all data from run X, from run X, give me only give me only specific events specific events that that fulfill certain criteria. fulfill certain criteria. I will I will analyse analyse this sample this sample manually manually Rinse and Repeat
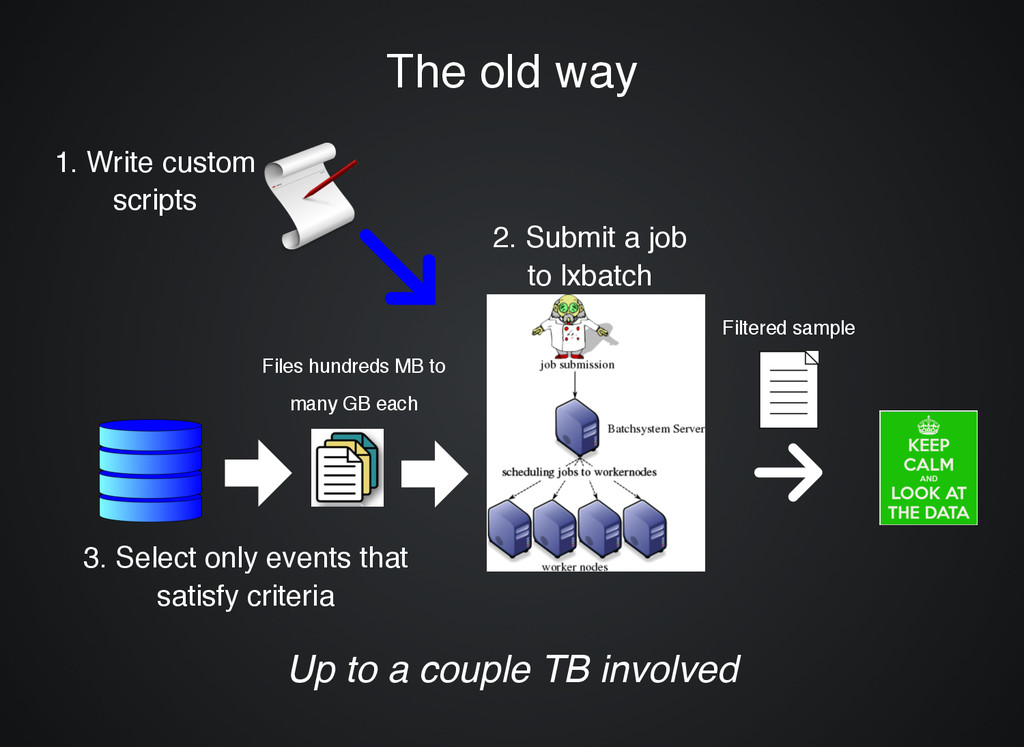
2. Submit a job to lxbatch 3. Select only events that satisfy criteria Files hundreds MB to many GB each Filtered sample Up to a couple TB involved Up to a couple TB involved
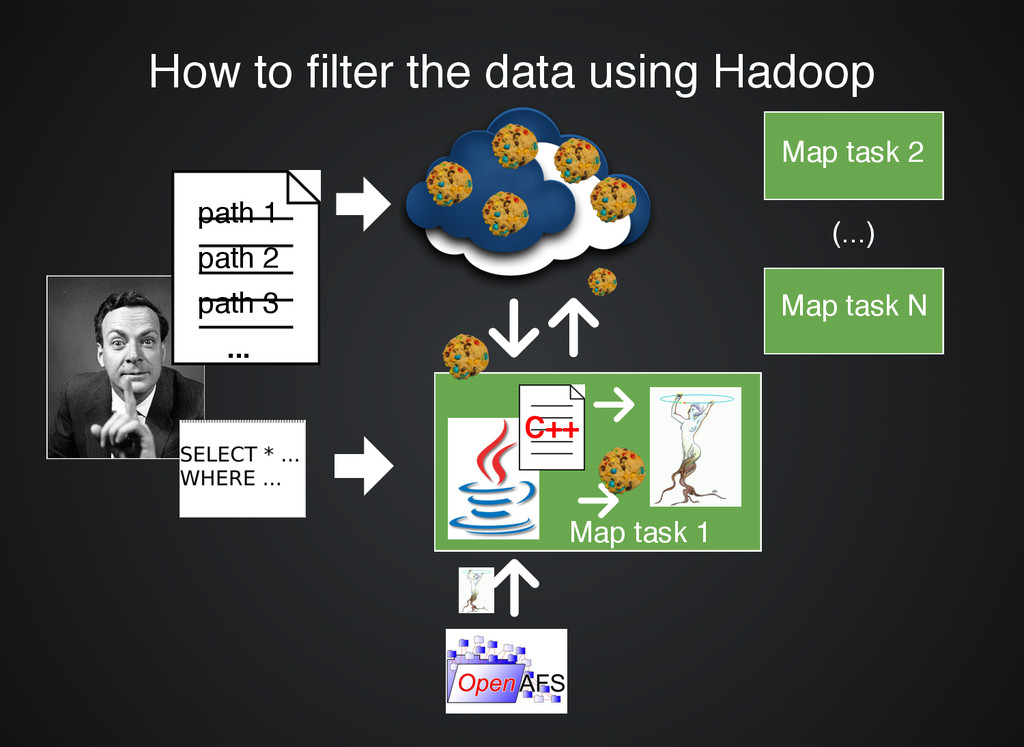
Job 1 1. CASTOR, give me files 1..100 2. Downloading file 1 from disk 3. ... 4. Downloading file 99 from disk 5. Bad luck, file 100 is on a tape 6. File 100 loaded onto a disk 7. Downloading file 100 Job 2 Job 2 1. CASTOR, give me files 1..100 2. ... 3. ... 4. ... 5. Bad luck, file 100 is on a tape, again Sometime later... Sometime later...
15 years of development 15 years of development 1,762,865 lines of code 1,762,865 lines of code 46,308 commits 46,308 commits Object-oriented libraries for: data analysis statistics visualization simulation reconstruction event display DAQ C++ Interpreter Suite CINT - the interpreter close enough to standard C++ extensions rich RTTI some syntactic sugar ACLiC - automatic compiler
idea ever the command language, the command language, the scripting language the scripting language the programming language the programming language are all C++ are all C++ Feature rich Extremely performant Specialized storage formats
idea ever the command language, the command language, the scripting language the scripting language the programming language the programming language are all C++ are all C++
"C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do, it C++ makes it harder, but when you do, it blows away your whole leg." blows away your whole leg." ― Bjarne Stroustrup ― Bjarne Stroustrup "Especially, when you use it as an interpreted "Especially, when you use it as an interpreted language with reflection." language with reflection." ― Captain Obvious ― Captain Obvious
1. Load once Load once, analyze many times , analyze many times 2. Optimal Optimal granularity of jobs granularity of jobs 3. Scalable Scalable 4. Little Little network and I/O network and I/O overhead overhead 5. Failure Failure tolerant tolerant 6. Takes care of Takes care of 2-5 automatically 2-5 automatically 7. Requires Requires me to write me to write less code less code
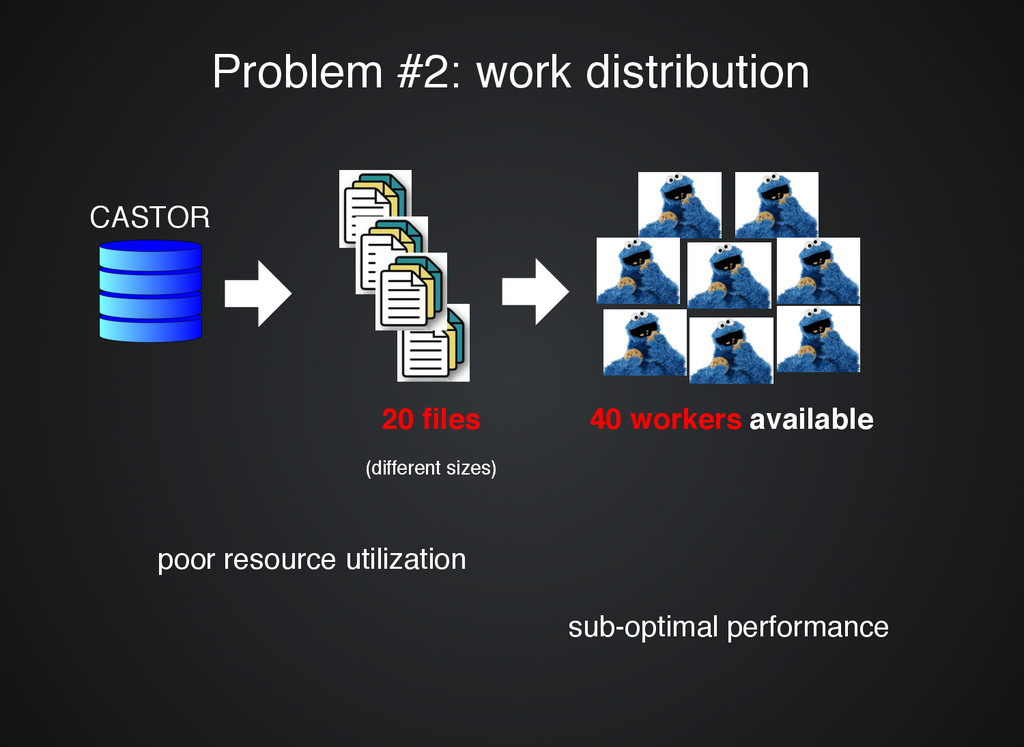
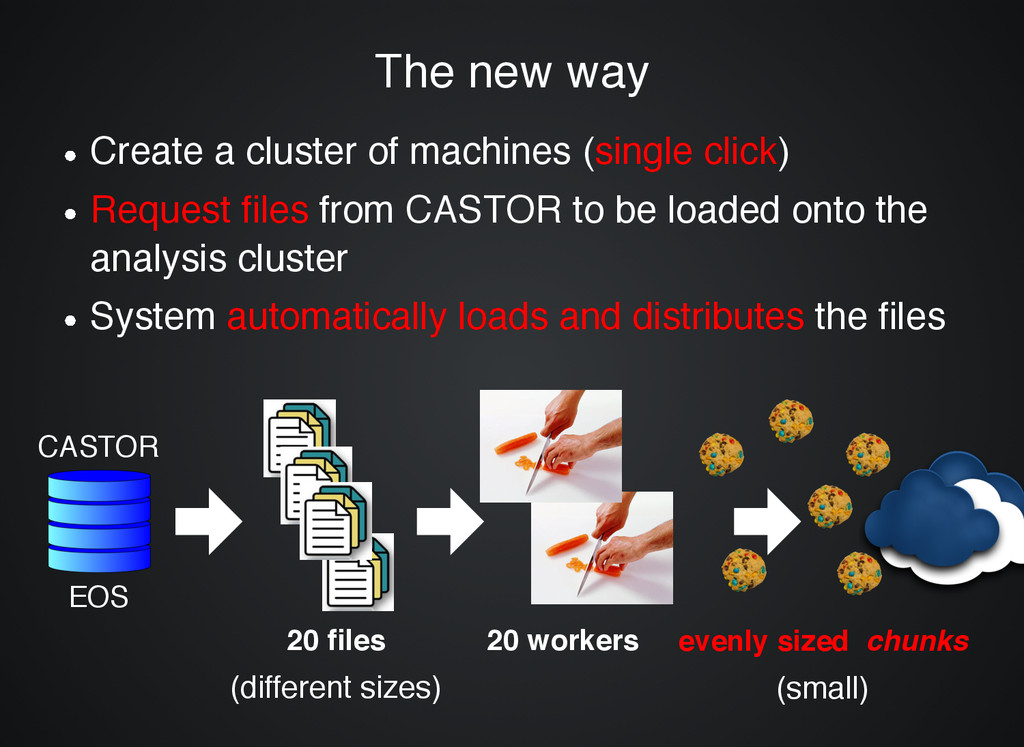
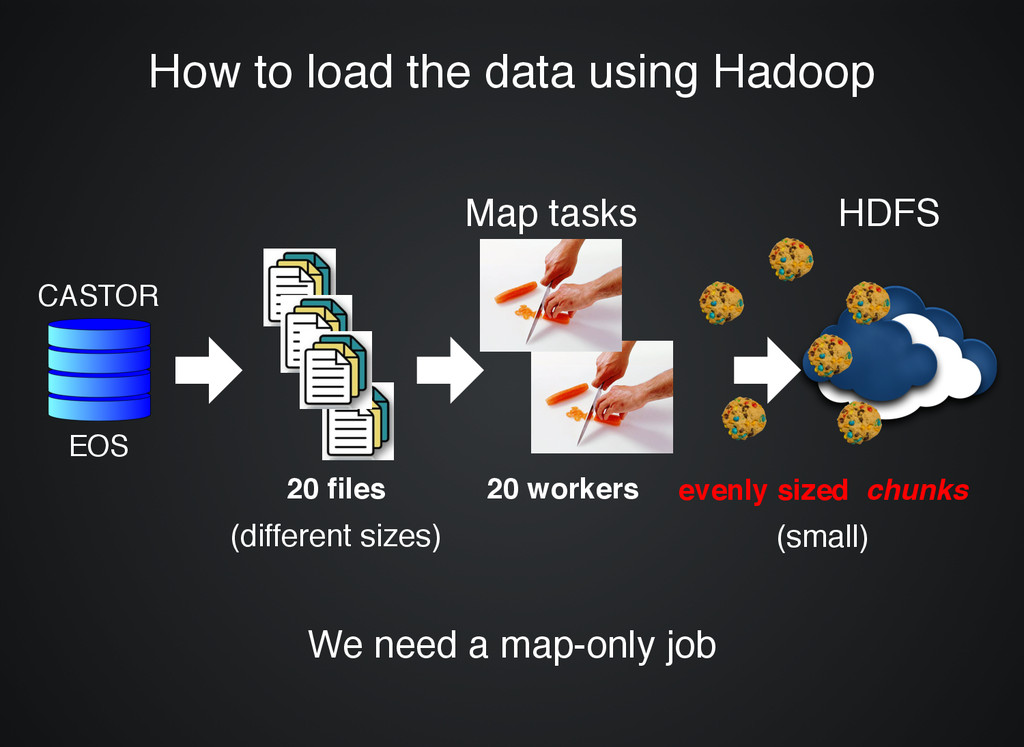
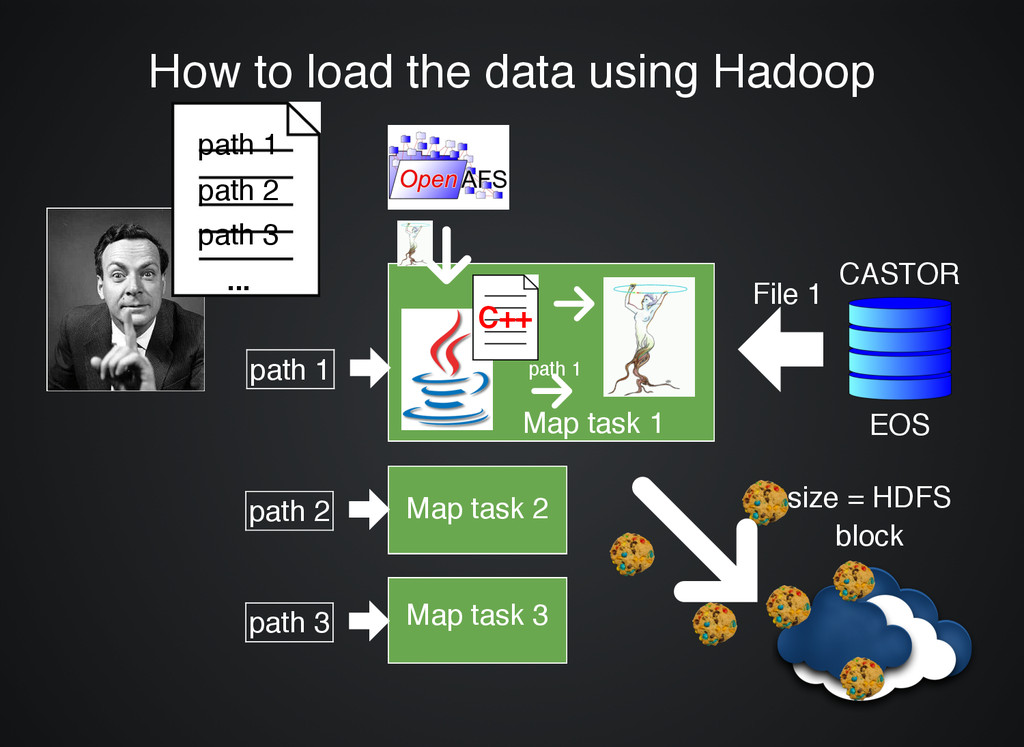
machines ( Create a cluster of machines (single click single click) ) Request files Request files from CASTOR to be loaded onto the from CASTOR to be loaded onto the analysis cluster analysis cluster System System automatically loads and distributes automatically loads and distributes the files the files CASTOR 20 files (different sizes) 20 workers evenly sized chunks (small) EOS
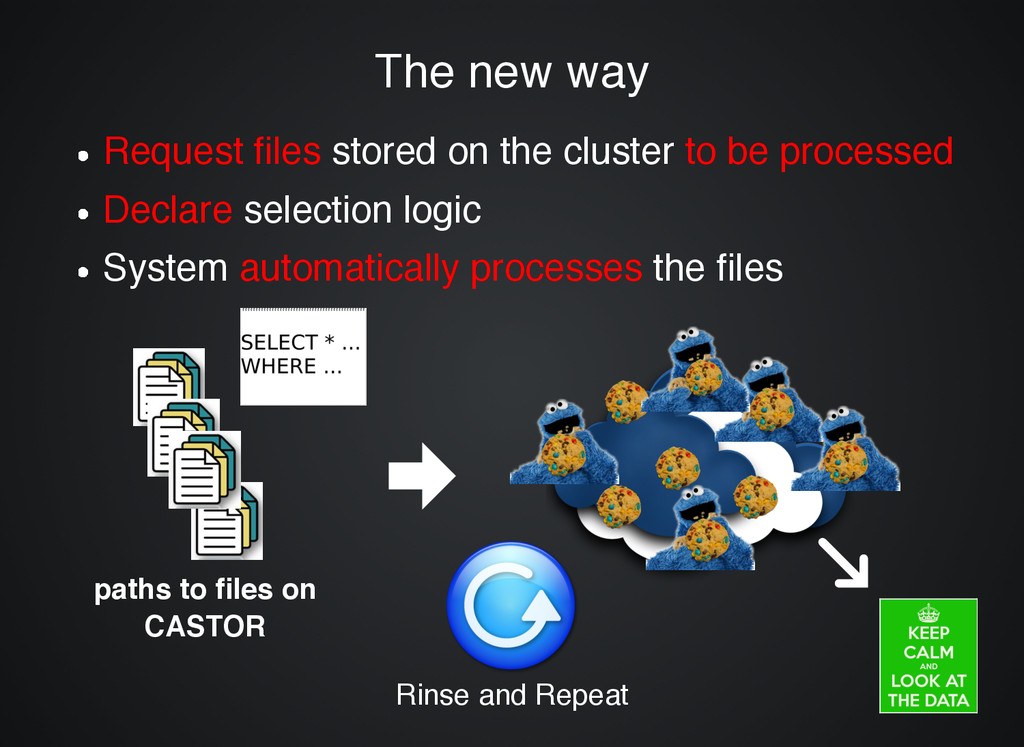
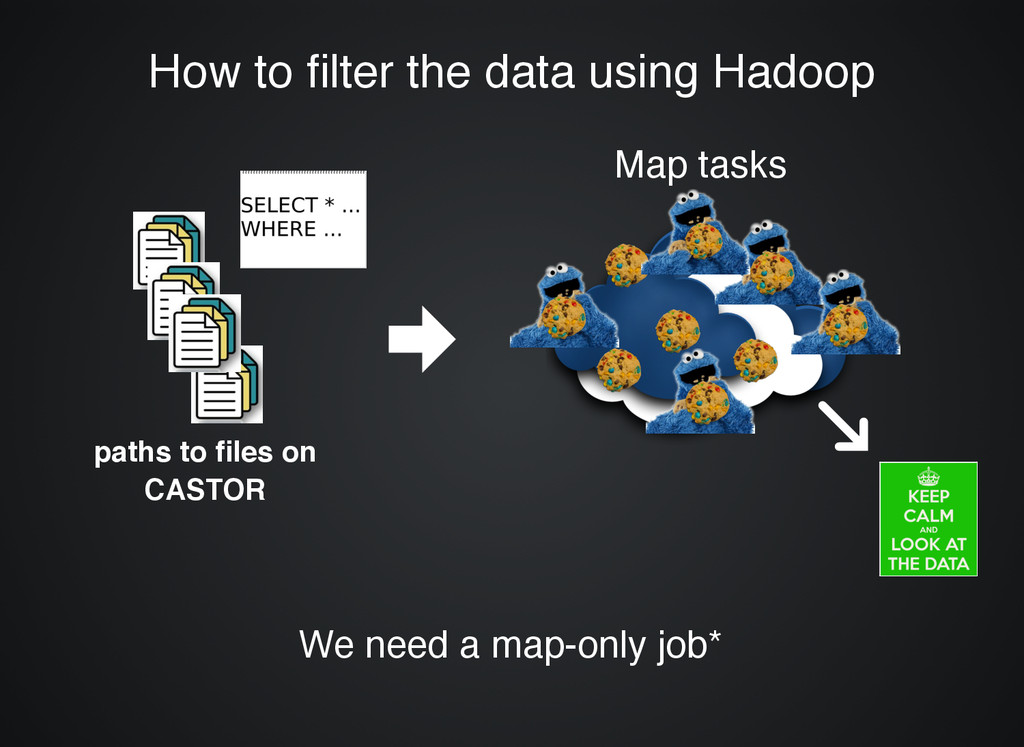
stored on the cluster stored on the cluster to be processed to be processed Declare Declare selection logic selection logic System System automatically processes automatically processes the files the files Rinse and Repeat paths to files on CASTOR
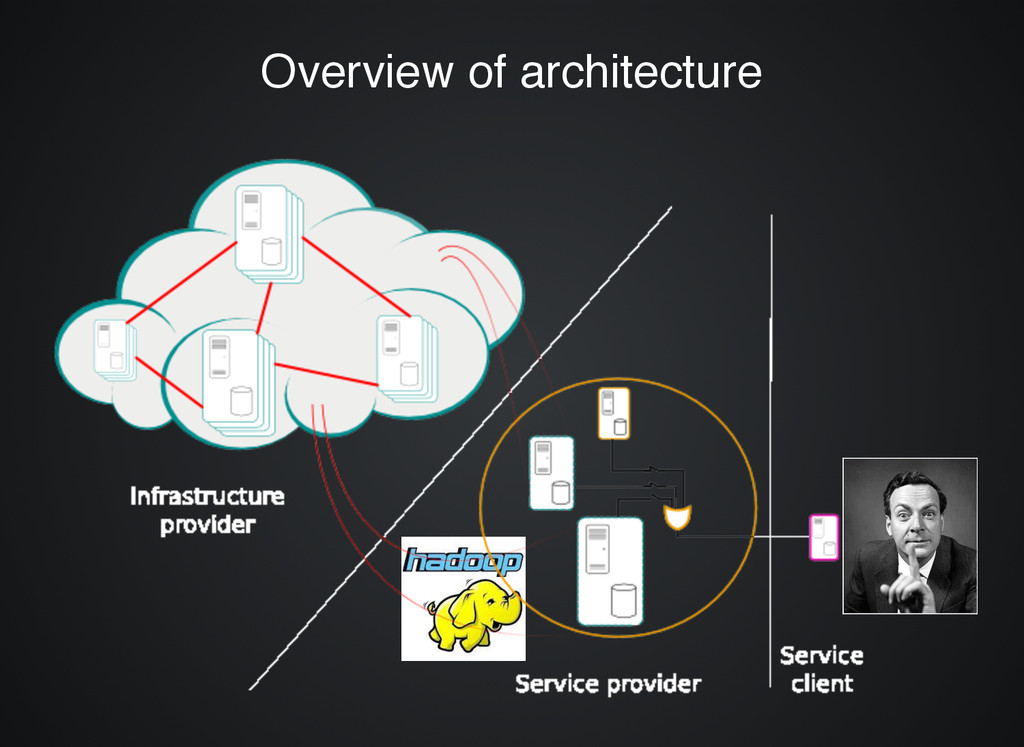
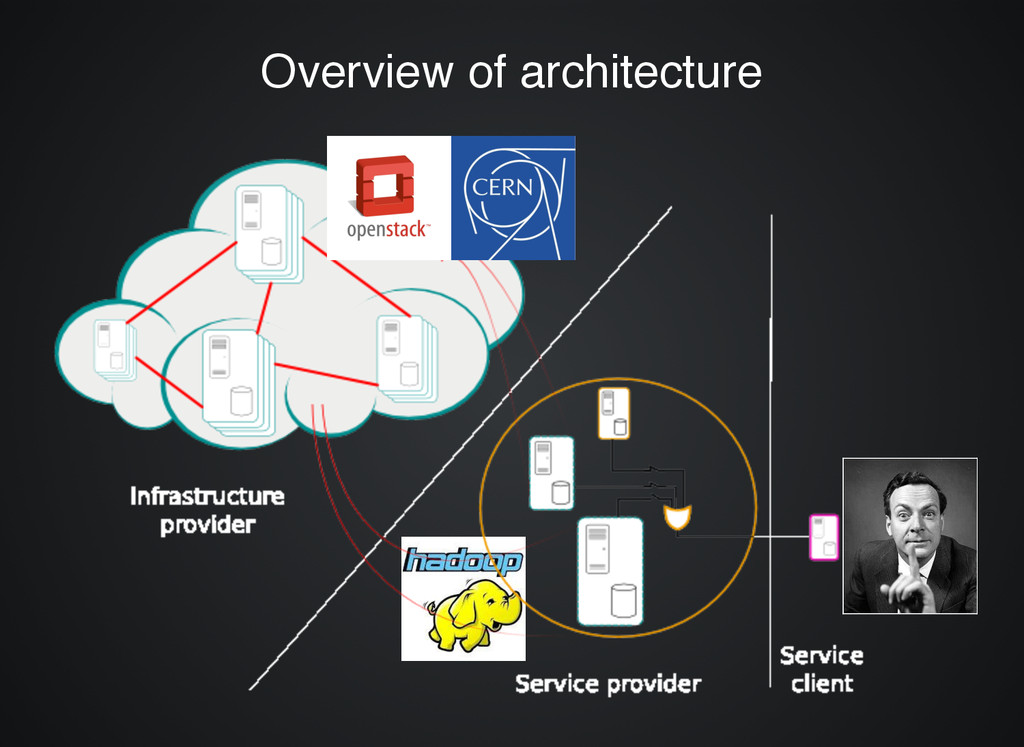
Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware. fault tolerant fault tolerant scalable scalable designed for data locality designed for data locality HDFS: A distributed file system that provides high-throughput access to application data. MapReduce: A YARN-based system for parallel processing of large data sets.
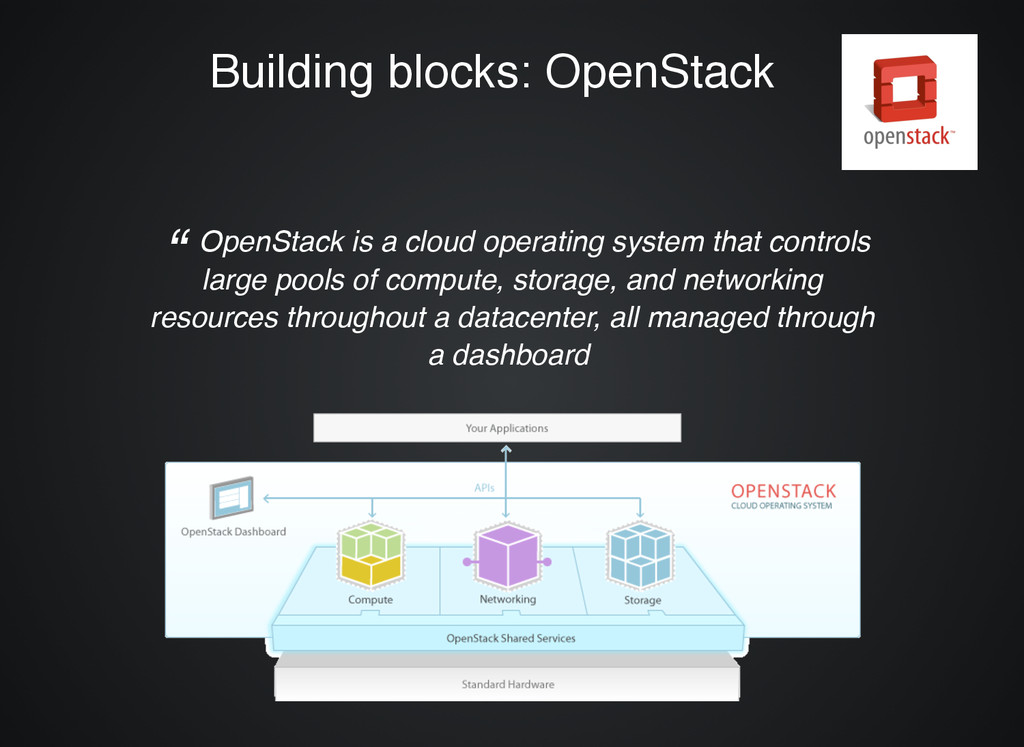
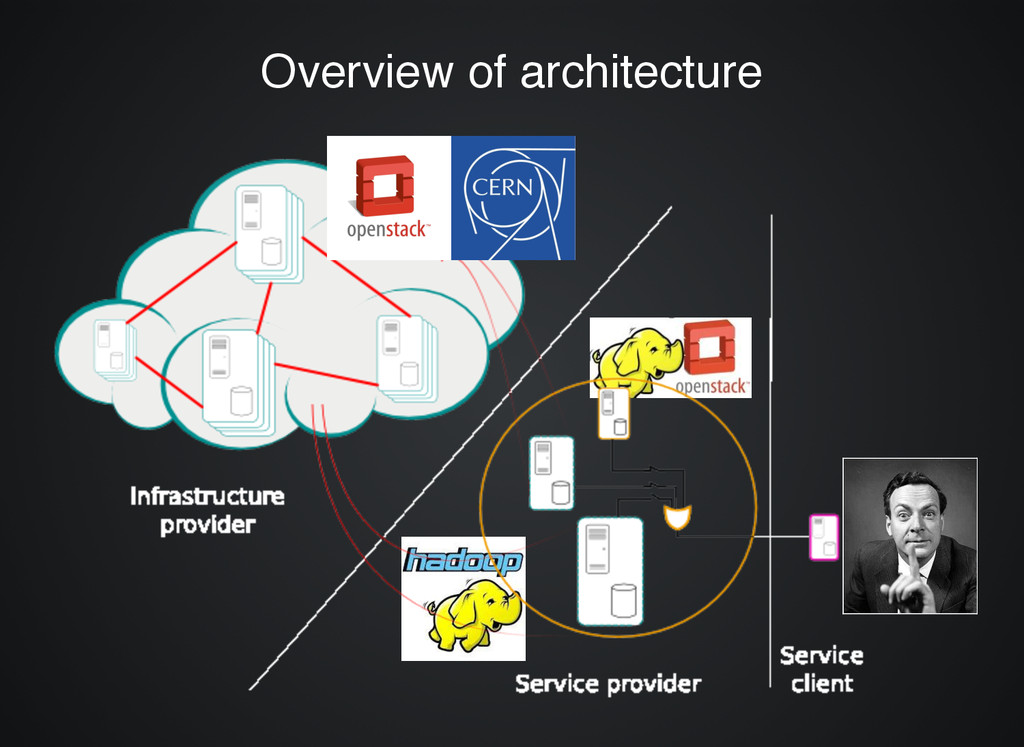
cloud operating system that controls large pools of compute, storage, and networking resources throughout a datacenter, all managed through a dashboard
vs vs Nova Nova Amazon Amazon S3 S3 vs vs Swift Swift Elastic Block Storage Elastic Block Storage vs vs Cinder Cinder Amazon Amazon VPC VPC vs vs Neutron Neutron Amazon Amazon CloudWatch CloudWatch vs vs Ceilometer Ceilometer Elastic MapReduce Elastic MapReduce vs vs Sahara Sahara AWS AWS Console Console vs vs Horizon Horizon
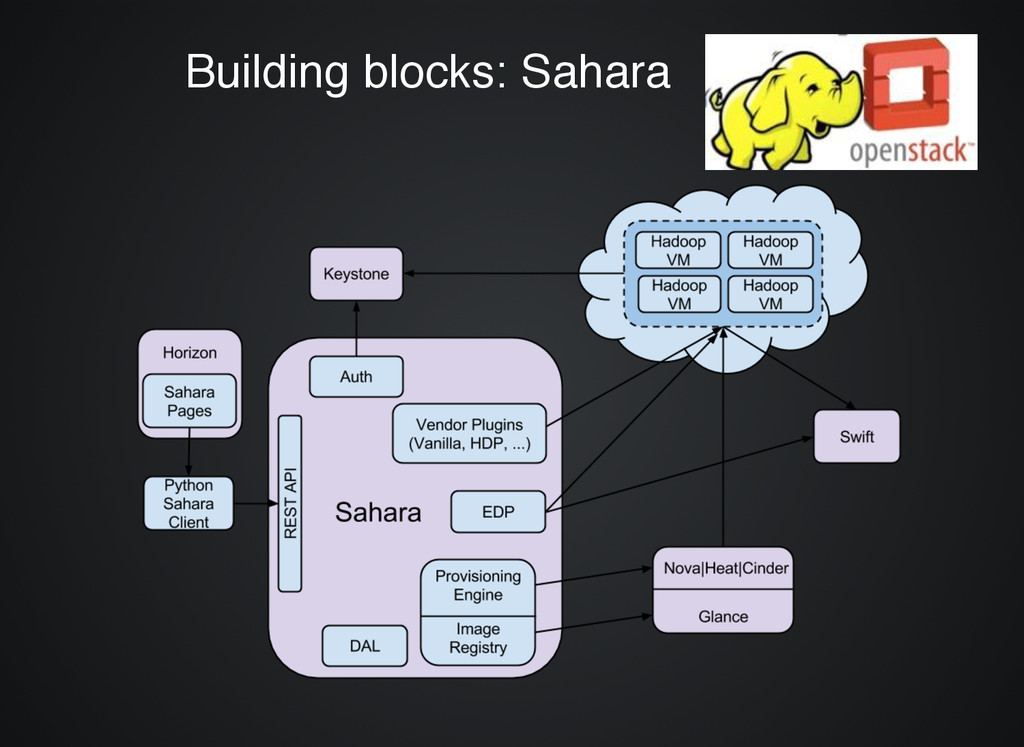
OpenStack data processing plugin, which provides a simple means to provision a Hadoop cluster on top of OpenStack. template, launch, manage Hadoop clusters with a single click (or a command) add / remove nodes submit, execute and track Hadoop jobs
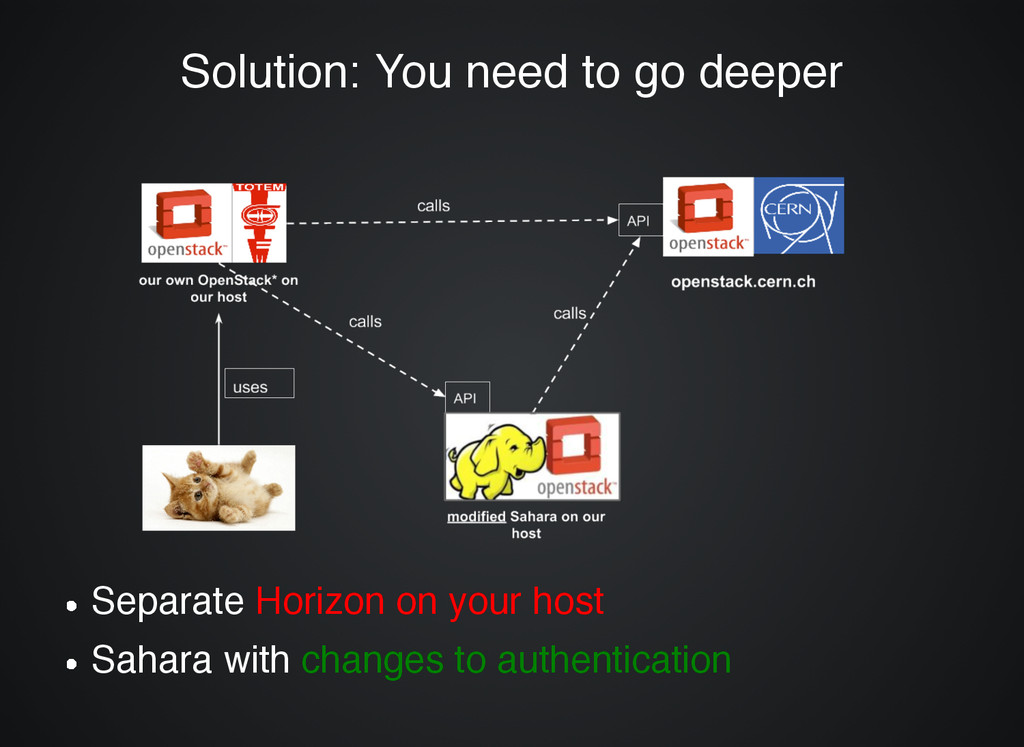
no Sahara How do you use Sahara on How do you use Sahara on OpenStack that ... OpenStack that ... ... does not support Sahara? ... does not support Sahara?
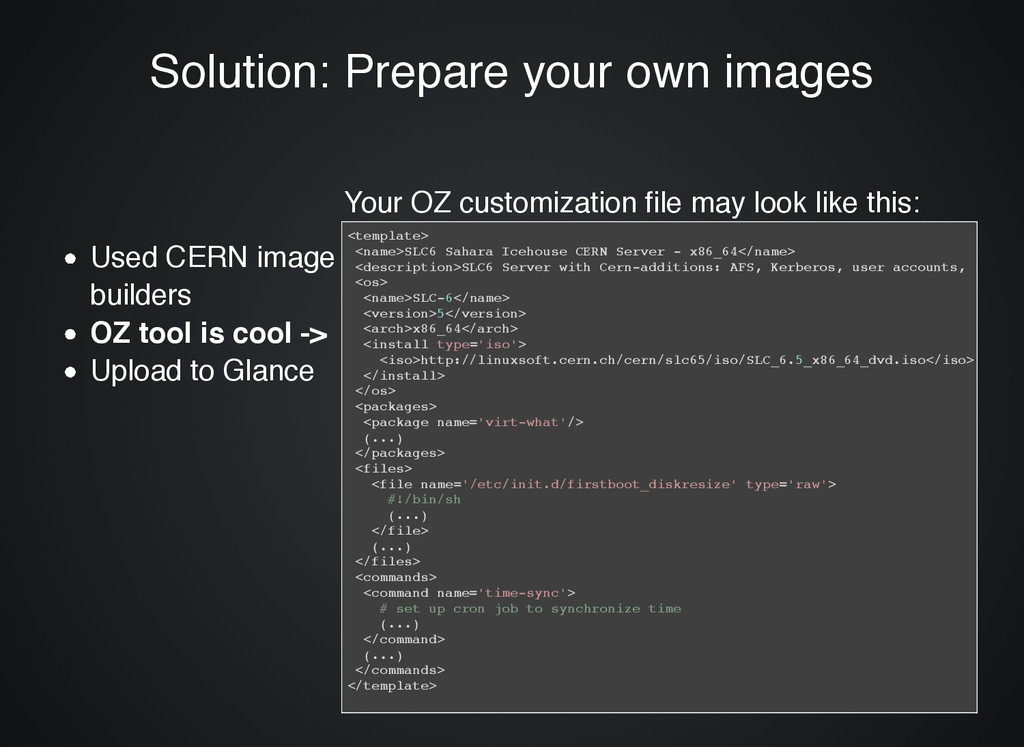
<template> <name>SLC6 Sahara Icehouse CERN Server - x86_64</name> <description>SLC6 Server with Cern-additions: AFS, Kerberos, user accounts, ... and <os> <name>SLC-6</name> <version>5</version> <arch>x86_64</arch> <install type='iso'> <iso>http://linuxsoft.cern.ch/cern/slc65/iso/SLC_6.5_x86_64_dvd.iso</iso> </install> </os> <packages> <package name='virt-what'/> (...) </packages> <files> <file name='/etc/init.d/firstboot_diskresize' type='raw'> #!/bin/sh (...) </file> (...) </files> <commands> <command name='time-sync'> # set up cron job to synchronize time (...) </command> (...) </commands> </template> Used CERN image builders OZ tool is cool -> Upload to Glance Your OZ customization file may look like this:
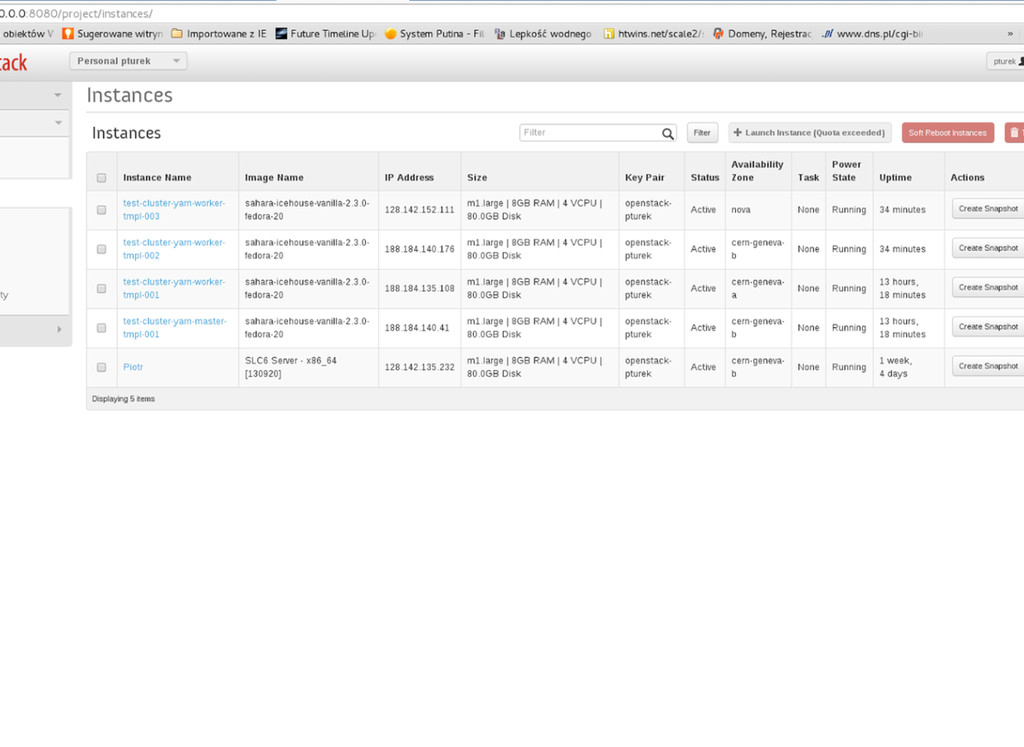
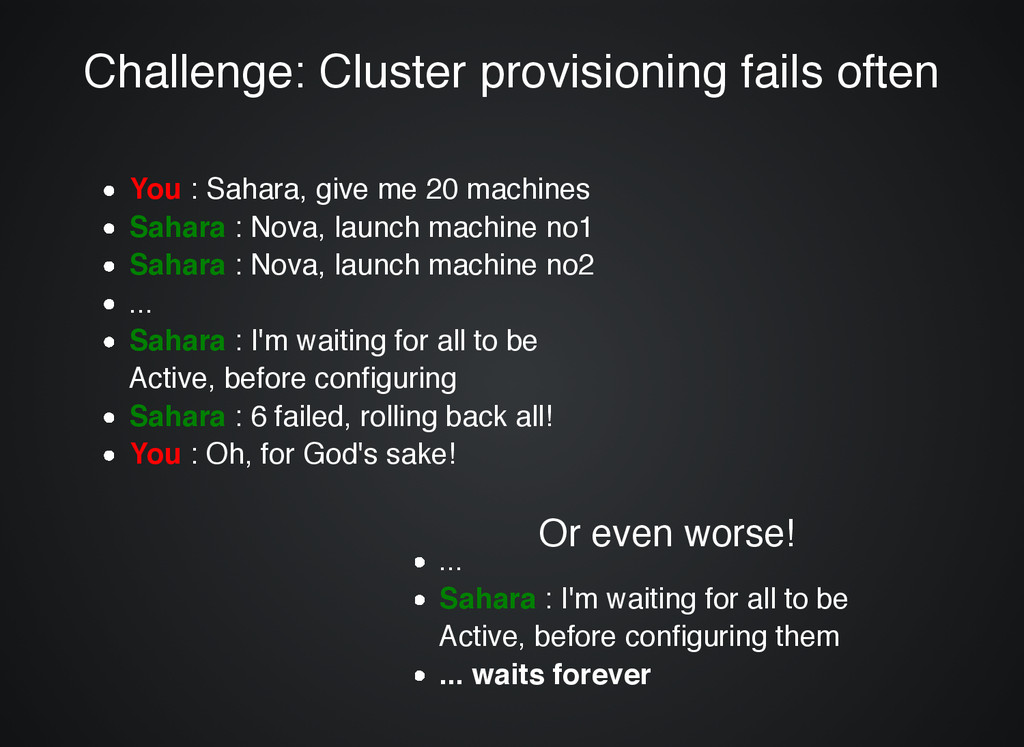
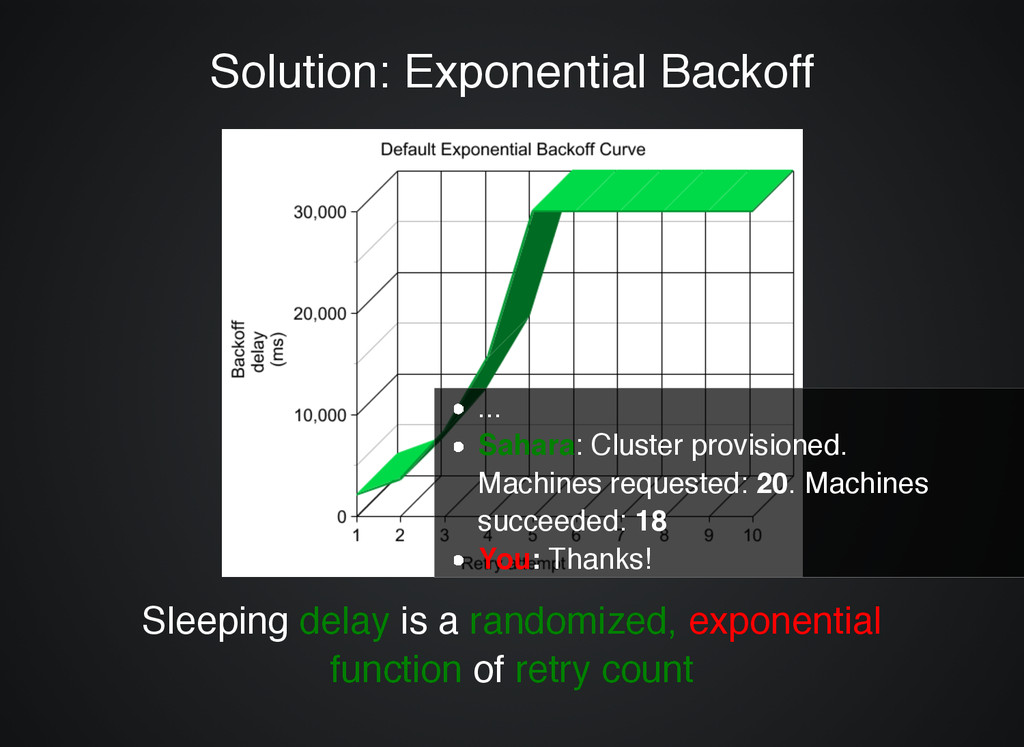
You : Sahara, give me 20 machines Sahara : Nova, launch machine no1 Sahara : Nova, launch machine no2 ... Sahara : I'm waiting for all to be Active, before configuring Sahara : 6 failed, rolling back all! You : Oh, for God's sake! ... Sahara : I'm waiting for all to be Active, before configuring them ... waits forever Or even worse! Or even worse!
is a is a randomized, randomized, exponential exponential function function of of retry count retry count ... Sahara: Cluster provisioned. Machines requested: 20. Machines succeeded: 18 You: Thanks!
the data using Hadoop CASTOR 20 files (different sizes) 20 workers evenly sized chunks (small) EOS Map tasks Map tasks HDFS HDFS We need a map-only job We need a map-only job
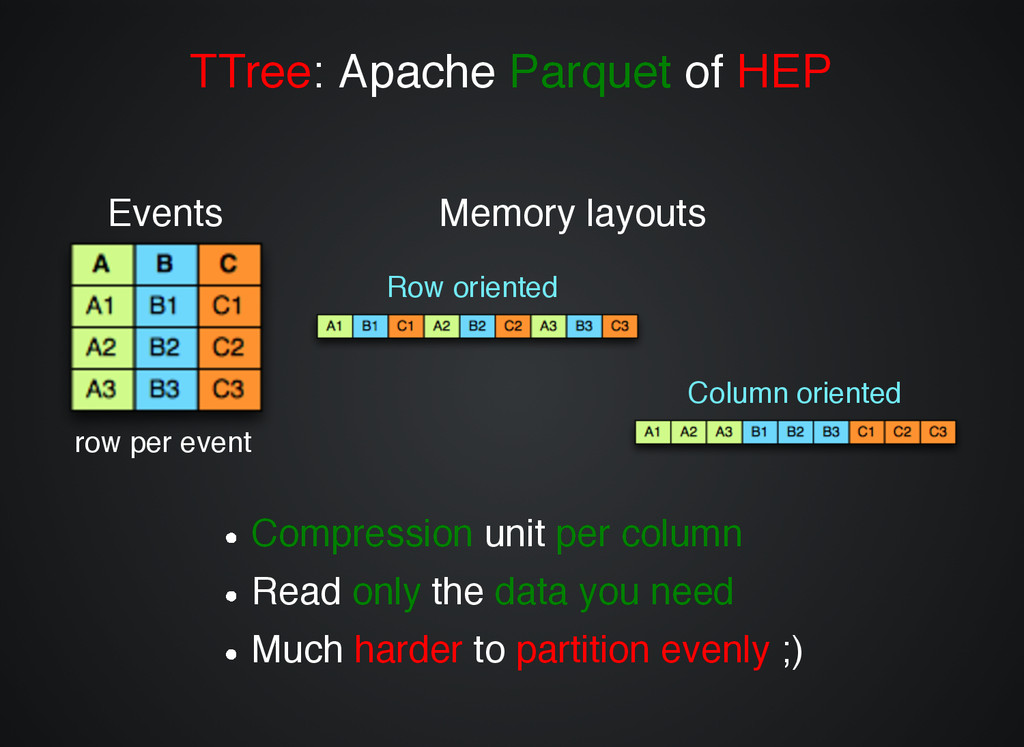
HEP Events Events row per event Row oriented Column oriented Memory layouts Memory layouts Compression Compression unit unit per column per column Read Read only only the the data you need data you need Much Much harder harder to to partition evenly partition evenly ;) ;)
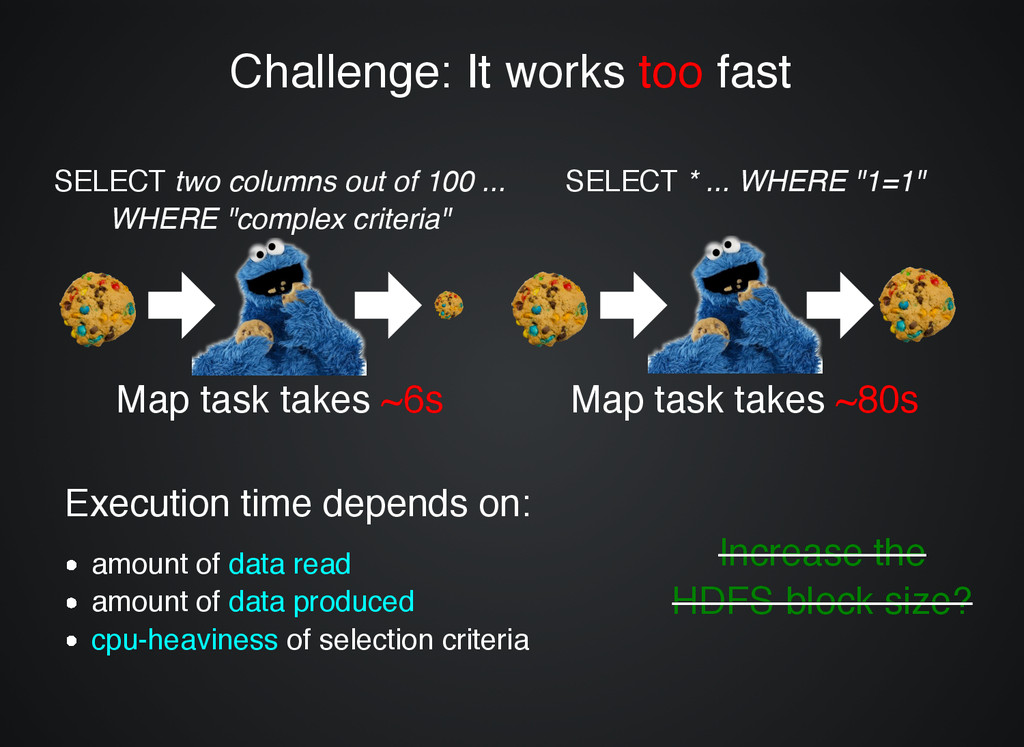
SELECT two columns out of 100 ... WHERE "complex criteria" SELECT * ... WHERE "1=1" Map task takes Map task takes ~6s ~6s Map task takes Map task takes ~80s ~80s Execution time depends on: Execution time depends on: amount of data read amount of data produced cpu-heaviness of selection criteria Increase the Increase the HDFS block size? HDFS block size? Increase the Increase the HDFS block size? HDFS block size?
job in two: Learning phase Learning phase 1. Select a small sample of input 2. Run the job 3. Calculate avg time of map-task r = t /t heaviness requested avg Mature phase Mature phase Use CombineWholeFileInputFormat maxInputSplitSize = r ∗ blockSize heaviness r ∗ heaviness Result: Filtering Result: Filtering up to 100 times faster up to 100 times faster than loading than loading
make any sense in the end? YES YES Much more Much more performant performant Much more Much more scalable scalable Little to no Little to no code req code req , but , but Some parts Some parts missing missing change change comes slowly comes slowly resources as resources as well well
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}