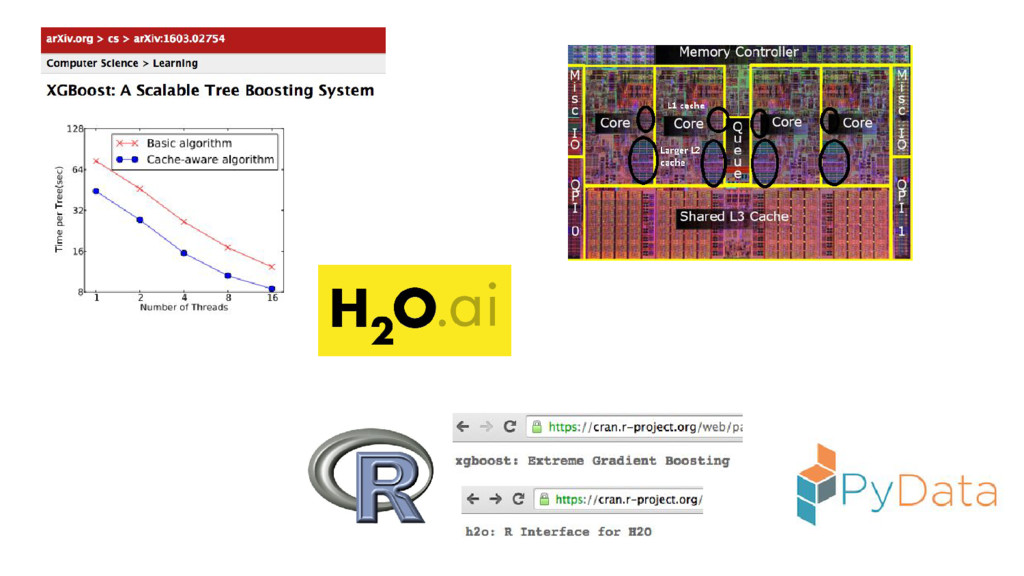
binary classification, 10M records numeric & categorical features, non-sparse
http://www.cs.cornell.edu/~alexn/papers/empirical.icml06.pdf http://lowrank.net/nikos/pubs/empirical.pdf
http://www.cs.cornell.edu/~alexn/papers/empirical.icml06.pdf http://lowrank.net/nikos/pubs/empirical.pdf
None
None
None
None
None
EC2
n = 10K, 100K, 1M, 10M, 100M Training time RAM
usage AUC CPU % by core read data, pre-process, score test data
n = 10K, 100K, 1M, 10M, 100M Training time RAM
usage AUC CPU % by core read data, pre-process, score test data
None
None
None
None
None
None
None
10x
None
None
None
None
None
http://datascience.la/benchmarking-random-forest-implementations/#comment-53599
None
None
None
None
None
None
None
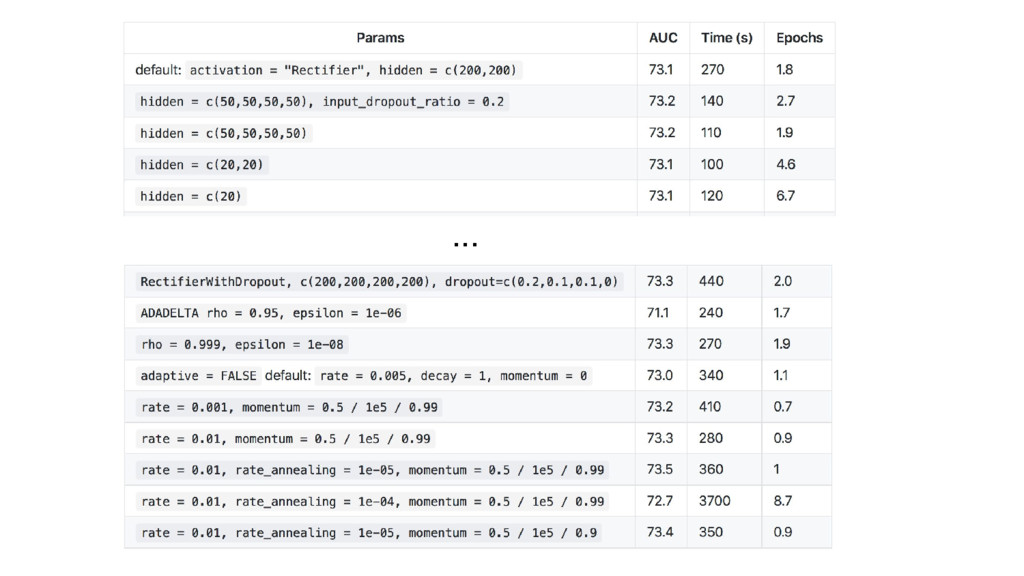
Best linear: 71.1
None
None
learn_rate = 0.1, max_depth = 6, n_trees = 300 learn_rate
= 0.01, max_depth = 16, n_trees = 1000
None
None
None
None
None
None
None
None
None
None
None
None
None
None
...
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}