def index_of_nearest(q, points): return min((sq_distance(q, p), i) for i, p in enumerate(points))[1] def nearest_center(points, centers): return [index_of_nearest(p, centers) for p in points] Example: Nearest Neighbor
for specific patterns of parallelism • Programmer (re)writes program to fit the pattern. Programming Language • Semantics of calculation entirely defined by source- code • Compiler and Runtime are responsible for efficient execution.
to integrate lots of different systems. • Simpler code • Much more expressive • Programs are easier to understand. • Cleaner failure modes • Much deeper optimizations are possible. Cons • More code • Program meaning obscured by implementation details • Hard to debug when something goes wrong • Very hard to implement
pattern that can be implemented in an API can be recognized in a language. • Language-based systems have the entire source code, so they have more to work with than API based systems. • Can measure behavior at runtime and use this to optimize.
zip(p1, p2)) def index_of_nearest(q, points): return min((sq_distance(q, p), i) for i, p in enumerate(points))[1] def nearest_center(points, centers): return [index_of_nearest(p, centers) for p in points]
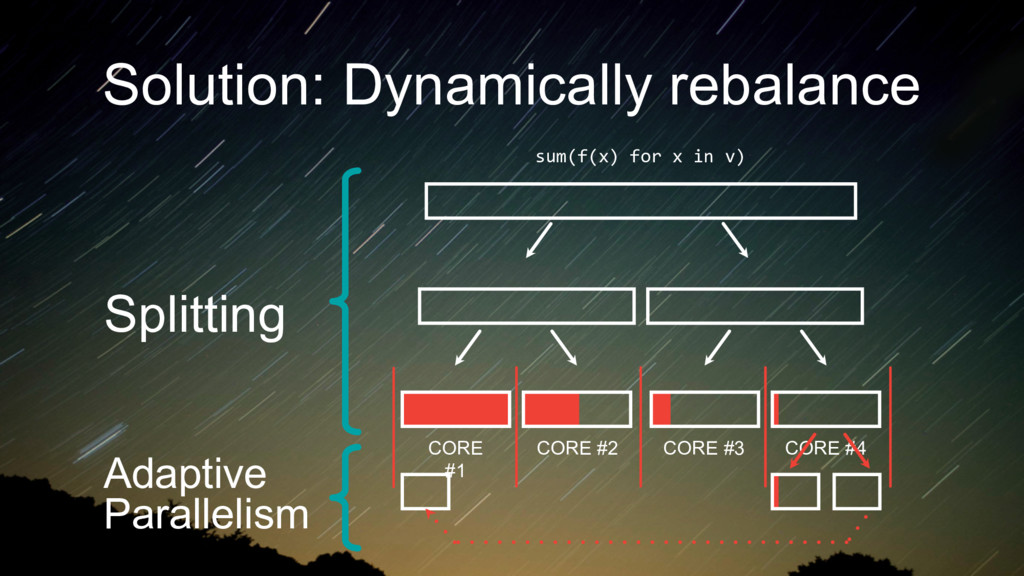
different code for each of these different situations. The source code contains the necessary structure. The key is to defer decisions to runtime, when the system can actually see how big the datasets are.
the programmer • Code is more readable • Code becomes more reusable. • Use the language the way it was intended: For instance, in Python, the “row” objects can be anything that looks like a list.
partition your data into chunks. • If you are running a complex task, the runtime may be really long for a small subset of chunks. You’ll end up waiting a long time for that last mapper. • If your tasks allocate memory, you can run out of RAM and crash.
to interrupt running tasks as they’re executing. • Adding support for this to an API makes it much more complicated to use. • This is much easier to do with compiler support.
• There is lots of parallelism in each iteration • But you also want to search over many hyperparameters With API-based approaches, you have to manage this yourself, either by constructing a graph of subtasks, or figuring out how to flatten your workload into something that can be map-reduced.
params = model.update_params(learning_rate, params) return params fits = [[fit_model(rate, model, params) for rate in learning_rates] for model in models] Solution: infer parallelism from source
of Python that restricts mutability (but we're relaxing this). • Built a JIT compiler that can “pop” code back into the interpreter • Can move sets of stack frames from one machine to another • Can rewrite selected stack frames to use futures if there is parallelism to exploit. • Carefully track what data a thread is using. • Dynamically schedule threads and data on machines to optimize for cache locality.
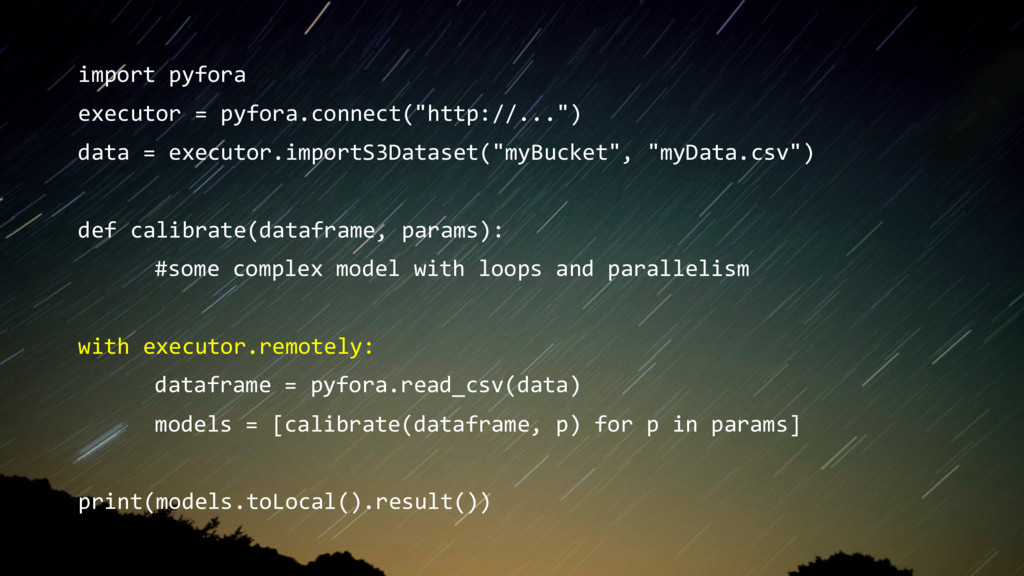
calibrate(dataframe, params): #some complex model with loops and parallelism with executor.remotely: dataframe = pyfora.read_csv(data) models = [calibrate(dataframe, p) for p in params] print(models.toLocal().result())
{kind=link}
{kind=link}
![def sq_distance(p1, p2): return sum((c[0]-c[1])**2 for c in zip(p1, p2))](https://files.speakerdeck.com/presentations/0790ad0124fd4dbca259e297aa3748d7/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example: Nearest Neighbors def sq_distance(p1,p2): return sum((c[0]-c[1])**2 for c in](https://files.speakerdeck.com/presentations/0790ad0124fd4dbca259e297aa3748d7/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}