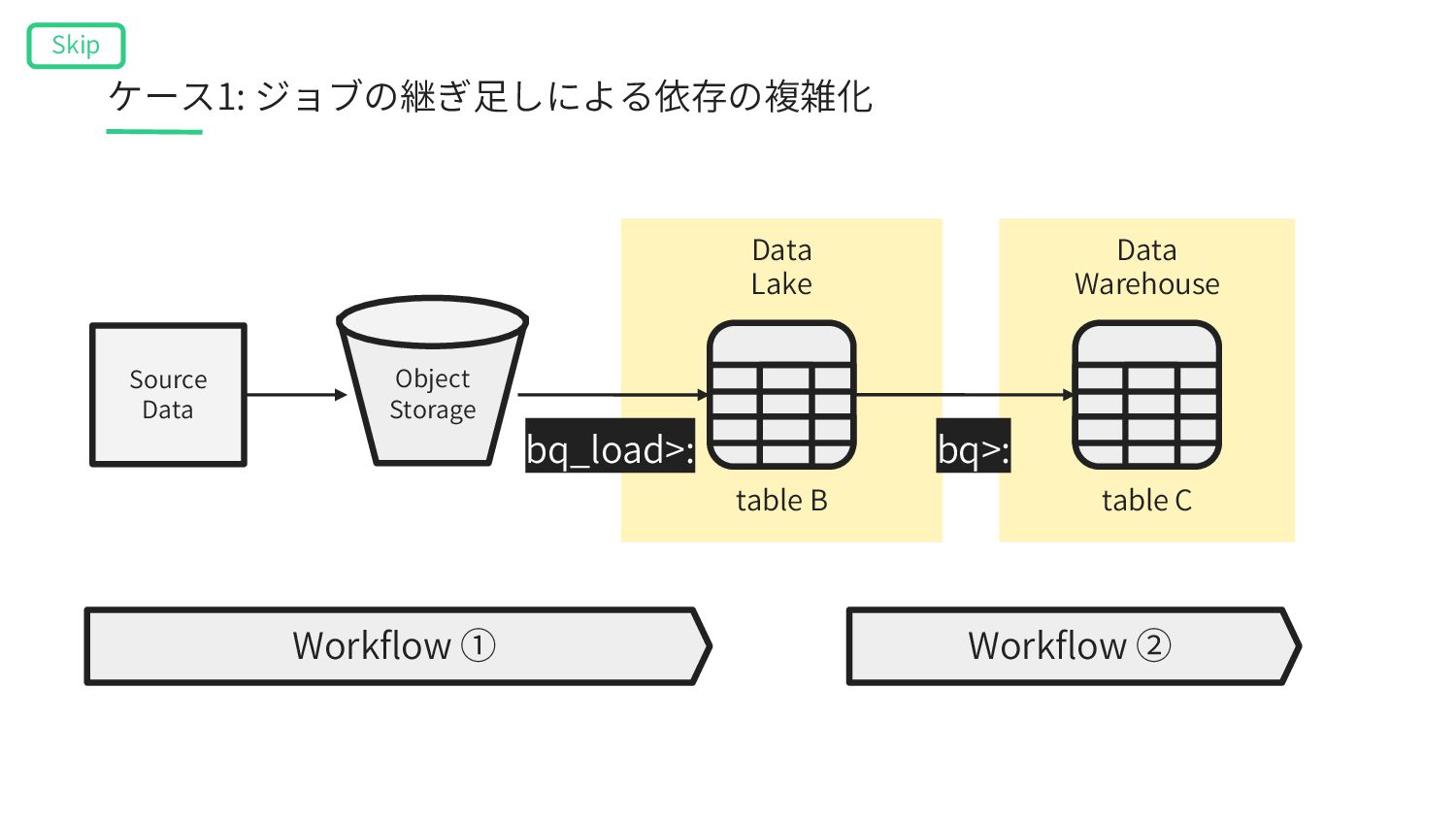
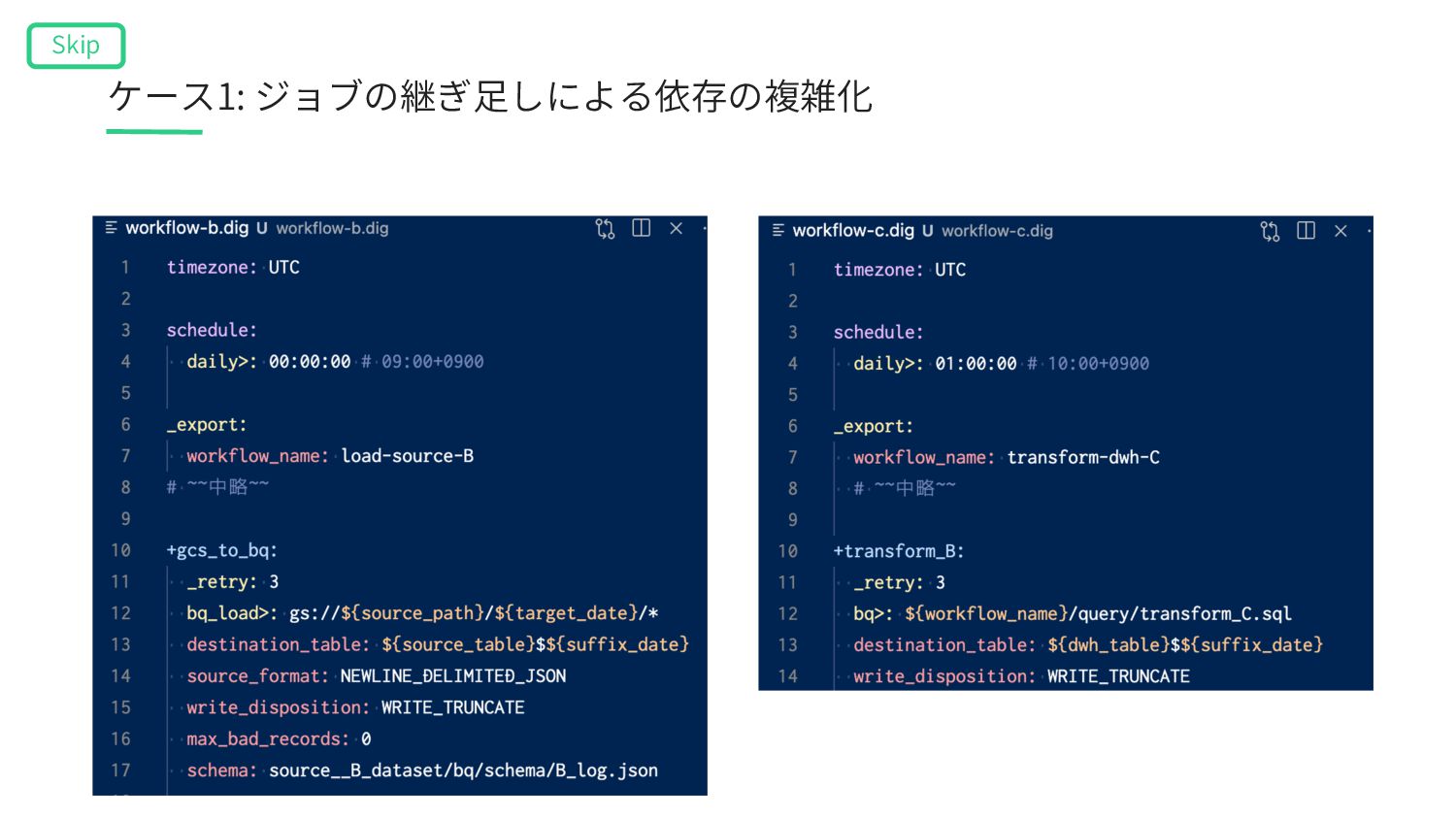
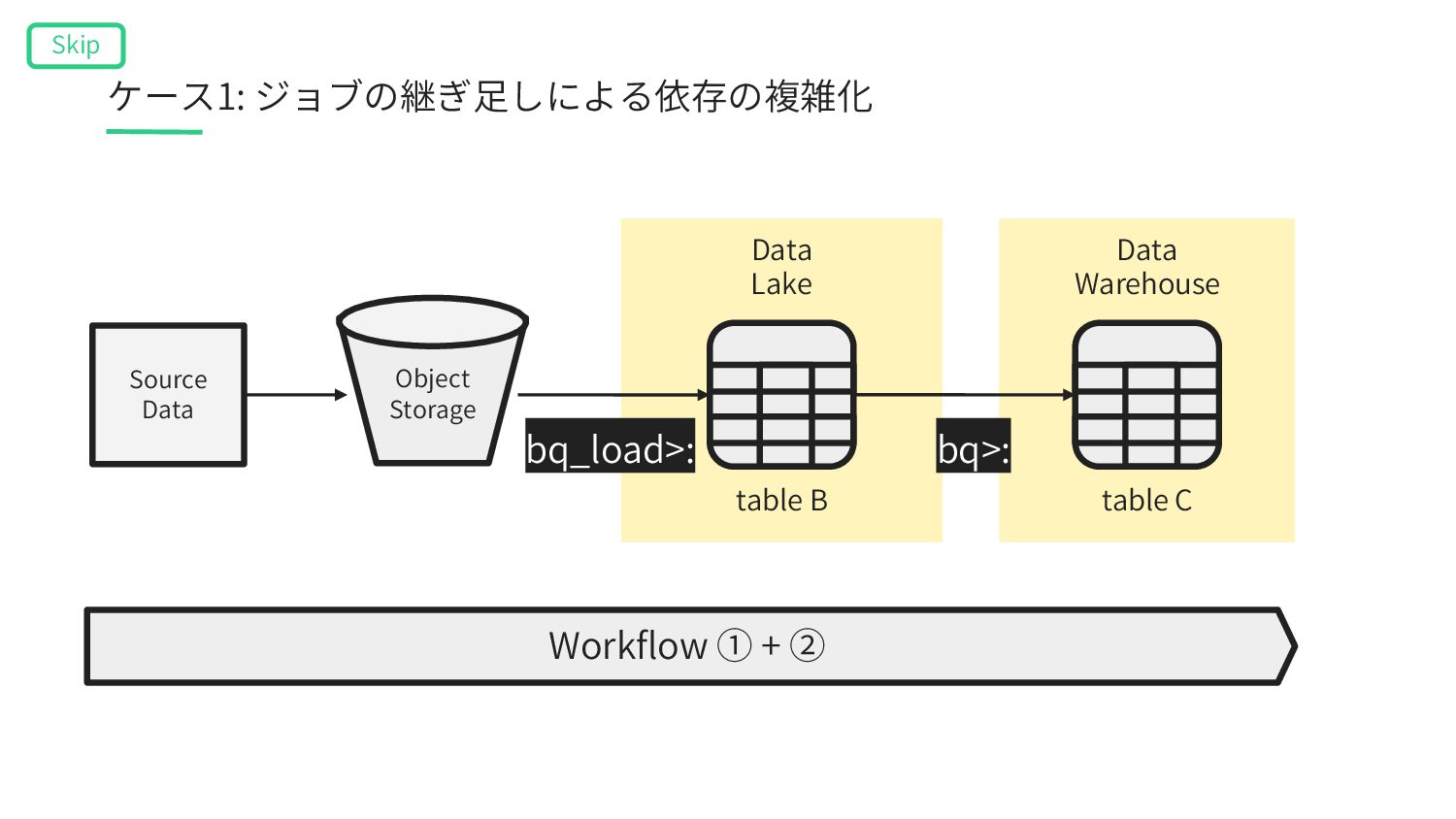
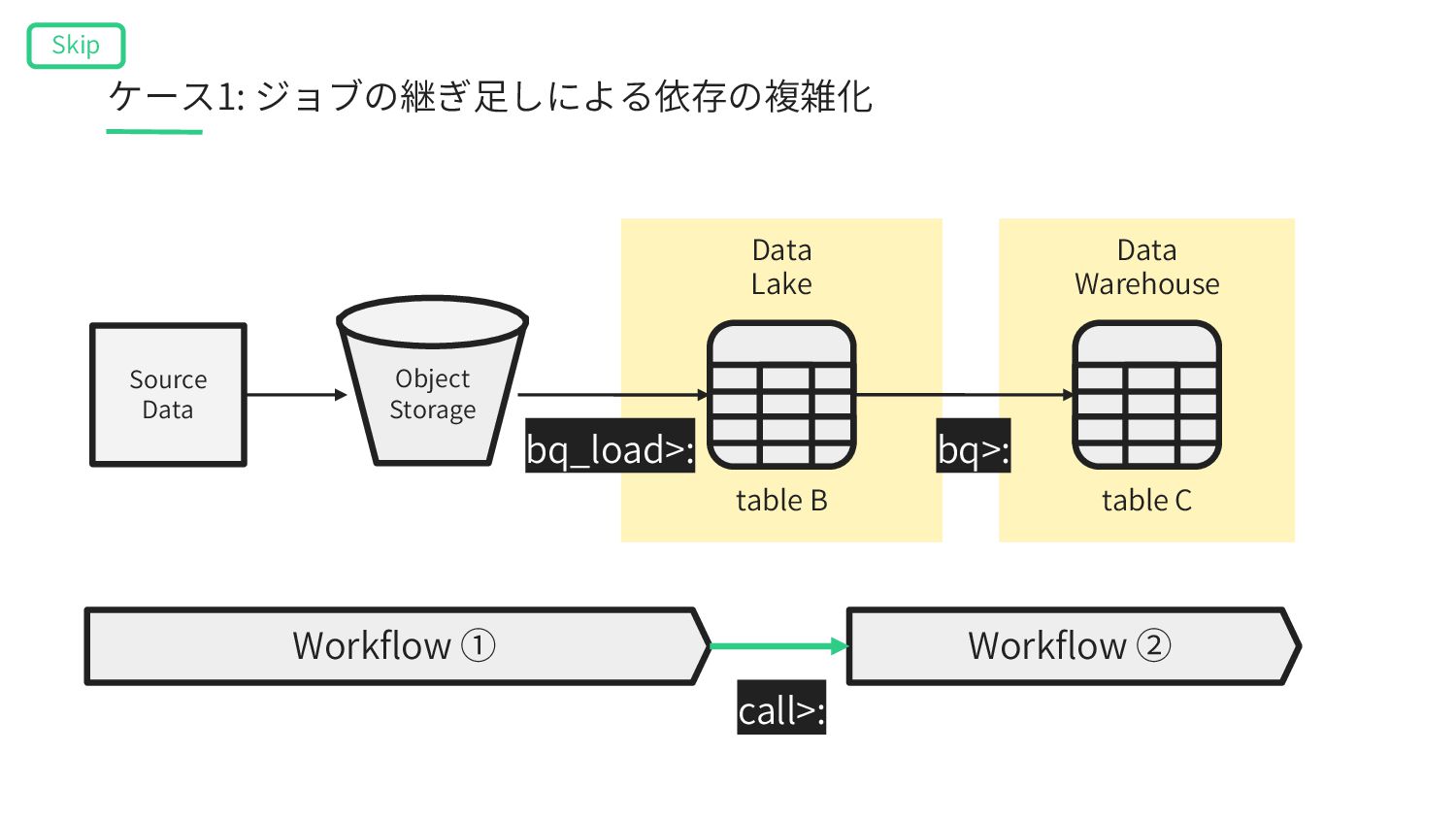
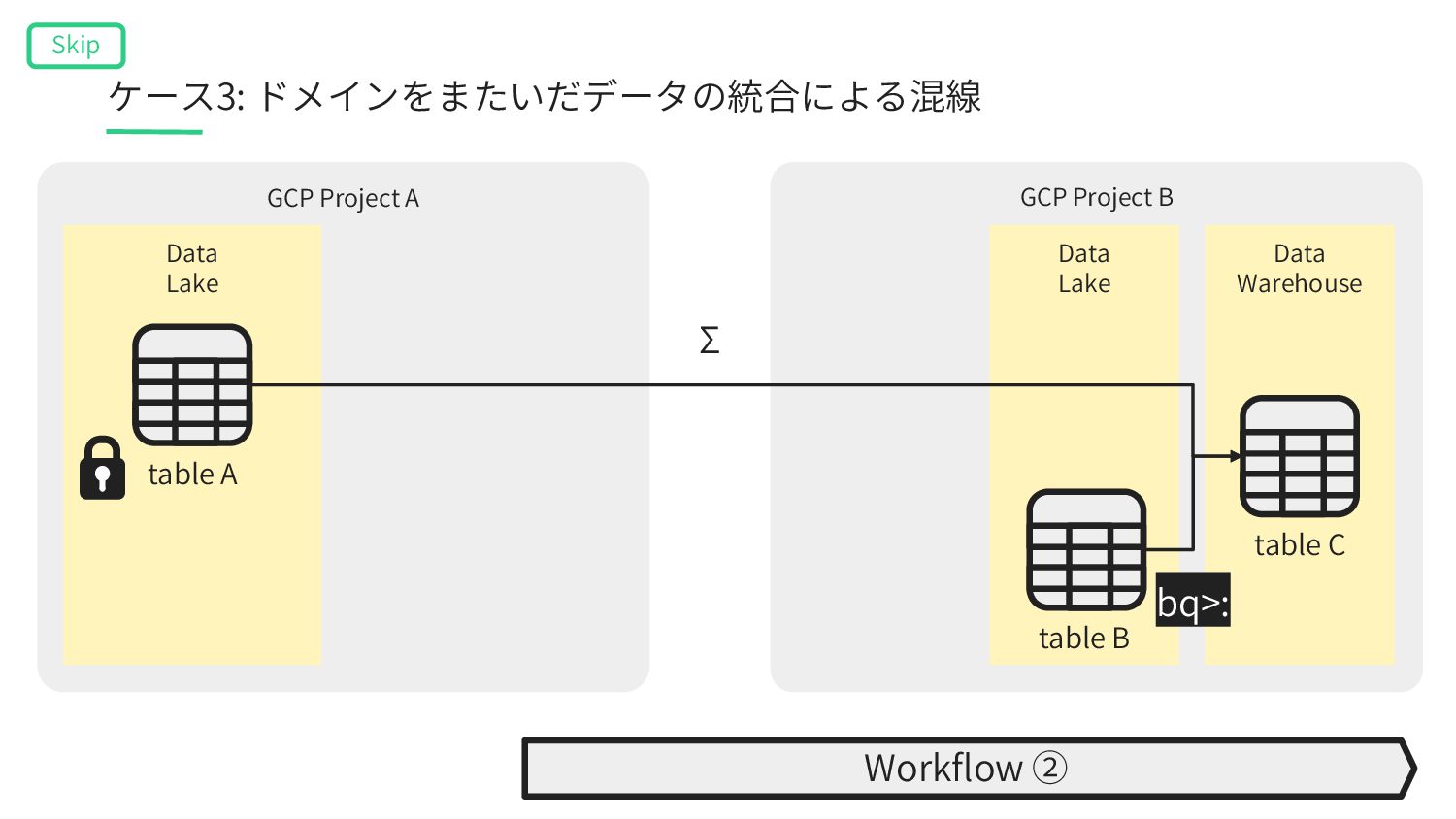
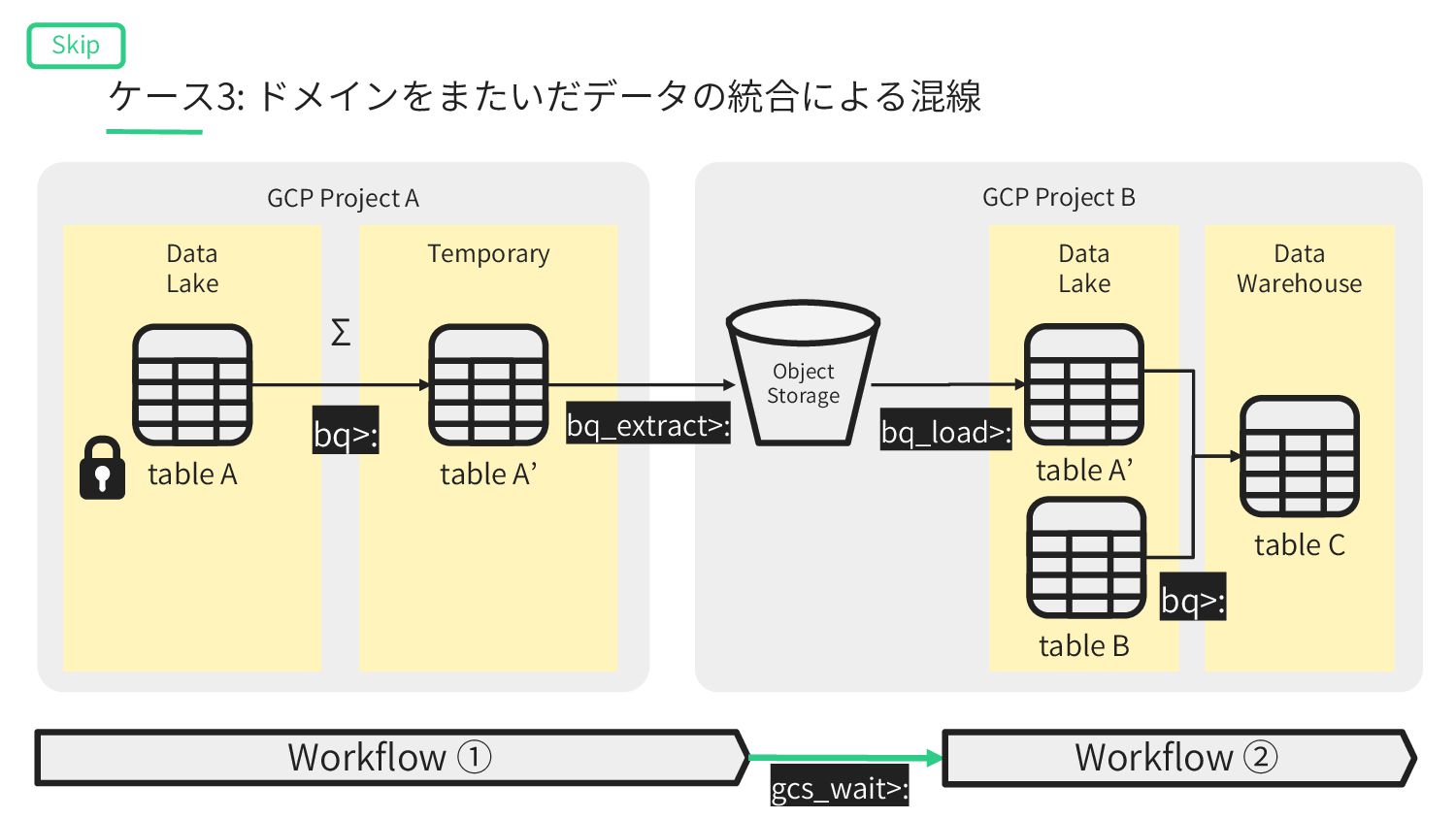
A’ table B Data Warehouse table C Data Lake Workflow ① table A’ gcs_wait>: Workflow ② bq_extract>: table A bq>: bq>: Σ bq_load>: Object Storage ケース3: ドメインをまたいだデータの統合による混線 Skip
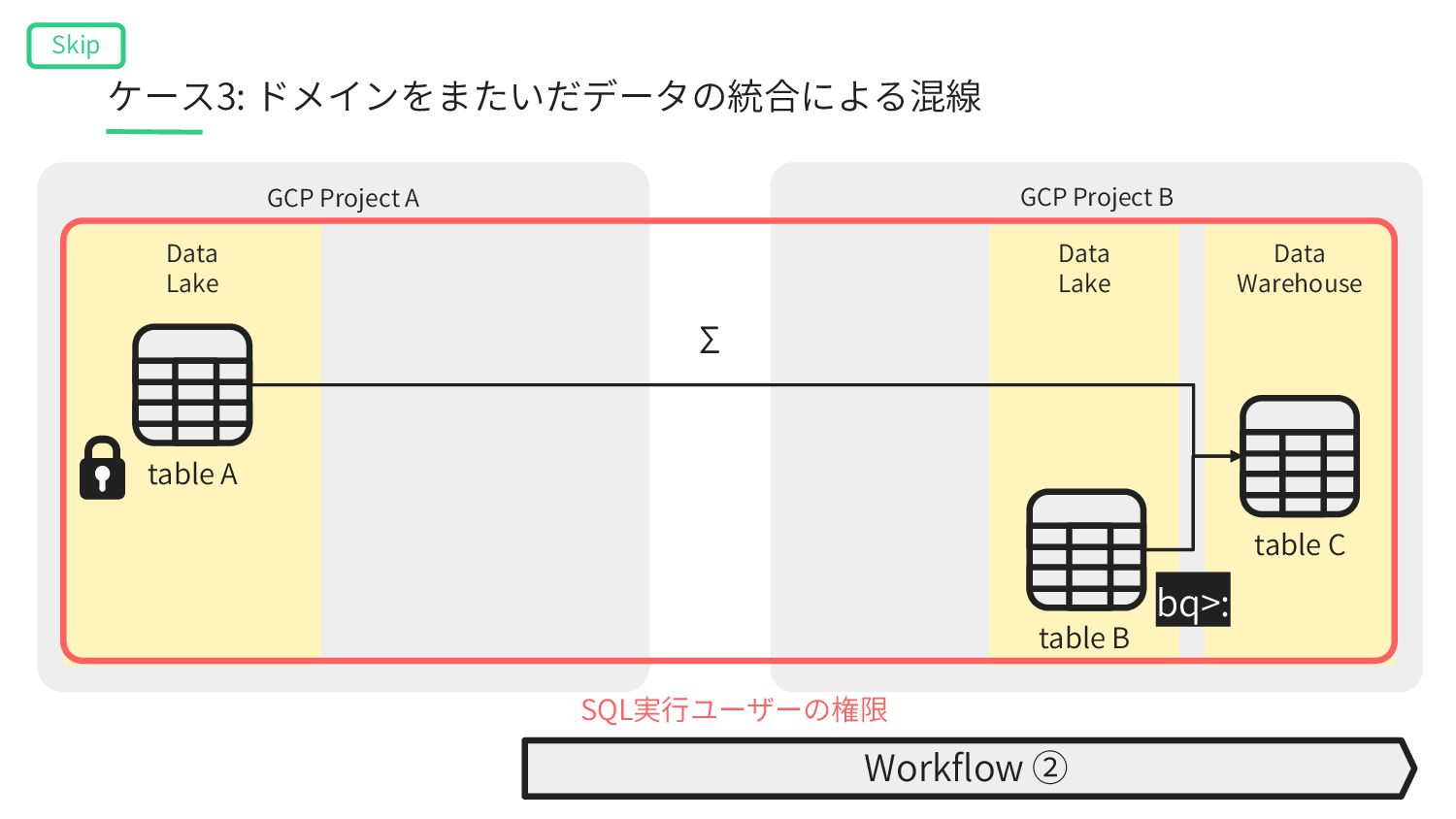
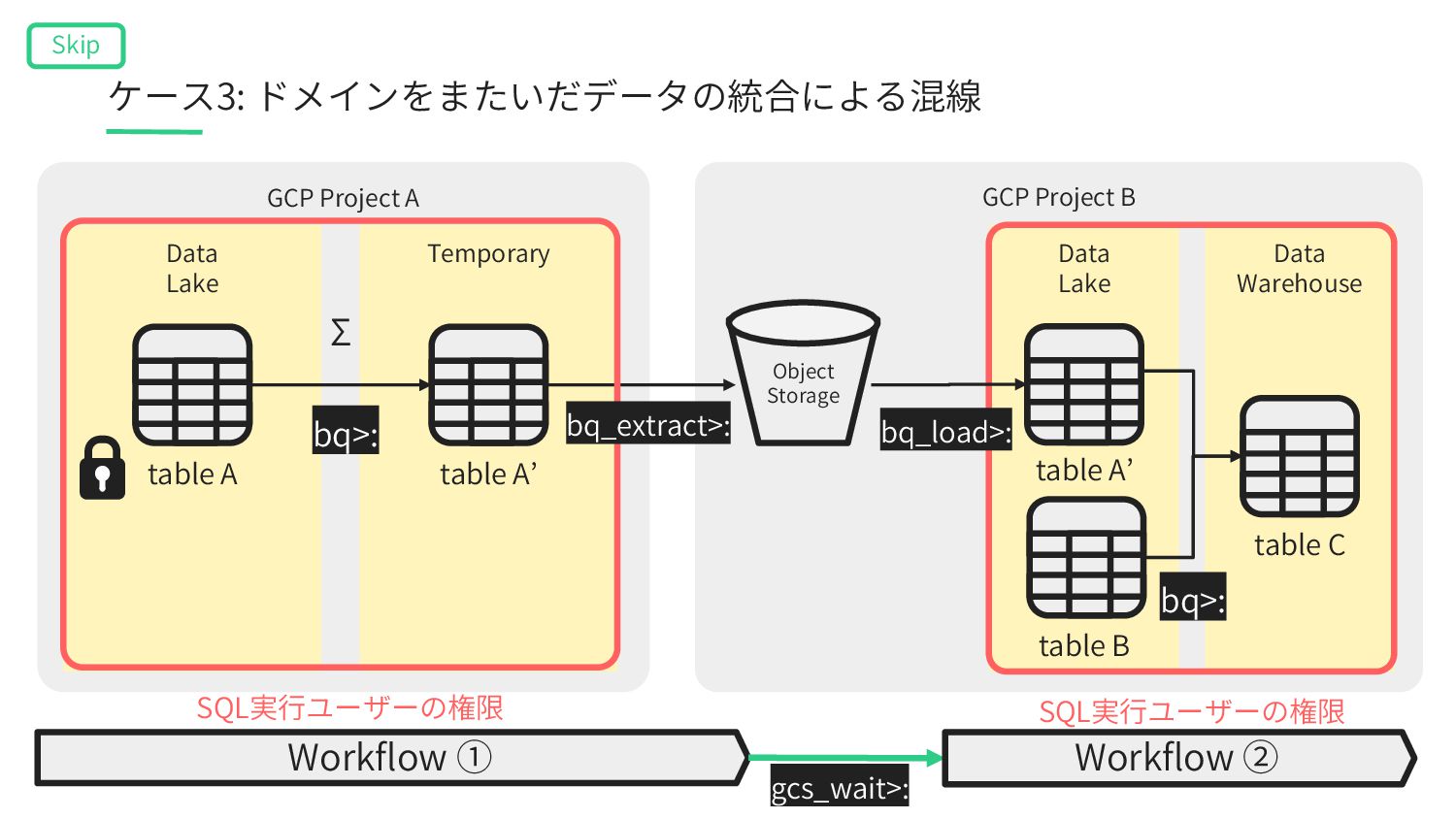
Lake table A’ table B Data Warehouse table C Workflow ① table A’ gcs_wait>: Workflow ② table A bq>: bq>: Σ Object Storage SQL実⾏ユーザーの権限 SQL実⾏ユーザーの権限 bq_extract>: ケース3: ドメインをまたいだデータの統合による混線 Skip bq_load>:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}