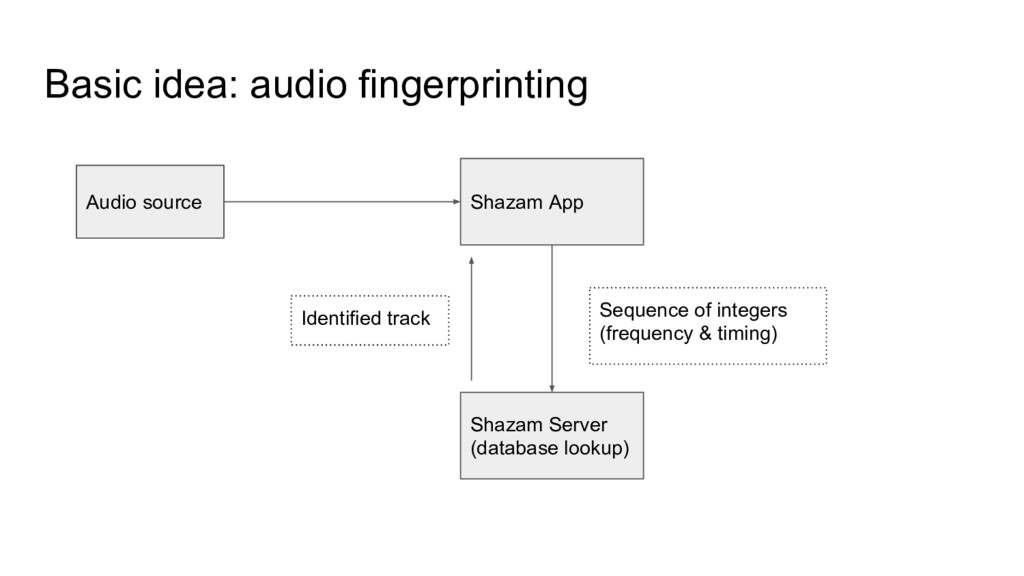
key off the pair (time_offset, frequency): database would be enormous, and processing would be terrible. • Frequency alone leads to many prospective matches.
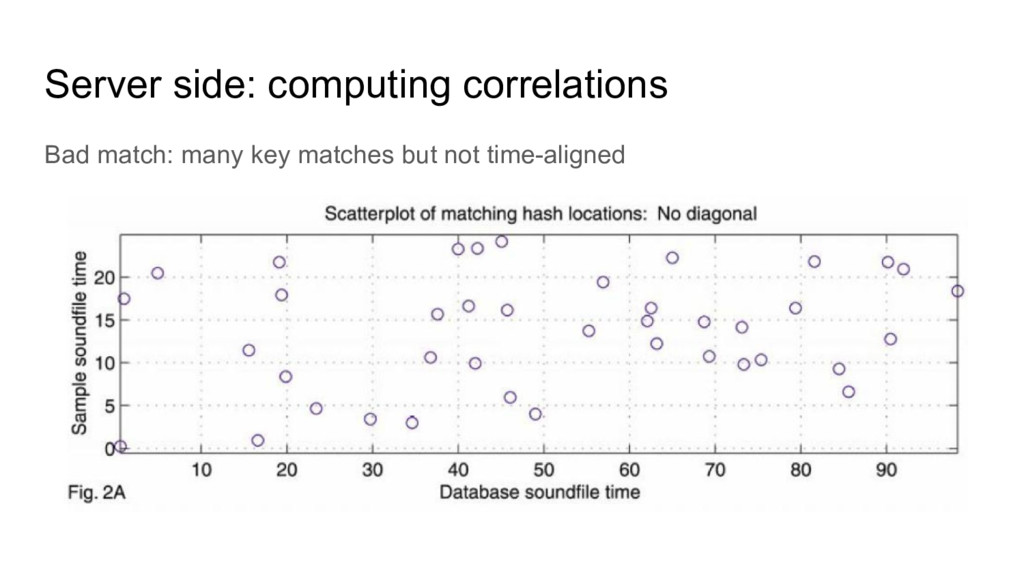
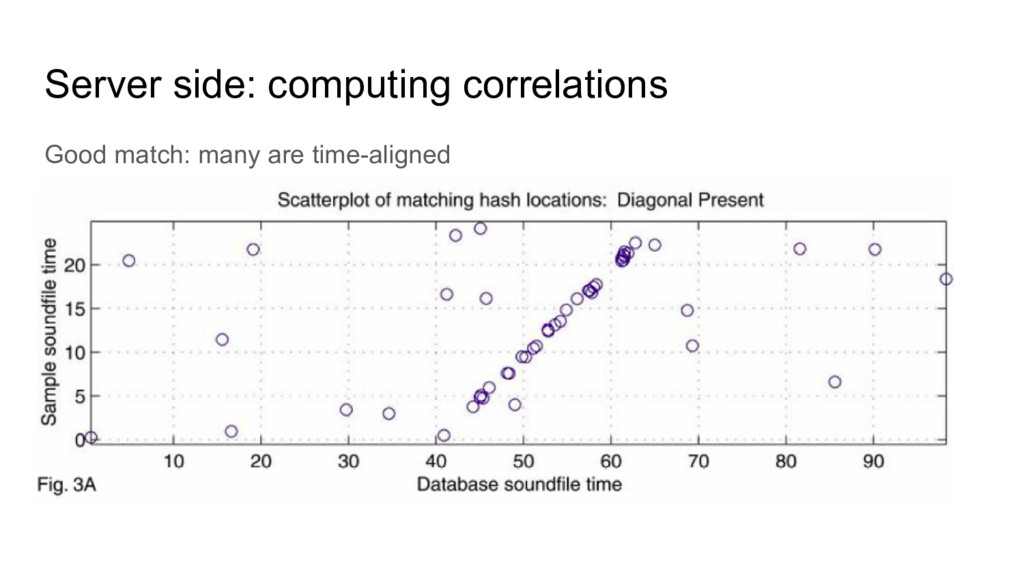
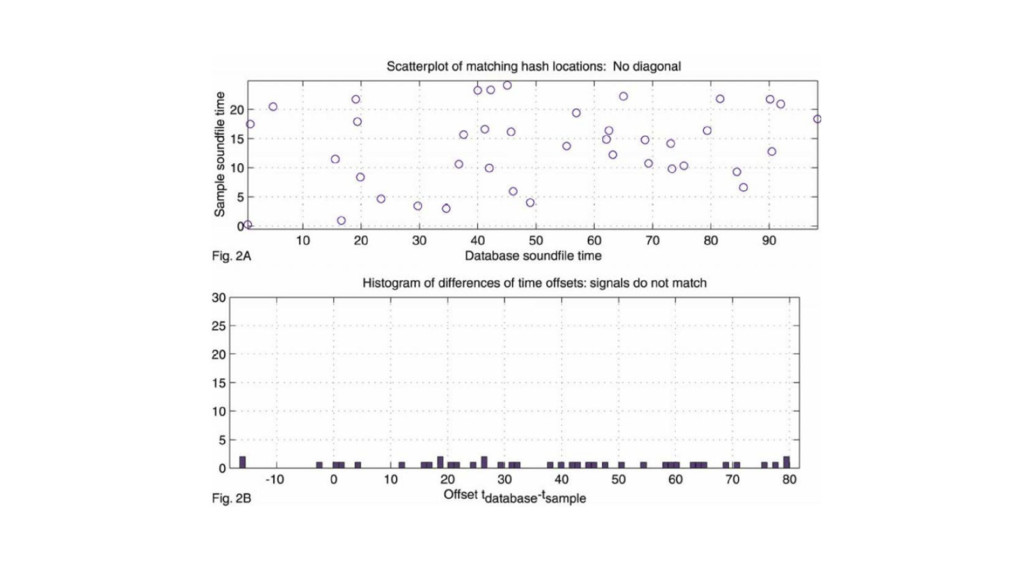
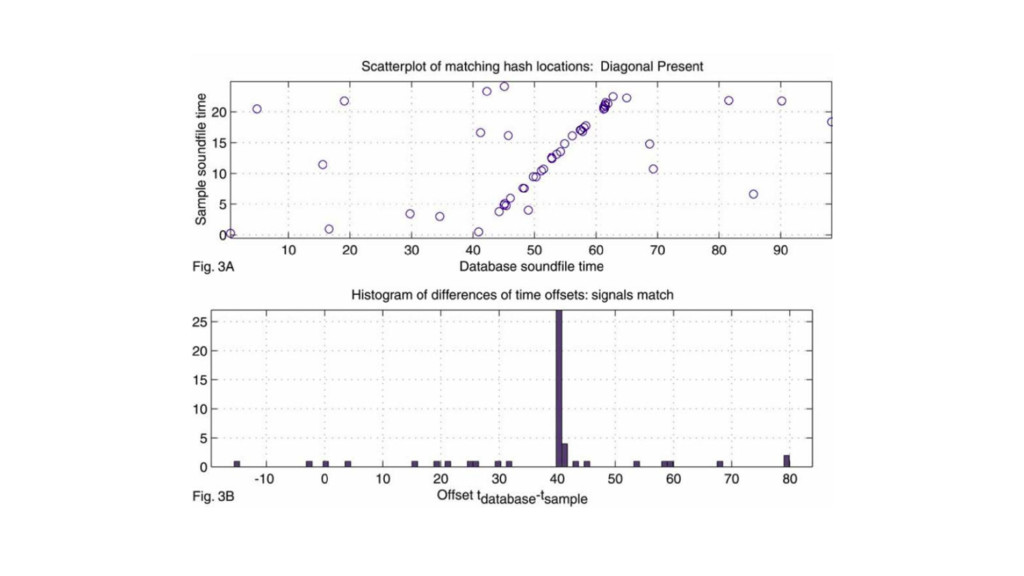
R^2 or whatnot (time complexity anyone?) • Much simpler approach: histograms (time complexity anyone?): ◦ Denote { t i } set of time offsets from sample, { t’ i } time offsets from database. ◦ If from same song, t i = t’ i + c for some constant c. ◦ Form histograms of { t i - t’ i } and look for peaks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Thank you! [email protected] • “An industrial-strength audio search algorithm”,](https://files.speakerdeck.com/presentations/757e987a4e314a44abcea7033199f04f/slide_30.jpg){kind=link}