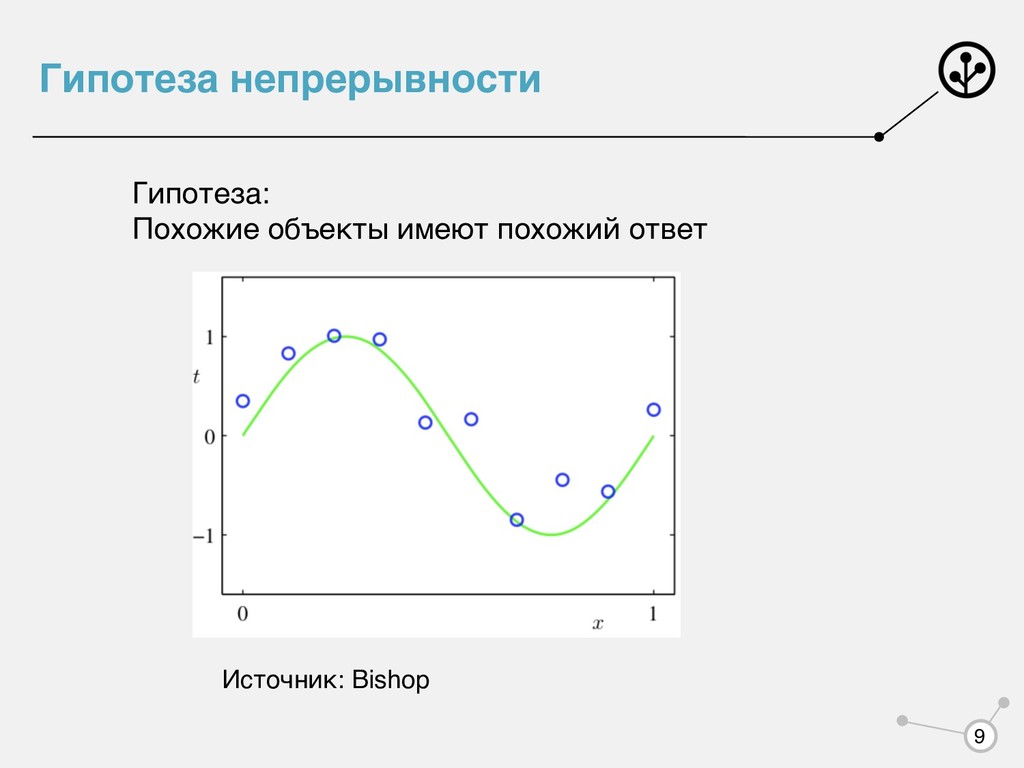
характеристик (целевая переменная). Существует некоторая функция Задача: имея ограниченный набор объектов, построить функцию , приближающую на всем множестве объектов Обучение с учителем — известны 1) Классификация — 2) Регрессия — x ∈ X y ∈ Y f : X → Y a : X → Y f {x1 , …, xN } = Xtrain , {y1 , …, yN } = Ytrain Xtrain , Ytrain Y = {1,…, M} Y = ℝ, Y = ℝ 4
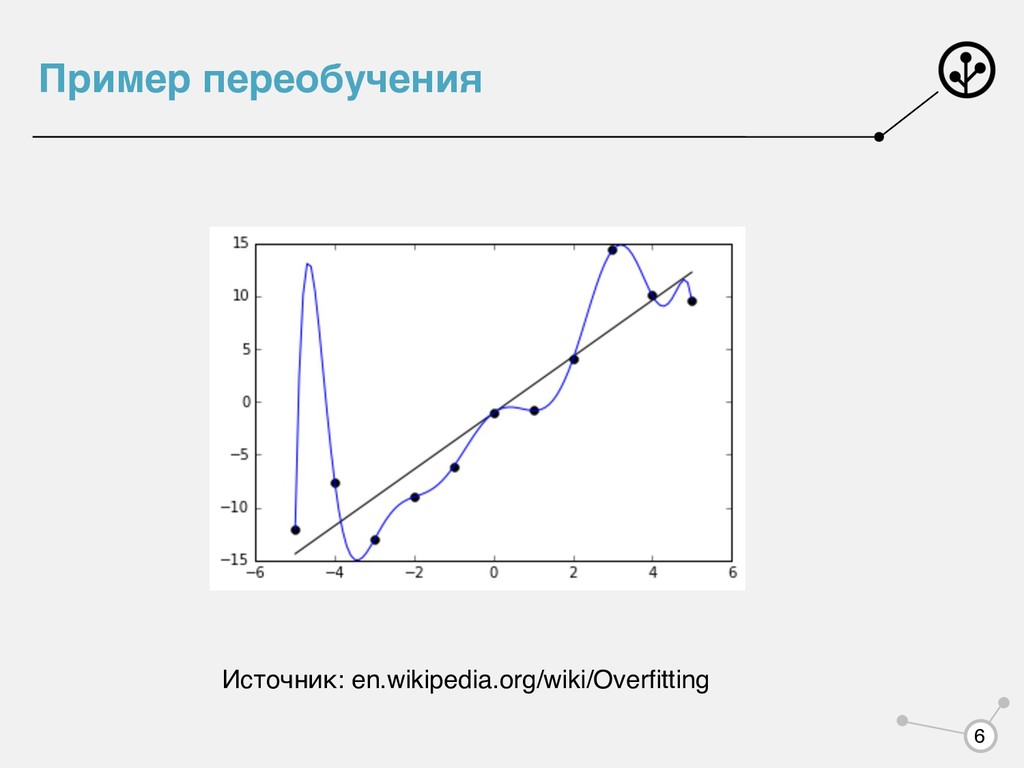
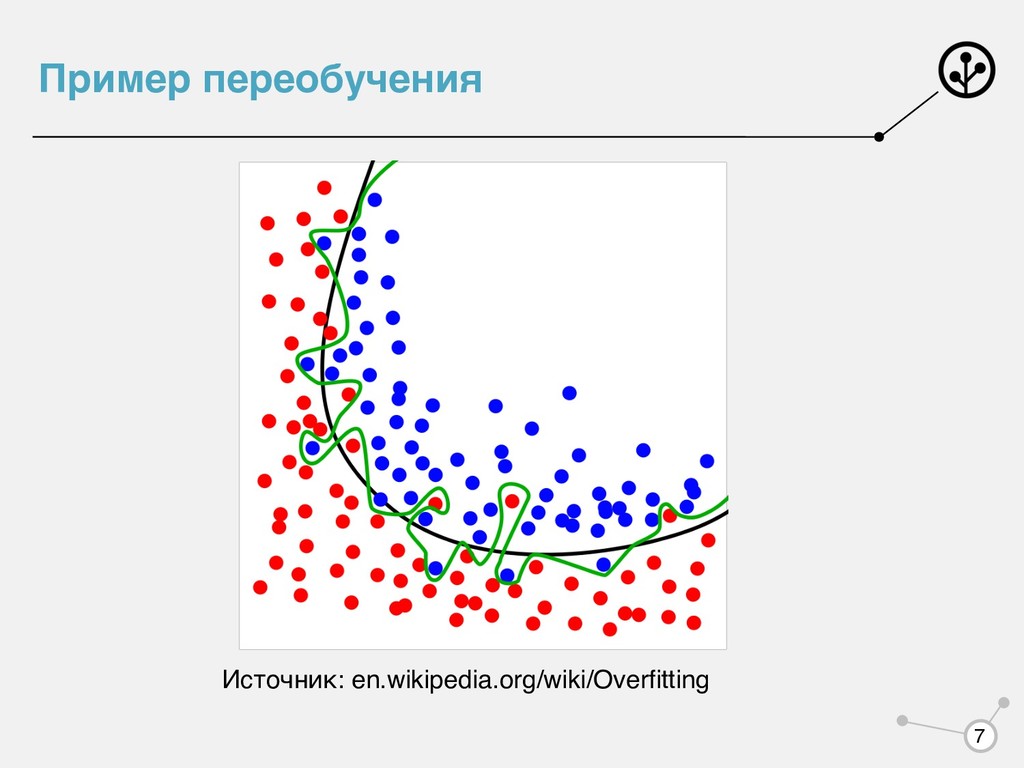
на объекте с ответом . Функционал качества Принцип минимизации эмпирического риска: , — семейство алгоритмов. Переобучение — << Формула обучения: Learning = Representation + Evaluation + Optimization Источник: homes.cs.washington.edu/~pedrod/papers/cacm12.pdf L(a, x, y) a x y Q(a, X, Y) = 1 N ∑N i=1 L(a, xi , yi ), xi ∈ X, yi ∈ Y a* = argmin A Q(a, Xtrain , Ytrain ) A Q(a, Xtrain , Ytrain ) Q(a, Xtest , Ytest ) 5
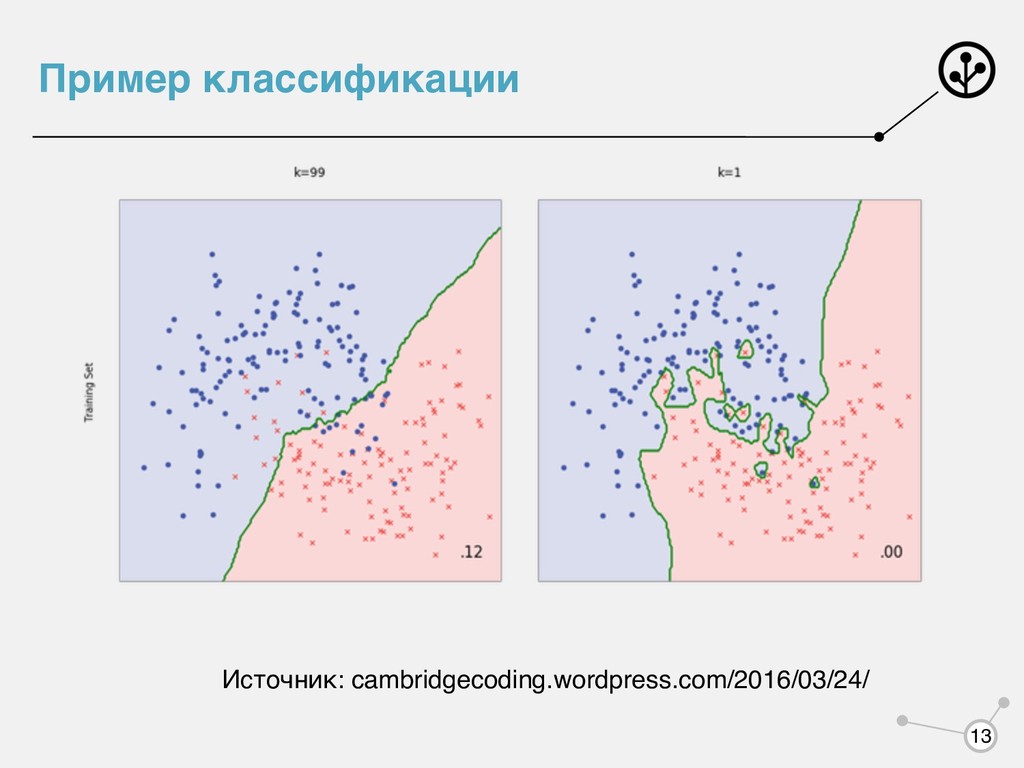
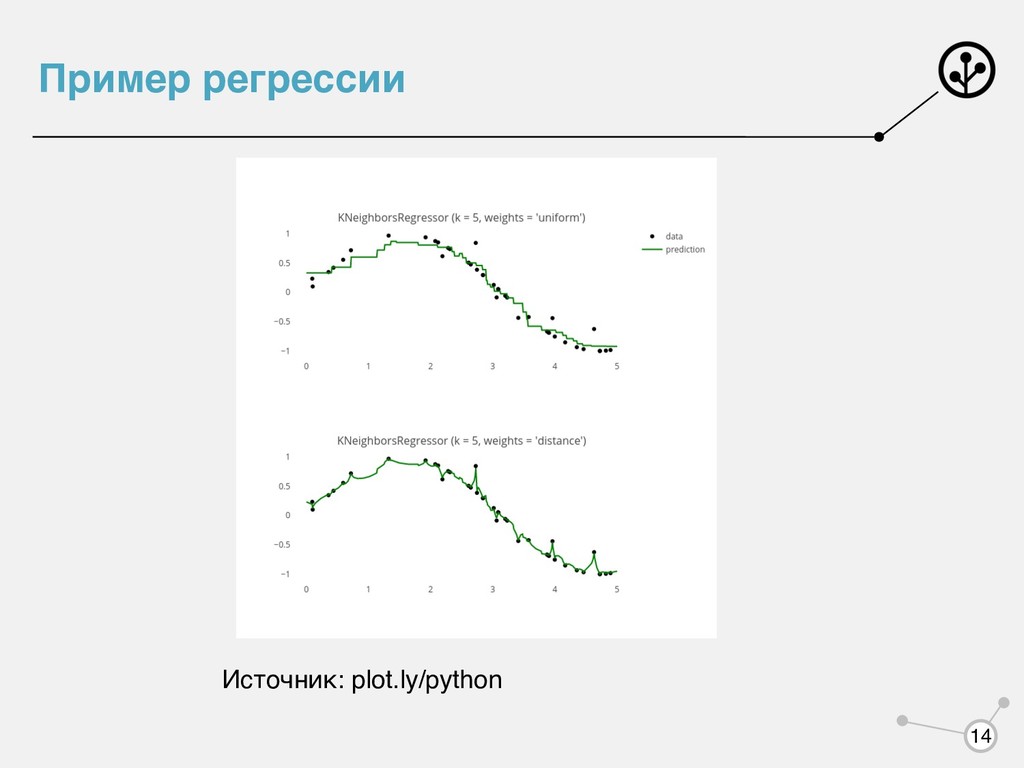
классификации: Общая формула для регрессии: Непараметрический, ленивый алгоритм N a(x, Xtrain ) = argmax c N ∑ i=1 w(x, xi )I[yi = c], xi ∈ Xtrain a(x, Xtrain ) = ∑N i=1 w(x, xi )yi ∑N i=1 w(x, xi ) , xi ∈ Xtrain 10
то алгоритм называют алгоритмом ближайшего соседа • Если ненулевые веса для ближайших объектов, то алгоритм называют алгоритмом ближайших соседей (k-nearest neighbors, knn). Пусть — -тый ближайший сосед объекта • • • k k xi i x w(x, xi ) = 1/k w(x, xi ) = k + 1 − i k w(x, xi ) = αi, α ∈ (0,1) 11
называть структурными. Обучающую выборку нужно разделить на обучающую и валидационную. На ней настраиваем структурные параметры! 16 Параметры метрических алгоритмов настраивать на обучающей выборке? На тестовой? Почему? Q(a, X, Y) = 1 N ∑N i=1 L(a, xi , yi ), xi ∈ X, yi ∈ Y Переобучение возникает из-за излишней сложности модели
объектов • Precision (аккуратность) —процент правильно классифицированных объектов класса 1 среди всех объектов, которым алгоритм присвоил метку 1. • Recall (полнота) — процент правильно классифицированных объектов класса 1 среди всех объектов класса 1 • F1-score — среднее гармоническое Precision и Recall Тестовая выборка содержит 10 объектов класса 1 и 990 объектов класса 0. Какая точность у константного алгоритма? Почему именно среднее гармоническое? L(a, x, y) = [a(x) = y] F1 = 2 1 Precision + 1 Recall = 2 ⋅ Precision ⋅ Recall Precision + Recall 19
мы решаем! Если выборка маленькая, то нужно сохранять баланс классов — stratified валидация. Как сделать валидацию в случае: • Спам-фильтра • Предсказания объема продаж на следующую неделю • Предсказания стоимости квартир для всего дома целиком 20
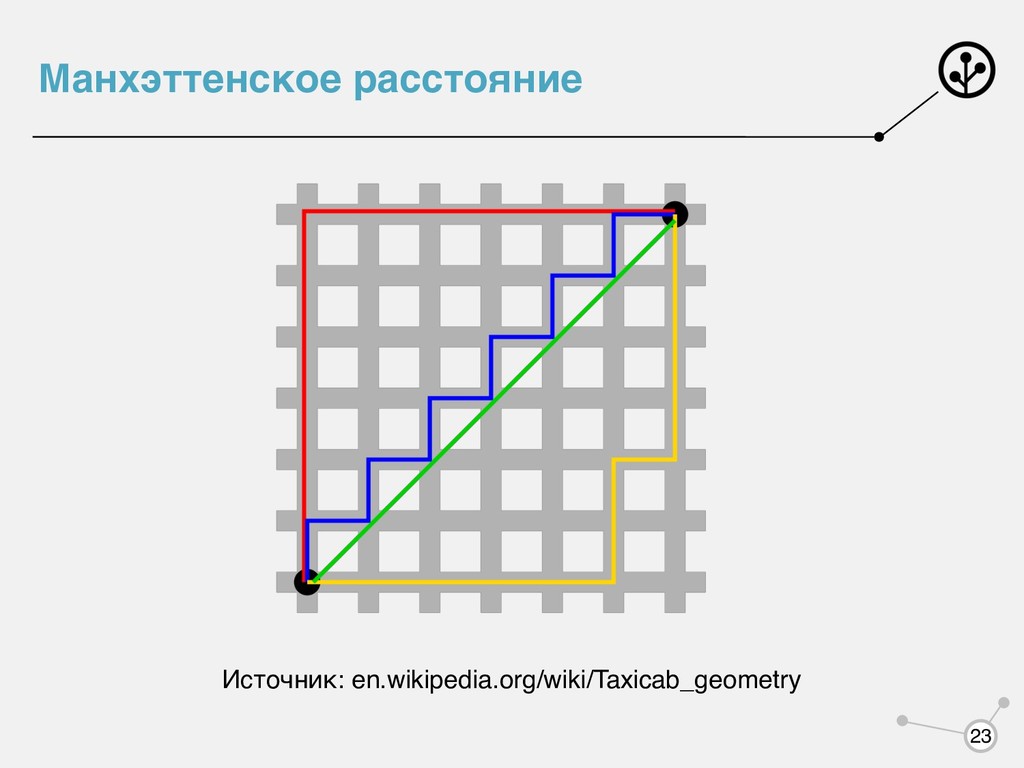
признаков. Метрика Минковского (при не метрика): • — Евклидово расстояние • — Манхэттенское расстояние • — Растояние Чебышева (максимальное расстояние между двумя признакми) ρ(x, y) = 0 x = y ρ(x, y) = ρ(y, x) ρ(x, z) ≤ ρ(x, y) + ρ(y, z) D p ∈ (0,1) ρ(x, y) = ( D ∑ j=1 |xj − yj |p )1 p p = 2 p = 1 p = ∞ 22
категориальных признаков, которые имеют разные значения. 2. Счетчики — среднее значение признака/целевой переменной с такой категорией. При кодировании признака с помощью целевой переменной нельзя использовать целевую переменную данного объекта!
На практике обычно считают так: Косинусное расстояние часто используют для текстов. Почему? ρ(x, y) = α = arccos x ⋅ y |x||y| sim(x, y) = x ⋅ y |x||y| rho(x, y) = 1 − sim(x, y) 26
символа и замены одного символа на другой, необходимых для превращения одной строки в другую. В каких задачах часто применяется расстояние Левенштейна? ρ(kitten, sitting) = 3 28
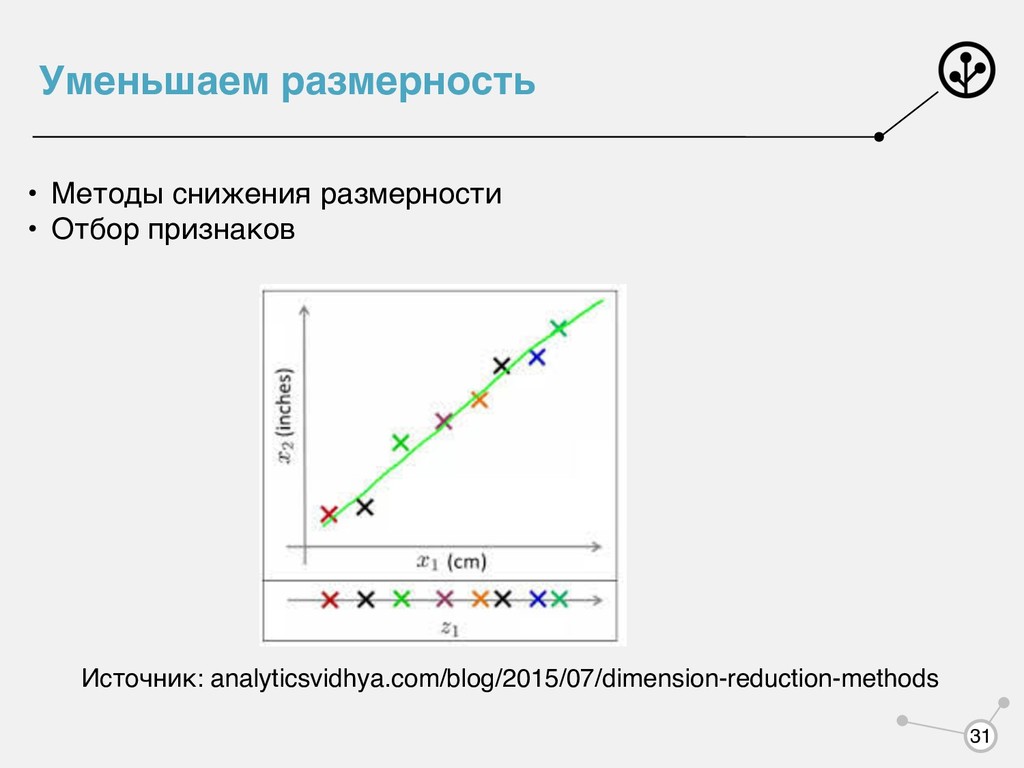
для нас вредные? • Перебрать все варианты и посмотреть качество (лучший, если признаков мало) • Посчитать корреляцию с целевой функцией и удалить шумные • Посчитать корреляцию всех пар признаков и удалить скоррелированные • Последовательно удалять худшие • Последовательно добавлять лучшие 32
выбрана метрика • Ленивый алгоритм, совсем не учится • Позволяет делать беспризнаковое распознавание • На признаковом распознавании, как правило, работает хуже других алгоритмов Какие можете придумать примеры беспризнакового распознавания? Какая сложность обучения алгоритма ближайшего соседа? Предсказания одного объекта? 33
(считаем все расстояния) В таком виде это в real time системах это работать не будет! А для ближайших соседей? Зачем мы тогда все это учим? O(ND) O(ND) k 34
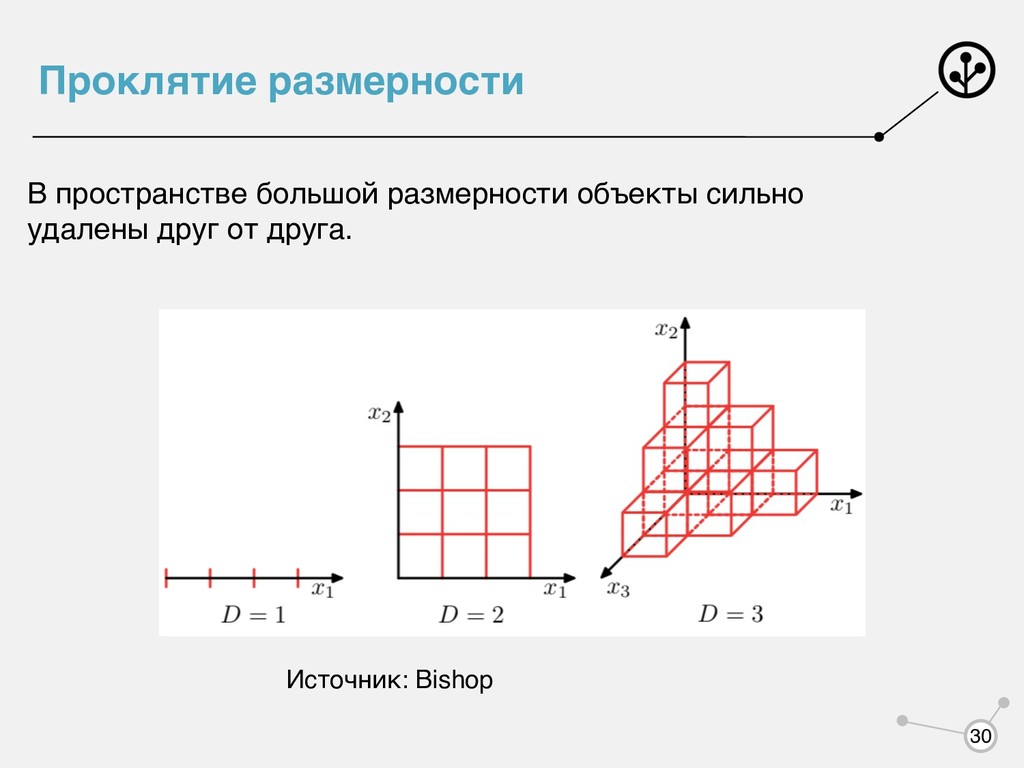
по нему быстрее искать. • KD-tree • Ball tree Если признаков мало (несколько десятков), то сложность по числу объектов логарифмическая. Если много — линейная (проклятие размерности), внедрять нельзя!
для больших признаковых пространств. Примеры методов: • ANNOY — делим пространство случайными плоскостями, строим дерево • Navigable Small World — гуляем по графу тесного мира • FAISS — кластеризуем пространство и ищем расстояния до центров кластеров • LSH (Locality-sensitive hashing) — делаем хэш функцию, которая близким объектам присваивает близкие значения хэша На семинаре разбираем ANNOY! 36
из двух компонент: • Грубый отбор кандидатов • Использование финальной модели Быстрый приближенный поиск ближайших соседей идеально подходит под задачу выборов кандидатов. Величину можно подавать в финальную модель! ρ(x, y) 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}