выборку. Если все объекты берутся независимо из одинакового распределения: С суммой, как правило, удобнее работать. Правильные параметры те, которые максимизируют L(θ) = p(X|θ) = N ∏ i=1 p(xi |θ) log L(θ) = N ∑ i=1 log p(xi |θ) L(θ) θML = argmax log L(θ) 4
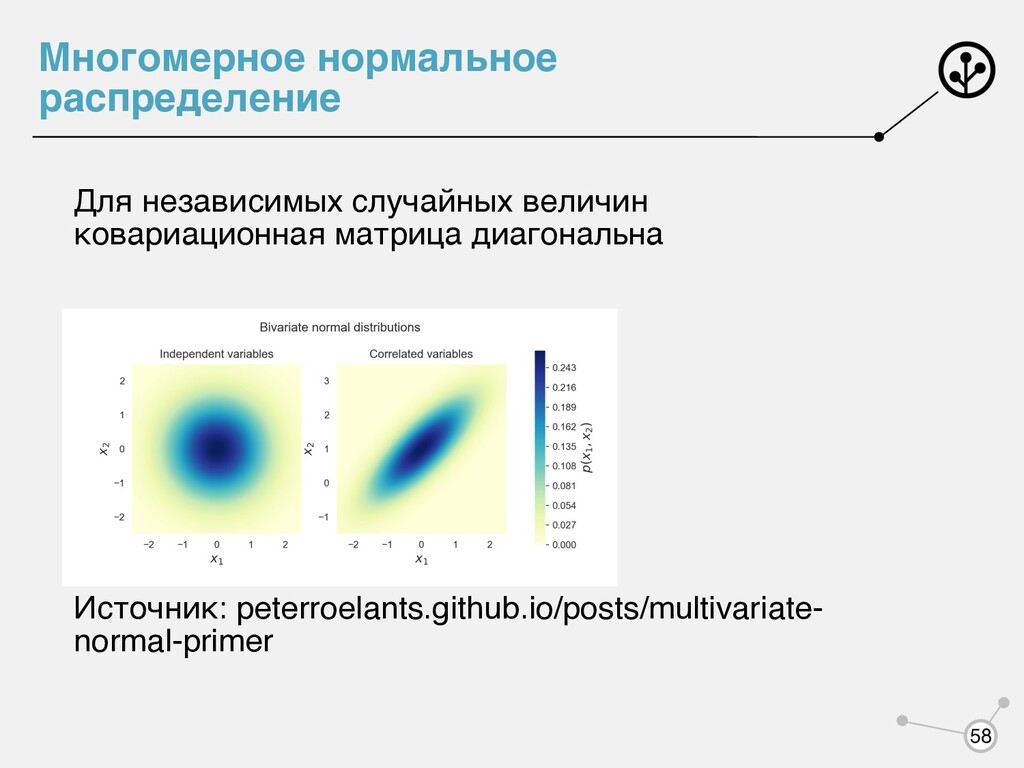
максимума правдоподобия может дать неадекватную оценку Свойства ММП: • Состоятельность (оценка сходится по вероятности к истинному значению) • Асимптотическая нормальность (оценка распределена нормально) • Асимптотическая эффективность (обладает наименьшей дисперсией среди всех состоятельных асимптотически нормальных оценок) При Для каких распределений мы можем легко посчитать оценку максимума правдоподобия? n d → ∞ 6
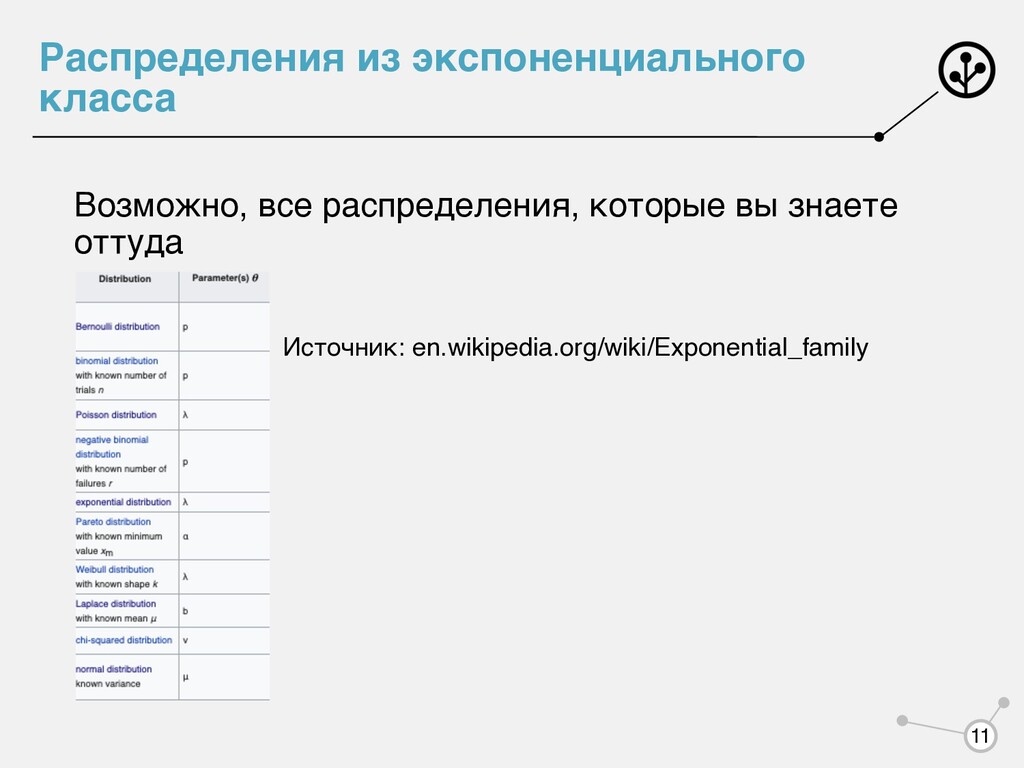
мы хотим от , чтобы быть уверенными, что мы сможем посчитать оценки ММП? θML = argmax log p(X|θ) p(x|θ) p(x|θ) = f(x) g(θ) exp(θTu(x)) g(θ) = ∫ f(x)exp(θTu(x))dx log p(X|θ) 7
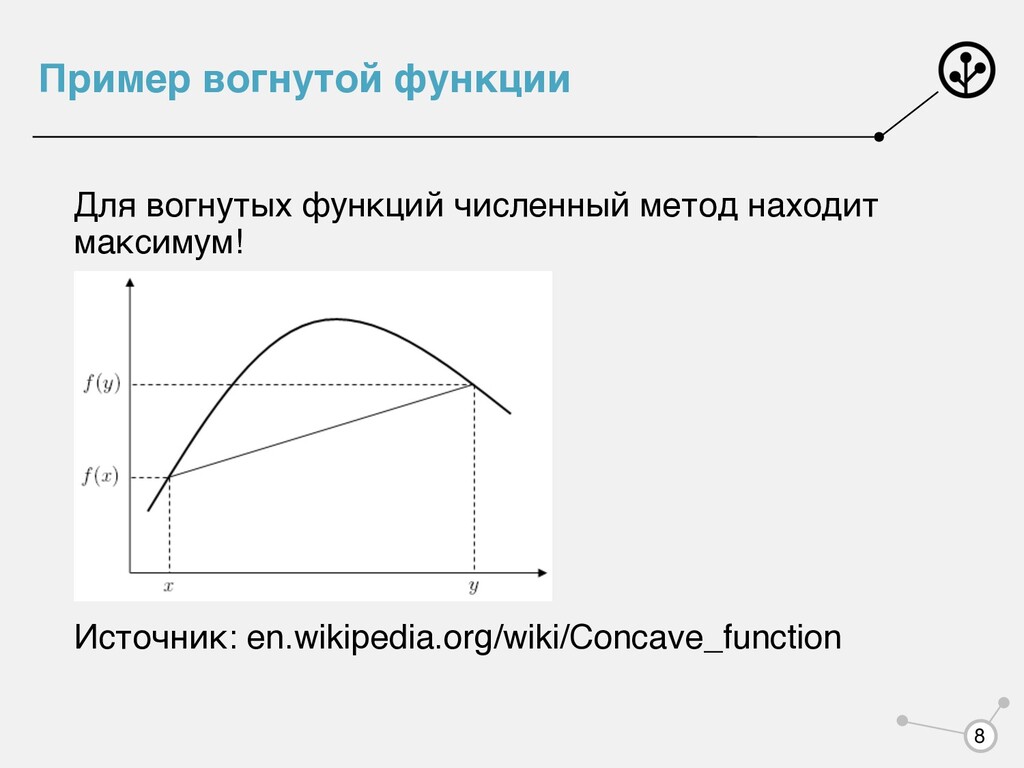
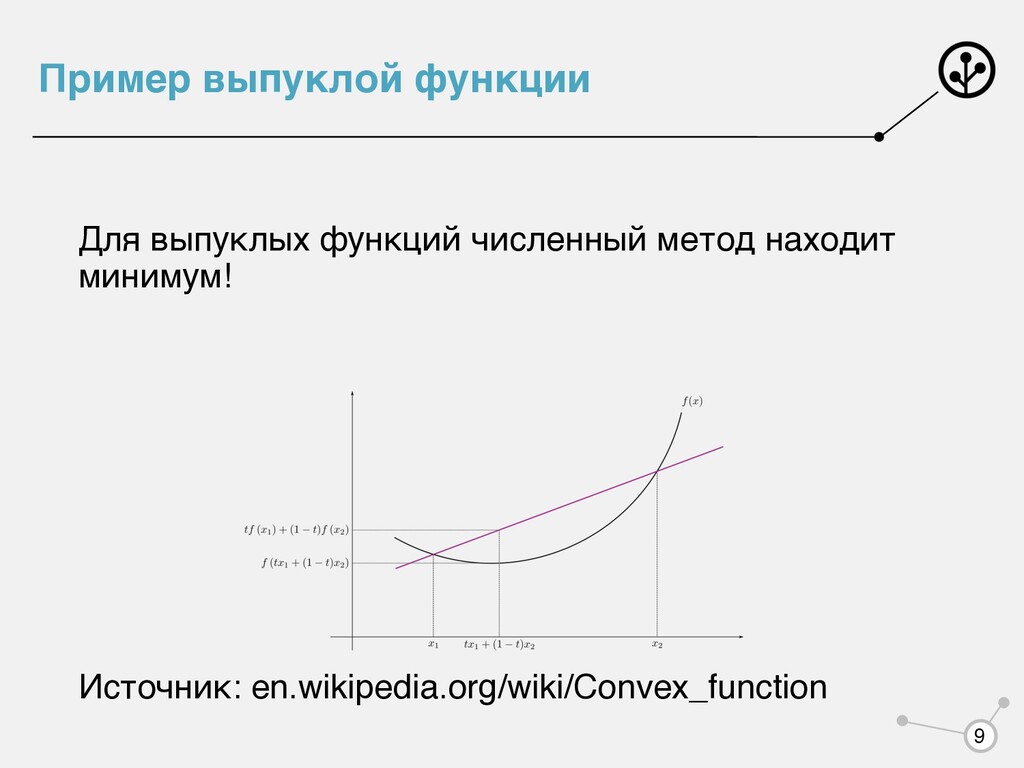
есть функция вогнутая Ну и что, наши то любимые распределения ни из какого не экспоненциального класса. log L(θ) = N ∑ i=1 f(xi ) − N log g(θ) + θT N ∑ i=1 u(xi ) ∂2g(θ) ∂θi ∂θj = cov(ui , uj ) log L(θ) 10
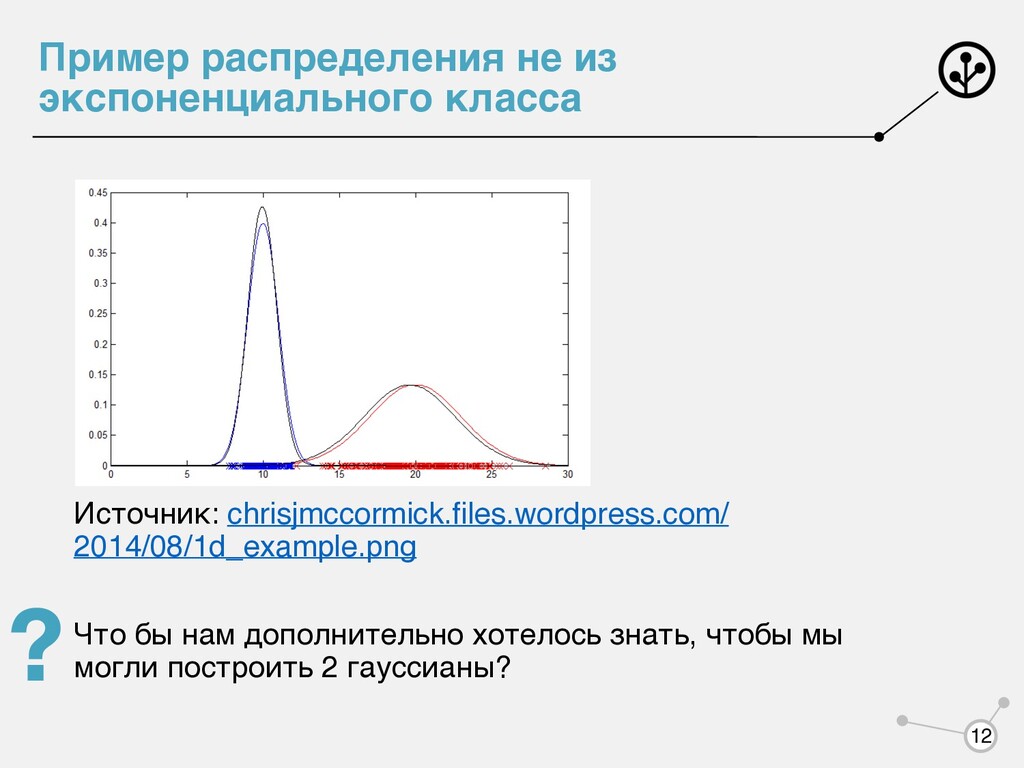
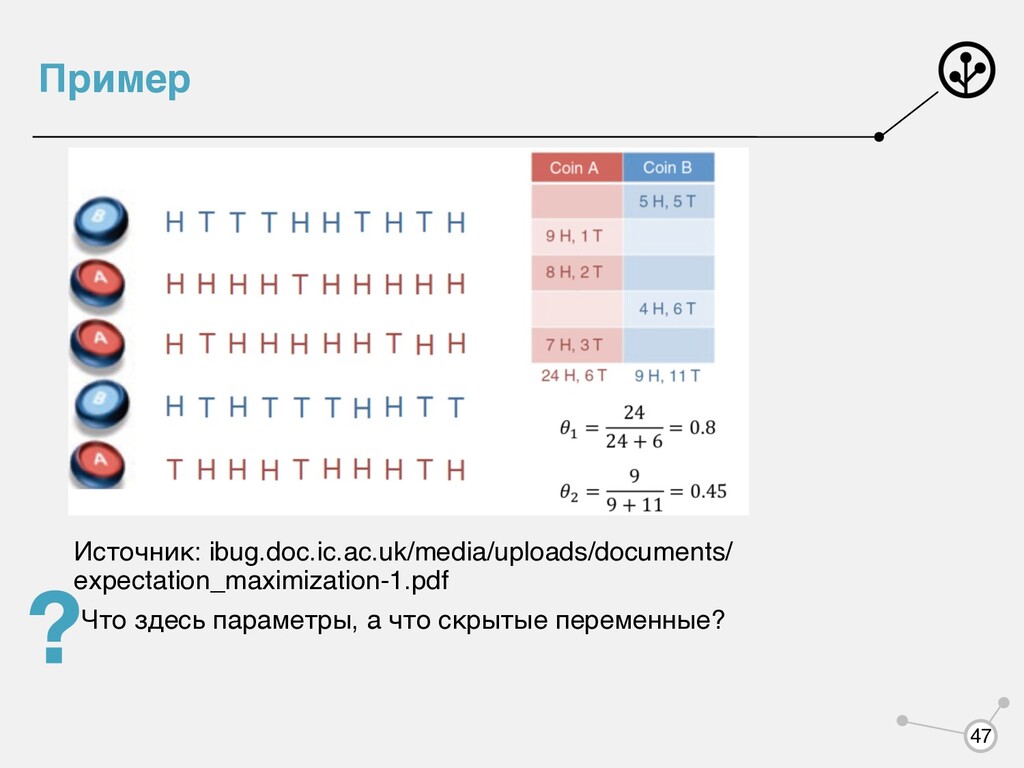
точки из каждой гауссианы и по формулам из ММП: Одна проблемка — мы не знаем из какой гауссианы пришла каждая точка! K σ2 k = ∑N i=1 [xi ∈ K](xi − μk )2 Nk 13 μk = ∑N i=1 xi [xi ∈ K] Nk
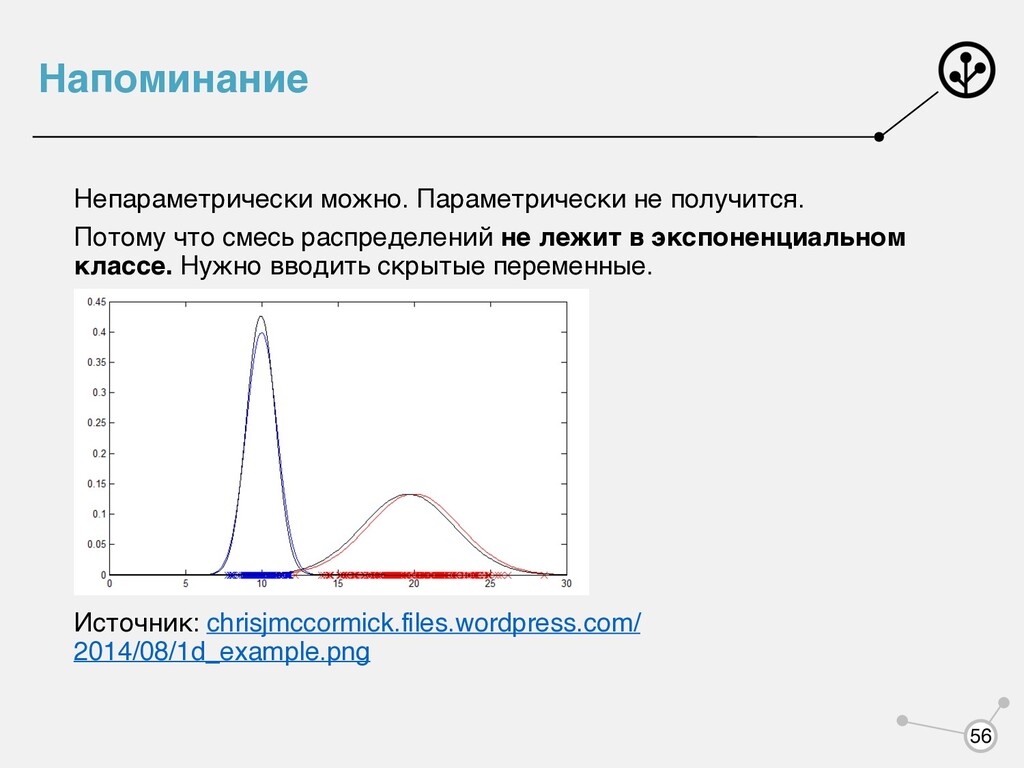
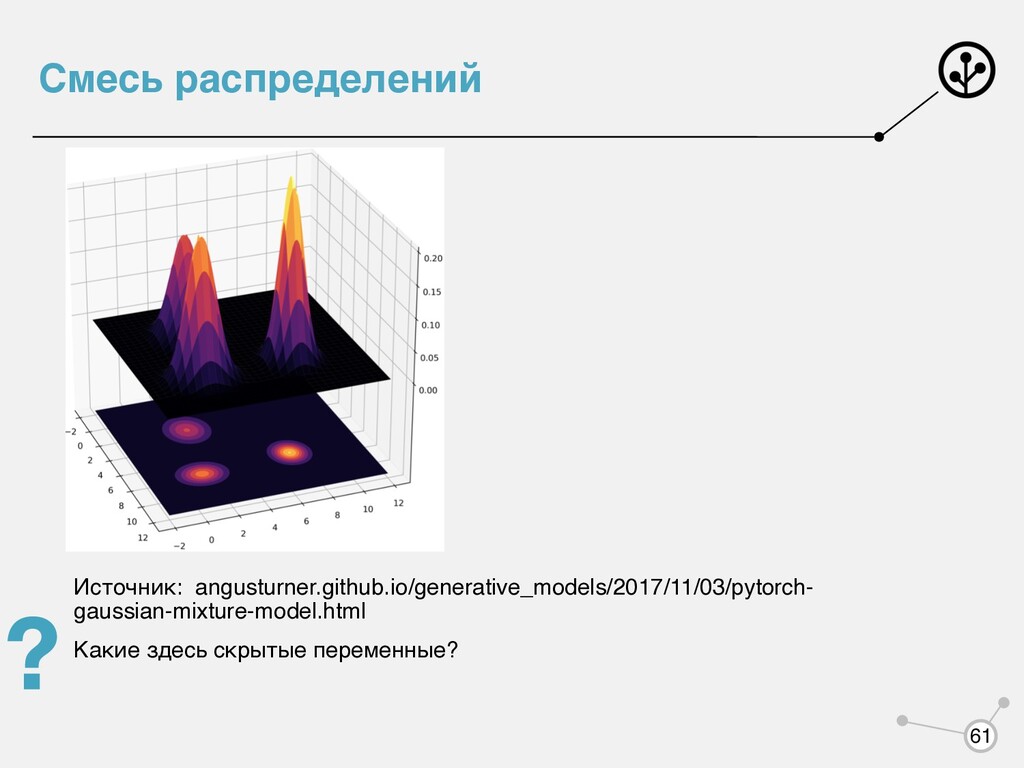
распределения, которое зависит не только от наблюдаемых переменных , но и от каких-то скрытых переменных , которые мы не наблюдаем. Есть два варианта: • Не обращаем на это внимание, просто решаем задачу выбирая какое-то параметрическое семейство • Смиряемся, что мы не наблюдаем, моделируем все равно и находим одновременно и параметры модели, и скрытые переменные X Z argmax log p(X|θ) Z argmax log p(X, Z|θ) 14
мы можем сделать так, что совместное распределение будет из экспоненциального класса, а значит будет вогнутой функцией и задача может быть решена эффективно! • — неполное правдоподобие • — полное правдоподобие p(X, Z|θ) log p(X, Z|θ) argmax θ log p(X, Z|θ) p(X|θ) p(X, Z|θ) 15
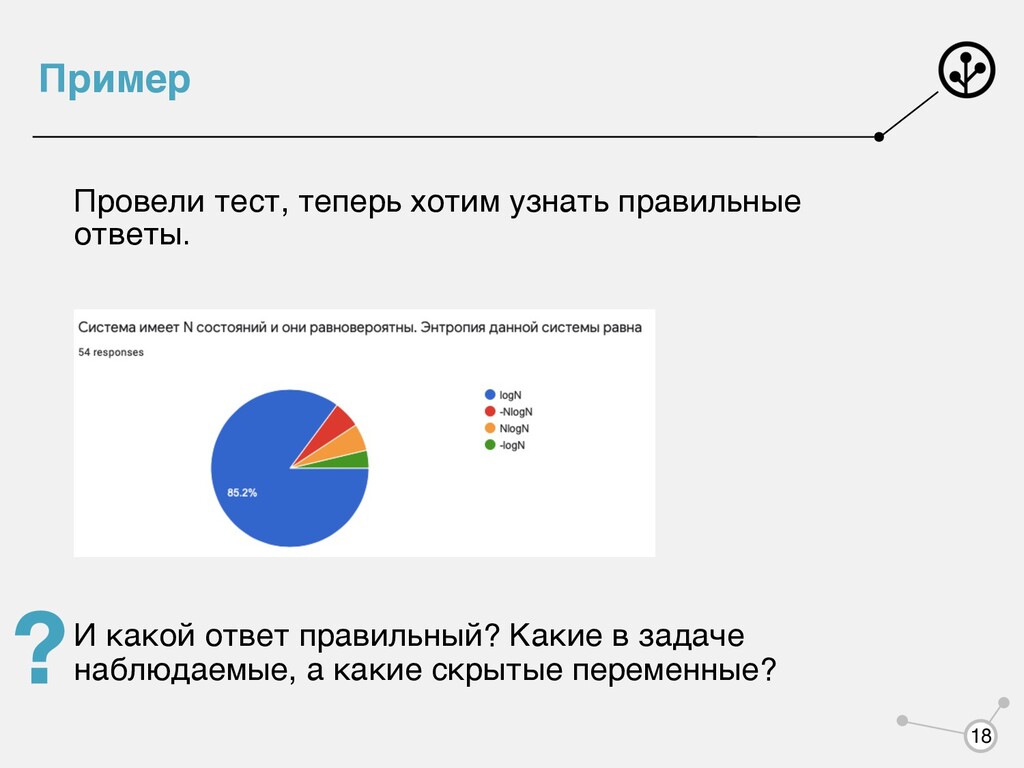
нужно восстановить Примеры задач со скрытыми переменными: • Кластеризация • Машинный перевод • Распознавание речи • Распознавание частей речи • Тематическое моделирование • Умная разметка в краудсорсинге • Восстановление плотности 17
— правильные ответы Параметры — «оценка студента» Такие задачи можно решать в 2 шага На первой итерации всех студентов оцениваем одинаково. 1. Оценили ответы через взвешенную сумму голосов с большими весами у отличников 2. По этим ответам пересчитали оценки студентов А какое практическое применение? Ответы то мы знаем. 19
собачек. Одну картинку оценивают сразу несколько людей. Применяем такой алгоритм, чтобы найти халтурщиков (ставят метки просто так) и восстановить правильные метки! 20
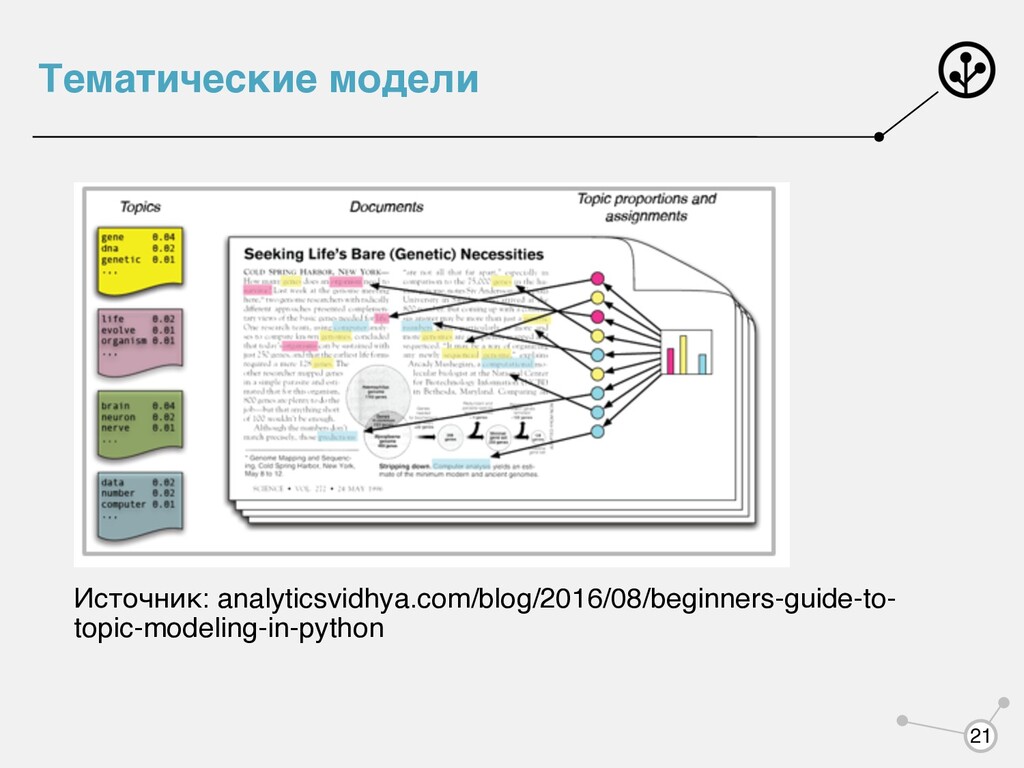
— семантический кластер текстов Цель тематического моделирования: понять, к каким темам относится документ и какие слова образуют тему. Примеры применения: • Категоризация документов • Рекомендательные системы • Информационный поиск • Выделение трендов в новостных потоках Какие параметры наблюдаемые, а какие скрытые? 22
Наблюдаем слова в документе. Настраиваем параметры: • — матрица вероятности темы для каждого слова • — матрица вероятности темы для каждого документа Строим генеративную модель порождения текстов: Если на матрицу наложить prior в виде распределения Дирихле, то модель будет называться latent dirichlet allocation Позволяет поощрять разреженность тематического профиля документа Находим параметры Φ Θ L(W, Z|Φ, Θ) = D ∏ d=1 Nd ∏ i=1 p(wd,i |zd,i , Φ)p(zd,i |Θd ) Θ log L(W, Z|Φ, Θ) → max Φ,Θ 23
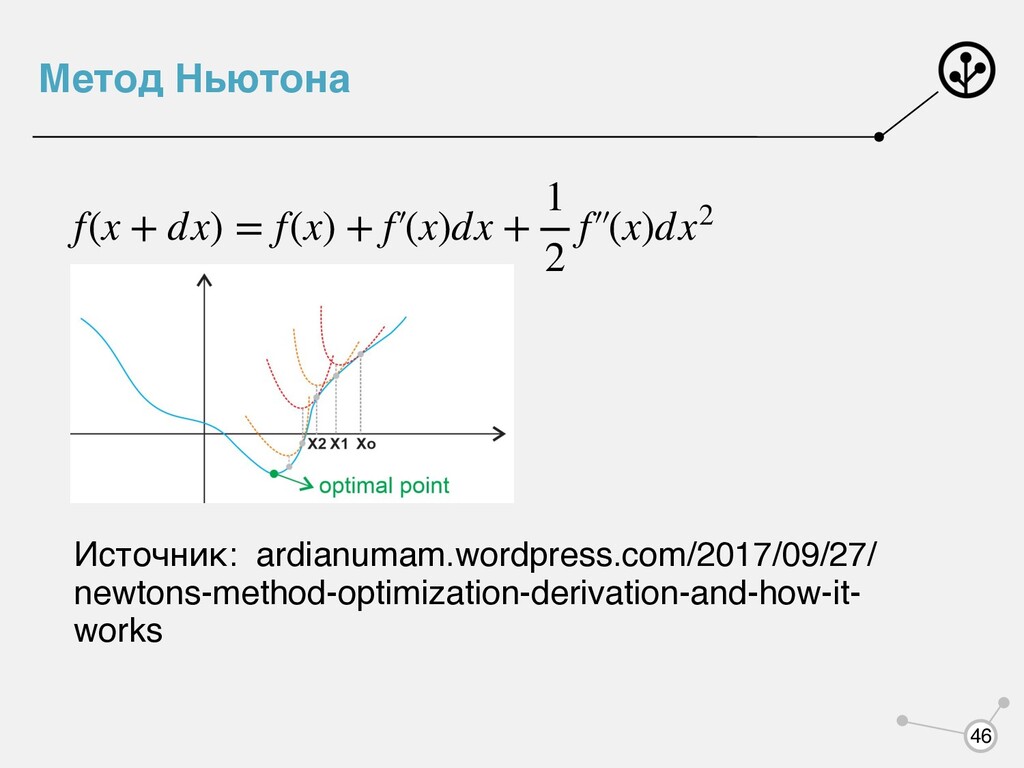
, если для любых и для любого найдется такой, что То есть мы пытаемся снизу подпереть нашу функцию каким-то классом функций! f(θ) g(θ, ν) θ, ν g(θ, ν) ≤ f(θ) θ* μ* g(θ*, ν*) = f(θ*) 26
но мы смогли построить вариационную нижнюю оценку , для которой максимум по искать просто. Тогда для решения задачи можно итеративно находить максимумы для 1. Инициализировали , посчитали для него 2. , Сходится ли такой метод? argmax θ f(θ) g(θ, ν) θ argmax θ f(θ) g(θ, ν) θold νold = argmax ν g(θold , ν) = f(θold ) θnew = argmax θ g(θ, νold ) νnew = argmax ν g(θnew , ν) 28
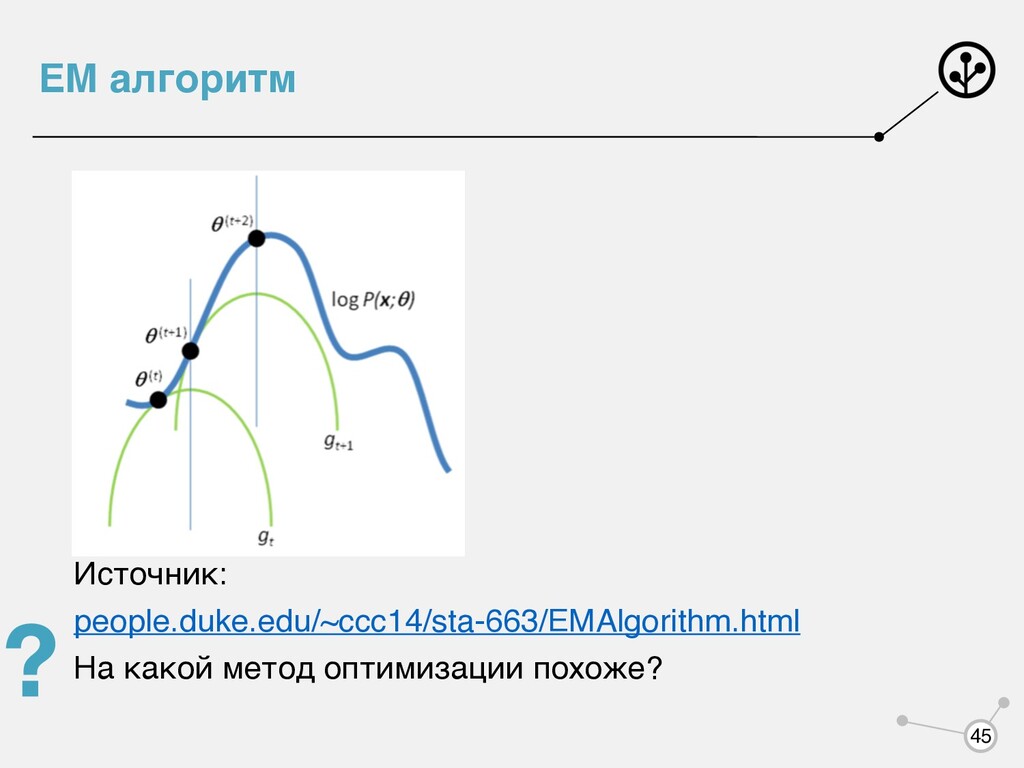
нашей функции , но глобального оптимума никто не гарантирует — сходимся к локальному. При чем тут машинное обучение? За что нам это? g(θold , μold ) = f(θold ) < g(θnew , μold ) < g(θnew , μnew ) = f(θnew ) f(θ) 29
построить для нее , которое бы являлась вариационной нижней оценкой. Очевидно, что в нее в каком-то виде войдут скрытые переменные. EM (Expectation-maximization) - алгоритм, позволяющий находить оценку максимального правдоподобия в задачах со скрытыми переменными. Схематично метод можно описать так: 1. Проинициализировали параметры 2. Максимизировать по скрытым переменным (E шаг) 3. Максимизировать по параметрам (M шаг) 4. Повторять 2 и 3 до сходимости f(θ) g(θ, ν) 30
мы получаем, когда наблюдаем определенную ее реализацию? Можно показать, что Получатель отправляет информацию о том, какая у него реализация случайной величины Сколько в среднем бит ему надо передать? Эта величина называется энтропией случайной величины Почему ее используют для дерева решений? h(x) h(x) = − log2 p(x) H[x] = − ∑ x p(x)log2 p(x) x 31
распределения и равна нулю у вырожденного (когда значение принимается с вероятностью 1) Для вещественных величин Для нормального распределения: Чем более «размазанное» распределение, тем больше у него энтропия! H[x] = − ∫ p(x)log p(x)dx H[x] = 1 2 (1 + log 2πσ2) 32
его каким-то . Как померить расстояние между этими двумя распределениями, насколько мы хорошо приблизили? Будем считать, насколько бит увеличится информация, если мы будем кодировать случайную величины из с помощью Это метрика? p(x) q(x) p(x) q(x) KL(q||p) = − ∫ p(x)log q(x)dx − ( − ∫ p(x)log p(x)dx) KL(q||p) = − ∫ p(x)log q(x) p(x) dx = ∫ p(x)log p(x) q(x) dx 33
симметричности, ни неравенству треугольника. Но она неотрицательна. Докажем. Неравенство Йенсена для выпуклых функций Равенство, когда в каждой точке. То есть можно использовать, как функцию расстояния. ∑ λi f(xi ) ≥ f(∑ λi xi ) KL(q||p) = − ∫ p(x)log q(x) p(x) dx ≥ − log ∫ p(x) q(x) p(x) dx = − log ∫ q(x)dx = 0 p(x) = q(x) 34
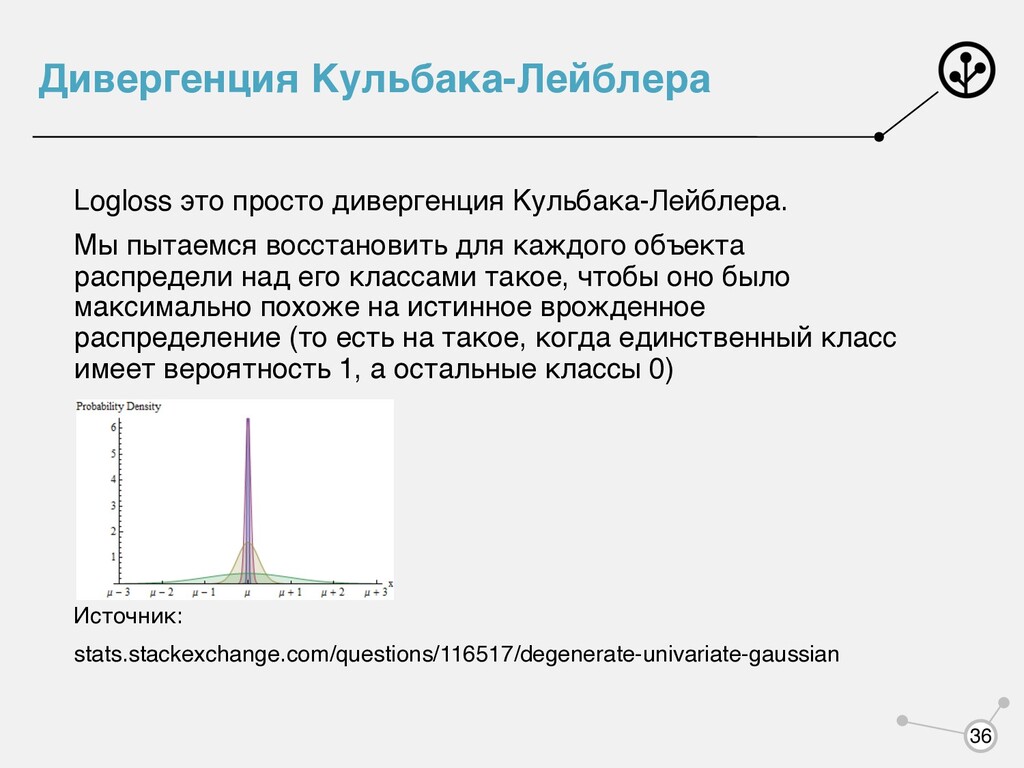
для каждого объекта распредели над его классами такое, чтобы оно было максимально похоже на истинное врожденное распределение (то есть на такое, когда единственный класс имеет вероятность 1, а остальные классы 0) Источник: stats.stackexchange.com/questions/116517/degenerate-univariate-gaussian 36
для , которую мы оптимизируем Таким образом для решения делаем итеративную оптимизацию (E шаг, expectation) (M шаг, maximization) L(q, θ) = ∫ q(Z)log P(X, Z|θ) q(Z) dZ f(θ) = log P(X|θ) log P(X|θ) → max θ L(θ, q) log L(θ*, q) → max q log L(θ, q*) → max θ 39
говоря, распределение. То есть нам нужно провести функциональную оптимизацию. Задача в общем случае непосильная, если бы не: То есть сумма от не зависит! Значит, чтобы максимизировать по , надо минимизировать по , ну а это то уже мы знаем как Как минимизировать по ? q log L(θ*, q) → max q q f(θ) = log P(X|θ) = L(θ, q) + KL(q||p) q L(θ, q) q KL(q||p) q KL(q||p) q 40
не зависит, его можно отбросить То есть на M шаге решаем задачу: Вместо исходной стали решать , в чем смысл? θ log L(θ, q*) → max θ L(θ, q*) = ∫ q*(Z)log P(X, Z|θ) q(Z) dZ = ∫ q*(Z)log P(X, Z|θ)dZ − ∫ q(Z)log q*(Z)dZ θ ∫ q*(Z)log P(X, Z|θ)dZ → max θ Z log P(X, Z|θ) → max θ log P(X|θ) → max θ Z log P(X, Z|θ) → max θ 42
экспоненциальном классе. Мы можем подобрать скрытые переменные так, что уже будет в экспоненциальном классе, а значит будет вогнутой функции, а значит, что и будет вогнутым! Интеграл можем даже не считать аналитически, а например использовать методы Монте-Карло. P(X|θ) P(X, Z|θ) log P(X, Z|θ) Z log P(X, Z|θ) 43
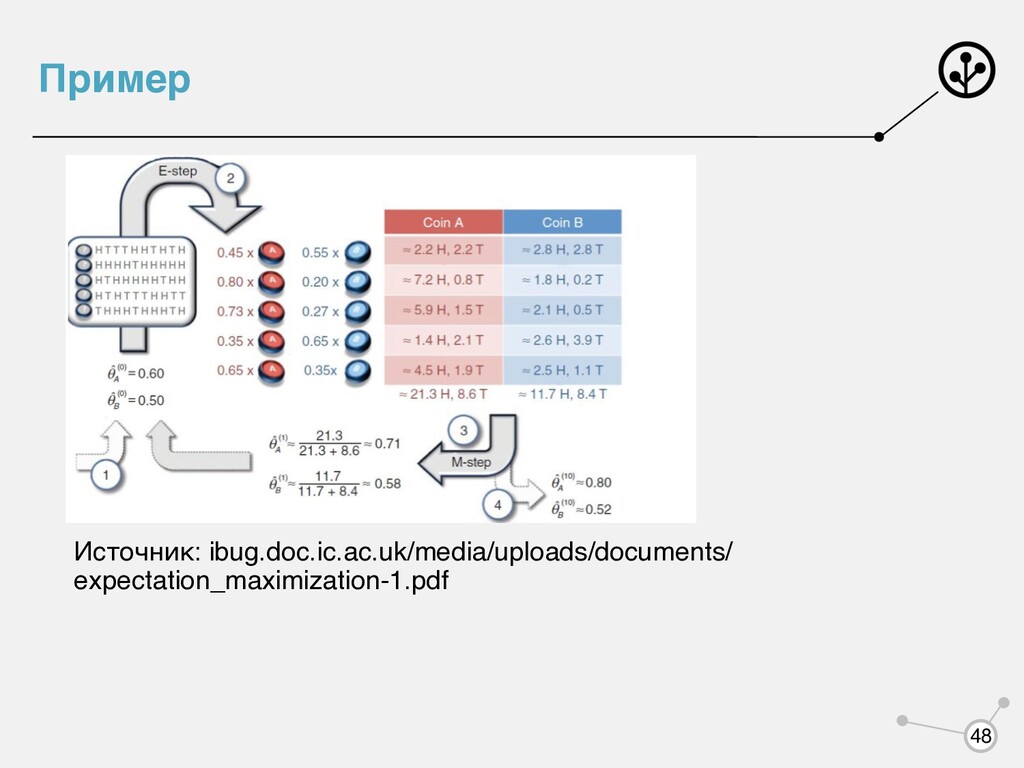
переменные с весами с прошлого шага (E шаг) 2. Нашли новые веса (M шаг) 3. Повторять до сходимости весов θ0 q*(Z) = P(Z|X, θold ) ∫ q*(Z)log P(X, Z|θ)dZ → max θ 44
«Насколько вероятно, что целевая переменная равна классу при условии, что этот объект имеет вектор весов » Считаем такую вероятность по обучающей выборке! Как оцениваем каждый множитель? a*(x) = argmax y∈Y p(y|x) y x a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x) = argmax y∈Y p(x|y)p(y) 53
по классам 2. Оценили , как долю данного класса в обучающей выборке для каждого класса 3. Решили, как будем считать 4. Посчитали и умножили на для каждого класса 5. Взяли класс с максимальным значением Какими способами можно оценить p(y) p(x|y) p(x|y) p(y) a*(x) = argmax y∈Y p(y|x) = argmax y∈Y p(x|y)p(y) p(x|y) 54 Напоминание
точек из обучающей выборки лежит в окрестности оцениваемого значения. 2. Параметрический — предполагаем, что наше распределение из параметрического семейства. Настраиваем параметры распределения по обучающей выборке. 3. Восстановление из смеси распределений — предполагаем, что наше распределение смесь параметрических распределений. Почему нельзя для смеси восстановить непараметрически или параметрически? 55
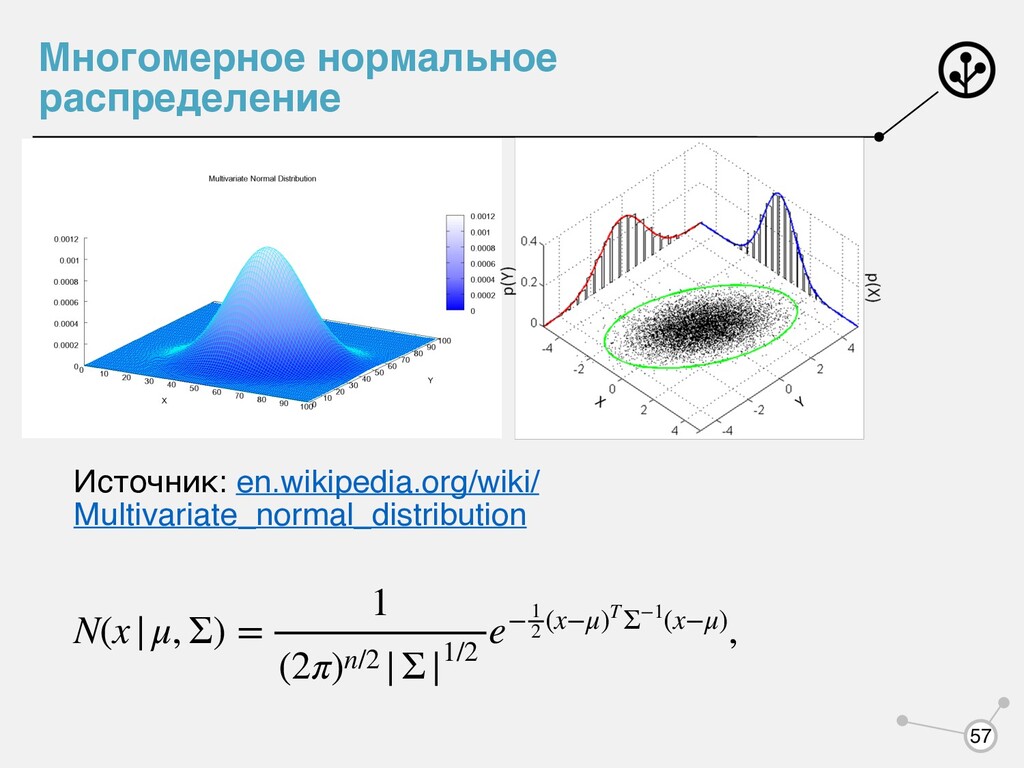
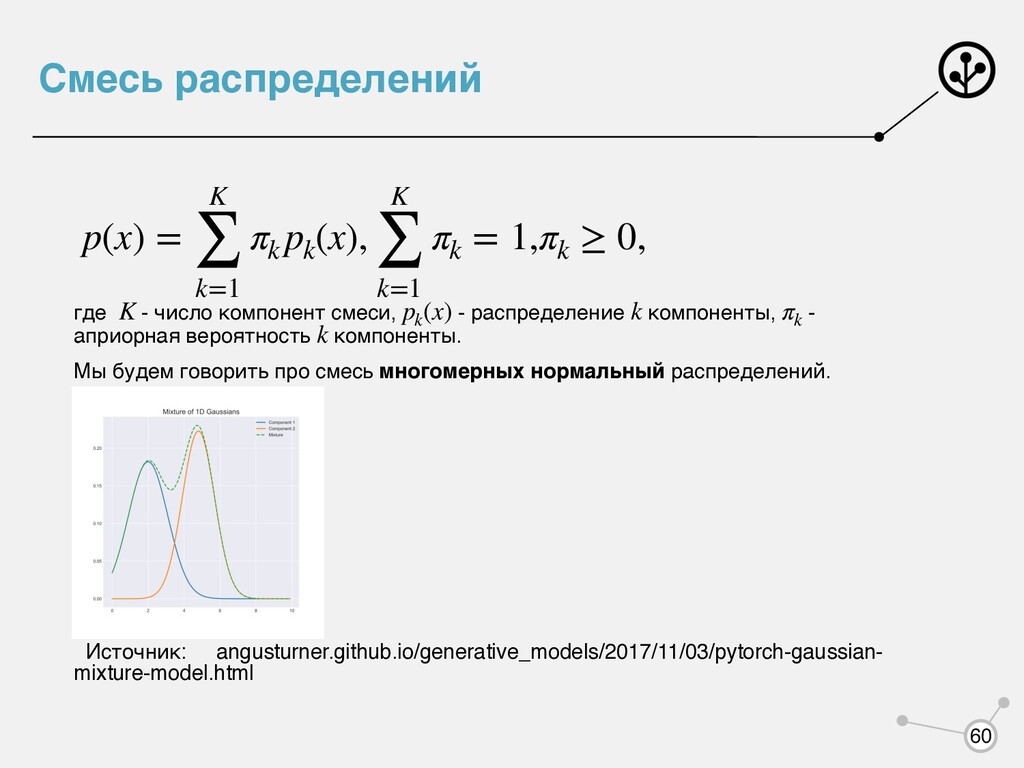
- априорная вероятность компоненты. Мы будем говорить про смесь многомерных нормальный распределений. Источник: angusturner.github.io/generative_models/2017/11/03/pytorch-gaussian- mixture-model.html p(x) = K ∑ k=1 πk pk (x), K ∑ k=1 πk = 1,πk ≥ 0, K pk (x) k πk k 60
скрытую переменную, которая будет отвечать за выбор компоненты. - -мерный вектор, у которого одна компонента равна 1 , а остальные 0. Вот так уже намного приятнее! pk (x) = ϕ(x|Θk ) log P(X|Θ) = log N ∏ i=1 p(xi |Θ) = N ∑ i=1 log K ∑ k=1 πk ϕ(xi |Θk ) log P(X, Z|Θ) = log N ∏ i=1 p(xi , Z|Θ) z k p(xi , Z|Θ) = K ∏ k=1 [πk ϕ(xi |Θk )]zi,k log P(X, Z|Θ) = N ∑ i=1 K ∑ k=1 zi,k (log πk + log ϕ(xi |Θk )) 62
ее градиент к нулю. Тогда получим: ММП для нормального распределения давало вот что: То есть по сути такие же формулы, только взвешены с помощью (насколько объект подходит под компоненту) πk = 1 N N ∑ i gi,k μk = ∑N i gi,k xi ∑N i gi,k Σk = ∑N i gi,k (xi − μk )(xi − μk )T ∑N i gi,k μ = 1 N N ∑ i=1 xi , Σ = 1 N N ∑ i=1 (xi − μ)T(xi − μ) gi,k 65
1. Выбрали начальные параметры 2. Оценили для каждого объекта его принадлежность к каждой гауссиане 3. Обновили параметры по формулам 4. Повторять 2 3 до сходимости Зачем это может понадобиться, кроме как для восстановления плотности? πk , μk , Σk gi,k πk , μk , Σk 66
кластеризация. Вы можете применять ее на огромных массивах неразменных данных, находя такие мягкие кластера. Дальше можно их использовать как признаки в задаче обучения с учителем. GMM это генеративная модель? 67
стремится к нулю, априорные вероятности кластеров равны. Если стремится к нулю, то для самой близкой к объекту гауссианы и для всех остальных. Дальше пересчитали единственный параметр: Ничего не напоминает? Σ = σ2I σ2 p(zi,k = 1|xi , Θold) = πold k N(xi |μold k , Σold k ) K ∑ j=1 πold j N(xi |μold j , Σold j ) = exp(− 1 2σ2 ||xi − μk ||2 ) ∑K j=1 exp(− 1 2σ2 ||xi − μj ||2 ) = gi,k σ2 gi,k = 1 i gi,k = 0 μk = ∑N i gi,k xi ∑N i gi,k 70
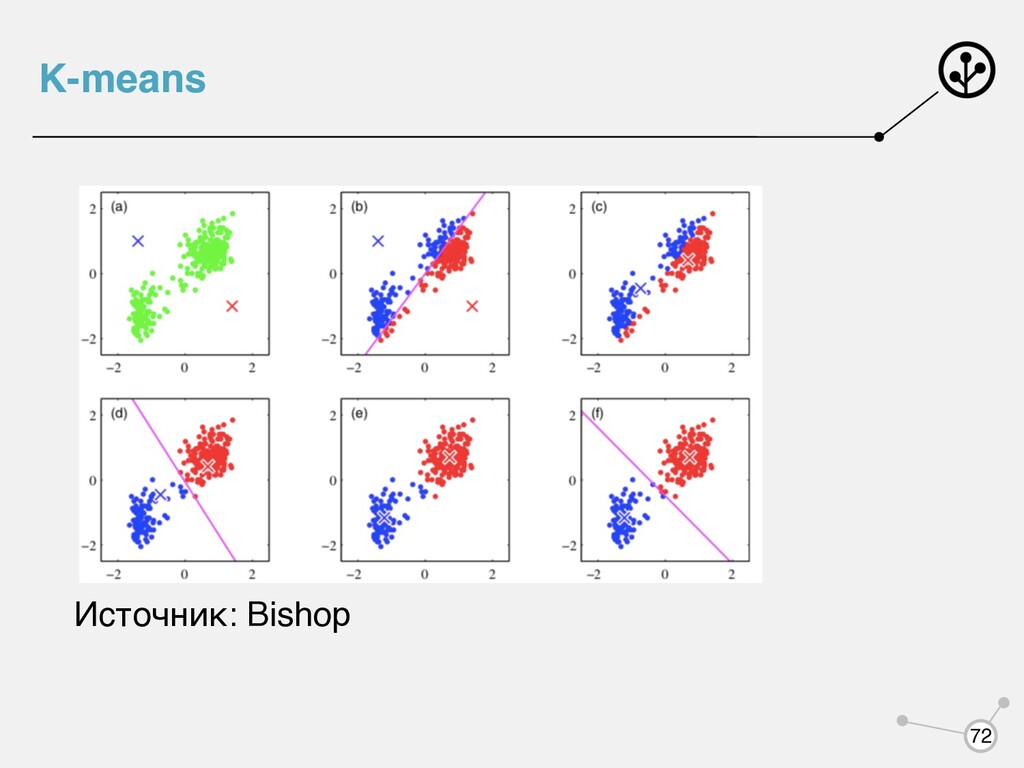
функциям мы переходим от мягкой кластеризации к жесткой. 1. Выбрали начальные центры кластеров 2. Каждый объект отнесли к ближайшему кластера 3. Обновили центры кластеров по формулам 4. Повторять 2 3 до сходимости 71
• Познакомились с многомерным нормальным распределением • С помощью EM алгоритма нашли параметры GMM • Вспомнили, что такое генеративные модели • Узнали связь k-means с GMM 73
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}