Share
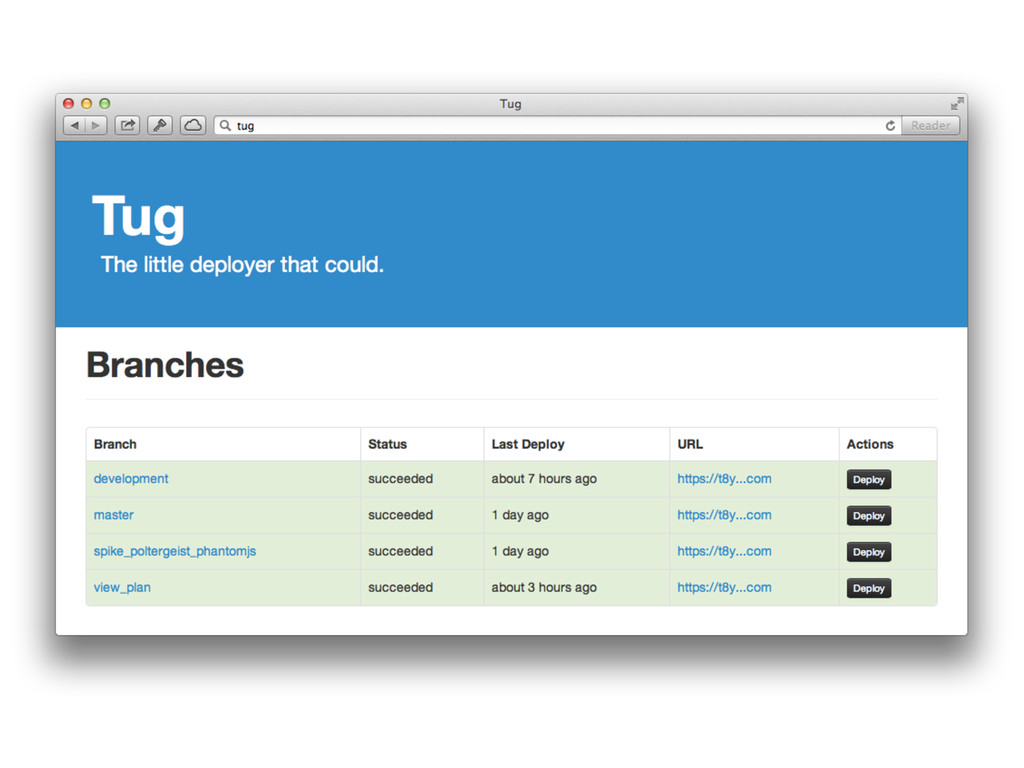
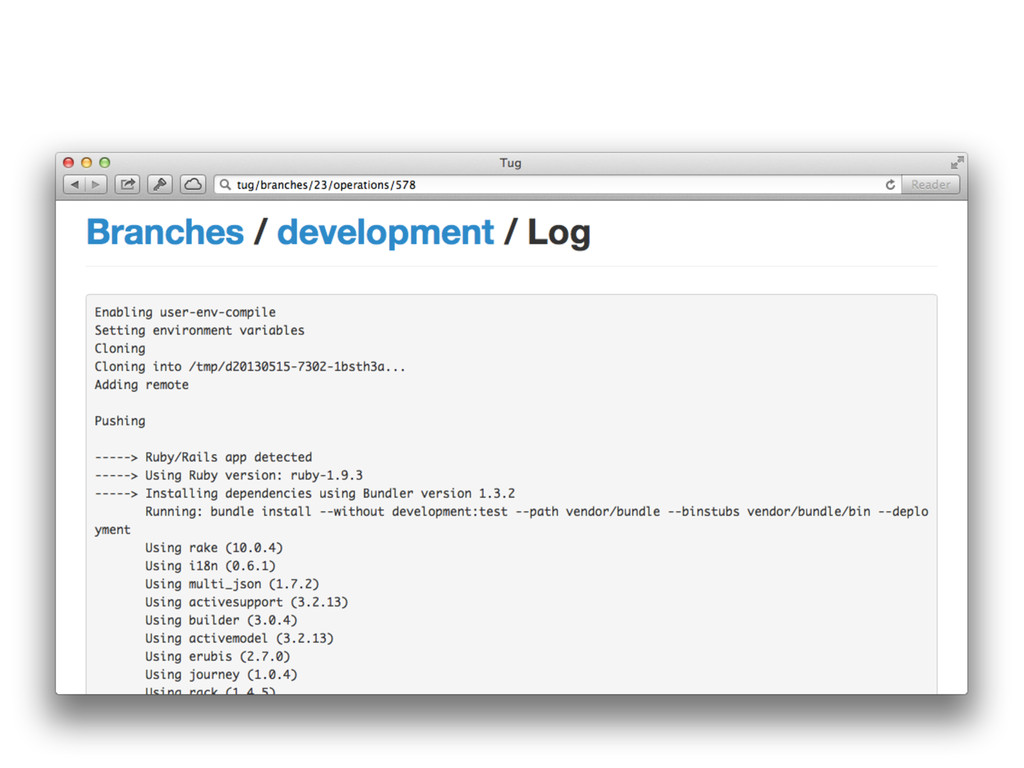
My lightning talk was given at Sydney DevOps on the 16 May, 2013. It was based on an earlier blog post (http://tatey.com/2013/05/06/experimenting-with-continuous-deployment-for-feature-branches/)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}