эмпирического риска: , — семейство алгоритмов. Формула обучения: Learning = Representation + Evaluation + Optimization Источник: homes.cs.washington.edu/~pedrod/papers/ cacm12.pdf Q(a, X, Y) = 1 N ∑N i=1 L(a, xi , yi ), xi ∈ X, yi ∈ Y a* = argmin A Q(a, Xtrain , Ytrain ) A 4
где — -мерный вектор признаков Далее будем считать, что в векторе признаков есть тождественно равный единице признак , тогда формула упростится до: Representation: Параметры модели интерпретируемы. — значение, на которое изменится предсказание, если признак увеличить на единицу. Какая гипотеза лежит в основе линейной модели? D f1 , f2 , …fD a(x, w) = w0 + ∑D j=1 fj wj w D w1 , w2 , …wD f0 a(x, w) = ∑D j=0 fj wj = x ⋅ w wi fi 6 Representation
— вектор предсказаний Источник: jakevdp.github.io/PythonDataScienceHandbook Q(X, w) = 1 N N ∑ i=1 (xi ⋅ w − yi )2 = 1 N ||X ⋅ w − y||2 X (N, D) w (D,1) y (N,1) X ⋅ w (N,1) 9 Optimization
очень редких функций потерь • Обращение матрицы — кубическая сложность • Матрица может быть плохо обусловенной, если есть ЛЗ признаки XT X rank(X) = rank(XT X) 11
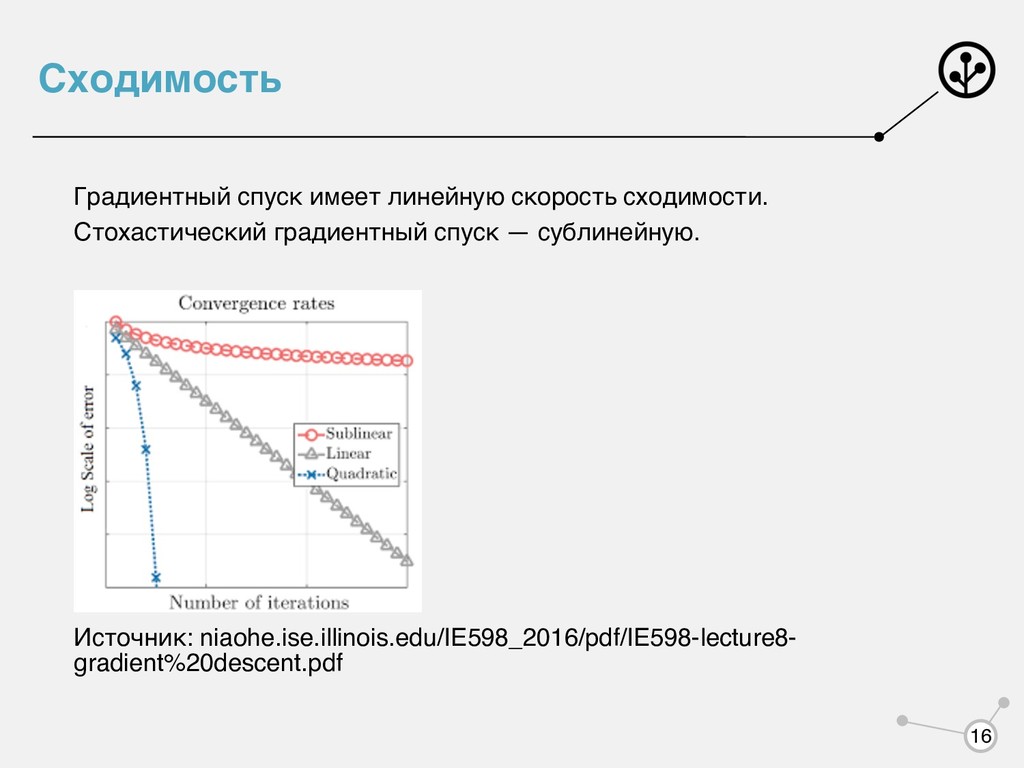
золотое сечение, метод парабол, имитация отжига, генетические алгоритмы и т.д. • Первого порядка: градиентный спуск, метод сопряженных градиентов, квазиньютоновские методы и т.д. • Второго порядка: ньютоновские методы. В курсе разбираем градиентный спуск. w* = argmin w 1 N N ∑ i=1 L(a(xi , w), yi ) 12
минимум 1. Выбрать начальную длину шага , начальное приближение 2. 3. 4. Повторять (2), (3) до сходимости или Можно качество на валидации использовать как критерий останова Q(w) α0 w0 wnew = wold − α∇w Q(wold ) α = f(k), k = k + 1 Q(w) w f(k) = α0 , f(k) = α0 k , f(k) = α0 kp , . . . 13
предсказания Сложность обучения одного шага Делаем GD: Сложность предсказания Сложность обучения одного шага Q(X, w) = 1 2N N ∑ i=1 (xi ⋅ w − yi )2 L(w, xi , yi ) = 1 2 (xi ⋅ w − yi )2 ∇w L(w, xi , yi ) = (xi ⋅ w − yi )xi wnew = wold − α(xi ⋅ wold − yi )xi i N O(D) O(D) wnew = wold − α∑N i=1 (xi ⋅ wold − yi )xi O(D) O(ND) 17
N значений Матожидание величины по определению мат. ожидания То есть в среднем мы как раз идем в сторону антиградиента! j ∼ U(1,N), ∇w Q*(wold ) = ∇w L(wold , xj , yj ) ∇w L(wold , xj , yj ) ∇w L(wold , xj , yj ) 1 N N ∑ j=1 ∇w L(wold , xj , yj ) 18
• Быстро учится • Быстро предсказывает • Легко интерпретируется • Легко хранить в памяти • Легко применять с дифференцируемой функцией потерь Весомый минус - не способен учитывать нелинейные зависимости в данных. 19
предсказание, если признак увеличить на единицу. Категориальные признаки кодируем: • One-hot кодирование - категориальный признак с значениями превращаем в бинарных признаков! • Кодирование через целевую переменную (нельзя включать переменную самого объекта) • Кодирование через вещественные признаки a(x, w) = ∑D j=0 fj wj = x ⋅ w wi fi k k 21
в степень, берем синус и т.д Учитываем взаимодействия: • Пару вещественных перемножаем, делим и т.д. • Для пары бинарных используем логические операции Невозможно сделать правильное признаковое пространство без понимания самой задачи! a(x, w) = ∑D j=0 fj wj = x ⋅ w 22
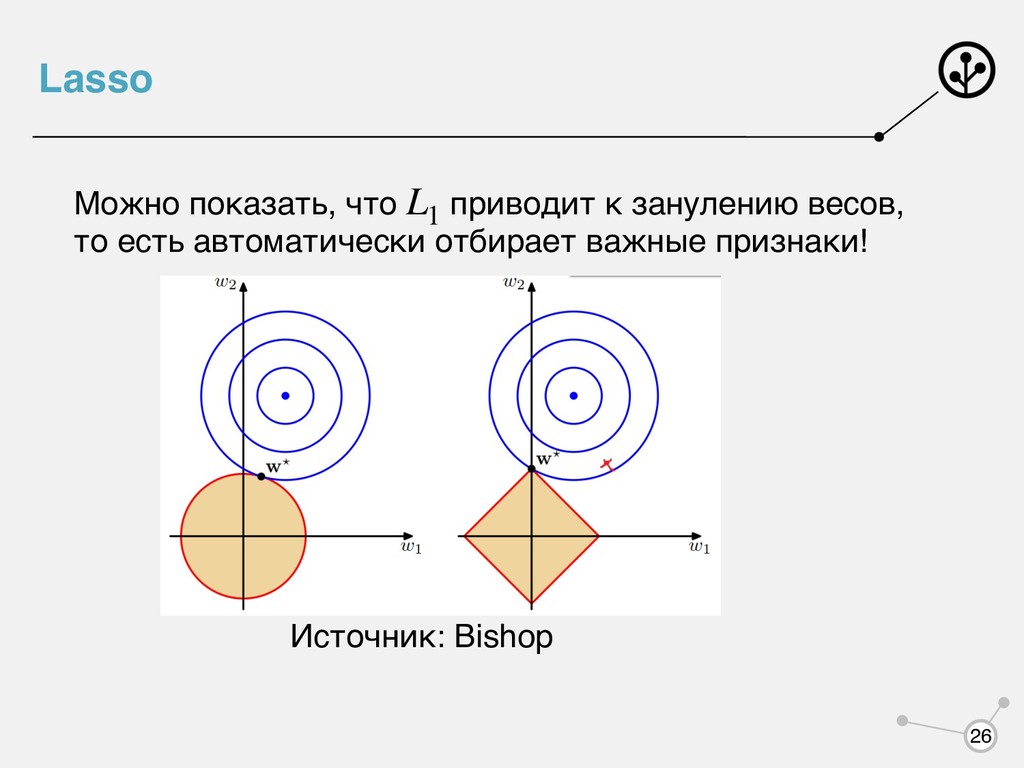
способность. Наложим доп. штраф, если решение удаляется от нашего представления о правильном решении. - регуляризатор, - параметр регуляризации. Как подобрать параметр ? a(x) Qr (w) = Q(w) + αR(w) R(w) α α 24
значения весов: • регуляризация (Lasso регрессия). ; С ней не будет гладким! • регуляризация (Ridge регрессия). Дома вывести формулу точного для регуляризации L1 R(w) = ∑D j=1 |wj | Qr L2 R(w) = ∑D j=1 w2 j . L2 w = (XT X + λ ⋅ I)−1XTy 25
данные в оперативной памяти! Взяли батч, обновили веса и сразу же его забыли. Позволяет легко обучаться на терабайтах данных. Рекомендую ознакомиться с библиотекой Vowpal Wabbit Online learning — обучение, когда прецеденты поступают потоком. 27
Разреженный формат данных - для каждого объекта храним словарь вида {номер ненулевого признака : значение} Приведите пример задачи с разреженными данными Q(X, w) = 1 2N N ∑ i=1 (xi ⋅ w − yi )2 L(w, xi , yi ) = 1 2 (xi ⋅ w − yi )2 ∇w L(w, xi , yi ) = (xi ⋅ w − yi )xi j xi,j = 0 28
— текст, признак — наличие слова в тексте. Делаем one hot кодирование, получаем пространство размера словарь слов. Вместо бинарных признаков часто делают TF-IDF преобразование TF(t) = (сколько раз t встречался в тексте) / (длина текста). IDF(t) =log_e(число текстов/ число текстов с t). 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}